nishu2402/android-malware-detection-ml
GitHub: nishu2402/android-malware-detection-ml
基于Drebin-215数据集使用静态分析检测Android恶意软件的机器学习分类系统。
Stars: 1 | Forks: 0
# 🛡️ ANDROID 恶意软件检测 — DREBIN-215
## 👾 作者
### Nisarg Chasmawala · 昵称: **HEAVEN**
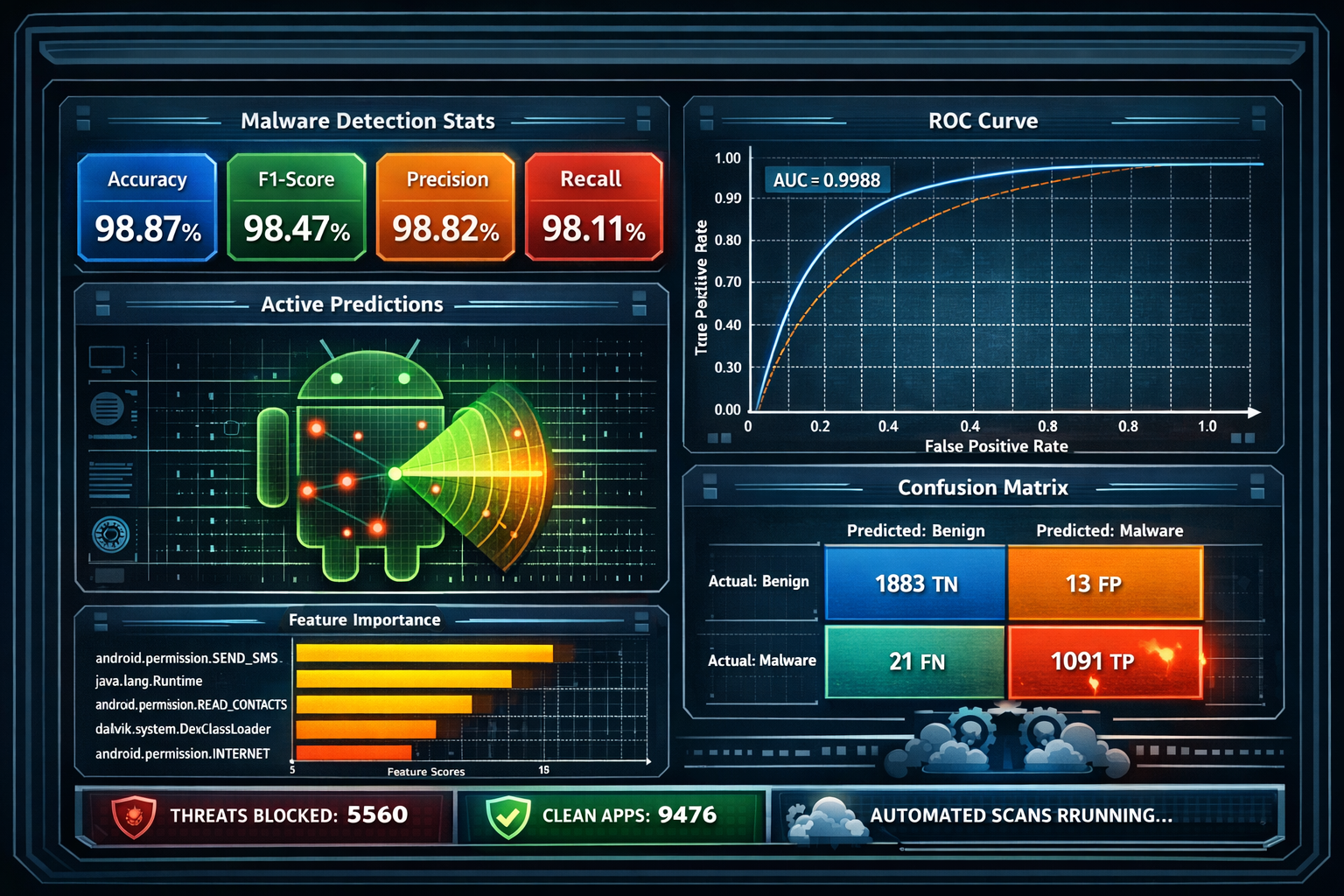 ## 💡 核心思路
## 💡 核心思路
 ## 🔍 降维与特征选择策略
## 🔍 降维与特征选择策略
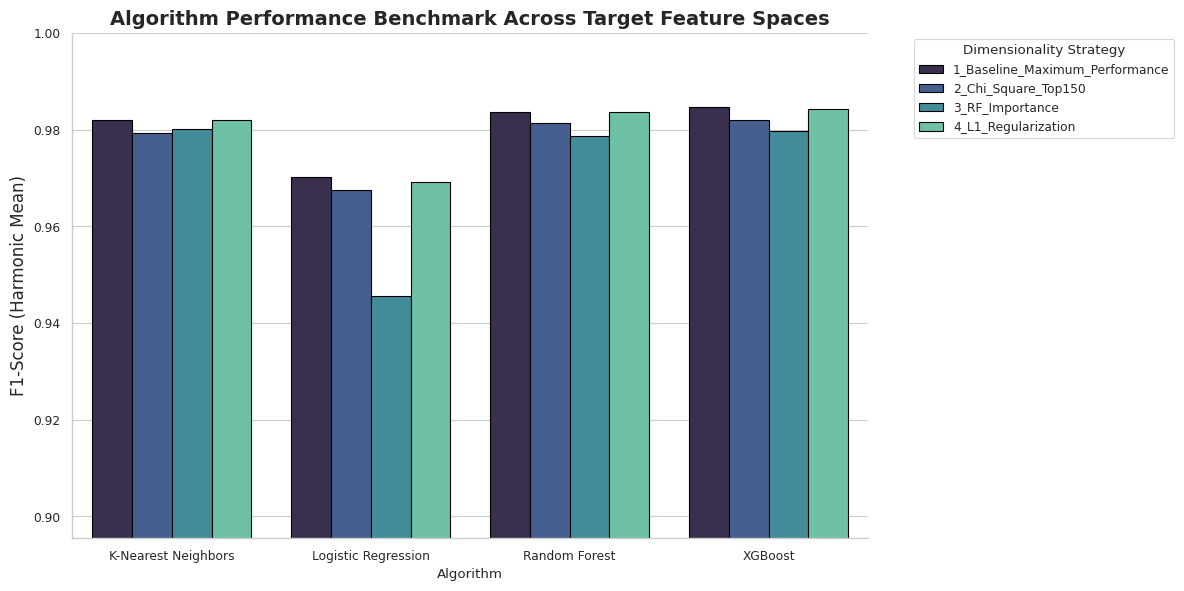 ## 🥇 为什么 XGBoost 胜出
### 3. 添加数据集
### 4. 运行笔记本
```
jupyter notebook ANDROID_MALWARE_CLASSIFICATION_PIPELINE.ipynb
```
### 5. 加载主模型进行推理
```
import joblib
import numpy as np
# ── 加载主管道 (XGBoost, Scenario A) ───────────────────
pipeline = joblib.load("saved_models/0_MASTER_MODEL/Ultimate_Master_Pipeline.pkl")
# ── 单个APK推理 ─────────────────────────────────────────
# 从APK清单构建215元素二进制特征向量
# 1 = 权限/API存在,0 = 不存在
X_apk = np.zeros((1, 215))
# 示例:具有可疑权限+API调用的高风险APG
X_apk[0, [12, 45, 67, 89, 102]] = 1 # READ_SMS, SEND_SMS, execShell, getDeviceId, crypto
prediction = pipeline.predict(X_apk)
probability = pipeline.predict_proba(X_apk)
label = "🚨 MALWARE" if prediction[0] == 1 else "✅ BENIGN"
print(f"Classification: {label}")
print(f"Malware probability: {probability[0][1]:.4f}")
# → 分类:🚨 恶意软件
# → 恶意软件概率:0.9873
# ── 加载单个场景模型 ───────────────────────────────
xgb_baseline = joblib.load("saved_models/1_Baseline_Maximum_Performance/XGBoost.pkl")
scaler = joblib.load("saved_models/1_Baseline_Maximum_Performance/scaler.pkl")
features = joblib.load("saved_models/1_Baseline_Maximum_Performance/selected_features.pkl")
X_scaled = scaler.transform(X_apk)
pred = xgb_baseline.predict(X_scaled)
```
## 🔮 未来路线图
## 🥇 为什么 XGBoost 胜出
### 3. 添加数据集
### 4. 运行笔记本
```
jupyter notebook ANDROID_MALWARE_CLASSIFICATION_PIPELINE.ipynb
```
### 5. 加载主模型进行推理
```
import joblib
import numpy as np
# ── 加载主管道 (XGBoost, Scenario A) ───────────────────
pipeline = joblib.load("saved_models/0_MASTER_MODEL/Ultimate_Master_Pipeline.pkl")
# ── 单个APK推理 ─────────────────────────────────────────
# 从APK清单构建215元素二进制特征向量
# 1 = 权限/API存在,0 = 不存在
X_apk = np.zeros((1, 215))
# 示例:具有可疑权限+API调用的高风险APG
X_apk[0, [12, 45, 67, 89, 102]] = 1 # READ_SMS, SEND_SMS, execShell, getDeviceId, crypto
prediction = pipeline.predict(X_apk)
probability = pipeline.predict_proba(X_apk)
label = "🚨 MALWARE" if prediction[0] == 1 else "✅ BENIGN"
print(f"Classification: {label}")
print(f"Malware probability: {probability[0][1]:.4f}")
# → 分类:🚨 恶意软件
# → 恶意软件概率:0.9873
# ── 加载单个场景模型 ───────────────────────────────
xgb_baseline = joblib.load("saved_models/1_Baseline_Maximum_Performance/XGBoost.pkl")
scaler = joblib.load("saved_models/1_Baseline_Maximum_Performance/scaler.pkl")
features = joblib.load("saved_models/1_Baseline_Maximum_Performance/selected_features.pkl")
X_scaled = scaler.transform(X_apk)
pred = xgb_baseline.predict(X_scaled)
```
## 🔮 未来路线图
| | 详情 |
|---|---|
| 🔗 **LinkedIn** | [linkedin.com/in/nisarg-chasmawala](https://www.linkedin.com/in/nisarg-chasmawala) |
| 🐙 **GitHub** | [github.com/nishu2402](https://github.com/nishu2402) |
## 📋 目录
- [👾 作者](#authors)
- [🧠 项目概述](#project-summary)
- [💡 核心思路](#core-idea)
- [📦 数据集](#dataset)
- [⚙️ 完整流程](#complete-pipeline)
- [🔍 降维与特征选择策略](#feature-selection)
- [🤖 模型详解](#models-explained)
- [📐 评估指标](#metrics)
- [🏆 完整性能](#complete-performance)
- [🔹 场景 A — 基线(215 个特征)](#scenario-a)
- [🔹 场景 B — 卡方检验(前 150 个)](#scenario-b)
- [🔹 场景 C — 随机森林重要性](#scenario-c)
- [🔹 场景 D — L1 正则化](#scenario-d)
- [🥇 为什么 XGBoost 胜出](#why-wins)
- [🗂️ 项目结构](#project-structure)
- [🚀 安装说明](#installation)
- [🔮 未来路线图](#future-roadmap)
- [⚠️ 免责声明](#disclaimer)
## 🧠 项目概述
| 指标 | 数值 |
|---|---|
| 🗃️ **总记录数** | 15,036 条 APK 记录 |
| 🎯 **目标变量** | 类别 — 良性 (B→0) / 恶意软件 (S→1) |
| ⚖️ **类别分布** | 恶意软件: 5,560 (37.0%) · 良性: 9,476 (63.0%) |
| 🔢 **特征** | 215 个二进制属性(权限 + API 调用) |
| 🔀 **训练/测试集划分** | 80% / 20%(分层) |
| 📐 **场景** | 4 个(基线 · 卡方检验 · 随机森林重要性 · L1) |
| 🏆 **最佳 F1** | 98.47%(XGBoost,基线-215) |
| 📈 **最佳 ROC-AUC** | 0.9989(随机森林,基线-215) |
| ✅ **缺失值** | 无 — 数据集 100% 完整 |
| ℹ️ **数据集来源** | [Kaggle — Drebin-215](https://www.kaggle.com/datasets/shashwatwork/android-malware-dataset-for-machine-learning) |
## 💡 核心思路
## 🔍 降维与特征选择策略
## 🥇 为什么 XGBoost 胜出
📋 完整的 requirements.txt
``` pandas>=1.5.0 numpy>=1.23.0 matplotlib>=3.6.0 seaborn>=0.12.0 scikit-learn>=1.3.0 xgboost>=1.7.0 joblib>=1.2.0 jupyter>=1.0.0 ```
⭐ 如果这个项目对您有帮助,请在 GitHub 上给它一个星标!
标签:AMSI绕过, Android APK分析, Android安全, Apex, API调用分析, BSD, Chi-Square特征选择, Drebin数据集, F1分数, Python, ROC-AUC, XGBoost, 二值特征, 二分类, 云安全监控, 威胁检测, 数据挖掘, 无后门, 机器学习, 权限分析, 模型评估, 正则化, 特征选择, 目录枚举, 移动安全, 网络安全, 逆向工具, 随机森林特征重要性, 隐私保护, 静态分析