一个用 Rust 编写的代码知识图谱引擎,将整个代码库的结构和关系统一索引并通过 MCP 协议提供给 AI 编程助手,大幅降低 agent 回答结构化代码问题时的上下文消耗。
## 🚀 为什么它对你的 LLM 大有裨益
**Code Explorer 将 AI agent 回答结构化问题所消耗的 context 减少了约 40 倍——并且使答案瞬间可得且可复用。**
以 [ollama](https://github.com/ollama/ollama) 上的测试为例——问题是*“如果我修改 `GenerateHandler`,什么会受到影响?”*:
| | 🐌 没有 Code Explorer | ⚡ 有 Code Explorer |
|---|--:|--:|
| **agent 消耗的 Context** | ~730,000 tokens(需读取 174 个文件) | **~18,000 tokens**(一次查询) |
| **延迟** | 逐跳进行数秒的文件读取 | **~25 ms** |
| **整个代码仓库** | ~2.5M tokens——超出*所有*模型的 context window | 一个 **22,982 节点的图**,一条命令即可查询 |
这就是一个*每次对话都要重新阅读你的代码库*的 agent 与一个*已经对其了如指掌*的 agent 之间的区别。在任何代码仓库中复现这些确切的数据:
```
code-explorer demo /path/to/ollama # or just: code-explorer demo (in any repo)
```
Tokens ≈ 字符数/4。“没有”一栏的数据是受影响符号所在文件的总和——即 agent 为了追踪同样的影响所必须阅读的内容(这是一个保守的下限;对于传导依赖链,没有任何廉价的非图谱替代方案)。
## 什么是 Code Explorer?
AI 编程助手**一次只能按需读取一个文件**。在实际项目(800+ 个文件)中,它们必须阅读数十个文件才能跟踪一条调用链,而且每次对话都要从头开始;它们用原始源代码填满了自己的 context window,以至于没有空间去进行思考。
Code Explorer 解决了这个问题。它**将你的整个代码库预索引**为一张关系图——包含 50 多种节点类型、带类型的边,并持久化到磁盘——然后通过 **29 个 MCP 工具**将其暴露出来。你的 agent 提出问题;Code Explorer 只返回相关的关系。这就相当于让 agent 拥有了一个已经知道代码结构的“大脑”,而不是每次都从原始文本开始重新构建。
- **使用 Rust 编写** —— 64 MB 的静态二进制文件,无需 runtime;几秒钟内即可索引数千个文件(对于极其庞大的代码仓库也只需几分钟)。
- **通过 tree-sitter 支持 14 种语言** —— JavaScript、TypeScript、Python、Java、C、C++、C#、Go、Rust、Ruby、PHP、Kotlin、Swift、Razor。
- **MCP 原生** —— 可直接插入 Claude Code、Codex、Cursor、VS Code 或任何 MCP 客户端。
- **100% 本地与离线** —— 你的代码永远不会离开你的机器。索引或查询均不需要 API key。
## 为什么它对 AI agent 至关重要
| | 仅使用 AI agent | AI agent **+ Code Explorer** |
|---|---|---|
| **关系** | 必须阅读每个文件才能发现谁调用了谁 | 预计算的图谱:即时获取调用者、被调用者、层级结构 |
| **规模** | context 仅能容纳 ~50 个文件 | 索引数千个文件,一条命令即可查询 |
| **持久化** | 每次对话都从头开始 | 图谱持久化在磁盘上,随时可用 |
| **Context 预算** | 读取 50 个文件 = context 占满,没有空间进行推理 | 仅返回相关的边——保持 context 充裕 |
| **影响分析** | 如果不阅读整个项目几乎是不可能的 | `impact PaymentService` → 0.3 秒内得出完整的影响范围 |
| **重构** | “查找每个调用者” = 只能 grep 碰运气 | 类型化的调用图能解析出真实的调用,而不仅仅是文本匹配 |
| **离线** | 需要 API | 100% 本地运行 |
**简而言之:** AI 助手*阅读*代码。Code Explorer *理解*代码。结合使用时,agent 能瞬间回答结构化问题,而不是消耗其 context window 去重建它们。
## 基准测试:有无 Code Explorer 的对比
真实的测试数据,可在公开代码仓库上复现。测试机器:24 核工作站,Code Explorer release binary,检出的 [ollama](https://github.com/ollama/ollama)(共索引 863 个文件)。
### 1. 整个代码库无法装入 context window——但图谱可以
| | 没有 Code Explorer | 有 Code Explorer |
|---|---|---|
| ollama 的源码 | **~2.5 M tokens**——超出*所有*模型的 context window | 一次 `analyze` → **~3.4 秒内生成 ~23,000 节点的图**,持久化在磁盘上(33 MB),可永久查询 |
agent 实际上根本无法将 ollama 加载到 context 中。Code Explorer 将其提炼为一张图谱,让你只需一条命令即可进行查询。
### 2. 回答一个结构化问题:*“`GenerateHandler` 的影响范围有多大?”*
| | 没有 Code Explorer | 有 Code Explorer |
|---|---|---|
| **方式** | 打开受影响代码所在的每个文件,手动递归排查 | `code-explorer impact GenerateHandler` |
| **消耗的 Context** | **~730,000 tokens**(需读取 174 个文件) | **~18,000 tokens**(一次查询) |
| **延迟** | 每一跳需数秒的文件读取时间 | **~25 ms** |
| **完整性** | 需要解析 174 个文件的原始文本 | **1,370 个受影响的符号**,完整的传导依赖链 |
| **可复用?** | 否——下一个问题需要从头再来 | 是——图谱在不同会话间持久存在 |
➡️ 以**约 40 倍更少的 context** 换取*更完整、更即时、可复用*的答案——使用 `code-explorer demo` 复现。
### 3. 跨真实代码仓库的实测(11 个项目,10 种语言)
每一行都是在具有代表性的核心符号上运行 `code-explorer demo
` 的结果——显示了在有无 Code Explorer 的情况下,agent 回答*“如果我修改这个,什么会受到影响?”*时所消耗的 context。每个代码仓库的完整源码都已经超出了任何模型的 context window。
**代码库越大,优势越明显。** 大型代码仓库超出 context window 的程度更严重,且具有更长的依赖链,因此图谱能按比例节省更多——Kubernetes 是本文中最大的项目,以 **164 倍** 位居榜首。(确切的每次查询比率还取决于你查询的符号的关联程度。)
| Repo | 语言 | 文件数 | 🐌 没有 | ⚡ 有 | 节省 | 代码仓库大小 |
|---|---|--:|--:|--:|:--:|--:|
| [**kubernetes**](https://github.com/kubernetes/kubernetes) | Go | **17,280** | 3.88M tok | 24K tok | **164×** | **42.8M tok** |
| [TypeScript](https://github.com/microsoft/TypeScript)* | TypeScript | 707 | 821K tok | 12K tok | **67×** | 3.9M tok |
| [mastodon](https://github.com/mastodon/mastodon) | Ruby | 4,055 | 266K tok | 5K tok | **54×** | 2.1M tok |
| [whisper.cpp](https://github.com/ggml-org/whisper.cpp) | C++ | 887 | 526K tok | 11K tok | **49×** | 4.8M tok |
| [django](https://github.com/django/django) | Python | 3,031 | 3.04M tok | 79K tok | **39×** | 5.1M tok |
| [ollama](https://github.com/ollama/ollama) | Go | 863 | 1.93M tok | 53K tok | **36×** | 2.5M tok |
| [okhttp](https://github.com/square/okhttp) | Kotlin | 640 | 731K tok | 21K tok | **35×** | 1.1M tok |
| [tokio](https://github.com/tokio-rs/tokio) | Rust | 781 | 39K tok | 1.3K tok | **29×** | 1.4M tok |
| [langchain4j](https://github.com/langchain4j/langchain4j) | Java | 2,869 | 248K tok | 12K tok | **20×** | 3.7M tok |
| [laravel](https://github.com/laravel/framework) | PHP | 2,960 | 1.84M tok | 100K tok | **18×** | 4.3M tok |
| [jellyfin](https://github.com/jellyfin/jellyfin) | C# | 2,095 | 12K tok | 2K tok | **6×** | 3.0M tok |
* TypeScript = 指编译器的 `src/`(排除了其 2 万个文件的测试集)。每次查询的比率取决于所选核心符号的影响范围——jellyfin 中所选的符号影响范围较小(6 倍);无论如何,语料库无法装入 context 的结论是成立的。
**规模检验——Kubernetes:** 将 **360 万行** Go 代码(约 4280 万 tokens ≈ 20 个完整的 context window)提炼为一个 **296,358 节点的图谱**。随后,一次影响范围查询只需在不到 1 秒内消耗 **24K tokens**,而不是让 agent 去阅读 390 万 tokens 的源码——**减少了 164 倍的 context**。(为如此庞大的规模进行索引建图属于一次性的批处理步骤——在 24 核机器上处理 Kubernetes 约需 38 分钟;之后的所有查询都能保持在亚秒级水平。)
*“没有” = 受影响符号所在文件的 token 数(即 agent 必须阅读以追踪相同影响的内容);“有” = 图谱答案的 token 数。中位数为 **~36 倍**,在规模化场景下最高可达 **164 倍**。Tokens ≈ 字符数/4。这些正是 14 种语言解析器在不断持续验证时所使用的相同的真实代码库。*
### 4. 跨语言的索引速度
| Repo | 语言 | 文件数 | 代码行数 | 索引时间 | 节点数 | 边数 |
|---|---|---:|---:|---:|---:|---:|
| [kubernetes](https://github.com/kubernetes/kubernetes) | Go | 17,280 | 3.6M | ~38 min | 296,358 | 1,097,538 |
| [mastodon](https://github.com/mastodon/mastodon) | Ruby | 4,055 | 264K | 17 s | 23,598 | 75,151 |
| [django](https://github.com/django/django) | Python | 3,031 | 522K | 41 s | 50,380 | 210,177 |
| [laravel](https://github.com/laravel/framework) | PHP | 2,960 | 528K | 29 s | 50,801 | 211,444 |
| [langchain4j](https://github.com/langchain4j/langchain4j) | Java | 2,869 | 376K | 16 s | 42,953 | 140,648 |
| [jellyfin](https://github.com/jellyfin/jellyfin) | C# | 2,095 | 318K | 8 s | 22,128 | 46,153 |
| [whisper.cpp](https://github.com/ggml-org/whisper.cpp) | C++ | 887 | 541K | 12 s | 26,938 | 77,501 |
| [ollama](https://github.com/ollama/ollama) | Go | 863 | 384K | 3 s | 22,982 | 70,538 |
| [io](https://github.com/tokio-rs/tokio) | Rust | 781 | 175K | 1.5 s | 12,413 | 27,938 |
| [TypeScript](https://github.com/microsoft/TypeScript) | TypeScript | 707 | 453K | 19 s | 30,664 | 89,976 |
| [okhttp](https://github.com/square/okhttp) | Kotlin | 640 | 133K | 4 s | 15,060 | 57,542 |
在文件数量达到数千个之前,索引时间基本与文件数量呈线性关系(3–30 秒);Kubernetes(1.7 万个文件,110 万条边的图)是一个特例,其主要耗时在于社区/过程检测——这是一次性成本,之后查询将保持亚秒级响应。
复现测试
```
git clone https://github.com/ollama/ollama && cd ollama
code-explorer demo # measures the LLM context savings, end to end
# 或按步骤操作:
code-explorer analyze . --force # build the graph
code-explorer impact GenerateHandler --direction both # the blast-radius query, in ~25 ms
```
*Token 数据使用常见的约 4 字符/token 的近似换算;“没有”一栏的基线值是受影响符号所在文件的总和——即 agent 必须阅读以追踪相同影响的内容(这是一个保守的下限)。*
## 实际运行
桌面应用将该图谱转化为一个代码健康驾驶舱——评分、热点、耦合度、所有权、覆盖率以及连接最紧密的符号,所有这些都源自你的 agent 所查询的同一个索引:
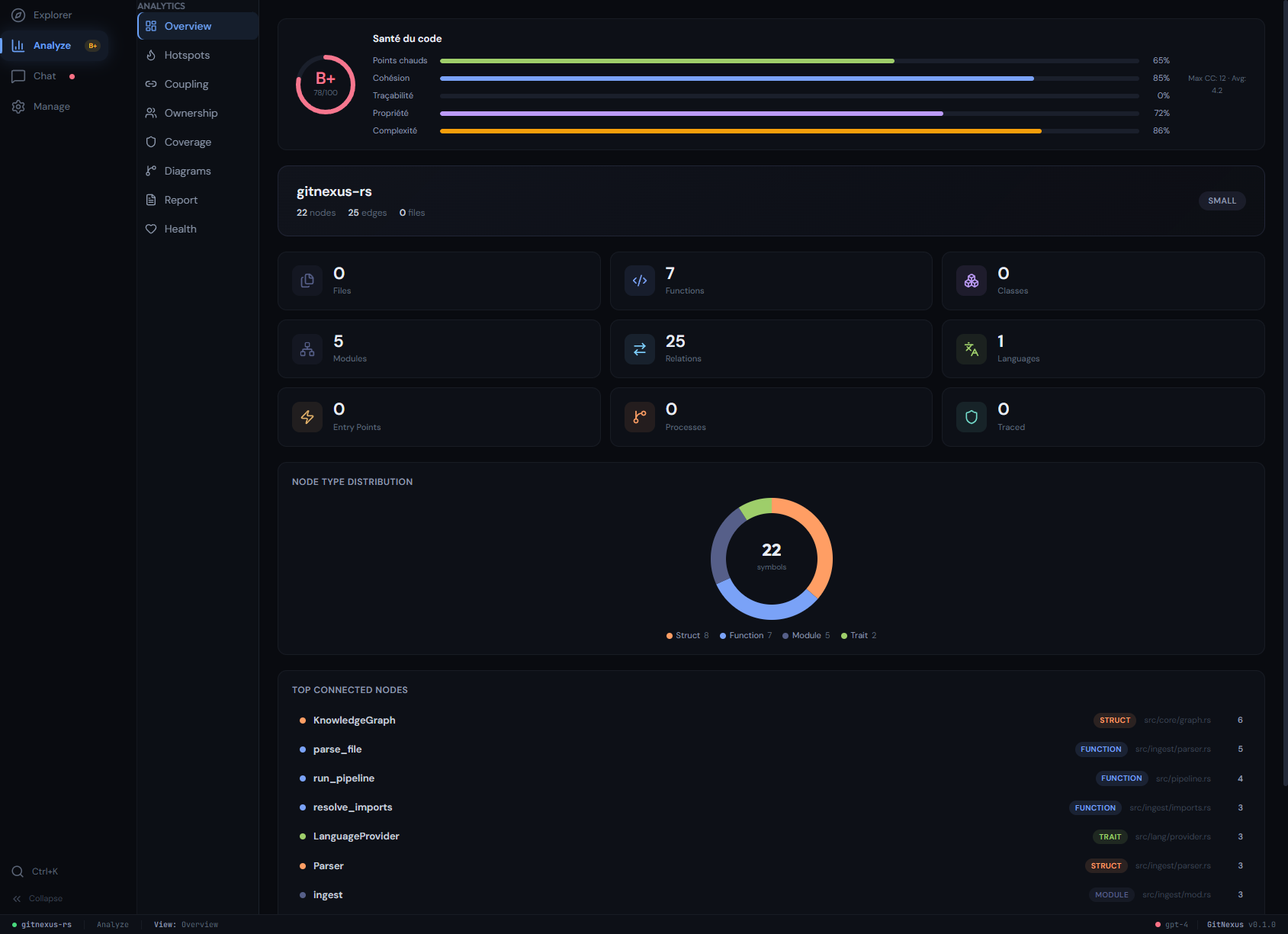
## 快速开始
```
# 1. Clone & build CLI(release:约 64 MB 的 static binary)
git clone https://github.com/phuetz/code-explorer.git
cd code-explorer
cargo build --release -p code-explorer-cli
# → binary 位于 target/release/code-explorer(Windows 上为 code-explorer.exe)
# 2. Index 一个项目
code-explorer analyze /path/to/your/project
# 3. 询问 graph
code-explorer context handleLogin # 360° view: callers, callees, imports, hierarchy
code-explorer impact PaymentService # blast radius, upstream + downstream
code-explorer search "where do we verify auth"
code-explorer cypher "MATCH (n:Function) RETURN n.name LIMIT 10"
```
索引或图谱查询无需互联网,也无需 API key。(诸如 `ask` 和 `--enrich` 等 LLM 功能为可选项,需使用你自己的 API key。)
## 与你的 agent 配合使用
Code Explorer 是一个 **MCP server**——只需连接一次,你的 agent 就能获得 29 个代码智能工具。
**Claude Code**
```
code-explorer mcp install # auto-configures the MCP server
# 或手动将你的 client 指向:code-explorer mcp(stdio transport)
```
**Claude 获得的能力:** 不需要为了回答*“谁调用了 `PaymentService`?”*或*“如果我修改这个,什么会受到影响?”*而阅读数十个文件并填满其 context window,Claude 只需调用一个工具即可在 **~990 tokens 内获得答案(减少了约 40 倍的 context——[查看基准测试](#benchmarks-with-vs-without))**。图谱持久化在磁盘上,因此 Claude 不会在每次对话中都去重新了解你的代码库,释放出来的 context 将被用于真正的推理,而不是阅读文件。这也同样适用于 Codex、Cursor 以及任何 MCP agent。
**Codex / Cursor / VS Code / 任何 MCP 客户端** —— 添加一个运行 `code-explorer mcp` (stdio) 的 MCP server,或针对 HTTP 传输方式运行 `code-explorer serve --http 8080`。
连接成功后,agent 可以调用:
| 分组 | 工具 |
|---|---|
| **图谱与查询** | `query`, `context`, `impact`, `cypher`, `search_code`, `read_file`, `find_cycles`, `find_similar_code`, `detect_changes`, `rename` |
| **分析** | `hotspots`, `coupling`, `ownership`, `coverage`, `diagram`, `report`, `get_complexity`, `analyze_execution_trace` |
| **内省** | `list_repos`, `list_todos`, `list_endpoints`, `list_db_tables`, `list_env_vars`, `get_endpoint_handler` |
| **Agent 辅助** | `get_insights`, `save_memory` |
此外还有一个内置的 **`/code-explorer` Claude Code skill**,能够在对话中针对自然语言问题自动调用该图谱。
## 功能
| 类别 | 亮点 |
|---|---|
| **知识图谱** | 50+ 种节点类型,27 种带类型的关联关系(调用、导入、继承、所有权),O(1) 查找,持久化快照 |
| **14 种语言** | JS, TS, Python, Java, C, C++, C#, Go, Rust, Ruby, PHP, Kotlin, Swift, Razor —— tree-sitter 解析器支持针对不同语言的结构嵌套与调用解析 |
| **MCP Server** | 29 个工具,支持 stdio + HTTP 传输,JSON-RPC 2.0 —— 可与任何 MCP agent 配合使用 |
| **混合搜索** | BM25 词法检索 + 可选的 ONNX 语义 embedding,通过 Reciprocal Rank Fusion 融合;可选 LLM 重排器 |
| **影响 / 爆炸半径** | 上游调用者、下游被调用者、任何符号的传导可达性 |
| **Git 分析** | 热点、时间耦合、所有权、单一评分健康报告(A–E) |
| **HTML 文档生成器** | DeepWiki 风格的站点:全文搜索、Mermaid 图表、交叉链接、内嵌聊天、DOCX/PDF 导出 |
| **桌面应用** | Tauri v2 + React 19 —— 交互式图谱、Treemap、分析驾驶舱、命令面板 |
| **企业级 / 旧版 .NET** | 深度支持 ASP.NET MVC 5 / EF6:控制器、Razor 视图、EDMX 实体、Telerik/Kendo 网格、jQuery→action 映射、DI 图谱 |
| **可插拔存储** | 内存后端(默认)或用于超大型代码仓库的 KuzuDB 图数据库 |
## 架构
```
code-explorer (CLI)
├── code-explorer-mcp MCP server — 29 tools, stdio/HTTP, JSON-RPC 2.0
├── code-explorer-search Hybrid search: BM25 + ONNX semantic + RRF
├── code-explorer-db Storage: in-memory (Cypher + FTS) or KuzuDB
├── code-explorer-ingest Parallel ingestion pipeline (rayon) + 14 language post-passes
│ └── code-explorer-lang 14 tree-sitter providers
├── code-explorer-query / -output / -git / -rag
└── code-explorer-core KnowledgeGraph, NodeLabel, relationships, config
```
有关完整的架构和设计说明,请参阅 [CLAUDE.md](CLAUDE.md)。
## 为什么选择这些技术方案
**Rust。** 索引大型代码仓库意味着解析数以千计的文件并遍历数以百万计的图边——这项工作是 CPU 和内存密集型的,这正是 Rust 的优势所在。它带来了:
- 一个 **约 64 MB 的单一静态二进制文件**,无需 runtime 或解释器 —— 将其放在 `PATH` 中即可直接运行(适用于 CI、队友的笔记本电脑或服务器上);
- **无所畏惧的并行能力** —— 文件解析在固定的内存预算(20 MB 数据块 + LRU AST cache)下通过 [rayon](https://github.com/rayon-rs/rayon) 在多个核心上并发执行,因此包含 3,000 个文件的代码仓库可在几秒内完成索引;
- **可预测的速度与内存**(无 GC 暂停),在 release 模式下开启 `opt-level 3` + thin LTO;
- 内存安全性,因此解析器永远不会因为奇怪的输入而发生 segfault —— 它会优雅降级。
**使用 tree-sitter 进行解析。** 使用一个久经考验的增量解析引擎以及适用于所有 14 种语言的语法,而不是去构建 14 个定制解析器。每种语言都在共享的 AST 遍历基础之上,增加了一个轻量级的后处理过程(调用解析、成员嵌套)。
**内存知识图谱,无需数据库。** 该图存在于由 `HashMap` 支持的存储中,具有 O(1) 的节点/边查找能力和确定性的 ID(`"Label:qualifiedName"`),并以 JSON 快照(`graph.bin`)的形式持久化。零配置,完全离线工作。真正的图数据库([KuzuDB](https://kuzudb.com/))是一个**可选的 (opt-in)** 功能开关,专为超大型代码仓库设计——除非你需要,否则无需为此付出额外代价。
**以 MCP 作为集成层。** Code Explorer 没有为每个编辑器开发定制的插件,而是采用了 [Model Context Protocol](https://modelcontextprotocol.io/)——因此同一套 server 即可通过 stdio 或 HTTP 与 Claude Code、Codex、Cursor、VS Code 以及任何其他支持 MCP 的工具配合使用。
**本地优先与隐私保护。** 索引和查询 100% 在本地进行——你的源码永远不会离开本机,也不需要 API key。LLM 相关功能(`ask`、`--enrich`)是可选的,并需使用你自己的 API key。
**混合检索。** 词法检索 [BM25](https://en.wikipedia.org/wiki/Okapi_BM25) 快速且精确;ONNX 语义 embedding(通过 [`ort`](https://github.com/pykeio/ort))能够捕捉语义改写。它们通过 Reciprocal Rank Fusion (K=60) 进行融合,并在未构建 embedding 时优雅地回退到纯 BM25 检索。
## 关于
Code Explorer 由 **Patrice Huetz**(开发者、软件架构师兼作家)在 **[agile-up.com](https://www.agile-up.com)** 设计并开发。
它是 [Code Buddy](https://github.com/phuetz/code-buddy)(多供应商 AI 编程 agent)的代码智能**伴侣**:Code Buddy 是编写代码和执行命令的*手*,而 Code Explorer 是早已洞悉代码库结构的*大脑*。让 agent 同时对接这两者,它就能在一个真正被其理解的代码仓库上大展身手。
Patrice 还**撰写书籍**——欢迎访问 **[patricehuetz.fr](https://www.patricehuetz.fr)** 探索他的作品。
🌐 **官网:** [phuetz.github.io/code-explorer](https://phuetz.github.io/code-explorer/)
## 许可证
Code Explorer 基于 **[PolyForm Noncommercial License 1.0.0](LICENSE)** 发布。
- ✅ 任何非商业用途均可**免费**使用——包括个人项目、研究、教育和评估。
- 💼 **商业用途**(在盈利环境中使用,或在产品/服务中使用)需要单独的许可。
对商业许可、合作或将 Code Explorer 集成到你的工具链中感兴趣?请联系:**patrice.huetz@gmail.com** · [agile-up.com](https://agile-up.com)。
**[在 GitHub 上点亮 Star⭐](https://github.com/phuetz/code-explorer)** ·
**[报告 Bug](https://github.com/phuetz/code-explorer/issues)** ·
**[请求新功能](https://github.com/phuetz/code-explorer/discussions)**
使用 Rust 构建 · MCP 原生 · 支持 Claude Code, Codex, Cursor 及任何 MCP agent
作者 [Patrice Huetz](https://www.patricehuetz.fr) · [agile-up.com](https://www.agile-up.com) · [Code Buddy](https://github.com/phuetz/code-buddy) 的伴侣项目