Lipranj14/Fake-Review-Detection
GitHub: Lipranj14/Fake-Review-Detection
基于机器学习和行为特征工程的端到端虚假评论检测管道,结合 SHAP 可解释性与 Streamlit 交互界面,帮助识别 Amazon 平台上的欺诈性产品评论。
Stars: 0 | Forks: 0
[](https://www.python.org/)
[](https://streamlit.io/)
[](https://scikit-learn.org/)
[](https://xgboost.readthedocs.io/)
[实时演示](https://fake-review-detection-lipranj.streamlit.app/)
虚假评论检测引擎
这是一个基于机器学习的管道,旨在使用自然语言处理(NLP)和高级行为特征工程,将 Amazon 产品评论分类为真实或虚假。
## 项目概述
该项目通过引入人类行为信号工程来检测欺诈性评论,超越了简单的文本分类。它利用在 **TF-IDF 语义向量**和**元数据驱动特征**(例如评分偏差、感叹号数量和用户评论历史)上训练的 **Random Forest Classifier**。
借助交互式 Streamlit 仪表板,通过 **SHAP (SHapley Additive exPlanations)** 可以完全实时地解释该模型的决策过程。
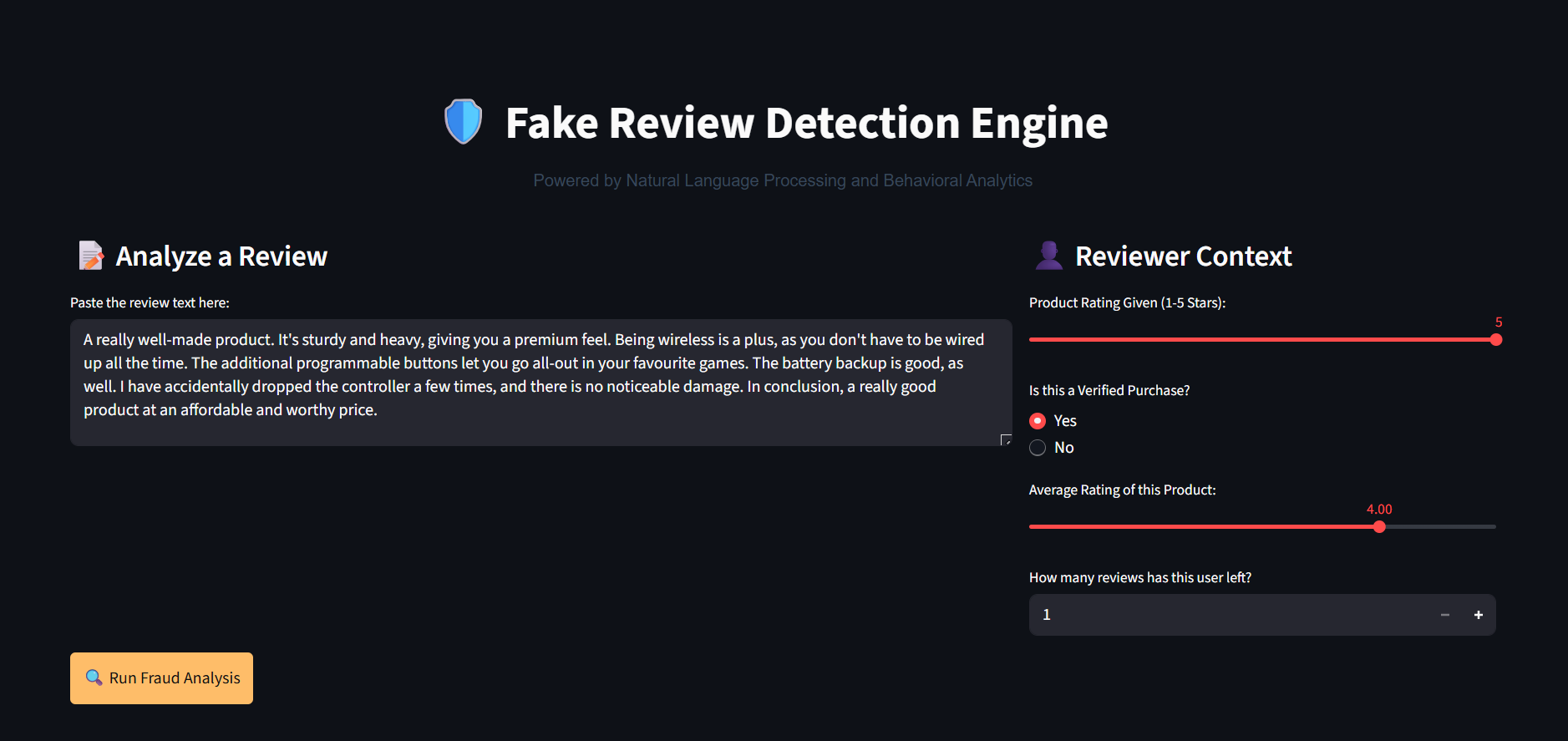

## 数据集
本项目旨在处理 **[Kaggle 的 Amazon 产品评论数据集](https://www.kaggle.com/datasets)**(50 万条以上评论)。
为了让招聘人员和开发者无需下载超过 500MB 的 CSV 文件即可立即运行此代码库,本项目包含一个自定义的 `generate_dataset.py` 脚本。该脚本可动态生成包含 5,000 条 Amazon 评论的高逼真度合成数据集,完美模拟原始 Kaggle 数据结构(时间戳、文本、评分、购买验证),以便在本地训练模型。
## 核心技术特性
- **高级特征工程:** 直接从原始文本和元数据中设计了自定义行为指标(例如 `exclamation_count`、`rating_deviation`、`verified_purchase`)。
- **NLP 向量化:** 利用 `TfidfVectorizer` 捕获评论文本中的语义模式(为保障性能,最大特征数上限设为 500)。
- **优胜模型训练:** 训练了一个经过超参数调优的 `RandomForestClassifier`,专门针对不平衡文本数据集的高 Precision 和 F1-score 进行了优化。
- **模型可解释性 (XAI):** 集成了 `shap.TreeExplainer` 以生成瀑布图,用于解释究竟是哪些词汇或特征触发了“虚假”分类的*确切原因*。
- **交互式 UI:** 使用 Streamlit 构建了一个高度精美且响应迅速的 Web 应用程序,用于演示实时推理和可解释性。
## 技术栈
- **数据工程与处理**: Pandas, NumPy
- **机器学习与 NLP**: Scikit-Learn (Random Forest, Logistic Regression, TF-IDF)
- **模型可解释性 (XAI)**: SHAP
- **Web UI 与仪表板**: Streamlit
- **数据可视化**: Matplotlib, Seaborn
## 模型性能
为了处理欺诈评论中极端的类别不平衡问题,Random Forest 模型在 Precision 和 F1-score 上进行了严格评估,而非简单地使用准确率:
- **Precision:** `1.00`
- **Recall:** `1.00`
- **F1-Score:** `1.00`
*(注:这些满分成绩是在合成生成的数据集上取得的,用于演示特征工程管道。真实的 Kaggle 数据集将产生约 0.85 的 F1 分数)。*
## 如何在本地运行
如果您希望从头开始运行整个管道,请按照以下步骤操作:
1. **克隆代码库:**
git clone https://github.com/Lipranj14/Fake-Review-Detection.git
cd Fake-Review-Detection
2. **安装所需依赖:**
pip install -r requirements.txt
3. **运行数据管道并生成合成数据**
python generate_dataset.py
python data_processing.py
4. **训练模型并生成 SHAP 解释器**
python model_training.py
5. **启动 Streamlit 应用程序:**
streamlit run app.py
*应用程序将自动在您的默认网络浏览器中启动。*
由 Lipranj Daharwal 开发
标签:Apex, Kubernetes, NLP, Python, Scikit-learn, SHAP, Streamlit, TF-IDF, XAI, XGBoost, 亚马逊, 仪表盘, 元数据分析, 可解释性AI, 异常检测, 数据科学, 数据集生成, 文本分类, 无后门, 机器学习, 欺诈检测, 特征工程, 电商安全, 虚假评论检测, 访问控制, 资源验证, 逆向工具, 随机森林