Yashchaudhary0809/KubeHeal
GitHub: Yashchaudhary0809/KubeHeal
KubeHeal 是一个基于 Prometheus 告警事件驱动 Kubernetes 工作负载自动修复的运维自愈系统。
Stars: 1 | Forks: 2
# KubeHeal
事件驱动的应急响应系统 - Kubernetes & Prometheus
# 事件驱动的自动修复系统
## 📘 项目概述
本项目使用事件驱动架构为 Kubernetes 实现了一个自动化应急响应系统。该系统可以监控应用程序、检测故障,并在无需人工干预的情况下执行自动修复。
## 🎯 目标
- 实时监控 Kubernetes 工作负载
- 自动检测故障
- 通过修复引擎实现自愈
- 减少人工 DevOps 工作
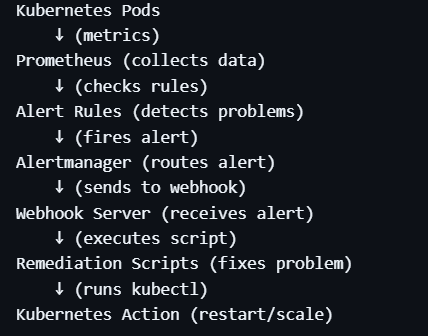
## 🧱 架构
Prometheus → Alertmanager → Webhook → 修复引擎 → Kubernetes 操作
 ## 🛠 技术
- Kubernetes (Minikube)
- Prometheus & Alertmanager
- Python Flask
- Docker
- kubectl
## 👥 团队角色
- 成员 1:Prometheus & Grafana 设置
- 成员 2:告警规则配置
- 成员 3:修复脚本 & GitHub
## 📂 结构
- devops-incident-response/
- ├── kubernetes/
- │ ├── alert-rules.yaml # 告警检测规则
- │ └── alertmanager-config.yaml # 告警路由配置
- ├── scripts/
- │ └── remediation-scripts.sh # 自动修复脚本
- ├── monitoring/
- │ └── prometheus-values.yaml # Prometheus 配置
- ├── docs/
- │ ├── SETUP.md # 安装指南
- │ ├── DEMO_INSTRUCTIONS.md # 演示说明
- │ └── TEAM_WORKFLOW.md # Git 工作流指南
- ├── README.md # 本文件
- └── .gitignore # 忽略文件
## 🚀 运行方式
1. 启动 Minikube
2. 部署示例应用
3. 安装 Prometheus
4. 配置告警
## 截图
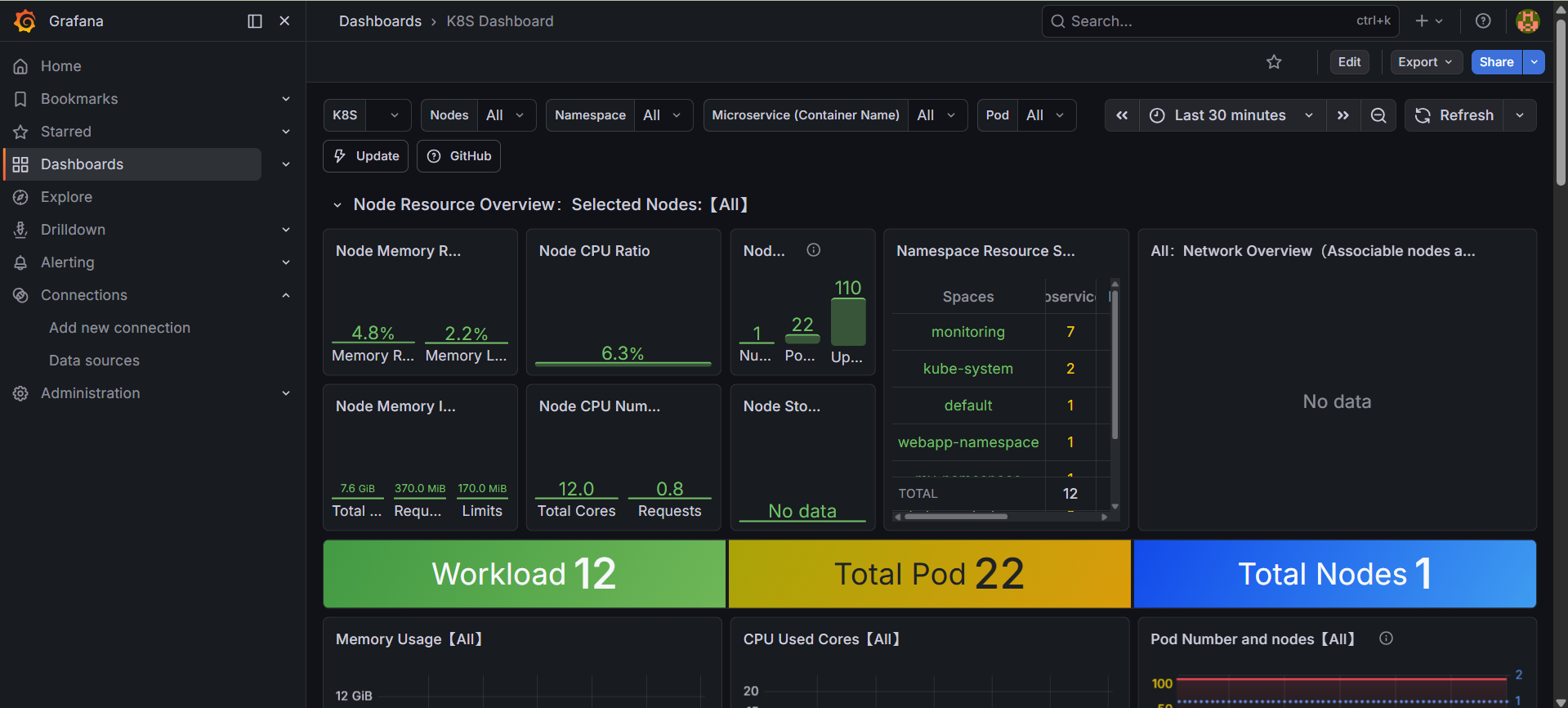
1. Grafana Dashboard
## 🛠 技术
- Kubernetes (Minikube)
- Prometheus & Alertmanager
- Python Flask
- Docker
- kubectl
## 👥 团队角色
- 成员 1:Prometheus & Grafana 设置
- 成员 2:告警规则配置
- 成员 3:修复脚本 & GitHub
## 📂 结构
- devops-incident-response/
- ├── kubernetes/
- │ ├── alert-rules.yaml # 告警检测规则
- │ └── alertmanager-config.yaml # 告警路由配置
- ├── scripts/
- │ └── remediation-scripts.sh # 自动修复脚本
- ├── monitoring/
- │ └── prometheus-values.yaml # Prometheus 配置
- ├── docs/
- │ ├── SETUP.md # 安装指南
- │ ├── DEMO_INSTRUCTIONS.md # 演示说明
- │ └── TEAM_WORKFLOW.md # Git 工作流指南
- ├── README.md # 本文件
- └── .gitignore # 忽略文件
## 🚀 运行方式
1. 启动 Minikube
2. 部署示例应用
3. 安装 Prometheus
4. 配置告警
## 截图
1. Grafana Dashboard
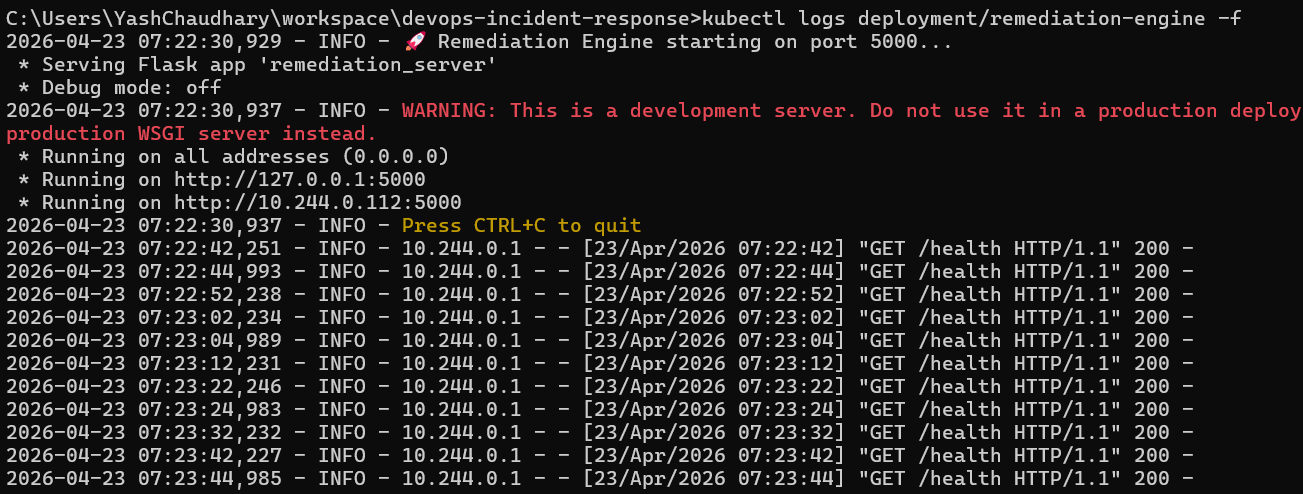
 2. 修复引擎运行中
2. 修复引擎运行中
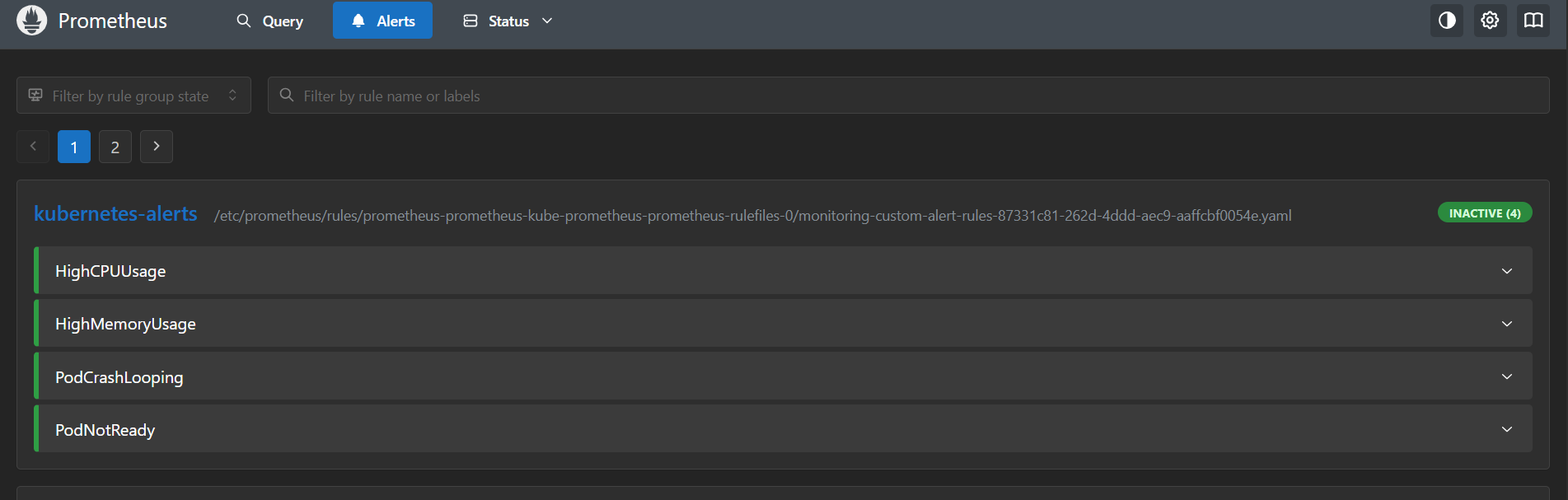
 3. Prometheus 显示告警
3. Prometheus 显示告警
 4. 告警触发
4. 告警触发
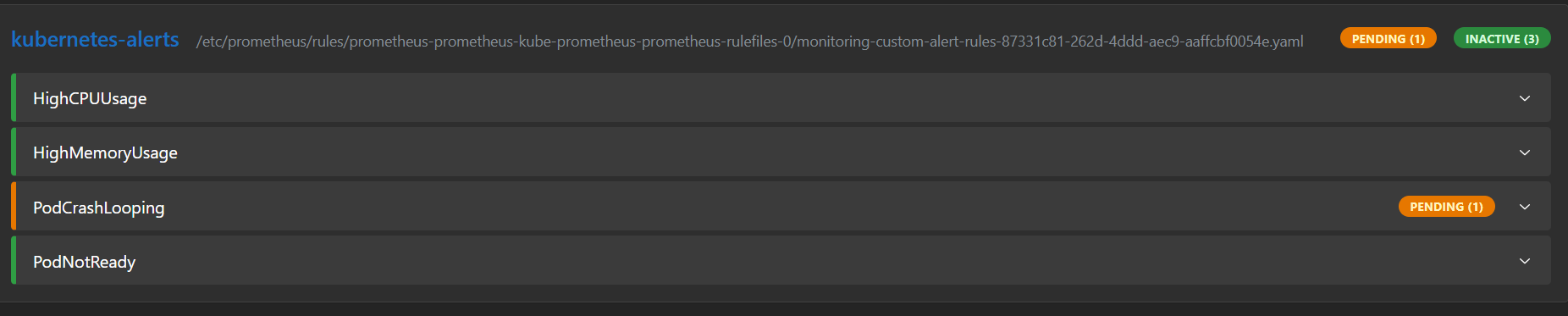 5. 告警激发
5. 告警激发
 6. 修复引擎重启 pod
6. 修复引擎重启 pod
 ## 📌 未来规划
- Email/短信通知
- 基于 AI 的决策引擎
- 多集群支持
## 📌 未来规划
- Email/短信通知
- 基于 AI 的决策引擎
- 多集群支持
## 🛠 技术
- Kubernetes (Minikube)
- Prometheus & Alertmanager
- Python Flask
- Docker
- kubectl
## 👥 团队角色
- 成员 1:Prometheus & Grafana 设置
- 成员 2:告警规则配置
- 成员 3:修复脚本 & GitHub
## 📂 结构
- devops-incident-response/
- ├── kubernetes/
- │ ├── alert-rules.yaml # 告警检测规则
- │ └── alertmanager-config.yaml # 告警路由配置
- ├── scripts/
- │ └── remediation-scripts.sh # 自动修复脚本
- ├── monitoring/
- │ └── prometheus-values.yaml # Prometheus 配置
- ├── docs/
- │ ├── SETUP.md # 安装指南
- │ ├── DEMO_INSTRUCTIONS.md # 演示说明
- │ └── TEAM_WORKFLOW.md # Git 工作流指南
- ├── README.md # 本文件
- └── .gitignore # 忽略文件
## 🚀 运行方式
1. 启动 Minikube
2. 部署示例应用
3. 安装 Prometheus
4. 配置告警
## 截图
1. Grafana Dashboard
2. 修复引擎运行中
3. Prometheus 显示告警
4. 告警触发
5. 告警激发
6. 修复引擎重启 pod
## 📌 未来规划
- Email/短信通知
- 基于 AI 的决策引擎
- 多集群支持标签:Pandas, WSL, 子域名突变, 模块化设计, 自动化修复, 自定义请求头, 请求拦截, 运维