AmirhosseinHonardoust/Underwriting-Decision-Safety-Lab
GitHub: AmirhosseinHonardoust/Underwriting-Decision-Safety-Lab
一个用于贷款审批的决策安全实验室,通过校准概率和优化阈值来制定可辩护的自动化决策策略。
Stars: 12 | Forks: 0
# 承保决策安全实验室
**校准 + 拒绝 + 决策安全的策略界面,用于贷款审批。**
将模型分数转换为**可辩护的行动**:*自动批准 / 自动拒绝 / 转交人工审核*。






## 为何存在此代码库
大多数机器学习项目止步于**“AUC 是这些”**。但承保业务不行。
在贷款领域,只有当预测能转化为带有以下特点的*决策策略*时,它才是有用的:
- **校准的概率**(一个“0.90 批准”在类似条件下应意味着约 90% 的批准正确率)
- **拒绝选项**(为不确定案例提供*审核*路径)
- **覆盖率权衡**(在保证质量的前提下,可以安全地自动决策多少案例)
- **决策安全的用户界面**(让用户看到置信度以及触发该结果的原因)
本实验室实现了一个完整的端到端工作流:
1. 训练一个基线贷款审批模型
2. 校准预测概率
3. 构建**覆盖率前沿**(阈值 ↔ 自动决策率 ↔ 质量)
4. 推荐一个**可辩护的阈值策略**
5. 提供一个用于**分诊**和**报告**的交互式 Streamlit 应用程序
## 您将获得
### 流程输出
- `outputs/metrics_overall.json` | 测试集上的模型指标(准确率、F1、ROC-AUC、ECE、Brier 分数等)
- `outputs/abstention_policy.json` | 推荐的阈值 + 预期覆盖率 + 预期“自动”质量
- `outputs/test_predictions.csv` | 逐行的概率 + 标签(供分诊 UI 使用)
- `outputs/coverage_curve.csv` | 阈值扫描结果(覆盖率 vs 性能)
### 图表
放置在 `reports/figures/` 目录中:
- 混淆矩阵(基线阈值)
- 覆盖率 vs 性能(拒绝权衡)
- 概率直方图(分离度 + 置信度)
- 可靠性图(校准)
### Streamlit 仪表板
包含以下标签页:
- **报告卡**
- **覆盖率曲线**
- **分诊 UI**
- **数据质量**
- **备注**
## 数据集
本实验室使用 Kaggle 的 **贷款审批数据集** (`loanapproval.csv`)。
关键列(如“数据质量”标签页所示):
- `applicant_id`(唯一标识符)
- `age`(数值型)
- `gender`(分类型)
- `marital_status`(分类型)
- `annual_income`(数值型)
- `loan_amount`(数值型)
- `credit_score`(数值型)
- `num_dependents`(数值型)
- `existing_loans_count`(数值型)
- `employment_status`(分类型)
- `loan_approved`(目标变量,0/1)
### 快速合理性检查(“数据质量”屏幕所示内容)
- **行数:** 1000
- **列数:** 11
- **缺失值:** 在此数据集快照中,所有列均为 0
- **目标平衡:** 批准案例占多数(这是经过整理的演示数据集的典型情况)
## 项目结构
```
underwriting-decision-safety-lab/
├─ app/
│ └─ app.py # Streamlit dashboard
├─ data/
│ └─ raw/
│ └─ loanapproval.csv
├─ outputs/ # generated JSON/CSV artifacts
├─ reports/
│ └─ figures/ # generated PNG charts
└─ src/
├─ pipeline.py # main pipeline entrypoint
├─ clean.py # cleaning + schema normalization
├─ train.py # model training
├─ calibrate.py # sigmoid/isotonic calibration
├─ abstention.py # threshold sweep + policy recommendation
├─ metrics.py # ECE/Brier/etc
└─ plots.py # figure generation
```
## 如何运行
### 1) 创建环境
```
python -m venv .venv
# Windows:
.venv\Scripts\activate
# macOS/Linux:
source .venv/bin/activate
pip install -r requirements.txt
```
### 2) 运行流程(生成输出 + 图表)
```
python -m src.pipeline --input data/raw/loanapproval.csv
```
您应该会看到类似这样的信息:
* 完成!
* 输出: `outputs/`
* 图表: `reports/figures/`
### 3) 启动 Streamlit 应用
```
streamlit run app/app.py
```
## 仪表板导览(界面 + “如何解读”)
以下是您分享的仪表板界面。每个部分解释:
* 该界面回答什么问题
* 如何解读结果
* 接下来您可以采取什么行动
# 1) 报告卡标签页
**目标:** 回答“模型是否*足够好*以考虑自动决策?以及安全的默认策略是什么?”
### 您将看到
* 顶级测试指标:**准确率、F1、ROC-AUC、ECE、Brier 分数**
* 一个**推荐的拒绝策略**(阈值和预期覆盖率)
* 一个 2×2 的图表网格:
* 混淆矩阵
* 可靠性图
* 覆盖率 vs 性能
* 概率直方图
 ## 指标解释(附承保含义)
### 准确率
“整体上,我们预测正确的频率是多少?”
**为何它不足:** 一个模型可能很准确,但其置信度可能危险地不准确。
### F1 分数
平衡精确率和召回率(当存在类别不平衡时尤其有用)。
**承保解读:** 帮助您避免“批准一切”或“拒绝一切”的行为。
### ROC-AUC
排序质量:“被批准的案例是否通常比被拒绝的案例得分更高?”
**承保解读:** 高 AUC 有帮助,但它不能保证阈值决策的良好表现。
### ECE(期望校准误差)
衡量置信度在不同概率区间内与实际情况的偏差程度。
* 如果模型对某个案例给出约 0.8 的批准概率,那么在类似条件下,大约 80 个这样的案例中应该有约 80 个被实际批准。
* 高 ECE 意味着在未校准的情况下,概率是不可信的。
### Brier 分数
概率预测的均方误差。
* 越低越好。
* 对自信的错误预测惩罚很重。
# 2) 混淆矩阵图
## 指标解释(附承保含义)
### 准确率
“整体上,我们预测正确的频率是多少?”
**为何它不足:** 一个模型可能很准确,但其置信度可能危险地不准确。
### F1 分数
平衡精确率和召回率(当存在类别不平衡时尤其有用)。
**承保解读:** 帮助您避免“批准一切”或“拒绝一切”的行为。
### ROC-AUC
排序质量:“被批准的案例是否通常比被拒绝的案例得分更高?”
**承保解读:** 高 AUC 有帮助,但它不能保证阈值决策的良好表现。
### ECE(期望校准误差)
衡量置信度在不同概率区间内与实际情况的偏差程度。
* 如果模型对某个案例给出约 0.8 的批准概率,那么在类似条件下,大约 80 个这样的案例中应该有约 80 个被实际批准。
* 高 ECE 意味着在未校准的情况下,概率是不可信的。
### Brier 分数
概率预测的均方误差。
* 越低越好。
* 对自信的错误预测惩罚很重。
# 2) 混淆矩阵图
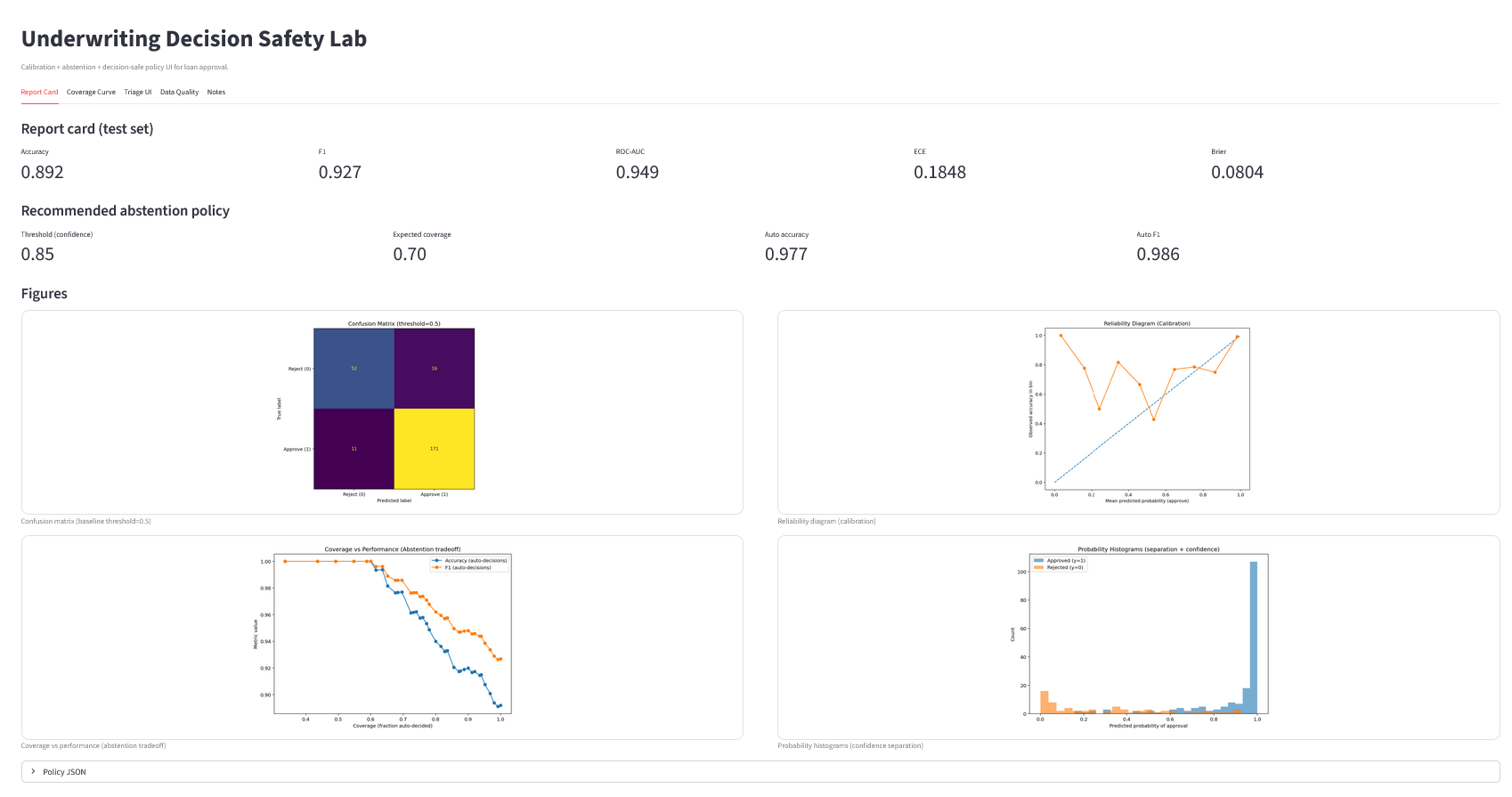
 ### 它回答什么问题
“在基线阈值(通常是 0.5)下,我们正在犯哪类错误?”
### 如何解读
* 行 = 真实标签
* 列 = 预测标签
* 对角线 = 正确预测
* 非对角线 = 错误:
* **错误批准**(预测批准但实际拒绝),风险/信用损失
* **错误拒绝**(预测拒绝但实际批准),机会成本/客户摩擦
### 为何它只是起点
承保通常*不是*在单一的固定阈值下运行。
本代码库的目的在于从“0.5 分类器”转向**策略**:
* 保守的自动批准
* 保守的自动拒绝
* 其他所有案例 → 转交审核
# 3) 可靠性图(校准)
### 它回答什么问题
“在基线阈值(通常是 0.5)下,我们正在犯哪类错误?”
### 如何解读
* 行 = 真实标签
* 列 = 预测标签
* 对角线 = 正确预测
* 非对角线 = 错误:
* **错误批准**(预测批准但实际拒绝),风险/信用损失
* **错误拒绝**(预测拒绝但实际批准),机会成本/客户摩擦
### 为何它只是起点
承保通常*不是*在单一的固定阈值下运行。
本代码库的目的在于从“0.5 分类器”转向**策略**:
* 保守的自动批准
* 保守的自动拒绝
* 其他所有案例 → 转交审核
# 3) 可靠性图(校准)
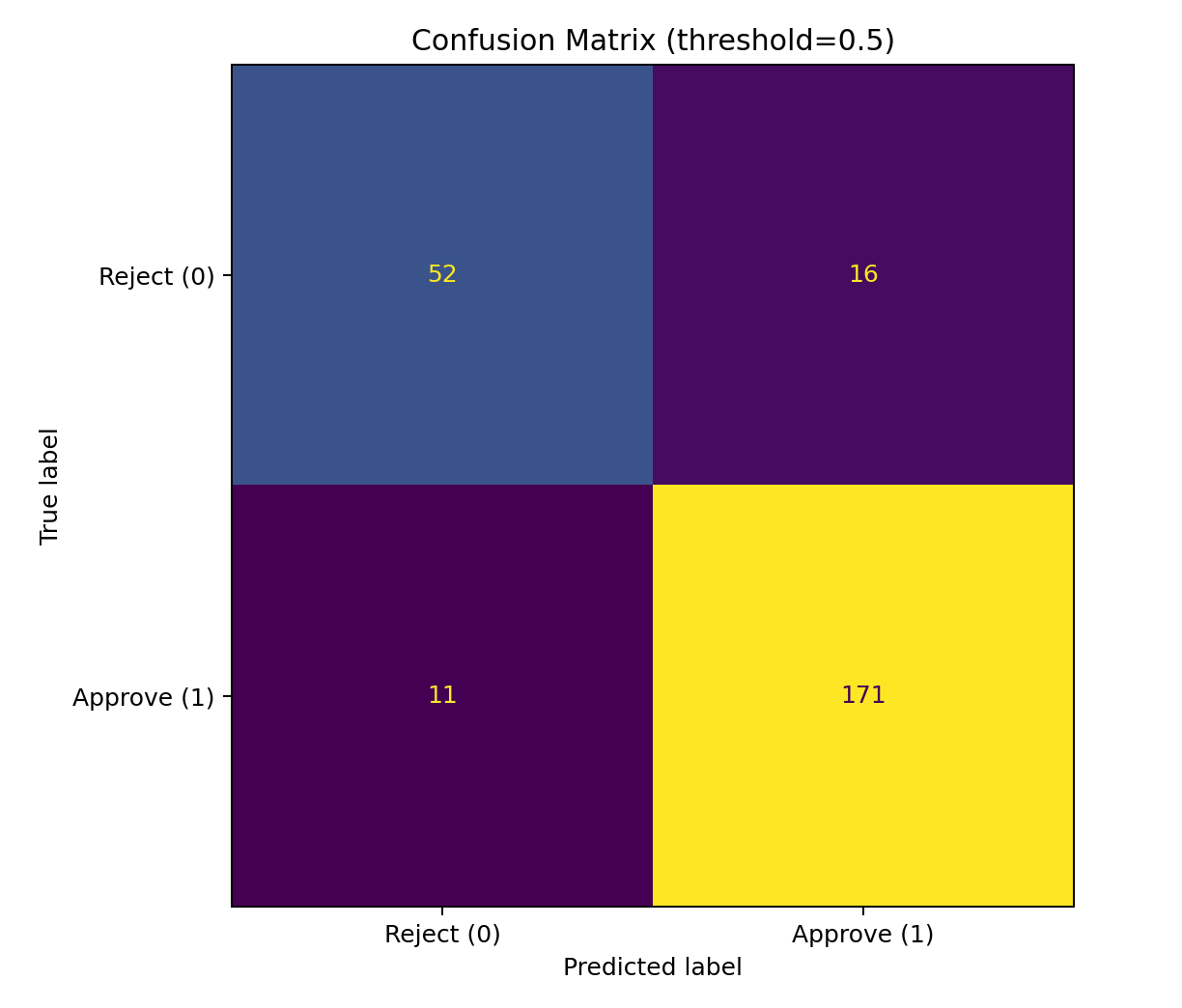
 ### 它回答什么问题
“我们能否信任预测概率作为真正的概率?”
### 如何解读
* X 轴:预测概率(分箱)
* Y 轴:观察到的准确率 / 经验频率
* 对角线 = 完美校准
* 点在对角线上方:置信不足(现实 > 置信度)
* 点在对角线下方:过度自信(置信度 > 现实)
### 为何校准在此至关重要
拒绝规则依赖于置信度阈值,例如:
* 仅当置信度 ≥ 0.85 时才自动决策
如果概率未校准,“0.85”就没有意义。
### 良好校准的表现
* 点在中高概率区域接近对角线
* 在您将要部署的决策阈值附近尤其重要
# 4) 概率直方图(分离度 + 置信度)
### 它回答什么问题
“我们能否信任预测概率作为真正的概率?”
### 如何解读
* X 轴:预测概率(分箱)
* Y 轴:观察到的准确率 / 经验频率
* 对角线 = 完美校准
* 点在对角线上方:置信不足(现实 > 置信度)
* 点在对角线下方:过度自信(置信度 > 现实)
### 为何校准在此至关重要
拒绝规则依赖于置信度阈值,例如:
* 仅当置信度 ≥ 0.85 时才自动决策
如果概率未校准,“0.85”就没有意义。
### 良好校准的表现
* 点在中高概率区域接近对角线
* 在您将要部署的决策阈值附近尤其重要
# 4) 概率直方图(分离度 + 置信度)
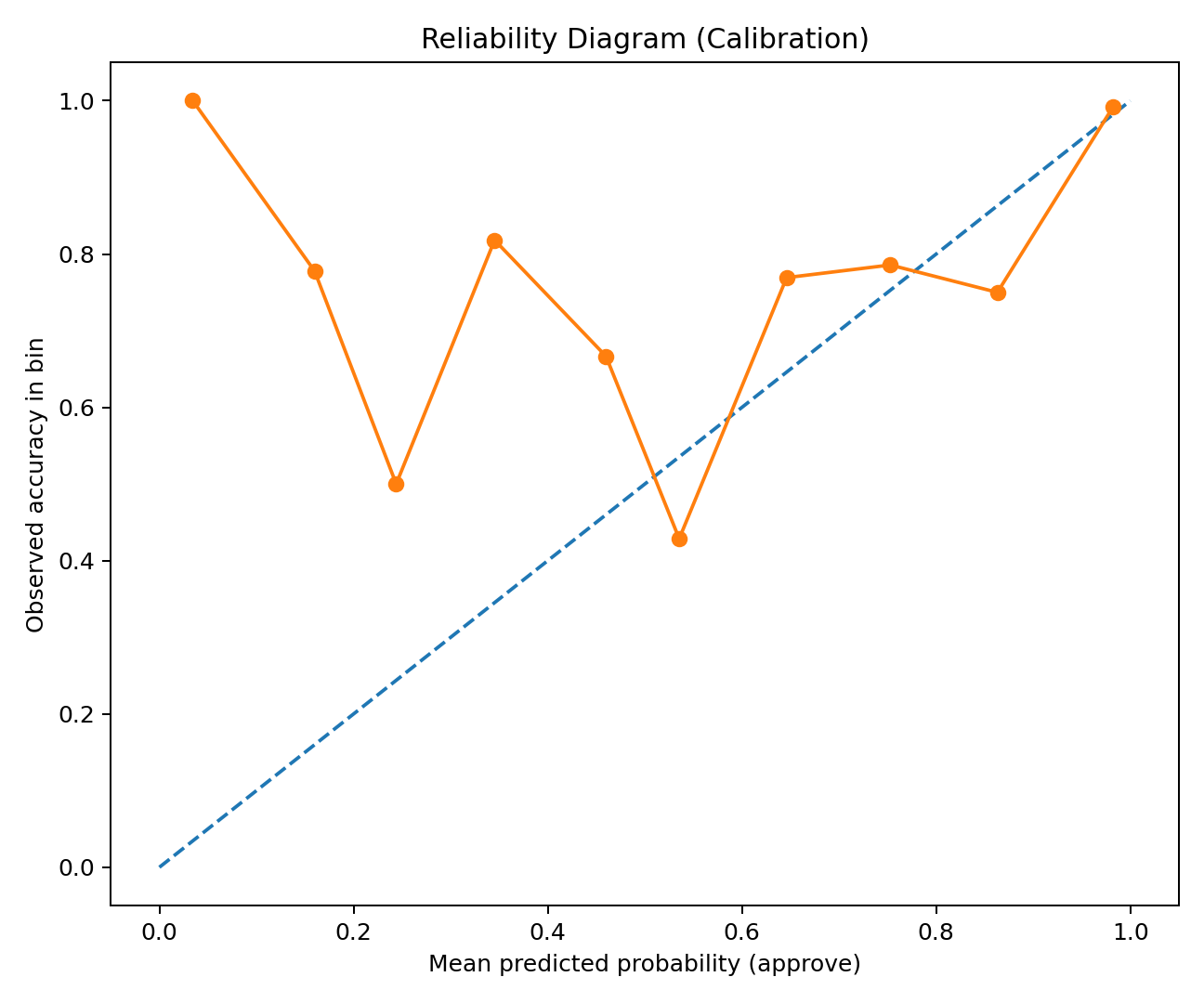
 ### 它回答什么问题
“模型能否将批准案例与拒绝案例区分开?不确定性集中在何处?”
### 如何解读
* 两个重叠的直方图:
* 批准 (y=1)
* 拒绝 (y=0)
* 如果分布分离良好,模型可以自信地自动决策更多案例。
* 如果在中间区域大量重叠,您将需要更多的拒绝/审核。
### 您可从中获得的承保洞察
* 在 **1.0** 附近对批准案例有大量聚集,表明存在强大的“安全批准”区域。
* 分散的拒绝分布表明拒绝案例更难识别或一致性较低。
* 重叠区域是您的审核队列候选区。
# 5) 覆盖率 vs 性能(拒绝权衡)
### 它回答什么问题
“模型能否将批准案例与拒绝案例区分开?不确定性集中在何处?”
### 如何解读
* 两个重叠的直方图:
* 批准 (y=1)
* 拒绝 (y=0)
* 如果分布分离良好,模型可以自信地自动决策更多案例。
* 如果在中间区域大量重叠,您将需要更多的拒绝/审核。
### 您可从中获得的承保洞察
* 在 **1.0** 附近对批准案例有大量聚集,表明存在强大的“安全批准”区域。
* 分散的拒绝分布表明拒绝案例更难识别或一致性较低。
* 重叠区域是您的审核队列候选区。
# 5) 覆盖率 vs 性能(拒绝权衡)
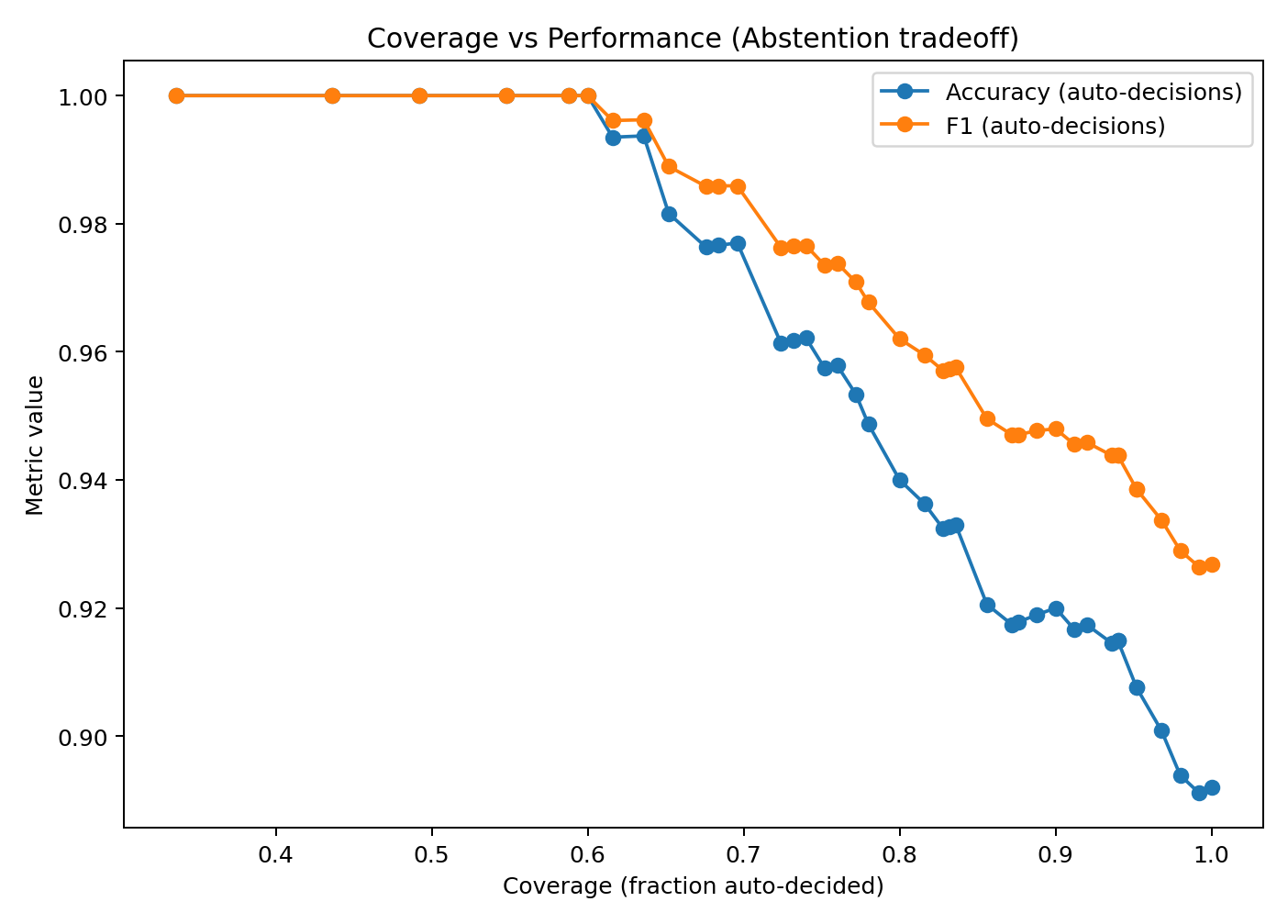 ### 它回答什么问题
“如果我们拒绝更多案例,能获得多少质量提升?”
### 定义
* **覆盖率:** 系统自动决策的案例比例
* **自动决策性能:** 仅在自动决策案例上衡量的准确率/F1
* 随着阈值增加:
* 覆盖率通常会下降
* 自动决策质量通常会提高
### 如何使用(实际工作流程)
1. 确定目标覆盖率(例如,70% 自动决策)
2. 选择实现该覆盖率的置信度阈值
3. 验证自动决策质量是否可接受
4. 审核队列大小变为 (1 - 覆盖率)
### 常见陷阱
如果在所有困难的案例上都选择拒绝,很容易获得高自动决策准确率。
因此,您必须始终**同时报告覆盖率和质量**。
# 6) 覆盖率曲线标签页
**目标:** 使覆盖率前沿交互化且易于检查。
### 它回答什么问题
“如果我们拒绝更多案例,能获得多少质量提升?”
### 定义
* **覆盖率:** 系统自动决策的案例比例
* **自动决策性能:** 仅在自动决策案例上衡量的准确率/F1
* 随着阈值增加:
* 覆盖率通常会下降
* 自动决策质量通常会提高
### 如何使用(实际工作流程)
1. 确定目标覆盖率(例如,70% 自动决策)
2. 选择实现该覆盖率的置信度阈值
3. 验证自动决策质量是否可接受
4. 审核队列大小变为 (1 - 覆盖率)
### 常见陷阱
如果在所有困难的案例上都选择拒绝,很容易获得高自动决策准确率。
因此,您必须始终**同时报告覆盖率和质量**。
# 6) 覆盖率曲线标签页
**目标:** 使覆盖率前沿交互化且易于检查。
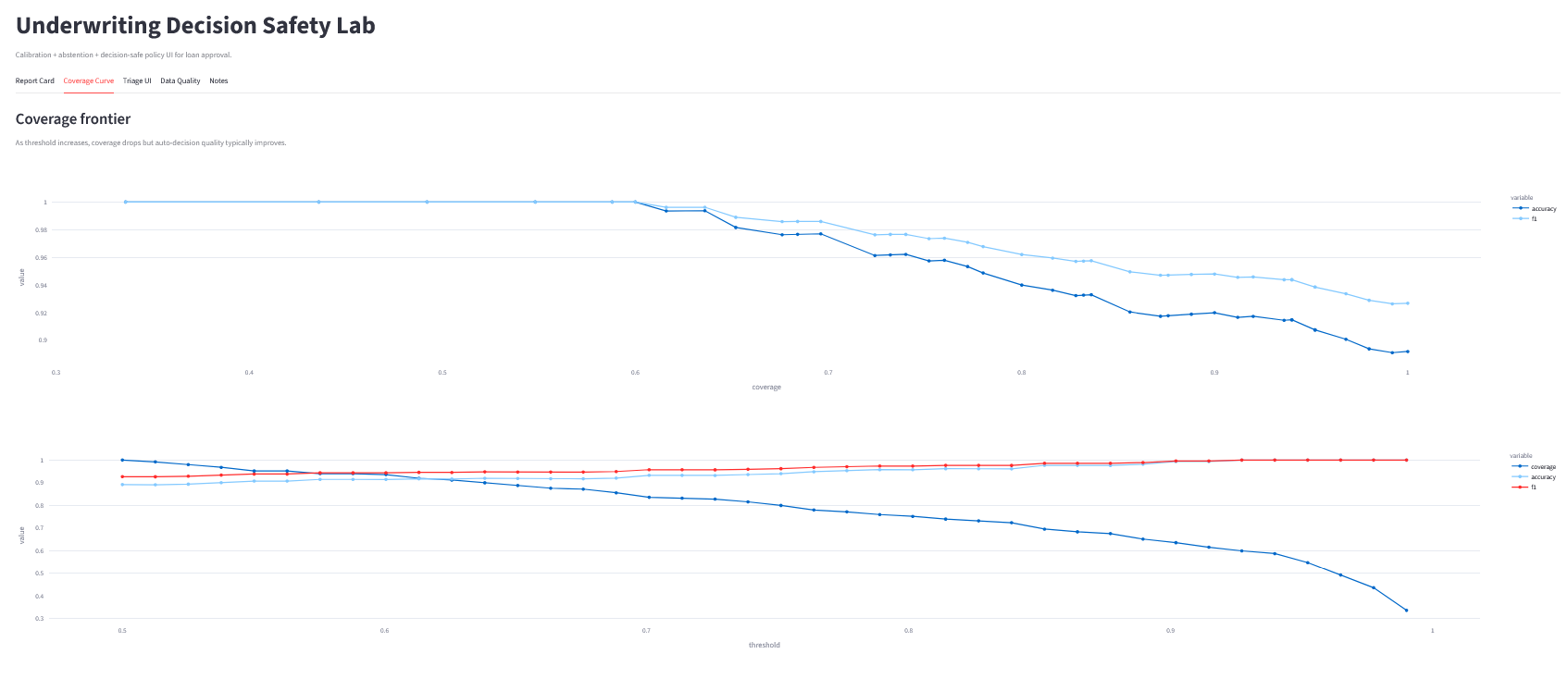 ### 您通常寻找什么
* 曲线中的“拐点”:一个小幅降低覆盖率就能带来质量大幅提升的区域
* 稳定性:避免微小变化导致大幅波动的阈值
* 一个可辩护的操作点:
* “在阈值 0.85 下,我们自动决策约 70% 的案例,自动决策准确率约为 0.98”
# 7) 分诊 UI 标签页(决策安全演示)
**目标:** 展示*承保员或分析师将如何体验该模型*。
### 您通常寻找什么
* 曲线中的“拐点”:一个小幅降低覆盖率就能带来质量大幅提升的区域
* 稳定性:避免微小变化导致大幅波动的阈值
* 一个可辩护的操作点:
* “在阈值 0.85 下,我们自动决策约 70% 的案例,自动决策准确率约为 0.98”
# 7) 分诊 UI 标签页(决策安全演示)
**目标:** 展示*承保员或分析师将如何体验该模型*。
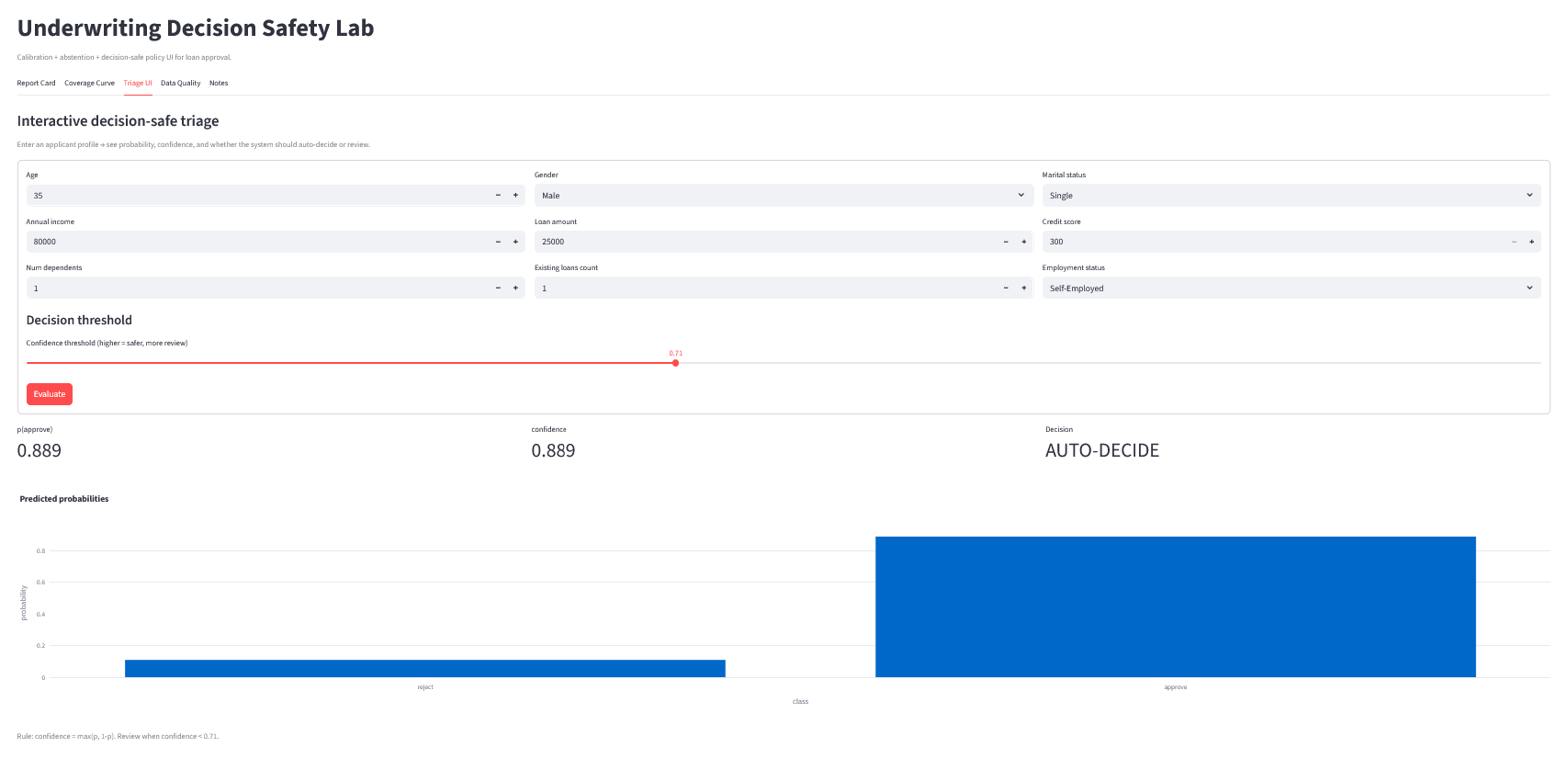 ### 它的功能
* 您输入申请人特征(年龄、收入、贷款金额、信用评分等)
* 应用输出:
* `p(批准)`
* 置信度度量(通常是最大概率或概率差值)
* 决策:**自动决策** 或 **转交审核**
* 类别概率条形图
### 决策安全规则(核心概念)
该 UI 不会因为 p=0.71 就说“批准”,而是显示:
* 当置信度 ≥ 阈值时**自动决策**
* 否则**转交审核**
这使得系统可辩护:
* 您可以解释您选择了什么置信度阈值
* 您可以估算工作量(审核量)
* 您可以监控漂移(覆盖率随时间变化)
### 为何这优于原始预测
没有策略的原始概率会导致误用:
* 不同团队解读不同
* 阈值被临时选定
* 您会丧失“为何做出此决策?”的可追溯性
# 8) 数据质量标签页(快速检查)
**目标:** 在信任指标之前发现问题。
### 它的功能
* 您输入申请人特征(年龄、收入、贷款金额、信用评分等)
* 应用输出:
* `p(批准)`
* 置信度度量(通常是最大概率或概率差值)
* 决策:**自动决策** 或 **转交审核**
* 类别概率条形图
### 决策安全规则(核心概念)
该 UI 不会因为 p=0.71 就说“批准”,而是显示:
* 当置信度 ≥ 阈值时**自动决策**
* 否则**转交审核**
这使得系统可辩护:
* 您可以解释您选择了什么置信度阈值
* 您可以估算工作量(审核量)
* 您可以监控漂移(覆盖率随时间变化)
### 为何这优于原始预测
没有策略的原始概率会导致误用:
* 不同团队解读不同
* 阈值被临时选定
* 您会丧失“为何做出此决策?”的可追溯性
# 8) 数据质量标签页(快速检查)
**目标:** 在信任指标之前发现问题。
 ### 此标签页应包含的内容(及原因)
即使在干净的演示数据集中,现实世界的承保系统也可能因以下原因出错:
#### 缺失值漂移
* 新渠道的收入数据缺失
* 合作伙伴集成的就业状态缺失
#### 合理性违规
* 信用评分超出预期范围
* 负的贷款金额
* 不可能的年龄
#### 类别漂移
* 新的 `employment_status` 值
* 婚姻状况编码发生变化
### 为何这对决策安全很重要
像“置信度高于 0.85 则自动决策”这样的策略,假设您的特征分布与训练时相似。
数据质量检查是策略应用前的“信任关口”。
# 9) 备注标签页(解读 + 生产指导)
### 此标签页应包含的内容(及原因)
即使在干净的演示数据集中,现实世界的承保系统也可能因以下原因出错:
#### 缺失值漂移
* 新渠道的收入数据缺失
* 合作伙伴集成的就业状态缺失
#### 合理性违规
* 信用评分超出预期范围
* 负的贷款金额
* 不可能的年龄
#### 类别漂移
* 新的 `employment_status` 值
* 婚姻状况编码发生变化
### 为何这对决策安全很重要
像“置信度高于 0.85 则自动决策”这样的策略,假设您的特征分布与训练时相似。
数据质量检查是策略应用前的“信任关口”。
# 9) 备注标签页(解读 + 生产指导)
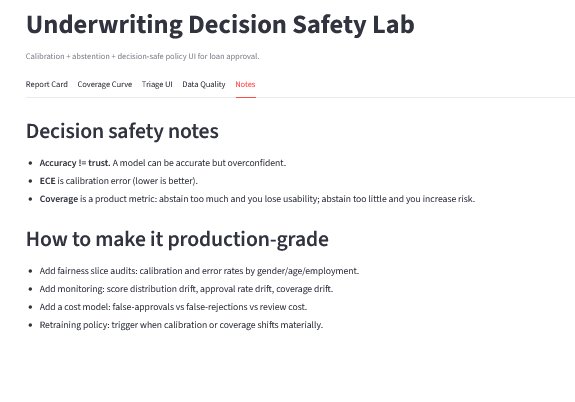 ### 重要信息
* **准确率 ≠ 可信**
* **ECE 是校准误差**
* **覆盖率是一个产品指标**(审核队列不是免费的)
### “生产级”在此处的含义
一个真正的系统应增加:
* 公平性分片审计(按性别/年龄/就业状态划分的校准 + 错误率)
* 监控:分数漂移、批准率漂移、覆盖率漂移
* 成本感知策略:错误批准 vs 错误拒绝 vs 审核成本
* 当校准退化时触发重新训练
## 推荐的拒绝策略(含义)
应用显示了一个推荐策略(例如来自您的报告卡界面):
* **阈值(置信度):** 0.85
* **预期覆盖率:** 0.70
* **自动决策准确率:** 0.977
* **自动决策 F1:** 0.986
解读:
* 系统自动决策约 70% 的申请人。
* 剩余的约 30% 转交人工审核。
* 自动决策的案例置信度高,因此质量高。
* 这**不是“作弊”**,而是一个有意识的设计决策,将机器学习转化为安全的工作流。
## 如何扩展此实验室
### 1) 双边策略(批准 + 拒绝 + 审核)
目前,许多原型使用单一置信度阈值。承保通常受益于:
* 若 p(批准) ≥ T_approve,则自动批准
* 若 p(批准) ≤ T_reject,则自动拒绝
* 否则转交审核
这可以在控制风险的同时减少审核工作量。
### 2) 成本感知优化
将“最大化准确率”替换为:
* 成本(错误批准) >> 成本(错误拒绝)
* 成本(审核) 作为工作量项
然后选择最小化预期成本的阈值。
### 3) 公平性感知报告
添加分片仪表板:
* 按性别划分的 ECE
* 按年龄组划分的错误率
* 按就业状态划分的批准率
* 按子群体划分的覆盖率
### 4) 监控手册
每周跟踪:
* 分数分布漂移
* 覆盖率漂移
* 批准率漂移
* 校准漂移(ECE 变化)
## 故障排除
### “我的 Streamlit 警告提到 `use_container_width`”
较新的 Streamlit 版本倾向于:
* 使用 `width="stretch"` 代替 `use_container_width=True`
如果您看到弃用警告,请相应地更新您的 `st.plotly_chart(...)` 和 `st.image(...)` 调用。
### “图表看起来太小 / 布局奇怪”
请确保:
* 设置了 `st.set_page_config(layout="wide")`
* 使用一致的容器/列
* 对 Streamlit 中的图表/图像使用 `width="stretch"`
## 致谢
* 数据集: https://www.kaggle.com/datasets/amineipad/loan-approval-dataset
* 工具: pandas, scikit-learn, Streamlit, matplotlib/plotly
### 重要信息
* **准确率 ≠ 可信**
* **ECE 是校准误差**
* **覆盖率是一个产品指标**(审核队列不是免费的)
### “生产级”在此处的含义
一个真正的系统应增加:
* 公平性分片审计(按性别/年龄/就业状态划分的校准 + 错误率)
* 监控:分数漂移、批准率漂移、覆盖率漂移
* 成本感知策略:错误批准 vs 错误拒绝 vs 审核成本
* 当校准退化时触发重新训练
## 推荐的拒绝策略(含义)
应用显示了一个推荐策略(例如来自您的报告卡界面):
* **阈值(置信度):** 0.85
* **预期覆盖率:** 0.70
* **自动决策准确率:** 0.977
* **自动决策 F1:** 0.986
解读:
* 系统自动决策约 70% 的申请人。
* 剩余的约 30% 转交人工审核。
* 自动决策的案例置信度高,因此质量高。
* 这**不是“作弊”**,而是一个有意识的设计决策,将机器学习转化为安全的工作流。
## 如何扩展此实验室
### 1) 双边策略(批准 + 拒绝 + 审核)
目前,许多原型使用单一置信度阈值。承保通常受益于:
* 若 p(批准) ≥ T_approve,则自动批准
* 若 p(批准) ≤ T_reject,则自动拒绝
* 否则转交审核
这可以在控制风险的同时减少审核工作量。
### 2) 成本感知优化
将“最大化准确率”替换为:
* 成本(错误批准) >> 成本(错误拒绝)
* 成本(审核) 作为工作量项
然后选择最小化预期成本的阈值。
### 3) 公平性感知报告
添加分片仪表板:
* 按性别划分的 ECE
* 按年龄组划分的错误率
* 按就业状态划分的批准率
* 按子群体划分的覆盖率
### 4) 监控手册
每周跟踪:
* 分数分布漂移
* 覆盖率漂移
* 批准率漂移
* 校准漂移(ECE 变化)
## 故障排除
### “我的 Streamlit 警告提到 `use_container_width`”
较新的 Streamlit 版本倾向于:
* 使用 `width="stretch"` 代替 `use_container_width=True`
如果您看到弃用警告,请相应地更新您的 `st.plotly_chart(...)` 和 `st.image(...)` 调用。
### “图表看起来太小 / 布局奇怪”
请确保:
* 设置了 `st.set_page_config(layout="wide")`
* 使用一致的容器/列
* 对 Streamlit 中的图表/图像使用 `width="stretch"`
## 致谢
* 数据集: https://www.kaggle.com/datasets/amineipad/loan-approval-dataset
* 工具: pandas, scikit-learn, Streamlit, matplotlib/plotly标签:Apex, Kubernetes, pandas, Python, scikit-learn, Streamlit, 决策安全, 决策支持系统, 分诊UI, 弃权策略, 报告卡, 数据质量检查, 无后门, 机器学习, 概率校准, 模型评估, 自动化决策, 覆盖前沿, 访问控制, 贷款审批, 逆向工具, 金融建模, 金融风控, 阈值优化, 风险审核