bukx/observability-platform
GitHub: bukx/observability-platform
一个整合 metrics、logs、traces、告警路由、runbooks 与混沌工程的全栈可观测性和事件响应平台,帮助团队从被动监控转向主动的可靠性实践。
Stars: 0 | Forks: 0
# 可观测性平台
围绕 metrics、logs、traces、alerting、runbooks 和 chaos validation 构建的全栈可观测性和事件响应平台。该 repo 展示了如何通过更清晰的信号和更快的响应工作流,从被动监控转向主动的可靠性实践。
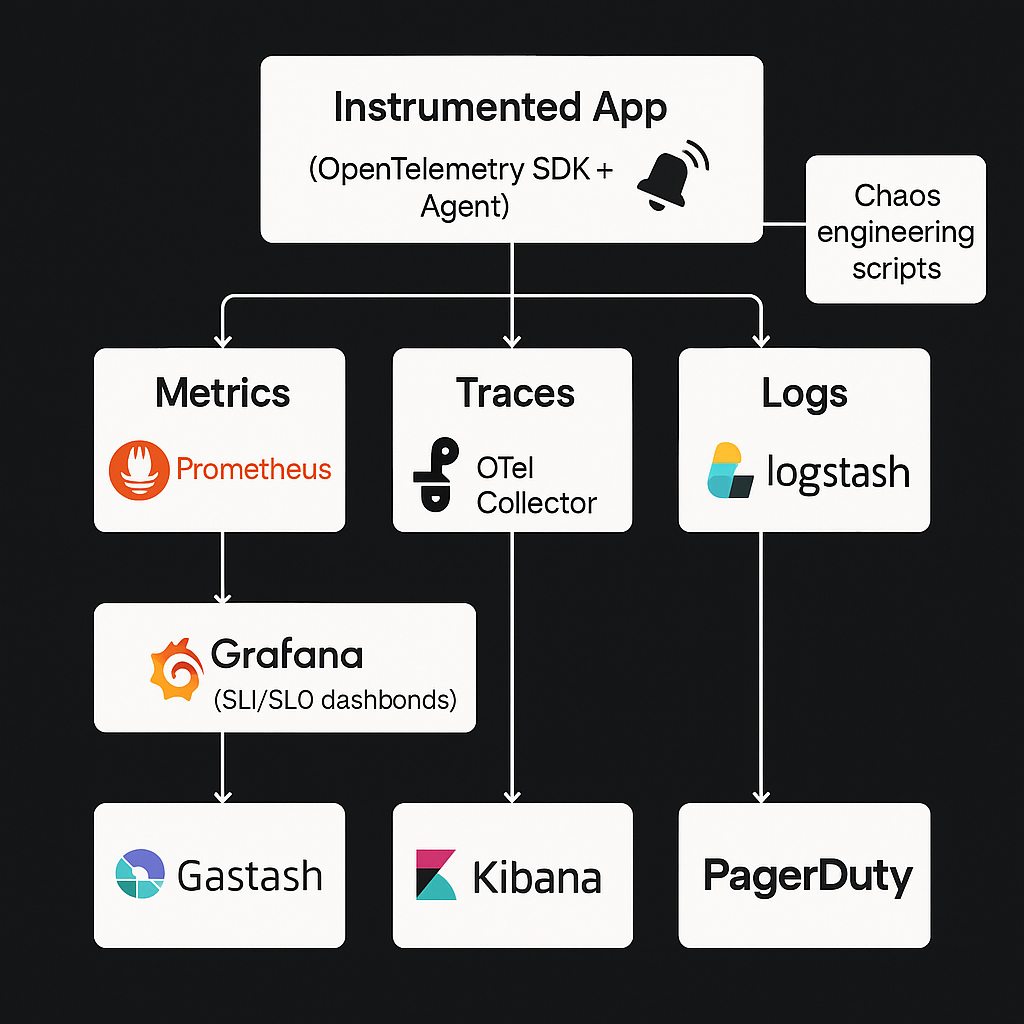
## 为什么这个 repo 很重要
许多监控 demo 仅停留在 dashboards 层面。该项目更进一步,将可观测性的三大支柱、SLI/SLO 思维、alert 路由、runbooks 和 fault injection 结合在了一起。
## 包含内容
- `app/` 下的插桩应用源码
- Prometheus、Alertmanager、Grafana、ELK 和 OpenTelemetry 部署资产
- Grafana dashboards 和 alerting rules
- 用于延迟和错误场景的 chaos 脚本
- 用于运维响应的 runbooks 和 postmortem 模板
- 本地 Docker 资产以及 Kubernetes manifests
## 可观测性范围
- **Metrics:** 使用 Prometheus 和 Grafana 进行收集、制作 dashboards 和 alerting
- **Logs:** 使用 ELK stack 进行集中式日志聚合和搜索
- **Traces:** OpenTelemetry 和 Jaeger 风格的 tracing pipeline
- **响应:** Alertmanager、runbooks 和 postmortem 模板
- **验证:** 用于在故障条件下测试系统的 chaos 脚本
## 快速开始
```
# 部署 stack
kubectl apply -f k8s/app/
kubectl apply -f k8s/prometheus/
kubectl apply -f k8s/grafana/
kubectl apply -f k8s/elk/
kubectl apply -f k8s/otel-collector/
# 注入 faults 并观察 behavior
./chaos-scripts/chaos-runner.sh latency
./chaos-scripts/chaos-runner.sh errors
./chaos-scripts/chaos-runner.sh reset
```
## 仓库布局
```
.
|-- app/ # instrumented application
|-- chaos-scripts/ # fault injection scripts
|-- dashboards/ # Grafana dashboard assets
|-- docker/ # local container assets
|-- k8s/ # Kubernetes deployment manifests
|-- postmortem-templates/ # incident review templates
|-- runbooks/ # operational runbooks
|-- docs/ # diagrams and supporting docs
`-- .github/ # validation workflows
```
## 展示内容
- 跨 metrics、logs 和 traces 的端到端可观测性设计
- 通过 alerting、runbooks 和 postmortems 展现的运维成熟度
- 面向 SLI/SLO 的监控,而非 dashboards 的泛滥
- 通过受控的 chaos 测试来验证可靠性假设
标签:API集成, ELK, 可观测性, 子域名突变, 混沌工程, 用户代理, 自定义请求头, 请求拦截, 运维监控