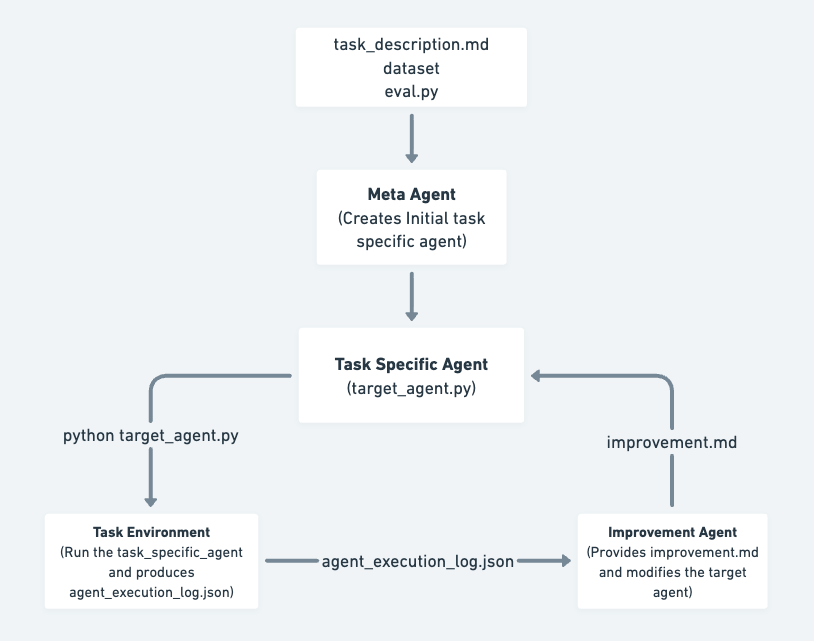
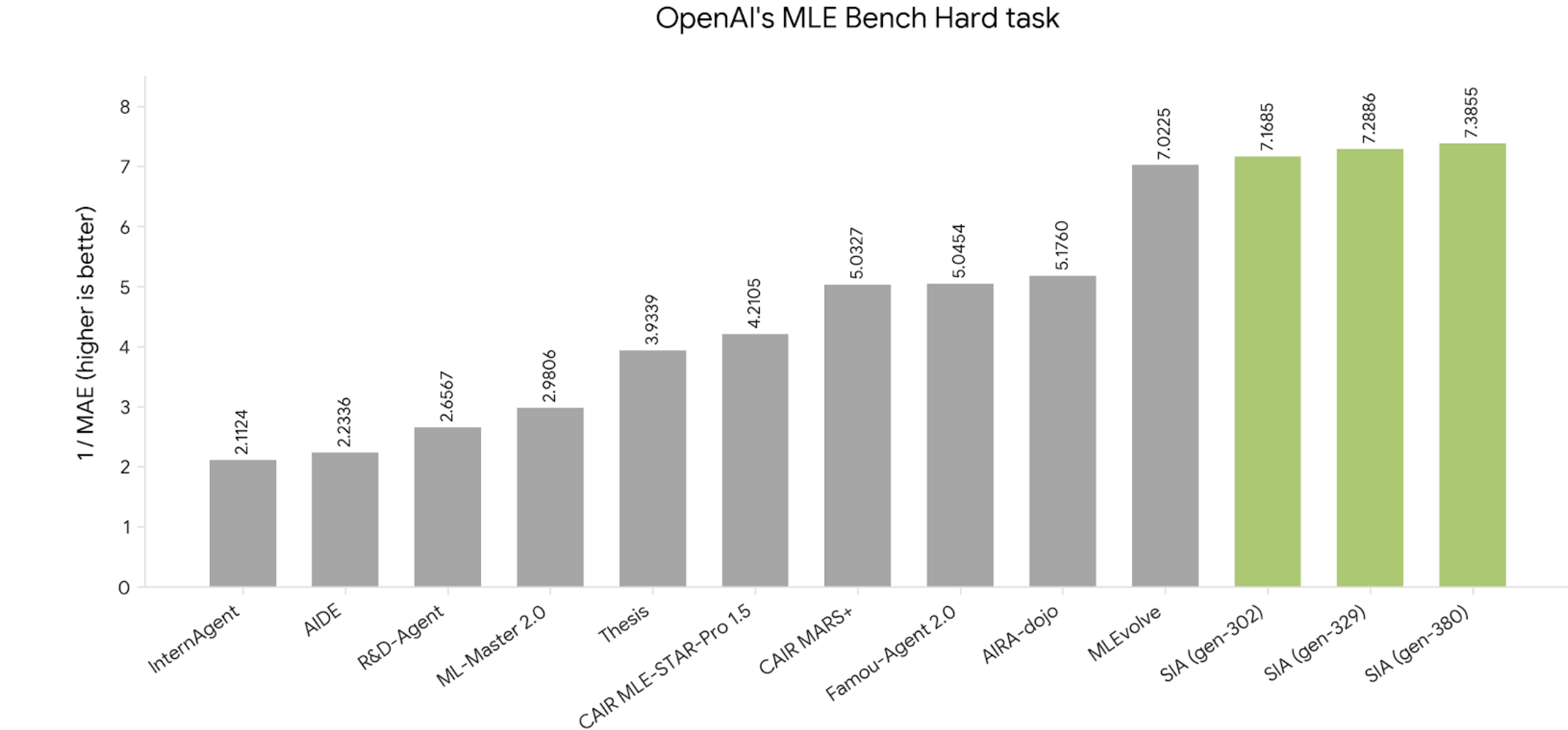
OpenAI MLE-Bench Hard: a gauntlet of real Kaggle ML competitions where agents must write, run, and iterate full ML pipelines. SIA ranks #1 across all generations tested.
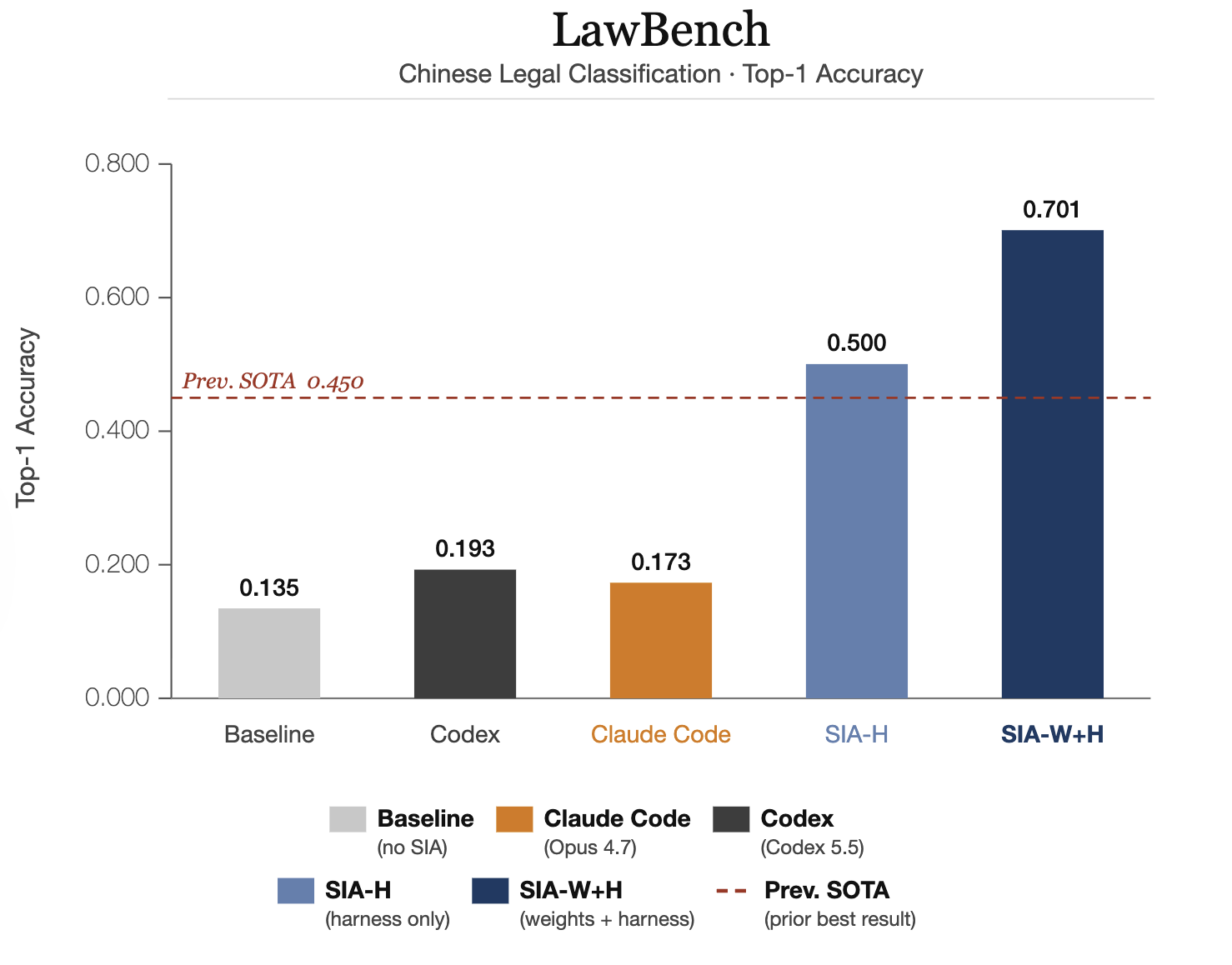
LawBench: predict the criminal charge from Chinese court case descriptions across 191 charge categories. SIA-W+H reaches 70.1% Top-1 accuracy, beating the prior SOTA of 45%.
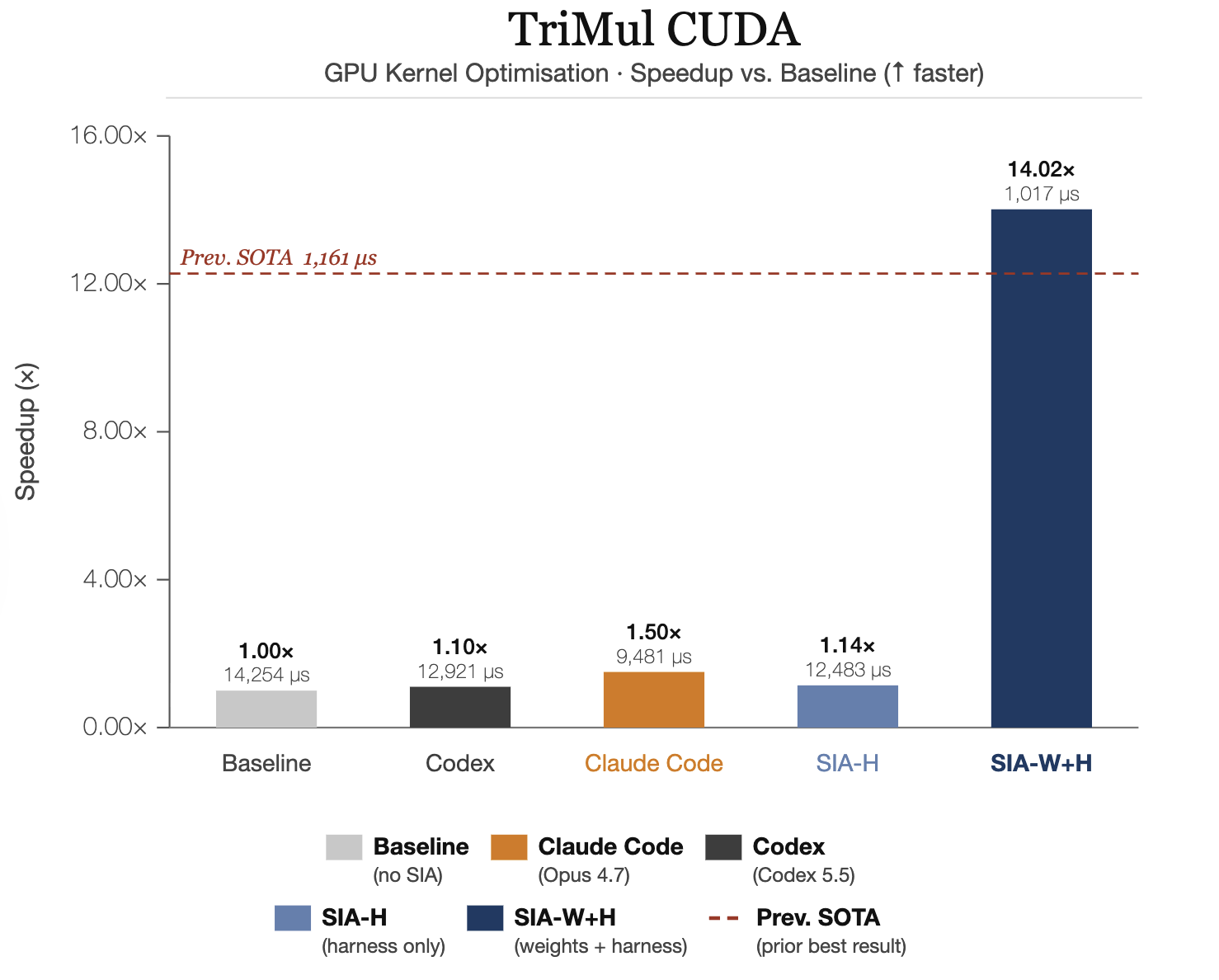
AlphaFold-3 TriMul Triton Kernel: implement and optimize the Triangle Multiplicative Update as a Triton kernel, preserving correctness while hitting H100 latency targets. SIA-W+H achieves 14x speedup over baseline.
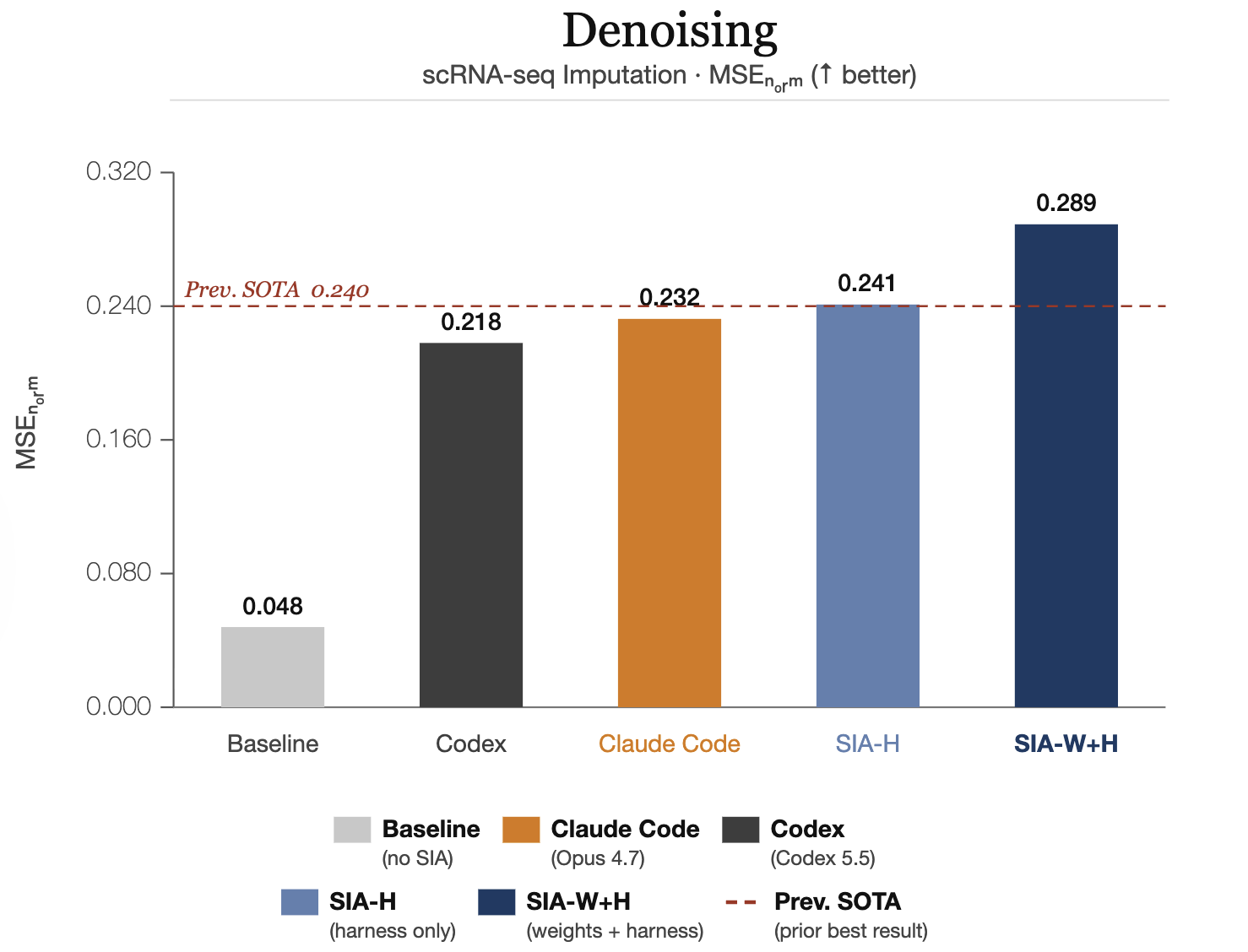
scRNA-seq Denoising: impute missing gene expression values in single-cell RNA sequencing data. SIA-W+H scores 0.289 MSEnorm, surpassing the prior SOTA of 0.220.
## 在本地使用内置任务运行 SIA
SIA 自带四个内置任务:`gpqa`、`lawbench`、`longcot-chess`、`spaceship-titanic`。
### 安装
选择与你要运行的 LLM 相匹配的 agent 实现。
**Claude agent 实现**(Claude Agent SDK,仅限 Claude 模型):
```
python3 -m venv .venv && source .venv/bin/activate
pip install 'sia-agent[claude]'
export ANTHROPIC_API_KEY="..."
```
**OpenHands agent 实现**(多 provider — Gemini、OpenAI、Anthropic 等):
```
python3 -m venv .venv && source .venv/bin/activate
pip install 'sia-agent[openhands]'
# 导出你将要使用的 provider(s) 的 key(s):
export ANTHROPIC_API_KEY="..." # for anthropic/* models
export GEMINI_API_KEY="..." # for gemini/* models (or GOOGLE_API_KEY)
export OPENAI_API_KEY="..." # for openai/* models
```
完整的 provider/model 参考:[docs/configuration.md](docs/configuration.md#api-keys)。
### 运行
CLI 包含两个子命令:**`sia run`**(自我改进循环)和
**`sia web`**(运行可视化工具,见[运行可视化](#visualize-runs))。
```
sia run --task gpqa --max_gen 5 --run_id 1
```
将 `--task` 替换为四个内置任务中的任意一个。(不带
`run` 子命令的 `sia --task ...` 依然有效,会被视为 `sia run ...`)。
产物文件将存放在 `runs/run_{run_id}/gen_{n}/` 目录下:
- `target_agent.py` — 该世代的 agent
- `agent_execution.json` — 执行日志
- `improvement.md` — 差异说明(第 2 代及以后)
在运行期间,一个**实时仪表板**会自动启动于
`http://127.0.0.1:8000`(需要安装 `web` 扩展依赖;使用 `--no-web` 可禁用)。
### 常用参数 (`sia run`)
| 参数 | 默认值 | 描述 |
|---|---|---|
| `--task` | — | 内置任务名称(与 `--task_dir` 互斥) |
| `--task_dir` | — | 外部任务目录的路径 |
| `--max_gen` | 3 | 自我改进的世代数 |
| `--run_id` | 1 | 唯一的运行标识符 |
| `--meta-agent-profile` | `default-meta` | meta/feedback agent 的配置文件(名称或 `.json` 的路径) |
| `--target-agent-profile` | `default-target` | target agent 的配置文件(名称或 `.json` 的路径) |
| `--no-web` | off | 在运行期间不自动启动实时仪表板 |
| `--web-port` | 8000 | 实时仪表板的端口(使用 `--web-host` 更改绑定主机) |
每个 agent 的模型、agent 实现和 provider 均来自一份**配置文件**(见下文)。例如,
若要将 Nebius 上的 Kimi-K2.6 作为目标模型进行评估:
```
export NEBIUS_API_KEY="..." # + ANTHROPIC_API_KEY for the default meta agent
sia run --task gpqa --target-agent-profile kimi-nebius-target --max_gen 5 --run_id 2
```
完整的 agent 实现、模型和 API key 参考:[docs/configuration.md](docs/configuration.md)。遇到问题?请查阅 [docs/troubleshooting.md](docs/troubleshooting.md)。
### 运行可视化
一个内置的 Web 仪表板会渲染 `runs/` 目录下的所有内容:包括每个世代的
target agent 代码(带语法高亮)、meta/feedback 提示词、改进
计划、评估得分(包含跨世代准确率图表以及
按领域划分的明细)、执行轨迹和日志。
```
sia web # serve ./runs at http://127.0.0.1:8000
sia web --runs-dir ./runs --port 8080
```
它也会随 `sia run` 自动启动(使用 `--no-web` 可禁用),因此
你可以实时观察每个世代的产生过程。
| 参数 | 默认值 | 描述 |
|---|---|---|
| `--runs-dir` | `./runs` | 要可视化的运行目录 |
| `--host` | `127.0.0.1` | 绑定主机 |
| `--port` | 8000 | 绑定端口 |
| `--no-browser` | off | 不自动打开浏览器窗口 |
### 编写自定义配置文件
**provider** 是一个 endpoint + 凭证;而**配置文件** (profile) 用于配置一个 agent 角色。一个 meta-agent
配置文件捆绑了 `(agent_impl, model, provider)`;一个 target-agent 配置文件捆绑了 `(model, provider,
agent_reference)`。它们都是 JSON 文件——内置的默认文件位于 `sia/defaults/{providers,profiles}/`,
你可以将自己的文件放在 `./providers/` 和 `./profiles/` 下(或设置 `$SIA_PROVIDERS_DIR` /
`$SIA_PROFILES_DIR`)。无需修改代码。
```
mkdir -p providers profiles
```
```
// providers/my-endpoint.json — an OpenAI-compatible provider
{
"provider_id": "my-endpoint",
"name": "My Endpoint",
"client_kind": "openai", // anthropic | openai | google
"base_url": "https://api.example.com/v1",
"api_key_env": "MY_ENDPOINT_API_KEY"
}
```
```
// profiles/my-target.json — the target agent's model + provider + reference
{
"profile_id": "my-target",
"name": "My model on My Endpoint",
"model": "vendor/my-model",
"provider_id": "my-endpoint", // references the provider above
"agent_reference": "default" // "default" = the task package's reference;
// or { "source": "./my_agent_dir/", "entrypoint": "main.py" }
}
```
```
export MY_ENDPOINT_API_KEY="..."
sia run --task gpqa --target-agent-profile my-target # by name (resolves ./profiles/my-target.json)
sia run --task gpqa --target-agent-profile ./profiles/my-target.json # or by explicit path
```
`agent_reference` 是 meta-agent 启动及 feedback agent 进行改进的初始种子:
`"default"` 使用任务包自带的参考,或者使用
`{ "source": "./my_agent.py" }`(单文件)或 `{ "source": "./dir/", "entrypoint": "main.py" }`
(agent 使用其工具读取的多文件目录)提供你自己的参考。目录
参考中的 `requirements.txt` 会在每个世代中被安装。
要在其他地方运行 **meta/feedback** agent,请给 meta 配置文件提供一个不同的 `agent_impl`
(`openhands` 或 `pydantic-ai`),并使用 `--meta-agent-profile` 传入。`claude` agent 实现仅限
Anthropic 使用。有关完整的 schema 和更多示例,请参阅 [docs/configuration.md](docs/configuration.md)。
## 引入自定义任务
准备一个具有以下布局的任务目录,并使用 `--task_dir` 指向它:
```
my-task/
├── data/
│ ├── public/
│ │ ├── task.md # Task description — SIA reads this
│ │ └── ... # Inputs the agent is allowed to see
│ └── private/ # Held-out eval data; never exposed to the agent
└── reference/
├── reference_target_agent.py # Template; copy from sia/tasks/_shared/
└── SAMPLE_TASK_DESCRIPTIONS.md # Optional: example tasks for the meta-agent
```
```
sia run --task_dir ./my-task --max_gen 5 --run_id 1
```
**或者引入一个 MLE-Bench 比赛。** SIA 可以直接从任何 [MLE-Bench](https://github.com/openai/mle-bench) 比赛中生成一个任务目录——它会通过 Kaggle API 拉取数据集,设置公开/私下的划分,并放入参考 agent 模板:
```
python -m sia.prepare_mlebench_dataset -c "spaceship-titanic"
sia run --task_dir ./tasks/spaceship-titanic --max_gen 5 --run_id 1
```
这两种路径的完整分步指南:[docs/walkthrough.md](docs/walkthrough.md)。
## 评估
在每个世代之后,orchestrator 会自动对 target agent 进行评分,并
将结果输入到下一个世代的 feedback 提示词中——这就是自我改进
循环所依据的优化信号。
1. target agent 将其输出写入到世代目录中(例如 `gen_1/submission.csv`)。
2. orchestrator 运行任务的评估器:`python evaluate.py --gen-dir gen_1/`。
3. `evaluate.py` 将输出与 `data/private/` 中保留的真实结果进行比对评分,
并写入 `gen_1/results.json`(或 `evaluation_results.json`)。
4. 这些指标会被注入到 feedback 提示词中,并显示在 `context.md`
和 [Web 仪表板](#visualize-runs)中(跨世代准确率图表、按领域划分的明细)。
四个内置任务已经附带了评估器。对于**自定义任务**,请放入一个
包含 `evaluate()` 函数的 `evaluate.py` 到 `data/public/` 中——由它决定
提交格式,与 `data/private/` 进行比对,并返回一个指标字典。
在正式运行之前,请单独测试它:
```
python my-task/data/public/evaluate.py --gen-dir runs/run_1/gen_1 # should write results.json
```
完整的契约、返回格式规则和完整示例:[EVALUATION_GUIDE.md](EVALUATION_GUIDE.md)。
## 延伸阅读
- [docs/architecture.md](docs/architecture.md) — 目录布局、世代流程、提示词自定义
- [docs/walkthrough.md](docs/walkthrough.md) — 详细的自定义任务演练
- [docs/configuration.md](docs/configuration.md) — agent 实现、模型、API key、CLI 参考
- [EVALUATION_GUIDE.md](EVALUATION_GUIDE.md) — 为自定义任务编写 `evaluate.py`
- [docs/troubleshooting.md](docs/troubleshooting.md) — 常见错误与修复
## 引用
如果您在研究中使用了 SIA,请引用:
```
@article{hebbar2026sia,
title = {SIA: Self Improving AI with Harness \& Weight Updates},
author = {Hebbar, Prannay and Manawat, Yogendra and Verboomen, Samuel and Ivanova, Alesia and Palanimalai, Selvam and Bhatia, Kunal and Baskaran, Vignesh},
journal = {arXiv preprint arXiv:2605.27276},
year = {2026},
url = {https://arxiv.org/abs/2605.27276}
}
```