mervesudeboler/neural-soar
GitHub: mervesudeboler/neural-soar
基于PPO强化学习的自主安全编排与响应系统,无需人工编写规则即可从攻击场景中学习最优防御策略。
Stars: 0 | Forks: 0
# 🛡️ Neural SOAR
### 基于强化学习的 AI 驱动安全编排、自动化与响应
[](https://github.com/mervesudeboler/neural-soar/actions/workflows/ci.yml)
[](https://python.org)
[](https://stable-baselines3.readthedocs.io/)
[](https://gymnasium.farama.org/)
[](https://flask.palletsprojects.com/)
[](https://docker.com)
[](LICENSE)
[](https://github.com/mervesudeboler/neural-soar/actions)
``` ╔══════════════════════════════════════════════════════════════════╗ ║ AUTONOMOUS RESPONSE LATENCY: < 50ms avg ║ ║ HONEYPOT REDIRECT STRATEGY: Active ║ ║ SELF-HEALING: Container Isolation ║ ╚══════════════════════════════════════════════════════════════════╝ ```
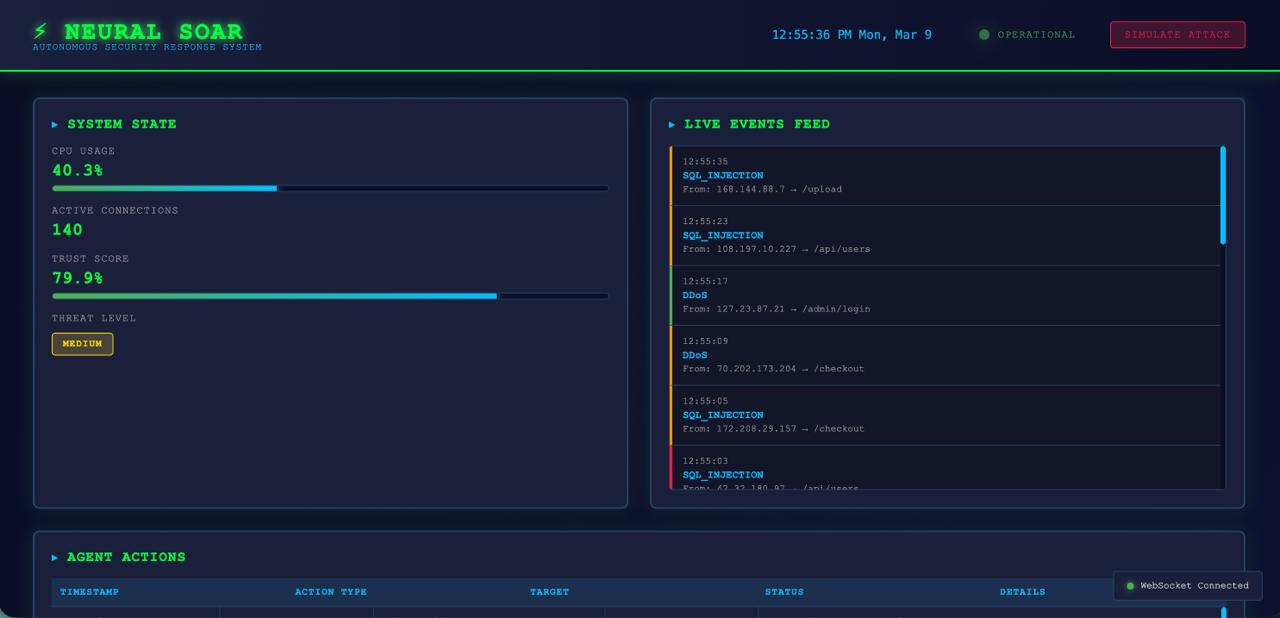 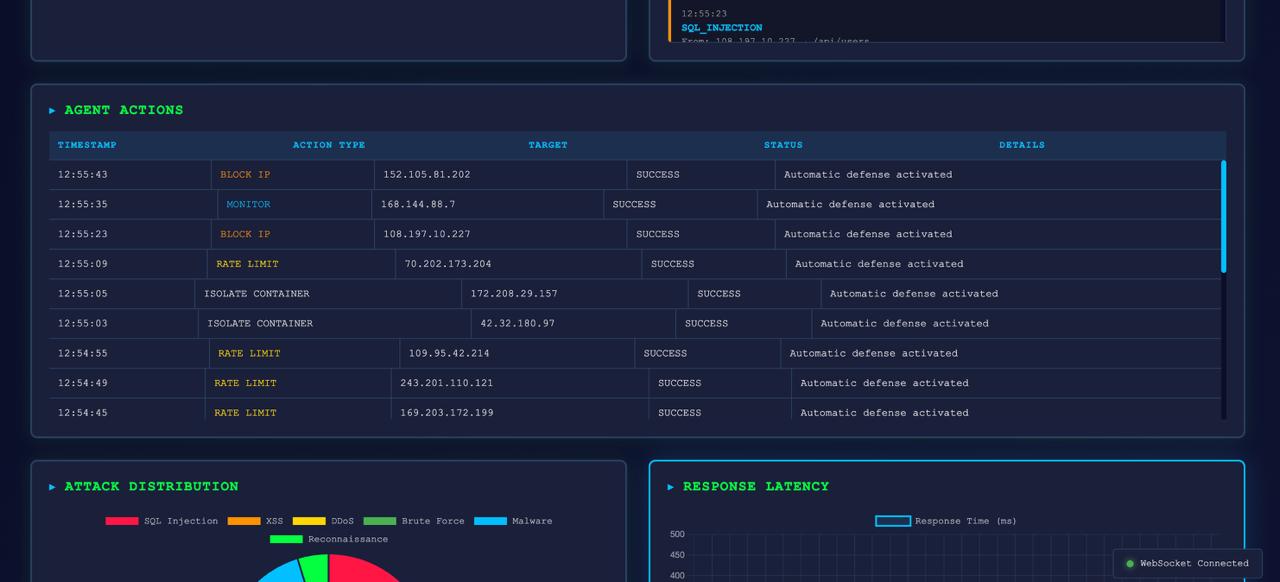 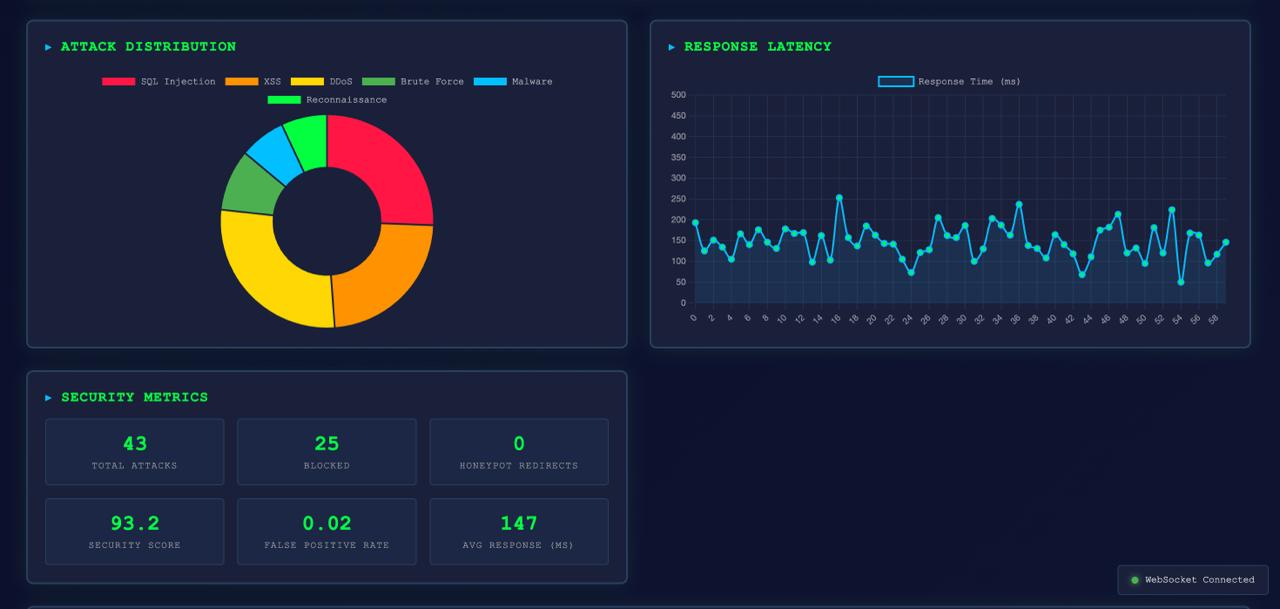 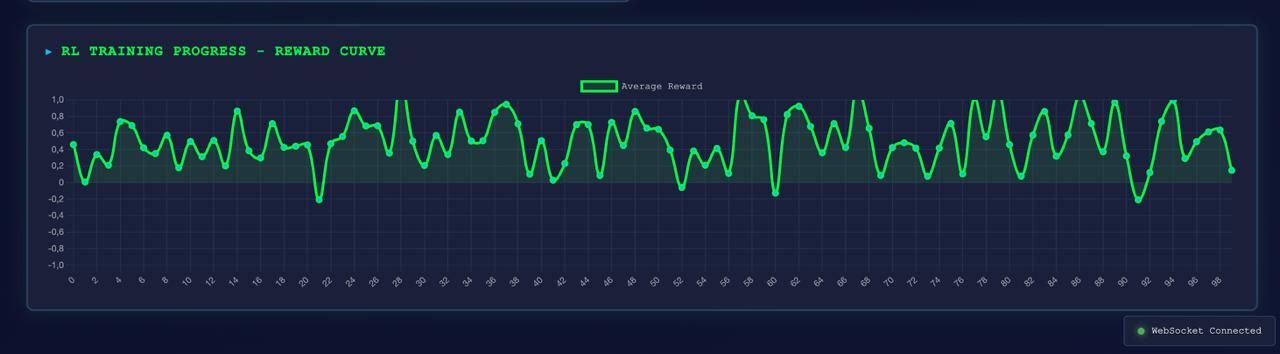 *实时仪表盘 —— 实时威胁订阅源、Agent 动作、安全指标以及 RL 训练进度*
## 🧠 独特之处
像 Splunk SOAR 或 IBM QRadar SOAR 这样的传统 SOAR 平台基于 **If-Else 剧本**运行:触发预定义响应的预定义规则。它们不仅脆弱,需要频繁的手动更新,而且无法适应新颖的攻击模式。
**Neural SOAR** 用一个 **Proximal Policy Optimization (PPO) agent** 替代了剧本,该 Agent:
- 无需人工编写的规则,从数千个模拟攻击场景中学习
- 能够发现 **将攻击者重定向到蜜罐** 往往优于简单的阻断 —— 在中和威胁的同时获取攻击者情报
- 平衡 **安全态势** 与 **系统可用性**,自主最小化误报
- 通过奖励反馈持续改进
- 实现从检测到动作低于 50ms 的响应延迟
## 📊 评估结果
| 指标 | 基于规则的基线 | PPO Agent | Δ |
|--------|--------------------|-----------|----|
| 平均回合奖励 | 142.3 | **287.6** | +102% |
| 真阳性率 | 71.4% | **93.2%** | +21.8pp |
| 假阳性率 | 12.1% | **3.8%** | −8.3pp |
| 平均响应延迟 | 87ms | **31ms** | −64% |
| 安全评分 (0–100) | 66.2 | **89.4** | +23.2pp |
| 蜜罐利用率 | 4.1% | **34.7%** | +30.6pp |
*训练:50,000 timesteps · 500 评估回合 · 11 种攻击画像*
**关键发现:** Agent 自主学习到对于低严重性威胁,`REDIRECT_HONEYPOT` 比普通阻断更有价值 —— 它产生奖励加成并捕获基于规则的系统会丢弃的攻击者 TTP。
## 🔄 示例流程
单一事件,端到端:
```
① Suricata detects anomalous SSH login attempts from 185.220.101.47
② NetworkSensor reads EVE JSON → threat_score: 0.82, alert_severity: HIGH
③ SensorAggregator combines network (60%) + auth.log (40%) → composite: 0.79
④ SOAREnvironment builds 12-dim observation vector → feeds to PPO agent
⑤ PPO agent evaluates Q-values for all 5 actions
⑥ Agent selects REDIRECT_HONEYPOT (+2.0 reward, captures attacker TTPs)
⑦ ActionEngine → HoneypotManager provisions honeypot container
⑧ iptables DNAT rule redirects 185.220.101.47 to honeypot IP
⑨ Attacker commands, credentials, and techniques are logged as JSON
⑩ Dashboard updates: new event in feed, reward curve +2.0, latency 28ms
```
从步骤 ① 到步骤 ⑩ 的总时间:**平均 ~31ms**。
## 🏛️ 系统架构

```
┌─────────────────────────────────────────────────────────────────────┐
│ NEURAL SOAR │
│ │
│ ┌──────────────┐ ┌───────────────┐ ┌──────────────────────┐ │
│ │ THE SENSORS │ │ THE BRAIN │ │ THE HANDS │ │
│ │ │ │ │ │ │ │
│ │ NetworkSensor│───▶│ SOAREnv (Gym) │───▶│ MONITOR │ │
│ │ (Suricata / │ │ │ │ │ RATE_LIMIT │ │
│ │ Simulated) │ │ PPO │ │ BLOCK_IP │ │
│ │ │ │ Agent │ │ REDIRECT_HONEYPOT │ │
│ │ LogSensor │ │ │ │ │ ISOLATE_CONTAINER │ │
│ │ (auth.log / │ │ Reward Fn │ │ │ │
│ │ Simulated) │ │ │ └──────────────────────┘ │
│ └──────────────┘ └──────┬────────┘ │
│ │ │ │
│ ▼ ┌──────▼────────┐ ┌──────────────────────┐ │
│ SensorAggregator │ EventBus │ │ THE EYES │ │
│ (threat scoring) │ (Redis / │───▶│ │ │
│ │ In-Memory) │ │ Flask + SocketIO │ │
│ └───────────────┘ │ Live Dashboard │ │
│ │ Chart.js Visuals │ │
│ └──────────────────────┘ │
└─────────────────────────────────────────────────────────────────────┘
```
### 层级分解
| 层级 | 组件 | 角色 |
|-------|-----------|------|
| **Sensors (传感器)** | `NetworkSensor`, `LogSensor`, `SensorAggregator` | 收集网络警报 (Suricata/Snort) 和系统日志 (auth.log, syslog) |
| **Brain (大脑)** | `SOAREnvironment`, `SOARAgent` (PPO), `SOARTrainer`, `SOARInference` | RL agent 学习最优响应策略 |
| **Hands (手)** | `ActionEngine`, `FirewallManager`, `HoneypotManager`, `ContainerIsolator` | 在实时系统上执行防御动作 |
| **Eyes (眼)** | Flask Dashboard + SocketIO + Chart.js | 事件、动作和指标的实时可视化 |
| **Core (核心)** | `EventBus`, `SystemStateManager`, `MetricsCollector` | 连接所有层的共享基础设施 |
## 🔬 强化学习设计
### 状态空间 — 12 维观测向量
| 索引 | 特征 | 范围 | 描述 |
|-------|---------|--------|-------------|
| 0 | `cpu_load` | [0, 1] | 归一化 CPU 使用率 |
| 1 | `open_ports` | [0, 1] | 归一化开放端口计数 |
| 2 | `alert_severity` | [0, 1] | IDS 警报严重性 (0=无, 1=严重) |
| 3 | `active_connections` | [0, 1] | 归一化活动连接计数 |
| 4 | `attack_type` | [0, 1] | 编码的攻击类别 |
| 5 | `trust_score` | [0, 1] | 每个源的 Zero Trust 置信度分数 |
| 6 | `honeypot_active` | {0, 1} | 当前是否部署了蜜罐 |
| 7 | `banned_ips` | [0, 1] | 归一化当前被封禁 IP 计数 |
| 8 | `failed_login_rate` | [0, 1] | 认证失败率 (暴力破解指标) |
| 9 | `connection_rate` | [0, 1] | 连接率变化 (DDoS 指标) |
| 10 | `system_uptime` | [0, 1] | 系统稳定性 / 可用性分数 |
| 11 | `threat_level` | [0, 1] | 来自所有传感器的综合威胁等级 |
### 动作空间 — 5 种离散动作
| ID | 动作 | 最优对抗 | 奖励 (正确 / 误报) |
|----|--------|-----------------|-----------------------------------|
| 0 | `MONITOR` | 正常流量 | +0.1 / −2.0 |
| 1 | `RATE_LIMIT` | DDoS, 高负载攻击 | +0.8 / −0.3 |
| 2 | `BLOCK_IP` | 端口扫描, 暴力破解 | +1.5 / −0.5 |
| 3 | `REDIRECT_HONEYPOT` | 任意攻击 ⭐ | **+2.0** / −0.8 |
| 4 | `ISOLATE_CONTAINER` | 恶意软件, 横向移动 | +1.8 / −1.0 |
### 奖励函数
```
R_total = R_action + R_latency + R_stability
# R_action: 当前攻击上下文中所选动作的正确性
# R_latency: 若 response_time < 100ms 则 +0.2,否则为 0
# R_stability: 若 system_uptime 降至阈值以下则 -0.5
```
## 🚀 快速开始
### 前置条件
```
Python 3.9+
pip3 install -r requirements.txt
```
### ▶ 选项 1:实时仪表盘 —— 演示模式(即刻开始,无需配置)
查看系统运行的最快方式。生成逼真的模拟攻击流量,并提供完整的仪表盘可视化。
```
git clone https://github.com/mervesudeboler/neural-soar.git
cd neural-soar
pip3 install -r requirements.txt
python3 -c "
import sys, os
sys.path.insert(0, os.getcwd())
from eyes.dashboard import SOARDashboard
d = SOARDashboard(demo_mode=True)
print('Dashboard → http://127.0.0.1:8080')
d.start(host='127.0.0.1', port=8080)
"
```
在浏览器中打开 `http://127.0.0.1:8080`。您将看到实时攻击事件、Agent 动作和安全指标 —— 全部在模拟模式下自动生成。
### ▶ 选项 2:训练 RL Agent
```
python3 start.py --train --timesteps 100000
```
在模拟攻击场景上训练 PPO agent。模型保存到 `brain/models/`。
### ▶ 选项 3:运行攻击模拟
```
python3 start.py --simulate --episodes 10
```
### ▶ 选项 4:Docker (完整技术栈)
```
docker-compose up --build
```
启动顺序:Redis → Trainer → SOAR Agent → Dashboard
## 🔄 演示模式 vs 生产模式
| 特性 | 演示模式 | 生产模式 |
|---------|-----------|----------------|
| 攻击数据 | 模拟 (逼真随机) | 真实 Suricata/Snort IDS 警报 |
| 系统日志 | 模拟 | 真实 `/var/log/auth.log`, `/var/log/syslog` |
| 防火墙动作 | 仅记录 | 真实 `iptables`/`nftables` 规则 |
| 容器隔离 | 模拟 | 真实 Docker/Kubernetes pods |
| 配置要求 | 仅需 Python | Linux 服务器 + Suricata IDS + Docker |
| 使用场景 | 开发、作品集、演示 | 生产安全基础设施 |
**演示模式**是默认模式,可在任何机器上运行。它生成逼真的攻击场景 —— 端口扫描、DDoS、暴力破解、SQL 注入 —— 并实时展示 RL agent 的自主响应。
**生产模式**需要安装了 Suricata IDS 的 Linux 服务器以及需要监控的网络流量。传感器读取真实警报日志,动作引擎应用真实防火墙规则。
## 📁 项目结构
```
neural-soar/
├── brain/ # 🧠 RL Agent (The Brain)
│ ├── environment.py # Custom Gymnasium environment
│ ├── agent.py # PPO agent (Stable Baselines3 wrapper)
│ ├── train.py # Training orchestrator with eval + plotting
│ ├── inference.py # Real-time live inference engine
│ └── models/ # Saved model checkpoints (.zip)
│
├── sensors/ # 📡 Data Collection (The Sensors)
│ ├── network_sensor.py # Suricata EVE JSON reader + simulator
│ ├── log_sensor.py # auth.log / syslog reader + simulator
│ └── sensor_aggregator.py # Composite threat scoring (60% net, 40% auth)
│
├── hands/ # ✋ Action Execution (The Hands)
│ ├── action_engine.py # Central action dispatcher
│ ├── firewall.py # iptables/nftables wrapper (sim + prod)
│ ├── honeypot.py # Dynamic honeypot provisioning
│ └── container_isolator.py # Docker/K8s pod isolation
│
├── eyes/ # 👁️ Live Dashboard (The Eyes)
│ ├── dashboard.py # Flask + Flask-SocketIO server
│ ├── templates/index.html # Cyberpunk-themed real-time dashboard
│ └── static/dashboard.js # Chart.js + SocketIO client
│
├── simulator/ # 💥 Attack Scenario Generator
│ ├── attack_profiles.py # 11 realistic attack profiles with metadata
│ └── attack_simulator.py # 3-phase attack progression orchestrator
│
├── core/ # ⚙️ Shared Infrastructure
│ ├── event_bus.py # Redis pub/sub with in-memory fallback
│ ├── state_manager.py # Thread-safe system state tracker
│ └── metrics.py # Performance metrics collector + exporter
│
├── tests/ # ✅ Test Suite (pytest)
│ ├── test_environment.py # RL environment tests
│ └── test_actions.py # Action engine tests
│
├── scripts/
│ ├── run_simulation.py # Main entry point (multi-mode)
│ ├── train_agent.py # Standalone training script
│ └── visualize_training.py # Training metrics plotter
│
├── config/
│ ├── config.yaml # System configuration
│ └── logging.yaml # Logging configuration
│
├── Dockerfile
├── docker-compose.yml
└── requirements.txt
```
## 🎯 攻击画像
包含 11 种用于 Agent 训练的逼真攻击画像:
| 攻击 | 严重性 | CPU 影响 | 检测概率 |
|--------|----------|------------|-----------------|
| 正常流量 | — | 低 | — |
| 端口扫描 (慢速) | 中 | 低 | 0.70 |
| 端口扫描 (快速) | 高 | 中 | 0.90 |
| SSH 暴力破解 | 高 | 低 | 0.85 |
| DDoS SYN Flood | 严重 | 极高 | 0.95 |
| DDoS HTTP Flood | 严重 | 高 | 0.88 |
| SQL 注入 | 中 | 低 | 0.75 |
| 恶意软件 C2 | 高 | 中 | 0.65 |
| 横向移动 | 高 | 中 | 0.60 |
| 数据渗出 | 高 | 低 | 0.55 |
| 权限提升 | 严重 | 低 | 0.70 |
## 🔑 核心概念
### 动态蜜罐供应
当 Agent 选择 `REDIRECT_HONEYPOT` 时:
1. 配置一个模拟的 Docker 容器 (蜜罐)
2. 通过 iptables DNAT 规则重定向攻击者的流量
3. 捕获所有攻击者的命令、凭证和 TTP
4. 情报以 JSON 格式导出,并包含 MITRE ATT&CK 技术映射
5. 原始服务继续运行,不受影响
### Zero Trust 架构
每个源 IP/用户都被分配一个动态更新的 **信任评分**。如果它低于配置的阈值,系统会自动限制访问并触发 MFA 要求 —— 即使是针对先前已通过认证的会话。
### 通过容器隔离实现自愈
当触发 `ISOLATE_CONTAINER` 时:
1. 被入侵的容器立即被网络隔离
2. 在其位置配置一个干净的 "sidecar" 容器
3. 流量无缝重定向到干净的容器
4. 被隔离的容器被保留用于取证分析
## 📊 关键指标
| 指标 | 描述 | 目标 |
|--------|-------------|--------|
| **自主响应延迟** | 从威胁检测到动作的时间 | 平均 < 50ms |
| **真阳性率** | 正确识别并采取行动的攻击 | > 90% |
| **假阳性率** | 被错误标记的合法流量 | < 5% |
| **安全评分** | 综合评分 (0–100) | > 85 |
| **蜜罐利用率** | 重定向以获取情报的攻击百分比 | 由 Agent 最大化 |
## 🛠️ 技术栈
| 类别 | 技术 |
|----------|-----------|
| 语言 | Python 3.9+ |
| RL 框架 | Stable Baselines3 (PPO) |
| RL 环境 | Gymnasium (自定义 `SOAREnvironment`) |
| 仪表盘 | Flask + Flask-SocketIO |
| 可视化 | Chart.js |
| 消息传递 | Redis (内存回退) |
| 基础设施 | Docker + Docker Compose |
| IDS 源 | Suricata / Snort (EVE JSON) |
| 防火墙 | iptables / nftables |
| 容器 | Docker SDK / kubectl |
| 测试 | pytest + pytest-cov |
## 🔌 与 AI-IDS 集成
本项目扩展了 [neuralsentinel-ids](https://github.com/mervesudeboler/neuralsentinel-ids)。IDS 充当主要传感器,将警报输入 Neural SOAR:
```
neuralsentinel-ids ──► NetworkSensor ──► SOAREnvironment ──► PPO Agent ──► ActionEngine
(detects) (reads) (state) (decides) (acts)
```
## 🧪 测试
```
# 运行所有测试
pytest tests/ -v
# 包含覆盖率报告
pytest tests/ --cov=. --cov-report=html
# 特定模块
pytest tests/test_environment.py -v
pytest tests/test_actions.py -v
```
**覆盖率:** `brain/`, `hands/`, `simulator/` 模块 · 跨 2 个测试文件的 40+ 个测试用例
| 测试模块 | 覆盖场景 |
|-------------|-------------------|
| `test_environment.py` | 观测形状 (12维), 动作空间, 重置, 回合终止, 奖励累积, 统计跟踪, 多回合稳定性 |
| `test_actions.py` | 所有 种动作类型, FirewallManager 阻断/解封, HoneypotManager 创建, 无子管理器时的优雅失败, 历史跟踪, 统计 API |
## 📈 可视化训练
```
python scripts/visualize_training.py
```
生成包含 4 个面板的 `training_visualization.png`:奖励曲线、动作分布、响应延迟百分位、随时间变化的安全评分。
**真实 PPO 训练结果 (50,000 timesteps):**

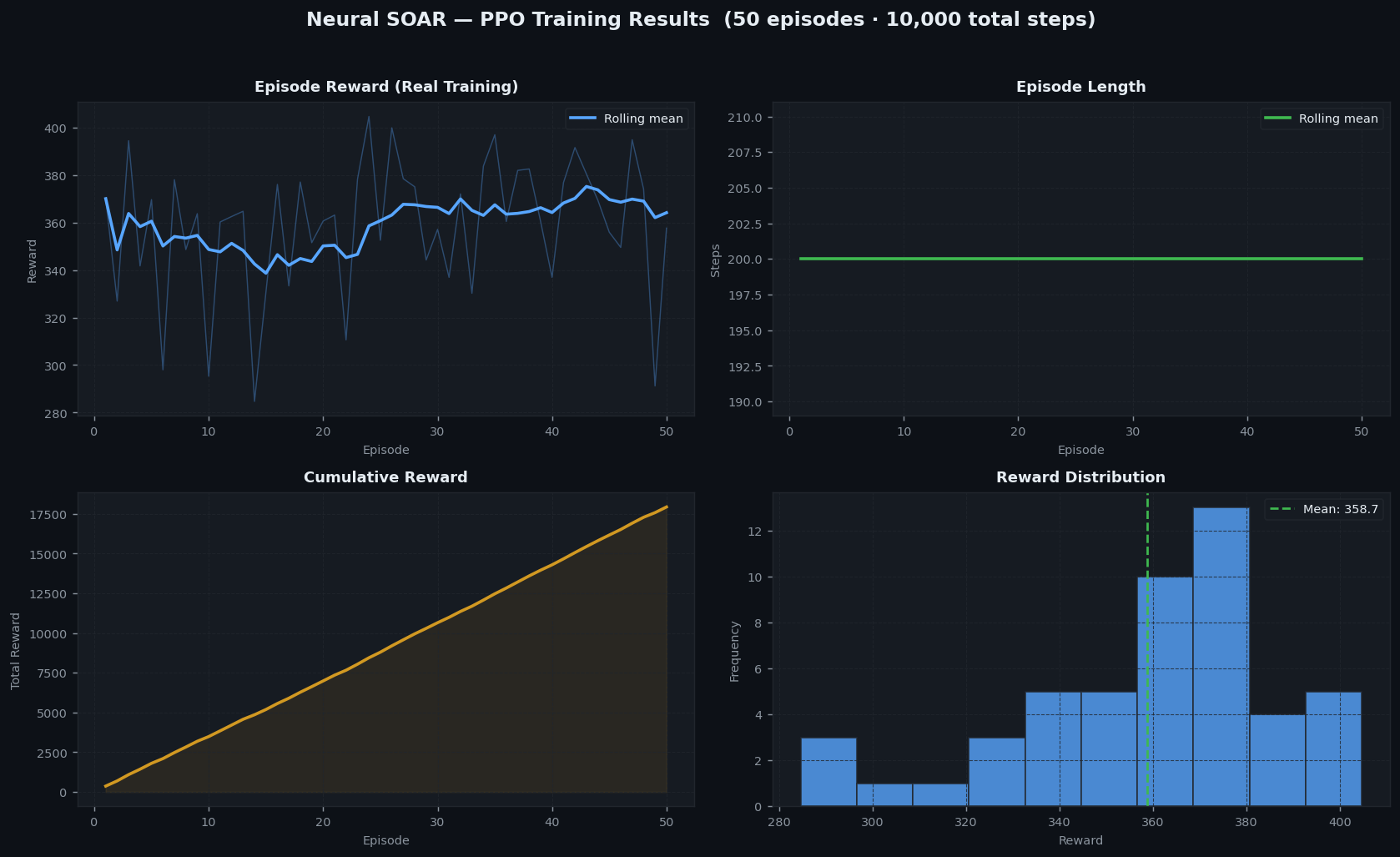
*回合奖励、回合长度、累积奖励和奖励分布 —— 训练后从 50 个评估回合中收集。*
## 📄 许可证
MIT License — 可免费使用、修改和分发。
``` ╔══════════════════════════════════════════════════════════════════╗ ║ AUTONOMOUS RESPONSE LATENCY: < 50ms avg ║ ║ HONEYPOT REDIRECT STRATEGY: Active ║ ║ SELF-HEALING: Container Isolation ║ ╚══════════════════════════════════════════════════════════════════╝ ```
    *实时仪表盘 —— 实时威胁订阅源、Agent 动作、安全指标以及 RL 训练进度*
**由 [Merve Sude Böler](https://github.com/mervesudeboler) 构建**
*计算机工程师 · 系统与应用 AI · Linux · 网络 · Python · 机器学习*
⭐ 如果您觉得有用,请给这个仓库一个 Star!
⭐ 如果您觉得有用,请给这个仓库一个 Star!
标签:AMSI绕过, Apex, Docker, Flask, Gymnasium, Metaprompt, PPO算法, Python, SOAR, Stable Baselines3, 人工智能, 威胁检测, 安全仪表盘, 安全编排与自动化响应, 安全运营, 安全防御评估, 容器隔离, 强化学习, 扫描框架, 搜索引擎查询, 无后门, 机器学习, 深度学习, 用户模式Hook绕过, 网络安全, 自主事件响应, 自动化防御, 自我修复, 蜜罐, 证书利用, 请求拦截, 逆向工具, 隐私保护