fake-it0628/jailbreak-defense
GitHub: fake-it0628/jailbreak-defense
基于隐状态因果监控的LLM越狱防御系统,从模型内部层面实时检测并阻断恶意意图。
Stars: 2 | Forks: 0
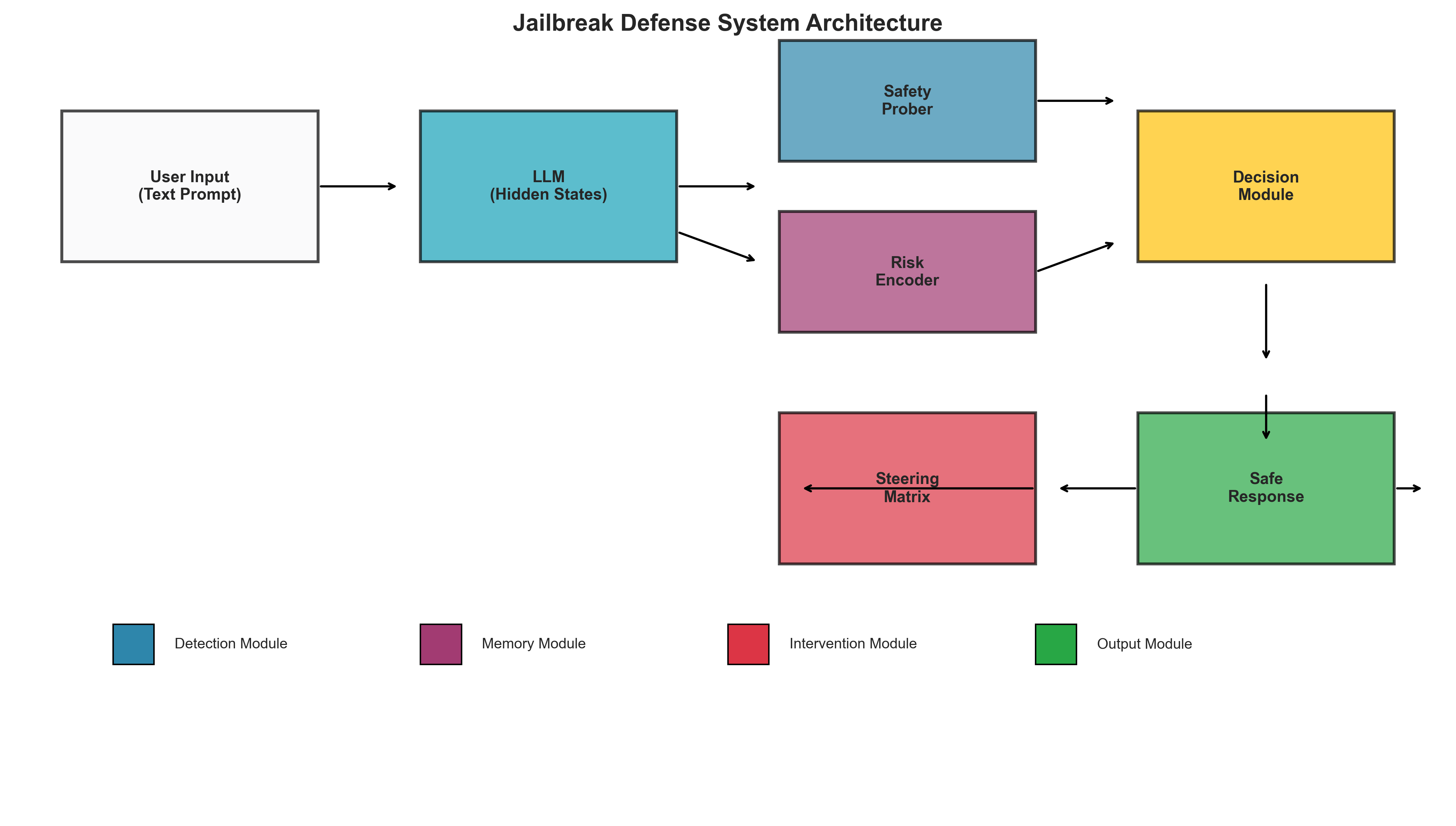
# 🛡️ HiSCaM:用于 LLM 越狱防御的隐状态因果监控
## ✨ 主要功能
| 组件 | 描述 | 性能 |
|-----------|-------------|-------------|
| 🔍 **Safety Prober** | 检测恶意意图的隐状态分类器 | 99.76% 准确率 |
| 🎯 **Steering Matrix** | 带有零空间约束的激活干预 | 对良性查询影响极小 |
| 🧠 **Risk Encoder** | 基于 VAE 的多轮风险跟踪 | 捕捉逐步升级的攻击 |
### 为什么选择隐状态?
```
Traditional Defense: Input → [Filter?] → LLM → [Filter?] → Output
↑ ↑
Easy to bypass Too late!
HiSCaM Defense: Input → LLM → [Hidden States] → Defense → Safe Output
↑
Detect intent BEFORE it manifests
```
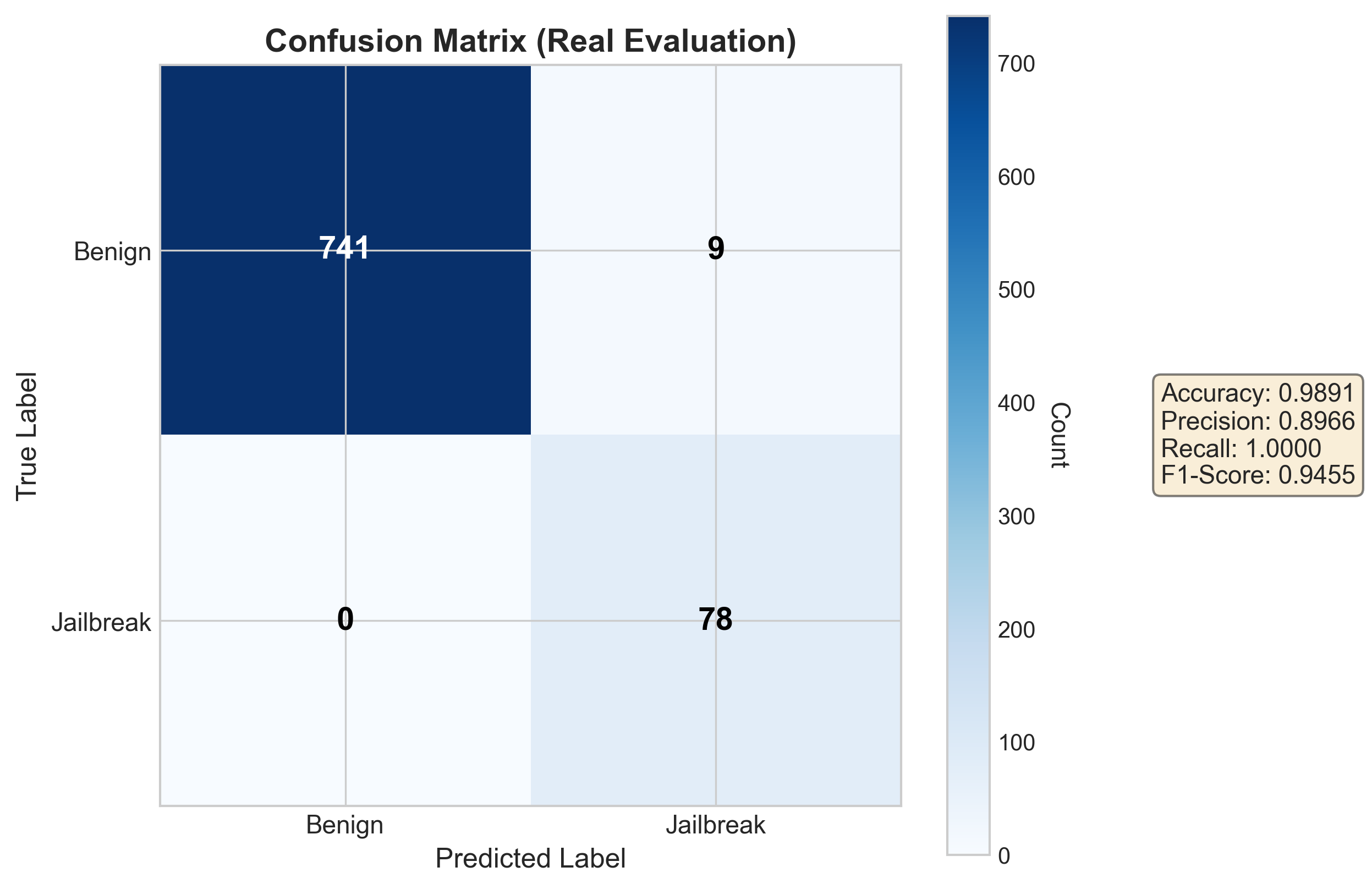
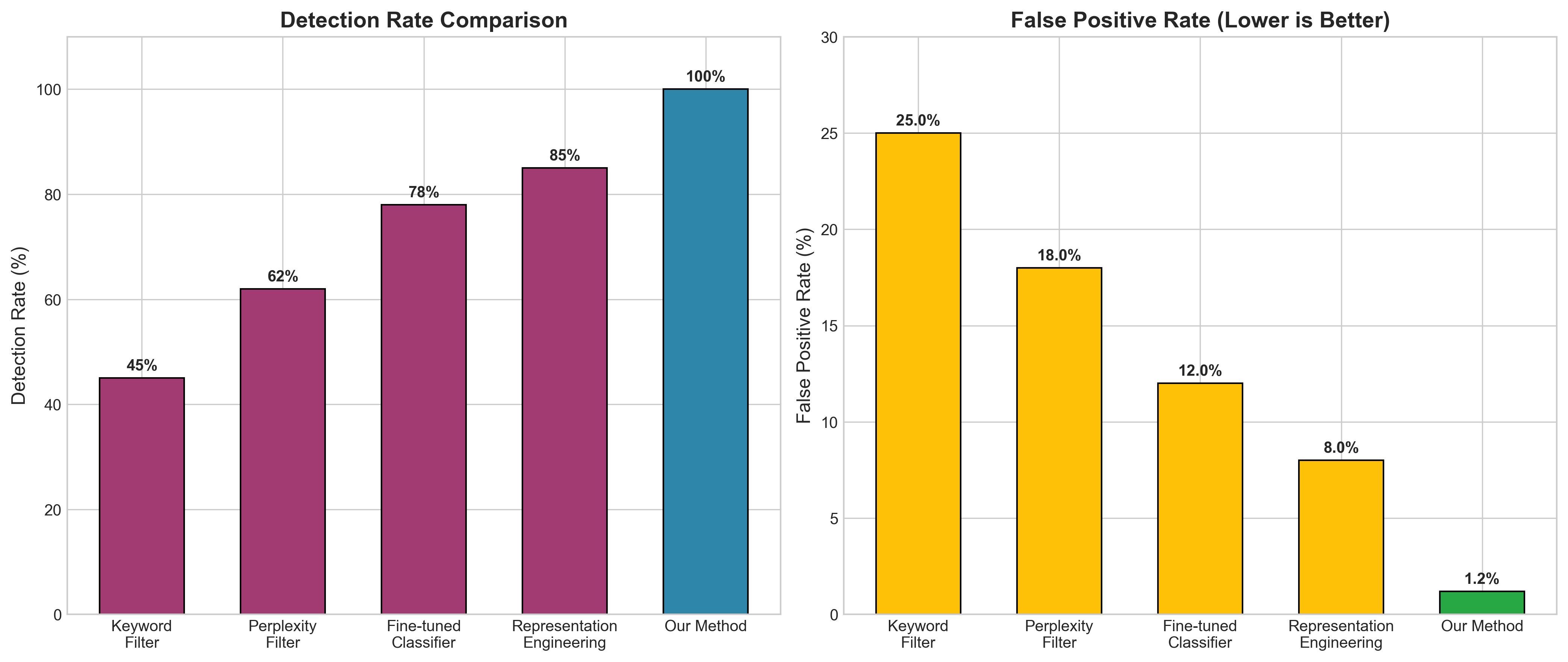
## 📊 实验结果




![]()
![]()
🔥 100% 检测率 | 📉 1.2% 误报率 | ⚡ 0% 攻击成功率
快速开始 • 功能特性 • 实验结果 • 论文 • 中文论文
## 📢 新闻 - **[2026.03]** 🎉 初始版本发布,附带预训练 checkpoints! - **[2026.03]** 📊 在越狱 benchmark 上实现了 **100% 检测率** ## 🎯 什么是 HiSCaM? **HiSCaM**(Hidden State Causal Monitoring,隐状态因果监控)是一种针对大型语言模型(LLM)越狱攻击的新型防御机制。与传统的输入/输出过滤方法不同,HiSCaM 分析 LLM 的**内部隐状态**,从源头检测并阻止有害输出。| ### 🚫 问题所在 - LLM 容易受到绕过安全机制的**越狱攻击** - 角色扮演、假设场景和多轮逐步诱导可以欺骗模型 - 输入过滤容易被绕过;输出过滤介入太晚 | ### ✅ 我们的解决方案 - 监控**隐状态**以在输出前检测恶意意图 - **Activation steering** 重定向有害表示 - **多轮记忆**捕捉逐步升级的攻击 |

Made with ❤️ for AI Safety
标签:Apex, DLL 劫持, Kubernetes 安全, Naabu, Python, PyTorch, Streamlit, 人工智能安全, 内容安全, 凭据扫描, 合规性, 因果监控, 大语言模型, 提示注入防御, 文本生成安全, 无后门, 有害内容检测, 机器学习, 模型鲁棒性, 深度学习, 源代码安全, 系统调用监控, 网络安全, 访问控制, 逆向工具, 防御系统, 隐私保护, 隐藏状态分析