AdeoluAdegboye/-Real-Time-Fraud-Detection-Pipeline
GitHub: AdeoluAdegboye/-Real-Time-Fraud-Detection-Pipeline
一个基于Kafka和Spark Structured Streaming的实时金融欺诈检测管道,解决传统批处理系统延迟过高无法及时阻止欺诈交易的问题。
Stars: 0 | Forks: 0
# 实时欺诈检测流水线
一个生产级流式数据管道,使用 Apache Kafka、Spark Structured Streaming 和 PostgreSQL 实时检测可疑金融交易 —— 完全通过 Docker 容器化。
## 项目概述
金融欺诈每年给全球经济造成数十亿美元的损失。传统的基于批处理的欺诈检测系统仅在交易发生数小时或数天后才标记可疑活动 —— 这对于防止损失来说太迟了。
本项目通过构建实时流式管道来解决这一问题,该管道能够:
* 持续接收模拟银行交易流
* 在每笔交易到达时应用基于规则的异常检测
* 立即将标记的交易持久化到 PostgreSQL 数据库以供审查
* 可通过机器学习评分层进行扩展,以实现更复杂的检测
该架构反映了 Moniepoint、Paystack 和 Flutterwave 等公司使用的现实世界 Fintech(金融科技)欺诈系统 —— 这些系统的交易监控必须以低延迟和高吞吐量每天处理数百万个事件。
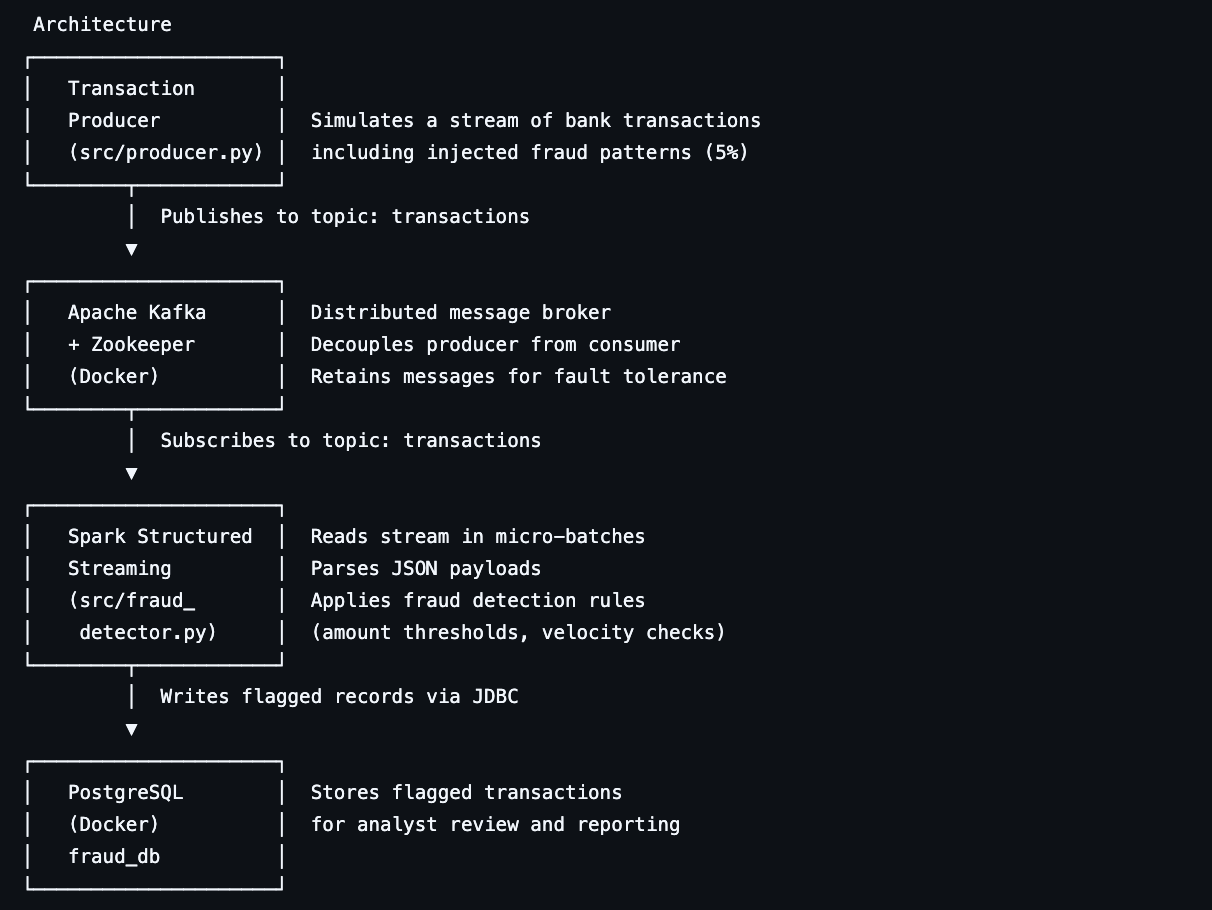
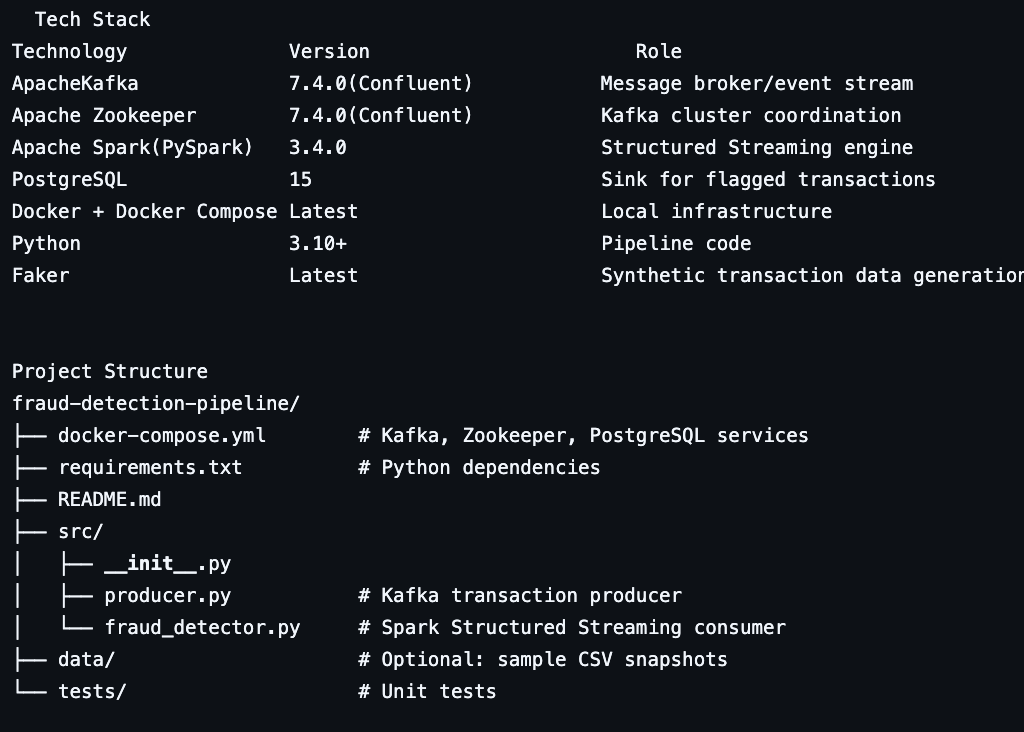 ## 如何运行
### 前置条件
* Docker Desktop 已安装并运行
* Python 3.10+
* Java 17(Spark 要求 —— 见下方说明)
**Java 说明:** Spark 3.4 需要 Java 17。如果您使用的是 Java 21+,请通过 Homebrew 安装 Java 17:
## 如何运行
### 前置条件
* Docker Desktop 已安装并运行
* Python 3.10+
* Java 17(Spark 要求 —— 见下方说明)
**Java 说明:** Spark 3.4 需要 Java 17。如果您使用的是 Java 21+,请通过 Homebrew 安装 Java 17:
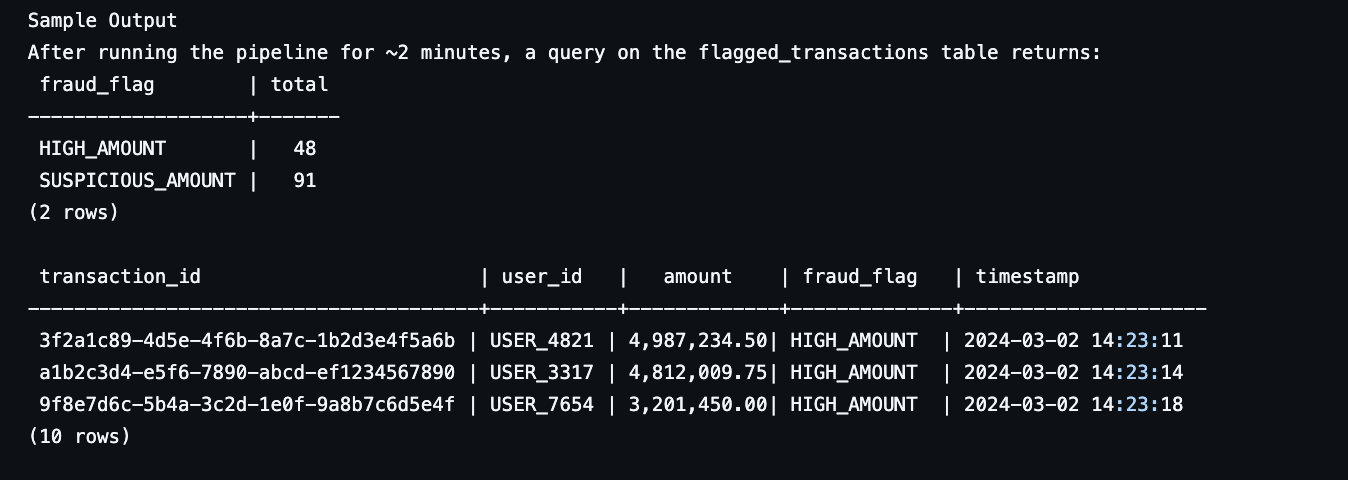 ## 未来改进
1. **基于 ML 的评分** — 用通过 MLflow 服务的训练好的异常检测模型(Isolation Forest 或 AutoEncoder)替换硬编码阈值
2. **速度检查** — 使用 Spark 的窗口聚合标记在滑动时间窗口内进行超过 N 笔交易的用户
3. **GCP Dataflow 部署** — 将 Spark 流式作业迁移到 Google Cloud Dataflow,以进行托管、自动缩放的执行
4. **实时仪表板** — 将 PostgreSQL sink 连接到 Grafana 或 Metabase 仪表板以进行实时欺诈监控
5. **告警** — 当标记的交易率超过阈值时,集成 PagerDuty 或发送 Slack 警报
6. **死信队列** — 将格式错误或无法解析的消息路由到单独的 Kafka topic 以进行调查
7. **多规则引擎** — 添加地理位置速度检查(同一用户在几分钟内在两个相距较远的城市进行交易)
## 未来改进
1. **基于 ML 的评分** — 用通过 MLflow 服务的训练好的异常检测模型(Isolation Forest 或 AutoEncoder)替换硬编码阈值
2. **速度检查** — 使用 Spark 的窗口聚合标记在滑动时间窗口内进行超过 N 笔交易的用户
3. **GCP Dataflow 部署** — 将 Spark 流式作业迁移到 Google Cloud Dataflow,以进行托管、自动缩放的执行
4. **实时仪表板** — 将 PostgreSQL sink 连接到 Grafana 或 Metabase 仪表板以进行实时欺诈监控
5. **告警** — 当标记的交易率超过阈值时,集成 PagerDuty 或发送 Slack 警报
6. **死信队列** — 将格式错误或无法解析的消息路由到单独的 Kafka topic 以进行调查
7. **多规则引擎** — 添加地理位置速度检查(同一用户在几分钟内在两个相距较远的城市进行交易)
## 如何运行
### 前置条件
* Docker Desktop 已安装并运行
* Python 3.10+
* Java 17(Spark 要求 —— 见下方说明)
**Java 说明:** Spark 3.4 需要 Java 17。如果您使用的是 Java 21+,请通过 Homebrew 安装 Java 17:
## 未来改进
1. **基于 ML 的评分** — 用通过 MLflow 服务的训练好的异常检测模型(Isolation Forest 或 AutoEncoder)替换硬编码阈值
2. **速度检查** — 使用 Spark 的窗口聚合标记在滑动时间窗口内进行超过 N 笔交易的用户
3. **GCP Dataflow 部署** — 将 Spark 流式作业迁移到 Google Cloud Dataflow,以进行托管、自动缩放的执行
4. **实时仪表板** — 将 PostgreSQL sink 连接到 Grafana 或 Metabase 仪表板以进行实时欺诈监控
5. **告警** — 当标记的交易率超过阈值时,集成 PagerDuty 或发送 Slack 警报
6. **死信队列** — 将格式错误或无法解析的消息路由到单独的 Kafka topic 以进行调查
7. **多规则引擎** — 添加地理位置速度检查(同一用户在几分钟内在两个相距较远的城市进行交易)标签:Apache Kafka, Docker, ETL, FinTech, JavaCC, NIDS, PMD, PostgreSQL, Python, Spark Structured Streaming, TCP/UDP协议, 云计算, 交易监控, 分布式系统, 反欺诈, 响应大小分析, 大数据, 安全防御评估, 实时流处理, 容器化, 异常检测, 数据工程, 数据库, 数据管道, 无后门, 流式计算, 测试用例, 目录扫描, 网络安全, 规则引擎, 请求拦截, 软件工程, 软件成分分析, 逆向工具, 金融欺诈检测, 隐私保护, 风险控制