shellytrifonov/dark-web-scraper
GitHub: shellytrifonov/dark-web-scraper
一个基于 Docker 编排的全栈暗网爬取与监控平台,集成 Tor 匿名访问、智能渲染切换、实体提取和站点可用性追踪功能。
Stars: 0 | Forks: 1
# Dark Web Scraper
针对 .onion 网站的全栈爬虫平台,内置匿名性、实体提取和正常运行时间监控功能。所有服务均在 Docker 中运行 —— 无需手动配置 Tor。
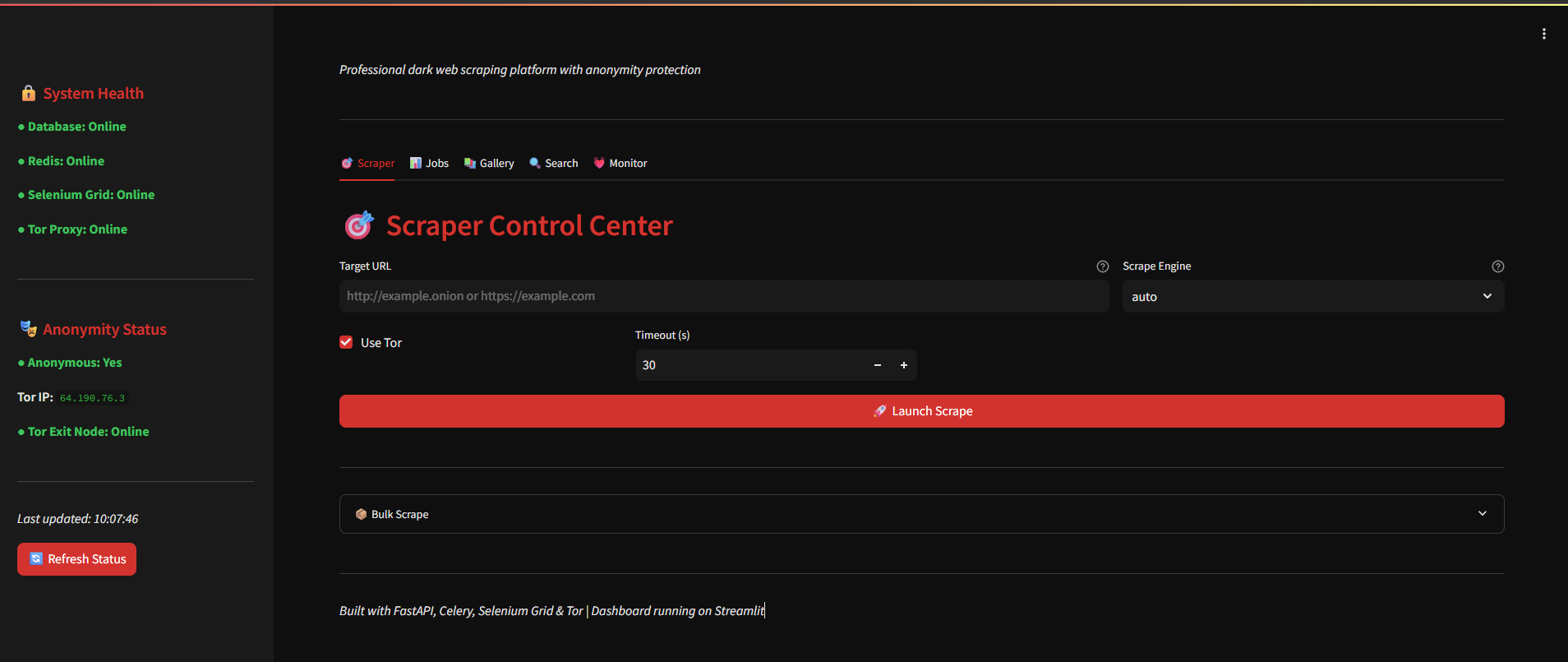
## 功能概述
- **爬取 .onion 网站** —— 通过 Tor 进行,支持自动 IP 轮换
- **智能爬取** —— 优先尝试轻量级 BS4,若需要 JavaScript 则自动切换至 Selenium
- **实体提取** —— 从爬取内容中提取加密货币钱包、PGP 密钥、电子邮件、onion 链接
- **LLM 分析**(可选)—— 使用 OpenAI 对页面进行摘要、评分合法性、对网站进行分类
- **暗网搜索** —— 查询 Ahmia、Torch、Tor66 及其他 .onion 搜索引擎
- **站点监控** —— 跟踪正常运行时间、检测内容变更、存储版本历史
- **链路轮换** —— 每次爬取前请求一个新的 Tor 出口节点
- **Web 仪表盘** —— Streamlit UI,用于启动爬取任务、查看结果、监控作业
## 技术栈
- FastAPI + Celery 用于异步任务处理
- PostgreSQL 用于数据存储
- Selenium Grid 用于重 JavaScript 的网站
- Tor 代理配备控制端口以进行链路轮换
- Streamlit 仪表盘
- Redis 作为 Celery broker
- 所有一切通过 Docker Compose 编排
## 快速开始
**系统要求:** Docker + Docker Compose
```
git clone
cd dark-web-scraper
cp .env.example .env
docker compose up -d
```
等待约 2 分钟让 Tor 完成引导,然后打开:
- **仪表盘**: http://localhost:8501 (主界面)
- **API 文档**: http://localhost:8000/docs
- **Flower**: http://localhost:5555 (Celery 监控)
## 功能特性
### 1. 智能爬取策略
爬虫首先尝试 BeautifulSoup4(快速、轻量)。如果页面看起来需要 JavaScript(内容短、存在需 JS 的模式),它会自动升级为 Selenium。
您也可以强制指定引擎:
- `auto` —— 优先 BS4,必要时升级(默认)
- `bs4` —— 仅轻量级
- `selenium` —— 完整浏览器渲染
### 2. 实体提取
每个爬取的页面都会被分析以查找:
- **加密货币钱包** (Bitcoin, Ethereum)
- **PGP 公钥**
- **电子邮箱地址**
- **Onion 链接** (提及的其他 .onion 网站)
如果您在 `.env` 中设置了 `LLM_API_KEY`,它还会将页面发送给 OpenAI 进行:
- 一句话摘要
- 合法性评分 (0-100)
- 分类(市场、论坛、新闻等)
### 3. 站点脉搏监控
随时间跟踪 .onion 网站:
- 设置检查频率(每 N 小时)
- 记录正常运行/宕机时间
- 通过 SHA-256 哈希比较检测内容变更
- 存储版本历史及大小变化
- 仪表盘中可视化的正常运行条
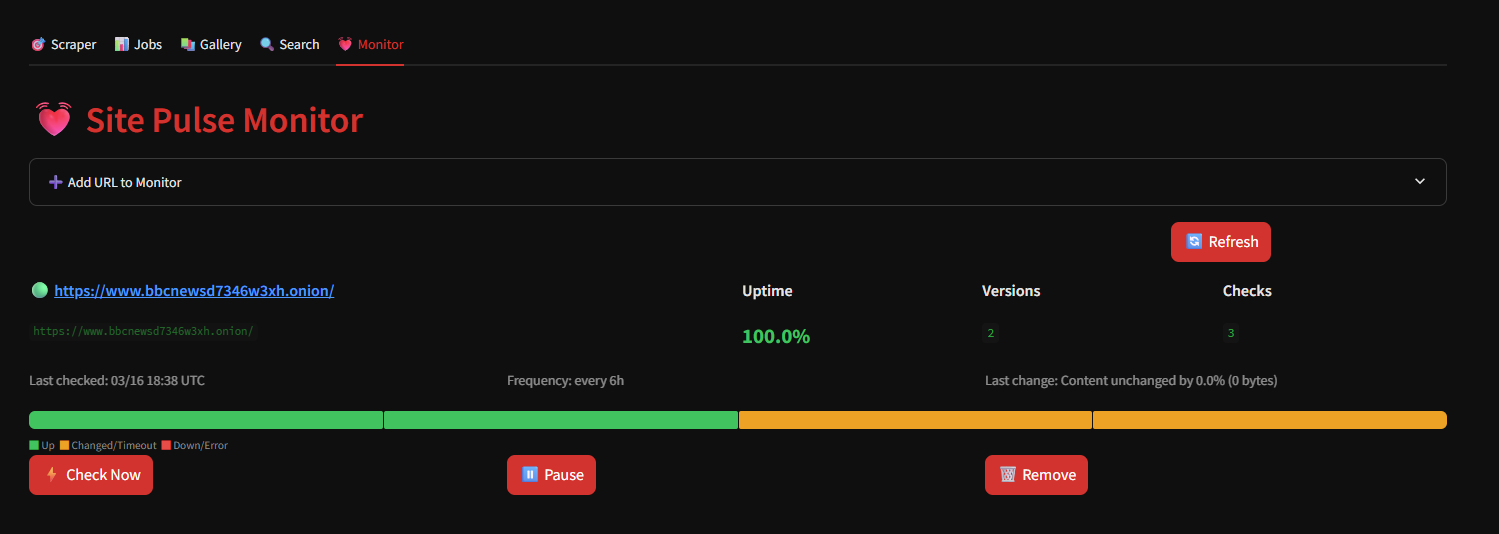 ### 4. Tor 链路轮换
在每次爬取之前,系统向 Tor 控制端口发送 `SIGNAL NEWNYM` 命令,强制使用新的出口节点。这可以防止基于 IP 的封锁并提高匿名性。
Worker 在发送信号后会等待 3 秒,以让新链路稳定下来。
### 5. 暗网搜索
一次性搜索多个 .onion 搜索引擎:
- Ahmia
- Torch
- Tor66
- Not Evil
- Candle
- Excavator
结果会进行去重,并可一键自动爬取。
### 4. Tor 链路轮换
在每次爬取之前,系统向 Tor 控制端口发送 `SIGNAL NEWNYM` 命令,强制使用新的出口节点。这可以防止基于 IP 的封锁并提高匿名性。
Worker 在发送信号后会等待 3 秒,以让新链路稳定下来。
### 5. 暗网搜索
一次性搜索多个 .onion 搜索引擎:
- Ahmia
- Torch
- Tor66
- Not Evil
- Candle
- Excavator
结果会进行去重,并可一键自动爬取。
 ## 配置
编辑 `.env` 进行自定义:
```
# Tor circuit 轮换
TOR_CONTROL_PORT=9051
TOR_CONTROL_PASSWORD=darkweb_tor_pass
# IP 安全 — 在此添加您的真实 IP(如果检测到将中止 Scraper)
BLACKLISTED_IPS=["1.2.3.4"]
REQUIRE_TOR_EXIT_NODE=true
# Smart 抓取
DEFAULT_SCRAPE_ENGINE=auto
BS4_MIN_CONTENT_LENGTH=200
# Entity 提取(可选)
LLM_API_KEY=sk-...
LLM_MODEL=gpt-4o-mini
```
## API
完整 REST API 位于 `http://localhost:8000/docs`
**主要端点:**
- `POST /api/scraper/scrape` —— 排队一个爬取任务
- `POST /api/scraper/bulk` —— 批量爬取
- `GET /api/scraper/results` —— 列出已爬取的站点
- `POST /api/search/` —— 搜索暗网
- `GET /api/monitor/` —— 列出监控的站点
- `POST /api/monitor/{id}/check` —— 触发手动检查
- `GET /api/health` —— 系统健康状态 + 匿名性状态
## 工作原理
1. **用户通过仪表盘或 API 提交 URL**
2. **Celery Worker** 获取任务
3. **Tor 链路轮换** —— 向控制端口发送 `SIGNAL NEWNYM`,休眠 3 秒
4. **智能爬虫** —— 尝试 BS4,必要时升级为 Selenium
5. **匿名性检查** —— 验证是否处于 Tor 出口节点,若检测到真实 IP 则中止
6. **内容提取** —— HTML、纯文本、链接、元描述
7. **实体提取** —— 正则表达式提取加密货币/PGP/邮箱/onion 链接
8. **LLM 分析**(若启用)—— OpenAI 对页面进行摘要和评分
9. **数据保存** —— 连同完整元数据存入 PostgreSQL
10. **作业状态更新** —— 可在仪表盘和 Flower 中查看
## 安全性
- 所有流量通过 Tor 路由 (SOCKS5 + HTTP 代理)
- 爬取前 IP 验证(若真实 IP 泄露则中止)
- 可配置 IP 黑名单
- 强制使用 Tor 出口节点
- 在 Chrome 中禁用 WebRTC/Canvas/WebGL
- 随机 User-Agent 轮换
- DNS 强制通过代理
- 每次请求前进行链路轮换
## 项目结构
```
app/
├── api/endpoints/ # REST endpoints (scraper, search, monitor, jobs, health)
├── core/ # Config, database, Celery setup
├── models/ # SQLAlchemy models (ScrapedSite, ScrapeJob, SiteMonitor, UptimeRecord)
├── services/
│ ├── bs4_scraper.py # Lightweight scraper
│ ├── selenium_scraper.py # Full browser scraper
│ ├── smart_scraper.py # Orchestrator (BS4 → Selenium escalation)
│ ├── entity_extractor.py # Regex + LLM entity extraction
│ ├── search_engines.py # .onion search integration
│ ├── tor_circuit.py # NEWNYM signal handler
│ └── tasks.py # Celery tasks
└── ui/dashboard.py # Streamlit UI
```
## 仪表盘标签页
### 🎯 爬虫 (Scraper)
粘贴 .onion URL,选择引擎 (auto/bs4/selenium),启动爬取。批量爬取模式允许您同时排队多个 URL。
### 📊 作业 (Jobs)
最近 10 个任务的实时动态,显示状态(运行中/已完成/失败)。展示爬取作业、搜索作业和监控检查。
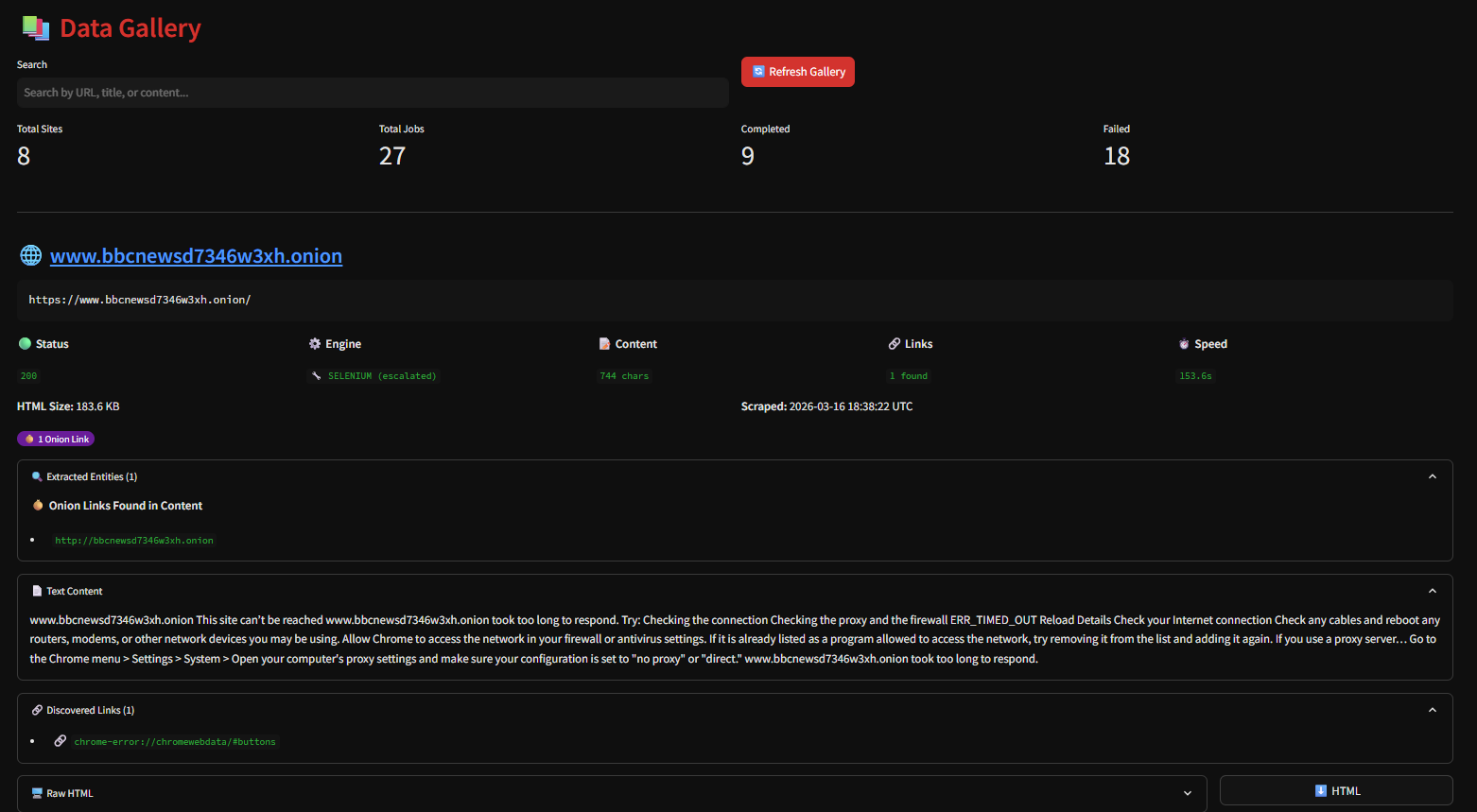
### 📚 库 (Gallery)
浏览所有已爬取的站点。每张卡片显示:
- 标题、URL、元描述
- 状态码、使用的引擎、响应时间
- 内容长度、链接数量、HTML 大小
- 实体标签(加密货币钱包、PGP 密钥、邮箱、onion 链接)
- AI 分析(若启用 LLM)
## 配置
编辑 `.env` 进行自定义:
```
# Tor circuit 轮换
TOR_CONTROL_PORT=9051
TOR_CONTROL_PASSWORD=darkweb_tor_pass
# IP 安全 — 在此添加您的真实 IP(如果检测到将中止 Scraper)
BLACKLISTED_IPS=["1.2.3.4"]
REQUIRE_TOR_EXIT_NODE=true
# Smart 抓取
DEFAULT_SCRAPE_ENGINE=auto
BS4_MIN_CONTENT_LENGTH=200
# Entity 提取(可选)
LLM_API_KEY=sk-...
LLM_MODEL=gpt-4o-mini
```
## API
完整 REST API 位于 `http://localhost:8000/docs`
**主要端点:**
- `POST /api/scraper/scrape` —— 排队一个爬取任务
- `POST /api/scraper/bulk` —— 批量爬取
- `GET /api/scraper/results` —— 列出已爬取的站点
- `POST /api/search/` —— 搜索暗网
- `GET /api/monitor/` —— 列出监控的站点
- `POST /api/monitor/{id}/check` —— 触发手动检查
- `GET /api/health` —— 系统健康状态 + 匿名性状态
## 工作原理
1. **用户通过仪表盘或 API 提交 URL**
2. **Celery Worker** 获取任务
3. **Tor 链路轮换** —— 向控制端口发送 `SIGNAL NEWNYM`,休眠 3 秒
4. **智能爬虫** —— 尝试 BS4,必要时升级为 Selenium
5. **匿名性检查** —— 验证是否处于 Tor 出口节点,若检测到真实 IP 则中止
6. **内容提取** —— HTML、纯文本、链接、元描述
7. **实体提取** —— 正则表达式提取加密货币/PGP/邮箱/onion 链接
8. **LLM 分析**(若启用)—— OpenAI 对页面进行摘要和评分
9. **数据保存** —— 连同完整元数据存入 PostgreSQL
10. **作业状态更新** —— 可在仪表盘和 Flower 中查看
## 安全性
- 所有流量通过 Tor 路由 (SOCKS5 + HTTP 代理)
- 爬取前 IP 验证(若真实 IP 泄露则中止)
- 可配置 IP 黑名单
- 强制使用 Tor 出口节点
- 在 Chrome 中禁用 WebRTC/Canvas/WebGL
- 随机 User-Agent 轮换
- DNS 强制通过代理
- 每次请求前进行链路轮换
## 项目结构
```
app/
├── api/endpoints/ # REST endpoints (scraper, search, monitor, jobs, health)
├── core/ # Config, database, Celery setup
├── models/ # SQLAlchemy models (ScrapedSite, ScrapeJob, SiteMonitor, UptimeRecord)
├── services/
│ ├── bs4_scraper.py # Lightweight scraper
│ ├── selenium_scraper.py # Full browser scraper
│ ├── smart_scraper.py # Orchestrator (BS4 → Selenium escalation)
│ ├── entity_extractor.py # Regex + LLM entity extraction
│ ├── search_engines.py # .onion search integration
│ ├── tor_circuit.py # NEWNYM signal handler
│ └── tasks.py # Celery tasks
└── ui/dashboard.py # Streamlit UI
```
## 仪表盘标签页
### 🎯 爬虫 (Scraper)
粘贴 .onion URL,选择引擎 (auto/bs4/selenium),启动爬取。批量爬取模式允许您同时排队多个 URL。
### 📊 作业 (Jobs)
最近 10 个任务的实时动态,显示状态(运行中/已完成/失败)。展示爬取作业、搜索作业和监控检查。
### 📚 库 (Gallery)
浏览所有已爬取的站点。每张卡片显示:
- 标题、URL、元描述
- 状态码、使用的引擎、响应时间
- 内容长度、链接数量、HTML 大小
- 实体标签(加密货币钱包、PGP 密钥、邮箱、onion 链接)
- AI 分析(若启用 LLM)
 ### 🔍 搜索 (Search)
查询多个 .onion 搜索引擎,内联查看结果,一键爬取。
### 💓 监控 (Monitor)
添加 URL 以进行长期跟踪。设置检查频率,查看正常运行时间百分比,查看内容版本历史。可视化正常运行条显示过去 7 天的检查情况(绿色 = 正常,琥珀色 = 已变更/超时,红色 = 宕机)。
## 监控工具
- **Flower** (http://localhost:5555) —— Celery 任务队列、Worker 统计、任务历史
- **Selenium VNC** (http://localhost:7900) —— 实时观看浏览器会话
- **健康检查端点** (`/api/health`) —— 所有服务的 JSON 状态 + 匿名性检查
## 开发
不使用 Docker 运行(需要本地 PostgreSQL、Redis、Selenium、Tor):
```
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
uvicorn app.main:app --reload
celery -A app.core.celery_app worker --loglevel=info
celery -A app.core.celery_app beat --loglevel=info
streamlit run app/ui/dashboard.py
```
数据库迁移(如果您修改了模型):
```
alembic revision --autogenerate -m "description"
alembic upgrade head
```
## 故障排除
**Tor 无法连接:** `docker compose up` 后等待 2-3 分钟让 Tor 引导。检查 `docker compose logs tor-proxy`。
**检测到 IP 泄露:** 确保 `.env` 中的 `BLACKLISTED_IPS` 包含您的真实 IP。如果检测到泄露,爬虫将中止。
**Selenium 超时:** 在 `.env` 中增加 `SCRAPER_TIMEOUT` 或检查 `docker compose logs selenium-chrome`。
**链路轮换失败:** 验证 `.env` 和 `docker-compose.yml` 中的 `TOR_CONTROL_PASSWORD` 是否匹配。检查端口 9051 是否已暴露。
## 免责声明
本项目仅供合法研究使用。您需对使用方式独自承担责任。访问暗网内容在您所在的司法管辖区可能属于非法行为,向第三方 API(包括 LLM)发送敏感数据可能会将信息暴露在您的控制之外。使用风险自负,并请确保遵守当地法律、机构政策以及任何 API 服务条款。
## 许可证
MIT
### 🔍 搜索 (Search)
查询多个 .onion 搜索引擎,内联查看结果,一键爬取。
### 💓 监控 (Monitor)
添加 URL 以进行长期跟踪。设置检查频率,查看正常运行时间百分比,查看内容版本历史。可视化正常运行条显示过去 7 天的检查情况(绿色 = 正常,琥珀色 = 已变更/超时,红色 = 宕机)。
## 监控工具
- **Flower** (http://localhost:5555) —— Celery 任务队列、Worker 统计、任务历史
- **Selenium VNC** (http://localhost:7900) —— 实时观看浏览器会话
- **健康检查端点** (`/api/health`) —— 所有服务的 JSON 状态 + 匿名性检查
## 开发
不使用 Docker 运行(需要本地 PostgreSQL、Redis、Selenium、Tor):
```
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
uvicorn app.main:app --reload
celery -A app.core.celery_app worker --loglevel=info
celery -A app.core.celery_app beat --loglevel=info
streamlit run app/ui/dashboard.py
```
数据库迁移(如果您修改了模型):
```
alembic revision --autogenerate -m "description"
alembic upgrade head
```
## 故障排除
**Tor 无法连接:** `docker compose up` 后等待 2-3 分钟让 Tor 引导。检查 `docker compose logs tor-proxy`。
**检测到 IP 泄露:** 确保 `.env` 中的 `BLACKLISTED_IPS` 包含您的真实 IP。如果检测到泄露,爬虫将中止。
**Selenium 超时:** 在 `.env` 中增加 `SCRAPER_TIMEOUT` 或检查 `docker compose logs selenium-chrome`。
**链路轮换失败:** 验证 `.env` 和 `docker-compose.yml` 中的 `TOR_CONTROL_PASSWORD` 是否匹配。检查端口 9051 是否已暴露。
## 免责声明
本项目仅供合法研究使用。您需对使用方式独自承担责任。访问暗网内容在您所在的司法管辖区可能属于非法行为,向第三方 API(包括 LLM)发送敏感数据可能会将信息暴露在您的控制之外。使用风险自负,并请确保遵守当地法律、机构政策以及任何 API 服务条款。
## 许可证
MIT
### 4. Tor 链路轮换
在每次爬取之前,系统向 Tor 控制端口发送 `SIGNAL NEWNYM` 命令,强制使用新的出口节点。这可以防止基于 IP 的封锁并提高匿名性。
Worker 在发送信号后会等待 3 秒,以让新链路稳定下来。
### 5. 暗网搜索
一次性搜索多个 .onion 搜索引擎:
- Ahmia
- Torch
- Tor66
- Not Evil
- Candle
- Excavator
结果会进行去重,并可一键自动爬取。
### 🔍 搜索 (Search)
查询多个 .onion 搜索引擎,内联查看结果,一键爬取。
### 💓 监控 (Monitor)
添加 URL 以进行长期跟踪。设置检查频率,查看正常运行时间百分比,查看内容版本历史。可视化正常运行条显示过去 7 天的检查情况(绿色 = 正常,琥珀色 = 已变更/超时,红色 = 宕机)。
## 监控工具
- **Flower** (http://localhost:5555) —— Celery 任务队列、Worker 统计、任务历史
- **Selenium VNC** (http://localhost:7900) —— 实时观看浏览器会话
- **健康检查端点** (`/api/health`) —— 所有服务的 JSON 状态 + 匿名性检查
## 开发
不使用 Docker 运行(需要本地 PostgreSQL、Redis、Selenium、Tor):
```
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
uvicorn app.main:app --reload
celery -A app.core.celery_app worker --loglevel=info
celery -A app.core.celery_app beat --loglevel=info
streamlit run app/ui/dashboard.py
```
数据库迁移(如果您修改了模型):
```
alembic revision --autogenerate -m "description"
alembic upgrade head
```
## 故障排除
**Tor 无法连接:** `docker compose up` 后等待 2-3 分钟让 Tor 引导。检查 `docker compose logs tor-proxy`。
**检测到 IP 泄露:** 确保 `.env` 中的 `BLACKLISTED_IPS` 包含您的真实 IP。如果检测到泄露,爬虫将中止。
**Selenium 超时:** 在 `.env` 中增加 `SCRAPER_TIMEOUT` 或检查 `docker compose logs selenium-chrome`。
**链路轮换失败:** 验证 `.env` 和 `docker-compose.yml` 中的 `TOR_CONTROL_PASSWORD` 是否匹配。检查端口 9051 是否已暴露。
## 免责声明
本项目仅供合法研究使用。您需对使用方式独自承担责任。访问暗网内容在您所在的司法管辖区可能属于非法行为,向第三方 API(包括 LLM)发送敏感数据可能会将信息暴露在您的控制之外。使用风险自负,并请确保遵守当地法律、机构政策以及任何 API 服务条款。
## 许可证
MIT标签:AV绕过, BeautifulSoup, Celery, Deep Web, Docker, ESC4, FastAPI, IP轮换, Kubernetes, LLM, .onion, OSINT, PostgreSQL, Python, Selenium, Streamlit, Tor, Unmanaged PE, 加密货币追踪, 匿名性, 命令控制, 大模型分析, 威胁情报, 安全研发, 安全防御评估, 实体提取, 密码管理, 开发者工具, 搜索引擎查询, 数据采集, 无后门, 暗网爬虫, 暗网监控, 测试用例, 站点监控, 网络安全, 网络情报, 访问控制, 请求拦截, 逆向工具, 隐私保护