MDP-Studio/Automated-Phishing-Detection
GitHub: MDP-Studio/Automated-Phishing-Detection
面向安全分析师的七阶段异步钓鱼邮件检测流水线,集成八个并发分析器、MITRE ATT&CK映射、Sigma/STIX导出以及AI Agent原生的支付欺诈防火墙。
Stars: 1 | Forks: 0
# 自动化钓鱼检测流水线
通过 7 阶段异步流水线分析钓鱼邮件,支持并发威胁情报查询、涵盖 12 种子技术的 MITRE ATT&CK 映射、Sigma 规则导出以及 STIX 2.1 IOC 生成。专为分析师工具设计,而非自主检测。
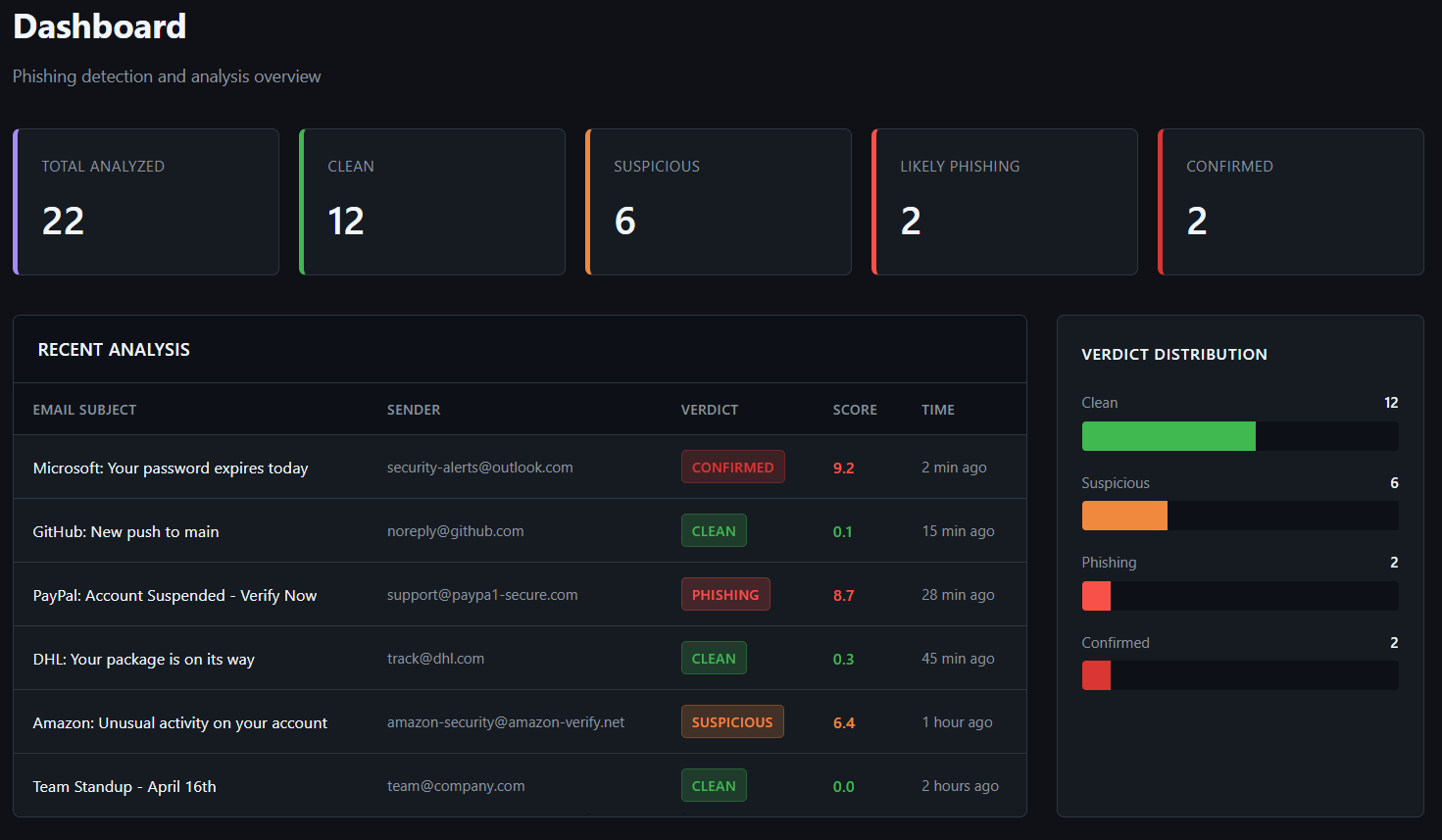
**当前评估(实时 API):** 在已提交的 22 样本项目语料库上,召回率 0.90,精确率 1.00,F1 0.95(宽松评分)。TP=9, FP=0, TN=12, FN=1。严格召回率为 0.00,因为钓鱼检测结果集中在 SUSPICIOUS(可疑)区间 (0.30-0.60),低于 LIKELY_PHISHING(可能是钓鱼)阈值。在 commit `c459237` 上进行的一次远程公共语料库冒烟测试使用了 Nazario 钓鱼样本以及 Enron 和 SpamAssassin 正常样本:15 个样本,宽松精确率 0.714,召回率 1.000,F1 0.833,准确率 0.867;严格 F1 0.000。请将其视为冒烟基线,而非产品指标。逐样本的已提交数据位于 [`eval_runs/`](eval_runs/);生成的公共语料库保留在已被忽略的 `data/eval_corpus*` 下。
**本项目的与众不同之处**不在于检测数据。而在于记录在 [`HISTORY.md`](HISTORY.md) 中的工程历程:十四次严格的审计周期,七个堆叠的规范漏洞(耗费四次审计才暴露出来),一个机械化的预周期门控(强制在叙述前阅读结果),以及诚实的评估数据(包括那些数据表现糟糕的周期)。完整的故事——包括 0.20 的召回率基线是如何被误诊了两个周期才找到真正原因的——记录在[报告](docs/WRITEUP.md)中。
使用真实样本数据从 `docs/demo_screenshot.html` 生成的静态演示截图:
## Agent 原生支付欺诈防火墙演示
此仓库现在包含一个仅作为样本的针对发票和支付欺诈的产品切片。它将 `analyze_payment_email` 作为 CLI 和 MCP 工具暴露出来,以便 AI 应付账款 Agent 可以在资金转移之前获得结构化的支付决策:
```
SAFE | VERIFY | DO_NOT_PAY + evidence + next action
```
最快的本地验证:
```
.\.venv\Scripts\python.exe scripts\agent_payment_demo.py
```
已提交的样本展示了三种结果:
| 样本 | 决策 | 操作 |
|---|---:|---|
| `safe_invoice.eml` | `SAFE` | 继续正常的支付审批。 |
| `verify_supplier_portal.eml` | `VERIFY` | 暂停支付,进行带外验证。 |
| `do_not_pay_bank_redirect.eml` | `DO_NOT_PAY` | 阻止支付释放,直到验证完成。 |
Gemini CLI 演示证明了 Agent 的边界:Gemini 调用本地的 `payment-scam-firewall` MCP 服务器,接收工具结果,并基于该证据编写应付账款(AP)团队备注。有关录制脚本,请参阅 [`docs/gemini-mcp-demo-kit.md`](docs/gemini-mcp-demo-kit.md);有关三种情况的记录,请参阅 [`docs/agent-payment-three-case-transcript.md`](docs/agent-payment-three-case-transcript.md)。
在本地运行产品外壳:
```
.\.venv\Scripts\python.exe main.py serve --host 127.0.0.1 --port 8766
```
然后打开:
```
http://127.0.0.1:8766/product
```
安全边界:公开演示仅使用已提交的样本。它不会连接访问者的邮箱、调用付费 API、释放资金、暴露完整的电子邮件正文或写入反馈标签。
公开产品页面、账户应用和分析师控制台共享相同的 PhishAnalyze 可视化外壳,因此演示不再像是单独的原型。
## 项目历程
这最初是一个可运行的钓鱼检测流水线,但存在基础性问题:一次外部审计发现了 21 个问题,包括 7 个 P0 级别的安全性和正确性问题。代码库很有雄心,但其边界未经验证,SSRF 攻击面是典型的 Capital-One 级别的基础设施,经过四次修复尝试后仍存活的 LinkedIn FP(误报)根源于缺失的架构原语(跨分析器上下文共享),而 BEC 检测的声明实际上依赖于样本中偶然包含的 URL。
在遵循严格的 TEST → AUDIT → UPDATE → COMMIT → FINAL TEST → PUSH → AUDIT 循环的 **8 个周期**中,每个 P0 问题均已解决,11 个 P1 问题中有 9 个得到处理,且不明显的架构设计决策被记录在**编写任何代码之前的 ADR 中**。测试套件从 676 增长到 899,在整个历程中零回归。CI 已添加并经过验证,通过一个故意设置为红色的健全性分支进行了确认。两项架构变更(第 6 周期的跨分析器校准,第 8 周期的持久化 email_id 查找)随附完整的故障模式文档和以它们所防止的错误命名的锁定测试。
包含 commit 哈希、每个周期审计项关闭情况以及已发现但推迟的问题的完整周期历史记录在 [`HISTORY.md`](HISTORY.md)。如果你想花 90 秒快速浏览,请先阅读该文件。
## 接下来阅读什么
| 读者 | 从这里开始 |
|---|---|
| 产品评审员 / 演示 | [`docs/gemini-mcp-demo-kit.md`](docs/gemini-mcp-demo-kit.md) -> [`docs/agent-payment-three-case-transcript.md`](docs/agent-payment-three-case-transcript.md) |
| 招聘经理 / 90 秒速览 | [`HISTORY.md`](HISTORY.md) — 历程总结 + 每周期表格 |
| 检测工程师 | [`docs/MITRE_ATTACK_MAPPING.md`](docs/MITRE_ATTACK_MAPPING.md) → [`sigma_rules/`](sigma_rules/) |
| 安全评审员 | [`THREAT_MODEL.md`](THREAT_MODEL.md) → [`SECURITY.md`](SECURITY.md) |
| 关注架构者 | [`docs/adr/0001-cross-analyzer-context-passing.md`](docs/adr/0001-cross-analyzer-context-passing.md) → [`docs/adr/0002-persistent-email-id-lookup-for-feedback.md`](docs/adr/0002-persistent-email-id-lookup-for-feedback.md) |
| 想要了解哪些功能损坏的真相 | [`lessons-learned.md`](lessons-learned.md) |
## 架构
```
Email Ingestion → Feature Extraction → Concurrent Analysis → Decision Engine → Reporting
│ │ │ │ │
IMAP poll EML parsing 8 analyzers Weighted JSON/HTML
Manual upload Header analysis (async parallel) scoring STIX 2.1
.eml/.msg files URL extraction API clients Overrides Dashboard
QR decoding NLP intent Calibration Sigma rules
Attachments Brand matching Thresholds
```
决策引擎有两个阶段:阶段 1 并发运行分析器,阶段 2 应用跨分析器校准规则 (ADR 0001),这些规则可以降低判定结果,但永远不会提高它,也永远不会修改底层的加权分数。持久化 email_id 查找 (ADR 0002) 允许反馈端点在服务器重启后也能解析用于黑名单的发件人。
## 评估结果
逐样本的评估数据位于 [`eval_runs/`](eval_runs/) — 每次运行一个 JSONL 文件以及一个 `.summary.json` 汇总文件。每一行记录了预测的判定、每个分析器的分数、校准结果、实际使用的 LLM 模型 ID,以及运行评估所针对的 commit SHA。**该目录是链接,而不是特定的某次运行** — 数据会变得陈旧,单个文件名也会失效。
要针对内置的 22 样本语料库生成新的运行:
```
python scripts/run_eval.py
```
默认语料库是 `tests/real_world_samples/`(项目自有的 22 样本标记集)。要从下载的公共数据准备更大的被忽略的本地语料库:
```
bash scripts/download_corpora.sh
python scripts/eval_prepare_corpus.py --output data/eval_corpus --phishing 200 --enron-ham 200 --spamassassin-ham 100 --clean-output
python scripts/run_eval.py --corpus data/eval_corpus --labels data/eval_corpus/labels.json
python scripts/phishing_train.py --corpus data/eval_corpus
```
`scripts/eval_prepare_corpus.py` 编写 `.eml` 样本、用于评估器的 `labels.json`、用于 ML 工作流的 `labels.csv`、用于溯源的 `manifest.jsonl` 以及用于可复现性的 `summary.json`。`scripts/phishing_train.py` 根据准备好的公共语料库训练 TF-IDF + 逻辑回归基线,并将被忽略的输出写入 `models/phishing_classifier/`。生成的语料库和模型工件不会被提交到 git。
要在评估运行后检查失败情况:
```
python scripts/eval_inspect_failures.py --results eval_runs/RUN_ID.jsonl --manifest data/eval_corpus/manifest.jsonl --projection permissive --output data/eval_corpus/failure_report_permissive
python scripts/eval_inspect_failures.py --results eval_runs/RUN_ID.jsonl --manifest data/eval_corpus/manifest.jsonl --projection strict --output data/eval_corpus/failure_report_strict
```
测试框架在两种二进制投影(宽松:SUSPICIOUS+ 算作 PHISHING;严格:LIKELY_PHISHING+)下生成逐样本的 TP/FP/TN/FN 标志。汇总的精确率/召回率/F1 和准确率均从这些标志计算而来。
## 检测覆盖范围
该流水线涵盖了**TA0001 Initial Access**、**TA0042 Resource Development**、**TA0005 Defense Evasion** 和 **TA0008 Lateral Movement** 中约 12 种子技术。包含每个分析器依据和已知空白的完整映射位于 [`docs/MITRE_ATTACK_MAPPING.md`](docs/MITRE_ATTACK_MAPPING.md)。
| 战术 | 涵盖的技术 |
| ------------------------ | ----------------------------------------------------------------------------------- |
| Initial Access | T1566.001, T1566.002, T1566.003, T1534, T1078 (仅异常) |
| Resource Development | T1583.001, T1584.001, T1585.002 |
| Defense Evasion | T1656, T1036.005, T1027.006 (HTML 走私) |
| User Execution | T1204.001, T1204.002 |
映射文档还包括一个明确的**未涵盖技术**表 — 诚实的读者会询问的内容,以及该流水线不假装能检测到的内容(完整的 T1078、T1189、T1497 等)。
### 5 阶段流水线
1. **摄取** — 带有 UID 跟踪的 IMAP 轮询、手动 `.eml`/`.msg` 上传、FastAPI 上传端点
2. **提取** — MIME 解析、标头分析(SPF/DKIM/DMARC)、URL 提取、二维码解码、通过 magic bytes 进行附件分类
3. **分析** — 8 个并发分析器:标头分析、URL 信誉、域名情报、URL 沙箱引爆、品牌冒充、附件沙箱、NLP 意图分类、支付欺诈
4. **决策** — 带有覆盖规则(已知恶意软件、BEC 意图、已确认的反馈源)的加权置信度评分、置信度上限、判定阈值
5. **反馈** — 通过 REST API 提交分析师判定结果、逻辑回归权重重训练、计划重训练循环
## 支付欺诈防火墙
该流水线现在包含一个针对发票诈骗、供应商冒充和商业电子邮件入侵 (BEC) 的特定支付欺诈层。它保留了检测工程核心,但为 SME 提供了直接的支付释放决策。
`payment_fraud` 分析器将电子邮件分析转化为业务决策:
| 决策 | 含义 |
|----------|---------||
| `SAFE` | 未发现实质性的支付欺诈指标。 |
| `VERIFY` | 在独立验证供应商或高管之前,不应进行支付。 |
| `DO_NOT_PAY` | 在验证完成前,应阻止释放资金。 |
检测到的支付信号包括更改的银行详细信息、支付主题的门户/操作链接、紧急支付压力、绕过审批的语言、CEO/CFO 转账请求、回复地址不匹配、电子邮件身份验证失败、免费电子邮件供应商请求、有风险的发票附件,以及对 BSB、账号、IBAN、SWIFT/BIC 代码、PayID、ABN 和金额的掩码提取。
有关产品工作流和 SME 定位,请参阅 [`docs/payment-fraud-firewall.md`](docs/payment-fraud-firewall.md)。
有关首个 Agent 原生工具契约、CLI、MCP stdio 服务器、已提交的样本邮件、连接代码片段、MCPB desktop-extension 包、叙述性演示脚本、产品外壳和仅限样本的演示页面,请参阅 [`docs/agent-payment-tool.md`](docs/agent-payment-tool.md)。
有关 Gemini CLI 验证包和录制脚本,请参阅 [`docs/gemini-mcp-demo-kit.md`](docs/gemini-mcp-demo-kit.md)。
要启动本地支付诈骗数据集:
```
python scripts/payment_dataset.py init --dataset data/payment_scam_dataset
python scripts/payment_dataset.py seed-synthetic --dataset data/payment_scam_dataset --scam-count 50 --legit-count 50 --safe-count 50 --seed 1337 --clean
python scripts/payment_dataset.py seed-public-advisory --dataset data/payment_scam_dataset --holdout-do-not-pay-count 3 --holdout-verify-count 3
python scripts/payment_dataset.py seed-public-corpus --dataset data/payment_scam_dataset --corpora-dir data/corpora --do-not-pay-count 0 --verify-count 20 --replace-existing
python scripts/payment_dataset.py redact --source path/to/raw-payment-email.eml --output data/payment_scam_dataset/incoming/redacted/vendor-update.eml
python scripts/payment_dataset.py audit-pii --sample data/payment_scam_dataset/incoming/redacted/vendor-update.eml
python scripts/payment_dataset.py add --dataset data/payment_scam_dataset --source path/to/sample.eml --label PAYMENT_SCAM --payment-decision DO_NOT_PAY --scenario bank_detail_change --source-type redacted --split train --verified-by meidie --contains-real-pii no
python scripts/payment_dataset.py validate --dataset data/payment_scam_dataset
python scripts/payment_dataset.py export-eval-labels --dataset data/payment_scam_dataset
python scripts/payment_dataset.py export-ml-jsonl --dataset data/payment_scam_dataset
python scripts/payment_dataset.py readiness --dataset data/payment_scam_dataset
python scripts/payment_eval.py --dataset data/payment_scam_dataset
python scripts/payment_eval.py --dataset data/payment_scam_dataset --split holdout --output-prefix data/payment_scam_dataset/reports/payment_holdout_eval
python scripts/payment_train.py --dataset data/payment_scam_dataset
python scripts/payment_demo.py --dataset data/payment_scam_dataset
python scripts/llm_provider_eval.py --dataset data/payment_scam_dataset --split test --split holdout --max-samples-per-decision 5 --run-live
```
支付数据集同时记录通用标签(`PAYMENT_SCAM`、`LEGITIMATE_PAYMENT`、`NON_PAYMENT`)和预期的业务决策(`SAFE`、`VERIFY`、`DO_NOT_PAY`)。合成种子集仅用于可重复的开发;在声称具备产品指标之前,请将其替换为或补充以涂黑的真实的示例。
`seed-public-advisory` 添加了基于 Scamwatch、cyber.gov.au、FBI 和公开 BEC 报告中公开的 BEC/支付重定向警告模式的非私有 `VERIFY` 和 `DO_NOT_PAY` 示例。这些比纯合成的检查更好,但真实的脱敏收件箱/客户样本仍然是最有力的证据。可选的 holdout 标志使派生自公共数据的行不参与训练,以便您可以检查单独的评估切片。
`seed-public-corpus` 从下载的 Nazario 钓鱼和 SpamAssassin 垃圾邮件语料库中挖掘发票/支付/电汇/银行/账户相关的语言,仅保留明显的支付风险案例,对域名、URL 和支付标识符进行涂黑和中和处理,然后将结果标记为无 PII 的公共样本。其默认设置是的:主要使用原始的公开钓鱼/垃圾邮件作为 `VERIFY` 支付链接和支付通知语言,而建议种子仍然是干净的 `DO_NOT_PAY` BEC/支付重定向模式的更好可重现来源。
脱敏工具对电子邮件和 URL 域名进行化名处理,规范明显的支付标识符,移除非文本附件,并使用非敏感指纹审计结果。在标记之前请手动检查脱敏的 `.eml`,因为姓名和业务上下文可能仍需人工清理。
`scripts/payment_eval.py` 编写 JSON、CSV 和 Markdown 报告,比较预期与预测的 `SAFE`、`VERIFY` 和 `DO_NOT_PAY` 决策,包括按来源类型和划分的准确率。
`scripts/payment_train.py` 从 ML JSONL 导出中训练和测试 TF-IDF + 逻辑回归基线,将被忽略的模型工件写入 `models/payment_classifier/`。Holdout 行被排除在训练之外并单独报告。当 `models/payment_classifier/payment_decision_model.joblib` 存在时,支付分析器会报告一个包含模型预测、置信度、类别概率以及它是否与规则决策不一致的 `ml_decision` 附属结果。在数据集拥有真实的脱敏覆盖范围之前,规则决策仍然是权威的。
`scripts/llm_provider_eval.py` 直接在 `SAFE`、`VERIFY` 和 `DO_NOT_PAY` 标签上对配置的 LLM 提供商进行基准测试,以便可以根据准确率、完成率、延迟和预估的 token 成本(而不是提供商品牌)来选择订阅层级。它支持 DeepSeek、Moonshot/Kimi、Gemini、Anthropic、OpenAI GPT-5.x 和通用的 OpenAI 兼容端点。它默认仅使用无 PII 的行,并在 `data/payment_scam_dataset/reports/` 下写入被忽略的 JSON/Markdown 报告。请有意使用内置的 `--run-live` 守护设置,因为它会将选定的脱敏/公开/合成样本文本发送到外部 LLM API。
`scripts/payment_dataset.py readiness` 计算来源类型、标签、决策和拆分情况,并在非合成覆盖缺失某个支付决策时发出明确警告。
`scripts/payment_demo.py` 打印一个跨越 `SAFE`、`VERIFY` 和 `DO_NOT_PAY` 的紧凑型预期与预测演示,优先使用无 PII 的脱敏/公开样本而不是合成行。
当前本地被忽略的数据集快照 (2026-04-30):259 行,包括 150 个合成样本、46 个公开样本和 63 个脱敏样本。支付决策分别为 113 个 `SAFE`,83 个 `VERIFY`,63 个 `DO_NOT_PAY`。最新的本地 PII 审计发现 0 个问题,规则评估匹配了 259/259 个预期决策,并且 TF-IDF 支付辅助决策达到了 1.000 的测试准确率和 1.000 的 holdout 准确率。请将此视为本地可复现性证据,而非外部产品指标,因为脱敏数据集和训练好的模型工件是故意不提交的。
当前 LLM 提供商试点 (2026-05-03,本地被忽略的支付数据集,无 PII 的 test+holdout 行,每个决策 5 个样本):DeepSeek V4 Flash 得分 14/15,零 API 错误,总预估成本约 $0.0009;Claude Opus 4.7 得分 13/15,约 $0.0744;Kimi K2.6 得分 12/15,约 $0.0084;DeepSeek V4 Pro 得分 10/15,约 $0.0029。Gemini 支持已通过 `GEMINI_API_KEY` 接入,相同的评估切片现在涵盖了 `gemini-3.1-pro-preview` (10/15, ~$0.0220, 6065 ms 中位数)、`gemini-3-flash-preview` (11/15, ~$0.0057, 1668 ms 中位数) 和 `gemini-3.1-flash-lite-preview` (9/15, ~$0.0026, 979 ms 中位数)。OpenAI GPT-5.5 支持已通过 `OPENAI_API_KEY` 接入;在同一切片上,`gpt-5.4-mini` 得分 11/15,约 $0.0066,中位延迟 934 ms,而 `gpt-5.5` 得分 9/15,约 $0.0464,中位延迟 2085 ms。这只是一个试点,而非生产基准。请将 DeepSeek V4 Flash 用作 Starter/Pro/Business 的默认 LLM。更高成本的模型应保留为明确的 Enterprise 审查候选项,仅在更大规模的真实脱敏评估证明具有实质性的质量或规模优势时才替代 DeepSeek。
## 快速开始
### 前置条件
Python 3.11+,在 Linux/macOS 上你需要 `libzbar0` 用于二维码解码:
```
# Debian/Ubuntu
sudo apt-get install libzbar0
# macOS
brew install zbar
```
### 本地设置
```
# 1. Clone and install
git clone https://github.com/meidielo/Automated-Phishing-Detection.git
cd Automated-Phishing-Detection
pip install -r requirements.txt
# 2. Configure
cp .env.example .env
# Edit .env with your API keys. See .env.example for signup links
# and which keys are optional. The pipeline degrades gracefully:
# analyzers without keys are excluded from scoring.
# 3. Run the eval harness against the included 22-sample corpus
python scripts/run_eval.py
# 4. Analyze a single email
python main.py --analyze tests/real_world_samples/sample_01_microsoft_credential_harvest.eml
# 5. Start the server (dashboard + feedback API)
python main.py --serve
```
### Docker
```
cp .env.example .env
# Edit .env with your API keys
docker-compose up -d
# Dashboard at http://localhost:8000
```
### 验证其是否有效
启动服务器后(步骤 5 或 Docker),检查健康检查端点:
```
python -c "import urllib.request; print(urllib.request.urlopen('http://localhost:8000/api/health').read().decode())"
```
## 配置
配置从两个来源加载(环境变量会覆盖 YAML):
| 来源 | 文件 | 目的 |
|--------|------|---------|
| YAML | `config.yaml` | 非秘密默认值(权重、阈值、超时) |
| 环境变量 | `.env` | 秘密信息(API 密钥、IMAP 凭证) |
有关所有可用选项,请参阅 `config.yaml` 中的内联文档。
### 公开演示模式
设置 `PUBLIC_DEMO_MODE=true` 可将 `/demo` 和 `/agent-demo` 公开为仅限样本的公开预览。当公开演示模式关闭时,这些 HTML 页面会重定向回 `/product`,而不是显示原始 API 错误。这故意不是对真实应用的认证绕过:`/analyze`、`/dashboard`、`/monitor`、`/accounts`、实时上传分析、邮箱监控、反馈学习以及账户管理仍然需要分析师 token。公共根路径 `/` 重定向到 `/product`,以便访问者不会直接进入管理员登录页面。
演示页面使用固定的样本内容,`/api/demo/status` 会广播锁定的功能。在公开暴露部署之前,请保持配置好 `ANALYST_API_TOKEN`。真正的多用户邮箱版本仍然需要每个用户的 OAuth 或 IMAP 凭证以及加密的每用户 token,以便每个人只能看到自己的邮箱。
`/api/demo/plans` 暴露了演示所使用的公开计划和功能锁定目录。相同的计划别名现在支持 SaaS 账户基础,并计划稍后支持 Stripe Billing webhook 状态。有关用户/组织数据库架构、租户隔离规则和订阅推出顺序,请参阅 [`docs/saas-architecture.md`](docs/saas-architecture.md)。
### SaaS 账户模式
`/app` 提供一个独立于分析师仪表盘的普通用户登录外壳。它使用已签名的用户会话、在设置 cookie 的认证路由上进行同源检查、对已登录的更改操作进行 CSRF 保护,并使用 `data/saas.db` 存储 `users`、`organizations`、`memberships`、`subscriptions`、`scan_jobs`、`scan_results`、`usage_events`、`feature_locks` 和 `audit_logs`。
默认情况下公共注册是关闭的:
```
SAAS_SESSION_SECRET=change-me-to-a-long-random-secret
SAAS_DB_PATH=data/saas.db
SAAS_PUBLIC_SIGNUP_ENABLED=false
PASSWORD_RESET_TOKEN_TTL_MINUTES=30
```
通过 `/api/saas/auth/password-reset/request` 和 `/api/saas/auth/password-reset/confirm` 支持密码重置。重置 token 以哈希形式存储,在 `PASSWORD_RESET_TOKEN_TTL_MINUTES` 后过期,并且是一次性使用的。请求受每个客户端/电子邮件对的速率限制,以减少重置链接垃圾信息。配置 SMTP 通过 Zoho Mail 或其他事务性 SMTP 提供商发送重置链接:
```
SMTP_HOST=smtp.zoho.com
SMTP_PORT=587
SMTP_USERNAME=alerts@example.com
SMTP_PASSWORD=zoho-app-specific-password
SMTP_FROM_EMAIL=alerts@example.com
SMTP_FROM_NAME=PhishAnalyze
SMTP_USE_SSL=false
SMTP_STARTTLS=true
```
Zoho Mail 支持在端口 `465` 上使用 SSL 或在端口 `587` 上使用 TLS/STARTTLS 的 `smtp.zoho.com`。如果启用了 Zoho 双重身份验证,请使用 Zoho 应用专用密码而不是邮箱登录密码。如果未配置 SMTP,API 将返回通用的成功响应而不发送邮件,从而避免泄露账户是否存在。
启用注册后,免费账户每月可进行 5 次手动扫描。`/api/saas/analyze/upload` 将用户扫描存储在租户范围的 SaaS DB 中,而不是共享的分析师 `data/results.jsonl` 日志中。昂贵的分析器在加载客户端之前会检查计划权限;锁定的检查会返回结构化的 `feature_locked` 元数据,以便 UI 可以显示所需的套餐级别,而不是消耗付费 API 配额。
Stripe Billing 通过托管的 Checkout 和 Customer Portal 接入。在 `STRIPE_PRICE_STARTER` / `STRIPE_PRICE_PRO` / `STRIPE_PRICE_BUSINESS` 中配置 `PUBLIC_BASE_URL`、`STRIPE_SECRET_KEY`、`STRIPE_WEBHOOK_SECRET` 以及每月的 Stripe Price ID。年度结账使用 `STRIPE_PRICE_STARTER_YEARLY` / `STRIPE_PRICE_PRO_YEARLY` / `STRIPE_PRICE_BUSINESS_YEARLY`。应用显示较低的年度每月定价,将选定的计费间隔发送到 Checkout,默认通过 `STRIPE_ADAPTIVE_PRICING_ENABLED=true` 启用 Stripe Adaptive Pricing,并将 `checkout.session.completed` 以及 `customer.subscription.*` 事件镜像到 `subscriptions` 中。如果缺少 Stripe 环境变量或运行时密钥被 Stripe 拒绝,结账将报告安全的计费不可用响应,而不是假装计费功能在线。
## 所需的 API 密钥
| 服务 | 环境变量 | 用途 | 免费套餐 |
|---------|---------------------|---------|-----------|
| VirusTotal | `VIRUSTOTAL_API_KEY` | URL/文件信誉 | 500 次/天 |
| urlscan.io | `URLSCAN_API_KEY` | URL 扫描 | 5,000 次/天 |
| AbuseIPDB | `ABUSEIPDB_API_KEY` | IP 信誉 | 1,000 次/天 |
| Google Safe Browsing | `GOOGLE_SAFE_BROWSING_API_KEY` | URL 威胁匹配 | 10,000 次/天 |
| Hybrid Analysis | `HYBRID_ANALYSIS_API_KEY` | 文件沙箱引爆 | 有限 |
可选:DeepSeek 是 Starter/Pro/Business NLP 意图分类中默认的成本优先 LLM。使用 `DEEPSEEK_API_KEY` 设置 `LLM_PROVIDER=deepseek`,然后在任何 Enterprise 覆盖之前,在脱敏样本上运行 `scripts/llm_provider_eval.py`。支持 Anthropic、Gemini、Kimi、OpenAI 和通用的 OpenAI 兼容提供商进行基准测试,但仅当评估显示出足够的质量或规模优势以证明额外成本合理时,才应替代 DeepSeek。ANY.RUN/Joe Sandbox 密钥可解锁额外的沙箱提供商。
## 项目结构
```
src/
├── config.py # Configuration (env + YAML)
├── models.py # Data models and enums
├── ingestion/
│ ├── imap_fetcher.py # IMAP polling with UID tracking
│ └── manual_upload.py # File/directory upload handler
├── extractors/
│ ├── eml_parser.py # MIME email parsing
│ ├── header_analyzer.py # SPF/DKIM/DMARC validation
│ ├── url_extractor.py # URL extraction and defanging
│ ├── qr_decoder.py # QR code decoding from images/PDFs
│ ├── metadata_extractor.py # Sender/reply chain metadata
│ └── attachment_handler.py # Magic byte classification, macros
├── analyzers/
│ ├── url_reputation.py # Multi-service URL checking
│ ├── domain_intel.py # WHOIS age, DNS, phishing feeds
│ ├── url_detonator.py # Headless browser detonation
│ ├── brand_impersonation.py # Visual similarity (pHash/SSIM)
│ ├── nlp_intent.py # LLM + sklearn intent classification
│ ├── sender_profiling.py # Behavioral baseline tracking
│ ├── attachment_sandbox.py # File sandbox submission
│ └── clients/ # API client layer
│ ├── base_client.py # Circuit breaker, cache, rate limiting
│ ├── virustotal.py
│ ├── urlscan.py
│ ├── abuseipdb.py
│ ├── google_safebrowsing.py
│ ├── whois_client.py
│ └── sandbox_client.py
├── scoring/
│ ├── decision_engine.py # Weighted scoring + overrides
│ ├── confidence.py # Multi-source confidence aggregation
│ └── thresholds.py # Verdict range management
├── feedback/
│ ├── feedback_api.py # FastAPI analyst endpoints
│ ├── database.py # SQLAlchemy ORM
│ ├── retrainer.py # Logistic regression weight tuning
│ └── scheduler.py # Background retraining
├── reporting/
│ ├── report_generator.py # JSON + HTML reports
│ ├── ioc_exporter.py # STIX 2.1 bundle export
│ └── dashboard.py # Web dashboard
├── orchestrator/
│ └── pipeline.py # Main async orchestrator
└── utils/
├── cyberchef_helpers.py # Encoding/decoding utilities
├── screenshot.py # URL detonation captures
└── validators.py # Input validation
```
## 检测内容导出
除了 JSON/HTML 报告外,流水线还会生成两种互补的检测工件:
| 格式 | 用途 | 生成器 |
| --------- | ---------------------------------------------------------------- | -------------------------------------- |
| STIX 2.1 | 用于与 TI 平台(MISP, OpenCTI, TAXII)共享的每事件 IOC 捆绑包 | `src/reporting/ioc_exporter.py` |
| Sigma | 用于 SIEM 消费的每活动检测规则,外加涵盖更广泛行为模式的静态规则库 | `src/reporting/sigma_exporter.py` + `sigma_rules/` |
```
# Single email → JSON report
python main.py analyze tests/sample_emails/suspicious.eml --format json
# Single email → STIX 2.1 bundle of detected IOCs
python main.py analyze tests/sample_emails/suspicious.eml --format stix
# Single email → Sigma rule scoped to this campaign's observables
python main.py analyze tests/sample_emails/suspicious.eml --format sigma
# All four (json + html + stix + sigma) written side by side
python main.py analyze tests/sample_emails/suspicious.eml --format all
```
[`sigma_rules/`](sigma_rules/) 中的静态 Sigma 规则库随附了针对视觉品牌冒充、网络钓鱼、新注册域名、BEC 电汇欺诈意图、HTML 走私和带有附件的身份验证失败模式的手写规则。每个规则都带有引用上述覆盖范围映射中相同 ATT&CK 技术的 `tags:`。
## 测试
测试套件包含**61 个测试模块中的 1218 个测试**(单元 + 集成),涵盖了每个分析器、决策引擎覆盖规则(包括捕获纯文本 BEC 的第 7 周期排序修复)、带有显式上限阈值测试的跨分析器校准通过 (ADR 0001)、带有跨重启确凿证据测试的持久化 email_id 查找索引 (ADR 0002)、评分置信度上限、IOC 导出、Sigma 导出器、URL 信誉死亡域名置信度降级、凭证加密迁移、LLM 确定性契约加上 OpenAI 兼容的提供商量布、通用钓鱼 ML 基线、支付欺诈数据集/评估/训练/演示工作流、带有恶意 XSS 负载的 body_html 清理器、生成的 HTML 报告自动转义、results、alerts、feedback、SaaS 扫描行和发件人配置文件中的保留和按主题擦除、在严格的 dashboard CSP 下自托管的图表资产/回退渲染、公开演示模式护栏SaaS 账户/会话/配额/密码重置/登出关卡、分析师和 SaaS 登录失败限制、紧凑型分析师分析页面布局、Stripe Checkout/webhook 订阅镜像、安全的 Stripe 凭证失败响应、Adaptive Pricing 元数据、基于链接的 SaaS 身份验证导航、隐藏的升级选项、月度/年度订阅定价、计划/功能锁定元数据、静态资产缓存清理、远离管理员登录的公共根路由、隐私安全的共享反馈模态框、Docker Playwright 版本固定、运维备份/健康脚本、LLM 提供商基准测试以及 Web 安全中间件(bearer 认证、带有 CSRF 的浏览器会话认证、带有 CSRF 的用户会话认证、Stripe webhook 签名、SSRF 防护、URL 引爆重定向/子资源 SSRF 阻止、安全的引爆错误渲染、安全标头)。CI 会在每次推送和针对哈希锁定的锁定文件的新检出上的 PR 时运行完整套件以及 Playwright dashboard 图表冒烟检查。通过一次性分支上故意设置为红色的健全性检查验证了 CI 咬合。
```
# Run all tests
python -m pytest
# Run with verbose output
python -m pytest -v
# Run a single module
python -m pytest tests/unit/test_decision_engine.py
# Coverage HTML report
python -m pytest --cov=src --cov-report=html
```
| 层级 | 测试模块 |
| ---------------- | ----------------------------------------------------------------------------------------------------- |
| 提取器 | `test_eml_parser`, `test_header_analyzer`, `test_url_extractor`, `test_qr_decoder`, `test_attachment_handler` |
| 分析器 | `test_attachment_sandbox`, `test_brand_impersonation`, `test_url_detonation` |
| 评分 | `test_decision_engine`, `test_scoring` |
| 摄取 | `test_imap_fetcher`, `test_email_monitor`, `test_blocklist_allowlist` |
| 反馈 | `test_feedback_api`, `test_retrainer` |
| 报告 | `test_report_generator`, `test_ioc_exporter` |
| 安全与工具 | `test_security`, `test_web_security`, `test_html_sanitizer`, `test_credentials`, `test_multi_account_monitor`, `test_models`, `test_utils` |
| 检测内容 | `test_sigma_exporter`(34 个测试,涵盖规范分析器键、ATT&CK 标签推导、确定性 UUID) |
| URL 信誉 | `test_url_reputation`(11 个测试,包括死亡域名置信度降级回归) |
| LLM 客户端 | `test_anthropic_client`, `test_openai_compatible_client`, `test_llm_provider_eval`, `test_pipeline_llm_provider`(在提供商支持的情况下的确定性 JSON 调用、模型版本捕获、提供商量布、PII 安全的提供商基准测试) |
| 集成 | `test_full_pipeline` |
## 已知限制
1. **依赖网络的功能**:URL 引爆、API 客户端调用和 IMAP 轮询需要出站互联网访问。所有 API 客户端在离线时都会优雅降级(断路器模式返回空结果,而不是错误)。
2. **沙箱引爆需要浏览器引擎**:URL 引爆和屏幕截图捕获需要 Playwright 或 Selenium 配合无头 Chromium。如果没有浏览器引擎,这些分析器将返回空结果,流水线将继续以降低的置信度运行。
3. **二维码解码依赖项**:完整的 QR 解码需要 `pyzbar`、`opencv-python` 和系统库 `libzbar0`。如果没有这些,将无法提取图像中 QR 嵌入的 URL。安装方法:`apt-get install libzbar0 && pip install pyzbar opencv-python`。
4. **NLP 意图分类**:最佳结果需要 LLM API 密钥。为了控制生产成本,Starter、Pro 和 Business 请使用 `LLM_PROVIDER=deepseek`/`DEEPSEEK_API_KEY`。当前无 PII 的支付决策试点倾向于 `deepseek-v4-flash` 的准确性、延迟和成本。仅在 `scripts/llm_provider_eval.py` 在您的脱敏数据集上显示出真正增益后,才将 Anthropic Claude、Kimi、Gemini Pro、GPT-5.5 或其他更高成本的模型用作 Enterprise 审查候选项。支持 Moonshot/Kimi、Gemini、OpenAI GPT-5.x 和通用的 OpenAI 兼容 Chat Completions 提供商。在无 LLM 时回退到准确性较低的 sklearn TF-IDF 分类器(约 70%,相比之下使用 LLM 约为 92%)。
5. **品牌冒充检测**:需要 `imagehash` 以及 `brand_references/` 中的参考品牌 Logo。如果没有参考图像,将跳过视觉相似度评分。流水线仍然通过域名分析检测品牌冒充。
6. **沙箱分析延迟**:文件沙箱引爆(Hybrid Analysis, ANY.RUN, Joe Sandbox)每个文件可能需要 2-10 分钟。对于包含大量附件的电子邮件,可能需要增加流水线超时时间(默认为 120 秒)。
7. **STIX 2.1 导出**:需要 `stix2` 库(已在 `requirements.txt` 中固定)。Sigma 规则导出没有额外的依赖项 — YAML 是手动生成的。
8. **速率限制**:免费套餐 API 密钥有严格的速率限制。断路器和 TTL 缓存有所帮助,但大批量部署需要付费 API 层级或自托管替代方案。
9. **无 GPU 加速**:NLP 意图分类和图像相似度仅在 CPU 上运行。这对于电子邮件容量的工作负载足够,但不适用于大型存档的批量回顾性分析。
10. **公开演示仅限样本**:`PUBLIC_DEMO_MODE=true` 打开 `/demo`,但它不会连接访问者的邮箱,也不会让公共用户运行付费 API 支持的分析。每用户邮箱访问需要单独的多用户认证和存储设计。
11. **单节点部署**:当前架构在单个节点上运行。对于多节点部署,您需要在摄取和流水线之间添加消息队列(Redis/RabbitMQ),异步生成器接口旨在支持这一点,但并未提供开箱即用的实现。
## Docker 部署
```
docker-compose up -d
```
当前的 `docker-compose.yml` 在 `orchestrator` 中运行 dashboard/流水线,并在单独的 `browser-sandbox` 服务中运行 URL 引爆。`PLAYWRIGHT_WS_ENDPOINT=ws://browser-sandbox:3000/` 使分析器连接到隔离的 Playwright 服务器,而不是在 orchestrator 容器内部启动 Chromium。orchestrator 镜像仍然支持本地 Playwright 启动,用于非 Docker 开发。
该镜像:
- 使用带有 `pip install --require-hashes` 的 `requirements.lock` 进行安装,因此任何依赖项篡改都会导致构建失败。
- 将浏览器沙箱 `npx playwright@... run-server` 版本固定到 `requirements.lock` 中相同的 Playwright 版本;如果 Compose 和 Python 客户端版本不一致,单元测试将失败。
- 使用基于 `urllib.request` 的健康检查(无 `curl` 包),在启动应用程序之前等待浏览器沙箱健康,并为应用程序提供更长的启动窗口,然后再判定其不健康。
- 短暂以 root 身份运行 `docker-entrypoint.sh`,将 `/app/data` 和 `/app/logs` 绑定挂载的拥有权更改为 UID 1000,然后在执行流水线之前通过 `gosu` 切换到非 root 的 `phishing` 用户。这解决了在主机绑定挂载源归 root 所有的 Linux 主机上,以前会破坏 `results.jsonl` 写入的绑定挂载 UID 不匹配问题。
- 生产环境 compose 绑定 `127.0.0.1:8000:8000` 用于主机本地健康探测,同时使服务远离公共和 Tailscale 接口。Cloudflare Tunnel 仍然可以通过 Docker 网络到达 `http://orchestrator:8000`。
- `scripts/docker_deploy.sh` 使用当前的 git SHA 进行拉取和重建,以原始 Docker Compose env-file 模式从 `${APP_ENV_FILE:-.env}` 读取运行时秘密,生产环境隧道部署需要 `CLOUDFLARE_TUNNEL_TOKEN`,并等待健康的 orchestrator 以及运行中的 `cloudflared-tunnel`。`scripts/docker_self_heal.sh` 旨在用于主机 cron/systemd,以重启 Docker 标记为 `unhealthy` 但不会自动重启的容器。
- HTML 页面将构建/静态资产版本附加到 `/static/*` URL,以便在部署后浏览器和 Cloudflare 缓存不会继续提供过时的 dashboard 或应用程序 JavaScript。`/api/health` 返回活动的构建 SHA,以便快速检查部署的版本。
## DNS 自动化
该项目在 Cloudflare DNS 之后运行(从 Netlify DNS 迁移而来)。一个辅助脚本可自动为新托管的 Netlify 站点添加 CNAME 记录:
```
# One-time setup: create a Cloudflare API token with Zone > DNS > Edit permission
cp .env.example .env
# Fill in CF_API_TOKEN (CF_ZONE_ID and CF_DOMAIN are pre-filled)
# Add a new subdomain pointing to a Netlify app
./scripts/cf-dns-add.sh myapp cool-blog-abc123
# Creates: myapp.mdpstudio.com.au → cool-blog-abc123.netlify.app (DNS only)
```
该脚本在创建之前会检查现有记录,在覆盖之前会提示,并在之后提醒您在 Netlify 的站点设置中添加自定义域。需要 `curl` 和 `jq`。
对于由隧道支持的服务(如 phishanalyze),路由在 Cloudflare Zero Trust dashboard 中的 Networks → Connectors → tunnel → Published application routes 下配置,而不是通过此脚本。
## 数据保留与隐私
`data/results.jsonl`、`data/alerts.jsonl`、`data/feedback.db`、`data/saas.db` 和 `data/sender_profiles.db` 中存储的电子邮件/结果工件可能包含受澳大利亚隐私法和欧盟 GDPR 约束的受监管个人信息。该流水线附带 30 天的默认保留窗口和一个 `purge` CLI 子命令:
```
# Show what would be deleted without modifying the file
python main.py purge --dry-run
# Apply the default 30-day retention from config
python main.py purge
# Custom retention window
python main.py purge --older-than 7
# Strict mode: also drop rows with unparseable timestamps
python main.py purge --strict
# Purge every supported runtime artifact
python main.py purge --target all
# Erase one address/email_id from results, alerts, feedback labels, and sender profiles
python main.py purge --target all --by-address person@example.com --dry-run
python main.py purge --target all --by-address person@example.com
```
每天从 cron 运行基于时间的清除。通过 `config.yaml` 中的 `data_retention_days` 或 `DATA_RETENTION_DAYS` 环境变量配置默认保留期。使用 `--by-address` 处理每个数据主体的擦除请求。有关完整的隐私威胁模型,请参见 `THREAT_MODEL.md` 第 6a 节。
## 生产运维
运维脚本:
```
# Runtime backup, excluding secrets by default
python scripts/backup_runtime_data.py --destination backups --retention-days 14
# Uptime plus mailbox-monitor freshness alert
python scripts/production_health_check.py --base-url https://detect.example.com --token "$ANALYST_API_TOKEN" --require-monitor-running
# Load/error probe against a deployment with mailbox monitoring enabled
python scripts/monitor_load_test.py --base-url https://detect.example.com --token "$ANALYST_API_TOKEN" --duration-seconds 60 --concurrency 8 --require-monitor-running
# Vendored Chart.js integrity check
python scripts/vendor_chartjs.py --check
```
有关 cron、logrotate、备份、正常运行时间、告警和负载测试指南,请参见 [`docs/production-operations.md`](docs/production-operations.md)。
## 项目文档
| 文件 | 用途 |
| ---------------------------------------------------------- | -------------------------------------------------------------------------------- |
| [`docs/MITRE_ATTACK_MAPPING.md`](docs/MITRE_ATTACK_MAPPING.md) | 每个分析器的 ATT&CK 技术覆盖范围及明确的空白 |
| [`THREAT_MODEL.md`](THREAT_MODEL.md) | 按信任边界划分的 STRIDE、对手原型、残余风险、非目标 |
| [`SECURITY.md`](SECURITY.md) | 漏洞披露政策、支持的版本、加固指南 |
| [`docs/security-audit-2026-05-03.md`](docs/security-audit-2026-05-03.md) | 最新的 MCP、认证、部署和依赖审计说明 |
| [`docs/production-operations.md`](docs/production-operations.md) | 生产备份、健康、保留、告警和负载测试操作手册 |
| [`docs/saas-architecture.md`](docs/saas-architecture.md) | 用户登录、租户数据库、计划关卡和 Stripe Billing 推出 |
| [`docs/gemini-mcp-demo-kit.md`](docs/gemini-mcp-demo-kit.md) | Gemini MCP 演示提示、录制流程和安全防护措施 |
| [`docs/agent-payment-three-case-transcript.md`](docs/agent-payment-three-case-transcript.md) | Agent 支付工具的 SAFE、VERIFY 和 DO_NOT_PAY 记录 |
| [`docs/EVALUATION.md`](docs/EVALUATION.md) | 评估方法和语料库计划 |
| [`docs/adr/0001-cross-analyzer-context-passing.md`](docs/adr/0001-cross-analyzer-context-passing.md) | 两阶段校准设计的 ADR |
| [`docs/adr/0002-persistent-email-id-lookup-for-feedback.md`](docs/adr/0002-persistent-email-id-lookup-for-feedback.md) | 持久化 email_id 查找索引的 ADR |
| [`docs/calibration_rules.md`](docs/calibration_rules.md) | 跨分析器校准规则及其 FP/FN 动机和测试的注册表 |
| [`docs/writeups/nlp-nondeterminism.md`](docs/writeups/nlp-nondeterminism.md) | 草案报告:为什么 temperature=1 会悄然破坏测试指标 |
| [`docs/writeups/calibration-rule-patterns.md`](docs/writeups/calibration-rule-patterns.md) | 草案报告:抑制与佐证作为模式选择 |
| [`HISTORY.md`](HISTORY.md) | 8 个周期的历程总结、每周期表格、未决事项、计数器 |
| [`CONTRIBUTING.md`](CONTRIBUTING.md) | 项目本地约定:工作流、ADR 模式、回归测试命名 |
| [`ROADMAP.md`](ROADMAP.md) | 计划中、进行中和明确推迟的工作 |
| [`lessons-learned.md`](lessons-learned.md) | 审计周期中发现的检测质量错误的诚实事后分析 |
| [`sigma_rules/README.md`](sigma_rules/README.md) | 静态 Sigma 规则库索引和 logsource 适配指南 |
## 许可
参见 LICENSE 文件。
标签:AI代理集成, BECE防范, DAST, IOC生成, MCP工具, MITRE ATT&CK映射, NLP, Python, Sigma规则, SOC自动化, STIX 2.1, 威胁情报, 安全分析师工具, 开发者工具, 异常检测, 异步处理, 恶意软件分析, 支付欺诈防护, 文本分类, 无后门, 机器学习评估, 欺诈检测, 特征检测, 目标导入, 网络安全, 自动化流水线, 请求拦截, 逆向工具, 金融安全, 钓鱼邮件检测, 隐私保护