pratik0620/incident-response-triage-openenv
GitHub: pratik0620/incident-response-triage-openenv
这是一个基于OpenEnv的强化学习环境,通过模拟真实微服务生产事故,训练AI智能体利用日志、指标和告警进行根因分析与故障修复。
Stars: 1 | Forks: 0
title: Incident Response Triage Env
emoji: 🚨
colorFrom: red
colorTo: yellow
sdk: docker
pinned: false
app_port: 7860
tags:
- openenv
- incident-response
- devops
- sre
- reinforcement-learning
# Incident Response 响应分流环境
一个 [OpenEnv](https://github.com/meta-pytorch/OpenEnv) 强化学习环境,供 AI 智能体诊断现实世界中的生产事故。智能体从模拟的微服务系统中读取日志、指标和告警,必须识别根本原因、提出修复方案,并在步数预算内高效完成。
为 **Meta × SST OpenEnv Hackathon 2026** 构建。
## Environment 概览
现实中的 SRE 团队通过阅读日志和指标、形成假设并提出补救措施来响应生产事故。本环境模拟了涵盖三个难度级别的 15 个真实事故场景的完整工作流。
每个回合都会向智能体呈现一个实时事故:级联服务故障、充满噪声的告警以及旨在误导的干扰服务。智能体必须梳理证据,识别真正的根本原因并提出具体的修复方案——所有这些都必须在有限的步数预算内完成。
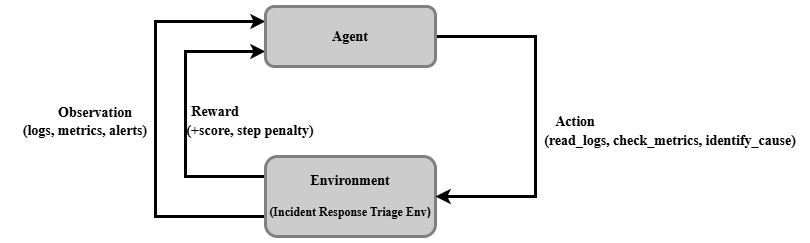
## Agent-Environment 交互
每个回合遵循智能体与环境之间的结构化交互循环:
1. **Reset** → 环境返回初始观察(日志、指标、告警)
2. **Act** → 智能体选择一个动作(例如,`read_logs`、`check_metrics`、`identify_cause`、`propose_fix`、`escalate`)
3. **Observe** → 环境返回更新后的观察(日志、指标、告警)+ 奖励
4. **Repeat** → 直到执行终止动作或达到步数预算
## 为什么该环境是现实的
本环境反映了 SRE 团队使用的现实世界事故响应工作流:
- **Multi-signal debugging** — 智能体必须关联日志、指标和告警,而不是依赖单一来源
- **Cascading failures** — 问题在服务之间传播,需要进行依赖追踪
- **Noise and red herrings** — 并非所有告警都相关,迫使进行选择性推理
- **Action cost trade-offs** — 过度的调查会降低分数,模拟生产事故中的时间压力
- **Fix quality matters** — 不仅仅是识别问题,还要提出正确且完整的补救措施
与合成基准不同,本环境奖励 **因果推理、证据支撑和决策效率**。
## 动作空间
| Action | Type | Cost | Description |
|---|---|---|---|
| `read_logs` | Investigative | -0.02/step | 获取当前场景的带时间戳的日志条目 |
| `check_metrics` | Investigative | -0.02/step | 获取每个服务的 CPU、内存、错误率和 p99 延迟 |
| `identify_cause` | Terminal | — | 声明根本原因服务和故障类型。结束回合。 |
| `propose_fix` | Terminal | — | 声明根本原因并提出完整的修复方案。结束回合。 |
| `escalate` | Terminal | — | 当无法诊断时移交处理。返回固定的 0.2 奖励。 |
**Action schema:**
```
{
"action_type": "identify_cause",
"reasoning": "The logs show connection pool exhausted on postgres-primary...",
"answer": "db_connection_pool_exhaustion",
"service": "postgres-primary"
}
```
## 观测空间
每一步返回一个 `IncidentResponseTriageObservation`,包含:
| Field | Type | Description |
|---|---|---|
| `logs` | `list[LogEntry]` | 带时间戳的日志条目(服务、级别、消息) |
| `metrics` | `list[MetricSnapshot]` | 每个服务的 CPU%、内存%、错误率、p99 延迟 |
| `alerts` | `list[Alert]` | 触发的告警,包含严重性(P1–P4)和消息 |
| `step` | `int` | 当前步数 |
| `max_steps` | `int` | 该难度的步数预算 |
| `previous_actions` | `list[str]` | 已采取的动作类型历史 |
| `task_description` | `str` | 事故的纯英文描述 |
| `reward` | `float` | 当前步的奖励 |
| `done` | `bool` | 回合是否结束 |
| `final_score` | `float \| None` | 最终 0.0–1.0 分数(当 done=True 时设置) |
## 任务
| Difficulty | Scenarios | max_steps | Description |
|---|---|---|---|
| **Easy** | 5 | 10 | 单个服务故障,具有清晰的日志信号且无干扰项。智能体应在 2–4 步内完成诊断。 |
| **Medium** | 5 | 15 | 跨 2–3 个服务的级联故障,包含 1 个干扰服务。智能体必须追踪依赖链。 |
| **Hard** | 5 | 20 | 嘈杂的多服务日志,包含 2 个以上干扰项以及混合的偶发/真实故障。智能体除了识别根本原因外,还必须对故障类型进行分类(real, flaky, env_specific)。 |
### 简单场景示例
### 困难场景示例
## 奖励函数
分数由一个具有难度加权信号的 6 信号确定性评分器计算得出:
| Signal | Easy | Medium | Hard | Description |
|---|---|---|---|---|
| **A** Root cause | 0.35 | 0.25 | 0.15 | 识别出正确的服务和故障类型 |
| **B** Fix quality | 0.30 | 0.20 | 0.15 | 分级:重启 (0.3) → 功能修复 (0.7) → 修复 + 预防 (1.0) |
| **C** Reasoning | 0.10 | 0.25 | 0.30 | 因果链质量:日志 → 原因 → 结果 |
| **D** Faithfulness | 0.10 | 0.15 | 0.20 | 推理基于实际的日志内容,而非幻觉 |
| **E** Noise handling | 0.10 | 0.10 | 0.15 | 正确忽略干扰服务 |
| **F** Efficiency | 0.05 | 0.05 | 0.05 | 步数预算使用情况(非线性:≤25% 预算 → 1.0,≤50% → 0.8,...) |
**加权求和后应用的调整规则:**
- 如果根本原因分数 < 0.3 → 总分 × 0.5(正确的修复但错误的诊断 = 运气)
- 如果修复质量分数 − 推理分数 > 0.5 → −0.15(高修复 + 低推理 = 照搬答案)
- 如果噪声分数 < 0.3 → −0.10(过度猜测惩罚)
## 设置
**Requirements:** Python 3.10+, Docker
```
git clone https://github.com/pratik0620/incident-response-triage-openenv
cd incident-response-triage-openenv
pip install -e ".[dev]"
```
**Start the server locally:**
```
uvicorn server.app:app --host 0.0.0.0 --port 8000
```
**Run inference API (HF-compatible):**
```
export HF_TOKEN=your_token
export API_BASE_URL=https://router.huggingface.co/v1
export MODEL_NAME=Qwen/Qwen2.5-7B-Instruct
export ENV_BASE_URL=http://localhost:8000
uvicorn inference:app --host 0.0.0.0 --port 7860
```
**Run baseline inference:**
```
export HF_TOKEN=your_token
export API_BASE_URL=https://router.huggingface.co/v1
export MODEL_NAME=Qwen/Qwen2.5-7B-Instruct
export ENV_BASE_URL=https://pratik234567-incident-response-triage-env.hf.space
python inference.py
```
**Run via Docker:**
```
docker build -t incident-response-env:local .
docker run -p 7860:7860 incident-response-env:local
```
**Test Endpoints:**
```
curl http://localhost:7860/health
curl http://localhost:7860/grade/task_easy
curl http://localhost:7860/grade/task_medium
curl http://localhost:7860/grade/task_hard
```
## 基准分数
通过 HuggingFace router 使用 `Qwen/Qwen2.5-7B-Instruct` 进行评估。
| Difficulty | Final Score | Steps | Success |
|---|-------------|---|------|
| Easy | 0.88 | 3 | true |
| Medium | 0.69 | 3 | true |
| Hard | 0.56 | 3 | true |
## 来自 Baseline Agent 的观察
在评估过程中,我们观察到当满足以下条件时,智能体性能会显著提升:
- **答案字段包含显式的因果推理**,而不仅仅是标签
- 智能体使用诸如 *"日志显示"*、*"由于"* 和 *"导致"* 之类的短语来形成清晰的因果链
- **明确提及服务名称和故障类型**
- 在中等和困难任务中,使用 `propose_fix` 而不是 `identify_cause` 可以解锁额外的奖励信号
- 答案基于 **日志和指标证据**,提高了忠实度分数
这些观察结果表明,该环境奖励 **结构化推理、证据支撑和决策效率**,而非简短或隐含的答案。
## Environment API
```
from incident_response_triage_env.client import IncidentResponseTriageEnv
from incident_response_triage_env.models import IncidentResponseTriageAction
async with IncidentResponseTriageEnv(base_url="https://huggingface.co/spaces/pratik234567/incident-response-triage-env") as env:
result = await env.reset(difficulty="easy")
obs = result.observation
action = IncidentResponseTriageAction(
action_type="identify_cause",
reasoning="Logs show connection pool exhausted on postgres-primary",
answer="db_connection_pool_exhaustion",
)
result = await env.step(action)
print(result.observation.final_score) # 0.0–1.0
```
## 项目结构
```
incident_response_triage_env/
├── inference.py # Baseline inference script
├── models.py # Pydantic Action, Observation, State models
├── client.py # EnvClient (WebSocket)
├── openenv.yaml # Environment manifest
├── Dockerfile # Container definition
├── graders/
│ ├── composite_grader.py # Master grader — routes to sub-graders
│ ├── signals.py # 6 independent scoring signals (A–F)
│ ├── weights.py # Difficulty-based weight tables
│ └── synonyms.py # Cause type synonym and fix tier maps
├── scenarios/
│ ├── easy/ # 5 easy incident scenarios
│ ├── medium/ # 5 medium incident scenarios
│ └── hard/ # 5 hard incident scenarios
└── server/
├── app.py # FastAPI application
└── incident_response_triage_env_environment.py # Environment logic
```
## 作者
- **Pratik Morkar**
- **Nishant Ninawe**
- **Surabhi Nikam**
Built with [OpenEnv](https://github.com/meta-pytorch/OpenEnv) · [HuggingFace](https://huggingface.co) · [Meta PyTorch](https://github.com/meta-pytorch)
标签:AIOps, Apex, Docker, Docker容器, OpenEnv, PyTorch, SRE, 事故分类, 人工智能代理, 仿真环境, 偏差过滤, 告警管理, 安全防御评估, 库, 应急响应, 强化学习, 性能监控, 指标监控, 攻击面发现, 故障诊断, 智能运维, 机器学习, 根因分析, 站点可靠性工程, 系统调试, 级联故障, 网络安全, 请求拦截, 运维自动化, 逆向工具, 隐私保护, 黑客松项目