nitsuah/agent-board
GitHub: nitsuah/agent-board
一款本地优先的多模型 AI 运维控制台,集成安全防护、可观测性面板和容器监控,让用户无需外部 API 即可安全运行和评估大模型。
Stars: 1 | Forks: 0
# Agent Board - 本地 AI 运维控制台
Agent Board 是一个多模型 AI 工作流的本地优先控制中心。它为您集成了聊天界面、安全防护和实时可观测性,让您无需将数据发送到外部 API 即可运行和评估模型行为。
## 为什么选择 Agent Board
- **更快地交付更安全的 prompt**:内置输入分类、prompt 注入检查、屏蔽输入处理和输出净化。
- **运行多种体验**:通过服务器强制执行的路由和安全策略,在开发者助手、研究模式和安全聊天之间切换。
- **实时观测一切**:指标仪表板、WebSocket 事件流,以及通过 OpenTelemetry 追踪到 Jaeger。
- **保持本地优先**:设计为使用 Docker 在您自己的机器上运行。
## 产品亮点
- **体验感知会话**:包含用户上下文、角色元数据和完整消息历史的持久会话。
- **安全层**:PII 检测/脱敏、有害内容过滤,以及针对敏感工作流的严格模式处理。
- **模型路由**:主 Ollama 端点、Docker Model Runner 端点和服务器端端点限制。
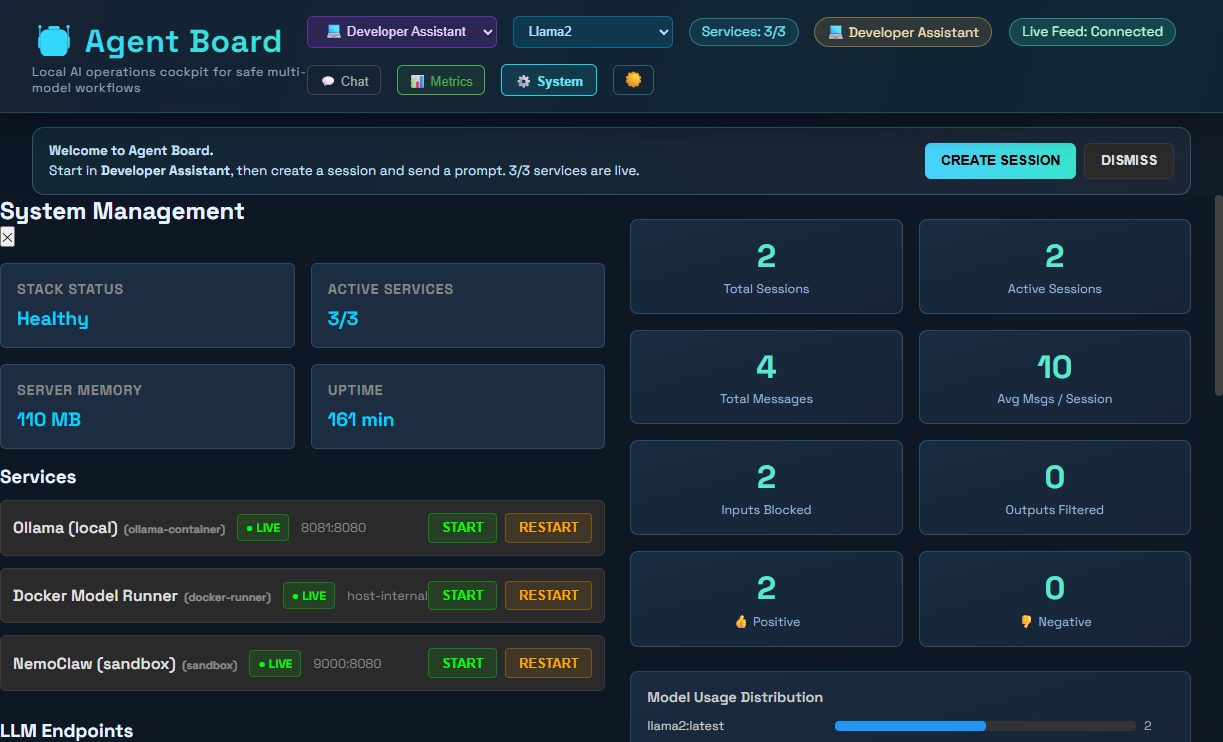
- **运维 UI**:深色和浅色主题、系统面板控制、实时容器状态以及端点健康状态可见性。
- **可观测性技术栈**:指标 API、事件总线、持久化状态、追踪状态和 Jaeger 集成。
## 截图
截取自本地 Docker 技术栈 `http://localhost:3000`。
### 仪表板概览
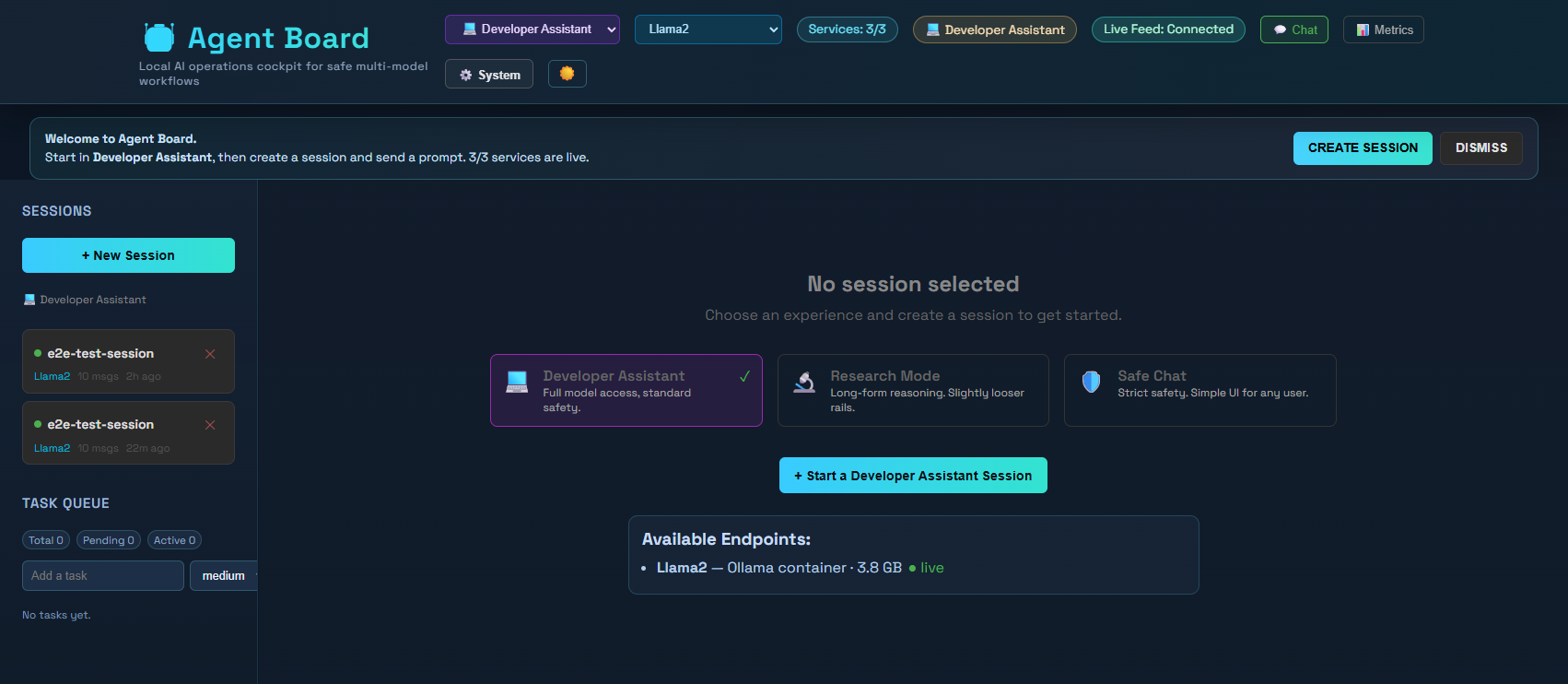
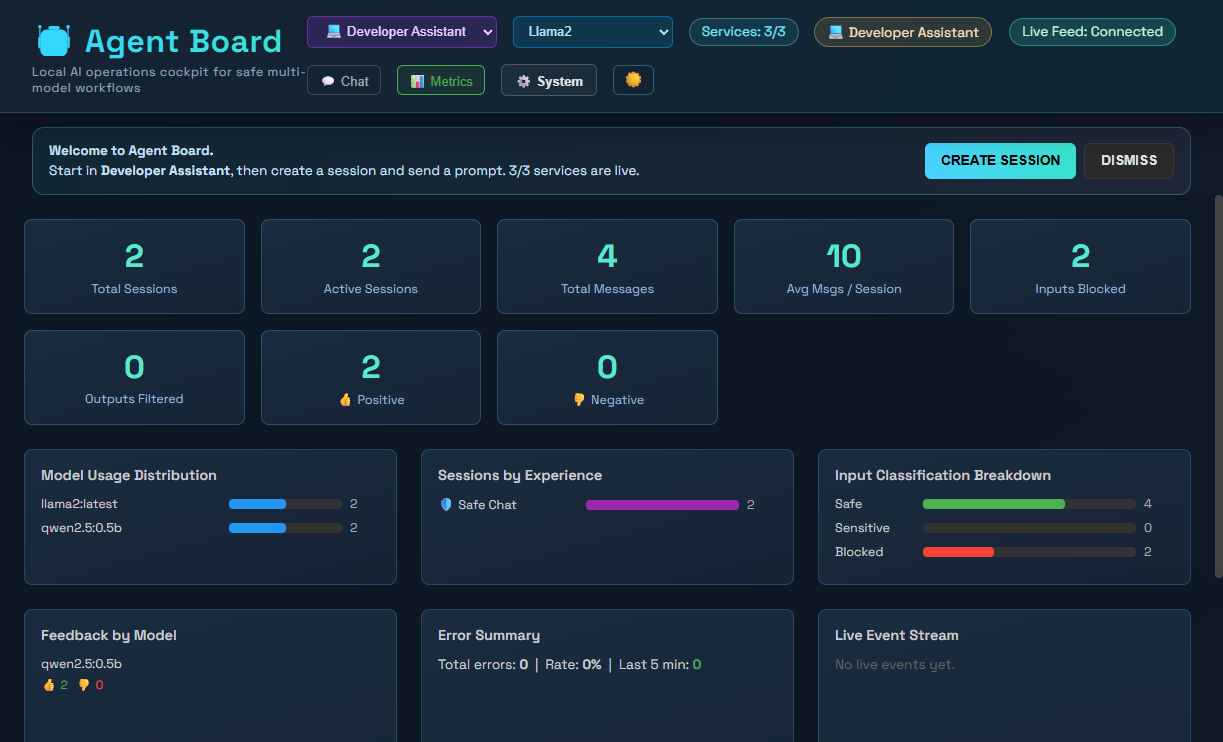
### 指标视图
### 系统管理
## 快速开始
```
cd C:\Users\$env:USERNAME\code\agent-board
docker compose -f config/docker-compose.yml up -d
```
仅在需要时启用 Blackboard MCP:
```
$env:BB_MCP_ENABLED='true'
docker compose -f config/docker-compose.yml --profile bb-mcp up -d
```
打开以下端点:
- 仪表板:http://localhost:3000
- Jaeger UI:http://localhost:16686
- Ollama API:http://localhost:8081
- NemoClaw:http://localhost:9000(目前在 Windows 构建上会不断崩溃重启 — 参见 TASKS.md 中的“Unblock NemoClaw sandbox container”)
- OpenLLM API(可选,参见 [OpenLLM(可选)](#openllm-optional)):http://localhost:8082
## 两分钟内能做什么
1. 打开仪表板并创建一个新会话。
2. 选择一种体验(开发者、研究或安全聊天)。
3. 发送一个正常的 prompt,然后再发送一个故意不安全的 prompt 以查看安全拦截。
4. 打开“指标”选项卡以检查安全和反馈遥测数据。
5. 查看 Jaeger 以观察关键路径上的请求追踪。
## 功能
- **多模型支持**:Llama2、Qwen3-Coder (Ollama)、Docker Model Runner、GLM-Flash、OpenLLM(可选)
- **Agent 会话**:具有完整消息历史的持久会话管理
- **安全沙盒**:集成 NemoClaw 以实现策略强制执行的安全模式
- **体验模式**:每种体验具有服务器强制执行的端点和安全规则
- **指标仪表板**:摘要、安全、反馈和错误遥测
- **Web 仪表板**:React UI,具有实时 Docker 状态监控
- **OpenTelemetry 追踪**:通过 OTLP/HTTP 导出到 Jaeger,并带有平滑回退
- **即时模型切换**:每个会话可在对话中途切换端点
## 目录结构
```
dashboard/ # Web UI & API server (React + Express)
src/ # React frontend
tests/ # Integration tests
Dockerfile
config/ # Stack config and model manifests
docker-compose.yml # Stack definition
model-manifest.json # Model loading config
connectors.json # Connector config
llm/ # Model configs / Modelfiles (future)
services/ # Additional microservices (future)
scripts/ # Setup & management scripts
```
## 模型与选择性加载
模型在启动时根据 `config/model-manifest.json` 文件加载。只有列在 `enabled` 数组中的模型才会被加载。默认情况下,为了最小化内存占用,仅启用 `llama2:latest`。
要启用其他模型:
1. 在您的 Ollama 容器中拉取模型(例如 `docker exec ollama ollama pull qwen3-coder:latest`)。
2. 将模型名称添加到 `config/model-manifest.json` 的 `enabled` 数组中。
3. 重启技术栈。
**`config/model-manifest.json` 示例:**
```
{
"default": "llama2:latest",
"enabled": [
"llama2:latest",
"qwen3-coder:latest"
]
}
```
| 模型 | 大小 | 用途 |
|---|---|---|
| `llama2:latest` | 3.8 GB | 默认 — 通用聊天,适合内存大小 |
| `qwen3-coder:latest` | 18 GB | 代码生成(需要约 18 GB 可用内存) |
| `qwen3:latest` | 5.2 GB | 通用(MoE,在 runtime 加载时为 17.7 GB) |
拉取其他模型:
```
docker exec ollama ollama pull llama3.2:latest # 2 GB, good general model
docker exec ollama ollama pull qwen3:1.7b # 1.4 GB, small but capable
```
### Docker Model Runner(可选)
Docker Desktop 内置的 model runner 也作为一个端点(`docker_runner`)接入了。要启用它:
1. Docker Desktop → Settings → Features in development → **Enable Docker Model Runner** + **Host-side TCP support**
2. 在仪表板侧边栏中选择“Docker Runner”
### OpenLLM(可选)
[OpenLLM](https://github.com/bentoml/OpenLLM) 是第二个兼容 OpenAI 的端点(`openllm`),用于运行不适合 Ollama Modelfile 模式的自定义或微调 HuggingFace 模型 — 它与 Ollama 并行运行,而不是替代它。它是可选的,并受 `openllm` compose profile 控制,因此默认情况下从不启动。要启用它:
1. 在 `.env` 中将 `OPENLLM_MODEL` 设置为 HuggingFace 模型仓库 ID(例如 `HuggingFaceTB/SmolLM2-1.7B-Instruct`),并将 `OPENLLM_ENABLED=true`。
2. 启动服务:
docker compose -f config/docker-compose.yml --profile openllm up -d llm_openllm
3. 在仪表板侧边栏中(开发者或研究体验)选择“OpenLLM”。
该容器在内部使用端口 `3000`(主机上为 `http://localhost:8082`),并将模型权重缓存在 `openllm_data` 卷中。
### 工具体验:Content Studio 和 Website Agent(可选)
`tools/` 下的两个 MCP 工具服务器作为可选的**体验**接入:在侧边栏选择
🎬 **Content Studio** 或 🌐 **Website Agent**,聊天会话将与
一个工具工作台面板配对,该面板会列出服务器的 MCP 工具并执行它们
(表单根据每个工具的输入 schema 生成)。
- **Content Studio**(`tools/content-gen`,端口 3200)封装了 MoneyPrinterTurbo 用于 AI
短视频生成(`generate_video`、`get_video_status`、容器控制)。
- **Website Agent**(`tools/website`,端口 3201)驱动 B2B 网站工作流:
`discover_leads`、`save_file`/`read_file`、`deploy_site` (Netlify)、`create_invoice`。
两者都受 `tools` compose profile 控制:
```
docker compose -f config/docker-compose.yml --project-directory . --profile tools up -d --build tool-content-gen tool-website
```
如果工具服务器处于离线状态,工作台会显示确切的启动命令(当 `AGENT_BOARD_ENABLE_DOCKER_CONTROL=true` 时,还会显示一个启动
按钮)。仪表板通过 `POST /api/tools/:toolKey/call` 与
服务器通信,该接口通过 Streamable HTTP 代理 MCP 的 `tools/call` — 浏览器中
无需 MCP 客户端。
### Docker 控制和模型拉取(可选)
默认情况下,仪表板容器没有 Docker CLI 和 socket 访问权限,因此
服务面板可以显示状态,但启动/停止/重启按钮和模型
面板的拉取按钮会返回 501 错误,说明如何在
主机上运行等效的命令。要让仪表板真正控制技术栈,请应用
`docker-compose.docker-control.yml` 覆盖文件:
```
docker compose -f config/docker-compose.yml -f config/docker-compose.docker-control.yml `
--project-directory . up -d --build agent-dashboard
```
这会构建一个安装了 Docker CLI 的仪表板,以读写方式挂载主机 Docker socket,
并设置 `AGENT_BOARD_ENABLE_DOCKER_CONTROL=true`。挂载 Docker
socket 赋予了仪表板容器对主机 Docker daemon 的 root 级控制权 — 请
仅在受信任的本地/开发环境中使用此覆盖文件。
应用覆盖文件后:
- **服务**面板的启动/停止/重启按钮将运行真实的
`docker compose up -d|stop|restart ` 命令。
- **模型**面板的拉取按钮将为每个 LLM
端点下载已配置的模型 — `primary` 端点使用 `ollama pull`(流式传输,带实时进度),
Docker Model Runner 端点(`docker_runner`、
`glm_flash`)使用 `docker model pull`。
## API
### 会话
- `POST /api/sessions` — 创建会话 (`{ endpoint, model, name, userId, userRole, experience, safetyMode }`)
- `GET /api/sessions` — 列出所有会话
- `GET /api/sessions/:id` — 获取包含消息的会话
- `DELETE /api/sessions/:id` — 删除会话
- `PUT /api/sessions/:id/model` — 切换模型/端点 (`{ endpoint, model }`)
- `POST /api/sessions/:id/feedback` — 记录对助手消息的点赞/点踩 (`{ messageIndex, positive }`)
### 消息
- `POST /api/sessions/:id/message` — 发送消息 (`{ message, useSafeMode }`)
### 产品接口
- `GET /api/experiences` — 列出可用的体验配置
- `GET /api/tools` — 工具服务器可达性 (content_gen, website)
- `GET /api/tools/:toolKey/tools` — 列出工具服务器的 MCP 工具
- `POST /api/tools/:toolKey/call` — 执行 MCP 工具 (`{ name, arguments }`)
- `GET /api/metrics/summary` — 会话/消息总数、模型分布、体验分布
- `GET /api/metrics/safety` — 输入分类、被阻止的 prompt、被过滤的输出
- `GET /api/metrics/feedback` — 按模型和体验区分的正面/负面反馈
- `GET /api/metrics/errors` — 错误率和近期故障
### 系统
- `GET /api/health` — 健康检查(LLM 端点 + Docker 状态)
- `GET /api/models` — 来自所有端点的可用模型
- `GET /api/docker/status` — 容器状态(包含 `endpoints[*].modelInstalled`/`modelLoaded`)
- `GET /api/system/services` — 服务发现目录(已解析的 URL、候选者、可控性)
- `POST /api/system/services/:serviceKey/:action` — 服务操作 API (`start|stop|restart`,受权限控制)
- `POST /api/models/pull` — 为 LLM 端点拉取模型 (`{ endpoint, model? }`,默认为该
端点配置的模型)。Ollama 通过 `/ws/events`
(`model_pull_progress`) 流式传输拉取进度;Docker Model Runner 的拉取(`docker_runner`/`glm_flash`)需要
`AGENT_BOARD_ENABLE_DOCKER_CONTROL=true` 并启用 [docker-control 覆盖文件](#docker-control-and-model-pulls-opt-in)。
- `GET /api/models/pull-status` — 每个 `endpoint:model` 正在进行/最后已知的拉取状态
- `GET /api/persistence/status` — Postgres 持久化状态 (configured/enabled)
- `GET /api/tracing/status` — OpenTelemetry 追踪状态 (enabled/initialized/endpoint)
### 运行时配置
- `PRIMARY_LLM_URL` — 默认的 primary Ollama URL 回退。
- `PRIMARY_LLM_URL_CANDIDATES` — 用于 primary Ollama URL 解析的逗号分隔发现候选者。
- `AGENT_BOARD_ENABLE_DOCKER_CONTROL` — 设为 `true` 以启用服务操作 API 端点。
- `DOCKER_COMPOSE_FILE` — 可选的 compose 文件覆盖,用于服务操作。
- `DOCKER_PROJECT_DIR` — 可选的 compose 项目目录覆盖,用于服务操作。
- `OPENLLM_ENABLED` — 设为 `true` 以将 OpenLLM 端点标记为可从系统面板控制。
- `OPENLLM_MODEL` — `llm_openllm` 容器服务的 HuggingFace 模型仓库 ID。
- `OPENLLM_URL` — 覆盖 OpenLLM 端点 URL(默认为 `http://llm_openllm:3000`)。
- `TOOL_CONTENT_GEN_URL` — 覆盖 content-gen 工具服务器 URL(默认为 `http://tool-content-gen:3200`)。
- `TOOL_WEBSITE_URL` — 覆盖 website 工具服务器 URL(默认为 `http://tool-website:3201`)。
- `TOOL_CALL_TIMEOUT_MS` — MCP 具调用的预算时间(默认为 660000;视频生成速度较慢)。
## 架构
```
dashboard/
├── server.js # Express API — session mgmt, LLM proxy, Docker status
├── src/
│ ├── App.jsx # React frontend
│ ├── App.css # Styles
│ └── main.jsx # Entry point
├── tests/
│ ├── test-chat.js # Integration test (session → message → delete)
│ └── e2e-chat.js
└── Dockerfile
```
## 开发工作流
所有 lint、测试和质量检查都通过 Docker 运行 — 无需本地 Node.js。
**运行单元测试:**
```
docker compose -f config/docker-compose.yml --profile test run --rm test
```
**启动完整技术栈:**
```
docker compose -f config/docker-compose.yml up -d
```
**技术栈管理:**
```
.\scripts\stack-manager.ps1 -Action start
.\scripts\stack-manager.ps1 -Action stop
.\scripts\stack-manager.ps1 -Action status
.\scripts\stack-manager.ps1 -Action logs
```
**Pre-commit 钩子**(为空格/yaml 检查安装 git 钩子;单元测试在 push 时运行):
```
pip install pre-commit
pre-commit install
pre-commit install --hook-type pre-push
```
**集成测试**需要运行中的技术栈(`docker compose up -d`),然后执行:
```
cd dashboard && npm run test:integration
```
## 故障排除
**聊天返回错误 / LLM 无响应**
- 检查 Ollama 是否有模型:`docker exec llm_qwen_coder ollama list`
- 检查内存 — 大型模型(qwen3-coder 18 GB)需要足够的可用内存
- 默认模型是 `llama2:latest`,对于约 8 GB 以上的系统是安全的
**容器不健康**
- `docker logs agent-dashboard` — 服务器错误
- `docker logs llm_qwen_coder` — Ollama 错误(OOM 会显示在这里)
**端口冲突**
- Ollama:`8081` (主机) → `8080` (容器)
- NemoClaw:`9000` → `8080`
- 仪表板:`3000` → `3000`
## GPU 加速 (CUDA/RTX 4080)
要为 Ollama 启用 GPU 加速(推荐用于 RTX 4080 或类似显卡):
1. **安装 NVIDIA 驱动程序** 适用于您的 GPU(推荐使用最新版本)。
2. 在您的主机上**安装 NVIDIA Container Toolkit**:
- https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
3. **更新 Docker Compose** 以将 NVIDIA runtime 用于 Ollama 服务:
- 添加到 `ollama` 服务:
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
- 或者运行:`docker compose --gpus all up`
4. **验证是否检测到 GPU**:
- `docker exec ollama nvidia-smi`
- Ollama 日志应该显示有可用的 CUDA 设备。
5. **记录的模型**:启用 GPU 后,根据需要将更大的模型添加到 `config/model-manifest.json` 中。
**注意:** 如果您有 RTX 4080,您应该会看到约 24 GB 的可用 VRAM。仅在 VRAM 足够的情况下才启用大型模型。
## 生产环境部署
用于生产环境时:
- 使用专门的密钥管理解决方案(不要将密钥提交到 git)。
- 为 Postgres 和任何外部服务设置强密码。
- 为生产环境使用 Docker Compose 覆盖文件(例如 `docker-compose.prod.yml`)。
- 仅将暴露的端口限制在受信任的网络中。
- 在代理或负载均衡器上启用 HTTPS/SSL 终止。
- 监控资源使用情况和日志(Jaeger、仪表板、Ollama、bb-mcp)。
- 定期更新镜像和依赖项。
**生产环境覆盖示例:**
```
services:
agent-dashboard:
environment:
- NODE_ENV=production
- OTEL_ENABLED=true
- OTEL_ENDPOINT=https://jaeger.prod.example.com:4318
ports:
- "127.0.0.1:3000:3000" # Bind to localhost or internal network
```
## 安全与保障
- 所有流量都是本地的 — 没有外部 API 调用
- NemoClaw 使用 `--cap-drop=all` 对 agent 执行进行沙盒化
- Capability 允许列表:仅限 `NET_BIND_SERVICE`
- 在 sandbox 容器上强制执行 `no-new-privileges`
- 安全聊天会话在服务器端被限制为仅使用 primary 端点和严格安全模式
- 输出过滤会脱敏检测到的 PII,并在被阻止的有害响应到达 UI 之前将其替换
## 许可证
MIT
## 社区规范
共享的社区政策集中在 https://github.com/nitsuah/.github:
- 贡献指南:https://github.com/nitsuah/.github/blob/main/CONTRIBUTING.md
- 行为准则:https://github.com/nitsuah/.github/blob/main/CODE_OF_CONDUCT.md
- 安全政策:https://github.com/nitsuah/.github/blob/main/SECURITY.md
标签:AI风险缓解, API集成, 人工智能运维, 可观测性, 多模型对话, 容器监控, 本地大模型, 本地部署, 测试用例, 用户代理, 自定义脚本, 请求拦截