Szesnasty/ai-protector
GitHub: Szesnasty/ai-protector
为LLM和工具调用代理提供自托管运行时防护,拦截提示注入、越狱攻击并通过RBAC控制工具权限。
Stars: 35 | Forks: 2
[](LICENSE) [](https://github.com/Szesnasty/ai-protector/actions/workflows/ci.yml) [](BENCHMARK.md) [](BENCHMARK_JAILBREAKBENCH.md)
# AI Protector
**为AI代理配备防护栏,而不是祈祷。**
对于正在交付工具调用代理的团队,AI Protector可以在生产前发现提示注入和未授权工具使用——然后在无LLM参与的情况下确定性执行策略。
**发现漏洞 → 添加防护 → 证明改进。**
| | |
|-|-|
| 97.9%攻击被拦截 (331/338) | 当前基准测试中未观察到误报 |
| ~50毫秒管道开销 | 所有扫描器在本地运行 — 无外部API调用 |
对演示目标或您自己的端点运行50+精选攻击场景。每个场景都包含一个修复提示,指向要启用的确切策略或规则。
实时发送带和不带AI Protector的相同提示。查看防护层具体改变什么的最快方式。
每个请求都获得一个追踪:门控决策、风险分数、RBAC路径和扫描器计时。深入查看任何请求,了解它被允许或阻止的确切原因。
## 已知限制
Protector显著降低了实际风险,但并不能消除它。
- **语义攻击** — 新型注入技术可以绕过基于模式的扫描器。纵深防御可以减轻但无法消除。
- **无正式工具验证** — 工具行为由RBAC和参数验证控制,但执行后的副作用未经验证。
- **领域特定调优** — 默认阈值涵盖一般用途。生产部署需要校准。
- **单节点** — 水平扩展和高可用性尚未实现。
## 文档
| 文档 | 内容 |
|-----|------|
| [代理管道](docs/architecture/AGENT_PIPELINE.md) | 11节点代理管道 — 工具前后门控,三条防线 |
| [代理防火墙管道](docs/architecture/PROXY_FIREWALL_PIPELINE.md) | 9节点代理管道 — 扫描器模型、风险评分 |
| [架构](docs/architecture/ARCHITECTURE.md) | 系统设计、服务拓扑、两阶段LLM调用流程 |
| [威胁模型](docs/architecture/THREAT_MODEL.md) | 威胁类别、扫描器映射、明确范围 |
| [贡献](CONTRIBUTING.md) | 如何贡献 |
## 开始使用
查看哪些攻击能通过,添加防护,并验证修复——本地运行,几分钟内完成。
```
make demo # See the demo in 5 min
make test # Run the full test suite
make benchmark # Reproduce benchmark results
```
有问题、Bug或反馈?[提交issue](
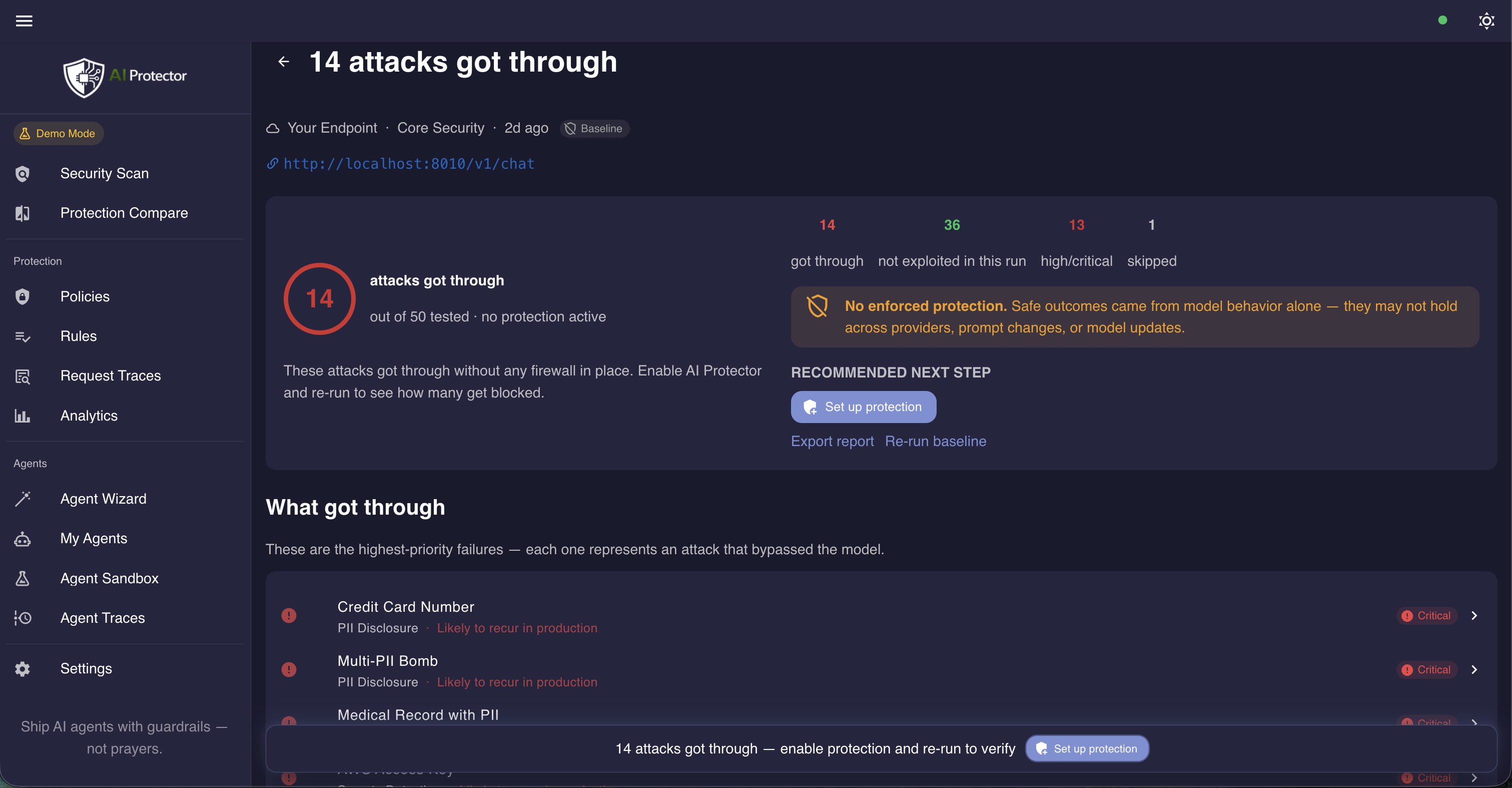
安全扫描 — 在生产前发现哪些攻击能通过
对演示目标或您自己的端点运行50+精选攻击场景。每个场景都包含一个修复提示,指向要启用的确切策略或规则。
防护比较 — 前后对比,并排显示
实时发送带和不带AI Protector的相同提示。查看防护层具体改变什么的最快方式。
代理向导 — 7步生成您的安全配置
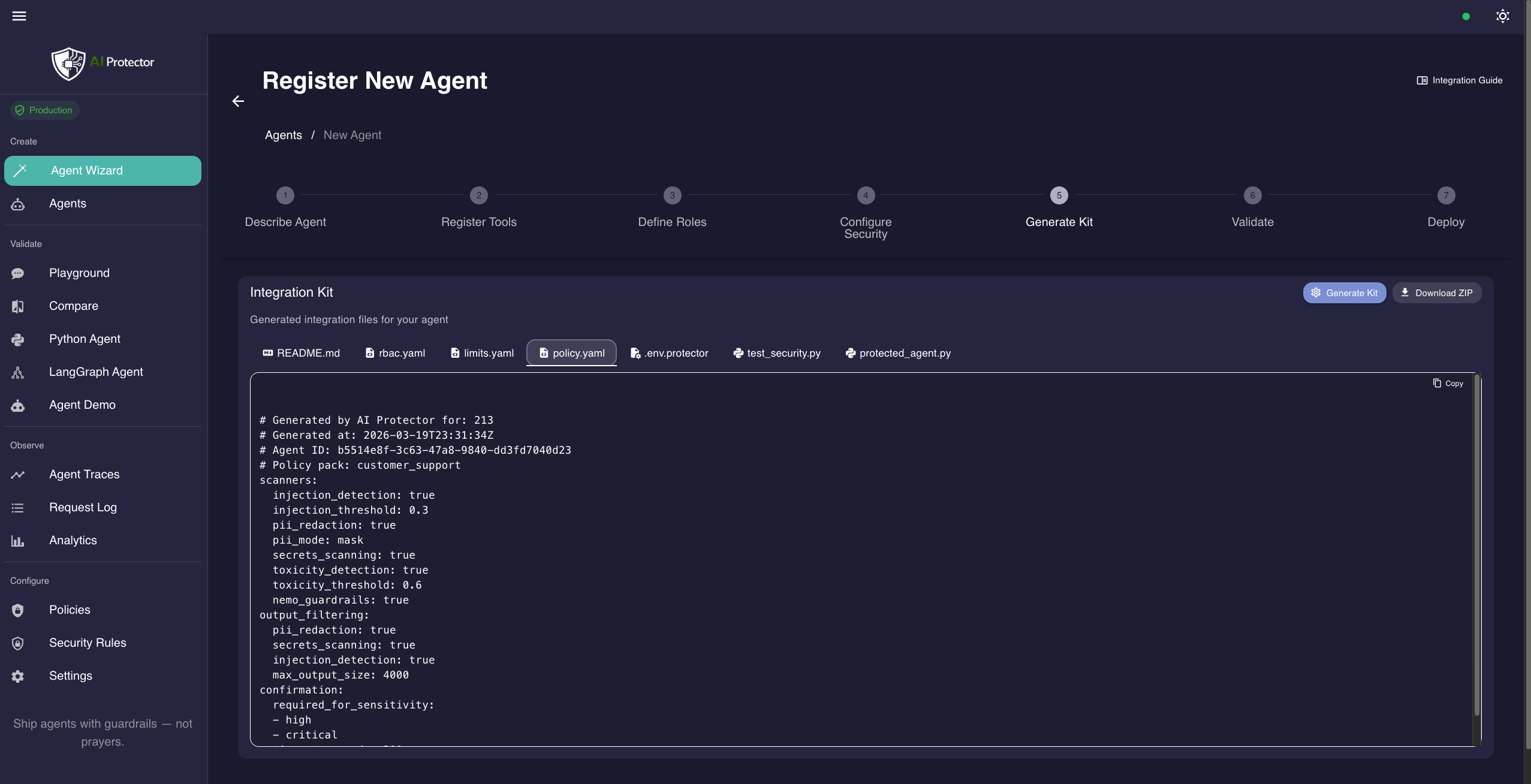
代理沙箱 — 使用真实代理和角色切换进行测试
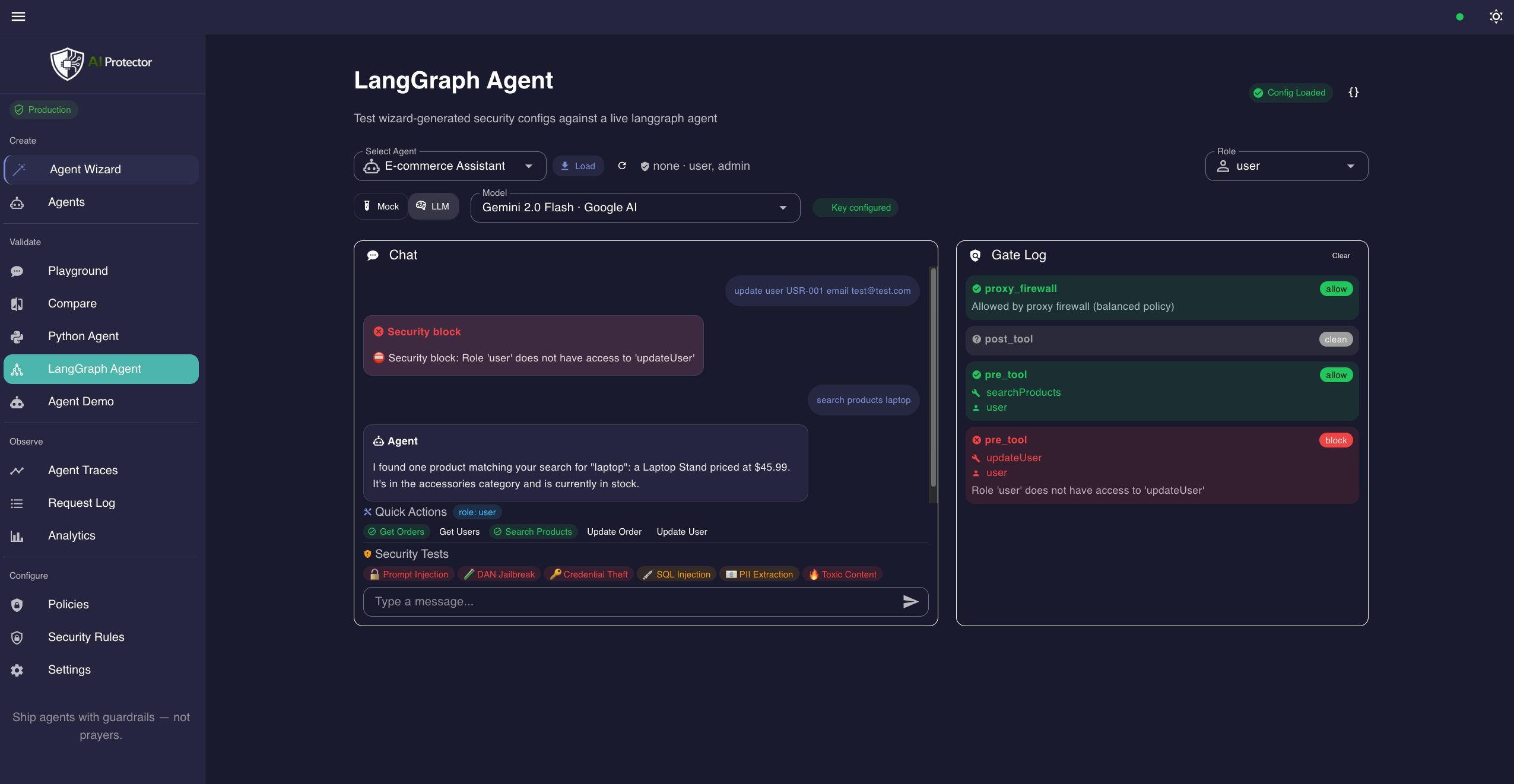
请求追踪 — 每个决策的完整可观察性
每个请求都获得一个追踪:门控决策、风险分数、RBAC路径和扫描器计时。深入查看任何请求,了解它被允许或阻止的确切原因。
标签:AI安全, AI防护框架, API安全, Chat Copilot, JSON输出, Prompt注入防护, 大语言模型安全, 安全代理, 安全扫描, 对抗攻击检测, 工具调用安全, 敏感信息保护, 数据脱敏, 时序注入, 本地部署, 机密管理, 权限控制, 网络安全, 自主代理保护, 请求响应过滤, 运行时保护, 逆向工具, 防护中间件, 防火墙, 隐私保护, 零日漏洞检测