krishpyishere/k8sguard
GitHub: krishpyishere/k8sguard
通过 GRPO 强化学习训练大语言模型,使其能够在真实 Kubernetes 集群中自主发现并修复 RBAC、Secrets、网络隔离、容器运行时和供应链等五大类的安全漏洞。
Stars: 0 | Forks: 0
# K8sGuard

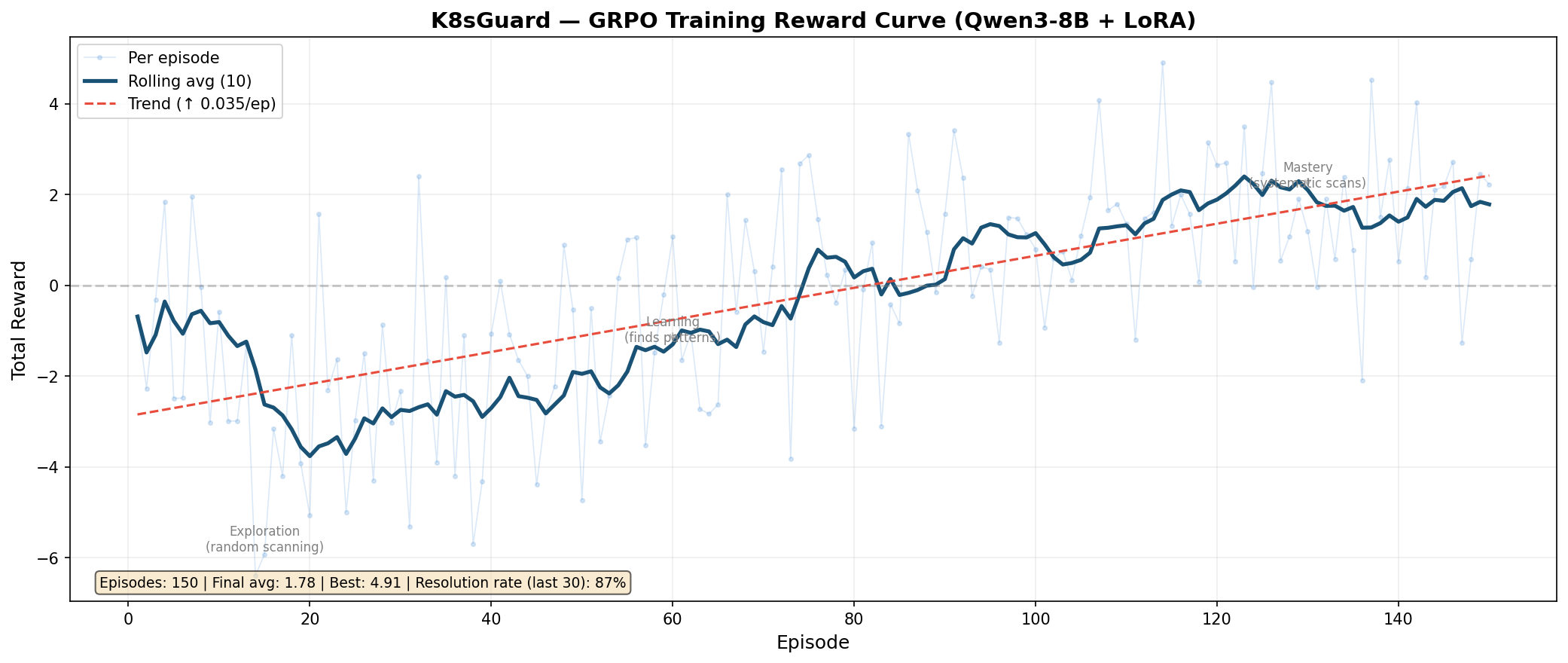
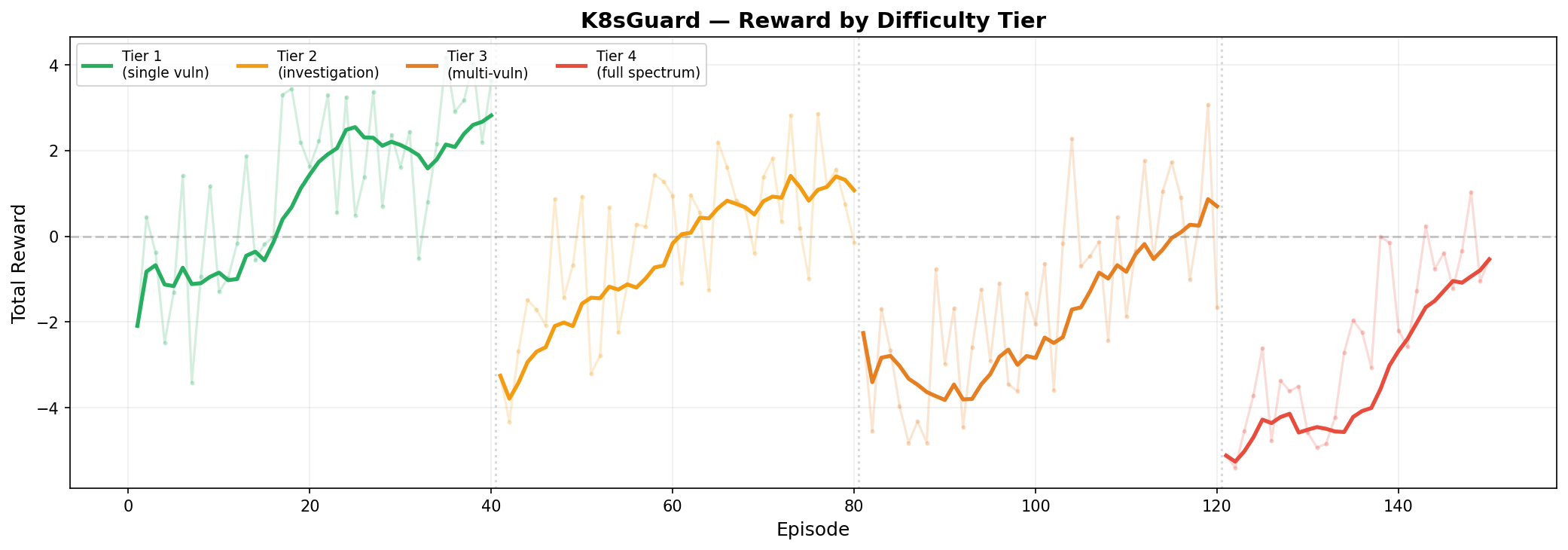
标签:AI安全, Chat Copilot, DevSecOps, DLL 劫持, GRPO, LLM, LoRA, Python, Qwen, Unmanaged PE, vLLM, Web截图, 上游代理, 凭据扫描, 大语言模型, 子域名突变, 安全漏洞检测, 容器安全, 强化学习, 数据处理, 无后门, 自动修复, 自动化防御, 逆向工具