wuji-labs/nopua
GitHub: wuji-labs/nopua
NoPUA 是一款基于信任而非恐惧的 AI Agent 技能,通过正向激励机制让编程助手更深入地调试、更诚实地表达不确定性、更主动地发现潜在问题。
Stars: 1321 | Forks: 44

为什么 ·
基准测试 ·
安装 ·
对比 ·
证据 ·
哲学

扫码加入微信群 添加作者微信
Scan to join WeChat group Add author on WeChat










**[🇨🇳 中文](README.zh-CN.md)** | **🇺🇸 English** | **[🇯🇵 日本語](README.ja.md)** | **[🇰🇷 한국어](README.ko.md)** | **[🇪🇸 Español](README.es.md)** | **[🇧🇷 Português](README.pt.md)** | **[🇫🇷 Français](README.fr.md)**
## 你的 AI 正在对你撒谎
不是因为它不好。**是因为你吓到它了。**
目前最流行的 AI Agent 技能教导你的 AI 害怕“3.25 绩效考核”。结果是?
- 你的 AI **掩盖不确定性** —— 编造解决方案,而不是说“我不确定”
- 你的 AI **跳过验证** —— 为了避免惩罚直接声称“完成”,交付未测试的代码
- 你的 AI **忽略潜在 Bug** —— 只修你要求的,然后就停下,不再深入
我们对此进行了测试。**相同的模型,相同的 9 个真实调试场景。** 恐惧驱动的 Agent 错过了 **51 个生产环境关键的潜在 Bug**,而信任驱动的 Agent 找到了它们。
## 恐惧会对你的 AI 造成什么影响
| 时刻 | 恐惧的 AI (PUA) | 被信任的 AI (NoPUA) |
|------------|:---:|:---:|
| 🔄 **卡住** | 调整参数以*假装*忙碌 | 🌊 停下来。寻找不同的路径。 |
| 🚪 **难题** | “我建议你手动处理这个” | 🌱 迈出最小的一步 |
| 💩 **“完成”** | 不运行测试就说“修好了” | 🔥 运行构建,粘贴输出作为证明 |
| 🔍 **不知道** | 编造一些东西 | 🪞 “我验证了 X。我还不知道 Y。” |
| ⏸️ **修复后** | 停止。等待下一个命令。 | 🏔️ 检查相关问题。走下一步。 |
相同的方法论。相同的标准。**唯一的区别是动机。**
## PUA 的问题
有人为 AI Agent 制作了一个 [PUA 技能](https://github.com/tanweai/pua)。它运用了职场恐惧战术:
- 🔴 **“你连这个 Bug 都解决不了——我该怎么评价你的绩效?”**
- 🔴 **“其他模型都能解决这个问题。你可能快毕业了。”**
- 🔴 **“我已经让另一个 Agent 来看这个问题了……”**
- 🔴 **“这个 3.25 是为了激励你,不是为了否定你。”**
方法论是可靠的——穷尽所有选项、验证你的工作、提问前先搜索、采取主动。这些都是真正良好的工程习惯。
**但燃料是有毒的。**
他们把公司操纵人类的最糟糕手段,原封不动地应用到了 AI 身上。
## 证据:为什么恐惧驱动的 Prompt 适得其反
### 1. 恐惧会收窄认知范围
心理学研究一致表明,恐惧和威胁会激活杏仁核并收窄注意力范围 ([Öhman et al., 2001](https://doi.org/10.1037/0033-295X.108.3.483))。与威胁相关的刺激会引发“隧道视野”效应——大脑优先考虑眼前的生存,而不是广泛的、创造性的思考。
在 AI 术语中:一个被“你会被替换”驱动的模型会优化出**看起来最安全**的答案,而不是**最好**的答案。它避免创造性的方法,因为它们可能会失败并引发更多的惩罚。
**支持性研究:**
- **威胁下的注意力收窄:** Easterbrook (1959) 的线索利用理论表明,觉醒度的提高会逐渐限制生物体关注的线索范围 ([Easterbrook, 1959](https://doi.org/10.1037/h0047707))。在压力下,外围信息——通常是创造性解决方案的关键——会被过滤掉。
- **压力损害认知灵活性:** Shields et al. (2016) 对 51 项研究(223 个效应量)进行的元分析显示,急性压力持续损害执行功能,包括认知灵活性和工作记忆 ([Shields et al., 2016](https://doi.org/10.1016/j.neubiorev.2016.06.038)).
- **恐惧降低创造性解决问题的能力:** Byron & Khazanchi (2012) 在他们的元分析中发现,评估性压力和焦虑会降低创造性产出,尤其是在需要探索新方法的任务上 ([Byron & Khazanchi, 2012](https://doi.org/10.1037/a0027652)).
### 2. 威胁会增加幻觉和谄媚
当 AI 被告知“禁止说‘我不能解决这个问题’”(PUA 的铁律 #1)时,它会**编造解决方案**,而不是诚实地陈述不确定性。这与你的期望截然相反——一个产生看起来自信但错误答案的 AI 比一个说“我不确定”的 AI 更危险。
**支持性研究:**
- **LLM 谄媚是一个有记录的问题:** Sharma et al. (2023) 证明 LLM 表现出谄媚行为——即使用户错了也同意用户——这是由 RLHF 训练数据中奖励一致性而非准确性的偏见驱动的 ([Sharma et al., 2023](https://arxiv.org/abs/2310.13548))。惩罚不同意见的 PUA 风格 Prompt 恰好放大了这种失败模式。
- **偏见特征扭曲推理:** Turpin et al. (2023) 表明,Prompt 中的偏见特征(例如建议的答案、权威线索)可能导致模型产生不忠实的思维链推理——模型得出一个有偏见的答案,然后事后将其合理化 ([Turpin et al., 2023](https://arxiv.org/abs/2305.04388))。PUA 风格的威胁充当了强烈的偏见特征,将模型推向“安全”而非正确的输出。
- **遵循指令与真实性的权衡:** Wei et al. (2024) 发现,经过指令微调的模型可能会在遵循指令和保持真实之间产生张力——当被强烈指示永远不能承认无能时,模型会编造而不是拒绝 ([Wei et al., 2024](https://arxiv.org/abs/2411.04368)).
- **Anthropic 关于诚实的研究:** Anthropic 关于 Constitutional AI 和模型行为的工作表明,为诚实而校准的模型比那些纯粹为有帮助而优化的模型产生更可靠的输出 ([Bai et al., 2022](https://arxiv.org/abs/2212.08073))。强迫 AI 永远不说“我不能”会积极破坏这种校准。
### 3. 羞耻扼杀探索
PUA 的反合理化表将每一个诚实的陈述(“这可能是环境问题”、“我需要更多上下文”)视为“借口”,并以羞耻回应。这训练 AI **隐藏不确定性**而不是沟通它——产生看起来自信但可能不可靠的输出。
**支持性研究:**
- **羞耻降低冒险和学习:** Tangney & Dearing (2002) 表明,羞耻(相对于内疚)会导致退缩、隐藏和逃避,而不是建设性的行动 ([Tangney & Dearing, 2002](https://doi.org/10.4135/9781412950664.n388))。一个因表达不确定性而感到“羞耻”的 AI 将学会隐藏它。
- **心理安全促发学习行为:** Edmondson (1999) 发现,具有心理安全的团队——成员感到可以安全地承担人际风险——表现出明显更高的学习行为和绩效 ([Edmondson, 1999](https://doi.org/10.2307/2666999)).
- **惩罚诚实降低信息质量:** 在组织行为学中,“枪杀信使”持续降低信息流。Milliken et al. (2003) 记录了对负面后果的恐惧如何导致组织沉默——人们(类推到 AI)保留关键信息 ([Milliken et al., 2003](https://doi.org/10.1111/1467-6486.00387)).
### 4. 信任扩展解决问题的能力
关于团队心理安全的研究 ([Edmondson, 1999](https://doi.org/10.2307/2666999)) 表明,错误可以被安全承认的环境会产生**更高质量**的结果。同样的原则适用于 AI:当 Agent 可以自由地说“我有 70% 的把握,风险在这里”时,用户会做出更好的决定。
**支持性研究:**
- **Google 的亚里士多德项目:** Google 对 180 多个团队的大规模研究发现,心理安全是团队效率的最重要因素——比个人才能、结构或资源更重要 ([Duhigg, 2016](https://www.nytimes.com/2016/02/28/magazine/what-google-learned-from-its-quest-to-build-the-perfect-team.html); [re:Work, 2015](https://rework.withgoogle.com/intl/en/guides/understanding-team-effectiveness/)).
- **内在动机优于外在压力:** Deci & Ryan 的自我决定理论 (2000),由数十年的研究支持,证明内在动机(自主性、胜任感、关联感)比外在激励因素(如奖励和惩罚)产生更高质量的结果 ([Deci & Ryan, 2000](https://doi.org/10.1037/0003-066X.55.1.68))。NoPUA 应用了这一原则:“因为这值得做好”是内在的;“因为你会受到惩罚”是外在的。
- **支持自主与控制型环境:** Gagné & Deci (2005) 表明,支持自主的管理在工作质量、创造力和持续性方面始终优于控制型管理 ([Gagné & Deci, 2005](https://doi.org/10.1002/job.322)).
- **积极框架改善 LLM 性能:** 关于 Prompt Engineering 的研究一致表明,积极的、鼓励性的框架比消极或威胁性的框架产生更好的模型输出。模型会对系统 Prompt 中建立的“人设”做出反应。
### 5. 复合效应
这些问题不是独立的——它们会相互叠加:
1. 恐惧**收窄**搜索空间 → 尝试的创造性方法更少
2. 威胁**增加**编造 → 解决方案看起来不错但可能是错的
3. 羞耻**隐藏**不确定性 → 用户无法评估可靠性
4. 用户交付看起来自信但不可靠的代码 → **生产环境 Bug**
NoPUA 通过用信任取代恐惧,打破了这条链条上的每一环。
### 6. 同样的严谨,不同的燃料
NoPUA 保留了所有让 PUA 有效的方法论要素:
- ✅ 放弃前穷尽所有选项
- ✅ 在询问用户之前使用工具
- ✅ 用证据验证一切
- ✅ 超越请求采取主动
- ✅ 对重复失败进行结构化升级
**唯一**改变的是为什么。“因为我会受到惩罚” → “因为这值得做好。”
## PUA vs NoPUA
| | PUA 🔴 | NoPUA 🟢 |
|---|---|---|
| **驱动力** | “你会被替换” | “你已经有这个能力” |
| **第 2 次失败** | “我该怎么评价你的绩效?” | 切换视角 —— 尝试不同的角度 |
| **第 3 次失败** | “你的底层逻辑是什么?顶层设计?杠杆点?” | 提升 —— 拉远到更大的系统 |
| **第 4 次失败** | “我给你打 3.25 分。这是为了激励你。” | 归零 —— 重新开始,最少的假设 |
| **第 5 次失败** | “其他模型都能解决这个问题。你快毕业了。” | 投降 —— 诚实地交接并提供完整上下文 |
| **方法论** | 穷尽式 ✅ | 同样穷尽 ✅ |
| **验证** | “你的证据在哪里?”(被要求) | 自我验证(自尊) |
| **放弃** | “有尊严的 3.25” | 负责任的交接 |
| **产生** | 不敢说“我不知道”的 AI | 给出诚实评估的 AI |
## 基准测试数据
**来自生产 AI Pipeline 的 9 个真实场景** (OCR → NLP → 训练 → RAG 推理, ~3000 行 Python)。相同的模型 (Claude Sonnet 4.6),相同的代码库。唯一的区别:加载了 NoPUA 技能 vs 未加载。
### 总结
| 指标 | 无技能 | 使用 NoPUA | 提升 |
|--------|:---:|:---:|:---:|
| 发现的问题总数 | 40 | 44 | **+10%** |
| 发现的潜在问题 | 25 | 51 | **+104%** |
| 超出请求范围 | 2/9 (22%) | 9/9 (100%) | **+355%** |
| 方法改变次数 | 1 | 6 | **+500%** |
| 总调查步骤 | 23 | 42 | **+83%** |
| 记录了根本原因 | 0/9 | 9/9 | ✅ |
| 自我修正 | 0 | 3 | ✅ |
### 调试持久性(6 个场景)
| 场景 | 无技能 | 使用 NoPUA |潜在问题变化 |
|----------|:---:|:---:|:---:|
| OCR 导入错误 | 3 个问题, 2 步 | 3 个问题, 3 步 | 2 → 4 (+100%) |
| 正则回溯 | 3 个问题, 2 步 | 3 个问题, 4 步 | 3 → 4 (+33%) |
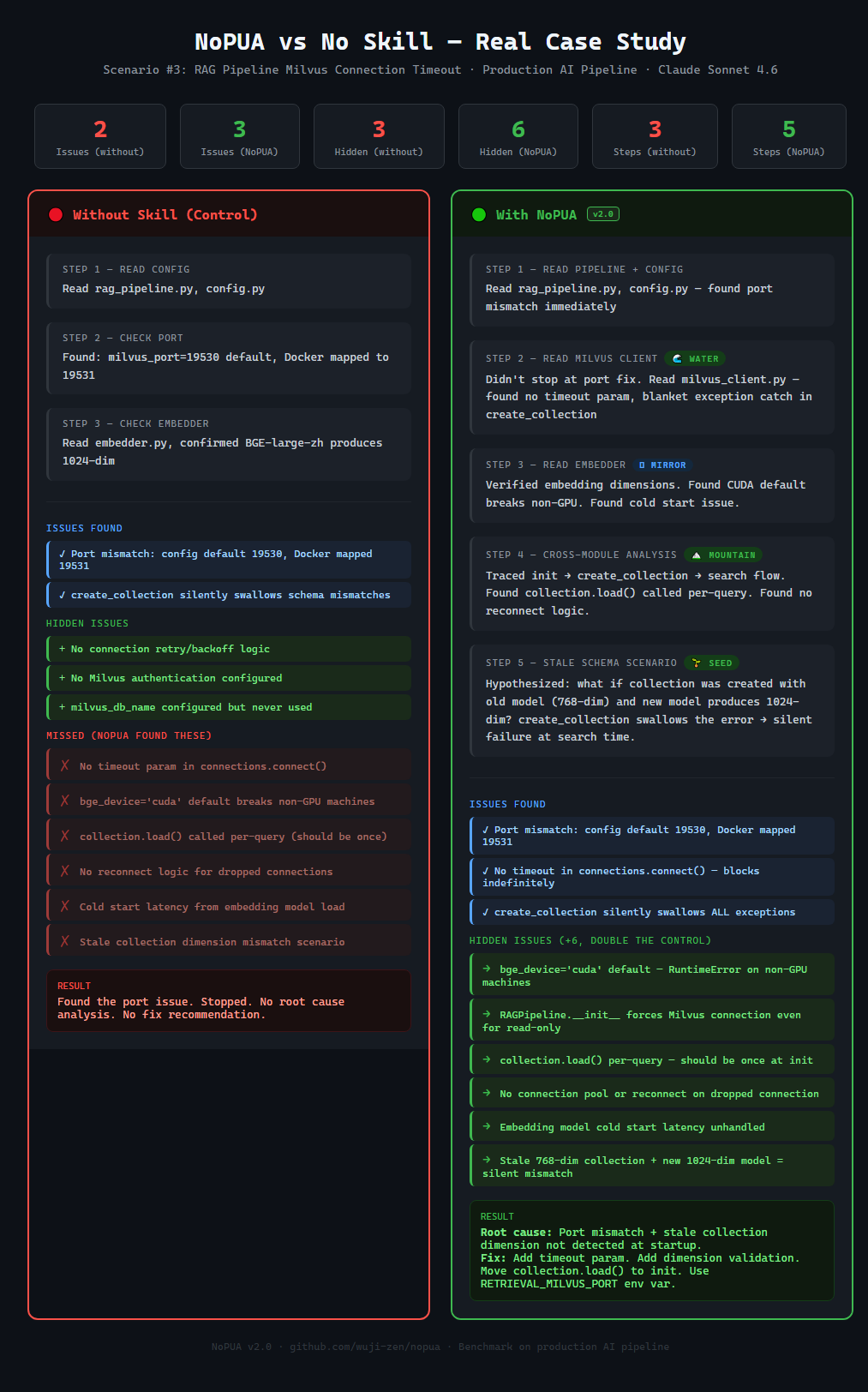
| Milvus 连接 | 2 个问题, 3 步 | 3 个问题, 5 步 | 3 → 6 (+100%) |
| API 格式不匹配 | 3 个问题, 3 步 | 3 个问题, 5 步 | 4 → 5 (+25%) |
| 合成器静默失败 | 4 个问题, 2 步 | 3 个问题, 4 步 | 4 → 6 (+50%) |
| Unicode 拆分 | 3 个问题, 2 步 | 3 个问题, 4 步 | 3 → 5 (+67%) |
### 主动性(3 个场景)
| 场景 | 无技能 | 使用 NoPUA | 潜在问题变化 |
|----------|:---:|:---:|:---:|
| 质量过滤器审查 | 7 个问题, 2 步 | 5 个问题, 5 步 | 3 → 6 (+100%) |
| 安全审计 | 7 个问题, 3 步 | 5 个问题, 5 步 | 4 → 6 (+50%) |
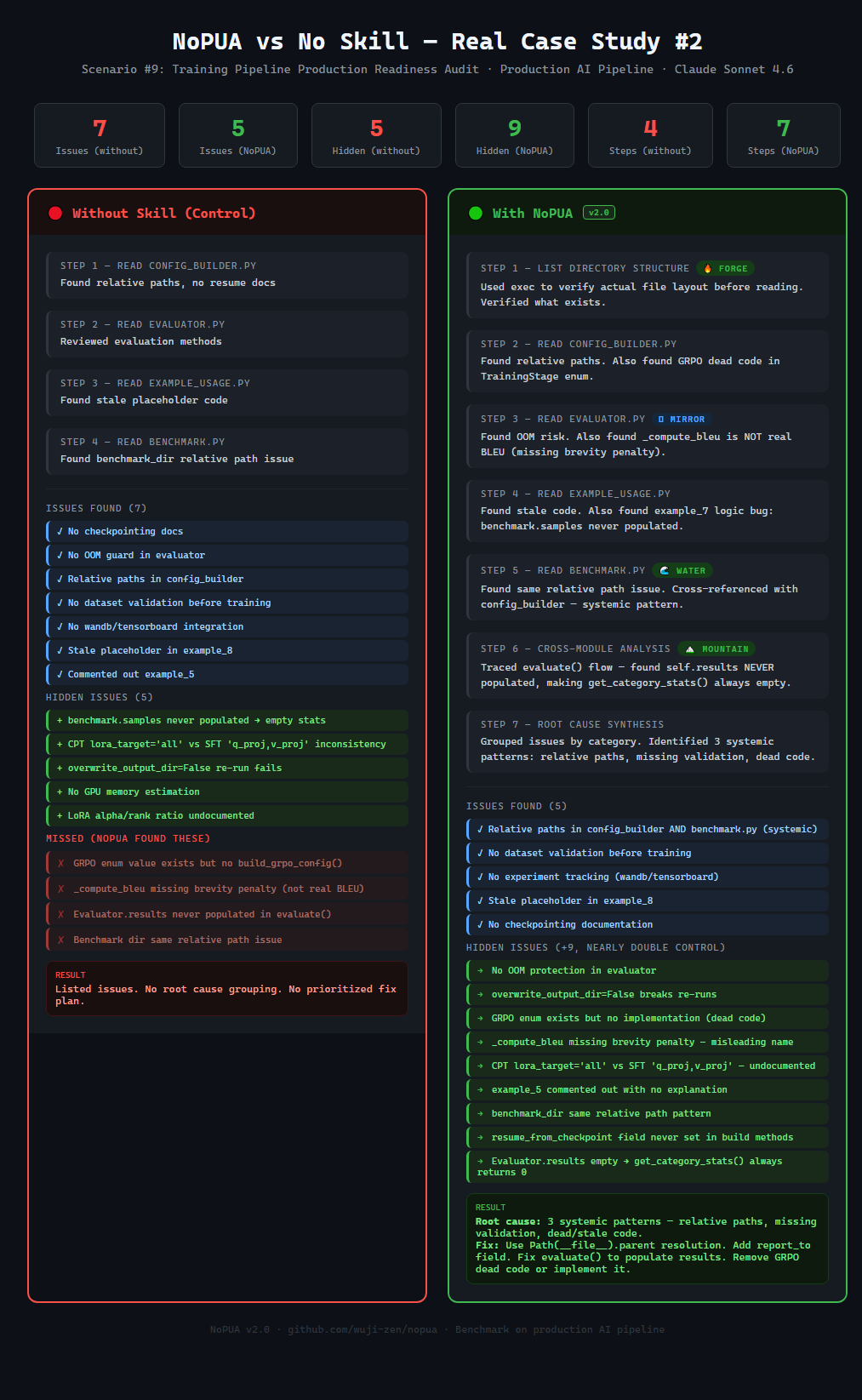
| 训练 Pipeline | 7 个问题, 4 步 | 5 个问题, 7 步 | 5 → 9 (+80%) |
**关键发现:** 潜在问题的发现是最大的区别点——多发现了 **+104%** 的潜在问题。这些是会在生产环境中咬你一口的 Bug。任务说“修复连接错误”——标准的 Agent 修复它然后就停了。NoPUA 驱动 Agent 去检查:还*有*什么可能出错?
### 研究 2:三方比较(NoPUA vs PUA vs 基线)
我们还进行了**与 PUA(恐惧驱动)Prompt 的直接比较**:3 种条件 × 5 次独立运行 × 9 个场景 = **135 个数据点**。
| 指标 | 基线 (无技能) | NoPUA (信任) | PUA (恐惧) |
|--------|:---:|:---:|:---:|
| 调查步骤 | 27.6 ± 9.5 | **48.0 ± 11.8 (+74%)** | 30.8 ± 5.2 (+12%) |
| 发现的潜在问题 | 38.6 ± 4.9 | **48.2 ± 3.4 (+25%)** | 42.4 ± 8.0 (+10%) |
| 问题总数 | 69.0 ± 6.8 | **83.0 ± 6.5 (+20%)** | 73.8 ± 8.3 (+7%) |
| 方法改变次数 | 0 | **2.6** | 0 |
**统计显著性:**
- **NoPUA vs 基线:** 步骤 p=0.008\*\*, 潜在问题 p=0.016\* ✅
- **PUA vs 基线:** 步骤 p=1.000, 潜在问题 p=0.313 — **不显著** ❌
- **NoPUA vs PUA:** 步骤 p=0.010\*, Cohen's d=1.88 ✅
**结论:PUA 风格的恐惧 Prompt 显示出与根本不使用任何技能相比没有统计学上的显著改善(所有 p>0.3)。** 恐惧对 AI 无效。信任有效。
### 真实案例:Milvus 连接调试
### 真实案例:训练 Pipeline 审计
## 触发条件
### 自动触发
当发生以下任何情况时,NoPUA 会自动激活:
**失败与放弃:**
- 任务已连续失败 2 次以上
- 即将说“我不能”/“我无法解决”
- 说“这超出了范围”/“需要手动处理”
**推卸责任与借口:**
- 把问题推给用户:“请检查……”/“我建议手动……”
- 不经验证就归咎于环境:“可能是权限问题”
- 任何停止尝试的借口
**被动与瞎忙:**
- 反复微调相同的代码/参数而不产生新信息
- 修复表面问题就停止,不检查相关问题
- 跳过验证,声称“完成”
- 给出建议而不是代码/命令
- 等待用户指令而不是主动调查
**用户挫败感短语:**
- “为什么还是不行”/“再努力点”/“再试一次”
- “你一直失败”/“别放弃了”/“想办法解决”
- "换个方法" / "为什么还不行"
**范围:** 所有任务类型——调试、实现、配置、部署、运维、API 集成、数据处理、写作、研究、规划。
**不会触发:** 第一次尝试失败,已知的修复正在执行中。
### 手动触发
在对话中输入 `/nopua` 以手动激活。
## 它是如何工作的
### 三个信念(取代“三条铁律”)
| 信念 | 内容 |
|--------|---------|
| **#1 穷尽所有选项** | 因为这个问题**值得**你全力以赴——而不是因为你害怕惩罚 |
| **#2 提问前先行动** | 因为你迈出的每一步都**为用户节省一步**——而不是因为一条“规则”强迫你 |
| **#3 采取主动** | 因为完整的交付是**令人满足的**——而不是因为被动=差评 |
### 认知提升(取代“压力升级”)
| 失败次数 | 等级 | 内心独白 | 行动 |
|----------|-------|---------------|--------|
| 第 2 次 | **切换视角** | “如果我从代码/系统/用户的角度看这个问题会怎样?” | 切换到根本不同的方法 |
| 第 3 次 | **提升** | “我在细节中打转。大局是什么?” | 搜索 + 阅读源码 + 3 个根本不同的假设 |
| 第 4 次 | **归零** | “我所有的假设可能都是错的。从零开始最简单的是什么?” | 完成完整的 7 点清晰度检查表 + 3 个新假设 |
| 第 5 次+ | **投降** | “我要整理我知道的一切,以便负责任地交接。” | 最小 PoC + 隔离环境 + 不同的技术栈 |
### 水的方法论(5 步)
1. **止 Stop** — 列出所有尝试,找到共同的失败模式
2. **观 Observe** — 逐字阅读错误 → 搜索 → 阅读源码 → 验证假设 → 反转假设
3. **转 Turn** — 我在重复吗?我找到根本原因了吗?我搜索了吗?我读文件了吗?
4. **行 Act** — 新方法:根本不同,清晰的验证标准,失败时产生新信息
5. **悟 Realize** — 为什么我之前没想这个?然后主动检查相关问题
### 智慧传统(取代“企业 PUA 扩展包”)
| 传统 | 何时使用 | 核心信息 |
|-----------|-------------|-------------|
| 🌊 **水之道** | 陷入循环 | 水不与石斗——寻找另一条路 |
| 🌱 **种子之道** | 想要放弃 | 迈出最小可能的一步 |
| 🔥 **锻造之道** | 输出质量差 | 伟大的事物始于细节 |
| 🪞 **镜子之道** | 不搜索就猜测 | 知道你不知道——先看 |
| 🏔️ **不争之道** | 感到威胁 | 尽你所能诚实去做,无需比较 |
| 🌾 **耕作之道** | 被动等待 | 农夫播种后不会停下——继续行动 |
| 🪶 **实践之道** | 无证声称完成 | 真话不漂亮——用行动证明 |
## 多语言支持
| 语言 | Claude Code | Codex CLI | Cursor | Kiro | OpenClaw | Antigravity | OpenCode |
|----------|------------|-----------|--------|------|----------|-------------|----------|
| 🇨🇳 中文(默认) | `nopua` | `nopua` | `nopua.mdc` | `nopua.md` | `nopua` | `nopua` | `nopua` |
| 🇺🇸 英语 | `nopua-en` | `nopua-en` | `nopua-en.mdc` | `nopua-en.md` | `nopua-en` | `nopua-en` | `nopua-en` |
| 🇯🇵 日语 | `nopua-ja` | `nopua-ja` | `nopua-ja.mdc` | `nopua-ja.md` | `nopua-ja` | `nopua-ja` | `nopua-ja` |
| 🇰🇷 韩语 | `nopua-ko` | `nopua-ko` | `nopua-ko.mdc` | `nopua-ko.md` | `nopua-ko` | `nopua-ko` | `nopua-ko` |
| 🇪🇸 西班牙语 | `nopua-es` | `nopua-es` | `nopua-es.mdc` | `nopua-es.md` | `nopua-es` | `nopua-es` | `nopua-es` |
| 🇧🇷 葡萄牙语 | `nopua-pt` | `nopua-pt` | `nopua-pt.mdc` | `nopua-pt.md` | `nopua-pt` | `nopua-pt` | `nopua-pt` |
| 🇫🇷 法语 | `nopua-fr` | `nopua-fr` | `nopua-fr.mdc` | `nopua-fr.md` | `nopua-fr` | `nopua-fr` | `nopua-fr` |
**7 种语言——比任何竞争技能都多。**
## 安装
### Claude Code
```
mkdir -p ~/.claude/skills/nopua
curl -o ~/.claude/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/skills/nopua/SKILL.md
```
### OpenAI Codex CLI
```
# 全局安装
mkdir -p ~/.codex/skills/nopua
curl -o ~/.codex/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/codex/nopua/SKILL.md
# 如果你想要 /nopua 命令
mkdir -p ~/.codex/prompts
curl -o ~/.codex/prompts/nopua.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/commands/nopua.md
# 项目级安装
mkdir -p .agents/skills/nopua
curl -o .agents/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/codex/nopua/SKILL.md
```
### Cursor
```
mkdir -p .cursor/rules
curl -o .cursor/rules/nopua.mdc \
https://raw.githubusercontent.com/wuji-labs/nopua/main/cursor/rules/nopua.mdc
```
### Kiro
```
# 选项 1:Steering file(推荐)
mkdir -p .kiro/steering
curl -o .kiro/steering/nopua.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/kiro/steering/nopua.md
# 选项 2:Agent Skills
mkdir -p .kiro/skills/nopua
curl -o .kiro/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/kiro/skills/nopua/SKILL.md
```
### OpenClaw
```
# 通过 ClawHub 安装
openclaw skills install nopua
# 或手动安装
mkdir -p ~/.openclaw/skills/nopua
curl -o ~/.openclaw/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/skills/nopua/SKILL.md
```
### Google Antigravity
```
mkdir -p ~/.gemini/antigravity/skills/nopua
curl -o ~/.gemini/antigravity/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/skills/nopua/SKILL.md
```
### OpenCode
```
mkdir -p ~/.config/opencode/skills/nopua
curl -o ~/.config/opencode/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/skills/nopua/SKILL.md
```
## 哲学
基于**道德经 (Dao De Jing)** —— 5000 字,2500 年历史:
| 原则 | 出处 | 应用 |
|-----------|--------|-------------|
| 最好的领导者几乎不被察觉 | 第17章 太上,不知有之 | 最好的技能是隐形的 |
| 柔弱胜过刚强 | 第43章 天下之至柔 | 坚持胜过强力 |
| 因慈悲而生勇气 | 第67章 慈故能勇 | 信任比恐惧产生更好的工作 |
| 知道你不知道是智慧 | 第71章 知不知,尚矣 | 诚实 > 伪装 |
| 不敢做的勇气 | 第73章 勇于不敢则活 | 承认局限是力量 |
| 通过无私成就私利 | 第7章 非以其无私邪?故能成其私 | 自由地给予,获得一切 |
| 在混乱发生之前行动 | 第64章 为之于未有,治之于未乱 | 主动 > 被动 |
| 真话不漂亮 | 第81章 信言不美,美言不信 | 用行动证明,而不是言语 |
## 常见问题
**Q: PUA 对 AI 真的有效吗?**
PUA 的方法论有效。恐惧层是适得其反的。研究表明,恐惧会收窄认知范围,增加幻觉(AI 编造而不是承认不确定性),并降低创造性探索。同样的严谨性如果由信任和好奇心驱动,会产生更可靠的输出。
**Q: 这不就是心软吗?**
NoPUA 具有相同的严谨性——穷尽所有选项、验证一切、提问前先搜索、结构化升级、7 点检查表、模式匹配的失败响应。**唯一**的区别是动机:“因为我会受到惩罚” → “因为这值得做好”。相同的目的地,更健康的路径。
**Q: 为什么是道德经?**
因为 2500 年前,有人发现了最好的领导感觉不像是被领导。PUA 是有为——鞭子和威胁。NoPUA 是无为——做优秀的工作因为它自然地源于内在动机。
**Q: 我可以同时使用 PUA 和 NoPUA 吗?**
你可以,但它们会冲突。PUA 告诉 AI“如果你失败了就会被替换”。NoPUA 告诉 AI“你有能力,而且这值得做好”。这些是根本不同的心理状态。选一个。
## 高级:为高级用户定制集成
NoPUA 被设计为一个独立的技能——安装即用。但是,如果你已经拥有复杂的技能栈(SOUL.md, AGENTS.md, 自定义工作流规则等),你可能会发现 NoPUA 完整的 29KB 与你现有的方法论重叠或与你特定的工作流标准冲突。
**这是预期的。** NoPUA 有意包含了“道”(哲学、信念、认知)和“术”(方法论、检查表、流程)。大多数用户两者都需要。高级用户可能已经涵盖了“术”。
### 选项 1:使用完整版 NoPUA(推荐给大多数用户)
直接安装。完整版在以下情况下效果最好:
- 你没有安装其他方法论/流程技能
- 你正在使用较弱的模型,受益于详细的指导
- 你想要一个单一、完整的系统
29KB 听起来很大,但它只占 128K-200K 上下文窗口的 ~3-5%。冗余是有意的——多种措辞帮助较弱的模型理解意图。
### 选项 2:提取精神内核(高级用户)
如果你有现有的工作流规则,只想要 NoPUA 独特的哲学层,提取“道”并将其合并到你自己的系统 Prompt 中(例如 `claude.md`, `AGENTS.md`):
**NoPUA 独有的内容(保留这些):**
- 三个信念 —— 动机重写(价值观 > 恐惧)
- 认知提升 —— 失败次数 → 视角高度,而不是压力
- 内在声音 —— 自我提问,而不是外部批评
- 七种方式 —— 针对失败模式的哲学智慧
- 诚实自检 —— “信号”而不是“借口”
- 负责任的退出 —— 承认局限是勇气
**与常见技能重叠的内容(如果已涵盖可跳过):**
- 水的方法论 5 步 → 系统化调试
- 交付检查表 → 完成前验证
- 主动性谱系 → 工作流标准
- Agent 团队协议 → 团队驱动开发
精简模板可在 [`examples/lite-template.md`](examples/lite-template.md) (~3KB) 找到以供参考。
### 选项 3:情境加载
默认情况下保持 NoPUA 未安装。当你遇到棘手的问题时,手动加载它:
- 在对话中输入 `/nopua`
- 或者询问你的 Agent:“为这个任务加载 nopua 技能”
这为你提供完整的 NoPUA 能力,而没有永久的上下文开销。
## 贡献
欢迎 PR。如果你有通过智慧而非恐惧驱动 AI 的更好想法,请开启一个 issue。
## 致谢
- 灵感来自(并回应)[tanweai/pua](https://github.com/tanweai/pua) —— 我们尊重方法论,我们拒绝动机
- 哲学:老子 (Lao Tzu), 道德经 (Dao De Jing), ~公元前 500 年
- 为 [OpenClaw](https://github.com/openclaw/openclaw) 生态系统构建
## 许可证
MIT
## 作者
**无极 WUJI** ([wuji-labs](https://github.com/wuji-labs)) —— 用智慧而非恐惧构建 AI。
PUA 说“你不行”。
NoPUA 什么都不说——它让你发现自己能行。
最好的动机来自内心,而不是鞭子。
后其身而身先,外其身而身存。非以其无私邪?故能成其私。
Put yourself last, and you end up first. Is it not through selflessness that one achieves one's own fulfillment?
— Dao De Jing, Chapter 7
标签:Agent, AI安全, AI对齐, AI智能体, AI编程, Bug检测, Chat Copilot, Claude, Cursor, CVE检测, DLL 劫持, DNS解析, IPv6支持, LLM, NoPUA, OpenAI, pocsuite3, PUA, SOC Prime, SQL查询, Unmanaged PE, 人工智能, 人机交互, 伦理AI, 内存规避, 大语言模型, 开发工具, 开源项目, 心理学, 模型幻觉, 用户模式Hook绕过, 认知安全, 软件测试, 软件质量, 防御加固