nash-dir/diffinite
GitHub: nash-dir/diffinite
Diffinite 是一款用于知识产权诉讼的取证级源代码比对工具,基于 Winnowing 指纹算法检测代码复用,并生成带 Bates 编号的法庭可用 PDF 报告。
Stars: 0 | Forks: 0
# Diffinite
[](https://pypi.org/project/diffinite/)
[](https://github.com/nash-dir/diffinite/actions/workflows/ci.yml)
[](LICENSE)
[](https://pypi.org/project/diffinite/)
**用于知识产权诉讼和代码审计的取证级源代码比对工具。**
Diffinite 会比对两个源代码目录,并生成专业的 PDF/HTML 报告,报告中包含带语法高亮的并排差异比对。它使用 [Winnowing 指纹](https://theory.stanford.edu/~aiken/publications/papers/sigmod03.pdf)(Schleimer 等人,2003 —— 即 [Stanford MOSS](https://theory.stanford.edu/~aiken/moss/) 背后的算法)进行 N:M 交叉匹配,即使文件被重命名、拆分或合并,也能检测出代码复用情况。
## VS Code 扩展
**在 Windows 上**使用 Diffinite 的推荐方式是通过 **VS Code 扩展**,该扩展内置了嵌入式 Python 运行时 —— 无需单独安装 Python。在 macOS/Linux 上,该扩展将运行于系统 Python 之上(`pip install diffinite`,然后设置 `diffinite.pythonPath`)—— 参见[平台支持](#platform-support)。
### 功能
- **可视化目录选择器** — 通过 GUI 面板选择两个目录并配置选项
- **实时进度条** — 分析期间实时跟踪百分比
- **分析前时间预估** — 预先扫描文件大小并预估 Simple/Deep 模式的持续时间
- **动态 CPU 校准** — 对第一阶段进行性能基准测试,以优化第二阶段的时间预测
- **OOM 防御** — 在分析超过 5MB 的文件对之前发出警告
- **交互式树状查看器** — 查看匹配对并选择性导出
- **一键导出 PDF/HTML** — 附带 Bates 编号、页码和文件名注释
### 从源码安装
```
cd vscode-extension
npm install
npm run compile
# 在 VS Code 中按 F5 启动 Extension Development Host
```
## CLI 安装
```
pip install diffinite
```
或从源码安装:
```
git clone https://github.com/nash-dir/diffinite.git
cd diffinite
pip install -e ".[dev]"
```
**环境要求**: Python ≥ 3.10
**依赖项**: [RapidFuzz](https://github.com/rapidfuzz/RapidFuzz), [Pygments](https://pygments.org/), [xhtml2pdf](https://github.com/xhtml2pdf/xhtml2pdf), [pypdf](https://github.com/py-pdf/pypdf), [reportlab](https://docs.reportlab.com/), [charset-normalizer](https://github.com/Ousret/charset_normalizer)
## 平台支持
| 组件 | Windows | Linux | macOS |
|-----------|:-------:|:-----:|:-----:|
| **CLI** (`pip install diffinite`) | ✅ 支持 | ✅ 已在 CI 中测试 | ◯ 预期可运行(纯 Python;未在 CI 中测试) |
| **VS Code 扩展** | ✅ 内置嵌入式 Python 运行时;主要测试目标 | △ 通过系统 Python 运行(`pip install diffinite` + `diffinite.pythonPath`);未经官方测试 | △ 同 Linux;未经官方测试 |
已发布的 VS Code 扩展专为 **Windows** (`win32-x64`) 打包,并内置了运行时。在 macOS/Linux 上,请直接使用 CLI,或通过 `diffinite.pythonPath` 设置将扩展指向你自己的解释器。CLI 本身是纯 Python 实现的,与平台无关。
## 快速开始
```
# 比较两个目录 → PDF 报告
diffinite original/ suspect/ -o report.pdf
# 带有注释剥离和 Bates numbering (forensic use)
diffinite original/ suspect/ -o report.pdf \
--strip-comments --bates-number --page-number --filename
# HTML 报告 (单个自包含文件,在浏览器中打开)
diffinite original/ suspect/ --report-html report.html
```
## 工作原理
Diffinite 运行一个两阶段的 pipeline:
### 阶段 1:1:1 文件匹配(`simple` 模式)
1. **模糊名称匹配** — 使用 [RapidFuzz](https://github.com/rapidfuzz/RapidFuzz) 字符串相似度(可配置阈值)将 `dir_a` 和 `dir_b` 中的文件进行配对。
2. **移除注释** — 使用支持 45 种以上文件扩展名的 6 状态有限状态机解析器,可选地移除代码中的注释。
3. **并排 diff** — 使用 Python 的 `difflib.SequenceMatcher`(开启 `autojunk=True`)计算逐行(或逐词)的 diff,这是一种会丢弃高频行以加快大文件匹配速度的启发式算法(`SequenceMatcher` 本身的时间复杂度仍为最坏情况下的二次方)。
4. **生成报告** — 通过 Pygments 渲染带语法高亮的 HTML diff,然后使用 xhtml2pdf 将其转换为 PDF。
### 阶段 2:N:M 交叉匹配(`deep` 模式,默认)
5. **提取 Winnowing 指纹** — 使用 Winnowing 算法(K-gram → 滚动哈希 → 窗口选择)提取与位置无关的代码指纹。
6. **构建倒排索引** — 为所有 B 目录的指纹构建哈希到文件的映射。
7. **计算 Jaccard 相似度** — 对于每一个 A 文件,查询索引以找出所有共享指纹的 B 文件,然后计算 Jaccard 相似度 `|A∩B| / |A∪B|`。
8. **交叉匹配报告** — 在报告中追加 N:M 相似度矩阵,显示 A 中的哪些文件与 B 中的哪些文件相似。
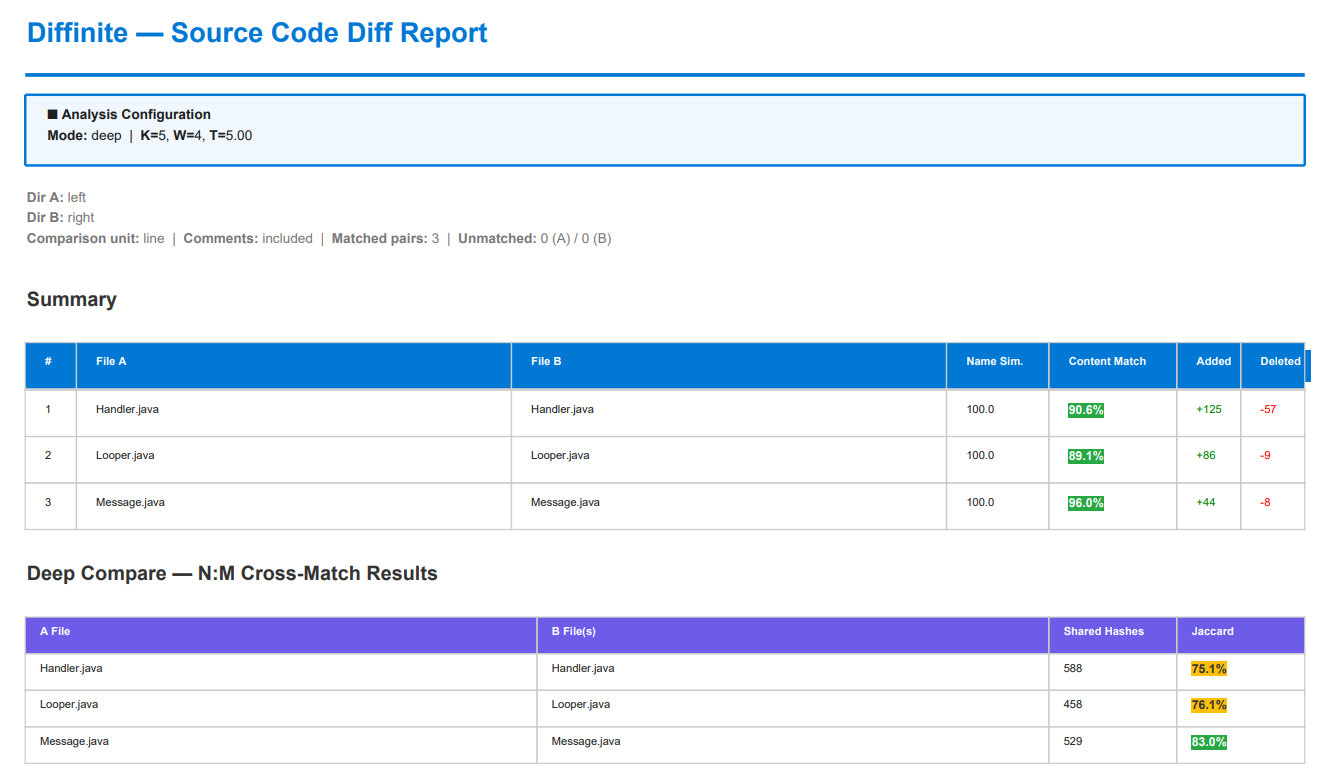
## 输出报告
### 封面
封面包含每个匹配文件对的汇总表:
| 列名 | 描述 |
|--------|-------------|
| **File A / File B** | 匹配的文件路径 |
| **Name Sim.** | 模糊文件名相似度得分 (0–100) |
| **Content Match** | `difflib.SequenceMatcher.ratio()` — 匹配内容的比例。`1.0` = 完全相同。 |
| **Added / Deleted** | 为了由 File A 生成 File B 而增加或删除的行(或词)数。 |
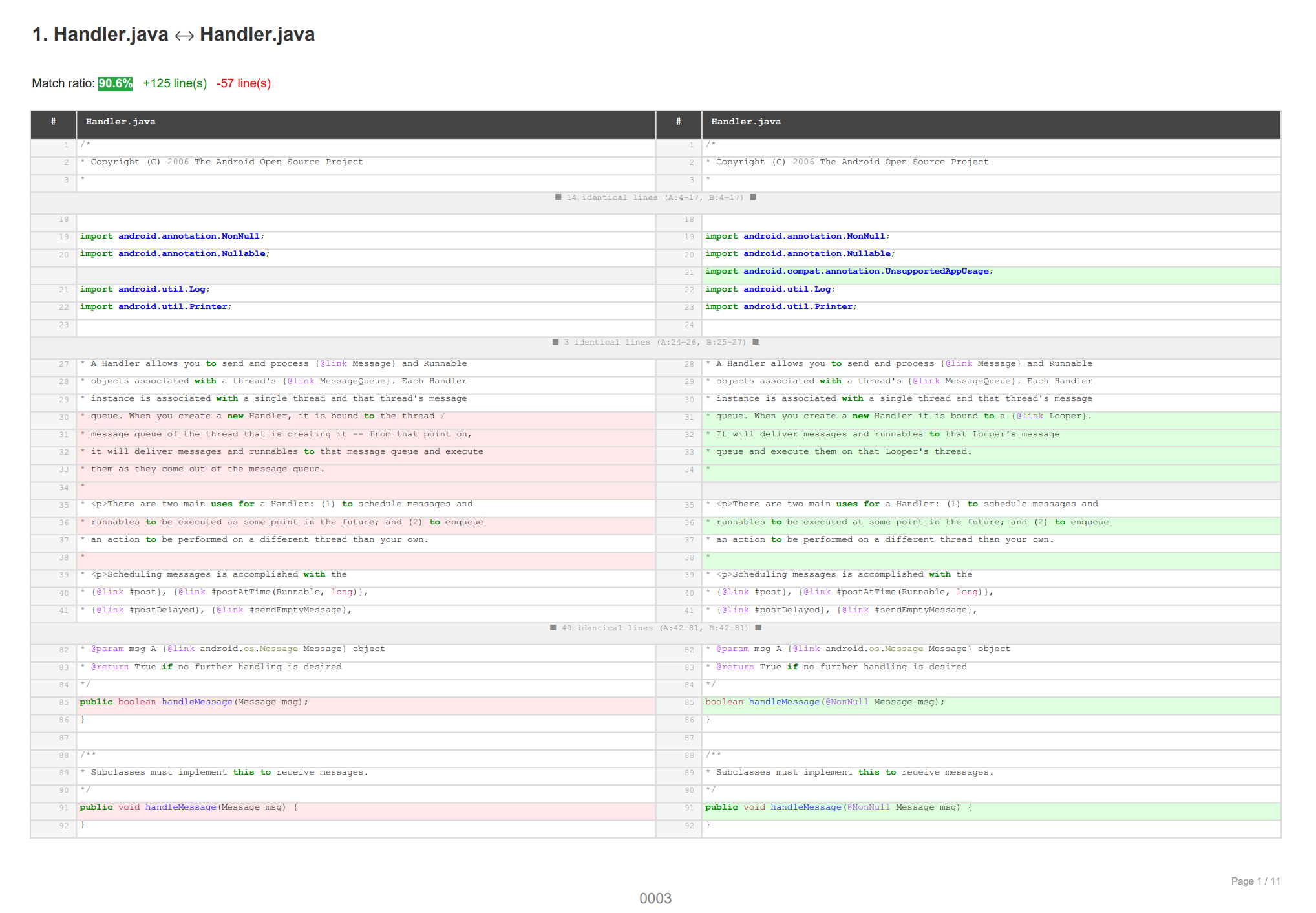
### Diff 页面
每一对匹配项都会得到一个并排的 diff 页面,其中包含:
- **绿色高亮** — 仅在 File B 中存在的行(新增)
- **红色高亮** — 仅在 File A 中存在的行(删除)
- **黄色高亮** — 在 A 和 B 之间发生更改的行;在 `--by-word` 模式下,其中更改的词语会被进一步标记(删除的词带有删除线,新增的词加粗显示)
- **紫色高亮** — 从该位置移走的行(`--detect-moved`)
- **蓝色高亮** — 移入该位置的行(`--detect-moved`)
- **无高亮** — 完全相同的行(带有可配置的上下文折叠)
### 深度比对部分
当运行在 `deep` 模式(默认)下时,报告将包含一个 N:M 交叉匹配表:
| 列名 | 描述 |
|--------|-------------|
| **File A** | 来自目录 A 的源文件 |
| **Matched Files (B)** | 目录 B 中所有与该文件共享的指纹高于 Jaccard 阈值的文件 |
| **Shared Hashes** | 该文件对共有的 Winnowing 指纹数量 |
| **Jaccard** | `|A∩B| / |A∪B|` — 共享的 Winnowing 指纹所占的比例。 |
Jaccard 相似度是一个定义明确的集合度量指标。对它的解释取决于具体领域、代码规模和编程语言。Diffinite 仅报告原始数值,不附加任何定性的标签。
### 页面标注
| 选项 | 标注 | 位置 |
|--------|-----------|----------|
| `--page-number` | `Page 3 / 47` | 右下角 |
| `--file-number` | `File 2 / 12` | 左下角 |
| `--bates-number` | `TEST-000003-CONF` | 底部居中 |
| `--filename` | `com/example/Foo.java` | 右上角 |
## CLI 参考
### 位置参数
```
dir_a Path to the original source directory (A)
dir_b Path to the comparison source directory (B)
```
### 执行模式
| 选项 | 默认值 | 描述 |
|--------|:-------:|-------------|
| `--mode {simple,deep}` | `deep` | `simple` = 仅进行 1:1 文件匹配。`deep` = 1:1 + N:M Winnowing 交叉匹配。 |
### 输出选项
| 选项 | 描述 |
|--------|-------------|
| `--report-pdf PATH` (别名 `-o`) | 生成合并的 PDF 报告。如果未给出任何 `--report-*` 标志,则默认为 `report.pdf`。 |
| `--report-html PATH` | 生成独立的 HTML 报告(单文件,无外部依赖) |
| `--report-md PATH` | 生成 Markdown 摘要报告 |
| `--report-json PATH` | 生成机器可读的 JSON 报告(由 VS Code 扩展使用) |
| `--no-merge` | 为每个文件生成单独的 PDF,而不是合并的 PDF |
| `--preserve-tree` / `--no-preserve-tree` | 在单个输出中保留目录树结构(默认:开启) |
| `--sort-by {filename,path,similarity,ratio}` | 在报告中对匹配对进行排序。默认:插入顺序(不排序)。 |
| `--sort-order {asc,desc}` | 排序方向(默认:`asc`)。仅在指定了 `--sort-by` 时有效。 |
### PDF 字体 / CJK 渲染
韩语、日语和中语文本可以在 PDF 输出中正确渲染。默认情况下,使用内置的 xhtml2pdf CJK 字体(`HYGothic-Medium`)作为回退;若要指定特定字体,请使用以下选项之一。HTML 输出依赖于浏览器的原生字体回退机制,无需配置。
| 选项 | 描述 |
|--------|-------------|
| `--pdf-lang {ko,ja,zh-cn,…}` | 根据内置的 `pdf_fonts.json` 映射(包含 Windows/macOS/Linux 路径),自动为指定语言解析最佳的操作系统已安装字体。 |
| `--pdf-font PATH` | 指向 `.ttf`/`.otf` 字体文件的绝对路径,该字体将通过 `@font-face` 嵌入作为主要字体。优先级高于 `--pdf-lang`。 |
### Diff 选项
| 选项 | 默认值 | 描述 |
|--------|:-------:|-------------|
| `--strip-comments` | off | 比较前移除注释(6 状态 FSM 解析器,支持 45+ 种扩展名) |
| `--by-word` | off | 按词而不是按行进行比较 |
| `--squash-blanks` | off | 折叠 3 行及以上的连续空行。⚠️ 会更改行号 —— 不推荐用于取证级的行追踪。 |
| `--threshold N` | `60` | 模糊文件名匹配阈值 (0–100)。数值越低 = 匹配越宽松。 |
| `--collapse-identical` | off | 折叠未更改的代码块(每次更改前后各保留 3 行上下文) |
| `--detect-moved` | off | 检测移动的代码块,并使用不同颜色高亮显示 |
| `--encoding ENC` | `auto` | 强制指定文件编码(例如 `euc-kr`, `utf-8`)。默认:通过 charset-normalizer 自动检测。 |
### 深度比对选项
| 选项 | 默认值 | 描述 |
|--------|:-------:|-------------|
| `--k-gram N` | `5` | Winnowing 的 K-gram 大小。K 值越大 = 指纹越少但越具体。(Schleimer 2003, §4.2) |
| `--window N` | `4` | Winnowing 窗口大小。保证能够检测出任何长度 ≥ `K+W−1` = 8 个 token 的共有序列。 |
| `--threshold-deep N` | `5` (原始) / `93` (归一化) | 包含在结果中的最小 Jaccard 相似度(百分比,0–100)。默认值因通道而异:原始使用 5;`--normalize` 使用 **93**,该校准值旨在将误报率控制在 ≤ 1%(参见下方的[归一化精度](#normalize-precision--false-positive-rate))。传入一个值即可覆盖默认设置。 |
| `--normalize` | off | 在提取指纹前,将标识符归一化为 `ID`,将字面量归一化为 `LIT`。改善 Type-2 克隆检测(重命名的变量),但**会提高独立代码的误报率** —— 参见[归一化精度](#normalize-precision--false-positive-rate)。低于 45-token 下限的匹配将被报告为*不确定inconclusive)*,并且每份归一化报告都会披露其测得的误报率。 |
| `--lang-aware` | off | 与 `--normalize` 配合使用时,采用感知语言的归一化(使用 Pygments 词法分析器,如果失败则回退到特定语言的关键词集合),这样像 Rust 的 `fn`/`pub` 或 Go 的 `func` 等关键词就会被保留,而不是被扁平化为 `ID`。需手动开启;生成的指纹与默认通道不兼容。如果不指定 `--normalize` 则无效。 |
| `--workers N` | `4` | 用于 diff 渲染和指纹提取的并行工作进程数。 |
### 取证选项
| 选项 | 默认值 | 描述 |
|--------|:-------:|-------------|
| `--no-autojunk` | off | 禁用 `SequenceMatcher` 的 autojunk 启发式算法。平等对待所有 token —— 速度较慢,但在取证分析中更精确。 |
| `--max-index-entries N` | `10,000,000` | 倒排索引的内存上限。防止在大型语料库上发生 OOM。1000 万条目大约占用 800MB。 |
| `--max-file-size N` | `10.0` | 超过此大小 (MB) 的文件将绕过内存中的文本解码,回退到 SHA-256 哈希比对(报告为匹配/不匹配,而不是行 diff)。防止在大型二进制/生成文件上出现 OOM/CPU 锁死。 |
| `--hash` | off | 在报告中为所有已分析文件嵌入 SHA-256 证据完整性哈希。 |
| `--uncompared-files {inline,separate,none}` | `inline` | 控制如何显示未匹配的文件:在主报告中内联显示、写入单独的 `*_uncompared.txt` 文件,或者完全忽略。 |
| `--bundle PATH` | — | 在 `PATH` 处创建证据包 ZIP 文件,其中包含源文件、生成的报告和完整性清单。 |
| `--dir-alias-a TEXT` / `--dir-alias-b TEXT` | — | 在报告中显示目录 A/B 的别名(避免暴露绝对路径)。 |
### 过滤与高级选项
| 选项 | 默认值 | 描述 |
|--------|:-------:|-------------|
| `--ignore-file PATH` | — | 指向包含 glob 匹配模式(例如 `node_modules`, `*.pyc`)的 `.diffignore` 文件的路径,用于在分析中排除这些文件。 |
| `--binary-handling {exclude,hash,error}` | `hash` | 如何处理不可解码(二进制)文件:跳过、显示 SHA-256 匹配状态,或报告解码错误。 |
| `--max-diff-html-size N` | `2.0` | 截断前的最大 HTML diff 大小 (MB)。防止在超大的 diff 上出现 xhtml2pdf OOM / `RecursionError`。 |
| `--metrics-only` | off | 仅第一阶段:计算相似度并输出 JSON,跳过 HTML/PDF 渲染。 |
| `--filter-json PATH` | — | 第二阶段:将输出限制为 JSON 数组中列出的 file-A 路径(与 `--metrics-only` 配对使用)。 |
| `--unreadable-log PATH` | — | 将无法读取(权限错误)的文件列表写入 `PATH`。 |
### 页面标注选项
| 选项 | 描述 |
|--------|-------------|
| `--page-number` | 在右下角显示 `Page n / N` |
| `--file-number` | 在左下角显示 `File n / N` |
| `--bates-number` | 在底部居中处加盖连续的 Bates 编号 |
| `--bates-prefix TEXT` | Bates 编号前缀(例如 `PLAINTIFF-`)。组合方式为:`{prefix}{number}{suffix}` |
| `--bates-suffix TEXT` | Bates 编号后缀(例如 `-CONFIDENTIAL`) |
| `--bates-start N` | 起始 Bates 编号(默认:`1`)。用于在多个报告间延续编号。 |
| `--filename` | 在右上角显示文件名 |
## 使用示例
### 基础 IP 诉讼报告
```
# 包含所有注释的完整 forensic 报告
diffinite plaintiff_code/ defendant_code/ -o exhibit_A.pdf \
--strip-comments \
--bates-number --bates-prefix=CASE2026- --bates-suffix=-CONFIDENTIAL \
--bates-start 1 --page-number --file-number --filename \
--collapse-identical --detect-moved --hash
```
### 代码审计(快速 HTML)
```
# 用于浏览器查看的 HTML 报告 (无 PDF 依赖问题)
diffinite vendor_v1/ vendor_v2/ --report-html audit.html --strip-comments
```
### 最高灵敏度(Type-2 克隆)
```
# 检测重命名变量的副本
diffinite original/ suspect/ -o report.pdf \
--normalize --no-autojunk --strip-comments
```
### Simple 模式(快速,无交叉匹配)
```
# 仅进行 1:1 匹配 — 快速比较速度更快
diffinite dir_a/ dir_b/ --mode simple -o quick_report.pdf
```
### 多种输出格式
```
# 一次生成所有格式
diffinite dir_a/ dir_b/ \
--report-pdf report.pdf \
--report-html report.html \
--report-md report.md \
--report-json report.json
```
### 调整灵敏度
```
# 较大的 K-gram = 较少的误报,可能会遗漏短匹配
diffinite dir_a/ dir_b/ --k-gram 7 --window 5
# 较低的 Jaccard 阈值 = 显示较弱的匹配 (0–100 尺度;raw 默认为 5,在 --normalize 下为 93)
diffinite dir_a/ dir_b/ --threshold-deep 2
# 更严格的文件名匹配
diffinite dir_a/ dir_b/ --threshold 80
```
## 注释移除支持
`--strip-comments` 标志使用一个 6 状态有限状态机解析器移除注释,支持 45 种以上的文件扩展名:
| 扩展名 | 注释风格 |
|------------|---------------|
| `.py`, `.pyw` | `# 单行` (保留文档字符串) |
| `.js`, `.jsx`, `.mjs`, `.ts`, `.tsx` | `// 单行`, `/* 块 */`, 模板字符串, 正则表达式字面量 |
| `.java`, `.kt`, `.kts`, `.scala`, `.c`, `.cc`, `.cpp`, `.h`, `.hpp`, `.cs`, `.go`, `.rs`, `.swift` | `// 单行`, `/* 块 */` |
| `.html`, `.htm`, `.xml`, `.svg` | `` |
| `.css`, `.scss`, `.less` | `/* 块 */` |
| `.sql`, `.ddl`, `.dml`, `.pks`, `.pkb`, `.plsql`, `.tsql` | `-- 单行`, `/* 块 */` |
| `.php` | `// 单行`, `# 单行`, `/* 块 */` |
| `.rb` | `# 单行`, `=begin … =end` 块 |
| `.pl`, `.pm`, `.sh`, `.bash`, `.zsh`, `.r`, `.yaml`, `.yml`, `.toml` | `# 单行` |
| `.lua` | `-- 单行`, `--[[ 块 ]]` |
## 项目结构
```
diffinite/
├── src/diffinite/
│ ├── cli.py # CLI entry point & argument parsing
│ ├── pipeline.py # Orchestration (simple/deep modes, parallel rendering)
│ ├── collector.py # File collection & fuzzy name matching
│ ├── parser.py # 6-state comment stripping FSM
│ ├── differ.py # Diff computation, moved-block detection & HTML rendering
│ ├── fingerprint.py # Winnowing fingerprint extraction
│ ├── deep_compare.py # N:M cross-matching (inverted index + Jaccard)
│ ├── evidence.py # SHA-256 integrity hashing & manifest generation
│ ├── models.py # Data classes (DiffResult, DeepMatchResult, etc.)
│ ├── pdf_gen.py # PDF/HTML report generation (xhtml2pdf)
│ └── languages/ # Per-language comment specs (45+ extensions)
├── vscode-extension/
│ ├── src/ # TypeScript extension source
│ │ ├── extension.ts # Extension activation & command registration
│ │ ├── compareCommand.ts # Directory selection, time estimation, pipeline orchestration
│ │ ├── dirScanner.ts # Pre-analysis file scanning & OOM heuristic
│ │ ├── runner.ts # Python backend spawner with progress bar integration
│ │ ├── optionsPanel.ts # GUI options webview (mode, comments, Bates, etc.)
│ │ ├── treeViewer.ts # Interactive matched-pair tree for selective export
│ │ └── resultViewer.ts # HTML report preview inside VS Code
│ ├── bin/python/ # Embedded Python 3.12 runtime (gitignored)
│ └── package.json
├── example/ # Benchmark datasets (see below)
├── pyproject.toml
├── LICENSE # Apache 2.0
└── NOTICE
```
## 基准测试
请先下载示例数据集,然后自行运行基准测试:
```
python example/download_examples.py # download all datasets
python example/download_examples.py --dataset aosp # or download one
```
预先生成的基准测试报告位于 `example/benchmark/` 中。
### 1. Google v. Oracle — API 头文件相似度
**为何使用此数据集**: [Oracle v. Google](https://en.wikipedia.org/wiki/Google_LLC_v._Oracle_America,_Inc.) 案是具有里程碑意义的 SSO(结构、序列、组织)版权纠纷。Google 的 Android 重新实现了 Java API 声明。代码*主体*是独立编写的,但 API *签名*必然是相似的。
```
diffinite example/Case-Oracle/AOSP_Google example/Case-Oracle/OpenJDK_Oracle \
--strip-comments --report-md example/benchmark/case_oracle.md
```
| 文件 | Match (difflib) | Deep 交叉匹配 (Jaccard) |
|------|:-:|:-:|
| `ArrayList.java` | 9.0% | 7.9% |
| `Collections.java` | 4.5% | 23.1% |
| `List.java` | 6.3% | 11.6% |
| `Math.java` | 5.2% | 6.3% |
| `String.java` | 3.3% | 6.8% |
**观察结果**: 行级的 Match (difflib) 得分保持在 10% 以下,证实*主体*确实是独立编写的。Deep Compare 仍然提取出了共享的 Winnowing 指纹 —— Jaccard 得分为 6–23%(在 `Collections.java` 上最高)—— 因为 API *签名和声明*必然是相似的。高结构相似性伴随着低行级 Match 正是本案中争议的 SSO 模式:相同的接口,独立的实现。Diffinite 同时报告这两个数值;如何解释它们是专家的工作。
### 2. Eclipse Collections v. OpenJDK — 阴性对照
**为何使用此数据集**: Eclipse Collections 和 OpenJDK 解决的是相似的问题(集合框架),但由不同的团队开发,没有代码共享。这是同一领域内**独立工作的预期基准**。
```
diffinite example/Case-NegativeControl/Eclipse_Collections example/Case-NegativeControl/OpenJDK \
--strip-comments --report-md example/benchmark/case_negative.md
```
| File A | File B | Match | Deep 交叉匹配 |
|--------|--------|:-:|:-:|
| `StringIterate.java` | `String.java` | 2.4% | — |
| `FastList.java` | `ArrayList.java` | 1.5% | — |
**观察结果**: 没有高于 5% Jaccard 阈值的交叉匹配。这是正确的结果 —— 相互独立的项目之间的相似度应该接近于零。
### 3. IR-Plag 案例 01 — 已知抄袭
**为何使用此数据集**: [IR-Plag](https://github.com/oscarkarnalim/sourcecodeplagiarismdataset) 是一个公开的抄袭检测语料库,带有标记的修改级别(L1=逐字复制,直至 L6=重度重构)。
```
diffinite example/plagiarism/case-01/original example/plagiarism/case-01/plagiarized \
--normalize --strip-comments --report-md example/benchmark/plagiarism_case01.md
```
| 原始文件 | 抄袭文件 | Jaccard |
|----------|-------------|:-:|
| `T1.java` | `L2/04/hellow.java` | 100.0% |
| `T1.java` | `L1/04/T1.java` | 100.0% |
| `T1.java` | `L1/05/HelloWorld.java` | 100.0% |
| `T1.java` | `L4/05/hellow.java` | 56.2% |
| `T1.java` | `L5/02/Main.java` | 38.1% |
| `T1.java` | `L6/07/PrintJava.java` | 36.4% |
| `T1.java` | `L6/01/L6.java` | 25.0% |
| `T1.java` | `L6/05/HelloWorld.java` | 15.4% |
**观察结果**: Jaccard 得分随着抄袭级别的增加(L1→L6)而降低。逐字复制和轻微修改的副本(L1–L3)得分为 100%。重度重构的副本(L5、L6)仍然显示出 15–38% 的共享指纹 —— 远高于阴性对照基准。
### 归一化精度 — 误报率
上面的阴性对照是在**没有**使用 `--normalize` 的情况下运行的,而 IR-Plag 的运行使用了它 —— 因此这两者都没有展示 `--normalize` 对*独立*代码的影响。这个核心问题很关键:将每个标识符扁平化为 `ID` 会让小型、标准代码(例如教科书式的 `for` 循环)的语言强制骨架变得完全一致,而无论作者是谁,因此独立的工作和重命名的副本可能会塌缩为**相同**的 Jaccard 值。
它是通过验证工具([`tests/validation/error_rate.py`](tests/validation/error_rate.py);使用 `python -m tests.validation.error_rate` 重新生成)进行对称测量的。该工具按**每个文件对**进行评分 —— 即每个原始文件与每个候选文件一一对应 —— 这与运行时的按文件 N:M 决策和按文件的 token 下限相匹配。在 IR-Plag 语料库中,`non-plagiarized/` 目录下的提交都是针对*相同*作业的独立答案(任何相似度都属于误报):
| 通道 | 阈值 5 时的误报率 | 阈值 5 时的召回率 |
|---------|:-:|:-:|
| raw | 100% (微型文件) | 100% |
| normalize | **100%** | 100% |
在 `--normalize` 下,内置的 `--threshold-deep 5` 毫无意义:误报率为 100%。因此我们提供了两项缓解措施(完整曲线和工作点特征描述见 [`example/validation/error_rate.md`](example/validation/error_rate.md),机器可读的数值见 [`calibration.json`](example/validation/calibration.json)):
1. **校准阈值** — 在 `--normalize` 下,默认阈值提高到 **93**,即误报率 ≤ 1% 时的工作点。
2. **不确定区间** — 如果一个归一化匹配中较小的文件低于 **45-token 下限**,则被报告为*不确定*:在这种大小下,无论使用任何有意义的阈值,精确率都无法挽救。
**工作点的客观本质**(校准本身的注意事项,会在每一份归一化报告和 `error_rate.md` 中披露):
- 误报率为 **0.95%,但这意味着 105 个文件对中有 1 个** —— Wilson 95% 置信区间为 **[0.17%, 5.2%]**。它并不是一个*已知的* 1% 比率;其上限超过了 5%。
- **召回率并不均匀。** 在阈值 93 时:L1 65%,L2 46%,L3 21%,**L4–L6 0%**。该阈值只能可靠地标记近乎逐字复制的代码;重度重构的副本会低于该阈值,需要人工审查。汇总后的“~22%”被理解为均匀的灵敏度。
- 这 105 个阴性样本仅来源于 **7 个作业**(非独立同分布),并且没有测试任何 **> 212 个 token** 的样本 —— 该工作点在大型文件上尚未得到验证。在 FP ≤ 1% 的情况下,45-token 的下限在该语料库上没有实际约束力(它在运行时控制了下限以下的匹配,但该语料库并未触发这种情况)。
对于非 JVM/Python/JS 语言,`--lang-aware` 可以通过保留语言关键字(例如 Rust 的 `fn`/`pub`),而不是将它们扁平化为 `ID`,从而减少这种塌缩现象。
### 4. AOSP Framework — 相同代码库,微小修改
**为何使用此数据集**: 这是 Android 的 `Handler`/`Looper`/`Message` 框架的两个版本。版本之间存在微小的演进式改动。
```
# 默认运行,包含注释 (如上图示例图像中所示的配置)
diffinite example/aosp/left example/aosp/right
# 带有注释剥离 (重现 example/benchmark/aosp.md)
diffinite example/aosp/left example/aosp/right \
--strip-comments --report-md example/benchmark/aosp.md
```
| 文件 | Match — 包含注释 | Match — 移除注释 |
|------|:-:|:-:|
| `Handler.java` | 90.6% | 88.6% |
| `Looper.java` | 89.1% | 90.0% |
| `Message.java` | 96.0% | 96.3% |
**观察结果**: 高 Match 得分正确地反映了它们是同一代码库的微小修订 —— 并且无论是否包含注释(默认行为)或移除注释,得分都保持在高位,表明该度量结果对此选择具有鲁棒性。本 README 顶部的示例报告图片使用的是包含注释的该数据集。
### 5. Unicode / i18n — 非 ASCII 源码
**为何使用此数据集**: 这是一对人工编写的小型 A/B 文件对,端到端贯穿报告 pipeline,测试了非 ASCII **文件名**(`계산기.py`, `日本語.java`),CJK / 西里尔文 / 阿拉伯语的标识符和注释,RTL 字符串以及 emoji。
```
diffinite example/unicode/left example/unicode/right \
--mode deep --normalize --pdf-lang ko \
--report-pdf uni.pdf --report-html uni.html --report-md uni.md
```
**它验证了什么**: 支持 Unicode 的分词器将 CJK/西里尔文的标识符视为单个 token(因此非 ASCII 的指纹密度与 ASCII 相匹配);注释移除功能可处理非 ASCII 字符;非 ASCII 文件名能在各种格式中正确渲染;并且 PDF 内嵌了 CJK 字形(`--pdf-lang ko` 选择韩文字体)。此项由 `tests/test_unicode_reports.py` 覆盖测试。
## Winnowing 算法
Diffinite 使用 **Winnowing** 算法(Schleimer, Wilkerson, Aiken. *"Winnowing: Local Algorithms for Document Fingerprinting."* SIGMOD 2003),这也是 [Stanford MOSS](https://theory.stanford.edu/~aiken/moss/) 的基础算法。
**Pipeline**: `源码 → 分词 → K-gram → 滚动哈希 → winnow 筛选 → 指纹集合`
该算法提供了**密度保证**:任何长度 ≥ `K + W − 1`(默认:8)的共享 token 序列都将被检测到,无论其在文件中的位置如何。
**参数**:
| 参数 | 默认值 | 原理 |
|-----------|:-------:|-----------|
| `K` (k-gram) | `5` | Schleimer 2003 §4.2 推荐范围。每个指纹单元包含 5 个连续的 token。 |
| `W` (window) | `4` | 包含 4 个指纹的窗口 → 最小可检测序列 = 8 个 token。 |
| `HASH_BASE` | `257` | 标准的 Rabin 哈希基数(素数)。 |
| `HASH_MOD` | `2⁶¹ − 1` | 梅森素数 —— 模运算高效,碰撞概率极低。 |
## 局限性
- **通用分词器**: 对所有语言使用单一的正则表达式分词器,而不是特定语言的解析器。准确度可能因语言而异。
- **位置无关性**: Winnowing 指纹在窗口内是顺序无关的。重新排列了函数顺序的代码可能会产生高于预期的相似度。
- **无语料库级分析**: 每次比较都是成对进行的。没有内置的语料库级频率加权(例如 TF-IDF)机制来降低常见惯用语的权重。
- **二进制和混淆代码**: 不支持。Diffinite 仅适用于源代码文本。
- **非法律意见**: 相似度得分属于数学度量结果,而非法律结论。在任何法律诉讼中使用前,必须经过专业人士的审查。
## 许可证
[Apache License 2.0](LICENSE)
归属声明请参见 [NOTICE](NOTICE)。
标签:PDF报告生成, Python, 代码相似度分析, 数字取证, 无后门, 源代码审计, 知识产权诉讼, 自动化脚本, 逆向工具