Aoblex/sparsemax-attn
GitHub: Aoblex/sparsemax-attn
基于 PyTorch 的高效近似 Sparsemax Attention 算法库,通过限制支撑集大小实现稀疏注意力计算的加速。
Stars: 0 | Forks: 0
# Sparsemax Attention
Softmax attention:
$$
O = \text{softmax}(\frac{Q K^T}{\sqrt{d}}) V
$$
Sparsemax attention:
$$
O = \text{sparsemax}(\frac{Q K^T}{\sqrt{d}}) V
$$
本仓库实现了 sparsemax 的**近似**版本,其支撑集大小至多为 $k \in \{4, 8\}$。
性能:
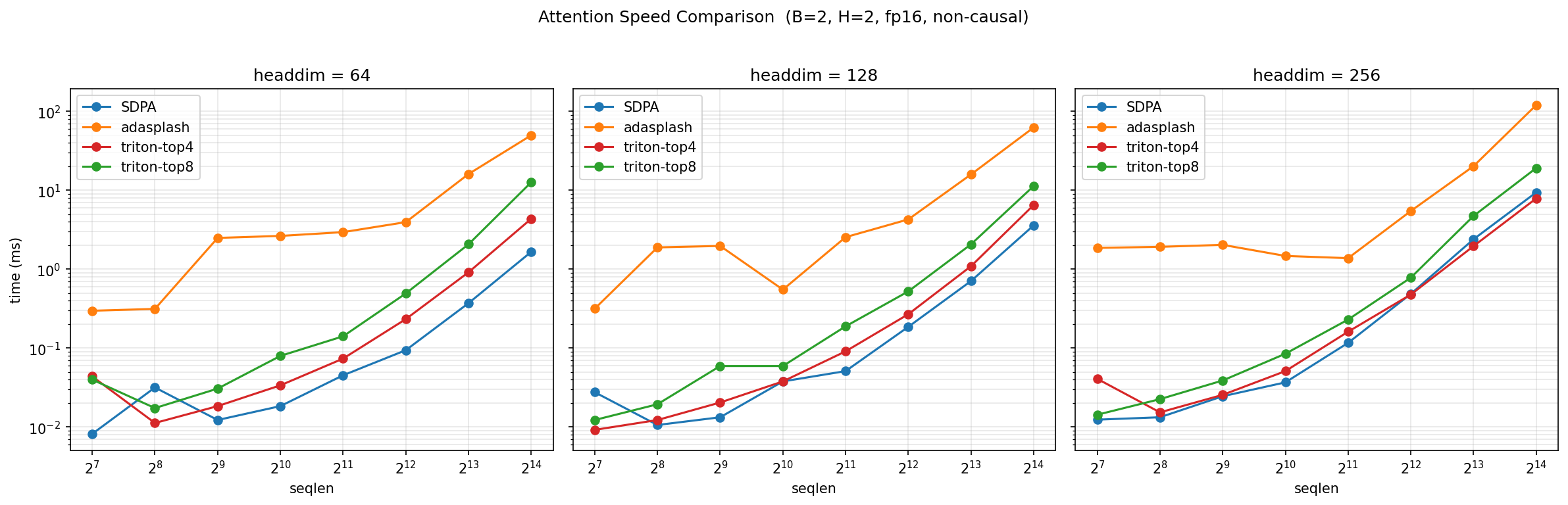
实现:
[Adasplash](https://github.com/deep-spin/adasplash)
[torch SDPA](https://docs.pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html#)
标签:AdaSplash, Apex, CUDA, PyTorch, SDPA, Sparsemax, Transformer, Vectored Exception Handling, 凭据扫描, 机器学习, 模型加速, 注意力机制, 深度学习, 稀疏注意力, 算法优化, 逆向工具, 降本增效, 高性能计算