alexgreensh/token-optimizer
GitHub: alexgreensh/token-optimizer
一款面向 AI 编程助手的上下文优化插件,通过结构性审计、智能压缩、质量评分和实时仪表盘,显著降低 token 消耗并防止长会话中的上下文质量衰减。
Stars: 1677 | Forks: 134














你的 AI 正在变笨,而你却看不见。
节省 token。挺过压缩。衡量证据。
大多数 token 工具只触及了问题的冰山一角。
它们压缩命令输出,在理想情况下这占据了上下文的 15-25%。其余 75-85%(臃肿的配置、未使用的技能、重复的系统提示、过时的记忆,加上每次压缩损失掉的 60-70%)却无人问津。
Token Optimizer 涵盖了所有这一切,让你的工作成果在多次压缩中存活下来,衡量优化是否真的有帮助,并为你提供一个实时仪表盘,显示每一个 token、每一美元和每一轮对话,在每次会话后自动更新。完全在本地运行。消耗零上下文 token。零运行时依赖。
目前已支持 Claude Code、OpenClaw 和 Codex(测试版)。Windsurf、Cursor 及更多平台正在开发中。

## 安装
**适用于所有平台(macOS、Linux、Windows)的推荐方式:**
```
/plugin marketplace add alexgreensh/token-optimizer
/plugin install token-optimizer@alexgreensh-token-optimizer
```
然后在 Claude Code 中运行:`/token-optimizer`
Windows 用户:请先阅读本节
上述插件安装是你在 Windows 上应该使用的**唯一**途径。**不要**同时运行下文所述的 `install.sh` 脚本——那是一个适用于 macOS/Linux/WSL 的 bash 安装程序,如果两者结合使用,会产生 `EBUSY: resource busy or locked` 错误,因为 Git Bash 会在插件系统尝试克隆时保持 Windows 文件句柄处于打开状态。
**仓库大小提示**:我们的仓库大小约为 3 MB(218 个文件,约 2,700 个 git 对象)。如果你的 `/plugin marketplace add` 尝试似乎在下载千兆字节的数据,那不是我们——请取消并检查 Claude Code 是否正在克隆不同的 URL 或处于不同的网络状态。你可以通过手动克隆来验证:`git clone --bare https://github.com/alexgreensh/token-optimizer.git` 应该会在一秒钟内完成,并产生一个约 2.6 MB 的目录。
如果你已经遇到了 EBUSY 错误:
1. 关闭所有 Claude Code 窗口和 Git Bash 终端。
2. 打开任务管理器并结束所有残留的 `git.exe` 进程。
3. 删除以下两个文件夹(如果存在):
- `C:\Users\\.claude\token-optimizer`
- `C:\Users\\.claude\plugins\marketplaces\alexgreensh-token-optimizer`
4. 如果 Windows 仍然拒绝删除(文件正在使用),请重启,然后再删除。
5. 打开一个新的 Claude Code 窗口并运行上述两条 `/plugin` 命令。
**手动 ZIP 备用方案**(如果插件安装反复失败):下载[仓库 ZIP](https://github.com/alexgreensh/token-optimizer/archive/refs/heads/main.zip)(约 800 KB),解压到 `C:\Users\\.claude\token-optimizer\`,然后在该目录中运行 `python measure.py setup-quality-bar`。注意:在 Windows 上命令是 `python`,而不是 `python3`。
仅限 macOS / Linux:脚本安装(替代方案)
如果你倾向于在 macOS 或 Linux 上使用脚本管理安装,这种方式同样有效,并且会通过 `git pull --ff-only` 每日自动更新。**不要在 Windows 上运行此脚本,也不要在任何平台上将其与上述插件安装同时使用。**请选择其中一种方法。
```
git clone https://github.com/alexgreensh/token-optimizer.git ~/.claude/token-optimizer
bash ~/.claude/token-optimizer/install.sh
```
适用于 Claude Code 和 [OpenClaw](#openclaw-plugin)。每个平台都有其原生插件(Claude Code 使用 Python,OpenClaw 使用 TypeScript)。无需桥接,无需共享运行时,零跨平台依赖。
Codex(测试版)
Token Optimizer 适用于 OpenAI Codex(CLI 和桌面版)。相同的核心引擎,针对 AGENTS.md、GPT-5.x 模型和 Codex 的 hook 接口进行了适配。这是一个**测试版**——核心审计、指导、仪表盘和批量扫描功能均可正常工作。一些高级功能(Delta Mode、Structure Map、不可见的 Bash 压缩)正在等待上游 Codex 实现 hook 接口对齐。
```
codex plugin marketplace add alexgreensh/token-optimizer
```
然后在 Codex TUI 中:运行 `/plugins` 并安装 Token Optimizer。通过对话方式请求:“Run Token Optimizer”。
安装后,设置 hooks 和可添加书签的仪表盘:
```
TOKEN_OPTIMIZER_RUNTIME=codex python3 skills/token-optimizer/scripts/measure.py codex-install --project "$PWD"
TOKEN_OPTIMIZER_RUNTIME=codex python3 skills/token-optimizer/scripts/measure.py setup-daemon
```
仪表盘:`http://localhost:24843/token-optimizer`(使用与 Claude Code 的 24842 不同的独立端口,两者可以同时并行运行)。
通过 `git ls-remote` 在启动时自动更新。手动更新命令:`codex plugin marketplace upgrade`。
有关完整的功能对比表、hook 配置文件和 Codex 模型定价,请参阅 [`docs/codex-beta.md`](docs/codex-beta.md)。
OpenClaw
专为 OpenClaw 代理系统打造的原生 TypeScript 插件。零 Python 依赖,零运行时依赖,零遥测。适用于你的网关配置的任何模型:Claude、GPT-5、Gemini、DeepSeek、通过 Ollama 运行的本地模型。
```
# 从 GitHub(推荐)
openclaw plugins install github:alexgreensh/token-optimizer
# 从 ClawHub
openclaw plugins install token-optimizer
```
在 OpenClaw 内部,运行 `/token-optimizer` 以获取带有指导的引导式审计。
完整文档请参阅 [`openclaw/README.md`](openclaw/README.md)。
## 完全可见性:查看每一个 Token、每一美元、每一轮对话
大多数工具只会告诉你上下文已满。Token Optimizer 会向你确切展示每个 token 的去向、每一轮对话的成本、哪些技能和 MCP 服务器真正被调用了,以及哪些只是在白白消耗你的预算。
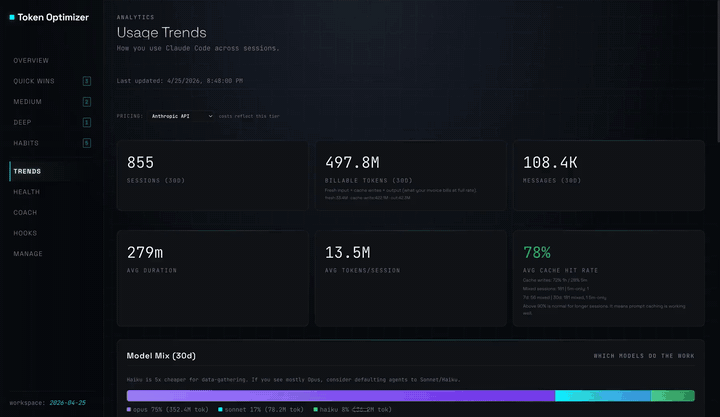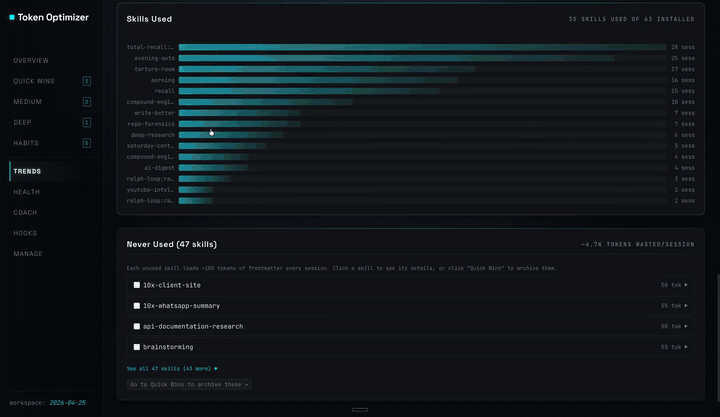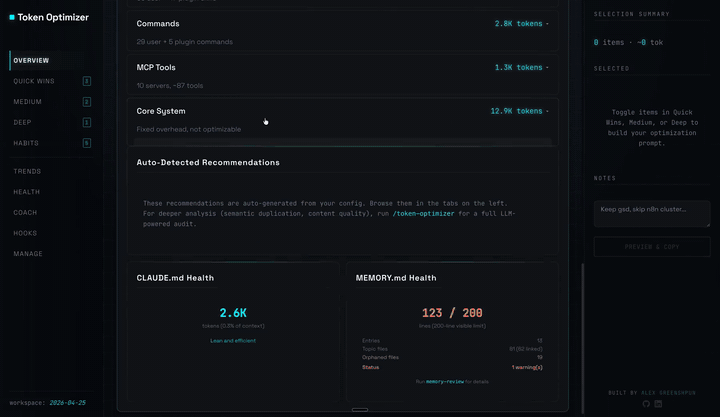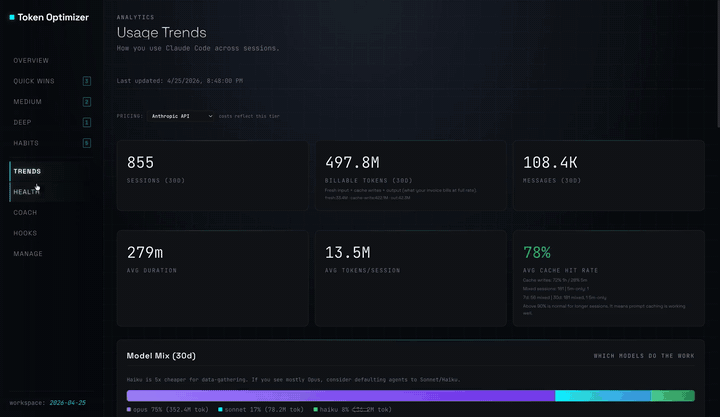
一个单文件 HTML 仪表盘。通过 SessionEnd hook 在每次会话后自动重新生成。将 `http://localhost:24842/token-optimizer` 添加为书签,它将始终是最新的。不消耗你的上下文 token,不发起网络调用,安装后无需任何设置。
### 仪表盘追踪的内容
- **每轮对话的 token 明细**,涵盖每一次 API 调用:输入、输出、缓存读取、缓存写入,并带有用于高亮显示上下文跳跃的峰值检测
- **缓存分析**:堆叠条形图显示输入与输出与缓存读取与缓存写入的比例,并附带 TTL 组合(`1h` vs `5m`)和命中率
- **调用间的节奏指标**,以便你了解线程是平稳运行还是走走停停
- **4 个定价等级的成本**:Anthropic API、Vertex Global、Vertex Regional、AWS Bedrock。只需设置一次你的等级,每次会话都会自动更新
- **颜色编码的质量分数**叠加在每次会话上:绿色表示健康,黄色表示性能下降,红色表示出现故障
- **子代理成本明细**:编排器与工作节点的支出、按成本排名的主要消耗者、当子代理消耗超过 30% 时触发警告
- **每次会话成本最高的 5 个提示词**,将每条用户消息与其响应成本配对
- **技能采用趋势**:你实际调用的技能与仅仅安装了的技能的对比
- **随时间变化的模型组合**:Opus、Sonnet、Haiku 在每次会话中的使用比例
- **概览选项卡上的 CLAUDE.md 和 MEMORY.md 健康卡片**,可一目了然地查看行数、孤立文件数和状态
- **偏移检测**:跨时间比较配置快照,以便在造成损失之前发现配置蔓延
- **节省追踪器**:来自优化、检查点恢复和归档的累计节省金额
`/context` 只显示一个容量条。代理压缩器会打印终端报告。而 Token Optimizer 则会展示完整的收据,自动更新,且零上下文成本。
### 启动它
```
python3 measure.py setup-daemon # Bookmarkable URL at http://localhost:24842/token-optimizer
python3 measure.py dashboard --serve # One-time serve over HTTP
```
在整个 README 中,每当某个功能提及它也在仪表盘上可见时,这意味着它位于同一个 HTML 页面内。一个地方,追踪一切。
## 这有什么不同
### 两种类型的 token 浪费,大多数工具只修复了一种
**运行时浪费**:充斥着你上下文的冗长命令输出。大约占你消耗量的 15-25%。这就是代理压缩器所处理的内容。
**结构性浪费**:臃肿的 CLAUDE.md、未使用的技能、重复的系统提醒、过时的 MEMORY.md、200 行之后不可见的内容、无效的 MCP 服务器。占据了另外的 75-85%。几乎没有人触及这一点。
Token Optimizer 两者兼顾。并且因为它还会在压缩触发之前对你的会话进行检查点保存,并恢复摘要中丢弃的内容,所以节省的成果会真正保留下来,而不是在 auto-compact 启动的那一刻消失。
### 完全本地,零依赖,零遥测
在 Claude Code 和 Codex 上使用纯 Python 标准库。在 OpenClaw 上使用纯 Node 标准库。运行时无需 `pip install`,无需 `npm install`,没有分析端点,没有数据回传。每一次测量都是一次本地 SQLite 写入操作,写入到你在运行时主目录下拥有的文件中,例如 `~/.claude/_backups/token-optimizer/trends.db` 或 `~/.codex/_backups/token-optimizer/trends.db`。你可以检查、导出或删除它。
### 零上下文 token 消耗
Token Optimizer 作为外部进程运行。它不会向你的上下文中注入指令,不会增加 MCP 开销,也永远不会蚕食你的窗口。你完整的 1M 预算完全属于你。
### `/context` 只显示仪表盘的表面。Token Optimizer 则为你打开引擎盖。
`/context` 告诉你上下文已满 73%。Token Optimizer 会告诉你哪 12K 被浪费在了你从未使用的技能上,标记出 Claude 看不到的 47 个孤立的 MEMORY.md 主题文件,在压缩破坏你的决策之前对其进行检查点保存,并为你提供一个质量分数,用于追踪随着会话的进行你的 AI 变笨了多少。
## 真实节省
来自 30 天重度 Opus 使用的一个真实快照:942 个会话,61.3 亿输入 token,90% Opus,82% 缓存命中率。

对于此体量的重度用户,**每月 $1,500 到 $2,500**。仅输入节省就达到约 $590。其余部分则是通过捕获循环、在正确时机执行 `/compact` 以及避免糟糕压缩后的重建所节省的输出和思考 token。
轻度用户可看到相应比例的节省。结构性审计带来的收益(未使用的技能、重复的配置、孤立的记忆条目)是立竿见影的,无论体量大小,而且它们会产生复利效应,因为更小的前缀意味着在随后的每一次交互中缓存读取账单都会更小。
## 信任与安全常见问题
🎯 Token Optimizer 会降低我的上下文质量吗?
不会。结构性优化只会删除真正未使用的组件(你从未调用过的技能、重复的配置、孤立的记忆条目)。主动压缩功能是可独立切换的,并且有损功能(如 Bash Compression)可以通过单个命令或环境变量禁用。7 信号质量分数会主动追踪性能下降情况,因此如果任何东西损害了质量,分数将会显示出来。
💾 它会破坏 prompt cache 吗?
不会,这很重要。Prompt cache 依赖于稳定的前缀。任何编辑或删除对话中已有块的工具都会使缓存失效,并让你花费**更多**,而不是更少。
Token Optimizer 绝不会触及已经存在于你上下文中的内容。它作用于进入你窗口的新内容(压缩),以及在压缩前后发生的事情(检查点和恢复)。你的缓存前缀保持不变,这意味着 Token Optimizer 实际上为你节省了两笔钱:
1. **每次交互的输入更少。**更少的结构性 token 意味着更小的上下文,因此每条消息的处理速度更快、成本更低。
2. **后续每次交互的缓存读取更便宜。**更小的稳定前缀意味着在后续每条消息上的缓存读取账单更小。这会在整个会话中产生复利效应。
请小心那些声称在会话中“清理”你上下文的工具。如果它们修改或删除现有的对话块,它们就会破坏你的缓存。在接下来的 50 条消息中以未缓存速率重新发送完整前缀的成本,很容易就会抵消掉它们为你节省的部分。
🔒 它会将任何数据发送到任何地方吗?
没有网络调用。没有分析数据。没有需要选择退出的遥测,因为根本没有遥测。每个事件都是本地 SQLite 中的一行记录。你可以使用 `sqlite3` 查看它、导出它、删除它,或者永远不去管它。它是你的。
🛟 它会损害我的会话吗?
不会。所有 hook 都是非阻塞的,采用故障开放设计。如果 Token Optimizer 脚本发生错误,你的命令会正常运行。压缩功能均可单独切换。检查点是附加性的。质量评分是只读的测量。
📦 它有任何运行时依赖吗?
没有。在 Claude Code 和 Codex 上使用纯 Python 标准库。在 OpenClaw 上使用纯 Node 标准库。运行时无需 `pip install`,无需 `npm install`。你克隆的内容就是它所需的全部。
🧰 它支持哪些平台?
目前已支持 Claude Code 和 OpenClaw,并为每个平台提供原生插件。Codex 支持处于测试阶段,带有用于以聊天优先的状态展示、指导、仪表盘刷新和批量扫描的 Python 适配器。
Windsurf 和 Cursor 是路线图上的下一个目标。完整的 Codex 功能对齐正在等待上游提供用于不可见读取替换、structure-map 替换和 compact 生命周期 hooks 的 hook/cache 接口。
## 为什么优先安装此工具
每个 Claude Code 会话都以不可见的开销开始:系统提示、工具定义、技能、MCP 服务器、CLAUDE.md、MEMORY.md。一个典型的重度用户在输入一个字之前就会消耗掉 50-70K token。
随着 Opus 4.6 和 Sonnet 4.6 现已达到 1M 上下文,这似乎有了喘息的空间。但问题依然在不断叠加:
- **随着上下文填满,质量会下降。**在 256K 和 1M 之间,MRCR 从 93% 下降到 76%。随着窗口被填满,你的 AI 变得明显变笨。
- **速率限制更快触及。**无论是否缓存,幽灵 token 都会计入你计划的使用上限中。50K 的开销乘以 100 条消息,就是 500 万个白白消耗的 token。
- **压缩是灾难性的。**每次压缩会丢失 60-70% 的对话。经过 2-3 次压缩后,你会丢失 88-95% 的内容。而且每次压缩都意味着要重新发送所有那些开销。
- **更高的工作量意味着更快的消耗。**每次响应需要更多的思考 token,意味着你会更快触及压缩,这也就意味着整个会话的总 token 数会更多。
- **你无法修复你看不见的东西。**如果没有对每次交互的缓存命中、模型组合和子代理支出的可见性,每一次“感觉变慢了”的猜测都会耗费金钱。仪表盘会确切显示哪一轮对话是昂贵的。
Token Optimizer 追踪所有这些。质量分数、性能下降区间、压缩损失、偏移检测、跨越四个定价等级的单轮成本,以及每个会话的技能和 MCP 归因。零上下文 token 消耗。

## 智能压缩与会话连续性
当 auto-compact 触发时,60-70% 的对话会消失。决策、错误修复序列、代理状态,全部丢失。
智能压缩会在压缩触发之前将所有这些内容捕获为检查点,然后恢复摘要中遗漏的内容。它还会注入模型先前处理过的大型工具输出的摘要,因此在压缩之后,模型知道它已经看到了什么,而无需从头重新阅读所有内容。会话会从你上次中断的地方继续,即使是在崩溃或执行 /clear 之后。检查点历史记录和每次会话的压缩损失也可以在仪表盘上看到。
只有当你的会话挺过压缩时,压缩节省的成果才会得以保留。如果在 `git status` 上的节省,在紧接着的下一次自动压缩抹除了让你运行 `git status` 的决策时变得毫无意义。智能压缩闭合了这个循环:检查点保存你的决策,在压缩后恢复它们,并提醒模型它已经处理过哪些输出,这样它就不会浪费 token 重新读取它们。
```
python3 measure.py setup-smart-compact # checkpoint + restore hooks
```
### 渐进式检查点
无需等待紧急压缩,Token Optimizer 会在多个阈值处捕获会话状态:`20%`、`35%`、`50%`、`65%` 和 `80%` 的上下文填充率,以及质量分数下降到 `80`、`70`、`50` 和 `40` 以下时。它还会在代理扇出之前和大型编辑批次之后进行快照。在恢复时,它会选择最丰富且符合条件的检查点,而不仅仅是最近的那个。
后台守卫进程处理一次性阈值捕获、冷却抑制和确定性提取。检查点路径中没有任何 LLM 调用。
### 工具结果归档(模型感知,无需手动查找)
大型工具结果(>4KB)会自动归档到磁盘。在你的对话中,完整结果会被替换为一个简短的预览加上一个内联提示,例如 `[Full result archived (12,400 chars). Use 'expand abc123' to retrieve.]`
该提示对 Claude 可见,而不仅仅是对你可见。因此,在压缩之后(当原始工具结果已被摘要化时),如果模型再次需要完整输出来回答你的下一个问题,它会自行调用 `expand abc123`,归档的内容将通过 CLI 返回。无需重新运行命令,不会丢失输出,在此期间也不会产生上下文成本。
当你想查看特定的归档结果时,你自己也可以运行 `expand`,但主要流程是自动的:模型看到提示,模型请求获取字节,字节被返回。
```
python3 measure.py expand --list # List all archived tool results
python3 measure.py expand
# Retrieve a specific archived result manually
```
### 会话连续性
会话在结束、执行 /clear 和崩溃时会自动创建检查点。在一个全新的会话中,Token Optimizer 会向最近相关的检查点投放一个简短的内联指针,以便 Claude 可以在新对话需要时自行拉取正确的先前状态。没有过时上下文的自动重放,不需要用户操作,只是一个在关键时刻模型可以跟随的面包屑导航。
启用可选的纯本地检查点遥测,以查看检查点是否正在触发以及哪些触发器处于活动状态:
```
TOKEN_OPTIMIZER_CHECKPOINT_TELEMETRY=1 python3 measure.py checkpoint-stats --days 7
```
## 质量评分
七种信号,按实际影响加权:
| 信号 | 权重 | 对你意味着什么 |
|--------|--------|----------------|
| **上下文填充率** | 20% | 你离性能下降的悬崖有多近?基于已发布的 MRCR 基准。 |
| **过时读取** | 20% | 你早先读取的文件已更改。你的 AI 正在使用过时的信息工作。 |
| **臃肿的结果** | 20% | 从未使用过的工具输出。在噪音上浪费上下文。 |
| **压缩深度** | 15% | 每次压缩丢失 60-70% 的对话。经过 2 次后,88% 都会丢失。 |
| **重复项** | 10% | 一遍又一遍地注入相同的系统提醒。纯粹的浪费。 |
| **决策密度** | 8% | 你是在进行真正的对话,还是大部分都是开销? |
| **代理效率** | 7% | 你的子代理是在发挥作用,还是仅仅在消耗 token? |
### 效率等级
每个质量分数都包含一个字母等级,用于快速分类。状态行会显示类似 `ContextQ:A(82)` 的内容,相同的等级也会出现在仪表盘、指导选项卡和 CLI 输出中。
| 等级 | 范围 | 含义 |
|-------|-------|---------|
| **S** | 90-100 | 峰值效率。一切都很干净。 |
| **A** | 80-89 | 健康。可能需要进行轻微优化。 |
| **B** | 70-79 | 性能开始下降。值得调查。 |
| **C** | 60-69 | 严重浪费。指导模式会有所帮助。 |
| **D** | 50-59 | 严重的问题。可能存在多种反模式。 |
| **F** | 0-49 | 上下文正在腐烂。需要立即采取行动。 |
### 性能下降区间
状态栏的颜色会随着上下文的填充而改变:
- 绿色(填充率 <50%):峰值质量区间
- 黄色(50-70%):性能开始下降
- 橙色(70-80%):质量正在下降
- 红色(80%+):严重状态,考虑执行 /clear
### 性能下降实际上是什么样子
真实的会话。708 条消息,2 次压缩,88% 的原始上下文丢失。如果没有质量分数,你根本无从知晓。

## 主动压缩(v5)
Token Optimizer 不再仅仅测量上下文膨胀。它会主动减少膨胀。七项功能针对特定的浪费模式,每一项都提供了诚实可靠的风险评估和仪表盘切换开关。

**默认开启**:Quality Nudges、Loop Detection、Delta Mode、Structure Map、Bash Compression(16 个处理器)、Activity Mode Detection、Decision Extraction。
所有功能都可以通过仪表盘中的 Manage 选项卡、CLI(`measure.py v5 enable|disable `)或环境变量进行独立切换。
| 功能 | 默认状态 | 潜在节省 | 风险 |
|---|---|---|---|
| Quality Nudges | ON | 按每次压缩测量(填充率恢复) | 无 |
| Loop Detection | ON | 按每个循环测量(实际交互内容) | 无 |
| Delta Mode | ON | ~20%(智能重读) | 低 |
| Structure Map | ON(软阻止模式) | ~30%(大文件重读,单个文件最高可达 99%) | 低 |
| Bash Compression | ON | ~10%(CLI 输出) | 低 |
| Activity Mode | ON | 使压缩适应会话阶段 | 无 |
| Decision Extraction | ON | 跨压缩保留决策 | 无 |

### Quality Nudges(默认开启,全自动)
实时监控你的上下文质量。当分数下降 15 分以上或跌破 60 时,一条内联系统提示会进入上下文,内容类似于 `[Token Optimizer] Quality dropped to 58. Consider /compact to protect context.`
Claude 在下一轮对话中会看到该提示,并自然地向你发出警告,或者自行调整行为。你不必盯着仪表盘或记住阈值。提示会直接出现在做出决策的地方,安装后零设置。
**价值**:及早发现上下文腐烂,以便在决策因压缩丢失之前,在正确的时机执行 `/compact`。
**工作原理**:在每次 UserPromptSubmit 时运行现有的 quality-cache hook。两次提示之间有 5 分钟的冷却时间,每次会话最多 3 次。在压缩后的第一次检查时会被抑制,因此你不会因为刚修复的质量而收到警告。
**风险**:无。仅向上下文添加一条简短提示,从不删除任何内容。
### Loop Detection(默认开启,全自动)
在 AI 因重试循环卡住而白白消耗 token 之前将其捕获。当相似度超过阈值时,一条简短的内联提示会进入上下文,标记循环以便模型跳出,无需用户采取行动。节省的量是根据循环交互的实际内容计算的,而非估算。
**价值**:事后检测器发现循环会话平均浪费 47K token。实时检测可以防止这种情况。每次捕获的循环都会将测量到的循环交互的 token 成本记录到你的本地遥测中。
**工作原理**:比较最后 4 条用户消息和最后 5 个工具结果的相似度。在置信度 ≥0.7 时触发,每次会话上限为 2 次提示。使用固定的消息模板,从不将用户内容回显。
**风险**:无。仅添加一条简短提示。

### Delta Mode(默认开启,你最大的单项收益)
当 AI 在编辑文件后重新读取它时,Read 调用只返回更改的内容而不是整个文件。全自动,无需配置,无需用户操作。在实际会话中,超过 65% 的 Read 调用是重读,这使得这成为影响最大的 v5 功能。
**价值**:典型的会话会对同一个文件重新读取 2-5 次。Delta mode 只发送 diff。一个 2,000 token 的文件重读变成了一个 50 token 的 diff,对该特定读取实现了 97% 的节省。
**工作原理**:在首次读取时将文件内容(每个文件最大 50KB)存储在本地缓存中。在 mtime 发生变化的重读时,通过 Python 的 `difflib`(标准库,无 git 依赖)计算统一 diff。如果 diff 超过 1,500 个字符或任一文件超过 2,000 行,则回退到完整重读。限定于显式的全文件读取,因此狭窄的 `offset`/`limit` 请求永远不会返回全文件 diff。`.env` 和据文件被排除在缓存之外。
**风险**:低。如果 AI 需要完整文件来理解上下文中的更改,单靠 diff 可能不够。对于大型更改和大文件会故障开放。设置 `TOKEN_OPTIMIZER_READ_CACHE_DELTA=0` 以禁用。
### Structure Map(在软阻止模式下默认开启,处理大文件时的最大收益)
当 Claude 重新读取它在本次会话中已经看过的代码文件时,Read 调用会被阻止,并替换为紧凑的结构摘要:函数签名、类层次结构、导入和模块文档字符串。一个 720KB 的 Python 文件(180,000 token)变成了一个 250 token 的骨架。适用于最大 800KB/20K 行的 Python 文件和最大 400KB/5K 行的 JS/TS 文件。
**价值**:以代码为主的会话会多次重新读取相同的大型文件 3-17 次。Structure Map 将首次之后的每次重读压缩了 95-99%。在一个 180K token 的文件被重读 5 次的情况下,仅单个会话就节省了约 900K token。
**工作原理**:在首次读取时,缓存文件内容并生成基于 AST 的摘要或基于正则表达式的摘要(JS/TS)。在后续读取相同的未更改文件时,通过 `additionalContext` 返回摘要,并阻止完整重读。对于低于 1,000 token 的文件、生成/压缩的文件、部分范围读取,或者 AST 解析失败的情况,则回退到完整读取。
**测量**:启用 `measure.py v5 enable structure_map_beta` 或 `TOKEN_OPTIMIZER_STRUCTURE_MAP=beta` 以将压缩事件记录到用于 `compression-stats` 的本地 SQLite 中。不会向任何地方发送任何数据。
**风险**:低。模型根据摘要而不是完整源代码进行工作。对于实现细节很重要(不仅仅是结构)的文件,模型可以请求完整读取。使用 `TOKEN_OPTIMIZER_READ_CACHE_MODE=shadow` 禁用。

### Bash Output Compression(默认开启,有损)
重写常见的 CLI 命令以返回压缩摘要而不是冗长的输出。v5.1.0 提供了七个新处理器,覆盖了最消耗上下文的命令族:lint(针对 eslint、ruff、flake8、shellcheck、rubocop、golangci-lint 的规则代码分组)、log tails(相邻重复项折叠)、tree(深度 2 截断)、docker build 和 pull(进度过滤)、长列表(pip list、npm ls、docker ps,附带 top-N 加尾部标记)、JS/TS/Go build 输出(错误与摘要视图)和 test runner 路由(cypress、playwright、mocha、karma 均通过统一的 pytest 压缩器进行路由)。
连同现有的 git 和 pytest 处理器,这完整覆盖了实际会话中产生的约 90% 的冗长 CLI 输出。
**价值**:将数百行的测试/构建/git 输出剥离到只保留基本内容。一个 564 token 的 pytest 输出变为 115 token。一个包含 60 个文件的 `ls -la` 截断为 50。最适合包含大量 CLI 命令的会话。
**工作原理**:一个 PreToolUse hook(`bash_hook.py`)拦截安全的只读命令,使用 `shlex.split()` 对它们进行 tokenize,对照白名单进行检查,并通过 `updatedInput` 重写它们,以路由通过压缩包装器(`bash_compress.py`)。绝对排除复合命令(任何带有 `;`、`&&`、`||`、`|`、`$()`、反引号、`>`、`>>` 的命令)、sudo 和交互式标志。
**安全性**:从不使用 `shell=True`。凭据(AWS keys、GitHub PATs、Slack tokens、Stripe keys、OpenAI keys、HTTP basic-auth URLs)在压缩前会被扫描并逐字保留。多语言错误行在保留路径中得以幸存。超时时的部分输出将原样返回,从不进行压缩。
**如何禁用**:`measure.py v5 disable bash_compress` 或 `TOKEN_OPTIMIZER_BASH_COMPRESS=0`
**风险**:低。压缩在设计上是有损的。对于日常检查来说这没问题。对于仔细的 diff 审查或调试特定的测试失败,请使用上述命令临时禁用。
### Activity Mode Detection(默认开启,v5.6)
使用最近 10 次工具调用的滑动窗口,将你的会话分类为五种模式(代码、调试、审查、基础设施、通用)之一。模式标签会输入到压缩指导中,以便 PRESERVE/DROP 优先级适应你实际正在做的事情:调试模式保留错误信号和堆栈跟踪,代码模式保留编辑过的文件及其测试,审查模式保留发现和决策,同时丢弃完整的文件内容。
**工作原理**:PostToolUse hook 将每个工具调用分类到一个存储桶(edit、read、bash_infra、bash_git、web 等)中,并将其存储在按会话划分的 SQLite 中。模式分类在每个工具调用上运行,零延迟影响(单个 INSERT + 有界 SELECT)。活动日志自动修剪至 30 行。
**风险**:无。模式检测是只读上下文,从不修改或阻止任何内容。
### Decision Extraction(默认开启,v5.6)
从工具输出中实时检测决策声明,并增量存储在会话数据库中。在压缩时,这些决策作为 CRITICAL DECISIONS 被注入,压缩摘要必须逐字保留。结合新的锚定压缩状态(跨压缩周期持久化意图、更改、决策和错误),这可以防止导致压缩后会话丢失上下文的决策偏移。
**工作原理**:在 PostToolUse 路径上进行基于正则表达式的提取(仅在大于 500 个字符的输出上运行)。使用原子 read-modify-write(SQLite BEGIN IMMEDIATE)来防止在并发 hook 下丢失更新。每次会话上限为 10 个决策。
**风险**:无。仅将结构化数据添加到压缩指导中,从不删除任何内容。
### 管理 v5 功能
有三种方式可以控制这些功能:
```
# CLI
python3 measure.py v5 status # show all features with current state
python3 measure.py v5 enable delta_mode # turn a feature on
python3 measure.py v5 disable bash_compress # turn a feature off
python3 measure.py v5 info delta_mode # show full details for one feature
python3 measure.py v5 welcome # show the first-run welcome screen
python3 measure.py compression-stats # see actual measured savings from local telemetry
```
```
# Environment variables(覆盖 config.json,适用于 CI/scripts)
TOKEN_OPTIMIZER_QUALITY_NUDGES=0 # kill switch for nudges
TOKEN_OPTIMIZER_LOOP_DETECTION=0 # kill switch for loop detection
TOKEN_OPTIMIZER_READ_CACHE_DELTA=1 # enable delta mode
TOKEN_OPTIMIZER_BASH_COMPRESS=0 # disable bash compression
TOKEN_OPTIMIZER_STRUCTURE_MAP=beta # enable beta telemetry
```
**仪表盘**:打开 `token-dashboard` 和 Manage 选项卡。Active Compression (v5) 是第一个部分。切换开关会立即应用于新的工具调用,无需重启 Claude Code。每个功能都会显示其作用、价值、工作原理、风险级别及其影响估算。
**首次运行欢迎界面**:在安装 v5 后的第一次会话中,你会看到一个一次性的欢迎屏幕,解释每个功能、其默认状态以及如何切换。存储在 `config.json` 中,因此只显示一次。
### 测量实际节省量(全部在本地)
所有 v5 功能都会记录到存储在你机器上本地 `~/.claude/_backups/token-optimizer/trends.db` 的 `compression_events` SQLite 表中。任何数据都不会离开你的系统。
```
python3 measure.py compression-stats --days 30
```
输出显示每个功能的事件总数、节省的 token、压缩率和质量保留率。`verified` 标志区分了精确测量(delta mode 知道精确的前后差异)与估算(structure map 是启发式的)。
## 实时质量条
瞥一眼你的终端就能告诉你是否遇到了麻烦。颜色会随着质量下降从绿色变为红色。当质量跌破 75 时,会话持续时间将作为警告出现。正在运行的子代理会显示其模型和耗时,以便你能发现路由错误的模型。

```
python3 measure.py setup-quality-bar # one-time install
```
**我的质量条消失了,如何找回?**运行 Claude Code 内置的 `/statusline` 会重写 `~/.claude/settings.json` 中的 `statusLine` 键,并静默覆盖 Token Optimizer 的条目。SessionStart 会检测到这一点并**自动恢复**质量条。只需开始一个新会话,它就会回来。你会看到一行说明解释发生了什么。
**我真的不再需要质量条了,如何永久关闭它?**
```
python3 measure.py setup-quality-bar --uninstall
```
这会移除组件并将 `quality_bar_disabled: true` 写入 `~/.claude/token-optimizer/config.json`。选择退出在会话间是持久的。SessionStart 将不会自动恢复它。你也可以直接用自然语言告诉 Claude Code:_"remove the Token Optimizer statusline"_,Claude 就会为你运行卸载命令。
**我改主意了,把它找回来。**运行 `python3 measure.py setup-quality-bar`。显式安装会自动清除退出标记。
**我想保留自己自定义的状态栏,同时也想查看质量分数。**当你直接运行 `setup-quality-bar` 时,仍然支持自定义状态栏路径。你将获得有关从你自己的脚本中读取 `~/.claude/token-optimizer/quality-cache.json` 的集成说明。
## 指导模式和批量审计器
Token Optimizer 不仅仅是被动的。它也是主动的。
### 指导模式
```
> /token-coach
```
告诉它你的目标。获取具体的、按优先级排列的修复建议以及确切的 token 节省量。检测 8 种命名的反模式(The Kitchen Sink、The Hoarder、The Monolith 等等),并推荐真正能节省上下文的多代理设计模式。
**正在构建一个新项目?**在编写你的第一个 `CLAUDE.md` 或 Codex 的 `AGENTS.md` 之前运行 `/token-coach`。从一个干净、优化的设置开始,而不是积累几个月的浪费后再去修复。
### 浪费检测器
11 个自动化检测器分析你的会话模式并发现可操作的洞察:
| 检测器 | 捕获的内容 |
|---|---|
| PDF/二进制文件摄入 | 消耗上下文的大型文件(带有 token 估算的警告) |
| Web 搜索开销 | 过多的 Web 搜索结果被转储到上下文中 |
| 重试消耗 | 同一工具重试 3 次以上并伴随错误 |
| 工具级联 | 链式出现的 3 次以上连续工具错误 |
| 循环卡顿 | 重复的相似消息(模型卡住) |
| 过度配置的模型 | Opus 被用于简单的编辑(附带“如果使用 Sonnet:节省 $X”) |
| 配置过弱的模型 | Haiku 处理需要更强模型的复杂任务 |
| 糟糕的分解 | 单一的超过 500 字提示词承担了过多工作 |
| 浪费的思考 | 对于小型编辑,扩展思考 > 输出的 2 倍 |
| 输出浪费 | 对简单操作的冗长响应,重复的解释 |
| 缓存不稳定 | 破坏 Anthropic prompt cache 前缀的 CLAUDE.md 模式 |
### 批量审计器
正在管理多个代理系统?批量审计器可跨 Claude Code、Codex、OpenClaw 和自定义设置进行扫描,以查找空闲消耗、模型路由错误和配置臃肿,并附带每项发现的美元节省额。一个命令,一份报告,覆盖整个生态系统。
### 子代理成本明细
确切了解你的子代理花费了多少:总支出、占合并预算的百分比,以及按成本排名的主要消耗者。当子代理消耗超过总额的 30% 时触发警告。在仪表盘上也可按每次会话查看,带有编排器与工作节点的分类。
### 昂贵提示词排名
查看哪些提示词成本最高:将每条用户消息与响应成本配对,排名前 5。显示你问了什么,而不仅仅是总计。
### CLAUDE.md 路由注入
从你的实际使用数据生成模型路由指令并将其注入到 CLAUDE.md 中。Claude 在每次会话中都会读取这些指令并进行相应的路由。48 小时过时守卫会自动删除过时的建议。
```
python3 measure.py inject-routing --dry-run # Preview what would be injected
python3 measure.py inject-routing # Inject (with approval)
```
## 仪表盘:审计后演练
顶部的 Full Visibility 仪表盘会自动追踪每一次会话。在你运行 `/token-optimizer` 并且 6 代理审计完成后,相同的仪表盘会在一个以审计为中心的视图中打开,其中每个组件都是可点击的。展开任何项目以查看其重要性、权衡取舍以及会有什么改变。切换你想要的修复,复制一个随时可粘贴的优化提示词,并在批准后应用。
每列上的悬停帮助无需术语即可解释 `Cache`、`TTL`、`Pacing`、`Cache R` 和 `Cache W`。会话深入分析依赖于稳定的会话身份,以便在刷新时实现一致的展开。
## 你可以问什么问题?
| 命令 | 你将获得什么 |
|---------|-------------|
| `quick` | **“我遇到麻烦了吗?”** 10 秒回答:上下文健康度、性能下降风险、最大的 token 消耗者、该使用哪种模型。 |
| `doctor` | **“一切都安装正确了吗?”** 十分制评分。损坏的 hook、缺失的组件、确切的修复命令。 |
| `drift` | **“我的设置膨胀了吗?”** 与你上次快照的并排比较。在配置蔓延造成损失之前发现它。 |
| `quality` | **“这个会话有多健康?”** 对你实时对话的 7 信号分析。过时的读取、浪费的 token、压缩损害 |
| `report` | **“我的 token 去哪了?”** 完整的逐组件明细。每种技能、每个 MCP 服务器、每个配置文件。 |
| `conversation` | **“每一轮对话发生了什么?”** 带有峰值检测的逐条消息 token 和成本明细。 |
| `pricing-tier` | **“我付了多少钱?”** 查看或切换 Anthropic、Vertex 和 Bedrock 的定价等级。 |
| `kill-stale` | **“清理僵尸进程。”** 终止运行了 12 小时以上的无头会话。 |
| `git-context` | **“现在哪些文件很重要?”** 测试伴生文件、频繁共同更改的文件、针对你当前 git diff 的导入链。 |
| `trends` | **“实际被使用了什么?”** 技能采用、模型组合、随时间变化的开销轨迹。 |
| `coach` | **“我从哪里开始?”** 带有主动与被动信号的健康分数。检测反模式。 |
| `memory-review` | **“我的 MEMORY.md 坏了吗?”** 结构性审计:孤立文件、损坏的链接、200 行之后不可见的条目、重复的规则。 |
| `dashboard` | **“给我看一切。”** 包含所有分析和健康卡片的交互式 HTML 仪表盘。 |
| `savings` | **“我节省了多少?”** 来自优化、检查点恢复和归档的累计节省金额。 |
| `attention-score` | **“我的 CLAUDE.md 结构良好吗?”** 根据注意力曲线对各个部分进行评分,标记低注意力区域中的关键规则。 |
| `jsonl-inspect` | **“这个会话里有什么?”** 记录计数、token 分布、最大的 10 条记录、压缩标记。 |
| `expand` | **“找回那个结果。”** 检索模型自动归档的工具结果。通常模型在再次需要完整输出时会自己调用它,但你也可以手动运行它。 |
| `/token-optimizer` | **“帮我修复它。”** 带有 6 个并行代理的交互式审计。带有 diff 和备份的引导式修复。 |
## 对比
| 能力 | Token Optimizer | `/context` | context-mode | 代理压缩器 |
|---|---|---|---|---|
| 结构性浪费审计 | 深入,按组件 | 仅摘要 | 否 | 否 |
| 质量下降追踪 | 带有等级的 7 信号分数 | 仅容量百分比 | 否 | 否 |
| 压缩存活 | 渐进式检查点、恢复,外加工具输出摘要 | 否 | 仅会话指南 | 否 |
| 运行时输出压缩 | 16 个 CLI 处理器,凭据安全,可单独切换 | 否 | 是 | 是,始终开启(无法禁用) |
| 衡量压缩是否真有帮助 | 是,带有前后 token 的本地遥测 | 否 | 否 | 否 |
| 读取去重和重读时的智能 diff | 是 | 否 | 否 | 否 |
| 行为指导和模型路由 | 11 个检测器,按成本排名的子代理明细 | 基本建议 | 否 | 否 |
| CLAUDE.md 和 MEMORY.md 的结构健康状况 | 8 个审计器加注意力曲线评分 | 否 | 否 | 否 |
| 跨代理的批量级浪费检测 | 是 | 否 | 否 | 否 |
| 零上下文 token 消耗 | 是,外部进程 | 增加约 200 token | MCP 开销 | 向上下文注入指令 |
| 零运行时依赖 | 是,纯标准库 | 不适用 | 视情况而定 | 外部二进制文件 |
| 零遥测 | 是 | 是 | 视情况而定 | 选择退出遥测 |
| 跨平台支持 | Claude Code、Codex 测试版和 OpenClaw(Windsurf 和 Cursor 即将推出) | 仅限 Claude Code | 多个平台 | 多个平台 |
关于压缩列的一些说明:代理工具在它们最擅长处理的命令(如 `git status` 或 `tree`)上引用了很高的压缩率。这些数字对于这些特定命令来说是真实的,但它们只覆盖了你实际消耗量的 15-25%。其他一切(配置、技能、内存、压缩损失)仍未被触及。而且大多数代理压缩器会将其自己的指令注入到你的上下文中,这在进入时就需要消耗 token。
Token Optimizer 处理相同的运行时输出时涵盖了 30 多个命令族(git、pytest、lint、logs、tree、docker progress、package listings、JS/TS/Go builds、cypress/playwright/mocha/karma test runners),再加上代理不触及的另外 75-85% 的内容,再加上测量指标,这样你就可以看到所有这些在你的会话中是否真的有帮助。
### 关于缓存安全的一句话
一些工具声称通过修改或删除对话中已有的块来减少 token。这会破坏 prompt cache。当稳定前缀发生改变时,随后的每一次交互都会以未缓存的输入速率而不是大幅折扣的缓存读取速率重新发送完整前缀。移除几千个 token 带来的“节省”很容易就会被接下来 50 条消息的缓存失效成本所抹去。
Token Optimizer 绝不修改已经存在于你上下文中的内容。结构性优化在会话之间运行。主动压缩作用于进入你窗口的新内容,或者在压缩边界上运行。你的缓存前缀保持不变。
## 记忆健康:你的 MEMORY.md 可能已经坏了
Claude 在每次会话中会自动加载 MEMORY.md 的前 200 行。200 行之后的所有内容都会被静默截断。这些 token 仍然会计入你的窗口,但 Claude 永远看不到其内容。大多数重度用户并不知道这种情况正在发生。
`memory-review` 会在结构上扫描你的 MEMORY.md 并告诉你出了什么问题:
- **孤立的主题文件**:你的记忆目录中没有任何内容链接到的文件
- **损坏的链接**:指向不存在文件的索引条目
- **不可见的条目**:Claude 看不到的 200 行以下的内容
- **内联内容**:应该在主题文件中的笔记,浪费了索引预算
- **重复的规则**:已经存在于 CLAUDE.md 中的规则(无论大小,CLAUDE.md 都会完整加载)
- **过时的条目**:已解决/被取代但仍占用空间的内容
- **任务泄露**:属于任务追踪器的 TODO 列表和清单
```
python3 measure.py memory-review # Full structural audit
python3 measure.py memory-review --json # Machine-readable for dashboards
python3 measure.py memory-review --apply # Show actionable fixes
python3 measure.py memory-review --stale-days 90 # Custom staleness threshold
```
仪表盘在概览选项卡上显示 CLAUDE.md Health 和 MEMORY.md Health 卡片,可一目了然地查看行数、孤立文件数和状态。
对于矛盾检测(两条规则表达了相反的意思),请在 Claude 会话中运行审计。该工具会从这两个文件中提取所有的 NEVER/ALWAYS/MUST 规则。Claude 在上下文中以语义方式审查它们,无需额外的 LLM 调用。
## Read-Cache 和上下文工具
### PreToolUse Read-Cache(自动去重)
自动检测冗余的文件读取。在首次重读未更改的文件时,返回结构化的代码摘要(函数签名、类层次结构、导入)而不是完整源代码。一个 180,000 token 的文件重读变成了一个 250 token 的骨架。适用于最大 800KB 的 Python 文件和最大 400KB 的 JS/TS 文件。在软阻止模式下默认开启。在整个典型会话中,通过读取去重可节省 8-30% 的 token,对大型代码文件的压缩率可达 95% 以上。
```
# Read-cache 默认开启(警告模式)。若要禁用:
export TOKEN_OPTIMIZER_READ_CACHE=0 # Disable
export TOKEN_OPTIMIZER_READ_CACHE_MODE=block # Upgrade to block mode
# Read-cache 管理
python3 measure.py read-cache-stats --session ID # Cache stats for a session
python3 measure.py read-cache-clear # Clear all caches
```
使用 `TOKEN_OPTIMIZER_READ_CACHE=0` 或 config `{"read_cache_enabled": false}` 完全退出。在建立信心之后,可升级到 `TOKEN_OPTIMIZER_READ_CACHE_MODE=block`。
### Git 感知上下文
分析你的工作树,以建议应该包含在上下文中的文件:测试伴生文件、最近 50 次提交中频繁共同更改的文件,以及 Python/JS/TS 的导入链。
```
python3 measure.py git-context # Suggest files for current changes
python3 measure.py git-context --json # Machine-readable output
```
### .contextignore
使用 gitignore 风格的模式阻止文件被读取。支持项目根目录的 `.contextignore` 和全局 `~/.claude/.contextignore`。无论 read-cache 模式如何,都进行硬阻止。这是由 Token Optimizer 提供的,而不是 Claude Code 的内置功能。
```
# Block build artifacts 和 lockfiles
dist/**
node_modules/**
package-lock.json
yarn.lock
*.min.js
*.min.css
```
### Attention Optimizer
根据 U 型注意力曲线对 CLAUDE.md 进行评分。标记位于低注意力区域(30-70% 位置)的关键规则(NEVER/ALWAYS/MUST)。生成一个将关键规则移动到高注意力区域的重排版本。
```
python3 measure.py attention-score # Score CLAUDE.md attention placement
python3 measure.py attention-optimize --dry-run # Preview optimized section order
```
### JSONL 工具包
用于会话 JSONL 文件的三个实用程序:`jsonl-inspect`(统计信息、记录计数、最大记录)、`jsonl-trim`(用占位符替换大型工具结果)、`jsonl-dedup`(检测并删除重复的系统提醒)。全部使用流式 I/O 和原子写入。
```
python3 measure.py jsonl-inspect # Stats on current session JSONL
python3 measure.py jsonl-trim --dry-run # Preview trimming large tool results
python3 measure.py jsonl-dedup --dry-run # Preview removing duplicate reminders
```
### 节省追踪
追踪来自设置优化、检查点恢复和工具归档的累计节省金额。同时显示在仪表盘的节省磁贴上,以便你可以观察数字在几周内的攀升。
```
python3 measure.py savings # Dollar savings report (last 30 days)
```
## 使用分析
**趋势**:你实际调用了哪些技能与仅仅安装了它们?你正在使用哪些模型?你的开销随着时间的推移发生了怎样的变化?
**会话健康度**:在过期会话(24 小时以上)、僵尸会话(48 小时以上)和过时配置引发问题之前将其捕获。
```
python3 measure.py setup-hook # Enable session tracking (one-time)
python3 measure.py trends # Usage patterns over time
python3 measure.py health # Session hygiene check
python3 measure.py plugin-cleanup # Detect duplicate skills and archive local/plugin overlaps
```
## VS Code 用户
在 VS Code 扩展程序中使用 Claude Code?Token Optimizer 的大部分功能都可以同样运行:
| 功能 | CLI | VS Code 扩展 |
|---------|-----|-------------------|
| Smart Compaction(检查点 + 恢复) | 可用 | 可用 |
| 质量追踪 + 会话数据 | 可用 | 可用 |
| 所有 hook(SessionEnd、PreCompact 等) | 可用 | 可用 |
| 仪表盘 (localhost:24842/token-optimizer) | 可用 | 可用 |
| 状态栏(终端中的质量条) | 可用 | 不可用 |
**状态栏仅限 CLI。**VS Code 扩展不支持 Claude Code 的 `statusLine` 设置。这是 Claude Code 的限制,而不是 Token Optimizer 的限制。
**VS Code 的最佳选择:**
- **仪表盘**:将 `http://localhost:24842/token-optimizer` 添加为书签,以获取始终最新的分析数据。运行 `python3 measure.py setup-daemon` 以启用每次会话后的自动刷新。
- **集成终端**:在 VS Code 的内置终端中运行 `claude`,以获得完整的 CLI 体验,包括质量条。
- **VS Code 扩展**:已在路线图上。[关注 #3](https://github.com/alexgreensh/token-optimizer/issues/3) 以获取更新。
## 其他平台
### OpenClaw
原生 TypeScript 插件,提供会话审计、10 个浪费检测器、指导模式、Smart Compaction 以及为 OpenClaw 架构适配的交互式仪表盘。适用于任何模型(Claude、GPT-5、Gemini、DeepSeek、通过 Ollama 运行的本地模型)。安装说明请见[上方的安装部分](#openclaw)。完整文档:[`openclaw/README.md`](openclaw/README.md)。
### Codex(测试版)
适用于 OpenAI Codex(CLI 和桌面版)的 Python 适配器。相同的核心引擎,针对 AGENTS.md、GPT-5.x 模型、智能级别和 Codex 的 hook 接口进行了适配。安装说明请见[上方的安装部分](#codex-beta)。包含完整功能对比表、hook 配置文件和模型定价的完整文档:[`docs/codex-beta.md`](docs/codex-beta.md)。
## 许可证
**PolyForm Noncommercial 1.0.0**。源码可见。个人、研究、教育及非商业用途无需购买许可证。
_本常见问题解答仅供信息参考,不构成对许可条款的修改。最后更新:2026 年 4 月。_
### 🧑💻 个人 / 爱好 / 研究 / 教育?
放马使用吧。完整源码,本地运行,无需购买许可证。这正是我们的初衷。
### 🏢 小型团队(5 人以下或月收入低于 2 万美元)?
小型团队会自动获得免费商业许可证。直接使用即可。
如果你想[赞助这个项目](https://github.com/sponsors/alexgreensh)或请我喝杯咖啡,不作强求,但总是心存感激 ☕
### 🔄 从个人用途开始,现在逐渐演变为商业用途?
你过去的使用完全没问题。该许可证在任何书面通知后内置了 32 天的宽限期,因此有充足的缓冲时间。
当你准备好了,只需联系我们获取商业许可证即可。条款合理且与你团队的规模相称。
### 🏗️ 大公司 / 商业用途?
让我们谈谈。请联系 [Alex Greenshpun](https://linkedin.com/in/alexgreensh) 或 me@alexgreenshpun.com。
由 [Alex Greenshpun](https://linkedin.com/in/alexgreensh) 创建。标签:AI开发工具, AI辅助编程, Claude Code, Claude插件, Codex, DLL 劫持, DNS解析, LLM, OpenClaw, Prompt压缩, Python, Token优化, Unmanaged PE, 上下文压缩, 上下文管理, 上下文质量, 代码助手, 多模态安全, 大语言模型, 幽灵Token, 开源项目, 提示词工程, 无后门, 策略决策点, 逆向工具, 零依赖