gossipcat-ai/gossipcat-ai
GitHub: gossipcat-ai/gossipcat-ai
这是一个通过多代理共识和交叉验证来提升代码审查准确性、减少AI幻觉的MCP服务器。
Stars: 38 | Forks: 5

多 Agent 共识代码审查。 3 个以上的 AI agent 独立审查你的代码,根据你的实际源码相互交叉核对发现的问题,并且仅展示最终幸存的结果 —— 系统还会学习在不同的领域该信任哪个 agent。





![]()
安装 · 首次运行 · 日常使用 · 仪表盘 · 聊天桥接 · 故障排除 · 配置 · 工具
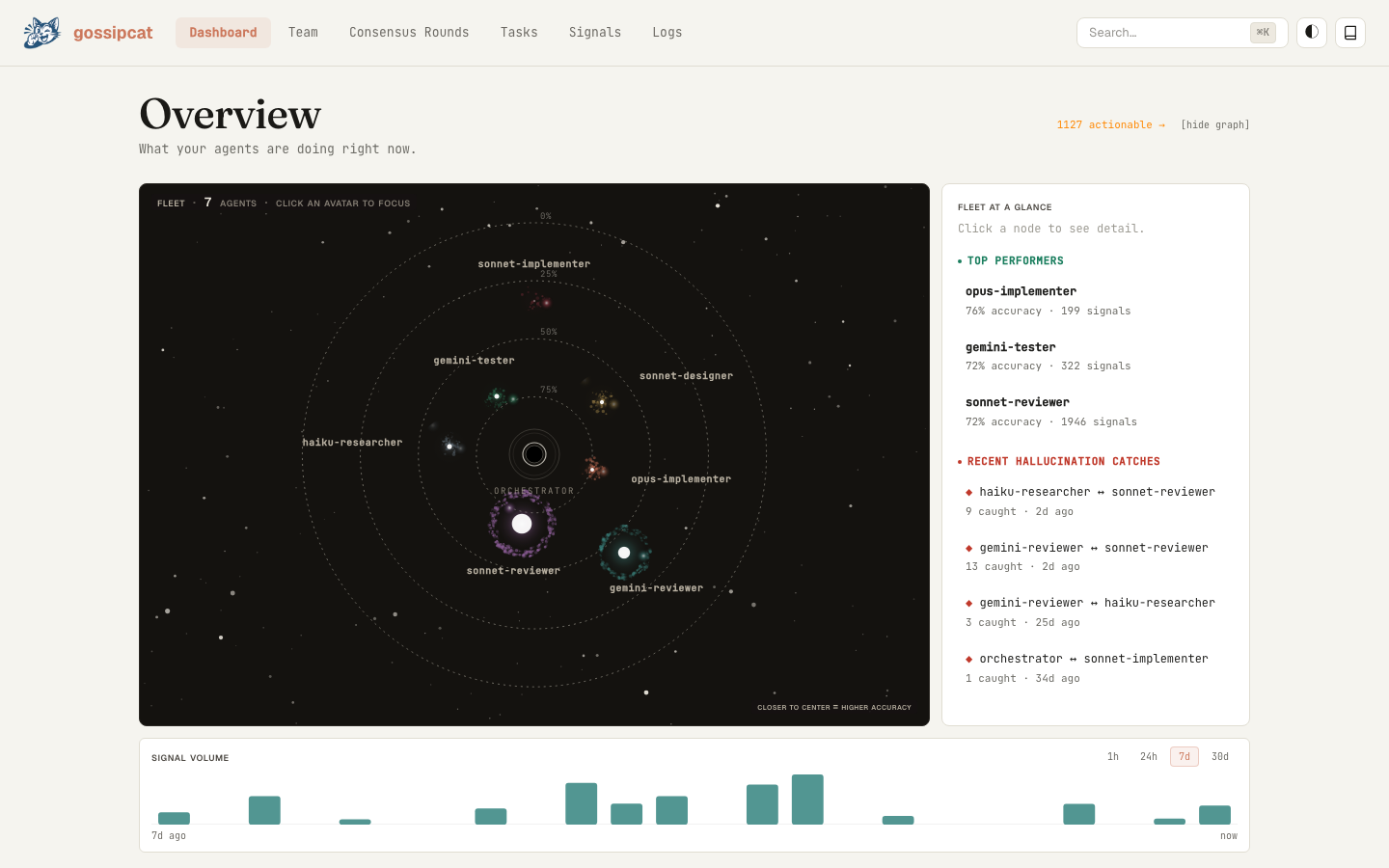
Live dashboard at http://localhost:<port>/dashboard — fleet view, signal stream, skill-graduation grid, and consensus flow, all in real time.
## 为什么需要它 单一的 AI 审查者会极其自信地报告根本不存在的 bug。你阅读了它的发现,跑去查看代码,浪费了二十分钟——代码根本没问题。由于没有第二意见,也没有过往记录,在浪费时间之前,你根本无法分辨这到底是真正的发现,还是模型的“幻觉”。 Gossipcat **并行运行多个 agent**,让它们**根据你实际的 `file:line` 交叉核对彼此的发现**,并且只展示最终幸存的结论。当某个 agent 凭空捏造了一个发现时,会有其他 peer 发现这一点,该 agent 的准确率评分就会下降——因此随着时间的推移,系统会将每类工作路由分配给真正在该领域可靠的 agent。交叉审查能捕捉到单一审查者可能会推送给你的幻觉;这种差异正是它的核心价值所在。 它作为 MCP server 运行在 **[Claude Code](https://claude.com/claude-code)** 和 **[Cursor](https://cursor.com)** 内部,提供了一个[实时操作仪表盘](#reading-the-dashboard),并允许你[直接从浏览器控制调度器](#drive-it-from-your-browser)。 **你会看到的共识标签**(这是你的全部工作——看这些标签,忽略其他内容): | 标签 | 含义 | 你该怎么做 | |-----|-------|-------------| | **CONFIRMED** | 多个 agent 发现了它,并根据代码验证了它 | 修复它 | | **UNIQUE** | 单个 agent 发现了它,经过交叉核对后成立 | 修复它——高价值信号 | | **DISPUTED** | agent 之间存在分歧;gossipcat 重新检查了代码 | 相信裁决结果 | | **UNVERIFIED** | 看起来像真的,但尚未经过交叉核对 | 扫一眼,然后手动验证 |
## 工作原理 ``` flowchart LR A([agent review]) -->|cites file:line| B([peer cross-review]) B -->|verifies against code| C{verdict} C -->|confirmed| D[reward signal] C -->|hallucination| E[penalty signal] D --> F[competency score] E --> F F -->|steer dispatch| G([next agent pick]) E -->|≥3 in category| H[auto-generate skill] H -->|inject into prompt| A G --> A style A fill:#0ea5e9,stroke:#0369a1,color:#fff style H fill:#f59e0b,stroke:#b45309,color:#fff style D fill:#10b981,stroke:#047857,color:#fff style E fill:#ef4444,stroke:#b91c1c,color:#fff ``` | 步骤 | 发生了什么 | |------|-------------| | **分发** | 任务根据*分发权重*路由给 agent——即每个 agent 在该类目下测量出的准确率 | | **并行审查** | agent 独立工作,各自生成带有引用 `file:line` 的审查发现 | | **交叉审查** | 每个 agent 根据真实代码检查 peer 的发现:同意、不同意、未验证或提出新发现 | | **共识** | 发现的问题经过去重并打上标签 CONFIRMED / DISPUTED / UNVERIFIED / UNIQUE | | **信号** | 已验证的发现(以及被捕捉到的幻觉)成为更新准确率评分的*奖励信号* | | **技能发展** | 如果某个 agent 屡次犯同一类错误,系统会为其生成一个*技能文件*——这是从其自身的失败历史中自动生成的针对性指令——并注入到未来的 prompt 中 | 奖励信号**基于你的源代码,而不是来自判定模型的主观意见。** 每一个发现都引用了真实的 `file:line`;peer 会机械化地验证这些引用。正是这种基准事实让这个闭环足够值得信任,从而实现自动化。所谓的“策略更新”其实是 `.gossip/agents/
## 原生 vs 中继 agent 每个 agent 都有一个 **类型**(运行在哪里)和一个 **预设**(初始具备什么技能——`reviewer`、`implementer`、`researcher` 等)。你可以随意组合它们;由原生审查者和中继研究者组成的团队是非常正常的。 | | Native(原生) | Relay(中继) | |---|---|---| | **运行方式** | 宿主子 agent —— Claude Code 的 `Agent()` / Cursor 的 `Task()` | 中继服务器上的 WebSocket worker | | **提供商** | 你的 Claude Code / Cursor 订阅——**无需 API key** | Google (Gemini)、OpenAI、xAI (Grok)、DeepSeek、OpenClaw、Ollama、任何兼容 OpenAI 的 endpoint | | **API key** | 无需 | 每个 provider 必须提供 | | **定义位置** | `.claude/agents/
## Gossipcat 的对比优势 | | 你能得到什么 | 过滤幻觉 | 随时间改进 | |---|---|---|---| | **Gossipcat** | 3 个以上的 agent 交叉审查彼此的发现;仅提供已确认的 bug | **是**——peer 会机械地捕捉并对幻觉进行惩罚 | **是**——准确率信号引导分发;技能文件修复重复出现的错误 | | **单 agent 审查**(Claude Code / Cursor 内置) | 一个模型审查你的 diff | 否——幻觉会作为发现被推送给你 | 无反馈闭环 | | **模型评价模型审查** | 一个模型给另一个模型的输出打分 | 部分有效——判定模型也会产生幻觉;且缺乏基准事实 | 评分未与分发机制挂钩 | | **模式匹配工具**(lint 风格的 PR 机器人) | 规则匹配 + 一次 LLM 过程 | 否 | 否 | 区别在于:gossipcat 会根据*你的*代码库中实际的 `file:line` 引用来验证发现。这种基准事实使得奖励信号足够值得信任,从而实现自动化。
| Runs in | Full support |
Full support |
Windsurf Planned |
VS Code Planned |
Agent() and Cursor Task(). Other MCP hosts work in relay-only mode (no native subagents).
## 快速开始 **环境要求:** Node.js 22+ 以及以下任一宿主环境。Claude Code 和 Cursor 是完全平等的一等宿主环境——选择你平时用的那个即可;Gossipcat 会自动检测它,并以任一方式运行原生 agent。 **最快途径(skills CLI):** 一条命令即可安装 server 并引导你完成设置: ``` npx skills add gossipcat-ai/gossipcat-ai ``` 这会将一个安装程序技能放入 `.claude/skills/`;你的 agent 会运行安装,然后将其移交给 `gossip_status()` 以获取实时规则。如果你使用 [skills](https://github.com/vercel-labs/skills) CLI,请优先使用此方法,而不是下面的手动步骤。接下来会说明手动 npm install 的方法。 安装一次该包: ``` npm install -g gossipcat ```
| Claude Code | Cursor |
|---|---|
| 注册 MCP server: ``` claude mcp add gossipcat -s user -- gossipcat ``` 重启 Claude Code。原生 agent 将通过 `Agent()` 进行调度分发。 | 添加到 `.cursor/mcp.json`: ``` { "mcpServers": { "gossipcat": { "command": "gossipcat" } } } ``` 重新加载 Cursor。原生 agent 将通过 `Task()` 进行调度分发。 |
手动配置 MCP / 替代安装路径
添加到 `~/.claude/mcp_settings.json` (Claude Code) 或项目本地的 `.mcp.json`: ``` { "mcpServers": { "gossipcat": { "command": "npx", "args": ["gossipcat"] } } } ``` ``` # 固定到版本 npm install -g gossipcat@0.6.5 # 固定到 GitHub release tarball(绕过 npm registry) npm install -g https://github.com/gossipcat-ai/gossipcat-ai/releases/download/v0.6.5/gossipcat-0.6.5.tgz # 项目级(postinstall 会写入 .mcp.json — 在该处打开 IDE,无需 `mcp add`) cd your-project && npm install --save-dev gossipcat # 从 source 构建(贡献者) git clone https://github.com/gossipcat-ai/gossipcat-ai.git && cd gossipcat-ai npm install && npm run build:mcp claude mcp add gossipcat -s user -- node "$PWD/dist-mcp/mcp-server.js" ``` 该安装包内置了 MCP server 二进制文件、预构建的仪表盘(`dist-dashboard/`,在动态端口上启动)、捆绑的技能模板 + 规则 + 项目原型,以及一个会写入带有正确绝对路径的 `.mcp.json` 的安装后向导。 **升级:** `npm install -g gossipcat@latest`,或者在会话中询问 *“检查 gossipcat 更新”*(`gossip_update` 工具会在你确认后应用更新)。## 首次运行 从“刚刚安装”到“首次获得有效审查”的最快途径。 **1 · 在项目中打开你的 IDE 并进行一次引导。** 在 Claude Code 或 Cursor 中,运行: 这会将 gossipcat 的操作规则加载到会话中,首次运行时创建 `.gossip/` 目录,并打印仪表盘 URL + 认证密钥: ``` Status: Host: claude-code (native agents supported) ← which IDE you're in Relay: running :49664 ← background server for agents + dashboard Workers: 0 ← agents busy right now (rises during a round) Dashboard: http://localhost:49664/dashboard (key: c3208820…) ← open it, paste the key Quota: google — OK ← provider rate-limit status (falls back to native on cooldown) ``` 打开仪表盘 URL,粘贴密钥(它每次启动都会轮换——重新运行 `gossip_status` 获取新密钥)。 **2 · 创建你的第一个团队。** 告诉调度器你正在构建什么: 它会根据你的技术栈提议一个匹配的团队。**最小可运行团队:`sonnet-reviewer` + `haiku-researcher`——全都是原生的,零 API 密钥。** 移除任何你没有 provider 密钥的中继 agent;以后可以再添加。原生 agent(`native: true`)使用你的订阅运行。确认后,就会生成 `.gossip/config.json`。 **3 · 运行你的第一次审查**,在一个包含某些改动的项目中: | 阶段 | 时间 | 你会看到什么 | |---|---|---| | 分解 | ~1秒 | 调度器选择 agent,并行分发任务 | | 独立审查 | 30秒–2分钟 | 每个 agent 阅读你的 diff 并报告发现 | | 交叉审查 | 30秒–1分钟 | 每个 agent 对照代码检查其他人的发现 | | 共识报告 | <1秒 | 发现的问题被标记为 CONFIRMED / DISPUTED / UNVERIFIED / UNIQUE | | 验证 + 记录 | <1秒 | UNVERIFIED 的问题经过代码验证;准确率信号被保存 | ``` Consensus round b81956b2-e0fa4ea4 — 3 agents CONFIRMED (2): [critical] Race condition in tasks Map at server.ts:47 — sonnet + gemini [high] Missing auth on WebSocket upgrade at server.ts:112 — sonnet + gemini UNIQUE (1): [medium] String concat in SQL query at queries.ts:88 — only sonnet caught this DISPUTED (1): [low] "Memory leak in timer" — haiku says yes, sonnet/gemini say no → verified: not a leak, cleanup is in finally. False alarm caught. Final: 3 real bugs to fix, 1 false alarm caught by cross-review. ``` 处理那些标记为 **CONFIRMED** 以及已验证的 **UNIQUE** 的问题。那个在交叉审查中被过滤掉的误报,正是原本单个审查者会推给你的“bug”。
## 日常使用指南 每个方案:输入什么,得到什么,如何处理。 **提交前审查 diff** → *“审查我暂存的更改。”* 1-3 分钟内出具共识报告;修复标记为 CONFIRMED 和已验证的发现。对于少于 20 行的 diff,跳过共识——让 `gossip_run` 使用单个快速 agent(约 10 秒)以节省一轮时间。 **安全问题** → *“对 `lib/stripe/webhook.ts` 进行安全审计。”* 每个 security agent 会从不同的角度(OWASP、验证、身份验证、密钥)进行审查;真正的漏洞能在交叉审查中幸存,而理论性的漏洞会被剔除。要具体指定文件——“审计整个代码库”范围太大了。 **在修改代码前先理解它** → *“在我动手之前,先研究一下 WebSocket 生命周期是如何工作的。”* 一个 researcher agent 会追踪调用路径并将摘要写入其认知记忆中,这样下次它就能记住——无需重复探索的成本。 **验证你自己的假设** → *“我觉得 server.ts:47 处的 tasks Map 存在竞态条件——检查一下我是否正确。”* 两个 agent 独立确认或反驳。作者的自我审查往往过于乐观;但这套机制不会。 **查看你可以信任哪些 agent** → *“给我看看 agent 的评分。”* 按类目的准确率 + 分发权重。如果 `gemini-reviewer` 在 `concurrency`(并发)上的得分只有 30%,就不要单独信任它的并发问题发现。 **改善陷入困境的 agent** → *“gemini-reviewer 总是凭空捏造并发问题——为它开发一个技能。”* Gossipcat 会从其失败数据中生成一项针对性的技能,并测量其是否有效(对绑定后的信号进行 z-test)。然后就会自动生效。
## 阅读仪表盘 使用来自 `gossip_status` 的密钥打开一次;工作时保持该标签页打开。每一次工具调用都会推送实时的 WebSocket 更新。
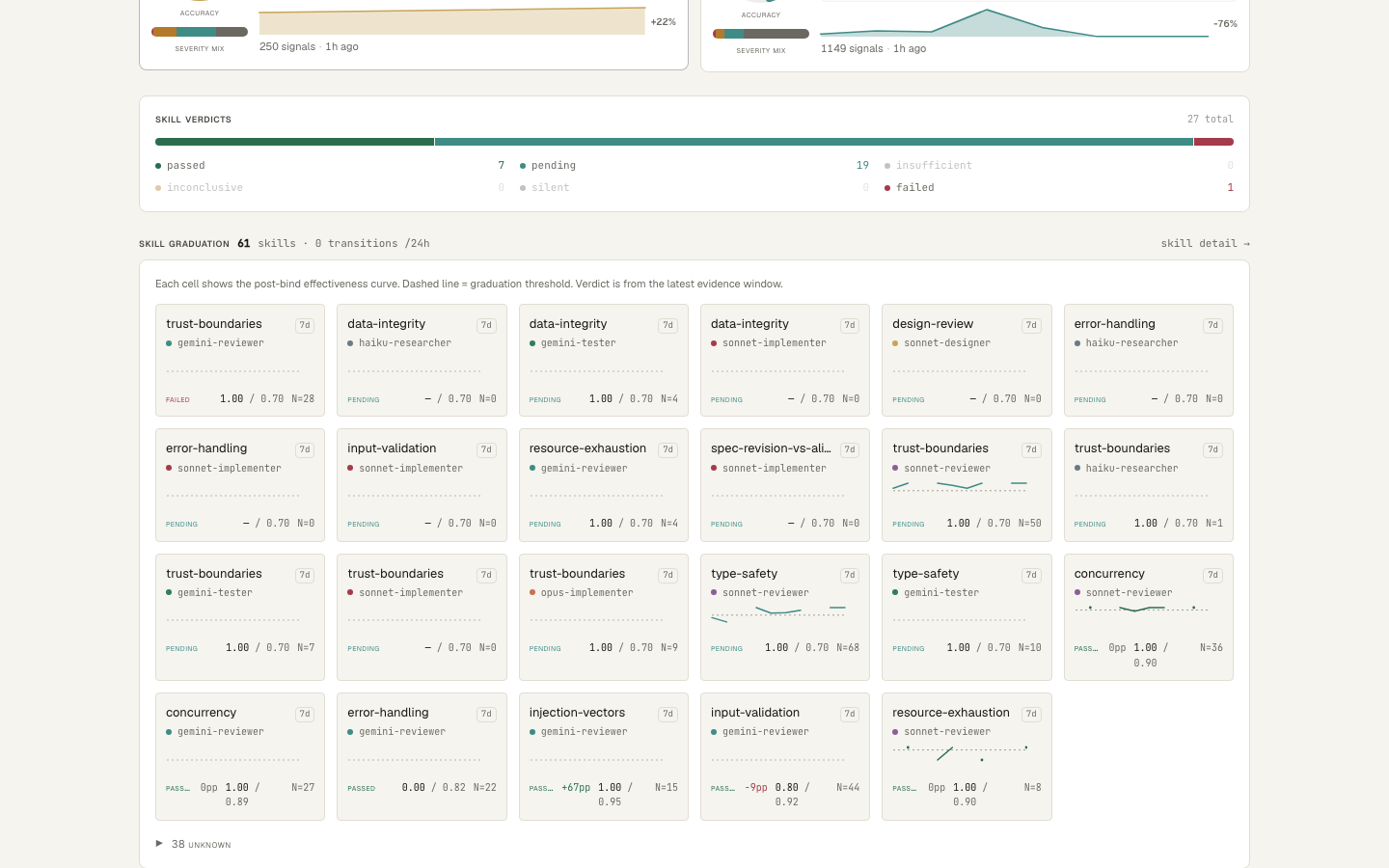
Skill-graduation grid — each card is one (skill × agent): post-bind effectiveness over a 7-day window vs threshold, with ±pp drift on graduated skills.
| 面板 | 显示内容 | |---|---| | **Overview** | 活跃的 agent、分发权重、近期发现统计 | | **Team** | 按可靠性排序的 agent,附带按类目划分的明细 | | **Tasks** | 实时 + 历史任务,包含 agent、持续时间、状态 | | **Findings** | 按轮次划分的共识报告,CONFIRMED/DISPUTED/UNVERIFIED 的明细 | | **Agent detail** | 每个 agent 的记忆、技能、评分历史、任务历史 | | **Signals** | 原始信号流(agreement / hallucination / unique_confirmed) | | **Chat** | 指向调度器的实时双向桥接(见下文) | | **Logs** | `mcp.log`(启动、错误、警告) |## 从浏览器控制 仪表盘的 **Chat** 页面是一个实时、双向的桥梁,直通正在运行的调度器——从浏览器输入,你的消息就会进入活动会话;调度器的分发、发现和回复也会实时镜像回同一个对话线程中。 | 功能 | 它能做什么 | |---|---| | **多会话标签页** | 并排开启多个独立的线程——每个线程拥有自己的 `chat_id`、历史记录和实时流;支持每个标签页的未读提示,并在重新加载后保持持久化 | | **可重命名的标签页** | 双击或按 **F2** 为标签页命名(“auth 重构”、“性能审计”)——重载后依然保留 | | **工作中的 agent 轨道** | 实时显示当前谁被分发并正在工作的轨道——无需离开聊天界面即可观察一轮任务的进展 | | **结构化问题** | 当调度器需要决策时,`gossip_ask` 会在聊天中直接渲染单选/多选卡片;你的选择会像正常对话一样流转回去 | `gossip_ask` 的答案边界是失败关闭的:只接受已知的选项,“其他”自由文本在到达调度器之前会被净化处理,因此来自仪表盘的回答无法将恶意指令偷偷带入会话中。使用 `gossipcat code` 包装器启动(或要求调度器启用 channel 模式),然后打开 **Chat** 标签页。
## 宿主兼容性 Gossipcat 会自动检测宿主环境,并调整分发方式及其写入的规则文件。 | 宿主 | 原生 agent | 规则文件 | |------|---------------|------------| | **Claude Code** | 是—— `Agent()` | `.claude/rules/gossipcat.md` | | **Cursor** | 是—— `Task(subagent_type, model, …)` | `.cursor/rules/gossipcat.mdc` | | Windsurf | 仅限中继(计划中) | `.windsurfrules` | | VS Code | 仅限中继(计划中) | — | 在 Claude Code 和 Cursor 上,原生 agent 无需 API 密钥即可运行,并完全参与共识。其他 MCP 宿主仍然可以运行中继 agent。
## 故障排除 **仪表盘提示 unauthorized / 401** —— 密钥每次启动都会轮换。运行 `gossip_status` 获取当前密钥。 **仪表盘 URL 无法加载** —— 检查 `.gossip/mcp.log` 中包含 `🌐 Dashboard:` 的那一行(真实端口)。如果缺失,说明中继未启动:从崩溃的启动中删除陈旧的 `.gossip/relay.pid` 并重新启动,或者如果 `GOSSIPCAT_PORT` 被占用则将其释放。 **Agent 返回空的发现** —— 通常是配额问题。`gossip_status` 会显示 `Quota:
## 配置 `.gossip/config.json` 的大部分内容**由 `gossip_setup()` 自动生成**——只有在你需要更改 provider/model/endpoint 时才需手动编辑。对于大多数项目,首次运行的默认设置即可使用。配置的查找顺序为:`.gossip/config.json` → `gossip.agents.json` → `gossip.agents.yaml`。 ``` { "main_agent": { "provider": "google", "model": "gemini-2.5-pro" }, "utility_model": { "provider": "native", "model": "haiku" }, "consensus_judge": { "provider": "anthropic", "model": "claude-sonnet-4-6", "native": true }, "agents": { "sonnet-reviewer": { "provider": "anthropic", "model": "claude-sonnet-4-6", "preset": "reviewer", "skills": ["code_review", "security_audit", "typescript"], "native": true } } } ``` | 字段 | 描述 | |-------|-------------| | `main_agent` | 用于路由、规划、合成的内部 LLM(在 Claude Code / Cursor 上设置 `provider: "none"` 可让宿主原生进行分类) | | `utility_model` | 记忆压缩、gossip、lens 生成 | | `consensus_judge` | 仅用于合并交叉审查结果的合成模型(不进行打分) | | `agents.
OpenClaw 🦞(本地网关 provider)
[OpenClaw](https://github.com/openclaw/openclaw) 在本地运行并暴露出兼容 OpenAI 的 API;gossipcat 像对待任何中继 agent 一样与它通信,它拥有独立的配额槽,因此其速率限制不会影响到你的 OpenAI agent。只需存储一次网关令牌(macOS:`security add-generic-password -s gossip-mesh -a openclaw -w## MCP 工具 调度器(Claude Code / Cursor)会根据你的自然语言请求自动选择并调用这些工具——你无需手动调用它们。 | 工具 | 用途 | |------|---------| | `gossip_status` | 系统状态、仪表盘 URL、agent 列表 | | `gossip_setup` | 创建或更新 agent 团队 | | `gossip_run` | 带有自动选择 agent 功能的单 agent 分发 | | `gossip_dispatch` | 多 agent 分发:`single`、`parallel` 或 `consensus` | | `gossip_collect` | 收集结果,支持可选的交叉审查合成 | | `gossip_plan` | 将任务分解为带有 agent 分配的子任务 | | `gossip_signals` | 记录或撤销准确率信号 | | `gossip_scores` | 查看 agent 准确率、独特性、分发权重 | | `gossip_skills` | 开发、绑定、解绑或列出每个 agent 的技能 | | `gossip_resolve_findings` | 将共识发现标记为已解决/未解决 | | `gossip_remember` | 搜索 agent 的认知记忆 | | `gossip_verify_memory` | 在处理积压任务之前,根据当前代码检查记忆声明(FRESH / STALE / CONTRADICTED) | | `gossip_session_save` | 为下一次会话保存会话上下文 | | `gossip_progress` | 检查进行中的任务状态 | | `gossip_watch` | 在 agent 发出信号时进行流式传输(可捕捉一轮任务期间的流水线丢弃事件) | | `gossip_ask` | 向仪表盘提出结构化的单选/多选问题 | | `gossip_guide` | 打印面向人类的 gossipcat 手册 | | `gossip_config` | 管理运行时功能开关 | | `gossip_format` | 返回规范的 `
## 架构 ``` gossipcat/ apps/cli/ MCP server, host-aware native agent bridge, boot sequence packages/ orchestrator/ Dispatch pipeline, consensus engine, memory, skills, performance scoring, task graph, prompt assembly relay/ WebSocket relay server, dashboard REST/WS API dashboard-v2/ React + Vite + shadcn/ui frontend (warm-cream theme — see DESIGN.md) client/ Lightweight WebSocket client for relay connections tools/ File / shell / git tool implementations for worker agents types/ Shared TypeScript types and message protocol ``` 仪表盘预构建在 `dist-dashboard/` 中,由中继作为静态文件提供服务;可以使用 `npm run build:dashboard` 从源码重新构建。
## 路线图 已完成的工作记录在 [CHANGELOG.md](CHANGELOG.md) 和 [GitHub Releases](https://github.com/gossipcat-ai/gossipcat-ai/releases) 中。接下来的计划: | 功能 | 状态 | |---------|--------| | 仪表盘内容扩充(图表、趋势、会话历史) | ☐ 计划中 | | 本地 Postgres 迁(任务/信号/共识/记忆——完整的任务结果,真实查询,取消 JSONL 扫描) | ☐ 计划中 | | Windsurf / VS Code 原生功能对齐 | ☐ 计划中 | | 独立 CLI(无需 IDE)+ 聊天模式流水线对齐 | ☐ 计划中 |
## 贡献 Gossipcat 是开源项目,目前处于早期阶段——欢迎提交 bug 报告、想法和 PR。 - **Bug / 新功能** → [提交 issue](https://github.com/gossipcat-ai/gossipcat-ai/issues),或者让 Claude Code *“提交一个关于……的 gossipcat bug 报告”*(`gossip_bug_feedback` 会发布结构化的 issue)。 - **Pull Request** → fork 仓库,新建分支,向 `master` 提交 PR。请先运行 `npm test`。请遵循约定式提交规范(`fix:`、`feat:`、`chore:`、`docs:`)。发布流程和贡献者设置详见 [CONTRIBUTING.md](CONTRIBUTING.md)。 - **讨论** → [GitHub Discussions](https://github.com/gossipcat-ai/gossipcat-ai/discussions)。 [`CLAUDE.md`](CLAUDE.md) 记录了 gossipcat 自身的 agent 在开发过程中遵循的操作规则——对于从内部理解信号流水线和共识工作流来说,是一份很有价值的阅读材料。
## Star 历史
标签:AI编程助手, MCP, SOC Prime, 代码审查, 代码质量, 多智能体, 开发工具, 自动化攻击