Ronilmuchandi/Riskpluse
GitHub: Ronilmuchandi/Riskpluse
一个端到端的生产级金融欺诈检测与风控平台,集成了多模型预测引擎、数据漂移监控和自动化告警系统。
Stars: 0 | Forks: 0
# 🛡️ RiskPulse — 智能金融风险与欺诈情报平台
      
RiskPulse 是一个生产级欺诈检测平台,它反映了像 JPMorgan 这样的银行在现实世界中如何运行机器学习——不仅仅是训练模型,还包括部署模型、监控模型,以及了解何时需要对它们进行重新训练。
## 问题背景
每次你刷信用卡时,你的银行都会在几毫秒内将该笔交易通过一个机器学习模型进行处理。它会检查金额、地点、时间和消费模式是否可疑。如果分数过高——你的卡将被冻结,或者你会收到一条短信。
最困难的部分不是构建那个模型。而是如何让它随着时间的推移持续发挥作用。
欺诈者会不断改变策略。在一月份训练的模型可能会在六月份悄悄失效,因为它所学到的欺诈模式不再与现实世界中发生的情况相匹配。大多数欺诈检测项目从未解决这个问题。RiskPulse 做到了。
## 我们构建了什么
三个协同工作的连接系统:
**A 部分 — 欺诈检测引擎**
在 284,807 条真实的信用卡交易数据上训练了三个模型,并进行了统计比较:
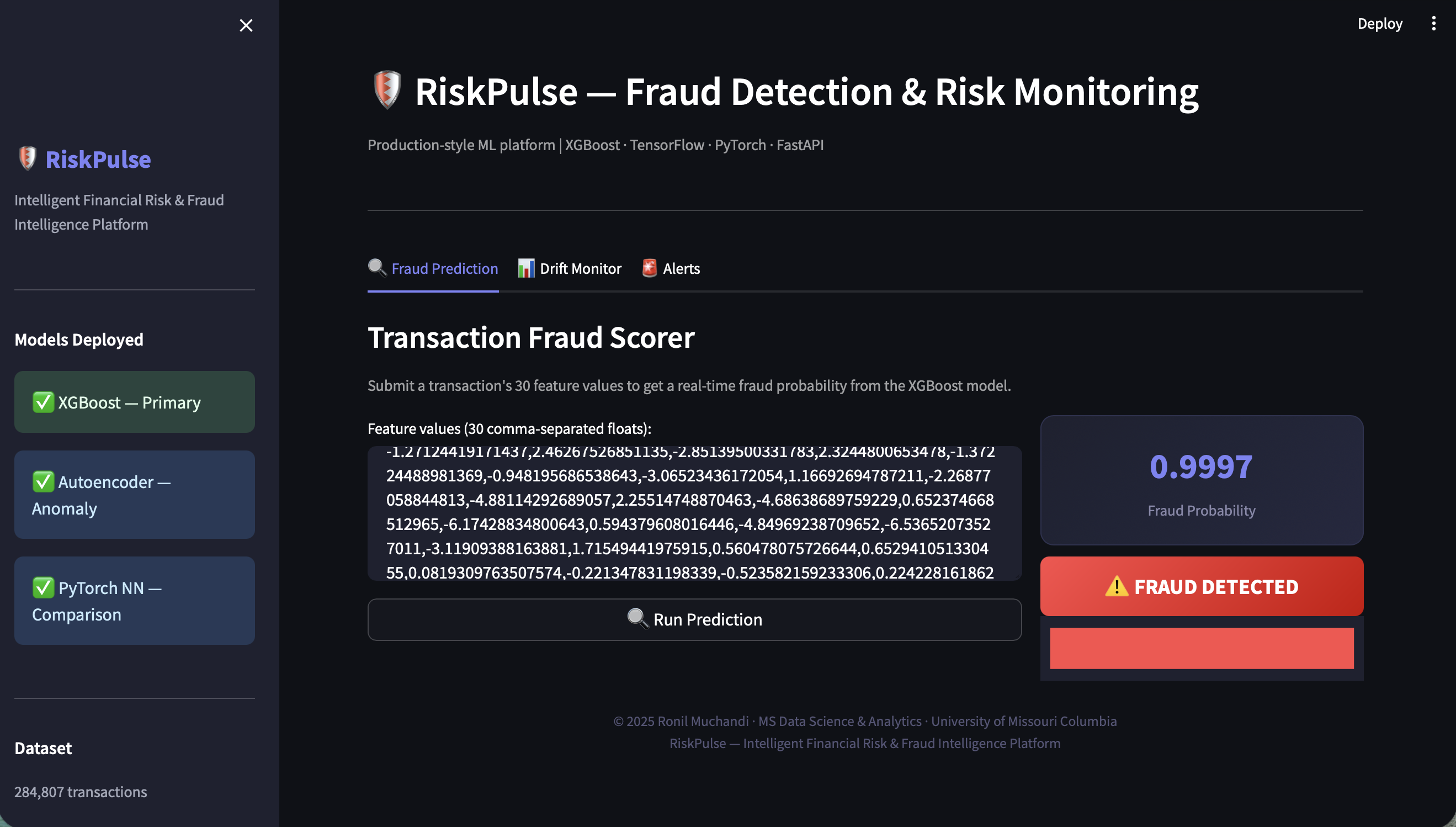
- XGBoost — 主要模型,最快且最准确
- TensorFlow/Keras Autoencoder — 捕捉训练中从未见过的欺诈模式
- PyTorch Neural Network — 对比模型
模型使用 A/B 测试和 KS 假设检验进行了验证——而不仅仅是准确率分数。
**B 部分 — 数据漂移监控**
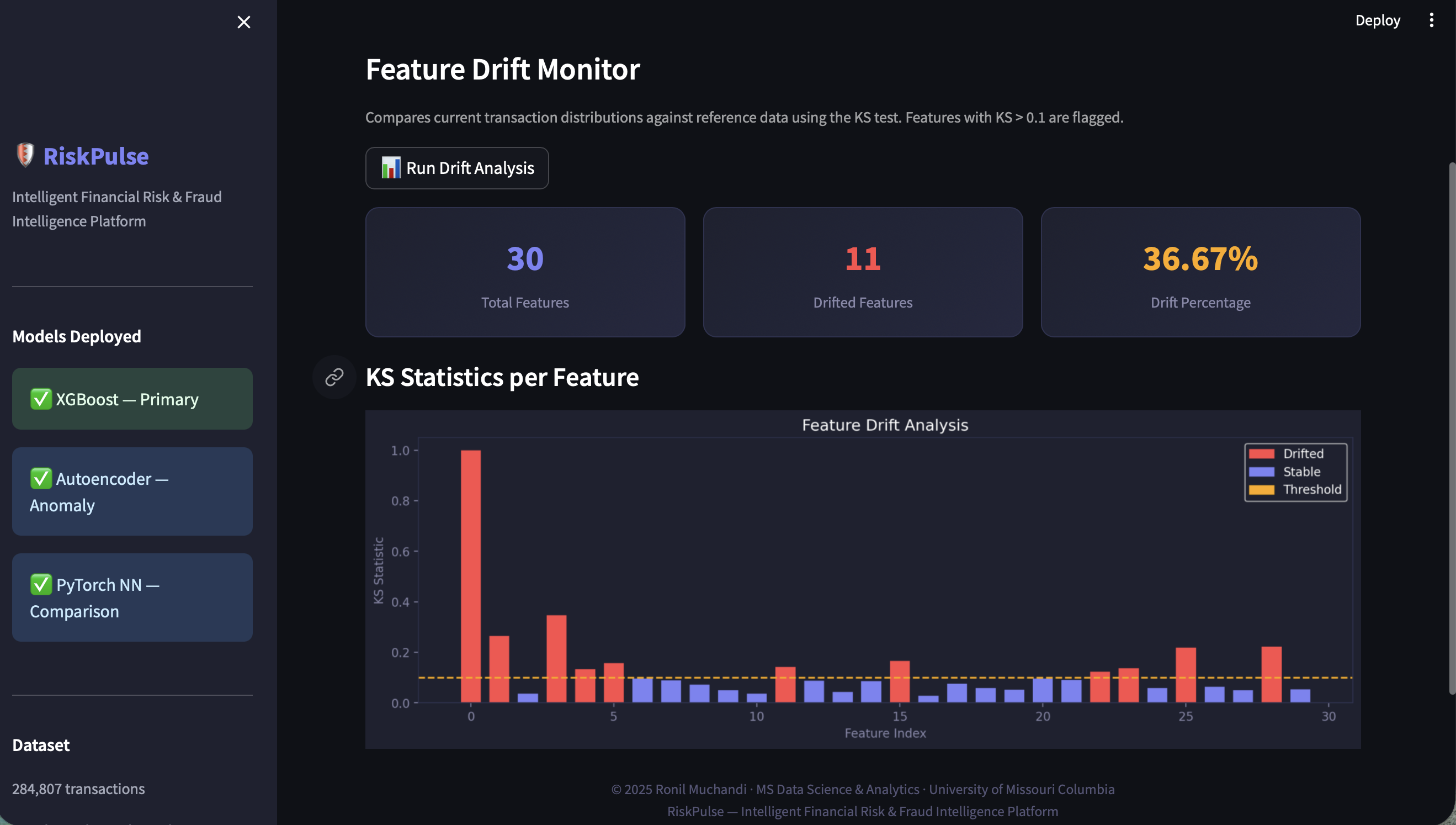
监控模型今天接收的数据是否看起来仍像它训练时的数据。对所有 30 个特征使用 KS 统计检验。当过多特征发生漂移时,会触发自动警报,建议重新训练。
**C 部分 — 部署**
- FastAPI REST API,包含三个端点:`/predict`、`/drift`、`/alerts`
- Streamlit 实时仪表板 — 深色 UI,欺诈评分器,漂移图表,警报面板
- Docker 容器化
- AWS S3 用于数据集存储,AWS EC2 用于云部署
## 现实中如何运作
```
Transaction comes in
│
▼
API receives 30 feature values
│
▼
XGBoost scores it in milliseconds
│
┌────┴────┐
▼ ▼
FRAUD NORMAL
block approve
│
▼
Drift monitor checks in background
│
▼
Alert fires if model health degrades
```
## 关键结果
| 模型 | ROC-AUC | 平均精度 |
|---|---|---|
| XGBoost | **0.9717** | **0.8214** |
| PyTorch NN | 0.9706 | 0.7608 |
| TF/Keras Autoencoder | 0.9595 | 0.5159 |
KS 检验证实所有三个模型在统计学上存在显著差异(p < 0.0001)——模型选择并非随意的。
在数据集中一个确认为真实欺诈的交易上:**欺诈概率为 0.9997**。
## 数据集
Kaggle 信用卡欺诈检测数据集 — 包含 284,807 条来自欧洲持卡人的真实匿名交易,由 ULB 和 Worldline(一家真正的支付公司)提供。特征 V1–V28 是经过 PCA 转换的真实交易属性,为保护隐私进行了匿名化处理。只有 0.17% 的交易是欺诈——这种极端的类别不平衡使用了仅在训练数据上应用的 SMOTE 来处理。
## 仪表板预览
## 技术栈
`Python 3.9` `XGBoost` `TensorFlow/Keras` `PyTorch` `Scikit-learn` `SMOTE` `SciPy` `FastAPI` `Streamlit` `Docker` `AWS S3` `AWS EC2` `Pandas` `NumPy`
## 本地运行
```
git clone https://github.com/Ronilmuchandi/Riskpluse.git
cd Riskpluse
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
```
从 Kaggle 下载数据集并将其放置在 `data/raw/creditcard.csv`,然后:
```
python3 notebooks/02_preprocessing.py
python3 models/xgboost/train_xgboost.py
python3 models/autoencoder/train_autoencoder.py
python3 models/pytorch/train_pytorch.py
python3 monitoring/drift_detector.py
python3 monitoring/alert_system.py
# 终端 1
uvicorn api.main:app --reload
# 终端 2
streamlit run dashboard/app.py
```
打开 `http://localhost:8501`
## 未来工作
- 超过漂移阈值时自动重新训练
- 将预测日志记录到数据库以进行审计跟踪
- API 端点上的 JWT 身份验证
- 通过 Apache Kafka 进行实时流处理
- 用于单个预测的 SHAP 可解释性
## 挑战
**类别不平衡(0.17% 欺诈率)**
朴素的模型将所有内容预测为正常,依然获得了 99.8% 的准确率。通过应用 SMOTE 过采样解决了此问题——但仅在训练数据上进行。如果在拆分之前应用它,将导致数据泄漏并使指标虚高。
**Autoencoder 阈值调优**
Autoencoder 没有自然的决策边界。通过将正常交易的重建误差的第 95 个百分位数设置为欺诈阈值来解决此问题——任何高于该值的都被标记为异常。
**大规模下的 KS 检验敏感性**
在拥有 28 万行数据的情况下,即使数据集之间微小的自然差异也会产生 0.0000 的 p 值,使得每个特征看起来都发生了漂移。直接从 p 值切换到了 KS 统计量——无论 p 值如何,KS > 0.1 的特征都会被标记为已漂移。
**AWS EC2 内存限制**
免费套餐 t3.micro 只有 1GB 内存。TensorFlow 单独通过 Docker 安装就需要超过这个容量的内存,导致构建在过程中被终止。通过在免费套餐的实例上直接运行 API 而不使用 Docker 解决了此问题,将 Docker 保留用于生产级部署。
**Streamlit Cloud 不兼容**
最初计划将仪表板部署在 Streamlit Community Cloud 上。内存和 CPU 限制使其与 TensorFlow + XGBoost 技术栈不兼容。转而采用带有演示录制的本地运行模型——对于机器学习工程项目来说,这是一种更简洁的方法。
## 作者
**Ronil Muchandi**
数据科学与分析硕士 | 密苏里大学哥伦比亚分校 | GPA 3.5
F1 签证 | 符合 CPT 资格 | 2027 年 5 月毕业
[LinkedIn](https://linkedin.com/in/ronil-muchandi-892602187) · [GitHub](https://github.com/Ronilmuchandi) · [LexiQuery](https://github.com/Ronilmuchandi/lexiquery)
标签:A/B测试, AV绕过, AWS, Docker, DPI, FastAPI, FinTech, JPMorgan, KS检验, Kubernetes, MLOps, Python, PyTorch, TensorFlow, XGBoost, 信用卡交易, 信用卡反欺诈, 凭据扫描, 反欺诈模型, 安全防御评估, 实时预测, 异常检测, 数据分布变化, 数据漂移监控, 数据科学, 无后门, 机器学习工程, 模型监控, 模型衰退, 模型部署, 欺诈检测, 深度学习, 生产级系统, 端到端机器学习, 自动化重训练, 自编码器, 请求拦截, 资源验证, 逆向工具, 金融科技, 金融风控, 风控引擎, 风控系统, 风险监控平台, 风险评分