AneetaBinoo/DeepCTI
GitHub: AneetaBinoo/DeepCTI
一个基于智能体工作流的网络安全威胁情报缓解分析框架,利用本地大语言模型通过迭代式证据检索与推理,为安全分析师自动生成有据可查的缓解建议。
Stars: 0 | Forks: 0
# DeepCTI:用于网络安全威胁情报缓解的智能体框架
[](#requirements)
[](#ollama-models)
[](#license)
本代码仓库包含 **DeepCTI:用于网络安全威胁情报缓解的智能体框架** 的数据集、实现代码、提示词、评估脚本以及可直接用于论文的结果构件。
DeepCTI 是一个智能体网络安全威胁情报(CTI)缓解分析框架,用于生成有证据支撑的缓解建议。该框架在包含 100 个案例的本地情报评估数据集上,比较了三种执行模式——单次生成、无记忆阶段生成以及迭代式证据保留 DeepCTI。
## 代码仓库内容
```
DeepCTI-main/
├── Dataset.xlsx # 100-case evaluation workbook
├── Metric Definitions.md # Metric definitions used in the paper
├── README.md # Original repository README
├── Run.cmd # Windows dependency installation helper
├── Run_All.cmd # Windows all-model reproduction helper
├── requirements.txt # Python dependencies
├── src/
│ └── deepcti/
│ ├── __init__.py
│ ├── dataset.py # Excel dataset loader and column parsing
│ ├── embedding_utils.py # SentenceTransformer embedding utilities
│ ├── evaluate_suggested.py # Evaluation and paper-table generation
│ ├── ollama_client.py # Local Ollama API wrapper
│ ├── prompts.py # Prompt templates and dry-run answer generator
│ └── run_experiment.py # Main experiment runner
└── FinalDeepCTIResults/
├── DeepCTIFramework.png # Framework figure
├── DeepIterations.png # Iterative-state figure
├── table1_framework_level_results.csv
├── table2_semantic_scorer_evaluation.csv
├── table3_model_agnostic_deepcti_results.csv
├── table4_cosine_similarity_by_embedding_model.csv
├── table5_state_transition_iteration_trace.csv
├── table6_stopping_iteration_summary.csv
└── table7_metric_definitions.csv
```
## 框架概述
DeepCTI 评估了与单步生成相比,迭代式证据积累是否能改善缓解建议。每个案例包含 CTI 上下文、本地环境信息、基线缓解文本、阶段性证据更新以及经过验证的参考缓解目标。
该实现支持三种模式:
| 模式 | 描述 |
|---|---|
| `one_shot` | 仅使用初始 CTI 和本地上下文。 |
| `no_memory` | 使用最新的阶段性证据,而不重建积累的证据轨迹。 |
| `iterative` | 保留阶段性证据,更新缓解状态,验证支持情况,并生成最终建议。 |
生成的输出要求包含:
1. 简明的最终缓解目标,
2. 所使用的证据,
3. 缓解的理由,以及
4. 验证/停止决策。
## 数据集
工作簿 `Dataset.xlsx` 包含实验运行器使用的评估数据。
重要工作表包括:
| 工作表 | 用途 |
|---|---|
| `DeepCTI_Run_Input` | `run_experiment.py` 使用的主要 100 个案例输入表。 |
| `Evaluation_Metadata` | 案例族、目标应用程序、漏洞类别、证据节点、评分细则字段和评分备注。 |
| `Run_Protocol` | 用于复现的协议元数据。 |
| `Column_Guide` | 人类可读的列描述。 |
| `Evaluation_Design` | 实验设计说明。 |
| `Metric_Mapping` | 生成的/参考的文本与评估指标之间的映射。 |
`src/deepcti/dataset.py` 中的加载器会自动检测关键列,例如 `Questions`、`Baseline_Mitigation`、阶段性证据列以及参考目标列(如 `Evaluation_Target_Text` 或 `Final_Mitigation_Reference`)。
## 环境要求
推荐环境:
- Python 3.10 或更新版本
- Windows PowerShell、Command Prompt、macOS shell 或 Linux shell
- 用于完整模型运行的本地 [Ollama](https://ollama.com/) 服务器
- 足够的磁盘空间和内存,用于本地 LLM 和 SentenceTransformer embedding 模型
Python 包已在 `requirements.txt` 中列出:
```
pandas
openpyxl
numpy
scikit-learn
sentence-transformers
matplotlib
requests
jinja2
rank-bm25
```
## 安装
### 选项 1:Windows 辅助脚本
```
Run.cmd
```
### 选项 2:手动安装
```
python -m venv .venv
source .venv/bin/activate # macOS/Linux
# .venv\Scripts\activate # Windows PowerShell
python -m pip install --upgrade pip
python -m pip install -r requirements.txt
```
在直接运行模块之前设置源路径:
```
export PYTHONPATH="$PWD/src" # macOS/Linux
# set PYTHONPATH=%CD%\src # Windows cmd.exe
# $env:PYTHONPATH="$PWD\src" # Windows PowerShell
```
## 快速冒烟测试
空运行不会调用 LLM。它验证数据集加载、提示词构建、JSONL 写入和模式处理是否正常工作。
```
PYTHONPATH=src python -m deepcti.run_experiment \
--data-path Dataset.xlsx \
--out-dir runs/smoke_test \
--modes one_shot,iterative \
--max-cases 2 \
--dry-run \
--no-resume
```
预期输出:
```
runs/smoke_test/
├── predictions.jsonl
├── errors.jsonl
└── run_log.txt
```
## 使用 Ollama 运行实验
在运行完整实验之前启动 Ollama:
```
ollama serve
```
拉取论文实验中使用的本地模型,或者将它们替换为本地 Ollama 注册表中可用的模型标签:
```
ollama pull llama3.1:8b
ollama pull qwen2.5:14b
ollama pull mistral-nemo:12b
ollama pull gemma3:12b
ollama pull deepseek-r1:8b
```
`run_experiment.py` 中的默认模型列表为:
```
gemma4:e4b, llama3.1:8b, qwen2.5:14b, mistral-nemo:12b, gemma3:12b, deepseek-r1:8b
```
单模型运行示例:
```
PYTHONPATH=src python -m deepcti.run_experiment \
--data-path Dataset.xlsx \
--out-dir runs/llama31_8b \
--models llama3.1:8b \
--modes one_shot,no_memory,iterative \
--no-resume
```
实用选项:
| 选项 | 含义 |
|---|---|
| `--data-path` | Excel 工作簿的路径。此压缩包请使用 `Dataset.xlsx`。 |
| `--out-dir` | 写入预测、错误和日志的目录。 |
| `--models` | 以逗号分隔的 Ollama 模型标签。 |
| `--modes` | 以逗号分隔的模式:`one_shot`、`no_memory`、`iterative`。 |
| `--max-cases` | 用于调试或消融实验的可选限制。 |
| `--dry-run` | 使用确定性占位符输出,而不是调用 Ollama。 |
| `--no-resume` | 在开始前删除现有的预测/错误文件。 |
| `--timeout` | Ollama 请求超时时间(以秒为单位)。默认值:`900`。 |
## 完整复现工作流程
### 1. 生成预测
运行每个模型,并将所有预测追加到一个组合的 JSONL 文件中。Windows 辅助程序 `Run_All.cmd` 可自动化此工作流程。
对于可移植的 shell 工作流程:
```
mkdir -p runs
: > runs/combined_all_models_predictions.jsonl
for model in llama3.1:8b qwen2.5:14b mistral-nemo:12b gemma3:12b deepseek-r1:8b; do
safe=$(echo "$model" | tr ':.-' '___')
ollama pull "$model"
PYTHONPATH=src python -m deepcti.run_experiment \
--data-path Dataset.xlsx \
--out-dir "runs/${safe}_suggested_full" \
--models "$model" \
--modes one_shot,no_memory,iterative \
--no-resume
cat "runs/${safe}_suggested_full/predictions.jsonl" >> runs/combined_all_models_predictions.jsonl
done
```
### 2. 评估预测
```
PYTHONPATH=src python -m deepcti.evaluate_suggested \
--predictions runs/combined_all_models_predictions.jsonl \
--out-dir runs/combined_suggested_eval
```
预期评估输出:
```
runs/combined_suggested_eval/
├── case_metrics_by_embedding.csv
├── semantic_similarity_by_embedding_and_mode.csv
├── summary_by_mode.csv
├── summary_by_llm_model_and_mode.csv
├── thresholded_match_f1.csv
├── thresholded_match_f1_pivot.csv
├── iteration_distribution.csv
└── paper_ready_tables.tex
```
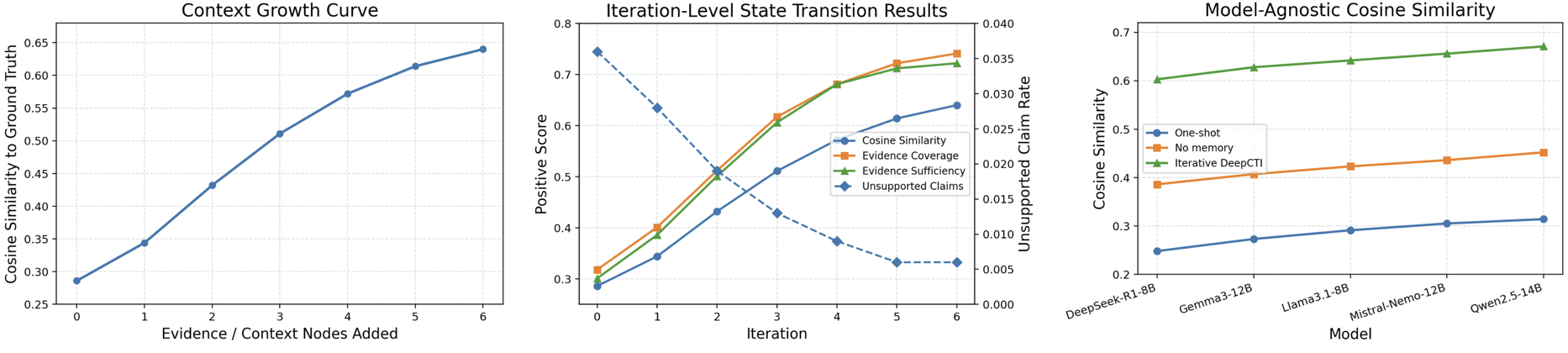
## 评估指标
DeepCTI 报告语义对齐、检索、停止和鲁棒性指标。
| 指标 | 用途 | 方向 |
|---|---|---|
| 平均余弦语义相似度 | 生成的缓解目标与验证的参考目标之间基于 embedding 的相似度。 | 越高越好 |
| 阈值匹配 F1 | 在将余弦相似度转换为二进制匹配/不匹配标签后的 F1 分数。 | 越高越好 |
| 证据覆盖率 | 检索并使用的相关证据节点的比例。 | 越高越好 |
| 证据可靠性 | 支持最终声明的引用证据的比例。 | 越高越好 |
| 证据充分性 | 累积的 top-p 证据质量是否支持停止。 | 越高越好 |
| 迭代次数 | 选定的证据块/状态转换的数量。 | 用于轨迹分析报告 |
| 不支持的声明 | 生成的缓解中不支持的或幻觉产生的声明。 | 越低越好 |
重要解释:
- 余弦相似度是一个连续的语义对齐分数,而不是 F1 分数。
- 匹配 F1 仅在将余弦相似度阈值化之后计算。
- 负对照是通过将生成的输出与错误的参考目标配对来创建的,从而使真阴性和假阳性具有意义。
- 默认情况下,评估使用在 `src/deepcti/embedding_utils.py` 中定义的 embedding 模型:
- `sentence-transformers/all-MiniLM-L6-v2`
- `sentence-transformers/all-mpnet-base-v2`
- `intfloat/e5-base-v2`
## 包含的论文结果构件
目录 `FinalDeepCTIResults/` 包含用于手稿准备的静态导出表格和图表。
| 文件 | 描述 |
|---|---|
| `DeepCTIFramework.png` | 框架图。 |
| `DeepIterations.png` | 迭代证据/状态转换图。 |
| `table1_framework_level_results.csv` | 单次生成、无记忆和迭代式 DeepCTI 之间的框架级比较。 |
| `table2_semantic_scorer_evaluation.csv` | 语义评分器/检索器评估。 |
| `table3_model_agnostic_deepcti_results.csv` | 与模型无关的鲁棒性结果。 |
| `table4_cosine_similarity_by_embedding_model.csv` | 按 embedding 模型划分的余弦相似度。 |
| `table5_state_transition_iteration_trace.csv` | 迭代/状态转换轨迹。 |
| `table6_stopping_iteration_summary.csv` | 停止迭代摘要。 |
| `table7_metric_definitions.csv` | 用于报告的指标定义。 |
对于重新生成的运行,请引用在 `runs/combined_suggested_eval/` 下生成的文件。对于论文快照,请引用 `FinalDeepCTIResults/` 中的导出文件。
## 实现说明
### 数据集加载
`dataset.py` 读取 `Dataset.xlsx`,在存在时选择 `DeepCTI_Run_Input` 工作表,检测分析师问题、基线缓解、阶段性证据和参考目标列,并返回一个 `Case` 对象列表。
### 提示词
`prompts.py` 定义了共享的系统指令和特定模式的上下文构建。提示词要求模型仅在提供的 CTI 证据和本地上下文中立足提出建议。
### LLM 后端
`ollama_client.py` 向以下地址发送非流式生成请求:
```
http://localhost:11434/api/generate
```
默认生成温度为 `0.1`,默认上下文窗口参数为 `num_ctx=8192`。
### 评估
`evaluate_suggested.py` 读取预测的 JSONL 记录,计算生成的和参考的缓解目标之间的 embedding 相似度,构建移位参考的负对照,估计检索充分性,总结模式级别和模型级别的结果,并导出 CSV 和 LaTeX 表格。
## 可复现性检查清单
在提交或发布本代码仓库之前,请验证以下内容:
- [ ] `Dataset.xlsx` 是预期的匿名化/公开发布数据集。
- [ ] 命令中的模型标签可通过已安装的 Ollama 版本使用。
- [ ] `Run_All.cmd` 指向 `Dataset.xlsx`,而不是较旧的数据集文件名。
- [ ] 重新生成的输出与论文中报告的值相匹配,或者差异已被记录。
- [ ] `FinalDeepCTIResults/` 包含论文中使用的确切图表/表格。
- [ ] 最终的论文标题、作者列表、出版地点、DOI 和引用已添加在下方。
- [ ] 项目许可证已被明确声明。
## 故障排除
### `未找到 Dataset`
请使用此压缩包中包含的数据集名称:
```
--data-path Dataset.xlsx
```
### 来自 Ollama 的 `Connection refused`
启动 Ollama 服务:
```
ollama serve
```
然后确认该模型在本地存在:
```
ollama list
```
### SentenceTransformer 模型下载失败
首次评估运行时会下载 embedding 模型。请确保环境具有网络访问权限,或在运行评估之前预先缓存模型。
### 本地 LLM 推理期间出现内存不足
请使用较小的模型,一次运行一个模型,减少并发进程,或者使用 `--max-cases` 限制案例数量以进行调试。
### 空的预测文件
请检查 `runs//errors.jsonl` 和 `runs//run_log.txt`。如果没有写入任何预测,实验运行器将引发错误。
## 联系方式
有关论文构件的问题,请在代码仓库中开启一个 issue,或联系出版物中列出的通讯作者。
标签:AI风险缓解, DLL 劫持, LLM, LLM评估, Ollama, Python, SentenceTransformer, Unmanaged PE, 反取证, 大语言模型, 威胁情报, 威胁阻断, 安全分析师, 安全智能, 安全评估, 安全运营中心, 开发者工具, 文本嵌入, 无后门, 本地大模型, 缓解分析, 缓解建议, 网络安全, 网络安全数据集, 网络映射, 自动化响应, 证据检索, 迭代推理, 逆向工具, 防御措施, 隐私保护