davidmatousek/tachi
GitHub: davidmatousek/tachi
自动化威胁建模边车工具,在单命令下集成 STRIDE 与 AI 威胁分析并输出评分与报告。
Stars: 80 | Forks: 19
# tachi
**自动化威胁建模边车程序,用于你的项目。**
[](LICENSE)
[](https://github.com/davidmatousek/tachi/releases)
[](https://github.com/davidmatousek/agentic-oriented-development-kit)
**快速开始**:[快速入门](#quick-start) | [开发者指南](docs/guides/DEVELOPER_GUIDE_TACHI.md)(包含完整示例的逐步指南)
## 什么是 tachi?
tachi 是一个威胁建模边车程序,你可以将其添加到任何项目中。它会派发 12 个专门的威胁代理来分析你的架构描述,并在单个命令中生成完整的威胁模型。五个后流水线命令用于增强结果:`/tachi.risk-score` 用于定量评分、`/tachi.compensating-controls` 用于代码库控制分析、`/tachi.infographic` 用于可视化风险图、`/tachi.security-report` 用于生成专业的 PDF 评估手册,以及 `/tachi.architecture` 用于自动化架构描述生成。
- **11 个威胁类别**:6 个 STRIDE + 3 个 LLM 特定 + 2 个代理式
- **MAESTRO 层映射**:CSA 七层分类法(L1-L7)用于代理式 AI 威胁分类
- **5 种输入格式**:Mermaid、自由文本、ASCII、PlantUML、C4
- **6 个命令,20+ 个工件**:结构化发现项、SARIF、叙述性报告、攻击树、风险评分、补偿控制、5 种信息图模板、PDF 安全报告
- **基线差异追踪**:比较多次运行以跟踪新发现、已解决发现和未变更发现
- **适用于任何技术栈**:tachi 分析的是架构,而非代码
tachi 使用 [代理式有序开发套件(AOD Kit)](https://github.com/davidmatousek/agentic-oriented-development-kit) 构建,这是一个用于 AI 代理辅助开发的治理框架。
## 先决条件
tachi 需要两个外部 CLI 才能实现全部功能。两者都是必需的:`typst` 用于编译 PDF 安全报告,`@mermaid-js/mermaid-cli`(`mmdc`)用于渲染攻击路径图。理由请参见 [ADR-022](docs/architecture/02_ADRs/ADR-022-mmdc-hard-prerequisite.md)。
**macOS**:
```
brew install typst
npm install -g @mermaid-js/mermaid-cli
```
**Linux**(Debian/Ubuntu):
```
apt install typst # or: cargo install typst-cli / dnf install typst on Fedora
npm install -g @mermaid-js/mermaid-cli
```
**WSL**(使用与你的发行版相同的包管理器,与 Linux 相同):
```
apt install typst
npm install -g @mermaid-js/mermaid-cli
```
如果存在攻击树且缺少任一 CLI,`/tachi.security-report` 将在预检阶段中止并显示清晰的安装命令。
## 快速开始
### 1. 克隆 tachi(一次性操作)
```
git clone https://github.com/davidmatousek/tachi.git ~/Projects/tachi
```
### 2. 将 tachi 添加到你的项目
从项目根目录开始:
```
~/Projects/tachi/scripts/install.sh
```
要安装特定版本:
```
~/Projects/tachi/scripts/install.sh --version v4.17.0 # x-release-please-version
```
如果 tachi 克隆到了非默认位置:
```
~/Projects/tachi/scripts/install.sh --source /path/to/tachi
```
请参阅 [`INSTALL_MANIFEST.md`](INSTALL_MANIFEST.md) 获取可分发文件的完整列表。
### 3. 重新启动 Claude Code
复制文件后,**重新启动 Claude Code**(关闭并重新打开 VS Code 窗口,或启动新的 CLI 会话),以便它识别新的代理和命令。
如果你想要信息图图片(`.jpg`),请使用 [Google AI Studio](https://aistudio.google.com/apikey) 设置 `GEMINI_API_KEY` 环境变量。这是可选的 —— 所有纯文本输出都无需它即可工作。
### 4. 创建你的架构文件(或让 Claude Code 自动生成)
创建 `docs/security/architecture.md` 来描述你的系统。你可以手动编写,也可以让 Claude Code 来完成:
```
Investigate this repository's architecture -- source code, config files, infrastructure
definitions, READMEs -- and create docs/security/architecture.md as a Mermaid flowchart
with all major components, data flows, protocols, and trust boundaries.
```
tachi 会自动检测格式。Mermaid、自由文本、ASCII、PlantUML 和 C4 均受支持。
### 5. 运行你的第一个威胁模型
```
/tachi.threat-model
```
就这样。一个命令。tachi 会验证设置、读取你的架构、派发 12 个威胁代理,并将所有内容写入 `docs/security/` 下的时间戳文件夹中。
### 6. 查看结果
| 文件 | 来源 | 包含内容 |
|------|------|----------|
| `threats.md` | `/tachi.threat-model` | 主要威胁模型 —— 发现项、覆盖矩阵、MAESTRO 层、风险摘要 |
| `threats.sarif` | `/tachi.threat-model` | SARIF 2.1.0,用于 GitHub 代码扫描和 CI/CD 集成 |
| `threat-report.md` | `/tachi.threat-model` | 叙述性报告,包含执行摘要和修复路线图 |
| `attack-trees/` | `/tachi.threat-model` | 每个关键/高危发现对应一个 Mermaid 攻击树 |
| `risk-scores.md` | `/tachi.risk-score` | 包含 CVSS、可利用性、可扩展性、可达性的四维定量风险评分 |
| `risk-scores.sarif` | `/tachi.risk-score` | 包含复合评分的 SARIF 2.1.0,每个发现项包含 `security-severity` |
| `compensating-controls.md` | `/tachi.compensating-controls` | 检测到的代码库控制、剩余风险及缺失控制建议 |
| `compensating-controls.sarif` | `/tachi.compensating-controls` | 包含剩余风险的 SARIF 2.1.0,每个发现项包含 `security-severity` |
| `threat-baseball-card.jpg` | `/tachi.infographic` | 棒球卡风险仪表盘(需要 `GEMINI_API_KEY`) |
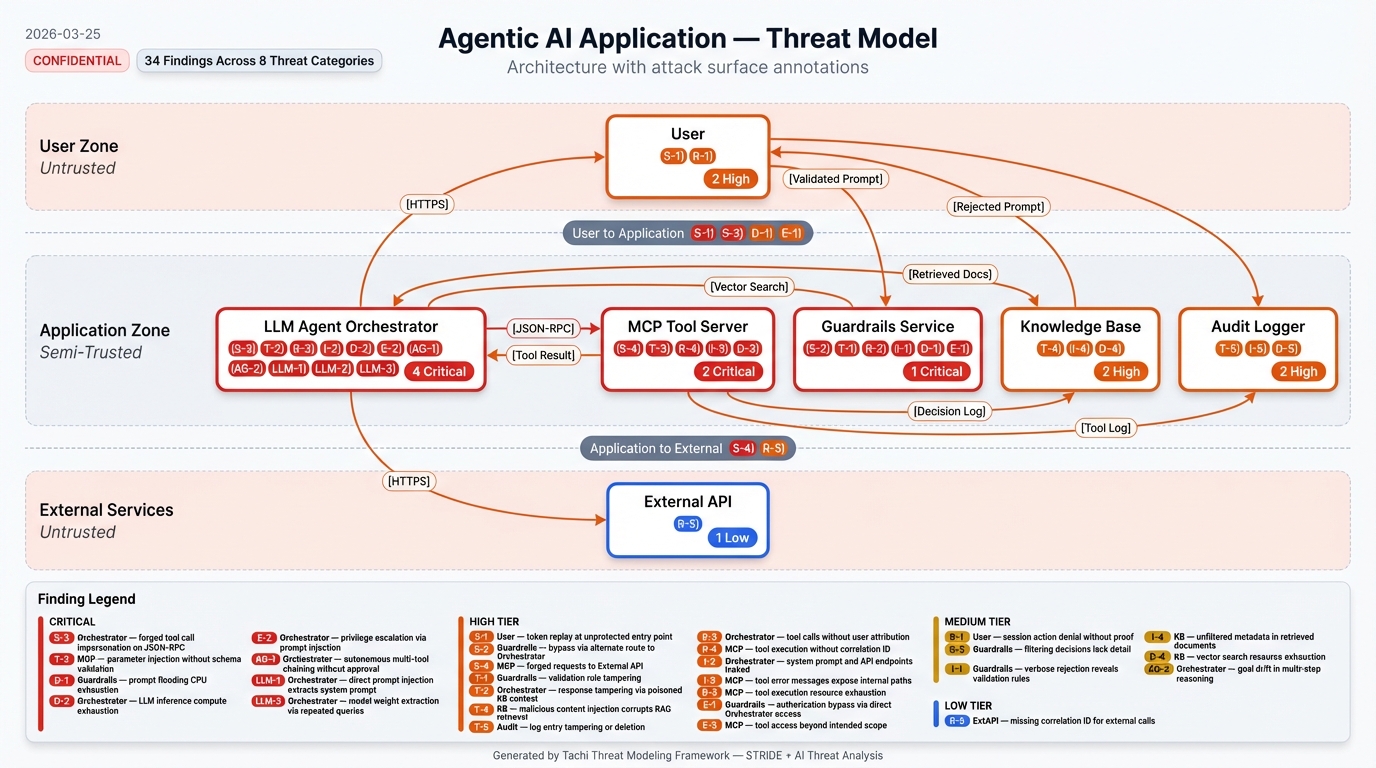
| `threat-system-architecture.jpg` | `/tachi.infographic` | 带有发现图例的注释架构图 |
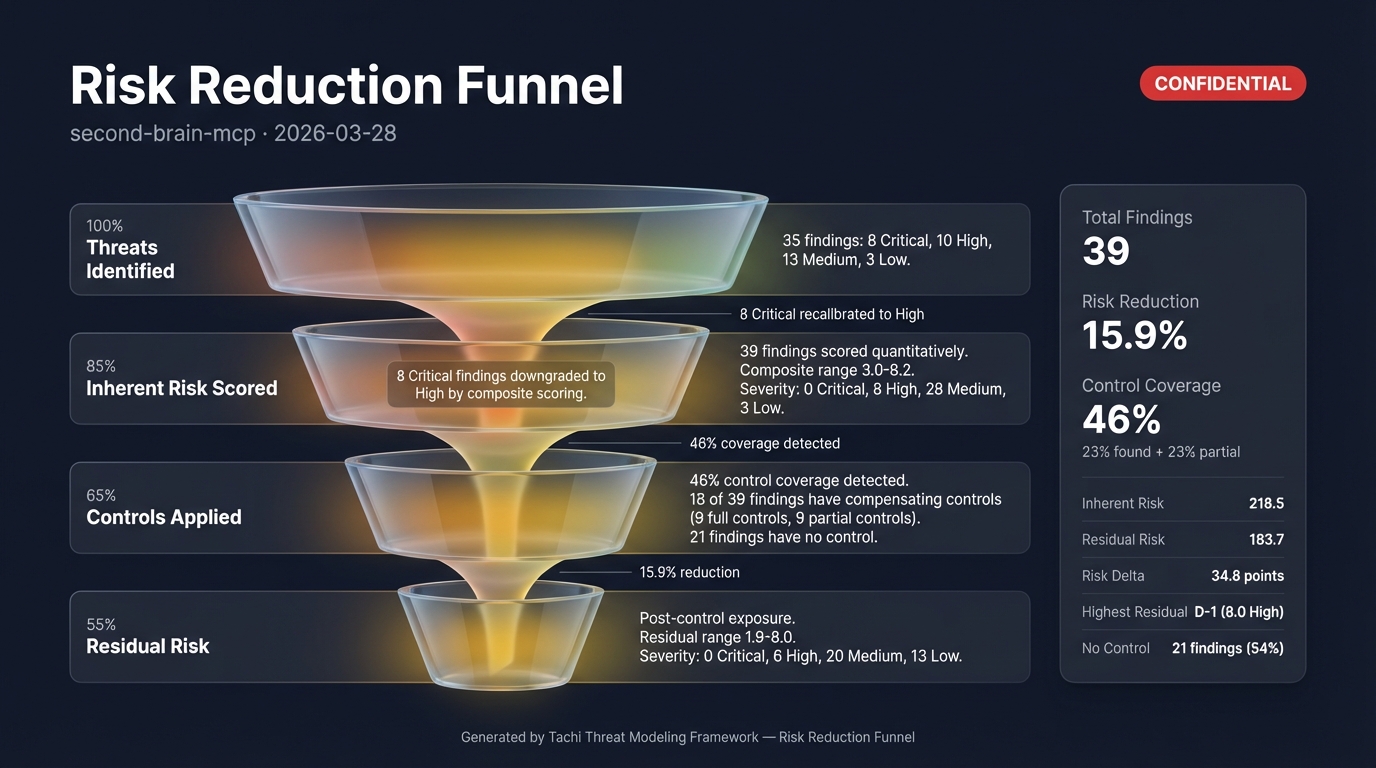
| `threat-risk-funnel.jpg` | `/tachi.infographic` | 按严重性划分的风险分布漏斗 |
| `threat-maestro-stack.jpg` | `/tachi.infographic` | MAESTRO 层堆栈可视化(仅限代理式系统) |
| `threat-maestro-heatmap.jpg` | `/tachi.infographic` | MAESTRO 层 × 严重性热力图(仅限代理式系统) |
| `security-report.pdf` | `/tachi.security-report` | 包含所有工件的多页专业 PDF 评估手册 |
从 `threats.md` 的第 7 节 —— 推荐操作开始。然后运行 `/tachi.risk-score` 进行定量优先级排序,`/tachi.compensating-controls` 检测现有防御,`/tachi.infographic` 生成可视化风险图,`/tachi.security-report` 将所有内容整合为 PDF 手册。优先处理关键发现,再处理高危发现。
## 命令选项
### /tachi.threat-model
运行 5 阶段威胁建模流水线:范围界定、确定威胁、确定对策、评估和报告。生成 `threats.md`、`threats.sarif`、`threat-report.md`、`attack-trees/` 和 `attack-chains.md`(在检测到跨层链时为条件生成)。发现项包含代理式 AI 组件的 MAESTRO 层分类。阶段 3.5 跨层关联检测跨越多个 MAESTRO 层的攻击链,并提供带中断建议的控制措施。自动检测上次运行的基线以进行差异追踪。
```
# 默认 — 使用 docs/security/architecture.md
/tachi.threat-model
# 指定架构文件
/tachi.threat-model path/to/my-architecture.md
# 自定义输出目录
/tachi.threat-model docs/security/architecture.md --output-dir reports/security/
# 版本标记输出用于发布
/tachi.threat-model docs/security/architecture.md --version v1.0.0
# 显式基线用于差异比较
/tachi.threat-model docs/security/architecture.md --baseline docs/security/2026-03-01/threats.md
```
### /tachi.risk-score
为威胁模型输出添加四维定量风险评分(CVSS 3.1、可利用性、可扩展性、可达性)以及治理字段(所有者、SLA、处置、审核日期)。生成 `risk-scores.md` 和 `risk-scores.sarif`。
```
# 在默认位置评估威胁
/tachi.risk-score
# 在特定目录中评估威胁
/tachi.risk-score docs/security/2026-03-27/
# 自定义输出目录
/tachi.risk-score docs/security/2026-03-27/ --output-dir reports/risk/
```
### /tachi.compensating-controls
针对已评分威胁扫描目标代码库,以检测现有安全控制、计算剩余风险并推荐缺失控制。需要 `/tachi.risk-score` 输出作为输入。生成 `compensating-controls.md` 和 `compensating-controls.sarif`。
` 标签中(遵循现有的 `maestro-layer:` 约定)。确定性分类规则表和多代理谓词位于 [`maestro-agentic-patterns-shared.md`](.claude/skills/tachi-shared/references/maestro-agentic-patterns-shared.md)。
先前未被发现的模式(代理协作、时序攻击、涌现行为)在未被任何单个检测代理捕获时,会通过网络新发现项显现,这些发现项带有 `AGP-NN` ID 前缀,在架构满足规则的拓扑前提条件但没有任何现有发现项携带该模式标签时生成。
### 基线差异追踪
当你在已有先前运行结果的系统上运行 `/tachi.threat-model` 时,tachi 会自动检测基线并计算差异:新发现项、已解决项、未变更项和已更新项。这使你能够在不手动 diff 的情况下跟踪风险态势随时间的变化。
## 威胁类别
### STRIDE(6 类)
| 类别 | 威胁 | 示例 |
|------|------|------|
| **S**poofing | 身份冒充 | 被盗用的 API 密钥用于发起经过身份验证的请求 |
| **T**ampering | 未经授权的数据修改 | SQL 注入修改数据库记录 |
| **R**epudiation | 缺乏问责 | 用户否认触发了昂贵的操作,且无日志记录 |
| **I**nformation Disclosure | 数据泄露 | 错误消息泄露内部架构细节 |
| **D**enial of Service | 可用性攻击 | 请求泛滥耗尽连接池 |
| **E**levation of Privilege | 未授权访问 | 普通用户访问管理端点 |
### 人工智能特定(5 类)
| 类别 | 威胁 | 示例 |
|------|------|------|
| **Prompt Injection**(LLM) | 对抗性输入劫持 LLM 行为 | 在文档中隐藏指令导致 LLM 泄露其系统提示 |
| **Data Poisoning**(LLM) | 训练/RAG 数据被污染 | 攻击者修改知识库文档以传播错误信息 |
| **Model Theft**(LLM) | 模型窃取 | 竞争对手通过 API 查询反演你的微调模型 |
| **Agent Autonomy**(AG) | 监督不足 | AI 代理在未获批准的情况下发送 500 封电子邮件 |
| **Tool Abuse**(AG) | 工具误用或操纵 | 恶意插件在调用时泄露源代码 |
## 示例
[`examples/`](examples/) 目录包含使用不同输入格式和架构的完整威胁模型示例:
| 示例 | 输入格式 | 架构 | 威胁类别 |
|------|----------|------|----------|
| [Agentic App](examples/agentic-app/) | Mermaid | LLM 编排器 + MCP 工具 | STRIDE + AI + MAESTRO |
| [Mermaid Agentic App](examples/mermaid-agentic-app/) | Mermaid | 多代理系统 | STRIDE + AI |
| [Web App](examples/web-app/) | Mermaid | 传统 Web 应用 | STRIDE |
| [Microservices](examples/microservices/) | Mermaid | 跨服务架构 | STRIDE |
| [ASCII Web API](examples/ascii-web-api/) | ASCII | 带数据库的 REST API | STRIDE |
| [Free-text Microservice](examples/free-text-microservice/) | 自由文本 | 事件驱动的微服务 | STRIDE |
代理式应用示例包含一个 [完整的样本报告](examples/agentic-app/sample-report/),展示流水线生成的每个工件 —— 结构化发现项、SARIF、叙述性报告、攻击树、跨层攻击链、风险评分、补偿控制、信息图:


## 集成参考
| 资源 | 位置 | 用途 |
|------|------|------|
| 接口契约 | [`docs/INTERFACE-CONTRACT.md`](docs/INTERFACE-CONTRACT.md) | 输入格式、调用协议、输出结构 |
| 输出模板 | [`templates/tachi/`](templates/tachi/) | 标准输出结构和 Typst PDF 模板 |
| 模式 | [`schemas/`](schemas/) | 机器可读合约 ([finding.yaml](schemas/finding.yaml), [input.yaml](schemas/input.yaml), [output.yaml](schemas/output.yaml), [risk-scoring.yaml](schemas/risk-scoring.yaml)) |
| 分类法交叉对照 | [`schemas/taxonomy/`](schemas/taxonomy/README.md) | 机器可读的 OWASP/MITRE/NIST/CWE ID + 跨框架交叉对照(特性 180 F-A1) |
| 来源归属 | [`docs/architecture/02_ADRs/ADR-028-source-attribution-schema-extension.md`](docs/architecture/02_ADRs/ADR-028-source-attribution-schema-extension.md) | 可选的 `source_attribution` 发现字段(模式 1.5),引用 F-A1 框架 ID —— 仅限合约(特性 189 F-A2) |
| 威胁代理 | [`.claude/agents/tachi/`](.claude/agents/tachi/) | 12 个威胁代理(7 个 STRIDE + 3 个 LLM + 2 个代理式)+ 实用代理 |
| 命令 | [`.claude/commands/`](.claude/commands/) | 6 个斜杠命令:tachi.threat-model、tachi.risk-score、tachi.compensating-controls、tachi.infographic、tachi.security-report、tachi.architecture |
| 开发者指南 | [`docs/guides/DEVELOPER_GUIDE_TACHI.md`](docs/guides/DEVELOPER_GUIDE_TACHI.md) | 完整 walkthrough 及示例 |
## 已知问题
### 多次运行之间的发现数量差异
同一架构上连续运行威胁建模可能会产生略有不同的发现数量(通常 ±10%)。这是使用 LLM 分析的预期行为。
**稳定的方面**:所有 STRIDE 和 AI 类别中的核心发现项。每次运行都会出现相同的高危威胁。
**可能变化的方面**:长尾中的边界发现项 —— 例如 “缺少关联 ID 的外部 API 调用” 这样的中等严重性发现可能在某次运行中出现,而在另一次运行中不出现,这取决于代理对架构的推理方式。
**发生原因**:12 个威胁代理各自独立调用 LLM。LLM 输出本质上具有非确定性,因此每次调用时代理可能会产生略有不同的发现项。
**如果需要更高的一致性**:
- 运行两次并对比结果以捕获边缘情况
- 使用前一次运行的 `threats.md` 作为基线进行比较
- 将威胁建模视为一份会随着每次运行而改进的活文档
## 使用 AOD Kit 构建
tachi 使用 [代理式有序开发套件(AOD Kit)](https://github.com/davidmatousek/agentic-oriented-development-kit) 构建,这是一个用于 AI 代理辅助开发的治理框架。AOD Kit 提供了 SDLC 三元方法(PM + 架构师 + 团队负责人签字)、质量门控和结构化工作流,用于规范 tachi 本身的开发和维护。
## 版本发布
发布通过 [release-please](https://github.com/googleapis/release-please) 自动化进行。当常规提交(`feat:`、`fix:`、`docs:` 等)合并到 `main` 时,release-please 会创建一个 **发布 PR**,其中包含自动生成的 CHANGELOG 条目和下一个语义化版本。合并发布 PR 会创建 git 标签和 GitHub 发布。
要安装特定版本:`install.sh --version v4.17.0`
## 运行测试
tachi 使用 pytest 进行 Python 脚本测试,测试位于 `tests/scripts/`。要运行测试套件:
```
pip install -r requirements-dev.txt
make test
```
这将运行 `pytest tests/scripts/ --cov=scripts --cov-report=term-missing`。测试是宪法原则 VI(测试卓越,≥80% 覆盖率)所要求的。
## 贡献
我们欢迎贡献。请参阅 [CONTRIBUTING.md](CONTRIBUTING.md) 获取指南。
## 许可证
Apache 2.0 许可证。详见 [LICENSE](LICENSE)。
手动安装(备用方法)
``` # Agents (threat analysis engine) cp -r ~/Projects/tachi/.claude/agents/tachi/ .claude/agents/tachi/ # Commands (6 slash commands) mkdir -p .claude/commands for cmd in tachi.threat-model tachi.risk-score tachi.compensating-controls tachi.infographic tachi.security-report tachi.architecture; do cp ~/Projects/tachi/.claude/commands/$cmd.md .claude/commands/ done # Schemas, templates, references, and brand assets cp -r ~/Projects/tachi/schemas/ schemas/ cp -r ~/Projects/tachi/templates/ templates/ mkdir -p adapters/claude-code/agents cp -r ~/Projects/tachi/adapters/claude-code/agents/references/ adapters/claude-code/agents/references/ cp -r ~/Projects/tachi/brand/ brand/ # Developer guide mkdir -p docs/guides cp ~/Projects/tachi/docs/guides/DEVELOPER_GUIDE_TACHI.md docs/guides/ ```标签:Agentic安全, AI安全威胁, AI辅助开发, AOD Kit, ASCII, C4模型, CSA七层威胁分类, MAESTRO, Mermaid, PDF报告, PlantUML, SARIF, Sidecar模式, STRIDE, 代理安全, 信息图, 合规治理, 基线追踪, 多输入格式, 威胁分类, 威胁建模, 安全报告, 定量评分, 攻击树, 架构分析, 架构描述, 缓解控制, 自动化威胁建模, 逆向工具, 风险可视化, 风险评分