Gesicht436/CareerPulse
GitHub: Gesicht436/CareerPulse
CareerPulse 是一个隐私优先的AI驱动平台,专注于语义职位匹配和招聘安全,解决传统ATS系统中的数据泄露和匹配不精准问题。
Stars: 0 | Forks: 0
# CareerPulse:AI驱动的职业优化与语义职位匹配
**CareerPulse** 是一个“隐私优先设计”的职业智能平台,它利用本地大型语言模型和向量数据库为求职者提供深度、可操作的职业对齐洞察。与依赖严格关键词匹配的传统ATS系统不同,CareerPulse理解您经历的**语义上下文**,识别隐藏的技能差距并生成个性化学习路线图,同时确保您的数据始终保留在本地机器上。
## 核心价值主张
在数据隐私问题和自动化招聘偏见日益突出的时代,CareerPulse 提供三大基础支柱:
1. **100% 数据主权**:所有AI推理——从向量嵌入到LLM推理——均在本地使用**量化Transformer模型**(Qwen 2.5)完成。您的简历永远不会被上传到OpenAI或Anthropic等外部云服务商。
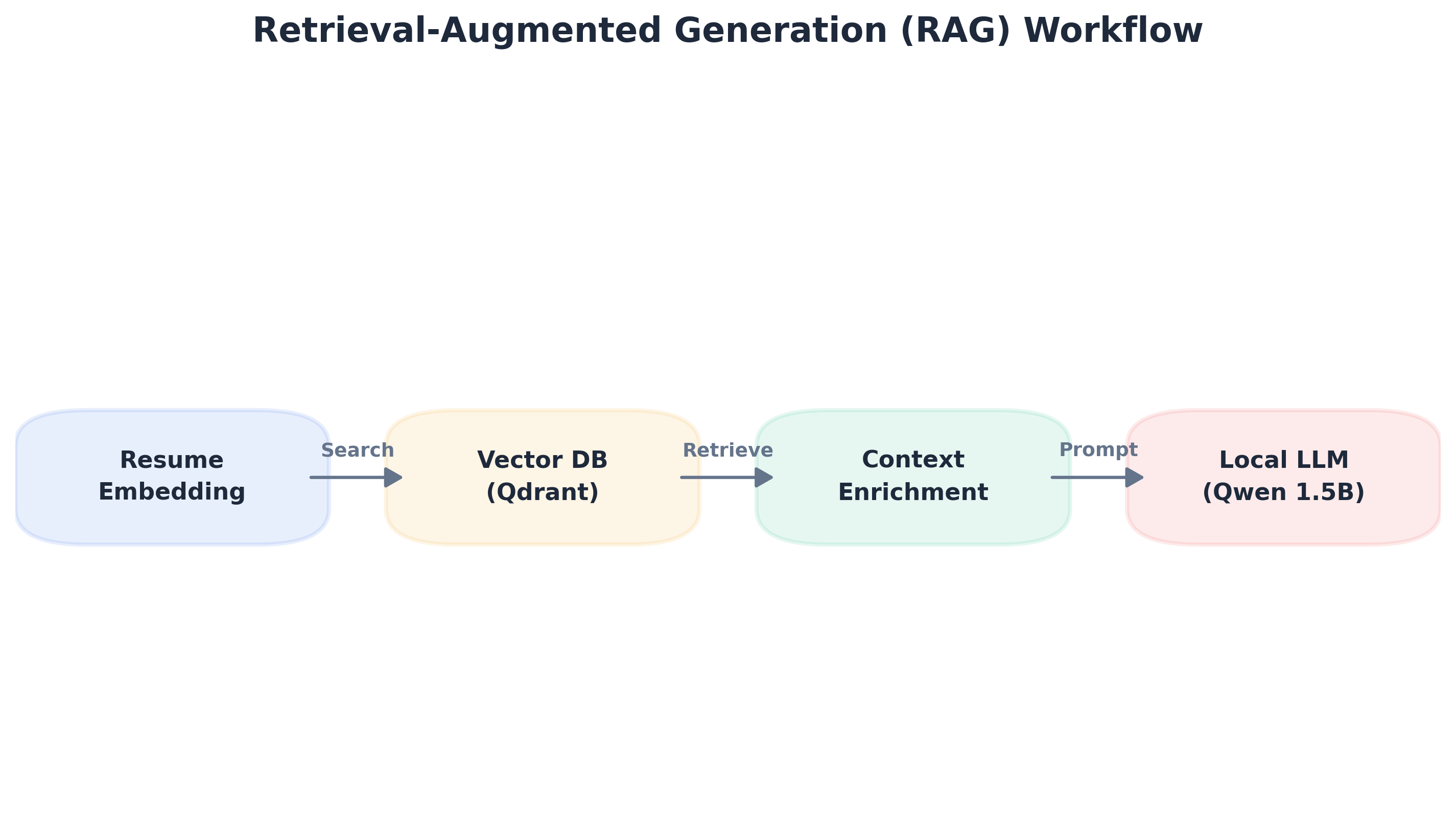
2. **语义优先对齐**:通过使用**SBERT(Sentence-BERT)**,引擎能够识别专业等效性(例如,理解“云编排”在概念上与“Kubernetes管理”相似)。
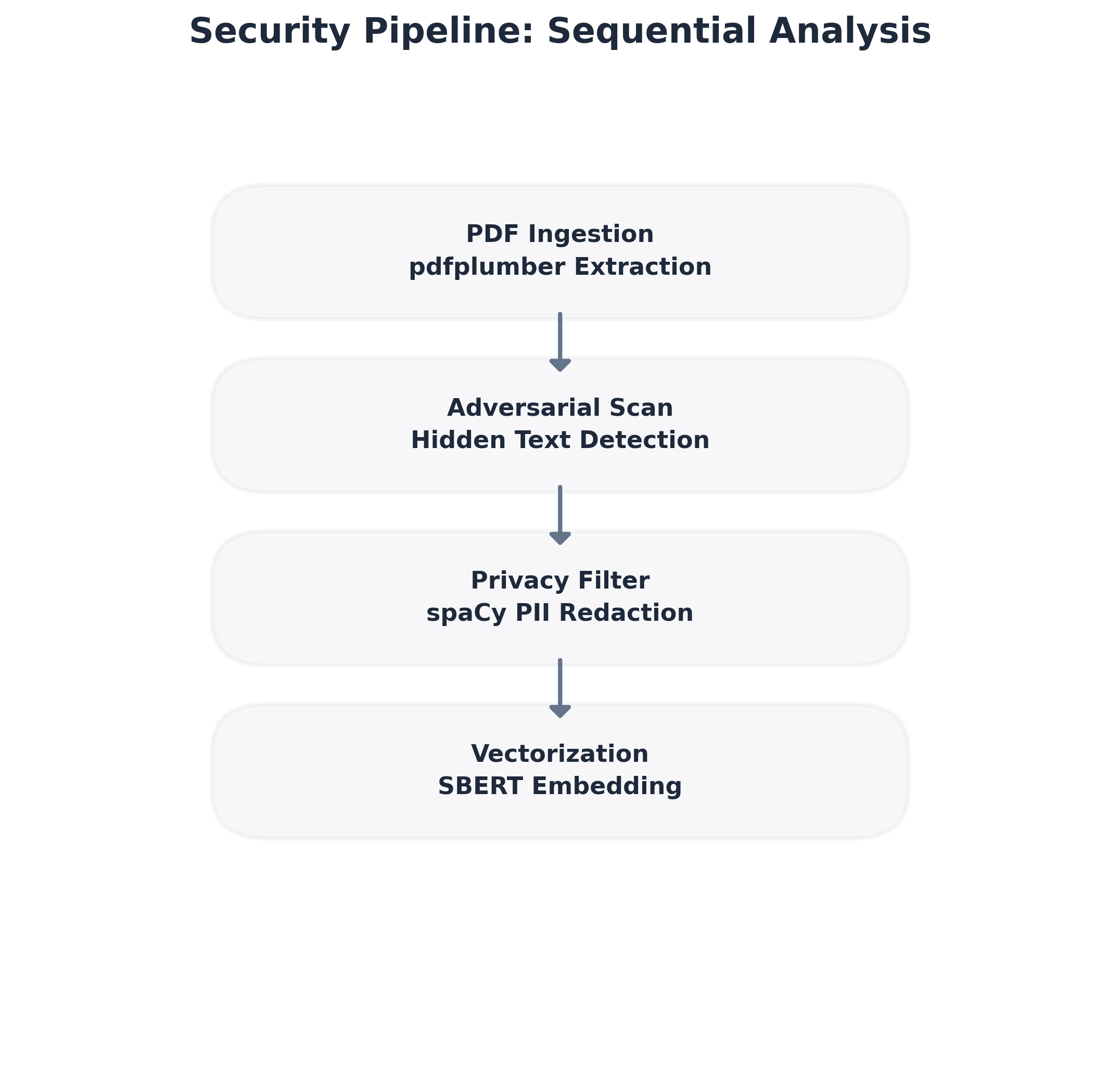
3. **防御性智能**:专门的安全层会对每份简历进行对抗性“提示注入”和隐藏“ATS Hack”的审计,确保匹配过程干净且诚实。
 ## 统一技术栈
## 统一技术栈
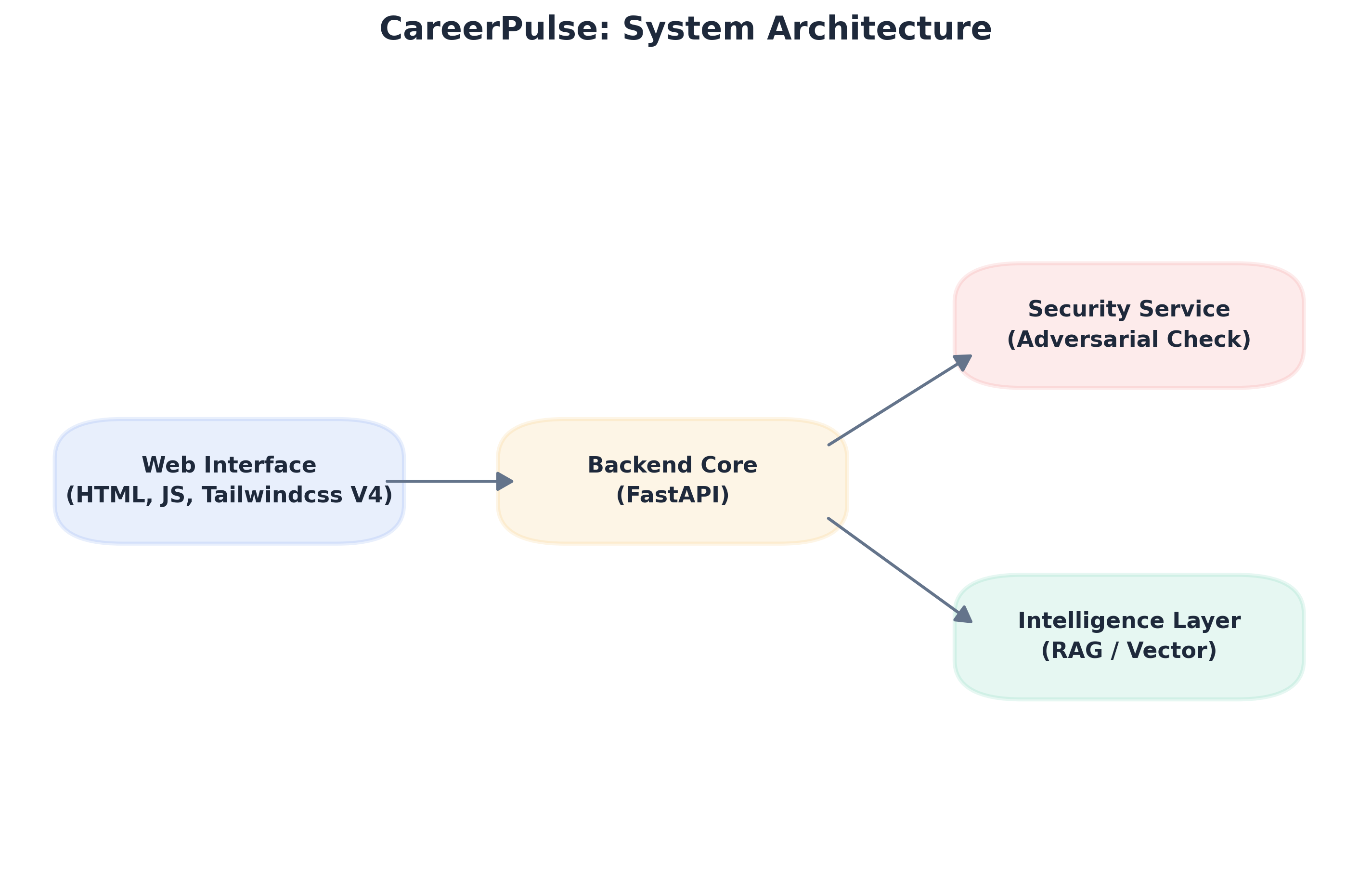 该项目被构建为一个高性能的**模块化单体应用**,分为专门的AI后端和现代、实用优先的前端。
该项目被构建为一个高性能的**模块化单体应用**,分为专门的AI后端和现代、实用优先的前端。
 ### **后端(核心引擎)**
- **API框架**:FastAPI(异步Python 3.12)
- **向量智能**:Qdrant(高性能HNSW索引)
- **嵌入模型**:`all-MiniLM-L6-v2`(384维语义向量)
- **本地LLM**:Qwen 2.5 1.5B/7B(通过`bitsandbytes`进行NF4量化)
- **提取与安全**:`pdfplumber`、`Tesseract-OCR`、`spaCy`(命名实体识别)、`OpenCV`
### **前端(Web界面)**
- **样式**:Tailwind CSS v4(实用优先,优化构建流程)
- **逻辑**:原生ES6+ JavaScript(零依赖,高速执行)
- **架构**:静态站点生成,配合动态API编排。
### **自动化与运维**
- **依赖管理**:`uv`(最快的Python包管理器)
- **可视化**:`matplotlib`、`numpy`(程序化生成技术图表)
- **文档**:`pandoc`(跨格式转换)
## 当前项目状态
| 里程碑 | 功能 | 状态 |
| :--- | :--- | :--- |
| **安全** | 布局感知的PDF提取与PII脱敏 | [x] 已完成 |
| **安全** | 扫描文档的OCR回退方案 | [x] 已完成 |
| **数据层** | Qdrant向量数据库集成与职位数据导入 | [x] 已完成 |
| **匹配** | 通过SBERT进行语义评分(余弦相似度) | [x] 已完成 |
| **智能** | 集成本地LLM(Qwen 2.5)并采用4位量化 | [x] 已完成 |
| **Web UI** | 响应式仪表盘、上传中心和搜索界面 | [x] 已完成 |
| **编排** | 统一的端到端分析流程(`/analyze`) | [x] 已完成 |
| **扩展格式** | 原生支持`.docx`和`.txt`文件导入 | [ ] 待处理 |
| **持久化** | 多用户认证与历史分析追踪 | [ ] 待处理 |
| **分析** | 使用实时职位数据进行市场趋势可视化 | [ ] 待处理 |
## 项目结构
```
CareerPulse/
├── core_engine/ # The Backend Central Nervous System
│ ├── data_layer/ # Qdrant persistence & Pydantic schemas
│ ├── resume_security/ # PDF extraction, Redaction, & Audit
│ ├── smart_match/ # SBERT Scoring & LLM Reasoning
│ ├── embedding_service.py # Shared SBERT singleton
│ ├── llm_service.py # Local Qwen 2.5 inference layer
│ └── main.py # FastAPI Gateway
├── web_interface/ # Modern Professional Frontend
│ ├── public/ # HTML templates & static assets
│ │ ├── css/ # Tailwind v4 source & output
│ │ └── js/ # Vanilla JS logic (api.js, analyzer.js)
│ └── package.json # Node.js build scripts
├── scripts/ # Automation & Data Pipelines
│ ├── ingest_qdrant.py # Vector ETL pipeline
│ ├── setup_data.py # Automated Kaggle data retrieval
│ └── generate_visuals.py # Technical diagram generator
├── project_assets/ # Generated visuals & Mid-Sem reports
├── ARCHITECTURE.md # Master system blueprint
└── README.md # You are here
```
### **后端(核心引擎)**
- **API框架**:FastAPI(异步Python 3.12)
- **向量智能**:Qdrant(高性能HNSW索引)
- **嵌入模型**:`all-MiniLM-L6-v2`(384维语义向量)
- **本地LLM**:Qwen 2.5 1.5B/7B(通过`bitsandbytes`进行NF4量化)
- **提取与安全**:`pdfplumber`、`Tesseract-OCR`、`spaCy`(命名实体识别)、`OpenCV`
### **前端(Web界面)**
- **样式**:Tailwind CSS v4(实用优先,优化构建流程)
- **逻辑**:原生ES6+ JavaScript(零依赖,高速执行)
- **架构**:静态站点生成,配合动态API编排。
### **自动化与运维**
- **依赖管理**:`uv`(最快的Python包管理器)
- **可视化**:`matplotlib`、`numpy`(程序化生成技术图表)
- **文档**:`pandoc`(跨格式转换)
## 当前项目状态
| 里程碑 | 功能 | 状态 |
| :--- | :--- | :--- |
| **安全** | 布局感知的PDF提取与PII脱敏 | [x] 已完成 |
| **安全** | 扫描文档的OCR回退方案 | [x] 已完成 |
| **数据层** | Qdrant向量数据库集成与职位数据导入 | [x] 已完成 |
| **匹配** | 通过SBERT进行语义评分(余弦相似度) | [x] 已完成 |
| **智能** | 集成本地LLM(Qwen 2.5)并采用4位量化 | [x] 已完成 |
| **Web UI** | 响应式仪表盘、上传中心和搜索界面 | [x] 已完成 |
| **编排** | 统一的端到端分析流程(`/analyze`) | [x] 已完成 |
| **扩展格式** | 原生支持`.docx`和`.txt`文件导入 | [ ] 待处理 |
| **持久化** | 多用户认证与历史分析追踪 | [ ] 待处理 |
| **分析** | 使用实时职位数据进行市场趋势可视化 | [ ] 待处理 |
## 项目结构
```
CareerPulse/
├── core_engine/ # The Backend Central Nervous System
│ ├── data_layer/ # Qdrant persistence & Pydantic schemas
│ ├── resume_security/ # PDF extraction, Redaction, & Audit
│ ├── smart_match/ # SBERT Scoring & LLM Reasoning
│ ├── embedding_service.py # Shared SBERT singleton
│ ├── llm_service.py # Local Qwen 2.5 inference layer
│ └── main.py # FastAPI Gateway
├── web_interface/ # Modern Professional Frontend
│ ├── public/ # HTML templates & static assets
│ │ ├── css/ # Tailwind v4 source & output
│ │ └── js/ # Vanilla JS logic (api.js, analyzer.js)
│ └── package.json # Node.js build scripts
├── scripts/ # Automation & Data Pipelines
│ ├── ingest_qdrant.py # Vector ETL pipeline
│ ├── setup_data.py # Automated Kaggle data retrieval
│ └── generate_visuals.py # Technical diagram generator
├── project_assets/ # Generated visuals & Mid-Sem reports
├── ARCHITECTURE.md # Master system blueprint
└── README.md # You are here
```
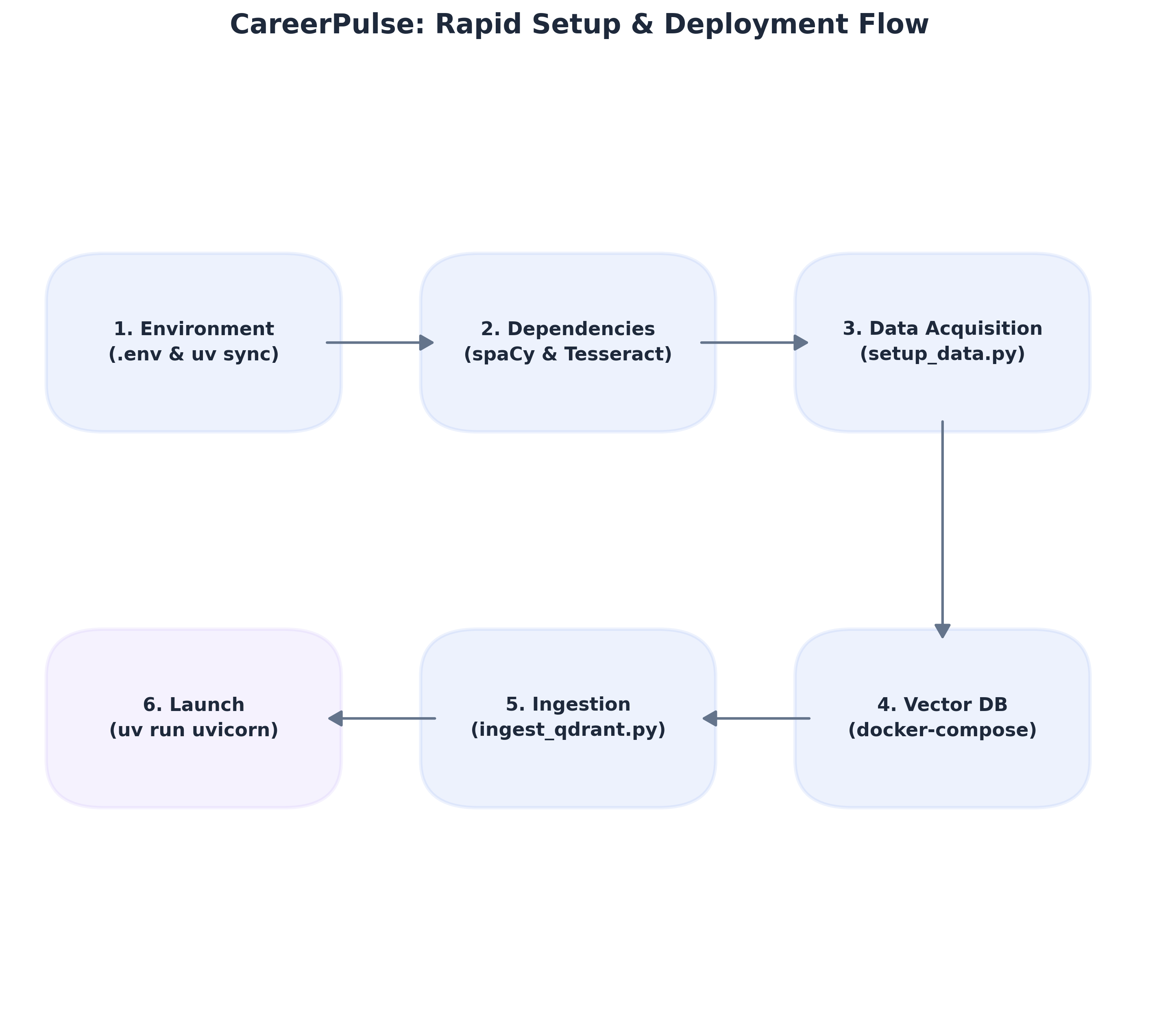 ## 快速开始
### 1. 系统前提条件
确保您已安装以下系统级依赖项:
- **Python 3.12+**(推荐使用`uv`包管理器)。
- **Node.js 20+**(用于前端样式)。
- **Tesseract-OCR**:处理扫描版PDF所必需。
- **Poppler**:PDF光栅化所必需。
- **Docker**:用于运行Qdrant向量数据库。
```
winget install --id Nvidia.CUDA --version 13.0
winget install Docker.DockerDesktop
uv install python 3.12
winget install CoreyButler.NVMforWindows
nvm install latest
```
### 2. 后端设置(核心引擎)
```
# 配置环境变量
# 将 .env.example 复制为 .env 并更新您的 Kaggle 凭据
cp .env.example .env
# 安装 Python 依赖项并同步环境
uv sync
# 下载 spaCy NLP 模型
uv run python -m spacy download en_core_web_sm
```
### 3. 数据获取与数据库初始化
```
# 从 Kaggle 下载 2025 年职位描述数据集
uv run python scripts/setup_data.py
# 构建并启动 Qdrant 向量数据库容器
docker-compose up --build -d
# 将职位数据嵌入并导入到正在运行的 Qdrant 实例中
uv run python scripts/ingest_qdrant.py
```
### 4. 前端设置(Web界面)
```
cd web_interface
npm install
# 启动开发服务器(CSS 监视 + Live Server)
npm run dev
# 如果遇到任何问题,请依次运行以下命令
Remove-Item -Recurse -Force node_modules
npm install
npm run dev
```
### 5. 启动引擎
在一个新的终端窗口中:
```
# 返回根目录
cd ..
# 启动 FastAPI 服务器
uv run uvicorn core_engine.main:app --reload
```
您的应用程序将在 `http://localhost:3000` 上运行,并与运行在 `http://localhost:8000` 的后端进行通信。
## 团队成员
- **Mayank Anand**:团队负责人,架构设计,LLM推理与用户体验优化。
- **Abhinav Anand (285)**:前端核心开发,API编排与仪表盘逻辑。
- **Harsh Anand**:UI/UX结构与Tailwind实现。
- **Abhinav Anand (08)**:安全审计与性能基准测试。
- **Ankit Anand**:数据工程与数据集策展。
## 快速开始
### 1. 系统前提条件
确保您已安装以下系统级依赖项:
- **Python 3.12+**(推荐使用`uv`包管理器)。
- **Node.js 20+**(用于前端样式)。
- **Tesseract-OCR**:处理扫描版PDF所必需。
- **Poppler**:PDF光栅化所必需。
- **Docker**:用于运行Qdrant向量数据库。
```
winget install --id Nvidia.CUDA --version 13.0
winget install Docker.DockerDesktop
uv install python 3.12
winget install CoreyButler.NVMforWindows
nvm install latest
```
### 2. 后端设置(核心引擎)
```
# 配置环境变量
# 将 .env.example 复制为 .env 并更新您的 Kaggle 凭据
cp .env.example .env
# 安装 Python 依赖项并同步环境
uv sync
# 下载 spaCy NLP 模型
uv run python -m spacy download en_core_web_sm
```
### 3. 数据获取与数据库初始化
```
# 从 Kaggle 下载 2025 年职位描述数据集
uv run python scripts/setup_data.py
# 构建并启动 Qdrant 向量数据库容器
docker-compose up --build -d
# 将职位数据嵌入并导入到正在运行的 Qdrant 实例中
uv run python scripts/ingest_qdrant.py
```
### 4. 前端设置(Web界面)
```
cd web_interface
npm install
# 启动开发服务器(CSS 监视 + Live Server)
npm run dev
# 如果遇到任何问题,请依次运行以下命令
Remove-Item -Recurse -Force node_modules
npm install
npm run dev
```
### 5. 启动引擎
在一个新的终端窗口中:
```
# 返回根目录
cd ..
# 启动 FastAPI 服务器
uv run uvicorn core_engine.main:app --reload
```
您的应用程序将在 `http://localhost:3000` 上运行,并与运行在 `http://localhost:8000` 的后端进行通信。
## 团队成员
- **Mayank Anand**:团队负责人,架构设计,LLM推理与用户体验优化。
- **Abhinav Anand (285)**:前端核心开发,API编排与仪表盘逻辑。
- **Harsh Anand**:UI/UX结构与Tailwind实现。
- **Abhinav Anand (08)**:安全审计与性能基准测试。
- **Ankit Anand**:数据工程与数据集策展。
## 统一技术栈
该项目被构建为一个高性能的**模块化单体应用**,分为专门的AI后端和现代、实用优先的前端。
### **后端(核心引擎)**
- **API框架**:FastAPI(异步Python 3.12)
- **向量智能**:Qdrant(高性能HNSW索引)
- **嵌入模型**:`all-MiniLM-L6-v2`(384维语义向量)
- **本地LLM**:Qwen 2.5 1.5B/7B(通过`bitsandbytes`进行NF4量化)
- **提取与安全**:`pdfplumber`、`Tesseract-OCR`、`spaCy`(命名实体识别)、`OpenCV`
### **前端(Web界面)**
- **样式**:Tailwind CSS v4(实用优先,优化构建流程)
- **逻辑**:原生ES6+ JavaScript(零依赖,高速执行)
- **架构**:静态站点生成,配合动态API编排。
### **自动化与运维**
- **依赖管理**:`uv`(最快的Python包管理器)
- **可视化**:`matplotlib`、`numpy`(程序化生成技术图表)
- **文档**:`pandoc`(跨格式转换)
## 当前项目状态
| 里程碑 | 功能 | 状态 |
| :--- | :--- | :--- |
| **安全** | 布局感知的PDF提取与PII脱敏 | [x] 已完成 |
| **安全** | 扫描文档的OCR回退方案 | [x] 已完成 |
| **数据层** | Qdrant向量数据库集成与职位数据导入 | [x] 已完成 |
| **匹配** | 通过SBERT进行语义评分(余弦相似度) | [x] 已完成 |
| **智能** | 集成本地LLM(Qwen 2.5)并采用4位量化 | [x] 已完成 |
| **Web UI** | 响应式仪表盘、上传中心和搜索界面 | [x] 已完成 |
| **编排** | 统一的端到端分析流程(`/analyze`) | [x] 已完成 |
| **扩展格式** | 原生支持`.docx`和`.txt`文件导入 | [ ] 待处理 |
| **持久化** | 多用户认证与历史分析追踪 | [ ] 待处理 |
| **分析** | 使用实时职位数据进行市场趋势可视化 | [ ] 待处理 |
## 项目结构
```
CareerPulse/
├── core_engine/ # The Backend Central Nervous System
│ ├── data_layer/ # Qdrant persistence & Pydantic schemas
│ ├── resume_security/ # PDF extraction, Redaction, & Audit
│ ├── smart_match/ # SBERT Scoring & LLM Reasoning
│ ├── embedding_service.py # Shared SBERT singleton
│ ├── llm_service.py # Local Qwen 2.5 inference layer
│ └── main.py # FastAPI Gateway
├── web_interface/ # Modern Professional Frontend
│ ├── public/ # HTML templates & static assets
│ │ ├── css/ # Tailwind v4 source & output
│ │ └── js/ # Vanilla JS logic (api.js, analyzer.js)
│ └── package.json # Node.js build scripts
├── scripts/ # Automation & Data Pipelines
│ ├── ingest_qdrant.py # Vector ETL pipeline
│ ├── setup_data.py # Automated Kaggle data retrieval
│ └── generate_visuals.py # Technical diagram generator
├── project_assets/ # Generated visuals & Mid-Sem reports
├── ARCHITECTURE.md # Master system blueprint
└── README.md # You are here
```
## 快速开始
### 1. 系统前提条件
确保您已安装以下系统级依赖项:
- **Python 3.12+**(推荐使用`uv`包管理器)。
- **Node.js 20+**(用于前端样式)。
- **Tesseract-OCR**:处理扫描版PDF所必需。
- **Poppler**:PDF光栅化所必需。
- **Docker**:用于运行Qdrant向量数据库。
```
winget install --id Nvidia.CUDA --version 13.0
winget install Docker.DockerDesktop
uv install python 3.12
winget install CoreyButler.NVMforWindows
nvm install latest
```
### 2. 后端设置(核心引擎)
```
# 配置环境变量
# 将 .env.example 复制为 .env 并更新您的 Kaggle 凭据
cp .env.example .env
# 安装 Python 依赖项并同步环境
uv sync
# 下载 spaCy NLP 模型
uv run python -m spacy download en_core_web_sm
```
### 3. 数据获取与数据库初始化
```
# 从 Kaggle 下载 2025 年职位描述数据集
uv run python scripts/setup_data.py
# 构建并启动 Qdrant 向量数据库容器
docker-compose up --build -d
# 将职位数据嵌入并导入到正在运行的 Qdrant 实例中
uv run python scripts/ingest_qdrant.py
```
### 4. 前端设置(Web界面)
```
cd web_interface
npm install
# 启动开发服务器(CSS 监视 + Live Server)
npm run dev
# 如果遇到任何问题,请依次运行以下命令
Remove-Item -Recurse -Force node_modules
npm install
npm run dev
```
### 5. 启动引擎
在一个新的终端窗口中:
```
# 返回根目录
cd ..
# 启动 FastAPI 服务器
uv run uvicorn core_engine.main:app --reload
```
您的应用程序将在 `http://localhost:3000` 上运行,并与运行在 `http://localhost:8000` 的后端进行通信。
## 团队成员
- **Mayank Anand**:团队负责人,架构设计,LLM推理与用户体验优化。
- **Abhinav Anand (285)**:前端核心开发,API编排与仪表盘逻辑。
- **Harsh Anand**:UI/UX结构与Tailwind实现。
- **Abhinav Anand (08)**:安全审计与性能基准测试。
- **Ankit Anand**:数据工程与数据集策展。标签:AI招聘, AI驱动, AV绕过, FastAPI, PII脱敏, Qdrant, Qwen 2.5, RAG, SBERT, 人才管理, 代码示例, 可扩展性, 向量数据库, 安全防护, 技能匹配, 技能差距可视化, 提示注入防御, 数据主权, 数据分析, 数据可视化, 本地AI推理, 求职平台, 源代码安全, 简历分析, 职业优化, 职业准备度评分, 职业规划, 语义匹配, 逆向工具