umair9747/bucky
GitHub: umair9747/bucky
从单个可访问的 S3 bucket 枚举 AWS 账户 ID 并发现同账户下其他 bucket 的安全侦察工具。
Stars: 21 | Forks: 0
Bucky
An S3 account ID enumeration and bucket discovery tool
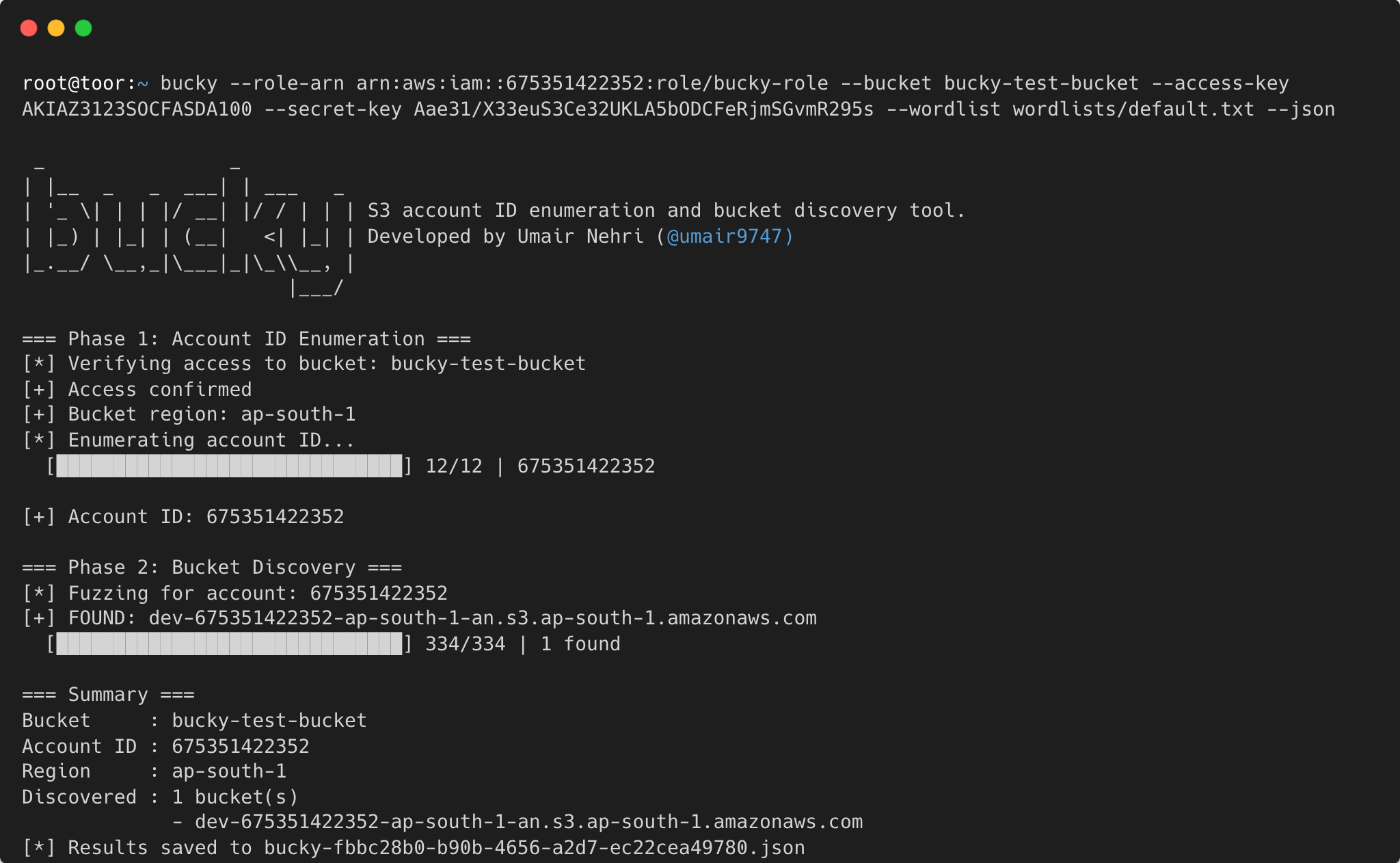
给定一个可访问的 S3 bucket,bucky 可以提取拥有该 bucket 的 12 位 AWS account ID,然后通过使用词表对 bucket 名称进行模糊测试来发现属于同一账户的其他 bucket —— 所有这些只需一条命令。
## 功能介绍
1. **枚举账户 ID (Account ID)** — 使用 `s3:ResourceAccount` IAM 条件键,通过内联 STS 会话策略逐位暴力破解 12 位 AWS 账户 ID
2. **发现更多 bucket** — 使用并发 worker 对词表中的 bucket 名称进行模糊测试,以查找同一账户拥有的其他 bucket
3. **报告所有信息** — 账户 ID、bucket 区域以及所有发现的 bucket
## 为什么这很重要
S3 bucket 名称最初共享一个单一的全局命名空间,这导致了 **bucketsquatting**(bucket 抢注)现象——攻击者可以抢注他们预计组织会创建的名称。AWS 通过推出 **account-regional namespaces**(账户-区域命名空间)解决了这个问题,这是一种将每个 bucket 绑定到其所属账户和区域的命名方案:
```
{name}-{accountID}-{region}-an
```
一个名为 `myapp-123456789123-eu-north-1-an` 的 bucket 将位于 `https://myapp-123456789123-eu-north-1-an.s3.eu-north-1.amazonaws.com`。AWS 现在建议新 bucket 使用此格式,尽管它尚未成为默认格式。(有关新命名空间如何消除 bucketsquatting 的背景知识,请参阅 [One Cloud Please](https://onecloudplease.com/blog/bucketsquatting-is-finally-dead)。)
权衡之处在于,账户 ID 和区域现在已融入 bucket 名称本身。一旦攻击者获得目标的账户 ID,他们就可以将其与词表配对,系统地构建有效的 bucket URL —— 即使 bucket 是私有的,S3 也会确认每个 URL 是否存在。仅此响应就是有用的侦察信息。
Bucky 正是利用了这一点。借鉴 [Pwned Labs](https://blog.pwnedlabs.io/a-new-s3-namespace-and-a-new-problem) 的研究,它首先使用 [s3-account-search](https://github.com/WeAreCloudar/s3-account-search) 技术从任何可访问的 bucket 中恢复 12 位账户 ID,然后对 `{name}-{accountID}-{region}-an` 模式进行暴力破解,以揭开目标更广泛的 S3 足迹。
## 技术原理
1. 您在**您自己的** AWS 账户中创建一个 IAM role,该 role 对目标 bucket 拥有 `s3:ListBucket` 或 `s3:GetObject` 权限
2. 您对该 role 调用 `sts:AssumeRole`,并传递一个带有 `s3:ResourceAccount` 条件(如 `"1*"`)的 **inline session policy**
3. 如果目标 bucket 的所属账户以 `1` 开头,则 `HeadBucket` 调用成功;否则返回 403
4. 对每个数字位置(0–9)重复此操作,直到发现所有 12 位数字
5. 内联会话策略充当权限边界 —— 它与 role 的权限相交,因此仅在条件匹配时才授予访问权限
这最多需要 **120 次 API 调用**(12 个位置 × 10 个数字),通常在一分钟内完成。
## 安装
### 使用 `go install`
```
go install github.com/umair9747/bucky@latest
```
### 从源码安装
```
git clone https://github.com/umair9747/bucky.git
cd bucky
go build -o bucky .
sudo mv bucky /usr/local/bin/
```
### 更新
```
bucky --update
```
这将拉取并安装存储库中的最新版本。
## 前置条件:IAM Role 设置
在使用 bucky 之前,您需要在**您自己的 AWS 账户**中拥有一个可以访问目标 S3 bucket 的 IAM role。目标 bucket 必须公开可访问,或者具有允许从您的账户访问的 bucket 策略。
### 步骤 1:创建信任策略
创建 `trust-policy.json` —— 这允许您的 IAM user 担任该 role:
```
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::
:root"
},
"Action": "sts:AssumeRole"
}
]
}
```
### 步骤 2:创建权限策略
创建 `s3-policy.json` —— 该 role 需要广泛的 S3 读取权限(bucky 内联会话策略中的 `s3:ResourceAccount` 条件负责账户级别过滤):
```
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject"
],
"Resource": "*"
}
]
}
```
### 步骤 3:创建 Role
```
aws iam create-role \
--role-name bucky-role \
--assume-role-policy-document file://trust-policy.json
aws iam put-role-policy \
--role-name bucky-role \
--policy-name S3ReadAccess \
--policy-document file://s3-policy.json
```
### 步骤 4:获取 Role ARN
```
aws iam get-role --role-name bucky-role --query 'Role.Arn' --output text
# 输出: arn:aws:iam::123456789012:role/bucky-role
```
### 步骤 5:确保拥有 AssumeRole 权限
如果您的 IAM user 尚未拥有 `sts:AssumeRole` 权限,请附加该权限:
```
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam:::role/bucky-role"
}
]
}
```
## 使用方法
### 完整工作流(默认)
使用 bucky 的主要方式 —— 从已知 bucket 枚举账户 ID,然后一次性模糊测试以发现更多 bucket:
```
bucky \
--role-arn arn:aws:iam::123456789012:role/bucky-role \
--bucket target-bucket \
--wordlist wordlists/default.txt \
--access-key AKIA... \
--secret-key wJal...
```
使用已知的对象键(提高可靠性):
```
bucky \
--role-arn arn:aws:iam::123456789012:role/bucky-role \
--bucket s3://target-bucket/index.html \
--wordlist wordlists/default.txt \
--workers 20
```
多个 bucket(以逗号分隔):
```
bucky \
--role-arn arn:aws:iam::123456789012:role/bucky-role \
--bucket bucket1,bucket2,bucket3 \
--wordlist wordlists/default.txt
```
从文件读取多个 bucket:
```
bucky \
--role-arn arn:aws:iam::123456789012:role/bucky-role \
--bucket-file targets.txt \
--wordlist wordlists/default.txt
```
将结果保存为 JSON:
```
bucky --bucket target-bucket --wordlist wordlists/default.txt --json
bucky --bucket target-bucket --wordlist wordlists/default.txt --json --output results.json
```
输出:
```
=== Phase 1: Account ID Enumeration ===
[*] Verifying access to bucket: target-bucket
[+] Access confirmed
[+] Bucket region: us-west-2
[*] Enumerating account ID...
[██████████████████████████████] 12/12 | 675351422352
[+] Account ID: 675351422352
=== Phase 2: Bucket Discovery ===
[*] Fuzzing buckets for account: 675351422352
[*] Loaded 312 candidates from wordlist
[+] FOUND: target-backups
[+] FOUND: target-logs
[██████████████████████████████] 312/312 | 2 found
=== Summary ===
Account ID : 675351422352
Source : target-bucket
Region : us-west-2
Discovered : 2 additional bucket(s)
- target-backups
- target-logs
```
### 仅枚举
如果您只需要账户 ID:
```
bucky enum \
--role-arn arn:aws:iam::123456789012:role/bucky-role \
--bucket target-bucket
```
多个 bucket 和 JSON 输出也适用于子命令:
```
bucky enum --bucket bucket1,bucket2 --json
bucky enum --bucket-file targets.txt --json --output results.json
```
### 仅模糊测试
如果您已经拥有账户 ID 并想要发现 bucket:
```
bucky fuzz \
--role-arn arn:aws:iam::123456789012:role/bucky-role \
--account-id 675351422352 \
--wordlist wordlists/default.txt \
--workers 20
```
## 环境变量
所有标志都可以通过环境变量设置。如果两者都设置了,标志优先。
| 变量 | 标志 | 描述 |
|---|---|---|
| `AWS_ACCESS_KEY_ID` | `--access-key` | AWS access key ID |
| `AWS_SECRET_ACCESS_KEY` | `--secret-key` | AWS secret access key |
| `AWS_SESSION_TOKEN` | `--session-token` | AWS session token(用于临时凭证) |
| `AWS_REGION` | `--region` | AWS 区域(默认:`us-east-1`) |
| `AWS_DEFAULT_REGION` | `--region` | 如果未设置 `AWS_REGION` 时的回退选项 |
| `AWS_PROFILE` | `--profile` | 来自 `~/.aws/credentials` 的 AWS 命名配置文件 |
| `BUCKY_ROLE_ARN` | `--role-arn` | 要担任的 IAM role 的 ARN |
| `BUCKY_BUCKET` | `--bucket` | 目标 S3 bucket 名称 |
| `BUCKY_ACCOUNT_ID` | `--account-id` | 目标 AWS 账户 ID(仅限 `fuzz`) |
| `BUCKY_WORDLIST` | `--wordlist` | 词表文件路径 |
| `BUCKY_WORKERS` | `--workers` | 并发模糊测试 worker(默认:`10`) |
### 使用环境变量的示例
```
export AWS_ACCESS_KEY_ID=AKIA...
export AWS_SECRET_ACCESS_KEY=wJal...
export BUCKY_ROLE_ARN=arn:aws:iam::123456789012:role/bucky-role
# 现在只需指定 target
bucky --bucket target-bucket --wordlist wordlists/default.txt
```
## 词表
Bucky 附带了一个位于 `wordlists/default.txt` 的默认词表,包含约 300 个常见的 S3 bucket 命名模式:
- 通用名称(`backups`、`logs`、`data`、`assets`、`uploads`)
- AWS 服务模式(`cloudtrail-logs`、`terraform-state`、`lambda-artifacts`)
- 环境变体(`prod-logs`、`staging-data`、`dev-backups`)
- 应用程序模式(`api`、`web-assets`、`cdn-origin`)
- 基础设施(`ci-artifacts`、`build-output`、`docker-images`)
### 自定义词表
对于针对性强的任务,通过添加组织名称前缀来生成自定义词表:
```
ORG="acme"
while read -r line; do
[[ "$line" =~ ^#.*$ || -z "$line" ]] && continue
echo "${ORG}-${line}"
echo "${line}-${ORG}"
echo "${ORG}${line}"
done < wordlists/default.txt > wordlists/acme.txt
```
任何兼容 ffuf 或 gobuster 等工具的词表均可使用。格式:每行一个 bucket 名称,支持 `#` 注释,忽略空行。
## 命令参考
| 命令 | 描述 |
|---|---|
| `bucky` | **完整工作流** — 枚举账户 ID,然后模糊测试以发现更多 bucket |
| `bucky enum` | 从已知 bucket 枚举 12 位账户 ID |
| `bucky fuzz` | 对已知的账户 ID 进行 bucket 名称模糊测试 |
### 标志
**全局标志**(所有命令):
| 标志 | 描述 |
|---|---|
| `--access-key` | AWS access key ID |
| `--secret-key` | AWS secret access key |
| `--session-token` | AWS session token |
| `--region` | AWS 区域(默认:`us-east-1`) |
| `--profile` | AWS 命名配置文件 |
| `--role-arn` | 要担任的 IAM role 的 ARN |
| `--json` | 将结果保存到 JSON 文件 |
| `--output` | JSON 输出文件路径(默认:`bucky-{uuid}.json`) |
**`bucky`(完整工作流):
| 标志 | 描述 |
|---|---|
| `--bucket` | 目标 S3 bucket,以逗号分隔 |
| `--bucket-file` | 包含 bucket 名称/URL 的文件,每行一个 |
| `--wordlist` | 词表文件路径 |
| `--workers` | 并发 worker(默认:`10`) |
**`bucky enum`:**
| 标志 | 描述 |
|---|---|
| `--bucket` | 目标 S3 bucket,以逗号分隔 |
| `--bucket-file` | 包含 bucket 名称/URL 的文件,每行一个 |
**`bucky fuzz`:**
| 标志 | 描述 |
|---|---|
| `--account-id` | 目标 12 位 AWS 账户 ID |
| `--wordlist` | 词表文件路径 |
| `--workers` | 并发 worker(默认:`10`) |
| `--regions` | 用于名称变异的区域,以逗号分隔 |
## Bucket 输入格式
`--bucket` 标志和 `--bucket-file` 接受多种输入格式。Bucky 会自动从以下格式中提取 bucket 名称(和可选键):
| 格式 | 示例 |
|---|---|
| 纯名称 | `my-bucket` |
| S3 URI | `s3://my-bucket/path/to/key` |
| Virtual-hosted URL | `https://my-bucket.s3.us-west-2.amazonaws.com/key` |
| Path-style URL | `https://s3.us-west-2.amazonaws.com/my-bucket/key` |
可以通过 `--bucket` 以逗号分隔传递多个 bucket:
```
--bucket bucket1,s3://bucket2/key,https://bucket3.s3.amazonaws.com/
```
或者通过 `--bucket-file` 在文件中每行列出一个:
```
my-bucket
s3://another-bucket/index.html
https://third.s3.us-east-1.amazonaws.com/
```
当多个 bucket 解析到同一个账户 ID 时,bucky 会去重,并仅对每个唯一账户运行一次模糊测试。
## JSON 输出
使用 `--json` 将结果保存到 JSON 文件。默认文件名为当前目录下的 `bucky-{uuid}.json`,或使用 `--output` 指定路径:
```
bucky --bucket target-bucket --wordlist wordlists/default.txt --json
bucky --bucket target-bucket --wordlist wordlists/default.txt --json --output results.json
```
输出格式:
```
{
"timestamp": "2024-01-15T10:30:00Z",
"results": [
{
"bucket": "target-bucket",
"account_id": "675351422352",
"region": "ap-south-1",
"discovered_buckets": [
"dev-675351422352-ap-south-1-an.s3.ap-south-1.amazonaws.com",
"prod-675351422352-ap-south-1-an.s3.ap-south-1.amazonaws.com"
]
}
]
}
```
## Bucket 区域处理
Bucky 自动检测目标 bucket 的区域。当 S3 返回 301 重定向(bucket 位于与 `--region` 不同的区域)时,bucky 通过 `x-amz-bucket-region` HTTP 响应头解析正确的区域,并将其缓存用于所有后续请求。无需为目标 bucket 配置手动区域。
## 联系我们!
如果您对 Genzai 有任何问题或反馈,或者只是想与我联系,请随时通过 LinkedIn 或 Email 与我联系。标签:Amazon Web Services, AWS S3, Bucket Security, Bucky, EVTX分析, ID枚举, Python, S3 存储桶, 信息泄露, 存储桶发现, 密码管理, 开源安全工具, 无后门, 日志审计, 账户枚举, 足迹分析, 逆向工程平台