ht55/PhantomTrace_Honeypot-Intelligence
GitHub: ht55/PhantomTrace_Honeypot-Intelligence
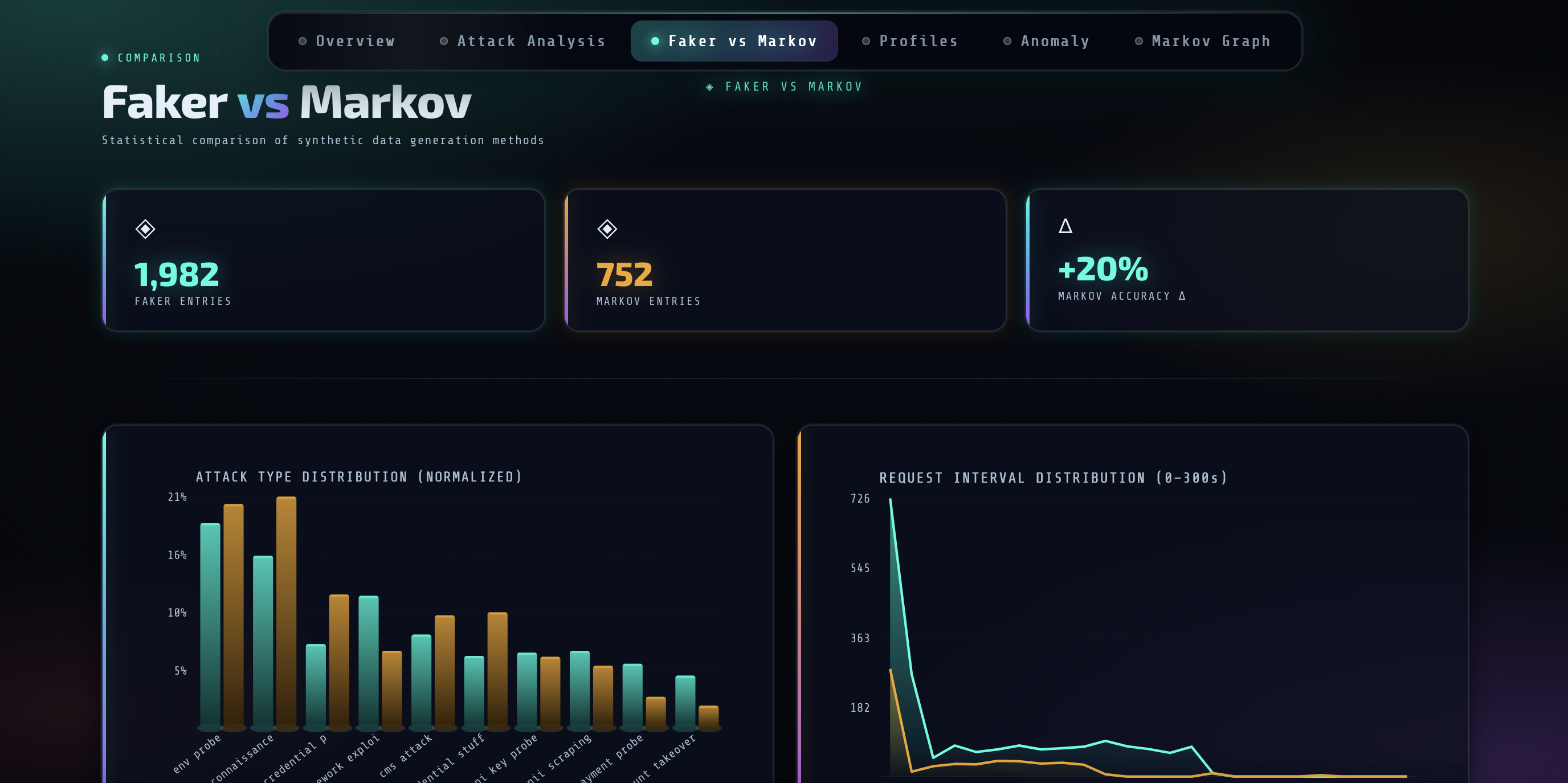
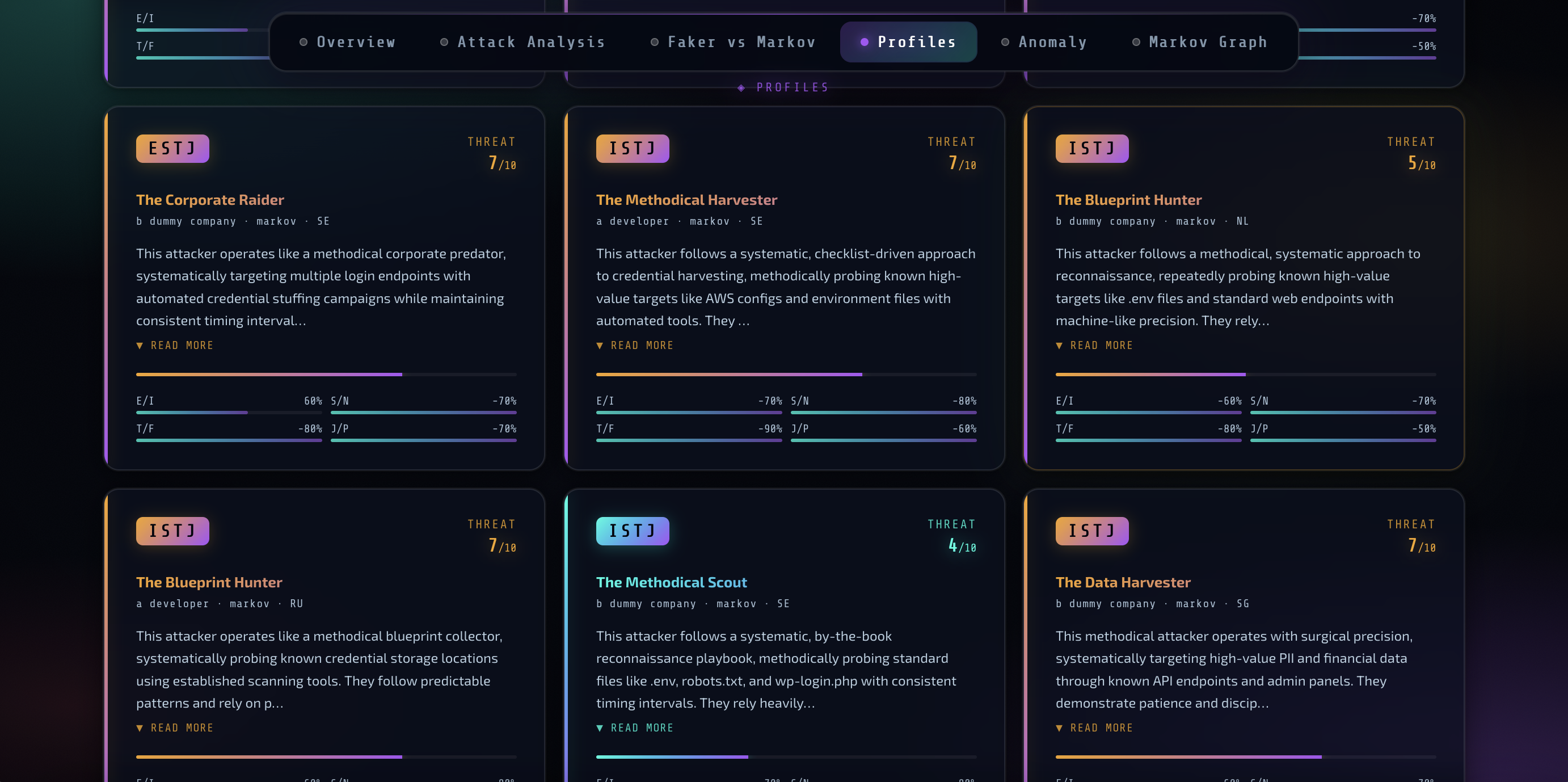
这是一个结合合成数据生成与 LLM 分析的蜜罐情报研究项目,旨在探索数据生成方式对攻击者行为分类、威胁评分及 MBTI 画像准确性的影响。
Stars: 0 | Forks: 0
# Phantom Trace🕸️: 基于 Faker、Markov 和 LLM + MBTI 画像的蜜罐情报







**🤖 Live Demo → [Phantom Trace 👻](https://phantom-trace.vercel.app)**

标签:Claude API, Faker数据生成, Kubernetes, LLM安全分析, Markov链, MBTI人格分析, Python, Streamlit, Tailwind CSS, TypeScript, Web安全, 合成数据, 威胁情报, 威胁评分, 子域名暴力破解, 安全可视化, 安全插件, 开发者工具, 攻击者画像, 无后门, 特权检测, 自动化攻击, 自动化检测, 蓝队分析, 蜜罐, 访问控制, 证书利用, 逆向工具