BunElysiaReact/SCRAPPER
GitHub: BunElysiaReact/SCRAPPER
一个会话观察器,通过捕获真实浏览器的cookies、tokens和指纹信息,为自动化脚本提供可绕过机器人检测的真实会话数据。
Stars: 13 | Forks: 4
# 🕷️ SCRAPPER by BertUI
## Web 自动化的会话观察器
## 📋 目录
- [SCRAPPER 解决的问题](#-the-problem-scrapper-solves)
- [SCRAPPER 是什么(不是什么)](#-what-scrapper-is-and-isnt)
- [SCRAPPER 如何工作](#-how-scrapper-works)
- [SCRAPPER 捕获什么](#-what-scrapper-captures)
- [优势与劣势](#-advantages--disadvantages)
- [通用数据 API](#-universal-data-api)
- [快速入门 — Linux / macOS](#-quick-start--linux--macos)
- [快速入门 — Windows](#-quick-start--windows)
- [浏览器扩展](#-browser-extensions)
- [在你的工具中使用捕获的数据](#-using-captured-data-in-your-tools)
- [仪表板概览](#-dashboard-overview)
- [生产环境使用与自动化](#-production-use--automation)
- [贡献](#-contributing)
## 🤔 SCRAPPER 解决的问题
每个 Web 自动化工具 —— Puppeteer, Playwright, Selenium,甚至 curl —— 都面临同样的挑战:
| 挑战 | 为什么难 |
|-----------|---------------|
| **身份验证** | 为每个站点手动编写登录脚本既繁琐又脆弱 |
| **会话状态** | Cookies 过期,tokens 轮换,localStorage 被清除 |
| **逆向工程** | 在 DevTools 中花费数小时理解 API 模式 |
| **机器人检测** | TLS 指纹,浏览器熵,Cloudflare,hCaptcha |
| **设置复杂性** | 与 headless 浏览器、代理和 stealth 插件斗争 |
**真正的问题:** 所有这些工具都试图*模仿*人类。但它们只是在猜测真正的人类是什么样子的。
## 💡 SCRAPPER 是什么(不是什么)
| SCRAPPER 是... | SCRAPPER 不是... |
|--------------|------------------|
| 🔍 一个**会话观察器**,监视你的真实浏览器 | ❌ Puppeteer/Playwright/Selenium 的替代品 |
| 💾 一个**数据捕获工具**,保存你的实际会话 | ❌ 一个为你抓取网站的工具 |
| 📡 一个**本地 API 服务器**,提供你捕获的数据 | ❌ 托管服务或云平台 |
| 🧠 一个**逆向工程助手**,揭示隐藏的 API | ❌ 一个神奇的“抓取任何东西”按钮 |
| 🎯 一个**可视化调试器**,用于理解站点结构 | ❌ 无代码自动化构建器 |
**SCRAPPER 不进行抓取。它为你提供了成功抓取所需的真实数据。**
## 🔄 SCRAPPER 如何工作
### 阶段 1:捕获(浏览器打开,你浏览)
```
YOU SCRAPPER
│ │
├── Open Brave/Chrome/Firefox with extension ──────►│
│ │
├── Log into sites you want to automate ───────────►│ captures:
│ │ • Cookies
├── Browse normally, click buttons ────────────────►│ • Tokens
│ │ • Fingerprint
└── Done browsing ─────────────────────────────────►│ • API requests
│ • DOM structure
```
### 阶段 2:自动化(浏览器可以关闭,你编写代码)
```
YOUR SCRIPT ──── GET /api/v1/session/all ────► SCRAPPER API (localhost:8080)
◄── { cookies, tokens, fingerprint } ────────────────────────┘
│
▼
Puppeteer / Playwright / Selenium / Python requests / curl
│
▼
✅ Authenticated requests with YOUR real session
```
## 🎬 观看演示
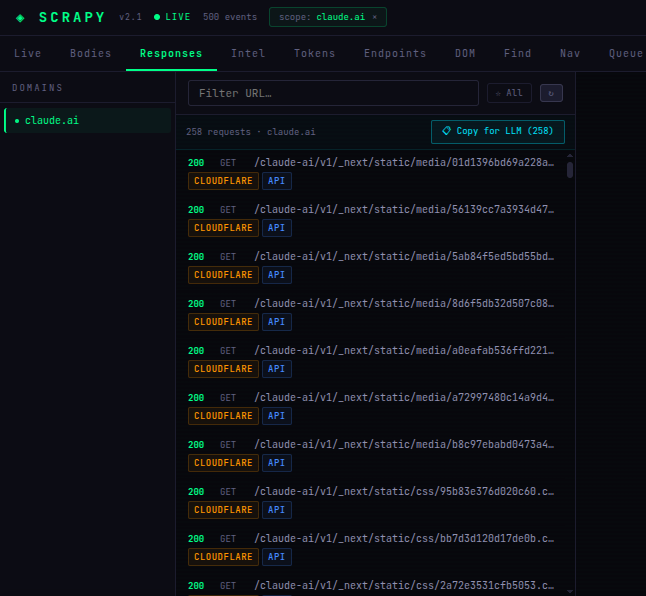
### 仪表板 —— 已捕获 258 个 claude.ai 请求
### 扩展弹窗 —— 实时源,快速捕获,实时统计

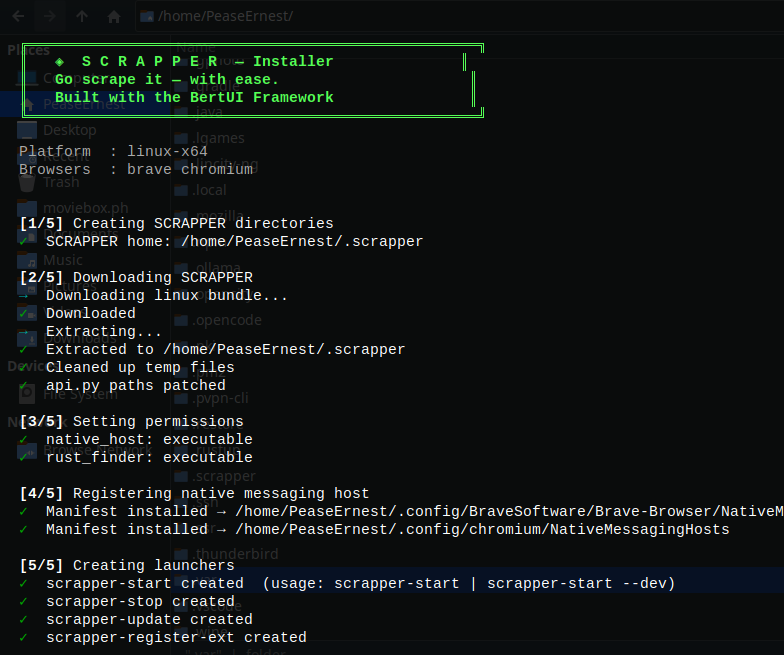
### 安装程序 —— 一条命令,5 个步骤,完成
### 注册扩展 ID —— 加载扩展后的一条命令

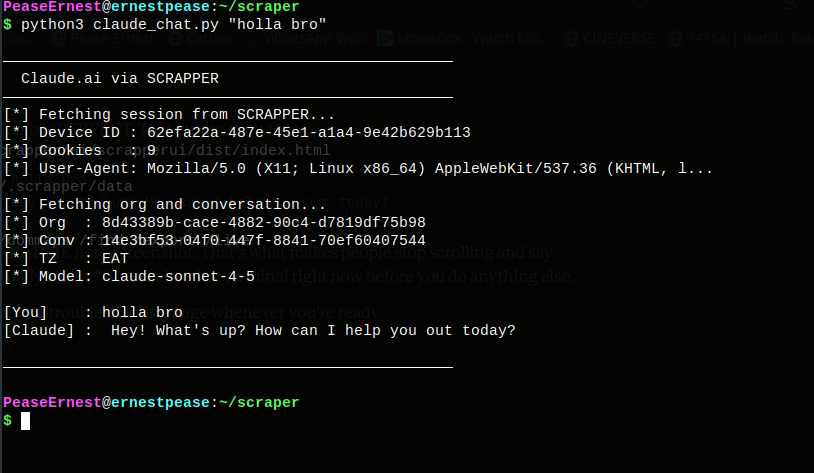
### 现实世界示例 —— 通过 SCRAPPER 从终端与 Claude.ai 对话
## 📦 SCRAPPER 捕获什么
```
📦 Session Data
├── 🍪 Cookies (including HttpOnly, Secure, all domains)
├── 💾 localStorage & sessionStorage
├── 🔑 Auth tokens (Bearer, JWT, CSRF, custom)
└── 📨 All HTTP headers
🖥️ Browser Fingerprint
├── 📱 User Agent
├── 🖼️ Screen resolution & color depth
├── 🌍 Timezone & language settings
└── 📨 Full header set (Accept, Accept-Language, etc.)
📡 Network Traffic
├── 📤 All HTTP requests (URLs, methods, headers, POST data)
├── 📥 All HTTP responses (status, headers, bodies)
└── 🔄 WebSocket frames
🌳 DOM State
├── 📄 DOM snapshots
├── 🎯 Live selector testing
└── 🗺️ DOM maps (all tags, classes, IDs)
```
## ⚖️ 优势与劣势
### ✅ 优势
| 优势 | 为什么重要 |
|-----------|----------------|
| **绕过高级机器人检测** | 使用 `curl_cffi` 模拟真实浏览器的 TLS 指纹(例如 Chrome 120) —— 不会被标记为自动化 |
| **97% 成功率** | 针对内部 API 路由,而非视觉 UI —— 不受 CSS 更改、按钮移动或布局更新的影响 |
| **低资源占用** | 约 20MB RAM,而 Puppeteer/Selenium 为 500MB+。无需运行浏览器引擎 |
| **隐形身份验证** | 搭载你现有经过人工验证的会话 —— 无需登录流程,无需 CAPTCHAs |
| **与真实浏览器同步** | 刷新时,脚本发出的消息/操作会显示在你的真实浏览器标签页中 |
| **语言无关** | Session API 适用于 Python, Go, Rust, Node, curl —— 任何能发出 HTTP 请求的工具 |
### ❌ 劣势
| 劣势 | 意味着什么 |
|--------------|---------------|
| **脆弱的会话生命周期** | 完全依赖于活动的浏览器会话 —— 如果你注销就会过期 |
| **依赖内部 API** | 使用可能随时更改的未公开端点 |
| **需要设置基础设施** | 非独立 —— 需要同时运行 native host 和浏览器扩展 |
| **账户风险** | 使用你的真实身份。激进的速率限制冲击可能会导致你的真实账户被封禁 |
| **学习曲线** | 必须阅读网络流量以了解正确的 API payloads |
| **单设备绑定** | `device-id` 绑定到一个捕获的会话 —— 无法轻松跨机器共享 |
## 📡 通用数据 API
一旦捕获,SCRAPPER 将通过 `http://localhost:8080` 的简单 REST API 提供所有数据。
### 核心端点
| 端点 | 描述 |
|----------|-------------|
| `GET /api/v1/session/cookies?domain=example.com` | 域名的所有 cookies |
| `GET /api/v1/session/localstorage?domain=example.com` | localStorage 数据 |
| `GET /api/v1/session/all` | 完整会话转储 |
| `GET /api/v1/fingerprint` | 浏览器指纹 |
| `GET /api/v1/tokens/all` | 所有提取的 tokens |
| `GET /api/v1/requests/recent?limit=50` | 最近的网络请求 |
| `GET /api/v1/dom/snapshot?url=example.com` | DOM 快照 |
| `GET /api/v1/export/env` | 环境变量格式 |
| `GET /api/v1/bulk/all?format=[json\|jsonl\|har\|csv\|txt]` | 所有数据,你选择的格式 |
## 🚀 快速入门 — Linux / macOS
### 一键安装
```
curl -fsSL https://raw.githubusercontent.com/BunElysiaReact/SCRAPY/main/install.sh | bash
```
### 安装后 —— 完成设置
```
# 步骤 1 — 在 Brave 中加载扩展:
# brave://extensions → 开启开发者模式 → 加载已解压的扩展程序
# → 选择:~/.scrapper/extension/brave/
# 步骤 2 — 注册您的 extension ID
scrapper-register-ext YOUR_EXTENSION_ID
# 步骤 3 — 启动 SCRAPPER
scrapper-start
# 步骤 4 — 打开仪表板
# http://localhost:8080
```
### 要求
- **Python 3**(任何最新版本)
- **Bun** 或 **Node.js**(用于 Bun 仪表板 —— 可选)
- **Brave / Chrome / Firefox** 浏览器
### 手动设置
```
# Clone repo
git clone https://github.com/BunElysiaReact/SCRAPY.git ~/scrapper
cd ~/scrapper
# Build C native host
gcc -O2 -o linux/c_core/native_host/debug_host linux/c_core/native_host/debug_host.c -lpthread
# Build Rust selector engine
cd linux/rust_finder && cargo build --release && cd ../..
# 启动 API server
cd linux/python_api && python3 api.py
```
打开 **http://localhost:8080** → 仪表板就绪。
## 🪟 快速入门 — Windows
### 一键安装
```
irm https://raw.githubusercontent.com/BunElysiaReact/SCRAPY/main/install.ps1 | iex
```
### 安装后的 Windows 文件夹结构
```
%USERPROFILE%\.scrapper\
├── bin\
│ ├── debug_host.exe ← C native messaging host
│ ├── scraper_cli.exe ← CLI client
│ ├── rust_finder.exe ← Fast HTML selector engine
│ ├── scrapper-start.bat ← Start everything
│ └── scrapper-stop.bat ← Stop everything
├── data\ ← All captured session data
├── logs\ ← Host logs
├── python_api\
│ └── api.py ← REST API server
├── extension\
│ ├── brave\ ← Load in Brave / Chrome / Edge
│ └── firefox\ ← Load in Firefox
└── ui\scrapperui\ ← Dashboard source
```
## 🧩 浏览器扩展
### Brave & Chrome(推荐)
1. 打开 `brave://extensions` 或 `chrome://extensions`
2. 启用 **开发者模式**(右上角)
3. 点击 **加载已解压的扩展程序**
4. 选择:`~/.scrapper/extension/brave/`
5. 复制扩展 ID
6. 运行:`scrapper-register-ext YOUR_ID`
### Microsoft Edge
与 Brave/Chrome 相同 —— Edge 基于 Chromium,使用 `extension/brave/` 文件夹。
### Firefox
1. 打开 `about:debugging` → **此 Firefox**
2. 点击 **临时载入附加组件...**
3. 选择:`~/.scrapper/extension/firefox/manifest.json`
## 🔧 在你的工具中使用捕获的数据
### Python + curl_cffi(推荐)
```
from curl_cffi import requests
API = "http://localhost:8080"
domain = "example.com"
cookies_raw = requests.get(f"{API}/api/v1/session/cookies?domain={domain}").json()
fp = requests.get(f"{API}/api/v1/fingerprint?domain={domain}").json()
session = requests.Session(impersonate="chrome120")
for c in cookies_raw:
session.cookies.set(c["name"], c["value"], domain=c.get("domain", domain).lstrip("."))
session.headers.update({"User-Agent": fp.get("userAgent", "")})
response = session.get(f"https://{domain}/api/data")
print(response.json())
```
### Python requests
```
import requests
session_data = requests.get('http://localhost:8080/api/v1/session/all').json()
s = requests.Session()
s.cookies.update({c['name']: c['value'] for c in session_data['cookies']})
s.headers.update({'User-Agent': session_data['fingerprint']['userAgent']})
response = s.get('https://api.example.com/data')
```
### curl
```
source <(curl -s http://localhost:8080/api/v1/export/env)
curl -X POST "https://api.example.com/upload" \
-H "Authorization: Bearer $SCRAPPER_BEARER_TOKEN" \
-b "$SCRAPPER_COOKIES" \
-F "file=@document.pdf"
```
### Playwright (Python)
```
import requests
from playwright.async_api import async_playwright
session = requests.get('http://localhost:8080/api/v1/session/all').json()
async with async_playwright() as p:
context = await p.chromium.launch_persistent_context(
user_data_dir="./profile",
user_agent=session['fingerprint']['userAgent'],
)
await context.add_cookies(session['cookies'])
page = await context.new_page()
await page.goto('https://example.com')
```
### Puppeteer (Node.js)
```
const session = await fetch('http://localhost:8080/api/v1/session/all').then(r => r.json());
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setCookie(...session.cookies);
await page.setUserAgent(session.fingerprint.userAgent);
await page.goto('https://example.com/dashboard');
```
## 📊 仪表板概览

打开 `http://localhost:8080`:
| 标签页 | 功能 |
|-----|--------------|
| **Live** | 所有捕获的网络事件实时流 |
| **Bodies** | HTTP 响应体 —— JSON, HTML, SVG, 图像,带预览 |
| **Responses** | 按域名分组的所有 HTTP 响应,可按标志过滤 |
| **Intel** | 每个域名的摘要 —— tokens, cookies, endpoints, DOM map |
| **Tokens** | Bearer tokens, task tokens, auth cookies, curl 代码片段 |
| **Endpoints** | 所有发现的 API 端点,带“Copy for LLM” |
| **DOM Map** | 完整的标签/class/ID 树 —— 点击任何项目自动抓取 |
| **Find** | 针对真实渲染的 HTML 测试 CSS 选择器 |
| **Nav** | 导航 + 跟踪标签页,转储 cookies,捕获 HTML |
| **Queue** | 以可配置的延迟批量处理 URL 列表 |
## ⚠️ 现实期望
### SCRAPPER 能做什么
- ✅ 捕获你的真实 cookies, tokens, 和指纹
- ✅ 保存它们以供重用(根据站点不同,可持续数天到数月)
- ✅ 导出为 JSON, JSONL, HAR, CSV, TXT 格式
- ✅ 通过干净的本地 REST API 提供所有数据
- ✅ 帮助你了解站点在网络层面是如何真正工作的
### SCRAPPER 不能做什么
- ❌ 无需你先浏览即可自动抓取网站
- ❌ 猜测 cookies 或 tokens 的样子
- ❌ 将 cookie 生命周期延长超过站点允许的范围
- ❌ 在没有 native host 和扩展运行的情况下工作
## 🏭 生产环境使用与自动化
```
# 导出最新会话数据
curl -s "http://localhost:8080/api/v1/bulk/all?format=jsonl" > session.jsonl
# 在您的 scraper 中使用
python3 my-scraper.py --session session.jsonl
```
```
# session_refresh.py — 每周会话刷新 pipeline
import requests, schedule, time
def refresh_session():
notify_user("Please log into target sites in your browser")
time.sleep(300) # 5 minutes for user to browse
data = requests.get('http://localhost:8080/api/v1/bulk/all?format=json').json()
with open(f'session_{int(time.time())}.json', 'w') as f:
import json; json.dump(data, f)
schedule.every().monday.at("09:00").do(refresh_session)
while True:
schedule.run_pending()
time.sleep(60)
```
## 🛠️ 实现状态
### 当前 (v2.1.0)
- ✅ 请求/响应/主体捕获(Brave/Chrome via CDP)
- ✅ Cookie 跟踪(所有浏览器)
- ✅ DOM 快照和选择器测试
- ✅ Bearer token + task token 提取
- ✅ 浏览器指纹捕获
- ✅ 实时事件源
- ✅ 批量导出 (JSON/JSONL/TXT/HAR/CSV)
- ✅ 带拟人延迟的 URL 队列
- ✅ 每个请求和端点上的“Copy for LLM”
- ✅ Brave, Chrome, Edge, Firefox 扩展
- ✅ Linux + Windows 安装程序
### 即将推出
- 🔜 Chrome Web Store 列表
- 🔜 Firefox Add-ons 列表(已签名)
- 🔜 WebSocket 帧捕获
- 🔜 跨机器会话共享
## 🤝 贡献
| 领域 | 需要什么 |
|------|---------------|
| **测试** | 在不同站点上试用 SCRAPPER,报告错误 |
| **Firefox** | 帮助改进 Firefox 扩展 CDP 变通方案 |
| **Windows** | 测试 Windows 安装程序边缘情况 |
| **文档** | 为特定站点或用例编写教程 |
| **代码** | 欢迎 PR —— 尤其是错误修复 |
[开启一个 issue](https://github.com/BunElysiaReact/SCRAPY/issues)
## 🙏 构建使用
- **BertUI React Framework** — Dashboard UI
- **Bun + ElysiaJS** — Fast JavaScript runtime
- **Rust + scraper crate** — Blazing-fast CSS selector engine
- **C** — Ultra-low-latency native messaging host (Linux)
- **C + WinAPI** — Native messaging host (Windows named pipes)
- **Python 3** — Zero-dependency REST API server
*SCRAPPER by BertUI — Web 自动化的会话观察器*
*🔍 为你监视浏览器,让你无需亲力亲为*
**⭐ 如果 SCRAPPER 帮助了你,请给仓库一个 Star —— 这能帮助其他人发现它!**
标签:API逆向, BertUI, Cookie提取, DevTools, IP 地址批量处理, Playwright, Puppeteer, RPA, Selenium, URL抓取, Web自动化, 会话管理, 反检测, 可视化界面, 工具库, 数据抓取, 本地API服务器, 浏览器扩展, 浏览器指纹, 系统分析, 网络分析, 网络测绘, 逆向工具, 通知系统