amruth-sn/kong
GitHub: amruth-sn/kong
基于 Ghidra 和 LLM 的智能二进制逆向工程工具,自动恢复去符号表二进制文件的函数名、类型和调用约定。
Stars: 700 | Forks: 93
# Kong:代理式逆向工程师


 **用于二进制文件逆向工程的 LLM 编排**
**用于二进制文件逆向工程的 LLM 编排**
## Kong 是什么?
大多数任务遵循线性关系:任务越困难,通常花费的时间越长。逆向工程(以及二进制分析)是一项实际难度有些微不足道,但执行时间可能长达数小时(甚至数天!)的任务,即使对于只有几百个函数的二进制文件也是如此。
Kong 使用 NSA 级别的逆向工程框架自动化了机械层。Kong 可以接收一个完全混淆、去除了符号表的二进制文件,并运行完整的分析流水线:对函数进行分类,构建调用图上下文,通过 LLM 引导的反编译恢复类型和符号,并将结果写回 Ghidra 的程序数据库。输出是一个二进制文件,其中原来的 `FUN_00401a30` 现在变成了 `parse_http_header`,并恢复了结构体、参数名称和调用约定。
**为什么存在这个项目**
去除了符号表的二进制文件丢失了所有使代码可读的上下文:函数名、类型信息、变量名、结构体布局。恢复这些上下文是大多数逆向工程任务中的主要工作,而且主要是模式匹配:识别标准库函数,从用法推断类型,通过调用图传播名称。
LLM 恰好擅长这种模式匹配。但是,将 LLM 指向原始反编译器输出并询问“这是做什么的?”只能得到平庸的结果。模型缺乏调用上下文、交叉引用信息以及二进制文件结构的宏观图景。此外,大多数混淆的二进制文件引入了极端的技术来防止逆向工程。
Kong 通过在接触 LLM 之前从 Ghidra 的程序分析(调用图、交叉引用、字符串引用、数据流)构建丰富的上下文窗口来解决这个问题,然后按依赖顺序编排分析,以便每个函数都能从其被调用者已命名的结果中受益。此外,Kong 引入了其独有的、首创的代理式反混淆流水线。
## 实战演示
**用于二进制文件逆向工程的 LLM 编排** 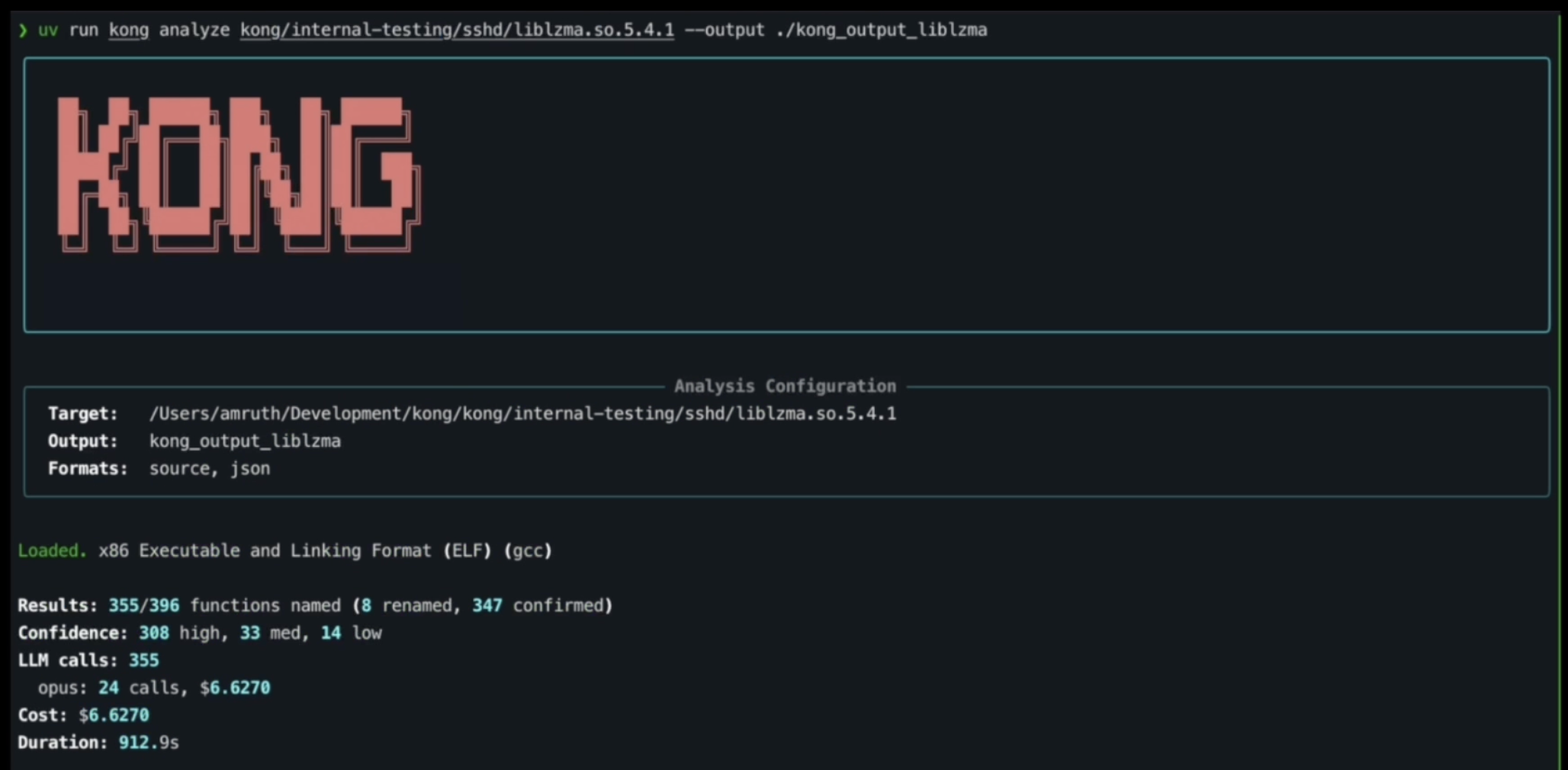
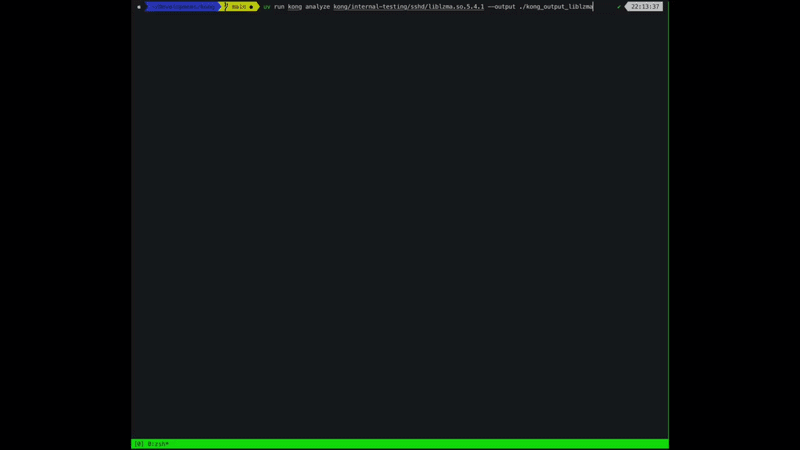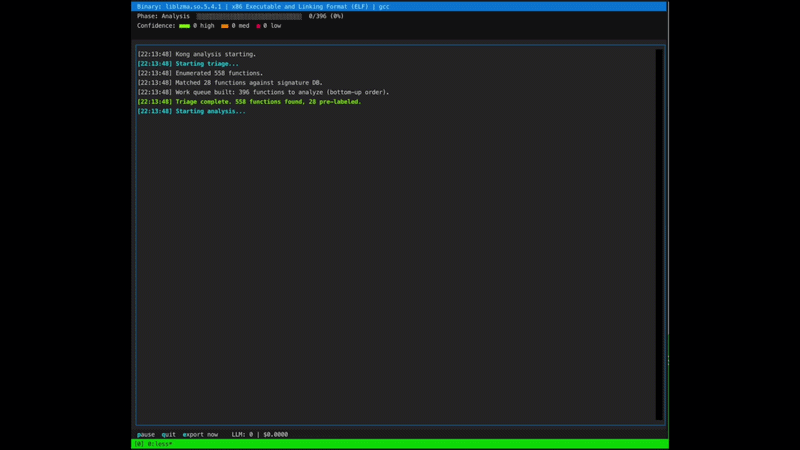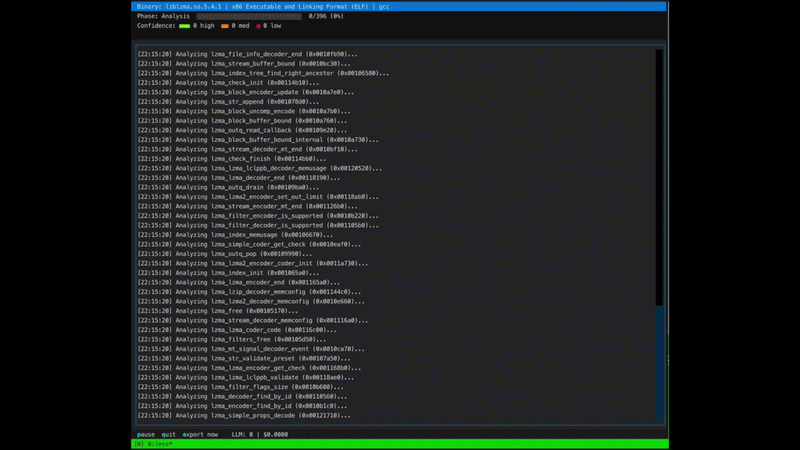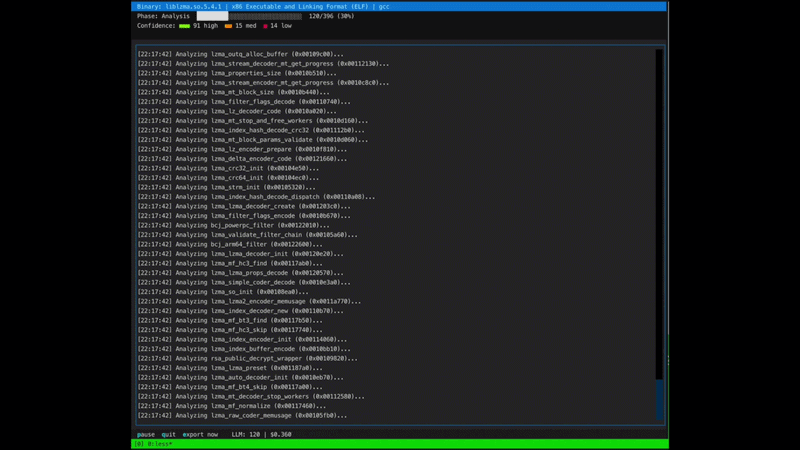 ## 功能特性
- **完全自主的流水线**:单个命令即可运行完整的分析。分类、函数分析、清理、语义合成和导出。无需人工干预。
- **进程内 Ghidra 集成**:通过 PyGhidra 和 JPype 在进程中运行 Ghidra 的分析引擎。无服务器、无 RPC、无子进程开销。直接访问程序数据库。
- **调用图顺序分析**:函数按调用图自下而上进行分析。叶子函数首先被命名,因此调用者可以在其反编译中受益于已解析的上下文。
- **丰富的上下文窗口**:每个 LLM 提示都包含目标函数的反编译结果以及交叉引用、字符串引用、调用者/被调用者签名和相邻数据;而不仅仅是孤立的原始反编译器输出。
- **语义合成**:一个后分析 pass,统一整个二进制文件的命名约定,从字段访问模式合成结构体定义,并解决独立分析的函数之间的不一致性。
- **签名匹配**:已知的标库和加密函数在 LLM 分析之前通过模式识别,跳过对已知身份函数的昂贵推理。
- **语法规范化**:反编译器输出在到达 LLM 之前经过清理(模运算恢复、负字面量重构、死赋值移除),减少噪音和 token 浪费。
- **代理式反混淆**:Kong 使用代理式反混淆流水线,可以从反编译器输出中识别并移除混淆技术(控制流平坦化、虚假控制流、指令替换、字符串加密、VM 保护等)。
- **评估框架**:内置评估工具,根据真实源代码对分析输出进行评分,测量符号准确性(基于词的 Jaccard)和类型准确性(签名组件评分)。
- **成本跟踪**:跟踪每次 LLM 调用的 token 使用量和成本,以及分析的总成本。
## 架构
Kong 使用由监督者协调分类、并行分析和后处理的五阶段流水线:
```
┌──────────────────────┐
│ Triage │
│ enumerate, classify,│
│ build call graph, │
│ match signatures │
└──────────┬───────────┘
│
▼
┌────────────────┼────────────────┐
│ │ │
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Analyze │ │ Analyze │ │ ... │
│ (leaf fns) │ │ (next tier) │ │ │
└──────┬───────┘ └──────┬───────┘ └──────┬───────┘
│ │ │
└────────┬───────┴────────────────┘
│
▼
┌──────────────────────┐
│ Cleanup │
│ normalize, dedupe │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Synthesis │
│ unify names, build │
│ structs, deobfuscate│
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Export │
│ analysis.json + │
│ Ghidra writeback │
└──────────────────────┘
```
### 工作原理
**分类 (Triage)** 枚举二进制文件中的所有函数,按大小(微小/小/中/大)对其进行分类,构建调用图,检测源语言,并针对已知的标库和加密函数运行签名匹配。通过签名匹配的函数被标记为已解析,并完全跳过 LLM 分析。
**分析 (Analysis)** 使用工作队列按调用图的自下而上顺序处理函数。对于每个函数,Kong 从 Ghidra 的程序数据库构建上下文窗口 —— 反编译、交叉引用、字符串引用和已分析的被调用者的签名 —— 规范化反编译器输出,并将其发送给 LLM 以恢复名称、类型和参数。如果在函数的反编译中检测到混淆,Kong 会在生成分析之前运行具有符号工具访问权限的代理式反混淆 pass。结果会立即写回 Ghidra,以便下游调用者看到更新的名称。
**清理 (Cleanup)** 统一分析期间累积的提案中的结构体类型,并重试在分析 pass 期间未能应用的任何函数签名。
**合成 (Synthesis)** 审视所有已分析函数的全局视图。单次 LLM 调用审查连接最紧密的函数,统一命名约定,从字段访问模式合成结构体定义,并优化在更广泛上下文中看起来不一致的名称。
**导出 (Export)** 编写最终的 `analysis.json`,并将所有恢复的名称、类型和签名应用回 Ghidra 程序数据库。
## 技术栈
- **运行时**:Python 3.11+,使用 [uv](https://github.com/astral-sh/uv) 管理
- **二进制分析**:通过 [PyGhidra](https://github.com/NationalSecurityAgency/ghidra/tree/master/Ghidra/Features/PyGhidra) 使用 [Ghidra](https://ghidra-sre.org/)(进程内,JPype)
- **LLM**:[Anthropic SDK](https://github.com/anthropics/anthropic-sdk-python) (Claude)
- **符号分析**:[z3-solver](https://github.com/Z3Prover/z3)
- **CLI**:[Click](https://click.palletsprojects.com/)
- **TUI**:[Textual](https://textual.textualize.io/)
- **显示**:[Rich](https://rich.readthedocs.io/)
- **构建**:[hatchling](https://hatch.pypa.io/)
- **测试**:[pytest](https://pytest.org/)
## 设置
### 前置条件
- **Python 3.11+** — ([python.org](https://www.python.org/downloads/) 或您的系统包管理器)
- **uv** — Python 包管理器 ([Install uv](https://docs.astral.sh/uv/getting-started/installation/))
- **Ghidra** — 美国国家安全局的逆向工程框架 ([Install Ghidra](https://ghidra-sre.org/InstallationGuide.html))
- **JDK 21+** — Ghidra 所需 ([Adoptium](https://adoptium.net/))
- **Anthropic API key** — 从 [Anthropic Console](https://console.anthropic.com) 获取
### 快速开始
```
# 克隆 Kong
git clone https://github.com/amruth-sn/kong.git
cd kong
# 安装依赖
uv sync
# 设置 API key
export ANTHROPIC_API_KEY="your-api-key"
# 分析 binary
uv run kong analyze ./path/to/stripped_binary
```
Kong 将自动检测您的 Ghidra 和 JDK 安装,将二进制文件加载到进程内的 Ghidra 实例中,并运行完整的流水线。
### 环境变量
| Variable | Required | Description |
|----------|----------|-------------|
| `ANTHROPIC_API_KEY` | 是 | 用于 LLM 分析的 Anthropic API key |
| `GHIDRA_INSTALL_DIR` | 否 | Ghidra 安装路径(如果未设置则自动检测)|
| `JAVA_HOME` | 否 | JDK 路径(如果未设置则自动检测)|
### 使用方法
```
# 分析 stripped binary(full pipeline)
uv run kong analyze ./binary
# 显示 binary 元数据而不运行分析
uv run kong info ./binary
# 根据 ground-truth source 评估分析输出
uv run kong eval ./analysis.json ./source.c
```
### 输出
结果将写入输出目录(默认:`./kong_output_{binary_name}/`):
```
kong_output_{binary_name}/
├── analysis.json # All recovered function names, types, parameters
└── events.log # Pipeline execution trace
```
## 项目布局
```
kong/
├── __main__.py # CLI entry point (click)
├── config.py # KongConfig, GhidraConfig, OutputConfig
├── agent/
│ ├── supervisor.py # Pipeline orchestrator
│ ├── triage.py # Function enumeration + classification
│ ├── analyzer.py # LLM-guided function analysis
│ ├── queue.py # BFS work queue from call graph
│ ├── signatures.py # Known function signature matching
│ ├── prompts.py # System prompt + output schema
│ ├── events.py # Phase/event types for pipeline tracing
│ └── models.py # FunctionResult dataclass
├── ghidra/
│ ├── client.py # In-process GhidraClient (PyGhidra/JPype)
│ ├── types.py # FunctionInfo, BinaryInfo, XRef, etc.
│ └── environment.py # Ghidra/JDK auto-detection
├── llm/
│ └── client.py # AnthropicClient, TokenUsage, cost tracking
├── normalizer/
│ └── syntactic.py # Decompiler output normalization
├── synthesis/
│ └── semantic.py # Global name unification + struct synthesis
├── evals/
│ ├── harness.py # Ground-truth extraction + scoring
│ └── metrics.py # symbol_accuracy, type_accuracy
├── export/
│ └── source.py # analysis.json + Ghidra writeback
├── signatures/
│ ├── stdlib.json # C standard library signatures
│ └── crypto.json # Cryptographic function signatures
└── tui/
└── app.py # Textual TUI
```
## 许可证
[APACHE](LICENSE)
Kong 根据 Apache License 2.0 授权。Kong 是一个免费的开源项目。
此许可证与 Ghidra 许可证兼容,并允许商业使用。
## 贡献
欢迎通过 [GitHub Issues](https://github.com/amruth-sn/kong/issues) 提出问题和功能请求。
此外,随时可以通过 [X](https://x.com/0xamruth) 或 [LinkedIn](https://www.linkedin.com/in/amruthn/) 联系我!
## 致谢
- [Ghidra](https://ghidra-sre.org/)
- [PyGhidra](https://github.com/NationalSecurityAgency/ghidra/tree/master/Ghidra/Features/PyGhidra)
- [JPype](https://github.com/jpype-project/jpype)
- [LLM](https://github.com/anthropics/anthropic-sdk-python)
- [Z3](https://github.com/Z3Prover/z3)
- [Textual](https://textual.textualize.io/)
- [Rich](https://rich.readthedocs.io/)
特别感谢 [KeygraphHQ](https://keygraph.io/) 的 [Shannon](https://github.com/KeygraphHQ/shannon) 项目,它为这个项目提供了灵感。我的动机是复制 Shannon 用于其基于 Web 的渗透测试工具的同类型流水线,并将其改编用于二进制分析和反编译。
敬畏猴子。
## 功能特性
- **完全自主的流水线**:单个命令即可运行完整的分析。分类、函数分析、清理、语义合成和导出。无需人工干预。
- **进程内 Ghidra 集成**:通过 PyGhidra 和 JPype 在进程中运行 Ghidra 的分析引擎。无服务器、无 RPC、无子进程开销。直接访问程序数据库。
- **调用图顺序分析**:函数按调用图自下而上进行分析。叶子函数首先被命名,因此调用者可以在其反编译中受益于已解析的上下文。
- **丰富的上下文窗口**:每个 LLM 提示都包含目标函数的反编译结果以及交叉引用、字符串引用、调用者/被调用者签名和相邻数据;而不仅仅是孤立的原始反编译器输出。
- **语义合成**:一个后分析 pass,统一整个二进制文件的命名约定,从字段访问模式合成结构体定义,并解决独立分析的函数之间的不一致性。
- **签名匹配**:已知的标库和加密函数在 LLM 分析之前通过模式识别,跳过对已知身份函数的昂贵推理。
- **语法规范化**:反编译器输出在到达 LLM 之前经过清理(模运算恢复、负字面量重构、死赋值移除),减少噪音和 token 浪费。
- **代理式反混淆**:Kong 使用代理式反混淆流水线,可以从反编译器输出中识别并移除混淆技术(控制流平坦化、虚假控制流、指令替换、字符串加密、VM 保护等)。
- **评估框架**:内置评估工具,根据真实源代码对分析输出进行评分,测量符号准确性(基于词的 Jaccard)和类型准确性(签名组件评分)。
- **成本跟踪**:跟踪每次 LLM 调用的 token 使用量和成本,以及分析的总成本。
## 架构
Kong 使用由监督者协调分类、并行分析和后处理的五阶段流水线:
```
┌──────────────────────┐
│ Triage │
│ enumerate, classify,│
│ build call graph, │
│ match signatures │
└──────────┬───────────┘
│
▼
┌────────────────┼────────────────┐
│ │ │
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Analyze │ │ Analyze │ │ ... │
│ (leaf fns) │ │ (next tier) │ │ │
└──────┬───────┘ └──────┬───────┘ └──────┬───────┘
│ │ │
└────────┬───────┴────────────────┘
│
▼
┌──────────────────────┐
│ Cleanup │
│ normalize, dedupe │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Synthesis │
│ unify names, build │
│ structs, deobfuscate│
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Export │
│ analysis.json + │
│ Ghidra writeback │
└──────────────────────┘
```
### 工作原理
**分类 (Triage)** 枚举二进制文件中的所有函数,按大小(微小/小/中/大)对其进行分类,构建调用图,检测源语言,并针对已知的标库和加密函数运行签名匹配。通过签名匹配的函数被标记为已解析,并完全跳过 LLM 分析。
**分析 (Analysis)** 使用工作队列按调用图的自下而上顺序处理函数。对于每个函数,Kong 从 Ghidra 的程序数据库构建上下文窗口 —— 反编译、交叉引用、字符串引用和已分析的被调用者的签名 —— 规范化反编译器输出,并将其发送给 LLM 以恢复名称、类型和参数。如果在函数的反编译中检测到混淆,Kong 会在生成分析之前运行具有符号工具访问权限的代理式反混淆 pass。结果会立即写回 Ghidra,以便下游调用者看到更新的名称。
**清理 (Cleanup)** 统一分析期间累积的提案中的结构体类型,并重试在分析 pass 期间未能应用的任何函数签名。
**合成 (Synthesis)** 审视所有已分析函数的全局视图。单次 LLM 调用审查连接最紧密的函数,统一命名约定,从字段访问模式合成结构体定义,并优化在更广泛上下文中看起来不一致的名称。
**导出 (Export)** 编写最终的 `analysis.json`,并将所有恢复的名称、类型和签名应用回 Ghidra 程序数据库。
## 技术栈
- **运行时**:Python 3.11+,使用 [uv](https://github.com/astral-sh/uv) 管理
- **二进制分析**:通过 [PyGhidra](https://github.com/NationalSecurityAgency/ghidra/tree/master/Ghidra/Features/PyGhidra) 使用 [Ghidra](https://ghidra-sre.org/)(进程内,JPype)
- **LLM**:[Anthropic SDK](https://github.com/anthropics/anthropic-sdk-python) (Claude)
- **符号分析**:[z3-solver](https://github.com/Z3Prover/z3)
- **CLI**:[Click](https://click.palletsprojects.com/)
- **TUI**:[Textual](https://textual.textualize.io/)
- **显示**:[Rich](https://rich.readthedocs.io/)
- **构建**:[hatchling](https://hatch.pypa.io/)
- **测试**:[pytest](https://pytest.org/)
## 设置
### 前置条件
- **Python 3.11+** — ([python.org](https://www.python.org/downloads/) 或您的系统包管理器)
- **uv** — Python 包管理器 ([Install uv](https://docs.astral.sh/uv/getting-started/installation/))
- **Ghidra** — 美国国家安全局的逆向工程框架 ([Install Ghidra](https://ghidra-sre.org/InstallationGuide.html))
- **JDK 21+** — Ghidra 所需 ([Adoptium](https://adoptium.net/))
- **Anthropic API key** — 从 [Anthropic Console](https://console.anthropic.com) 获取
### 快速开始
```
# 克隆 Kong
git clone https://github.com/amruth-sn/kong.git
cd kong
# 安装依赖
uv sync
# 设置 API key
export ANTHROPIC_API_KEY="your-api-key"
# 分析 binary
uv run kong analyze ./path/to/stripped_binary
```
Kong 将自动检测您的 Ghidra 和 JDK 安装,将二进制文件加载到进程内的 Ghidra 实例中,并运行完整的流水线。
### 环境变量
| Variable | Required | Description |
|----------|----------|-------------|
| `ANTHROPIC_API_KEY` | 是 | 用于 LLM 分析的 Anthropic API key |
| `GHIDRA_INSTALL_DIR` | 否 | Ghidra 安装路径(如果未设置则自动检测)|
| `JAVA_HOME` | 否 | JDK 路径(如果未设置则自动检测)|
### 使用方法
```
# 分析 stripped binary(full pipeline)
uv run kong analyze ./binary
# 显示 binary 元数据而不运行分析
uv run kong info ./binary
# 根据 ground-truth source 评估分析输出
uv run kong eval ./analysis.json ./source.c
```
### 输出
结果将写入输出目录(默认:`./kong_output_{binary_name}/`):
```
kong_output_{binary_name}/
├── analysis.json # All recovered function names, types, parameters
└── events.log # Pipeline execution trace
```
## 项目布局
```
kong/
├── __main__.py # CLI entry point (click)
├── config.py # KongConfig, GhidraConfig, OutputConfig
├── agent/
│ ├── supervisor.py # Pipeline orchestrator
│ ├── triage.py # Function enumeration + classification
│ ├── analyzer.py # LLM-guided function analysis
│ ├── queue.py # BFS work queue from call graph
│ ├── signatures.py # Known function signature matching
│ ├── prompts.py # System prompt + output schema
│ ├── events.py # Phase/event types for pipeline tracing
│ └── models.py # FunctionResult dataclass
├── ghidra/
│ ├── client.py # In-process GhidraClient (PyGhidra/JPype)
│ ├── types.py # FunctionInfo, BinaryInfo, XRef, etc.
│ └── environment.py # Ghidra/JDK auto-detection
├── llm/
│ └── client.py # AnthropicClient, TokenUsage, cost tracking
├── normalizer/
│ └── syntactic.py # Decompiler output normalization
├── synthesis/
│ └── semantic.py # Global name unification + struct synthesis
├── evals/
│ ├── harness.py # Ground-truth extraction + scoring
│ └── metrics.py # symbol_accuracy, type_accuracy
├── export/
│ └── source.py # analysis.json + Ghidra writeback
├── signatures/
│ ├── stdlib.json # C standard library signatures
│ └── crypto.json # Cryptographic function signatures
└── tui/
└── app.py # Textual TUI
```
## 许可证
[APACHE](LICENSE)
Kong 根据 Apache License 2.0 授权。Kong 是一个免费的开源项目。
此许可证与 Ghidra 许可证兼容,并允许商业使用。
## 贡献
欢迎通过 [GitHub Issues](https://github.com/amruth-sn/kong/issues) 提出问题和功能请求。
此外,随时可以通过 [X](https://x.com/0xamruth) 或 [LinkedIn](https://www.linkedin.com/in/amruthn/) 联系我!
## 致谢
- [Ghidra](https://ghidra-sre.org/)
- [PyGhidra](https://github.com/NationalSecurityAgency/ghidra/tree/master/Ghidra/Features/PyGhidra)
- [JPype](https://github.com/jpype-project/jpype)
- [LLM](https://github.com/anthropics/anthropic-sdk-python)
- [Z3](https://github.com/Z3Prover/z3)
- [Textual](https://textual.textualize.io/)
- [Rich](https://rich.readthedocs.io/)
特别感谢 [KeygraphHQ](https://keygraph.io/) 的 [Shannon](https://github.com/KeygraphHQ/shannon) 项目,它为这个项目提供了灵感。我的动机是复制 Shannon 用于其基于 Web 的渗透测试工具的同类型流水线,并将其改编用于二进制分析和反编译。
敬畏猴子。
![]()
Kong: The world's first AI reverse engineer
标签:Agent, DAST, DLL 劫持, Ghidra, LLM, Python, Unmanaged PE, 二进制分析, 二进制安全, 二进制还原, 云安全监控, 云安全运维, 云资产清单, 人工智能, 代码理解, 去混淆, 反混淆, 大语言模型, 恶意软件分析, 无后门, 用户模式Hook绕过, 符号恢复, 类型恢复, 网络安全, 网络调试, 自动化, 逆向工具, 逆向工程, 隐私保护, 静态分析, 静态逆向