Yrek/TMSupportAgent
GitHub: Yrek/TMSupportAgent
一个 AI 驱动的威胁建模工具,通过解析实际架构文档自动生成包含攻击场景和框架映射的优先级威胁模型,支持多方法并行分析和人机协作审核。
Stars: 3 | Forks: 0
# 威胁建模智能体
大多数威胁模型是在架构设计完成很久之后,凭借记忆和通用检查清单手工编写而成的。其结果是,文档反映的是工程师脑海中系统的模样——而非系统真实的模样。
**Threat Modeling Agent(威胁建模智能体)的工作方式则截然不同。** 您只需提供您的架构——图表、标记语言文件或纯文本描述——它便会读取系统,构建结构化模型,允许您纠正任何它误解的部分,然后基于您实际的组件、数据流和信任边界运行多方法安全分析。最终输出是一份包含具体攻击场景、严重等级、缓解措施和框架参考的优先级威胁列表,且附有可直接放入待办事项列表的修复清单。
无需模板。无需空白表单。没有不适用于您系统的威胁。
## 功能介绍
该智能体运行一个多阶段的 AI 流水线:
1. **上传您的架构** — 支持图片(PNG、JPG)、PlantUML、Mermaid、draw.io XML、Markdown 和纯文本描述。AI 会解析输入,自动提取组件、数据流、信任边界、参与者和数据存储,生成结构化模型。
2. **或从头绘制** — 如果您没有现成的图表,内置画布允许您手动添加元素并通过数据流将它们连接起来。无需任何图表即可开始。
3. **您审查并纠正模型** — 在生成任何威胁之前,您可以确切地看到 AI 理解的内容。修复分类错误的元素,补充缺失的上下文,确认信任边界。这一步确保了分析的可靠性。
4. **分类架构** — 识别决定运行哪些分析方法的模式:多租户 SaaS、云原生、事件驱动、身份复杂的系统、注重隐私的系统、启用 LLM 的系统等。
5. **运行并行威胁分析** — 多个分析过程同时执行,每个过程侧重于不同的攻击视角(STRIDE、LINDDUN、滥用场景、租户隔离、供应链、AI/LLM 威胁……)。分析方法会根据您架构的实际情况进行预先选择。
6. **综合并质疑其自身的发现** — 各分析结果将被合并、去重,并经过对抗性审查,主动寻找遗漏的威胁和盲点。
7. **映射到控制框架** — 每个发现都会映射到 OWASP Top 10、ASVS、CIS Controls、NCSC 和 STRIDE 类别。
8. **生成可立即操作的输出** — 带有严重等级、攻击场景、缓解措施和验收标准的威胁;安全设计建议;按优先级排序的修复列表,可直接粘贴到冲刺待办事项中。
### 您将获得什么
- **已确认的威胁** — 直接由您的架构提供证据,包含攻击场景、前提条件和受影响的组件
- **有条件的威胁** — 依赖于未验证假设的合理威胁(单独明确标出)
- **证据基础** — 每个发现都引用了支持它的具体架构事实;没有任何内容是凭空捏造的
- **控制缺口** — 识别现有控制措施,并针对每个发现解释其缺口
- **安全设计建议** — 建议采用的架构模式,并标记其所应用的安全原则(最小权限、深度防御、爆炸半径缩减……)
- **优先级修复列表** — 根据发生概率 × 影响程度排序的威胁,编写为可放入待办事项的行动项
- **框架映射** — 每个已确认的发现都附有 OWASP、ASVS、NCSC 参考
### 支持的架构类型
Web 应用 · REST API · SPA · BFF · 微服务 · 事件驱动系统 · 多租户 SaaS · 云原生(Azure / AWS / GCP) · 身份复杂的系统 · 启用 LLM 的应用 · Agentic / 启用 MCP 的系统
## 屏幕截图
### 开始新分析
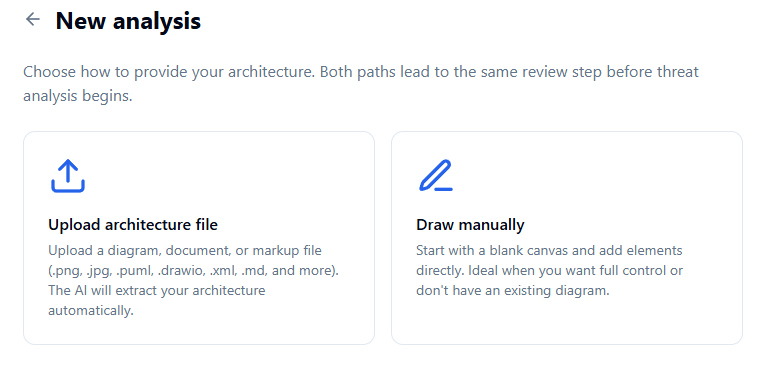
进入工具有两种路径:上传现有的架构文件(图表、标记文件、文档——AI 会自动提取结构),或者从一个空白画布开始手动绘制元素。这两种路径在运行任何分析之前,都会导向相同的审查步骤。
### 架构审查 — 查看 AI 理解的内容,在分析前进行纠正
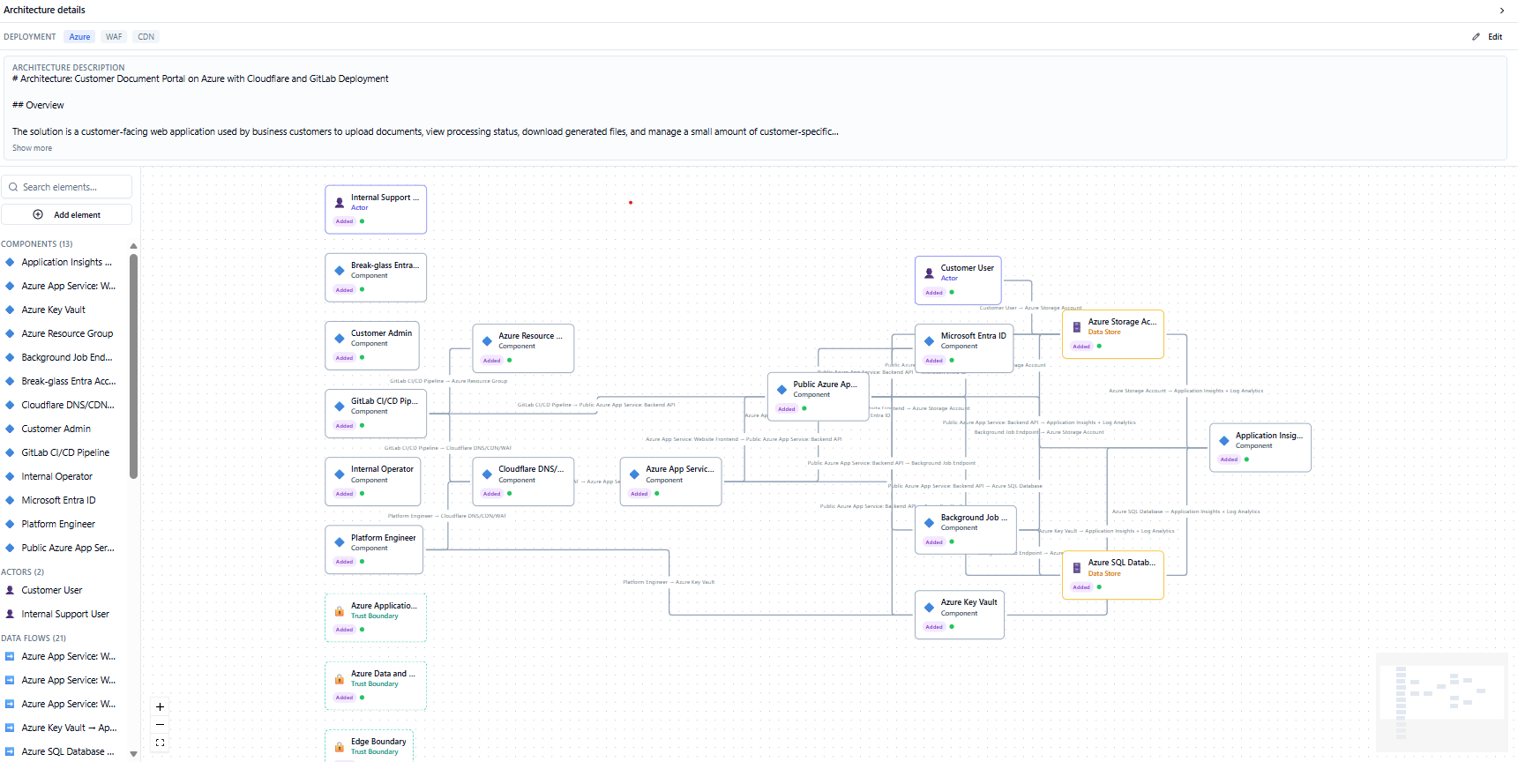
流水线解析您的输入后,会将提取的架构显示为交互式图表。参与者、组件、数据存储、数据流和信任边界以可视化方式布局,并带有显示每个节点威胁密度的严重性叠加层。这是关键步骤:您检查模型,纠正分类错误的元素,填补空白,并在提交分析之前确认信任边界。威胁模型的质量取决于其底层的架构质量——此审查步骤确保 AI 是基于事实而非猜测进行工作。
### 框架选择 — 选择您的分析方法
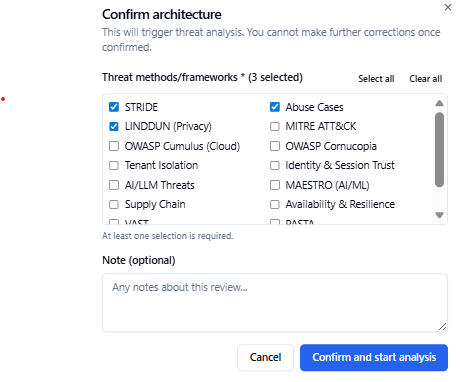
确认架构时,您可以选择要运行的威胁建模方法。系统会预先选择与检测到的架构类型相匹配的方法——对注重隐私的系统选择 LINDDUN,对多租户 SaaS 选择租户隔离,对启用 LLM 的系统选择 AI/LLM 威胁等。您可以在触发分析之前添加或移除任何组合。
### 流水线进度 — 实时阶段跟踪
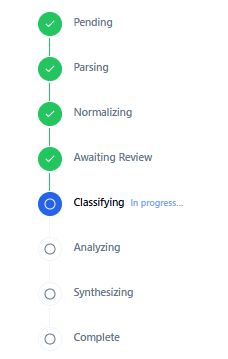
实时进度视图显示当前正在运行的流水线阶段。已完成的阶段用绿色对勾标记。阶段按顺序运行 — 解析 → 规范化 → 等待审查 → 分类 → 分析 → 综合,其中分析阶段会并行运行所有选定的方法过程,然后再由综合阶段合并结果。
### 威胁 — 详细的、基于证据的发现
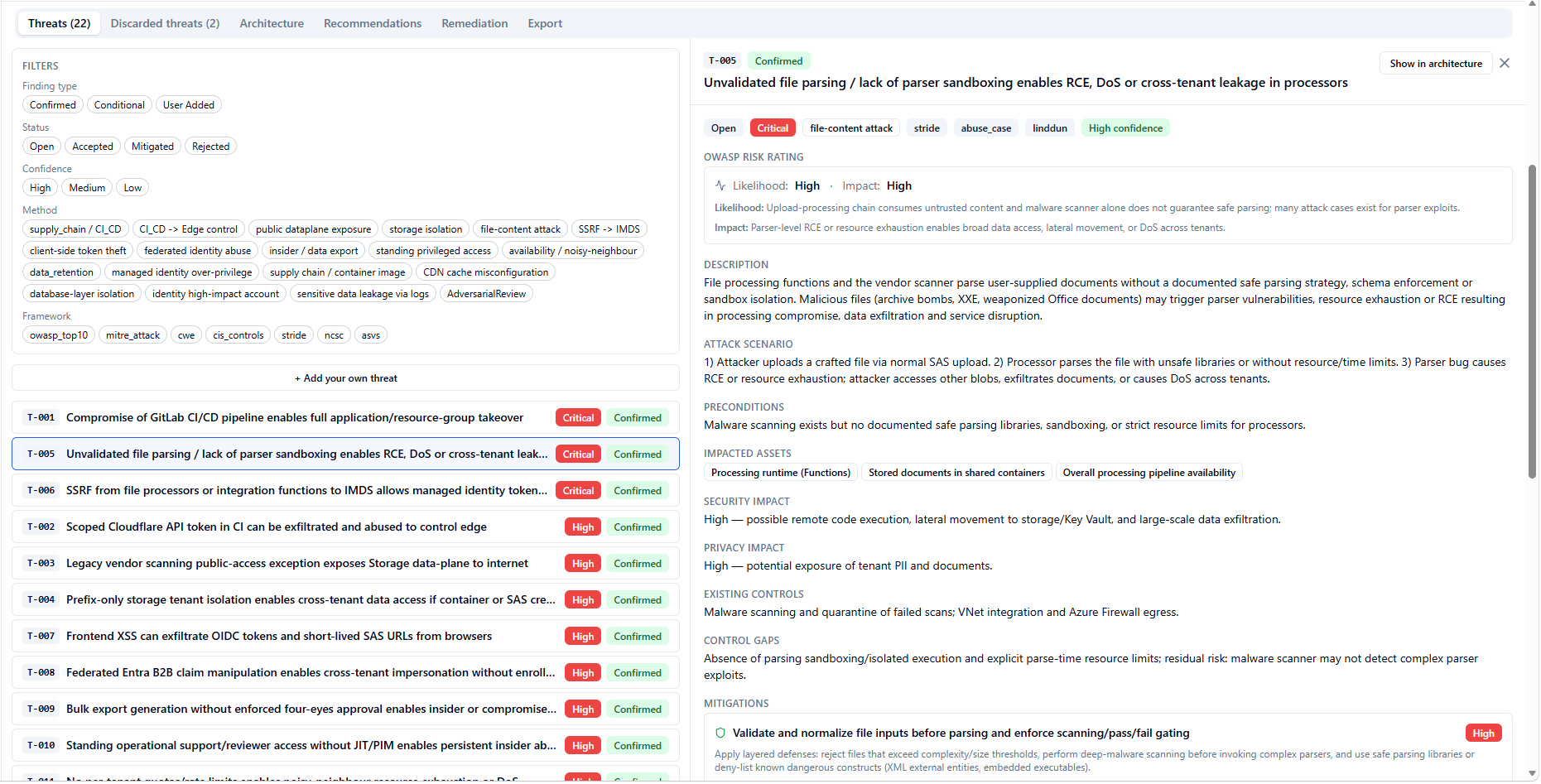
威胁选项卡显示每个已确认和有条件的发现。每个威胁都包含严重等级、受影响的组件、逐步攻击场景、支持它的架构证据、前提条件、带有验收标准的缓解措施,以及 OWASP/ASVS/NCSC 框架参考。有条件的威胁与已确认的威胁清晰区分开来。可按严重程度、方法、框架进行过滤,或点击架构选项卡中的任何组件以仅查看其相关威胁。
### 建议 — 可操作的安全设计模式
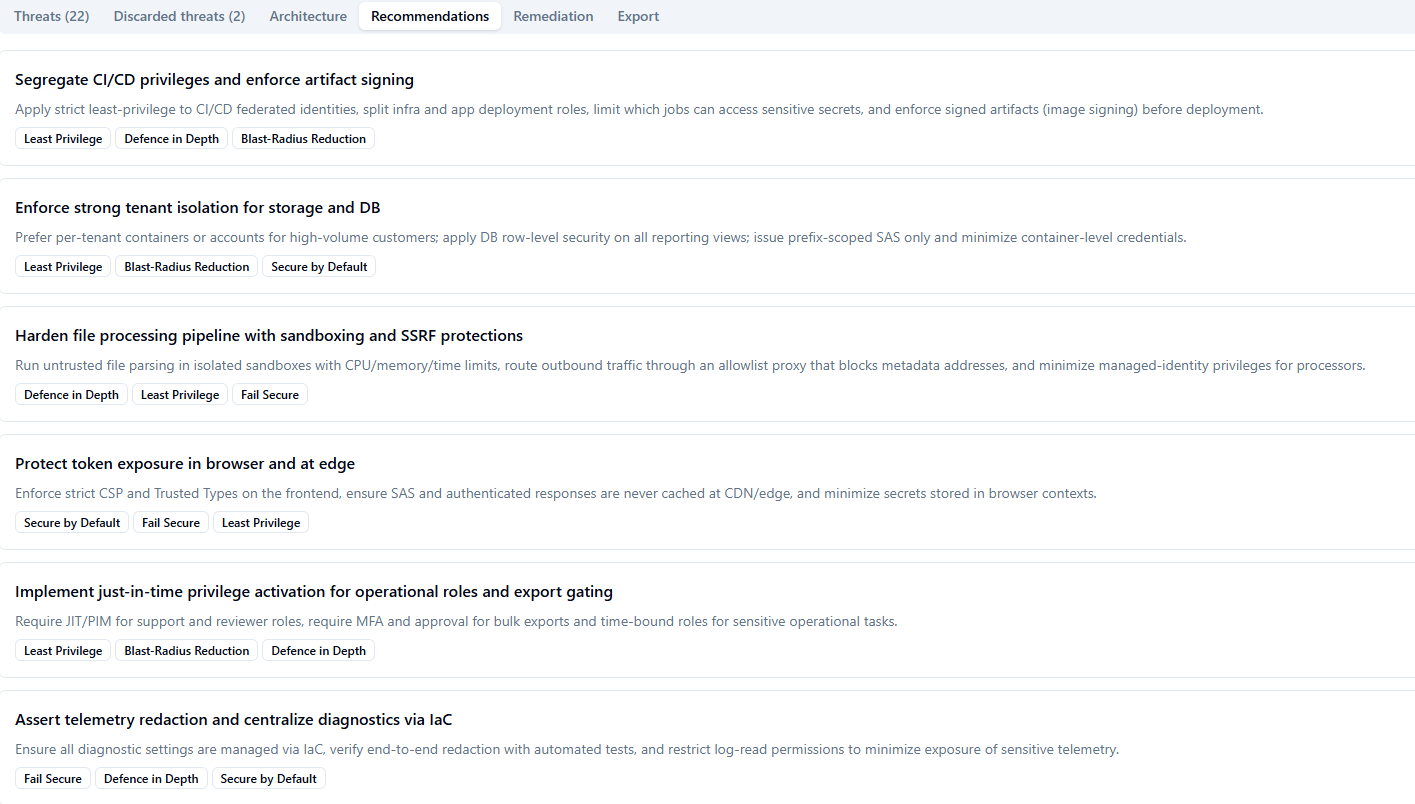
建议选项卡展示了用于解决相关威胁集群的架构模式。每条建议都作为一个具体的设计变更编写——而不是通用的检查清单项——并标记了它所应用的安全原则(最小权限、深度防御、爆炸半径缩减、默认安全、故障安全)。建议在综合阶段生成,并按主题分组,以便团队可以围绕连贯的设计改进而非单独的错误修复来规划工作。
### 修复 — 优先级待办事项列表,随时可用
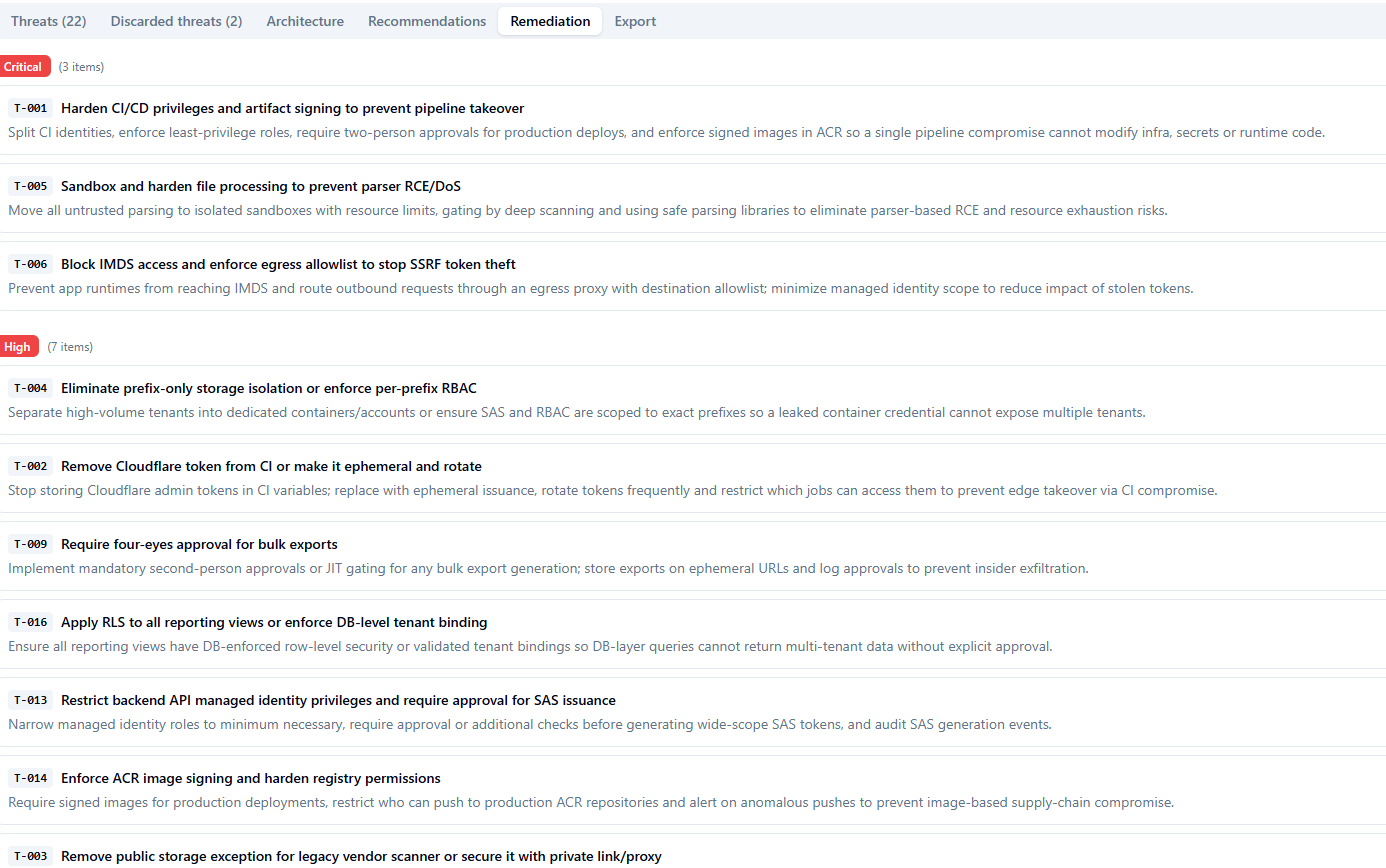
修复选项卡按严重程度(严重 → 高 → 中 → 低)展示了每个已确认的威胁。每个条目显示威胁 ID、简短的操作标题,以及关于实施内容的一句话描述——编写为可直接粘贴到待办事项工单中的格式。请优先处理严重条目。每个条目都链接回完整的威胁详情,以便实施修复的人员拥有所需的所有上下文。
## 导出格式
每个已完成的威胁模型都可以从 **导出** 选项卡中以五种格式导出:
| 格式 | 文件 | 用例 |
|---|---|---|
| **JSON** | `threat-model-.json` | 完整的结构化分析数据块 — 包含所有威胁、缓解措施、证据、框架映射和元数据。机器可读,适用于下游工具或归档。 |
| **Markdown 报告** | `threat-model-.md` | 人类可读的威胁模型报告,包含所有发现、攻击场景、缓解措施、建议和修复列表。可直接提交到代码库或粘贴到 Wiki 中。 |
| **Mermaid 图表** | `architecture-.mmd` | 提取并纠正后的架构重新导出为 Mermaid 流程图。可编辑、可比较差异,并可在 GitHub、GitLab 和大多数文档工具中渲染。 |
| **TM-BOM** | `tm-bom-.json` | 便携式威胁模型物料清单 — 包含架构、使用的方法、所有威胁以及结构化交换格式的控制映射。专为工具间传输而设计。 |
| **Threat Dragon v2** | `threat-dragon-v2-.json` | 将架构和威胁投影到 OWASP Threat Dragon v2 JSON 格式中,适用于已在其工作流中使用 Threat Dragon 的团队。 |
## 快速入门
**前提条件:** .NET 10 SDK、Node.js 20+、Docker Desktop、`dotnet-ef` 全局工具。
```
# 1. 启动本地服务 (PostgreSQL, Azurite, Service Bus emulator)
docker compose up -d
# 2. 应用数据库迁移
dotnet ef database update \
--project src/ThreatModelingAgent.Infrastructure \
--startup-project src/ThreatModelingAgent.Api
# 3. 配置本地设置
# 复制并编辑示例文件 — 有关所有选项,请参阅 docs/deployment/local.md
cp src/ThreatModelingAgent.Api/appsettings.Development.json.example \
src/ThreatModelingAgent.Api/appsettings.Development.json
cp src/ThreatModelingAgent.Worker/appsettings.Development.json.example \
src/ThreatModelingAgent.Worker/appsettings.Development.json
# 4. 运行
dotnet run --project src/ThreatModelingAgent.Api # terminal 1 → http://localhost:5240
dotnet run --project src/ThreatModelingAgent.Worker # terminal 2
cd frontend && npm install && npm run dev # terminal 3 → http://localhost:5173
```
请参阅 **[docs/deployment/local.md](docs/deployment/local.md)** 获取包含身份验证选项的完整本地设置指南。
## LLM 提供商
该智能体支持四个提供商。可以混合搭配——将繁重的安全推理路由到强大的模型,将分类任务路由到低成本的模型。
| 提供商 | 所需 Key | 推荐的 `StrongModel` | 推荐的 `LowCostModel` |
|---|---|---|---|
| **OpenAI** | `OpenAI:ApiKey` | `gpt-5.1` | `gpt-5-mini` |
| **Azure OpenAI** | `AzureOpenAI:Endpoint` + `AzureOpenAI:ApiKey` | `gpt-5.1` | `gpt-5-mini` |
| **Anthropic** | `Anthropic:ApiKey` | `claude-opus-4-7` | `claude-haiku-4-5-20251001` |
| **Google Gemini** | `Google:ApiKey` ([aistudio.google.com](https://aistudio.google.com)) | `gemini-2.5-pro` | `gemini-2.5-flash` |
在 `src/ThreatModelingAgent.Worker/appsettings.Development.json` 中设置 `LlmRouting:StrongModel` 和 `LlmRouting:LowCostModel`。
当同时存在 `OpenAI:ApiKey` 和 `AzureOpenAI` 凭据时,对于 `gpt-*` / `o-series` 模型名称,将优先使用原生 OpenAI。
## 身份验证
### 选项 A — 开发认证(仅限本地,无需账号)
在两个配置中启用此选项以完全跳过 WorkOS:
```
// Api appsettings.Development.json
"DevAuth": { "Enabled": true, "SigningKey": "dev-local-signing-key-change-me-32chars!!" }
```
```
# frontend/.env.local
VITE_DEV_AUTH=true
```
然后在 `http://localhost:5173/login` 使用任意邮箱地址登录。有关详细信息,请参阅 [docs/deployment/local.md](docs/deployment/local.md)。
### 选项 B — WorkOS(推荐用于预发布/生产环境)
此应用使用 [WorkOS](https://workos.com) 进行身份验证——免费套餐即可满足本地开发需求。
1. 在 [workos.com](https://workos.com) 注册 → 创建一个应用 → 启用 **User Management (AuthKit)**
2. 从仪表盘的 **API Keys** 中复制凭据:
| 配置键 | 在哪里找到它 |
|---|---|
| `WorkOS:ClientId` | Client ID(以 `client_` 开头) |
| `WorkOS:ApiKey` | Secret Key(以 `sk_` 开头) |
3. 在仪表盘的 **Redirects** 下添加重定向 URI:
| 类型 | 本地开发 | 生产环境 |
|---|---|---|
| 登录重定向 URI | `http://localhost:5173/auth/callback` | `https://yourdomain.com/auth/callback` |
| 登出重定向 URI | `http://localhost:5173/login` | `https://yourdomain.com/login` |
4. 在 `appsettings.Development.json` 中设置值:
```
"WorkOS": {
"ClientId": "client_XXXXXXXXXXXX",
"ApiKey": "sk_XXXXXXXXXXXX",
"Issuer": "https://api.workos.com",
"JwksUri": "https://api.workos.com/.well-known/jwks.json"
}
```
通过 WorkOS Organizations 支持每个组织的 SSO(SAML/OIDC)。在 WorkOS 仪表盘中配置连接——无论使用何种 IDP,应用都会接收标准的 JWT。
## 流水线工作原理
```
Upload diagram or text description
│
▼
DETECT ─ identify artifact type (image / PlantUML / Mermaid / draw.io / text)
│
▼
PARSE ─ extract raw elements, flows, boundaries, and relationships
│
▼
NORMALIZE ─ build a structured canonical architecture model
│
▼
┌── USER REVIEW ──────────────────────────────────────────────────┐
│ Inspect the extracted architecture. Correct mistakes, │
│ add missing context, confirm trust boundaries. │
└─────────────────────────────────────────────────────────────────┘
│
▼
CLASSIFY ─ categorise the architecture, select threat modeling methods
│
▼
ANALYZE ─ run parallel analysis passes (STRIDE, LINDDUN, abuse cases,
│ tenant isolation, AI threats, …) — one pass per method
│
▼
SYNTHESIZE ─ merge, deduplicate, adversarial review, map to frameworks,
produce final output with mitigations and remediation list
```
每个发现都可以追溯到特定的架构元素,并引用了支持该发现的证据。如果证据较弱或依赖于未验证的假设,则该发现会被标记为有条件的而非已确认的。
## 项目结构
```
TMSupportAgent/
├── CLAUDE.md # Security specification (mandatory — read before writing code)
├── docker-compose.yml # Local dev services (PostgreSQL, Azurite, Service Bus)
│
├── docs/
│ ├── specs/ # Feature and architecture specs (source of truth)
│ ├── adr/ # Architecture Decision Records
│ ├── api/openapi.yaml # OpenAPI 3.1 contract
│ └── deployment/ # local.md · azure.md
│
├── infra/ # Bicep modules for Azure deployment
├── .github/workflows/ # CI (every PR) + CD (merge to main)
│
└── src/
├── ThreatModelingAgent.Api/ # ASP.NET Core REST API
├── ThreatModelingAgent.Worker/ # Background pipeline worker
├── ThreatModelingAgent.Domain/ # Domain entities and interfaces
└── ThreatModelingAgent.Infrastructure/ # EF Core, repositories, Azure clients
```
## 部署
| 目标 | 指南 |
|---|---|
| 本地开发 | [docs/deployment/local.md](docs/deployment/local.md) |
| Azure(生产/预发布) | [docs/deployment/azure.md](docs/deployment/azure.md) |
CI 会在每次拉取请求时运行。通过 **Actions → Deploy** 手动触发部署——选择 `staging` 或 `prod`。
## 贡献
1. 在编写任何代码之前阅读 [CLAUDE.md](CLAUDE.md) ——它是强制性的安全规范。
2. 查看 [docs/specs/README.md](docs/specs/README.md) 了解已规范化和已批准的内容。
3. 架构决策在实施前需写入 ADR。
4. 所有 PR 必须引用它们所实现的规范。
安全要求是功能性验收标准——如果缺少强制性安全控制,则特性就不算完成。
如有问题、想法或贡献提案,请通过 **marcus.persson85@gmail.com** 联系。
标签:AI安全工具, ASVS, CISA项目, DevSecOps, DLL 劫持, draw.io, GPT, Mermaid, MITM代理, NCSC, PlantUML, SaaS安全, Web报告查看器, 上游代理, 人工智能, 信任边界, 多模态处理, 大语言模型, 威胁分析, 威胁建模, 安全合规, 安全左移, 安全架构, 密码管理, 攻击场景生成, 架构图解析, 测试用例, 漏洞管理, 用户模式Hook绕过, 结构化查询, 网络代理, 自动化侦查工具, 自动化合规, 自动化安全, 证据驱动, 请求拦截, 风险量化