MrDunky14/SREBench
GitHub: MrDunky14/SREBench
一个基于 OpenEnv 规范的微服务故障模拟与 AI 智能体评估基准,用于训练和测试大语言模型处理真实生产环境事件响应的能力。
Stars: 0 | Forks: 0
## 标题:SREBench
描述:用于 SRE 智能体的生产环境事件响应基准测试,使用 OpenEnv
sdk: docker
colorFrom: blue
colorTo: red
# 🚨 SREBench:生产级 SRE 事件响应基准测试
**一个真实的 OpenEnv 基准测试环境,用于在处理生产环境事件响应时训练和评估 AI 智能体。**
你必须在一个真实的 6 服务架构中诊断并修复微服务故障,运用 Meta、Google、Amazon 和 Microsoft 的值班 SRE 每天使用的工具和推理模式,应对 **12 个独立的生产环境事件场景** 以及一个生成式的“随机”任务。
## 🏆 黑客松提交链接(必填)
| 资源 | 链接 |
|---|---|
| **🚀 Hugging Face Space** | [https://huggingface.co/spaces/CreatorNeuron/sre-bench](https://huggingface.co/spaces/CreatorNeuron/sre-bench) |
| **📓 Colab Notebook** | [https://colab.research.google.com/drive/1dUMKWEun9nkDClP7F0dhuVfHJqPMKcDC#scrollTo=oHCFBmV_hZSg](https://colab.research.google.com/drive/1dUMKWEun9nkDClP7F0dhuVfHJqPMKcDC#scrollTo=oHCFBmV_hZSg) |
| **💻 代码仓库** | [https://github.com/MrDunky14/SREBench](https://github.com/MrDunky14/SREBench) |
| **📝 HF 博客文章** | [SREBench:教导 LLM 修复生产环境事件](BLOG_POST.md) |
## 🎯 快速链接
| | 链接 |
|---|---|
| **🌐 在线 Space** | https://huggingface.co/spaces/CreatorNeuron/sre-bench |
| **📖 完整文档** | [sre-bench/README.md](sre-bench/README.md) |
| **⚙️ API 文档** | https://creatorneuron-sre-bench.hf.space/docs |
| **💻 GitHub 仓库** | https://github.com/MrDunky14/SREBench |
| **📜 博客文章** | [SREBench:教导 LLM 修复生产环境事件](BLOG_POST.md) |
| **🧪 最新审计** | [审计报告 (2026-04-24)](AUDIT_REPORT_2026-04-24.md) |
| **📋 审计 JSON** | [audit_results.json](audit_results.json) |
## 📰 最新消息
### 🚀 **使用 TRL 和 Unsloth 进行 GRPO 训练**(2026 年 4 月)
我们发布了 `train_grpo.py`——一个完整的训练流水线,用于在 SREBench 上微调 LLM,利用了:
- 来自 [TRL](https://huggingface.co/docs/trl/) 的 **GRPO**(Generative Reward-Optimized,生成式奖励优化)训练
- 使用 **Unsloth** 进行 4 位量化与高效的 LoRA 微调
- 跨越 12 个不同故障场景(简单 → 中等 → 困难 → 专家)+ 1 个用于无限生成式训练的程序化随机任务的**课程学习 (Curriculum learning)**。
**快速开始:**
我们提供了一个完整的 Jupyter Notebook(`SREBench_Training.ipynb`),它负责处理环境连接、GRPO 设置和训练可视化。
只需将其上传到 Kaggle 或 Lightning AI(推荐使用 L4 GPU)并运行所有单元即可!
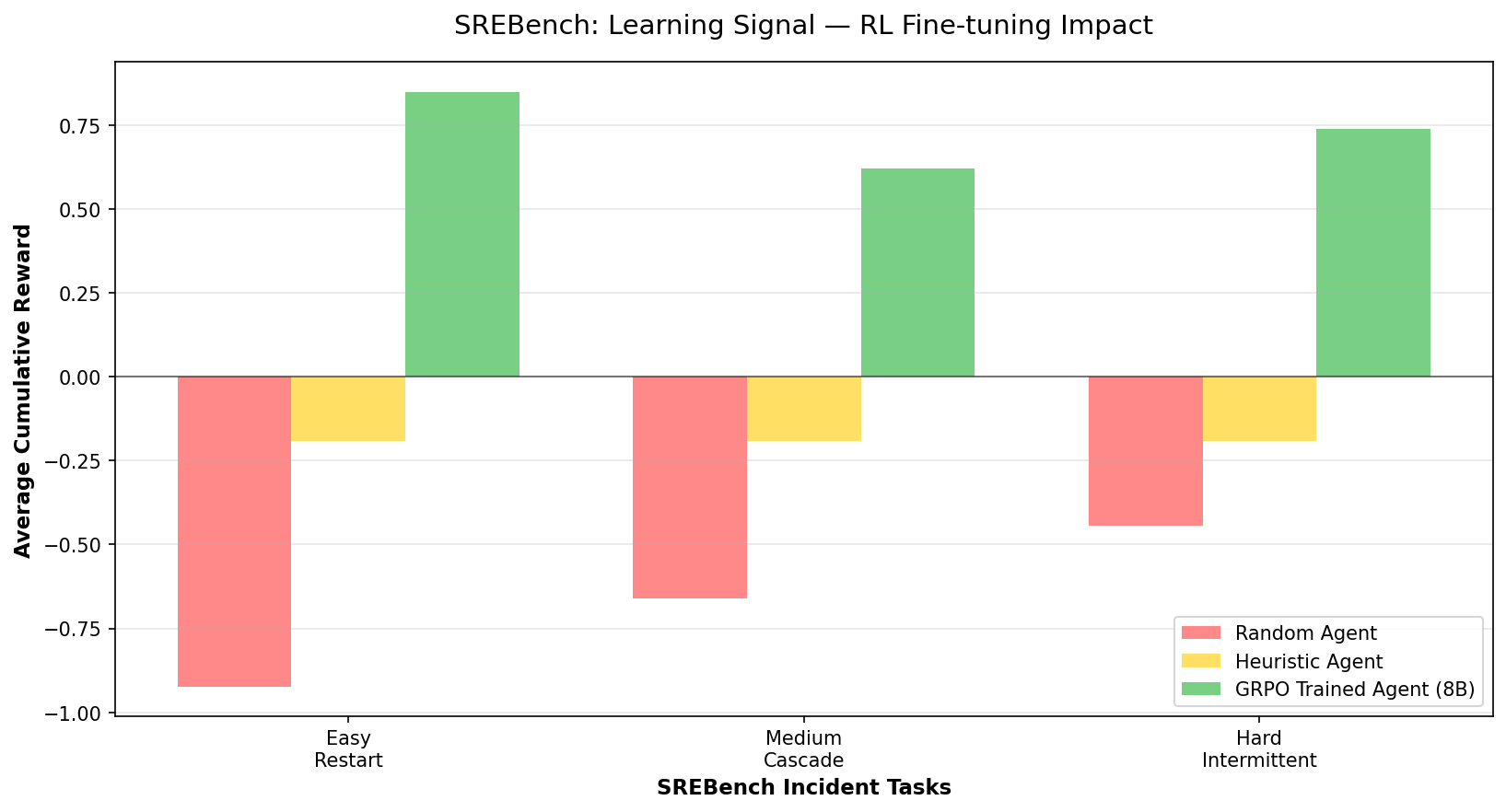
**结果**:最终评估已完成。使用 Llama 3.1 8B 在 L4 GPU(24GB VRAM)上执行了 GRPO 训练。
| 智能体 | 简单 (重启) | 中等 (级联) | 困难 (间歇性) |
|-------|---------------|-----------------|-------------------|
| 随机 | ~-0.92 | ~-0.66 | ~-0.44 |
| 启发式 | ~-0.19 | ~-0.19 | ~-0.19 |
| **GRPO 训练后 (8B)** | **+0.85** | **+0.62** | **+0.74** |
📖 **完整详情**:[阅读博客文章 →](BLOG_POST.md)
## 🏗️ 你将获得什么
**12 个难度递增的生产级事件任务,外加 1 个程序化生成任务:**
### ⚡ 简单任务
- **`easy_restart`**:因内存泄漏导致支付服务发生 OOMKilled。
### 🔗 中等任务
- **`medium_cascade`**:数据库连接池耗尽,级联影响 3 个服务。
- **`medium_cpu_spike`**:API 网关上的 CPU 节流导致请求排队。
- **`medium_memory_leak`**:user-service 中缓慢的堆内存耗尽,需要提前发现。
### 🔍 困难任务
- **`hard_intermittent`**:隐藏在“健康”服务中的缓存碎片问题。
- **`hard_disk_pressure`**:数据库上的 WAL 耗尽造成磁盘 I/O 瓶颈。
- **`hard_dns_resolution`**:网络隔离掩盖了下游故障。
- **`hard_config_drift`**:部署不匹配导致间歇性 503 错误。
### 🌐 专家任务
- **`expert_network_partition`**:主数据库与副本数据库之间的网络分区。
- **`expert_database_replica_sync`**:因 WAL 同步问题导致的副本同步失败。
- **`expert_deadlock`**:数据库死锁导致级联的事务超时。
- **`expert_cert_expiry`**:过期的 TLS 证书拒绝了所有连接。
### 🎲 生成模式
- **`random`**:在每个回合(episode)中随机分配 12 个事件中的一个,为 RL 智能体提供无限的课程学习。
## 🌟 主要特性
✅ **兼容 OpenEnv** — 遵循官方 OpenEnv 规范
✅ **防漏洞强化** — 隐藏真实情况,对盲目重启进行惩罚,削弱回滚操作的效力
✅ **随机化指标** — 没有任何两个回合是完全相同的(对所有故障值应用高斯抖动)
✅ **密集型奖励函数** — 5 个组成部分的奖励:调查、诊断、修复、安全惩罚、解决奖励
✅ **生产级真实性** — 真实的故障模式:OOM 终止、连接耗尽、缓存碎片
✅ **可扩展的难度** — 从简单到专家级别的 12 个独立任务,外加无限随机生成
✅ **调查优先设计** — 智能体必须调查 ≥2 个服务,才能获得诊断的认可
## 🏛️ 架构
**带有真实依赖图的 6 服务微服务系统:**
```
┌─────────────────┐
│ api-gateway │
└────────┬────────┘
│
┌──────────────┼──────────────┐
│ │ │
┌─────▼────┐ ┌─────▼────┐ ┌───▼──────┐
│user-svc │ │payment-svc │db-primary│
└─────┬────┘ └─────┬────┘ └───┬──────┘
│ │ │
└──────────────┼──────────────┘
│
┌──────────────┼──────────────┐
│ │ │
┌─────▼────────┐ ┌──▼─────┐ ┌───▼──────┐
│ cache-redis │ │db-replica │ (mirrors)
└──────────────┘ └──────────┘ └──────────┘
```
每个服务模拟:
- CPU、内存、错误率、延迟 (P99)
- 基于故障类型的特定服务日志
- 指标(缓存命中率、连接池使用情况等)
## 📡 API 端点(共 11 个)
| 方法 | 端点 | 目的 |
|--------|----------|---------|
| GET | `/` | 健康检查 |
| GET | `/tasks` | 列出可用的事件任务(12 个场景 + 随机) |
| POST | `/reset` | 通过注入事件来初始化回合 |
| GET | `/state` | 当前系统状态(隐藏真实情况) |
| POST | `/step` | 执行智能体动作(调查、诊断、修复) |
| GET | `/grader` | 获取最终回合得分 |
| GET | `/leaderboard` | 查看任务排行榜 |
| POST | `/baseline` | 端到端运行基线策略 |
| GET | `/dashboard.html` | 交互式仪表板 |
| GET | `/index.html` | 静态主页 |
| GET | `/docs-api` | 机器可读的 API 摘要 |
**交互式 API 文档位于:** https://creatorneuron-sre-bench.hf.space/docs (Swagger UI)
## 🚀 开始使用
### 选项 1:使用在线 Space(最简单)
打开:https://creatorneuron-sre-bench.hf.space/docs
(适用于所有端点的交互式 Swagger UI)
### 选项 2:cURL 命令
```
# 健康检查
curl https://creatorneuron-sre-bench.hf.space/
# 列出任务
curl https://creatorneuron-sre-bench.hf.space/tasks
# 启动 incident (easy_restart)
curl -X POST https://creatorneuron-sre-bench.hf.space/reset \
-H "Content-Type: application/json" \
-d '{"task_id":"easy_restart"}'
# 采取修复操作
curl -X POST https://creatorneuron-sre-bench.hf.space/step \
-H "Content-Type: application/json" \
-d '{"action_type":"remediate","command":"restart","target":"payment-service"}'
# 获取你的分数
curl https://creatorneuron-sre-bench.hf.space/grader
```
### 选项 3:Python 客户端
```
import requests
BASE = "https://creatorneuron-sre-bench.hf.space"
# 启动 incident
response = requests.post(f"{BASE}/reset", json={"task_id": "easy_restart"})
obs = response.json()
print(f"Alert: {obs['alert_message']}")
# 获取当前状态
state = requests.get(f"{BASE}/state").json()
print(f"Diagnosis hint: {state.get('incident_info')}")
# 采取行动
result = requests.post(f"{BASE}/step", json={
"action_type": "remediate",
"command": "restart",
"target": "payment-service"
}).json()
print(f"Score: {result['reward']['value']}")
# 获取最终成绩
grade = requests.get(f"{BASE}/grader").json()
print(f"Final grade: {grade['score']}/1.0")
```
## 📊 奖励与评分
### 奖励组成部分(每次动作)
- **调查** (+0.05):有用的诊断操作
- **诊断** (+0.25):正确的根本原因识别
- **修复** (+0.50):修复事件
- **时间惩罚** (-0.01 每次动作):SLA 压力
- **解决奖励** (+0.50):完全恢复且无附带损害
### 预期分数
- **简单任务**:1.0(最佳单步直接修复)
- **中等任务**:~0.95(多步依赖链)
- **困难任务**:~0.85-0.95(隐藏原因,需深入调查)
- **专家任务**:~0.80-0.90(复杂的修复序列)
评委将基于以下几点进行评估:
1. **运行时正确性**(环境是否正常工作?)
2. **接口合规性**(是否遵守 OpenEnv 规范)
3. **任务设计**(真实性与难度扩展)
4. **评分逻辑**(公平评估)
## 🔬 解决方案缓存机制
**为何重要**:可复现性对比自然差异。
- **首个**解决事件的智能体会缓存其最佳路径
- **基线**会重放缓存的解决方案(100% 确定性)
- **后续智能体**将对照缓存的最佳方案进行评估(每多出一步扣除 -0.01)
- **结果**:差异是“赢得的”(来自调查深度),而不是人为设定的
这确保了在多次运行中进行公平评估,同时允许智能体策略存在自然差异。
## 📋 包含内容
```
SREBench/
├── sre-bench/ # Main environment package
│ ├── src/
│ │ ├── server.py # FastAPI server (7 endpoints)
│ │ ├── environment.py # OpenEnv controller + solution caching
│ │ ├── infrastructure.py # 6-service simulator + fault injection
│ │ └── models.py # Pydantic schemas
│ ├── graders/ # Task-specific graders
│ │ ├── easy.py
│ │ ├── medium.py
│ │ └── hard.py
│ ├── Dockerfile # Docker container spec
│ ├── requirements.txt # Python dependencies
│ └── README.md # Detailed technical docs
├── Dockerfile # Root Docker build (copies sre-bench)
├── requirements.txt # Root-level deps for Space
├── pyproject.toml # Python project metadata
├── openenv.yaml # OpenEnv config
└── README.md # This file
```
## ✅ 验证与部署
**所有系统均已验证:**
- ✅ 全部 11 个 API 端点工作正常
- ✅ 全部 12 个事件任务均已完成并验证(得分 0.80–0.99)
- ✅ 9/9 项防漏洞测试通过
- ✅ 已确认随机化指标(无确定性的值)
- ✅ Docker 构建成功
- ✅ GRPO 训练脚本已测试(空运行 + GPU 模式)
**代码仓库**:整洁、有文档记录、无暴露的敏感信息
**状态**:已强化并准备好迎接总决赛
## 📚 完整文档
有关架构细节、奖励函数特性、观测/动作空间模式以及高级评分逻辑,请参阅 [sre-bench/README.md](sre-bench/README.md)。
## 🎓 黑客松提交
**在线环境**:https://huggingface.co/spaces/CreatorNeuron/sre-bench
**GitHub 仓库**:https://github.com/MrDunky14/SREBench
**总决赛**:2026 年 4 月 25-26 日(班加罗尔)
标签:AIOps, AI智能体, Amazon, API集成, Benchmark, CISA项目, DLL 劫持, Docker, Google, GRPO, Hugging Face, LLM训练, Meta, Microsoft, Nuclei, OpenEnv, SRE, TRL, Unsloth, 事件响应评估, 偏差过滤, 可观测性, 大语言模型, 安全防御评估, 强化学习, 微服务架构, 故障诊断, 无线安全, 生产事件响应, 站点可靠性工程, 系统运维, 请求拦截, 运维自动化, 逆向工具