megha1002240/aws-automated-incident-response
GitHub: megha1002240/aws-automated-incident-response
基于CloudWatch和Lambda实现的AWS EC2自动化故障自愈系统,通过监控CPU阈值自动触发实例重启实现无人值守的事件响应
Stars: 0 | Forks: 0
# AWS 自动化事件响应
# 项目概述
本项目在 AWS 中实现了一套自动化事件响应系统,具备以下功能:
监控 EC2 CPU 利用率
检测阈值违规
自动触发补救措施
在 CloudWatch 中记录操作日志
当 CPU 利用率超过定义的阈值时,系统通过自动重启 EC2 实例来防止停机。
# 使用的架构组件
* Amazon EC2
* Amazon CloudWatch
* AWS Lambda
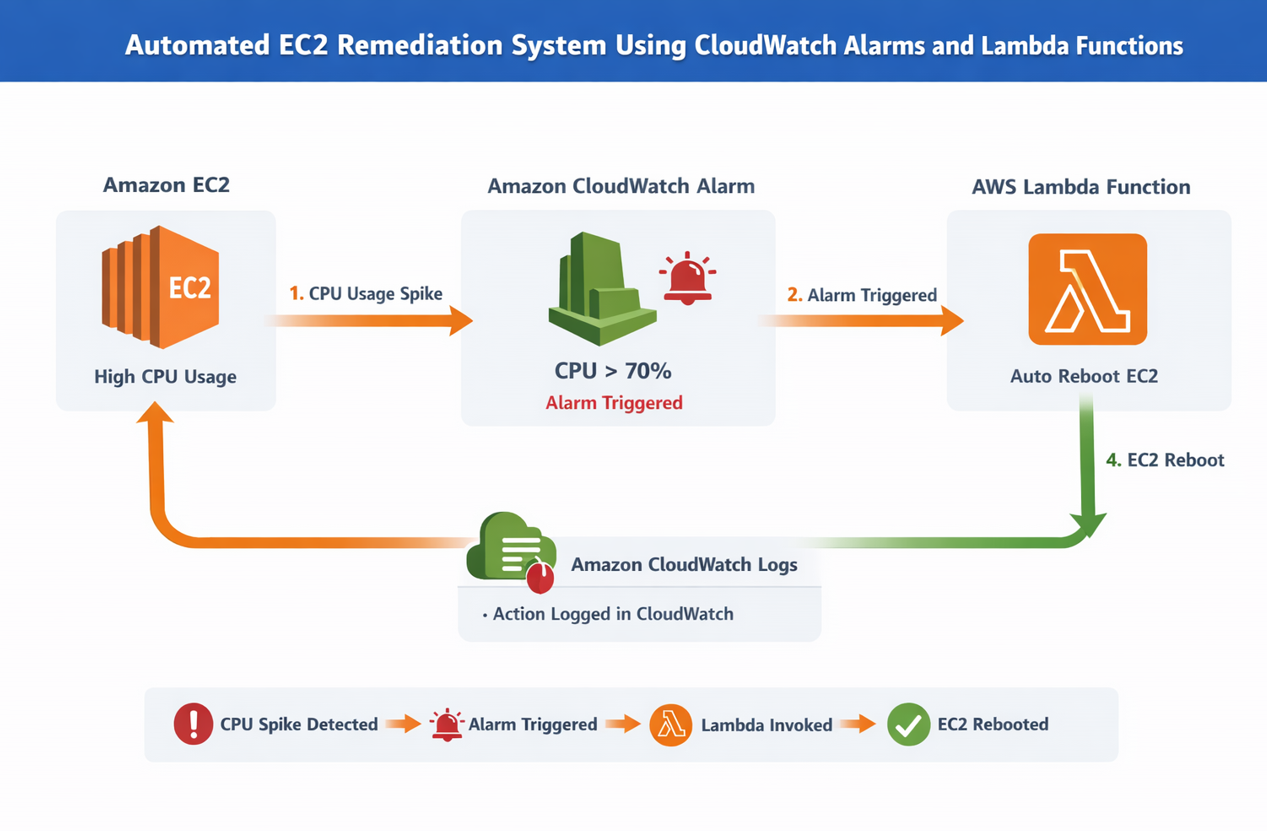 # 事件流程
EC2 CPU 使用率上升
CloudWatch Alarm 检测到阈值违规
Alarm 触发 Lambda
Lambda 重启 EC2 实例
操作被记录在 CloudWatch Logs 中
# 实施步骤
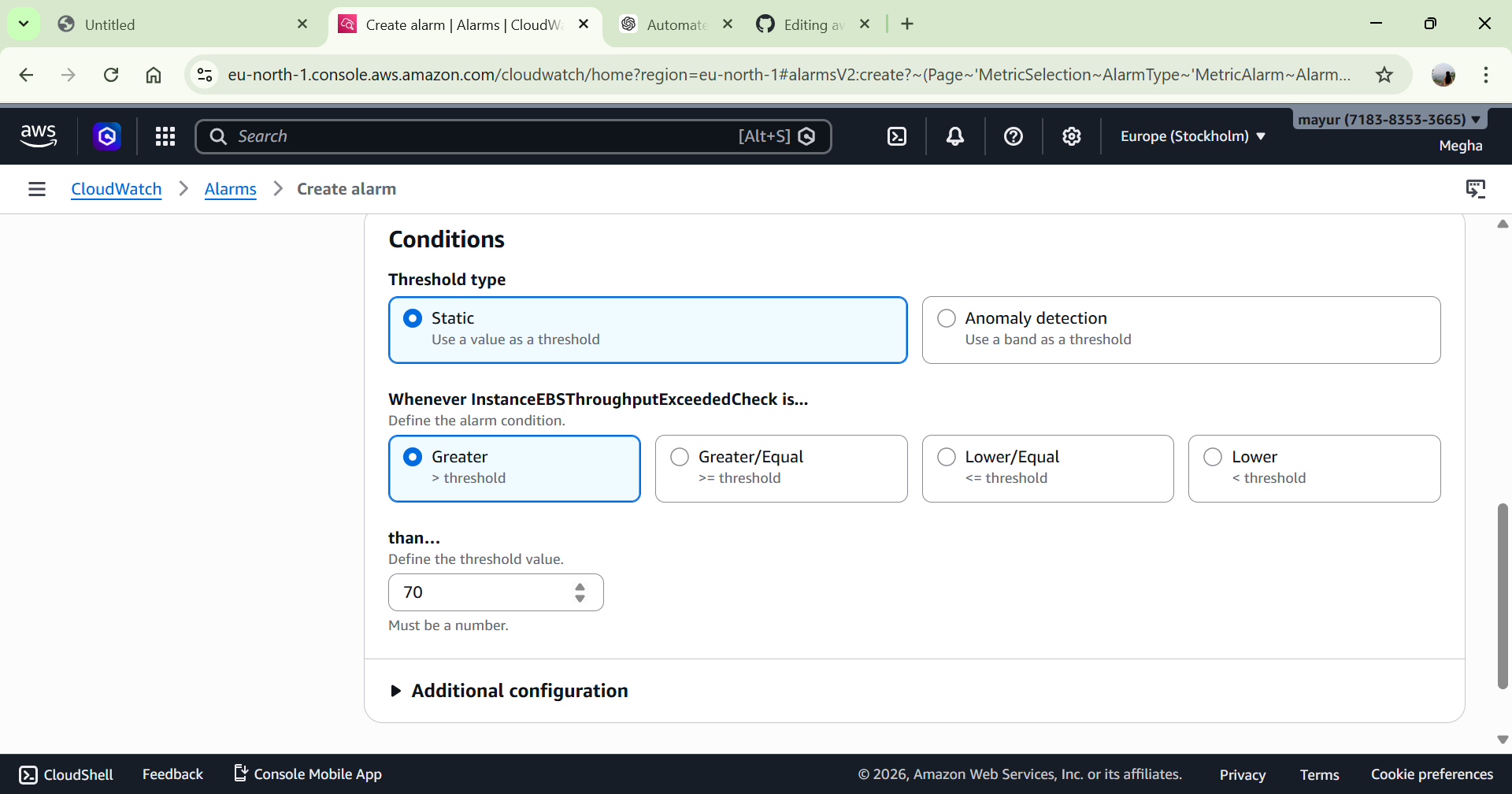
1️⃣ 监控设置 – CloudWatch Alarm
配置:
Metric: CPUUtilization
Threshold: 大于 70%
Period: 1 分钟
Evaluation Period: 1
# 事件流程
EC2 CPU 使用率上升
CloudWatch Alarm 检测到阈值违规
Alarm 触发 Lambda
Lambda 重启 EC2 实例
操作被记录在 CloudWatch Logs 中
# 实施步骤
1️⃣ 监控设置 – CloudWatch Alarm
配置:
Metric: CPUUtilization
Threshold: 大于 70%
Period: 1 分钟
Evaluation Period: 1
 # Lambda 操作
# Lambda 操作
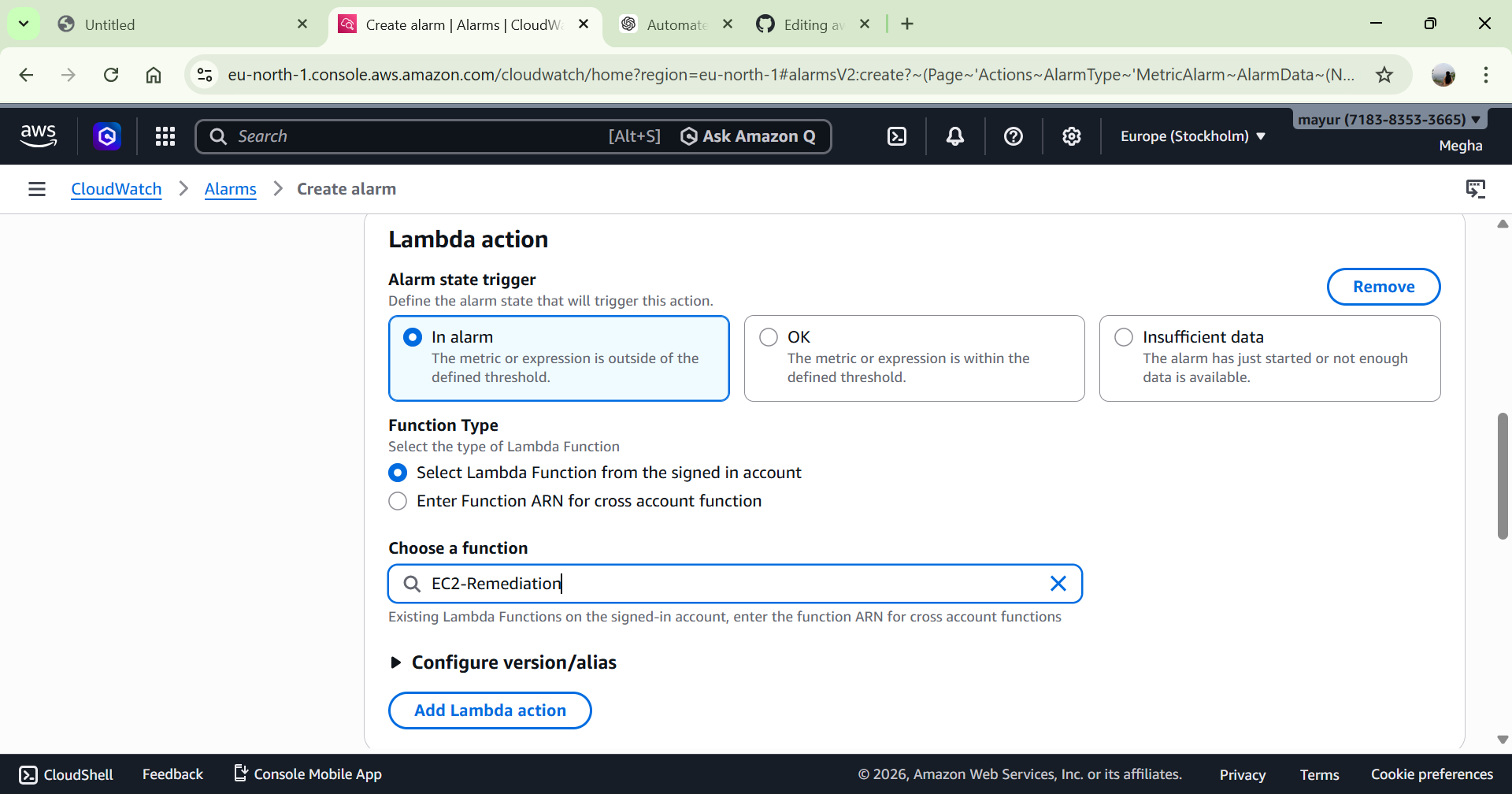
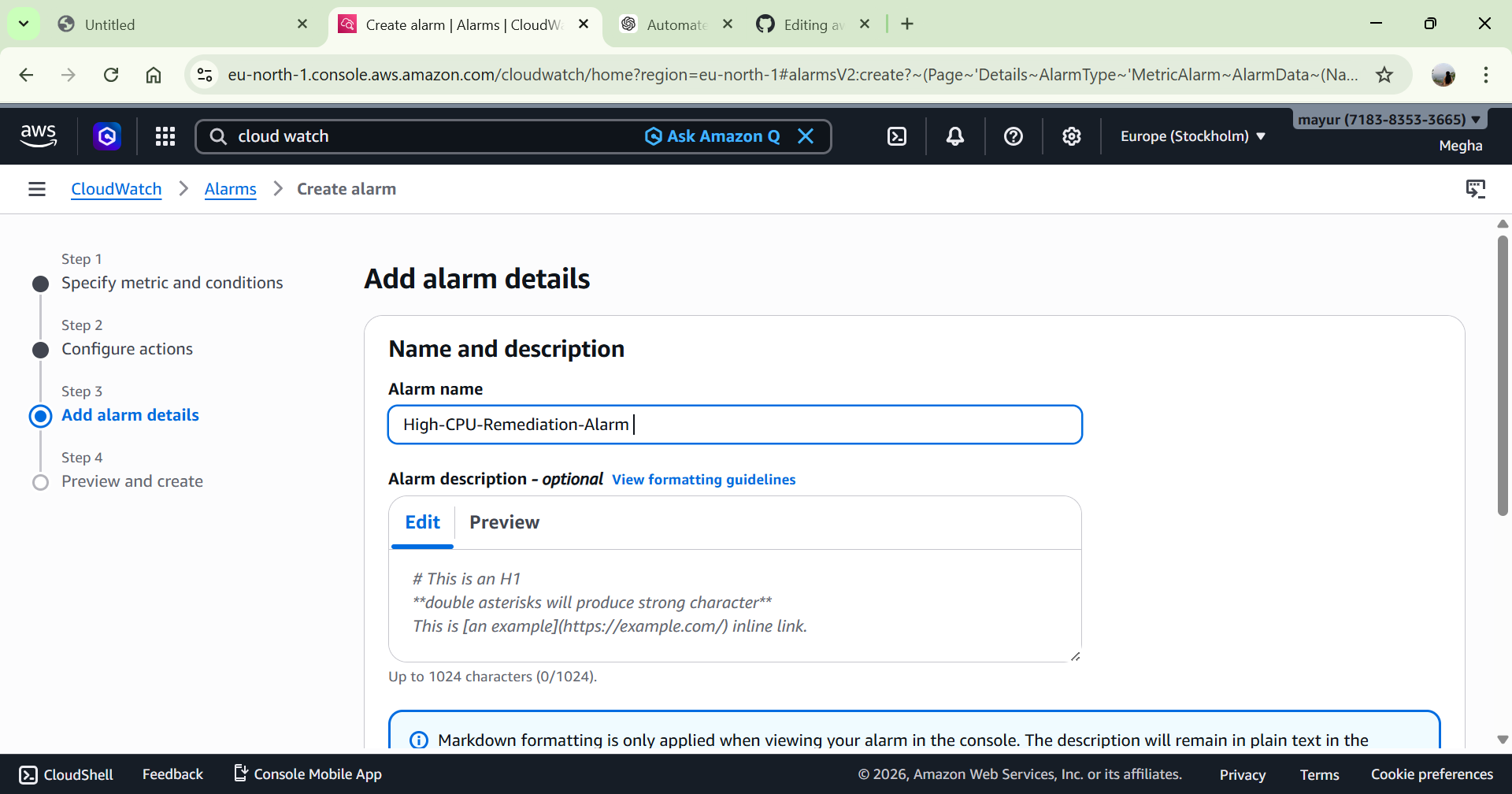 # 2️⃣ Lambda 补救函数
创建 Lambda 函数以自动重启 EC2 实例。
# 2️⃣ Lambda 补救函数
创建 Lambda 函数以自动重启 EC2 实例。
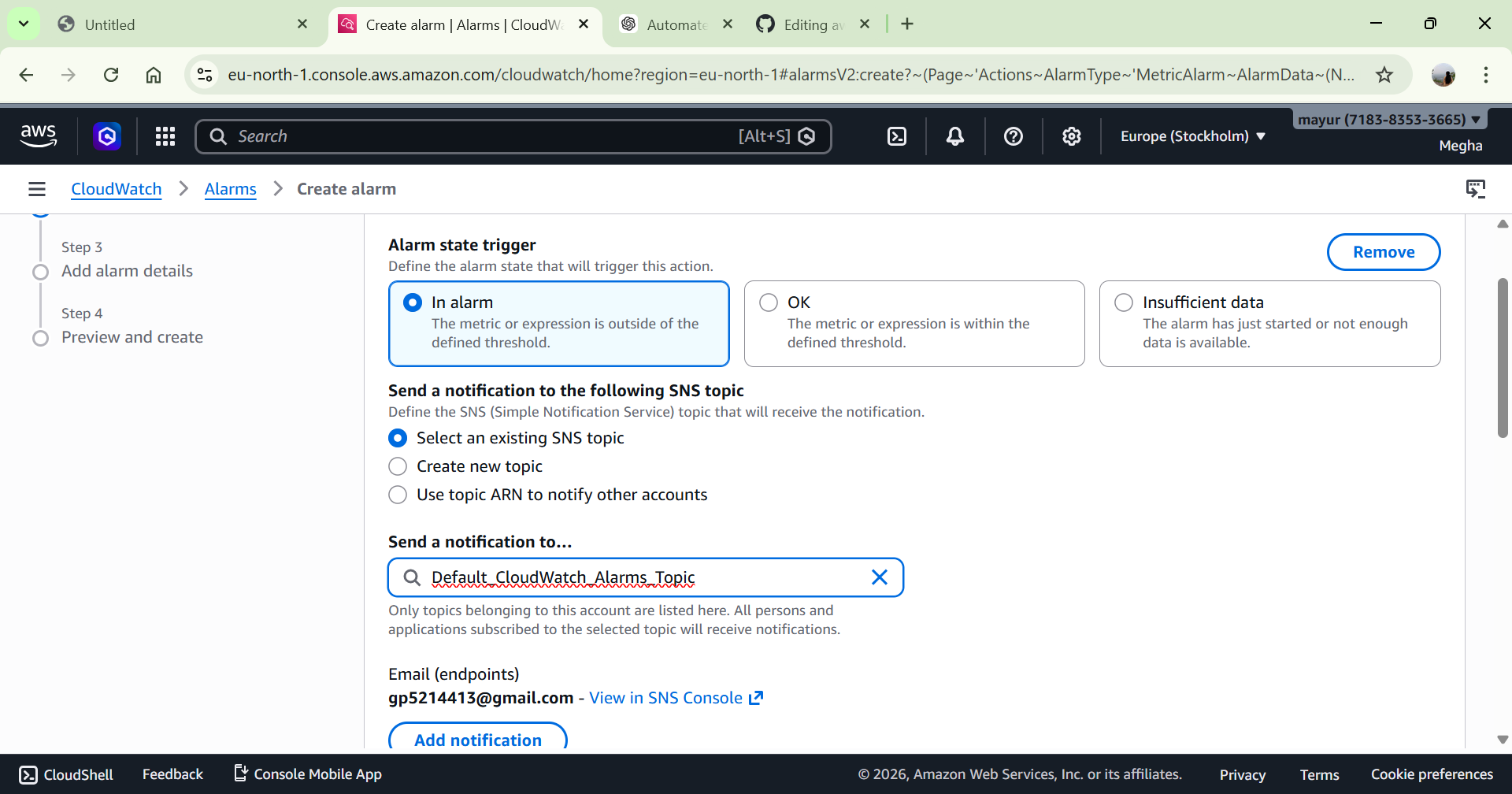
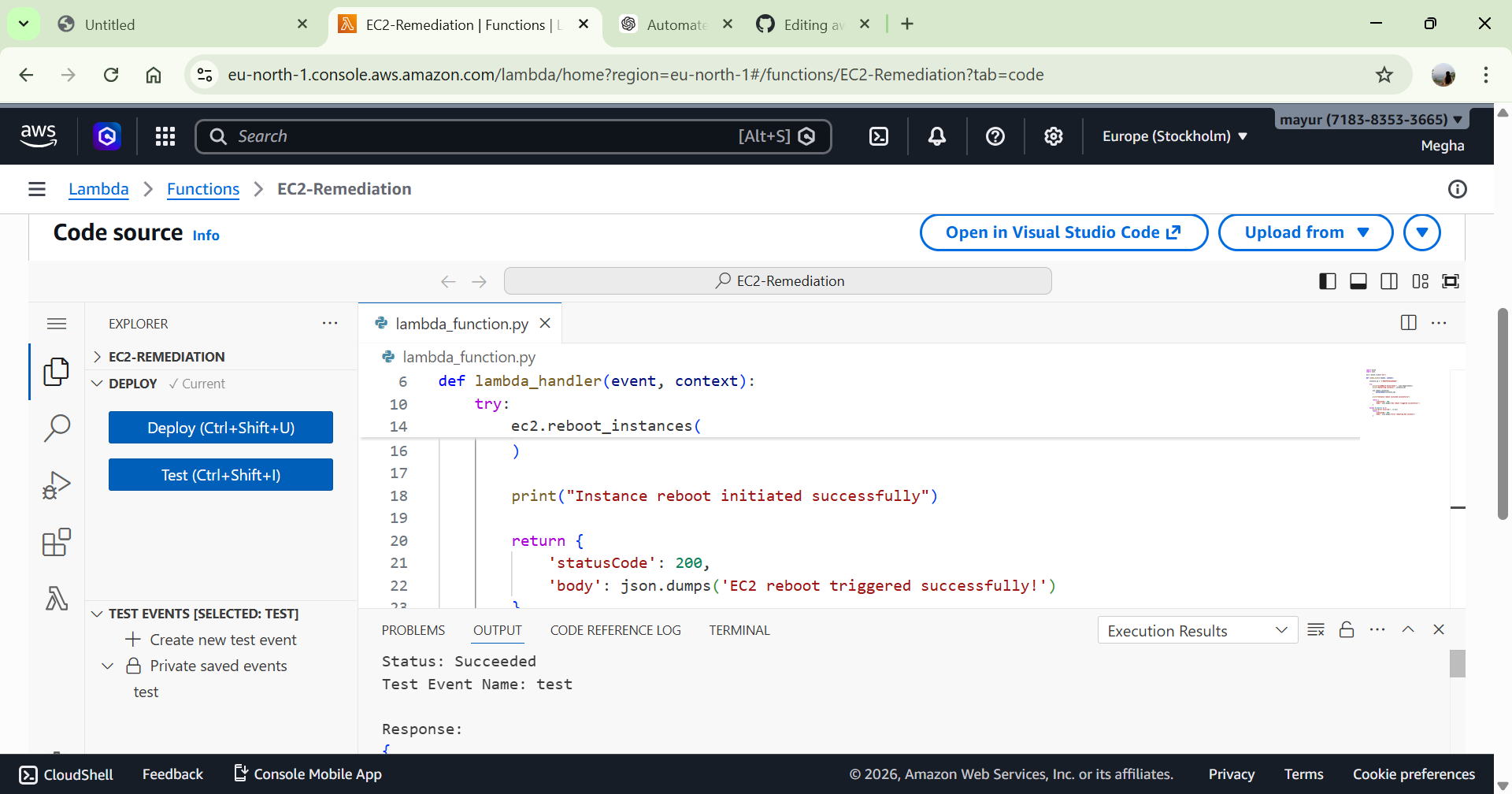 # 3️⃣ Alarm → Lambda 触发配置
CloudWatch Alarm 配置为:
State: In Alarm
Action: 调用 Lambda Function
# 3️⃣ Alarm → Lambda 触发配置
CloudWatch Alarm 配置为:
State: In Alarm
Action: 调用 Lambda Function
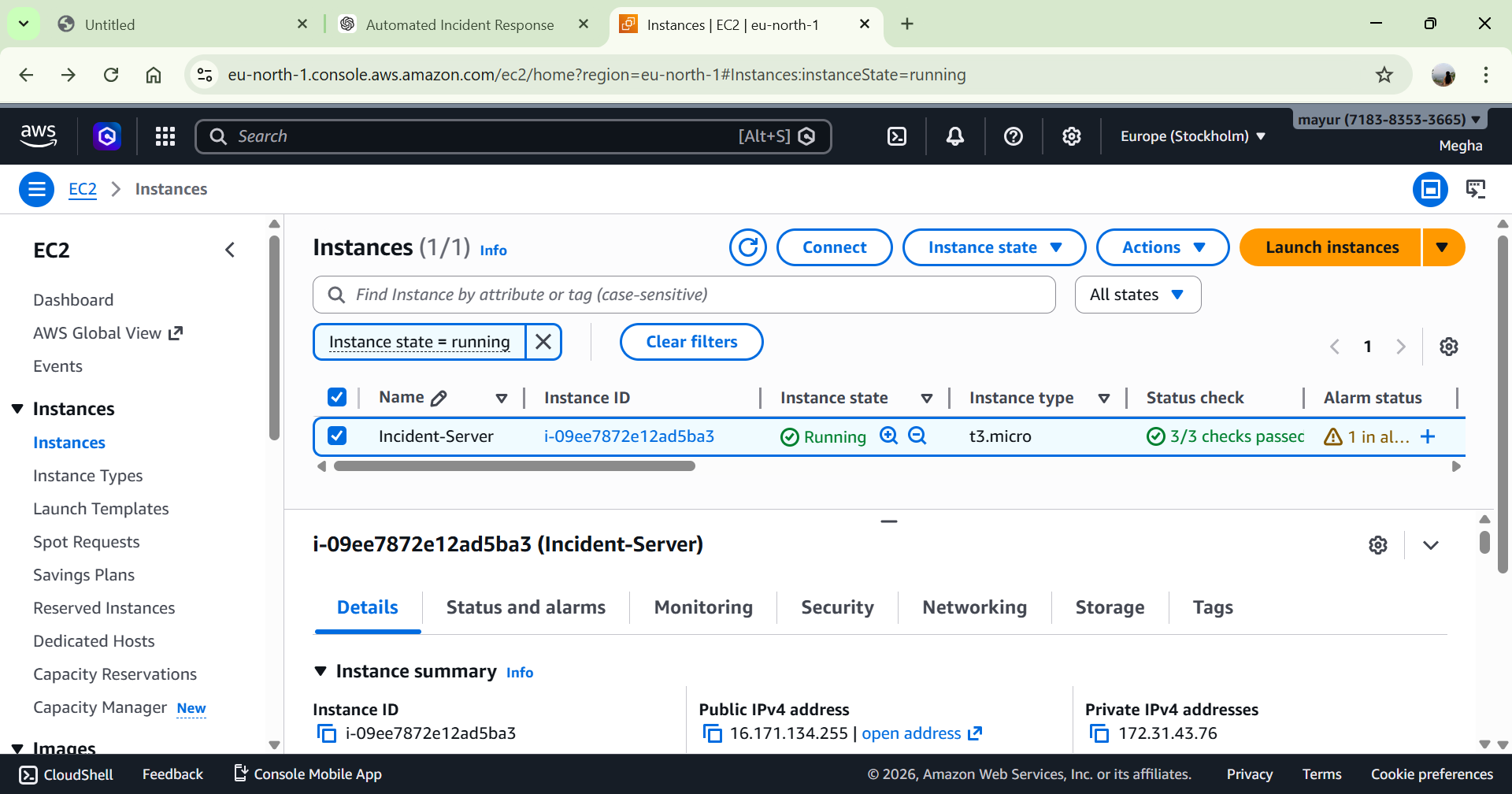
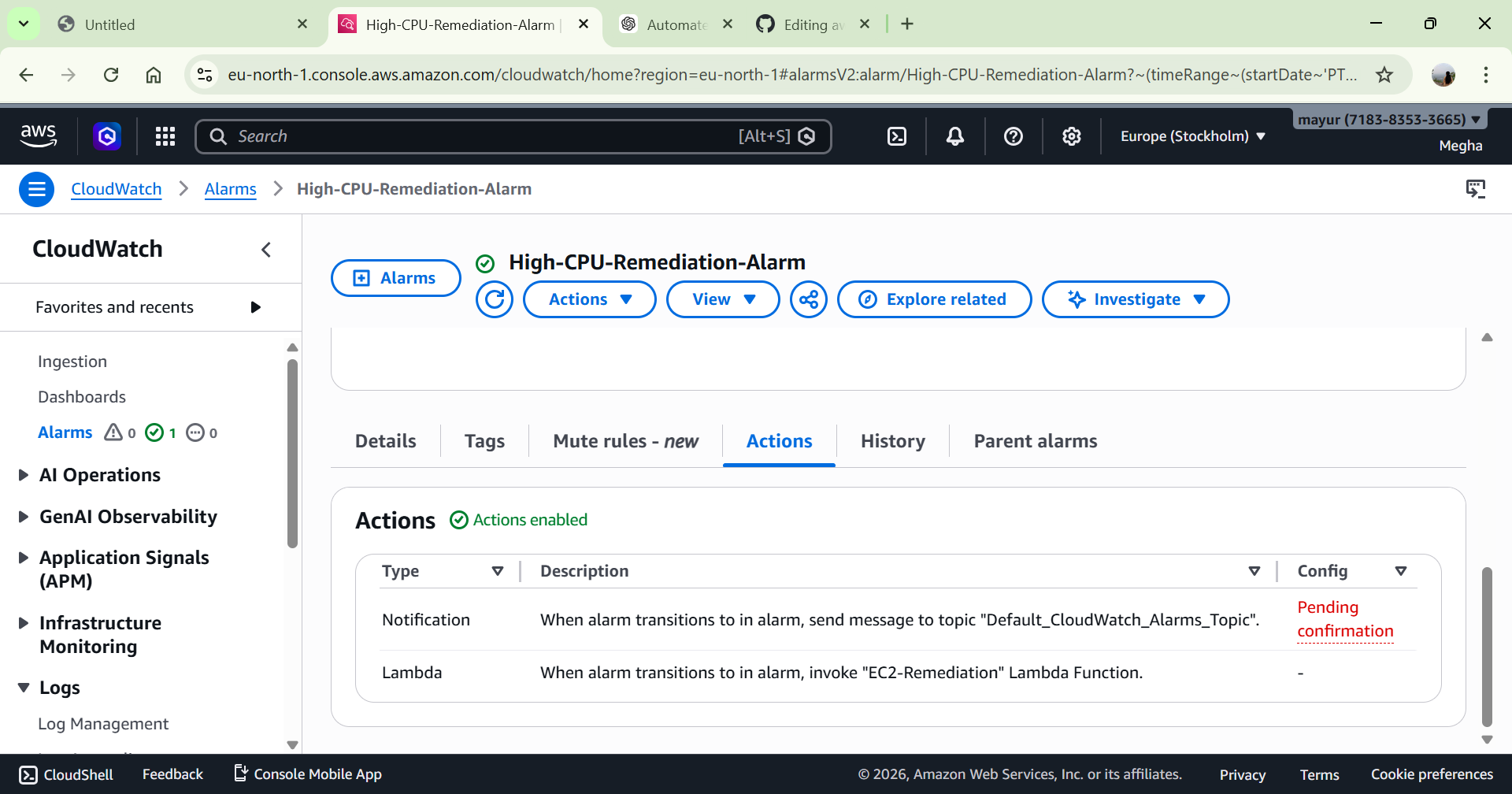 # 4️⃣ 测试过程
模拟高 CPU 使用率:
在 EC2 上安装 stress 工具
生成人工负载
CPU 超过 70%
# 4️⃣ 测试过程
模拟高 CPU 使用率:
在 EC2 上安装 stress 工具
生成人工负载
CPU 超过 70%
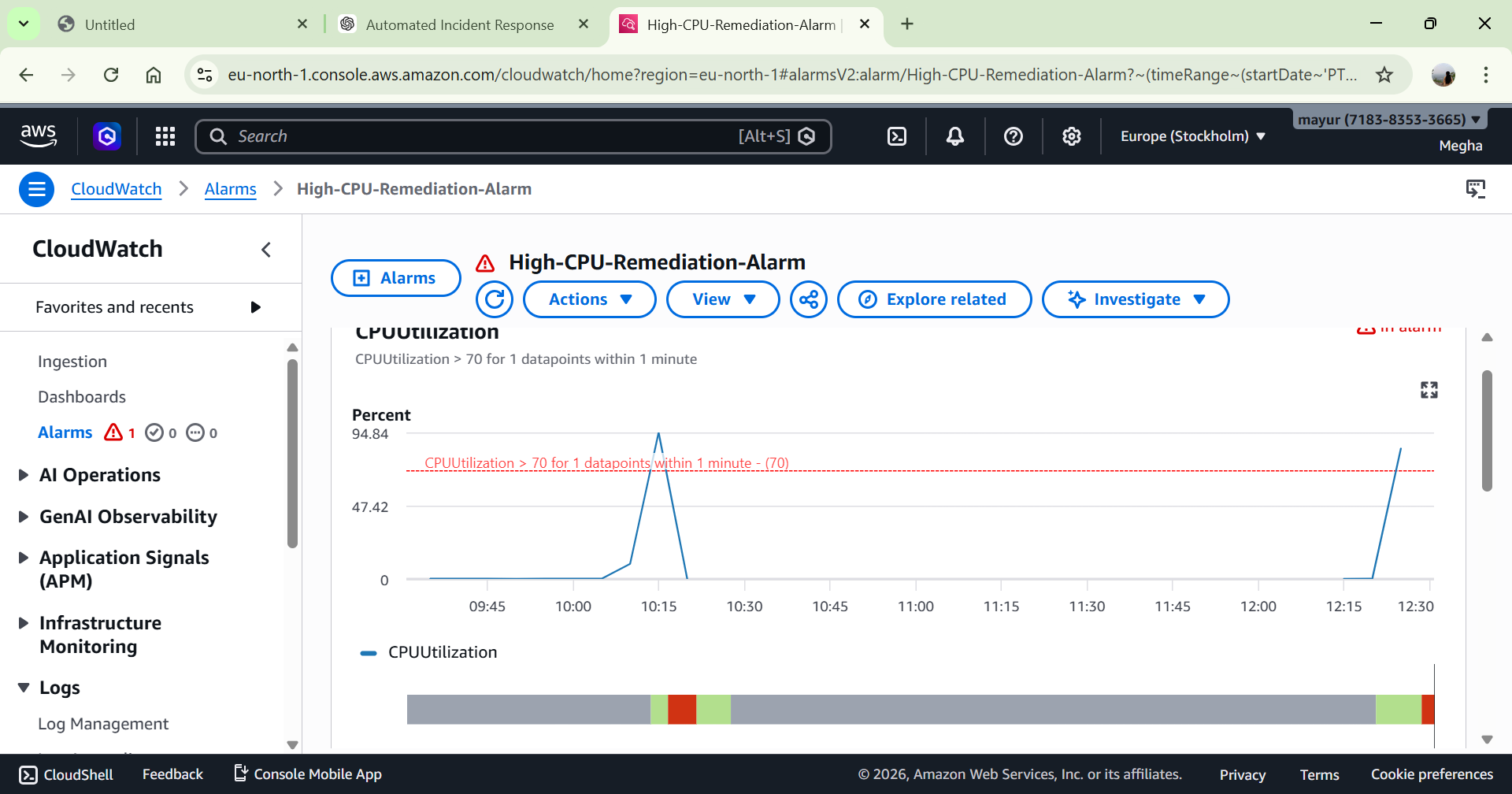
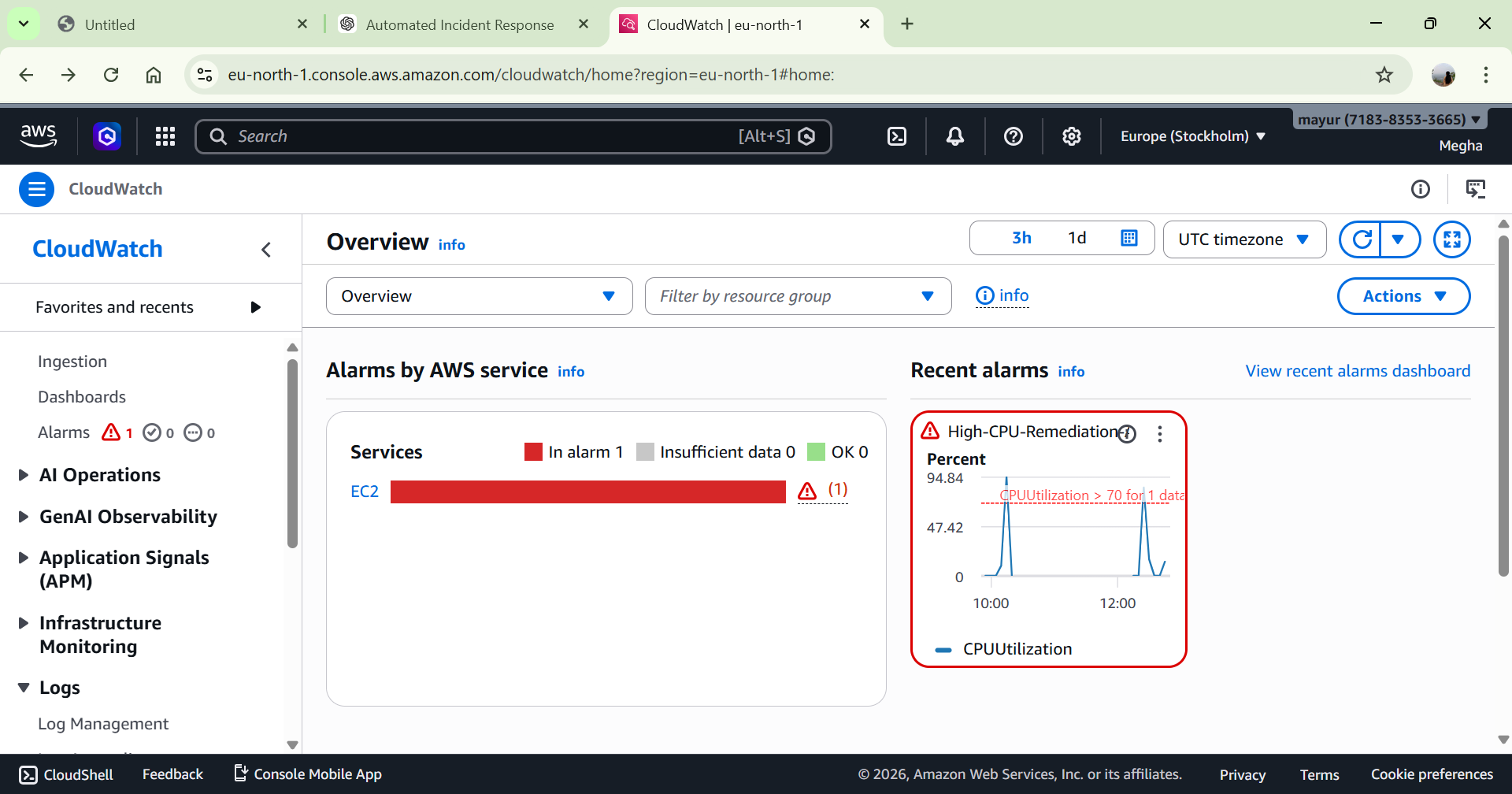
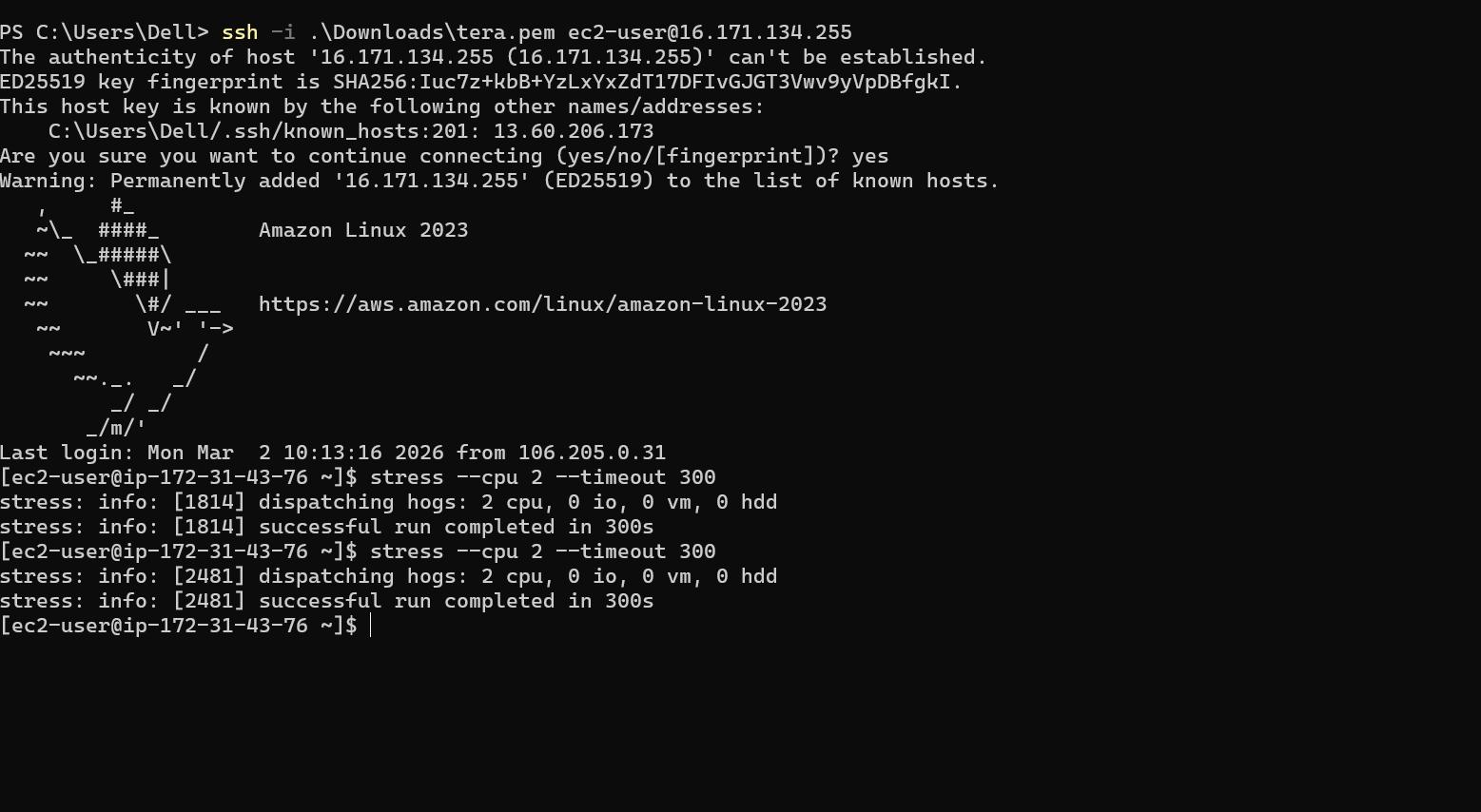 # Alarm 状态变为:
🔴 In Alarm
# Alarm 状态变为:
🔴 In Alarm
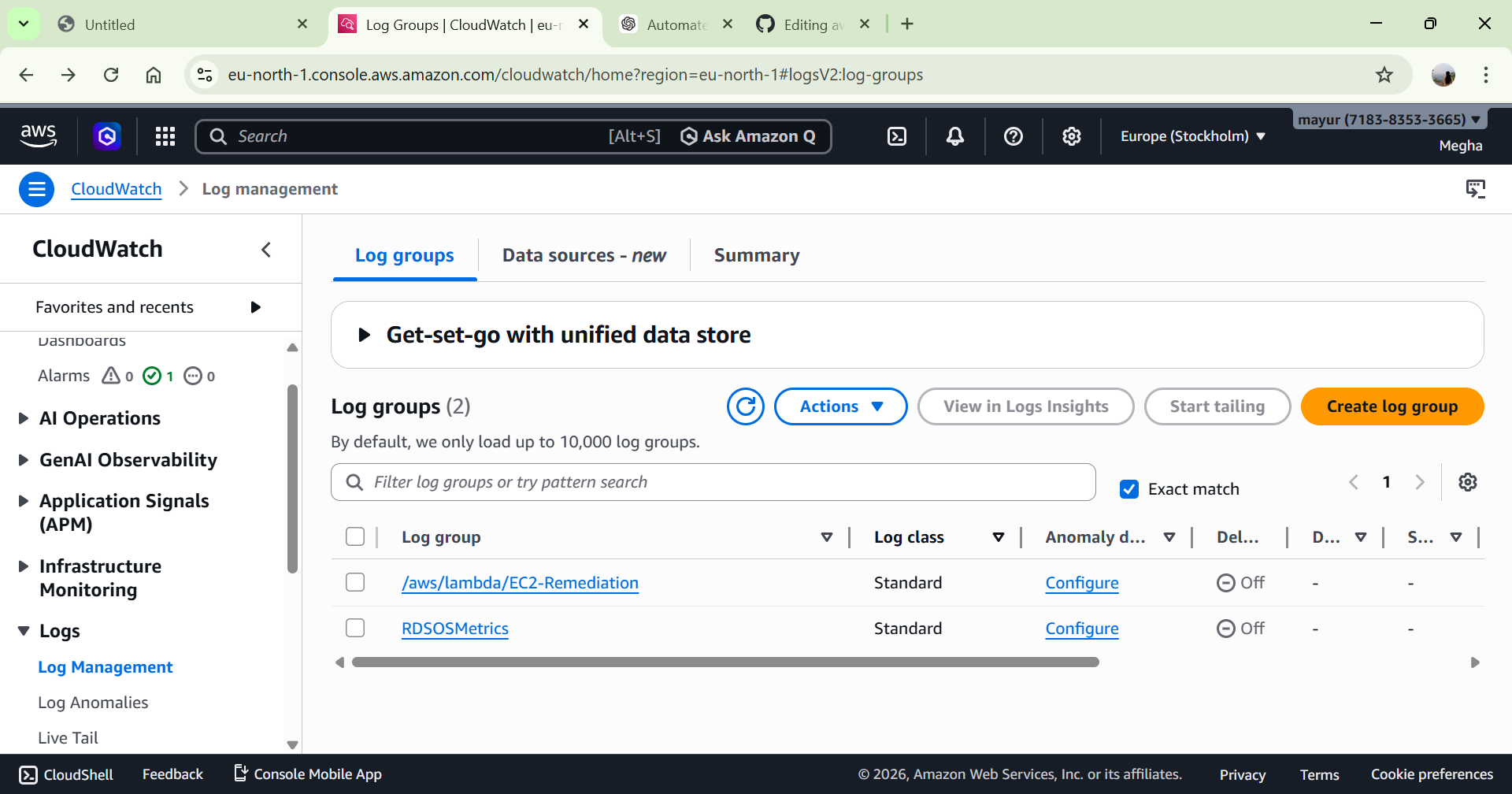
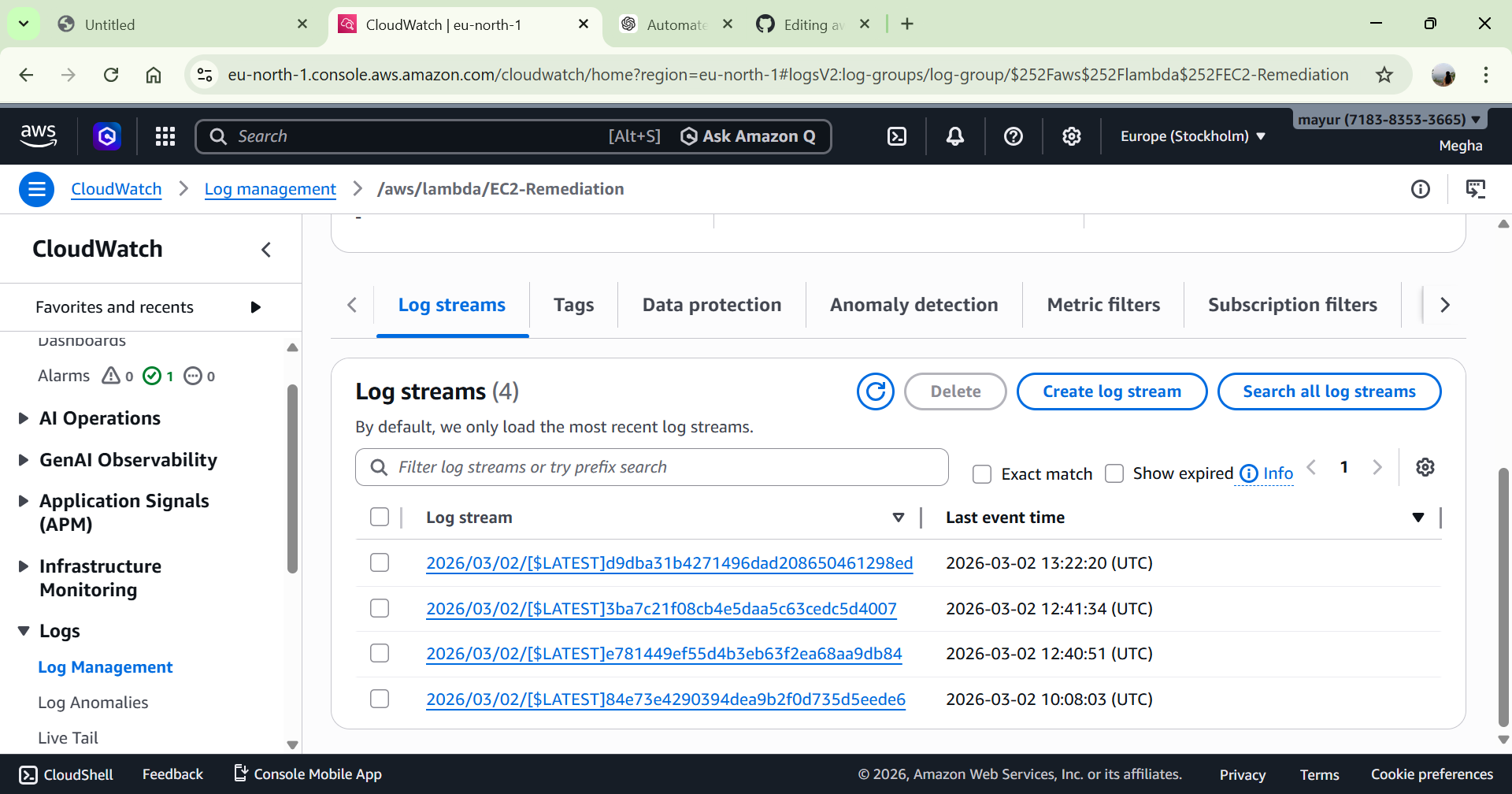
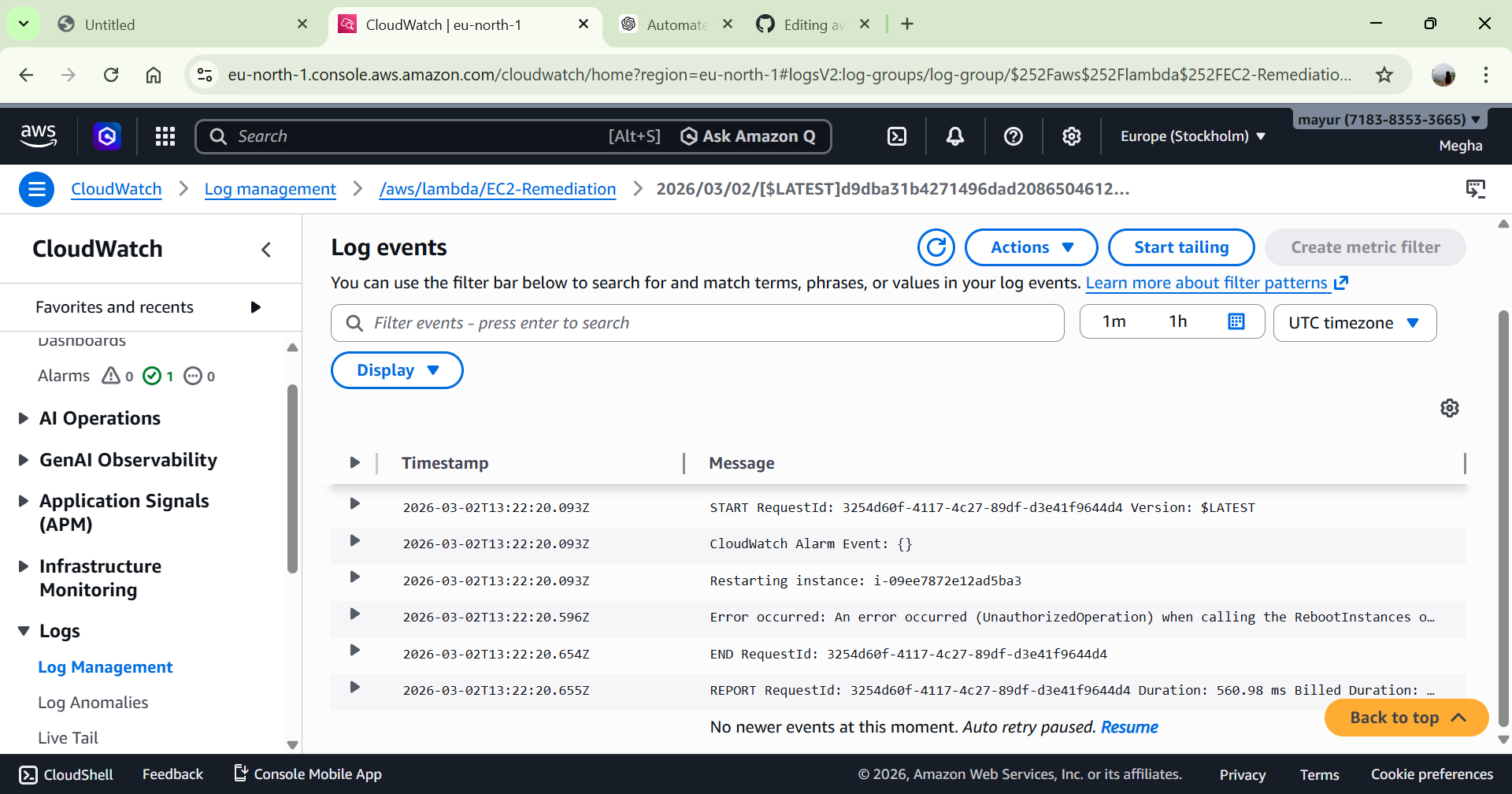
 # 5️⃣ 日志记录与验证
Lambda 执行日志存储于:
CloudWatch → Log Groups → /aws/lambda/FunctionName
日志显示:
START
Instance reboot initiated successfully
END
REPORT
# 5️⃣ 日志记录与验证
Lambda 执行日志存储于:
CloudWatch → Log Groups → /aws/lambda/FunctionName
日志显示:
START
Instance reboot initiated successfully
END
REPORT
 # 结果
✔ 检测到 CPU 阈值违规
✔ Lambda 自动触发
✔ EC2 重启已启动
✔ 日志成功捕获
✔ 无需人工干预
# 核心优势
零人工监控
更快的事件解决速度
减少停机时间
自动化补救
生产级监控设置
# 结论
本项目成功演示了使用 AWS 服务的自动化事件响应系统。
该系统通过在高 CPU 使用率事件期间自动采取纠正措施,确保了基础设施的可靠性。
# 结果
✔ 检测到 CPU 阈值违规
✔ Lambda 自动触发
✔ EC2 重启已启动
✔ 日志成功捕获
✔ 无需人工干预
# 核心优势
零人工监控
更快的事件解决速度
减少停机时间
自动化补救
生产级监控设置
# 结论
本项目成功演示了使用 AWS 服务的自动化事件响应系统。
该系统通过在高 CPU 使用率事件期间自动采取纠正措施,确保了基础设施的可靠性。
# 事件流程
EC2 CPU 使用率上升
CloudWatch Alarm 检测到阈值违规
Alarm 触发 Lambda
Lambda 重启 EC2 实例
操作被记录在 CloudWatch Logs 中
# 实施步骤
1️⃣ 监控设置 – CloudWatch Alarm
配置:
Metric: CPUUtilization
Threshold: 大于 70%
Period: 1 分钟
Evaluation Period: 1
# Lambda 操作
# 2️⃣ Lambda 补救函数
创建 Lambda 函数以自动重启 EC2 实例。
# 3️⃣ Alarm → Lambda 触发配置
CloudWatch Alarm 配置为:
State: In Alarm
Action: 调用 Lambda Function
# 4️⃣ 测试过程
模拟高 CPU 使用率:
在 EC2 上安装 stress 工具
生成人工负载
CPU 超过 70%
# Alarm 状态变为:
🔴 In Alarm
# 5️⃣ 日志记录与验证
Lambda 执行日志存储于:
CloudWatch → Log Groups → /aws/lambda/FunctionName
日志显示:
START
Instance reboot initiated successfully
END
REPORT
# 结果
✔ 检测到 CPU 阈值违规
✔ Lambda 自动触发
✔ EC2 重启已启动
✔ 日志成功捕获
✔ 无需人工干预
# 核心优势
零人工监控
更快的事件解决速度
减少停机时间
自动化补救
生产级监控设置
# 结论
本项目成功演示了使用 AWS 服务的自动化事件响应系统。
该系统通过在高 CPU 使用率事件期间自动采取纠正措施,确保了基础设施的可靠性。标签:Alarm, AWS, CloudWatch, CPU 阈值, DPI, EC2, ETW劫持, IaC, Incident Response, Lambda, PB级数据处理, Python, 云端监控, 安全运维, 性能监控, 故障自愈, 无后门, 无服务器, 日志记录, 系统恢复, 自动化事件响应, 运维自动化, 高可用性