RightNow-AI/picolm
GitHub: RightNow-AI/picolm
PicoLM 是一个纯C语言编写的超轻量LLM推理引擎,通过mmap层流式加载、SIMD加速和量化支持,让10亿参数模型在仅256MB内存的十美元开发板上离线运行。
Stars: 1775 | Forks: 227





PicoLM
在配备 256MB RAM 的 10 美元开发板上运行 10 亿参数的 LLM。
纯 C 语言。零依赖。单一可执行文件。无需 Python。无需云端。
echo "Explain gravity" | ./picolm model.gguf -n 100 -j 4
## 完美组合:PicoLM + PicoClaw
PicoLM 是为 [PicoClaw](https://github.com/sipeed/picoclaw) 构建的**本地大脑** —— 这是一个用 Go 语言编写的超轻量级 AI 助手,可运行在 10 美元的硬件上。它们共同组成了一个**完全离线的 AI agent** —— 无需云服务,无需 API 密钥,无需互联网,也无需月度账单。
| The Hardware |
The Architecture |
 |
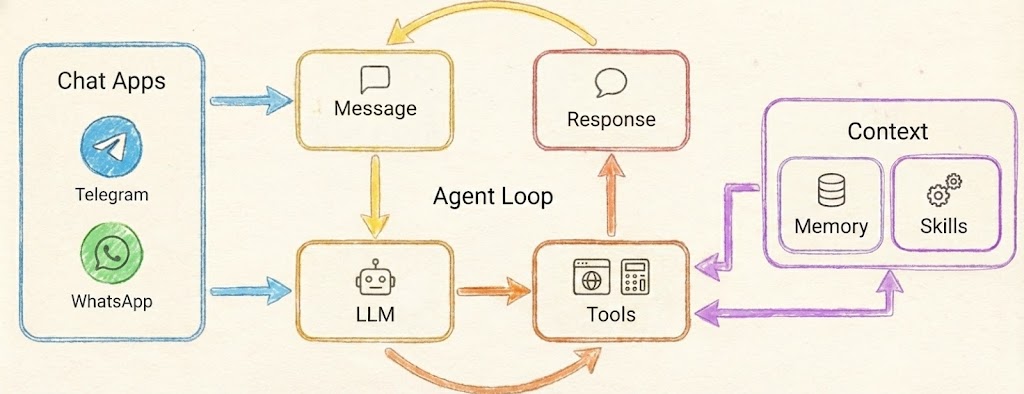 |
| $9.90 — that's the entire server |
PicoLM powers the LLM box in PicoClaw's agent loop |
### 为什么它们是天作之合
| | 云提供商 (OpenAI 等) | PicoLM (本地) |
|---|---|---|
| **成本** | 永远按 token 付费 | 永久免费 |
| **隐私** | 你的数据被发送到服务器 | 一切数据都保留在设备上 |
| **互联网** | 每次请求都需要 | 完全不需要 |
| **延迟** | 网络往返 + 推理 | 仅推理 |
| **硬件** | 需要一台 $599 的 Mac Mini | 运行在 $10 的开发板上 |
| **二进制文件** | N/A | ~80KB 单文件 |
| **RAM** | N/A | 总计 45 MB |
### 工作原理
PicoClaw 的 agent 循环将 PicoLM 作为子进程运行。消息来自 Telegram、Discord 或 CLI —— PicoClaw 将它们格式化为聊天模板,通过 stdin 将 prompt 传给 `picolm`,并从 stdout 读取响应。当需要使用工具时,`--json` 语法模式能保证即使是 1B 模型也能输出有效的 JSON。
```
Telegram / Discord / CLI
│
▼
┌──────────┐ stdin: prompt ┌───────────┐
│ PicoClaw │ ──────────────────► │ picolm │
│ (Go) │ ◄────────────────── │ (C) │
└──────────┘ stdout: response │ + model │
│ └───────────┘
▼ 45 MB RAM
User gets reply No internet
```
### 快速设置
```
# 1. 构建 PicoLM
cd picolm && make native # or: make pi (Raspberry Pi)
# 2. 下载模型(一次性,638 MB)
make model
# 3. 构建 PicoClaw
cd ../picoclaw && make deps && make build
# 4. 配置 (~/.picoclaw/config.json)
```
```
{
"agents": {
"defaults": {
"provider": "picolm",
"model": "picolm-local"
}
},
"providers": {
"picolm": {
"binary": "~/.picolm/bin/picolm",
"model": "~/.picolm/models/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf",
"max_tokens": 256,
"threads": 4,
"template": "chatml"
}
}
}
```
```
# 5. 聊天 — 完全离线!
picoclaw agent -m "What is photosynthesis?"
```
### 或者一行命令安装所有内容
```
curl -sSL https://raw.githubusercontent.com/RightNow-AI/picolm/main/install.sh | bash
```
### 真实硬件上的性能表现
| 设备 | 价格 | 生成速度 | RAM 占用 |
|--------|-------|-----------------|----------|
| **Pi 5** (4核) | $60 | ~10 tok/s | 45 MB |
| **Pi 4** (4核) | $35 | ~8 tok/s | 45 MB |
| **Pi 3B+** | $25 | ~4 tok/s | 45 MB |
| **Pi Zero 2W** | $15 | ~2 tok/s | 45 MB |
| **LicheeRV Nano** | $10 | ~1 tok/s | 45 MB |
### JSON 工具调用
当 PicoClaw 需要结构化输出时,会自动激活 `--json` 语法模式。这能**保证语法上有效的 JSON** 输出,即使是在 1B 参数模型上 —— 这对于在微型硬件上进行可靠的工具调用至关重要:
```
picoclaw agent -m "Search for weather in Tokyo"
# → PicoLM 生成: {"tool_calls": [{"function": {"name": "web_search", "arguments": "{\"query\": \"weather Tokyo\"}"}}]}
```
## 什么是 PicoLM?
PicoLM 是一个用大约 2,500 行 C11 代码**从零开始编写的极简 LLM 推理引擎**。它可以在大多数推理框架根本不会考虑的硬件上运行 [TinyLlama 1.1B](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0)(以及其他采用 LLaMA 架构的 GGUF 格式模型):
- **Raspberry Pi Zero 2W** ($15, 512MB RAM, ARM Cortex-A53)
- **Sipeed LicheeRV** ($12, 512MB RAM, RISC-V)
- **Raspberry Pi 3/4/5** (1-8GB RAM, ARM NEON SIMD)
- 任何 Linux/Windows/macOS x86-64 机器
模型文件 (638MB) 留在磁盘上。PicoLM 对其进行**内存映射**,并每次在 RAM 中流式传输一层。总运行时内存:**~45MB**(包括 FP16 KV cache)。
```
┌──────────────────────────────────────────┐
What goes │ 45 MB Runtime RAM │
in RAM │ ┌─────────┐ ┌──────────┐ ┌───────────┐ │
│ │ Buffers │ │ FP16 KV │ │ Tokenizer │ │
│ │ 1.2 MB │ │ Cache │ │ 4.5 MB │ │
│ │ │ │ ~40 MB │ │ │ │
│ └─────────┘ └──────────┘ └───────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
What stays │ 638 MB Model on Disk │
on disk │ (mmap — OS pages in layers │
(via mmap) │ as needed, ~1 at a time) │
└──────────────────────────────────────────┘
```
## 功能特性
| 功能 | 描述 |
|---------|-------------|
| **GGUF 原生支持** | 直接读取 GGUF v2/v3 文件 —— 无需转换 |
| **K-Quant 支持** | Q2_K, Q3_K, Q4_K, Q5_K, Q6_K, Q8_0, Q4_0, F16, F32 |
| **mmap 层流式传输** | 模型权重保留在磁盘上;操作系统每次只调入一层 |
| **FP16 KV Cache** | KV 缓存内存减半(2048 上下文下为 44MB,而非 88MB) |
| **Flash Attention** | 在线 softmax —— 不需要 O(seq_len) 的注意力缓冲区 |
| **预计算 RoPE** | cos/sin 查找表消除了热循环中的超越函数 |
| **SIMD 加速** | 自动检测 ARM NEON (Pi 3/4/5) 和 x86 SSE2 (Intel/AMD) |
| **融合点积** | 在一次遍历中完成反量化和点积 —— 无需中间缓冲区 |
| **多线程 matmul** | 跨 CPU 核心并行进行矩阵-向量乘法 |
| **语法约束 JSON** | `--json` 标志强制输出有效 JSON(用于工具调用) |
| **KV 缓存持久化** | `--cache` 保存/加载 prompt 状态 —— 重新运行时跳过 prefill 阶段 |
| **BPE 分词器** | 基于分数的字节对编码,从 GGUF 元数据加载 |
| **Top-p 采样** | 温度 + 核采样,可配置随机种子 |
| **管道友好** | 从 stdin 读取 prompt:`echo "Hello" \| ./picolm model.gguf` |
| **零依赖** | 仅需 libc, libm, libpthread。没有外部库。 |
| **跨平台** | Linux, Windows (MSVC), macOS. ARM, x86-64, RISC-V. |
## 快速开始
### 一键安装 (Raspberry Pi / Linux)
```
curl -sSL https://raw.githubusercontent.com/RightNow-AI/picolm/main/install.sh | bash
```
此操作将:
1. 检测你的平台 (ARM64, ARMv7, x86-64)
2. 安装构建依赖 (`gcc`, `make`, `curl`)
3. 使用针对你的 CPU 优化的 SIMD 标志构建 PicoLM
4. 下载 TinyLlama 1.1B Q4_K_M (638 MB)
5. 运行快速测试
6. 生成 PicoClaw 配置
7. 将 `picolm` 添加到你的 PATH
### 从源码构建
```
git clone https://github.com/rightnow-ai/picolm.git
cd picolm/picolm
# 自动检测 CPU (在 x86 上启用 SSE2/AVX,在 ARM 上启用 NEON)
make native
# 下载模型
make model
# 运行它
./picolm /opt/picolm/models/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf \
-p "The meaning of life is" -n 100
```
### 在 Windows 上构建 (MSVC)
```
cd picolm
build.bat
picolm.exe model.gguf -p "Hello world" -n 50
```
### 特定平台构建
```
make native # x86/ARM auto-detect (recommended for local machine)
make pi # Raspberry Pi 3/4/5 (64-bit ARM + NEON SIMD)
make pi-arm32 # Pi Zero / Pi 1 (32-bit ARM)
make cross-pi # Cross-compile for Pi from x86 (static binary)
make riscv # RISC-V (Sipeed LicheeRV, etc.)
make static # Static binary for single-file deployment
make debug # Debug build with symbols, no optimization
```
## 用法
```
PicoLM — ultra-lightweight LLM inference engine
Usage: picolm
[options]
Generation options:
-p Input prompt (or pipe via stdin)
-n Max tokens to generate (default: 256)
-t Temperature (default: 0.8, 0=greedy)
-k Top-p / nucleus sampling (default: 0.9)
-s RNG seed (default: 42)
-c Context length override
-j Number of threads (default: 4)
Advanced options:
--json Grammar-constrained JSON output mode
--cache KV cache file (saves/loads prompt state)
```
### 示例
**基础生成:**
```
./picolm model.gguf -p "Once upon a time" -n 200
```
**贪心解码(确定性, temperature=0):**
```
./picolm model.gguf -p "The capital of France is" -n 20 -t 0
# 输出: Paris. It is the largest city in France and...
```
**与 TinyLlama 聊天 (ChatML 格式):**
```
./picolm model.gguf -n 200 -t 0.7 -p "<|user|>
What is photosynthesis?
<|assistant|>
"
```
**强制输出 JSON (用于工具调用 / 结构化数据):**
```
./picolm model.gguf --json -t 0.3 -n 100 -p "<|user|>
Return the current time as JSON.
<|assistant|>
"
# 输出: {"time": "12:00 PM"}
```
**从标准输入通过管道传入:**
```
echo "Explain quantum computing in one sentence" | ./picolm model.gguf -n 50
```
**KV 缓存 —— 跳过重复的 prefill:**
```
# 首次运行: 处理 prompt + 保存 cache
./picolm model.gguf --cache prompt.kvc -p "Long system prompt here..." -n 50
# 第二次运行: 加载 cache,跳过 prompt prefill (快 74%)
./picolm model.gguf --cache prompt.kvc -p "Long system prompt here..." -n 50
# 输出: "Skipping 25 cached prompt tokens"
```
**在 Pi 4 上多线程运行 (4核):**
```
./picolm model.gguf -p "Hello" -n 100 -j 4
```
## 性能表现
在 TinyLlama 1.1B Q4_K_M (638 MB 模型) 上测量:
| 指标 | x86-64 (8线程) | Pi 4 (4核, NEON) | Pi Zero 2W |
|--------|--------------------|-----------------------|------------|
| **Prefill** | ~11 tok/s | ~6 tok/s | ~1.5 tok/s |
| **生成速度** | ~13 tok/s | ~8 tok/s* | ~2 tok/s* |
| **运行时 RAM** | 45 MB | 45 MB | 45 MB |
| **首个 token** | ~2.3s | ~4s | ~16s |
| **二进制文件大小** | ~80 KB | ~70 KB | ~65 KB |
*\*启用 NEON SIMD 的估算值。实际数据取决于 SD 卡速度和热降频。*
### 速度快的秘诀
```
Raw C inference ████████████░░░░░░░░ 13.5 tok/s (baseline: 1.6)
+ Fused dot products ████████████████░░░░ (eliminate dequant buffer)
+ Multi-threaded matmul █████████████████░░░ (4-8 cores in parallel)
+ FP16 KV cache █████████████████░░░ (halve memory bandwidth)
+ Pre-computed RoPE ██████████████████░░ (no sin/cos in hot loop)
+ Flash attention ██████████████████░░ (no O(n) attention alloc)
+ NEON/SSE2 SIMD ███████████████████░ (4-wide vector ops)
+ KV cache persistence ████████████████████ (skip prefill entirely)
```
## 架构
```
┌─────────────────────────────────┐
│ picolm.c │
│ CLI + Generation Loop │
└──────┬──────────────┬───────────┘
│ │
┌────────────┘ └────────────┐
│ │
┌────────┴────────┐ ┌──────────┴──────────┐
│ model.h/c │ │ sampler.h/c │
│ GGUF Parser │ │ Temperature + │
│ mmap Layer │ │ Top-p Sampling │
│ Streaming │ └──────────┬──────────┘
│ Forward Pass │ │
│ KV Cache I/O │ ┌──────────┴──────────┐
└───┬────────┬────┘ │ grammar.h/c │
│ │ │ JSON Constraint │
┌────────┘ └───────┐ │ Logit Masking │
│ │ └─────────────────────┘
┌─────┴──────┐ ┌───────┴────────┐
│ tensor.h/c │ │ tokenizer.h/c │
│ matmul │ │ BPE Encode │
│ rmsnorm │ │ Decode │
│ softmax │ │ Vocab Lookup │
│ rope │ └────────────────┘
│ silu │
│ threading │
└─────┬──────┘
│
┌─────┴──────┐
│ quant.h/c │
│ Q4_K, Q6_K │
│ Q3_K, Q2_K │
│ FP16, F32 │
│ NEON + SSE │
│ Fused Dots │
└────────────┘
```
### LLaMA 前向传播(每个 token 发生了什么)
```
Input Token
│
▼
┌───────────────┐
│ Embedding │ Dequantize row from token_embd → x[2048]
│ Lookup │
└───────┬───────┘
│
▼
┌───────────────┐ ×22 layers
│ RMSNorm │─────────────────────────────────────────┐
│ │ │
│ Q = xb @ Wq │ Matrix-vector multiply (quantized) │
│ K = xb @ Wk │ Store K,V in FP16 KV cache │
│ V = xb @ Wv │ │
│ │ │
│ RoPE(Q, K) │ Rotary position encoding (table lookup)│
│ │ │
│ Attention │ Flash attention with online softmax │
│ (GQA 32→4) │ Grouped-query: 32 Q heads, 4 KV heads │
│ │ │
│ x += Out@Wo │ Output projection + residual │
│ │ │
│ RMSNorm │ │
│ │ │
│ SwiGLU FFN │ gate=SiLU(xb@Wg), up=xb@Wu │
│ │ x += (gate*up) @ Wd │
└───────┬───────┘─────────────────────────────────────────┘
│
▼
┌───────────────┐
│ Final RMSNorm │
│ x @ W_output │─→ logits[32000]
└───────┬───────┘
│
▼
┌───────────────┐
│ Grammar Mask │ (if --json: force valid JSON structure)
│ Sample Token │ temperature → softmax → top-p → pick
└───────────────┘
```
## 内存预算
对于上下文长度为 2048 的 TinyLlama 1.1B Q4_K_M:
| 组件 | 大小 | 备注 |
|-----------|------|-------|
| FP16 KV cache | ~40 MB | 22 层 x 2 x 2048 x 256 x 2 字节 |
| 分词器 | ~4.5 MB | 32K 词汇表字符串 + 分数 + 排序后的索引 |
| 激活缓冲区 | ~0.14 MB | x, xb, xb2, q, hb, hb2 |
| Logits 缓冲区 | ~0.12 MB | 32000 x 4 字节 |
| 反量化暂存区 | ~0.02 MB | Max(n_embd, n_ffn) 浮点数 |
| 归一化权重 (pre-dequant) | ~0.35 MB | 45 个归一化向量 x 2048 x 4 字节 |
| RoPE 表 | ~0.03 MB | cos + sin x 2048 x 32 条目 |
| **总运行时** | **~45 MB** | |
| | | |
| 模型文件 (磁盘上) | 638 MB | 内存映射,RAM 中一次约 1 层 |
上下文长度为 512(针对受限设备)时:
| 组件 | 大小 |
|-----------|------|
| FP16 KV cache | ~10 MB |
| 其他所有内容 | ~5 MB |
| **总计** | **~15 MB** |
## 深入优化解析
PicoLM 实现了 9 项优化,将 x86 上的生成速度从 **1.6 tok/s 提升至 13.5 tok/s**,在支持 NEON 的 ARM 平台上预期会有更大的提升:
### 1. ARM NEON SIMD
所有热路径均使用 4 宽度浮点向量操作。例如:使用 `vmovl_u8` → `vmovl_u16` → `vcvtq_f32_u32` 对 Q4_K 半字节进行反量化,以及使用交错存储的 `vld2q_f32` / `vst2q_f32` 处理 RoPE。
### 2. x86 SSE2 SIMD
在 Intel/AMD 上自动检测。使用 4 宽度的 `__m128` 操作进行点积、RMSNorm 和向量运算。
### 3. FP16 KV Cache
Key 和 Value 向量以 16 位浮点数而非 32 位存储。将 KV 缓存内存从约 88MB 减半至约 44MB。转换过程使用软件 `fp32_to_fp16()` / `fp16_to_fp32()` —— 无需硬件 FP16 支持。
### 4. 预计算 RoPE 表
所有位置的正弦和余弦值在模型加载时一次性计算完毕。前向传播通过查表完成,而不是每个 token 调用 64 次 `sinf()` / `cosf()` / `powf()`。
### 5. Flash Attention (在线 Softmax)
带有运行最大值重新缩放的单次遍历注意力机制。消除了 `O(seq_len)` 的注意力分数缓冲区 —— 这对于内存受限设备上的长上下文至关重要。
### 6. 融合反量化 + 点积
`vec_dot_q4_K_f32()` 在一次遍历中完成反量化并累加。不需要为权重行分配中间浮点缓冲区。将 matmul 的内存流量减少了约 50%。
### 7. 多线程矩阵乘法
`matmul()` 使用 pthreads 将输出行分配给各个线程。每个线程使用融合点积独立处理自己的数据块。可线性扩展至约 8 个核心。
### 8. 语法约束 JSON
`--json` 模式在加载时预分析词汇表中的每个 token(大括号增量、中括号增量、引号奇偶校验)。在生成过程中,它会掩盖 logits 以保证语法上有效的 JSON 输出 —— 这对于使用小型模型进行工具调用至关重要。
### 9. KV 缓存持久化
`--cache file.kvc` 在处理完 prompt 后保存 FP16 KV 缓存状态。在使用相同 prompt 的下一次运行中,它会加载缓存并完全跳过 prefill 阶段。对于重复的系统 prompt,**延迟降低了 74%**。
## 支持的
PicoLM 支持任何采用 LLaMA 架构的 GGUF 格式模型:
| 模型 | 参数量 | GGUF 大小 (Q4_K_M) | 所需 RAM |
|-------|-----------|---------------------|------------|
| **TinyLlama 1.1B** | 1.1B | 638 MB | ~45 MB |
| **Llama 2 7B** | 7B | 4.1 GB | ~200 MB |
| **Phi-2** | 2.7B | 1.6 GB | ~90 MB |
### 支持的量化格式
`Q2_K` `Q3_K` `Q4_K` `Q4_0` `Q5_K` `Q6_K` `Q8_0` `F16` `F32`
## 文件结构
```
PicoLM/
├── README.md ← you are here
├── BLOG.md ← technical deep-dive blog post
├── install.sh ← one-liner Pi installer
│
├── picolm/ ← the inference engine (pure C)
│ ├── picolm.c ← CLI entry point, generation loop (273 lines)
│ ├── model.h/c ← GGUF parser, mmap, forward pass (146 + 833 lines)
│ ├── tensor.h/c ← matmul, rmsnorm, softmax, rope (44 + 298 lines)
│ ├── quant.h/c ← dequantization, SIMD kernels (140 + 534 lines)
│ ├── tokenizer.h/c ← BPE tokenizer (32 + ~200 lines)
│ ├── sampler.h/c ← temperature + top-p sampling (19 + ~100 lines)
│ ├── grammar.h/c ← JSON grammar constraints (64 + 175 lines)
│ ├── Makefile ← build targets for all platforms
│ └── build.bat ← Windows MSVC build script
│
└── tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf ← model file (638 MB, not in git)
```
**C 源代码总计:约 2,500 行。** 这包含了整个推理引擎 —— GGUF 解析、mmap、反量化、矩阵运算、注意力机制、tokenization、采样和语法约束。
## 运作原理
### mmap 技巧
传统的推理引擎会将整个模型加载到 RAM 中。PicoLM 不会这样做。相反:
1. 模型文件被**内存映射**(Linux/macOS 上使用 `mmap`,Windows 上使用 `MapViewOfFile`)
2. 权重指针直接指向映射文件 —— 无需拷贝
3. 在前向传播期间,每层的权重按顺序被访问
4. 操作系统自动调入所需的权重并换出旧的权重
5. `madvise(MADV_SEQUENTIAL)` 向内核提示访问模式
**结果:** 638MB 的模型可以在具有 256MB RAM 的设备上运行。任何时候物理内存中只有约 30MB 的模型数据。
### 量化
权重以 4 位量化格式 (Q4_K_M) 存储。对于 TinyLlama:
- **原始:** 1.1B 参数 x 4 字节 = 4.4 GB
- **Q4_K:** 1.1B 参数 x ~0.56 字节 = 638 MB
- **质量损失:** 极小 —— Q4_K 为每 32 个权重的子块保留 6 位的缩放比例
### 分组查询注意力 (GQA)
TinyLlama 使用 32 个查询头但只有 4 个键/值头。每个 KV 头由 8 个查询头共享。与完整的多头注意力相比,这将 KV 缓存大小减少了 8 倍。
## 构建与测试
### 前置条件
| 平台 | 要求 |
|----------|-------------|
| **Linux/Pi** | `gcc`, `make` (通过 `apt install build-essential` 安装) |
| **macOS** | Xcode 命令行工具 (`xcode-select --install`) |
| **Windows** | Visual Studio Build Tools (cl.exe) |
### 验证你的构建
```
# 构建
make native
# 使用 greedy decoding 测试 (确定性输出)
./picolm model.gguf -p "The capital of France is" -n 20 -t 0
# 预期: "Paris. It is the largest city in France..."
# 测试 JSON 模式
./picolm model.gguf --json -p "Return JSON with name and age" -n 50 -t 0.3
# 预期: 有效的 JSON,如 {"name": "...", "age": ...}
# 测试 KV cache
./picolm model.gguf --cache test.kvc -p "Hello" -n 10 -t 0
./picolm model.gguf --cache test.kvc -p "Hello" -n 10 -t 0
# 第二次运行应显示 "Skipping N cached prompt tokens"
```
### 内存验证
PicoLM 将内存统计信息打印到 stderr:
```
Memory: 1.17 MB runtime state (FP16 KV cache separate)
```
总计 = 运行时状态 + FP16 KV 缓存。对于上下文长度为 2048 的 TinyLlama:约 45 MB。
## 常见问题
**问:这能运行 Llama 2 7B 吗?**
答:可以,前提是你有足够的 RAM 用于 KV 缓存(7B 模型在 4096 上下文下约需 1.4 GB)。模型文件通过 mmap 保留在磁盘上。在配备 4GB RAM 的 Pi 4 上,可以运行但速度较慢(约 1-2 tok/s)。
**问:为什么不使用 llama.cpp?**
答:llama.cpp 非常出色,但运行小型模型需要约 200MB 以上的运行时内存,构建依赖复杂,且主要针对桌面/服务器用例。PicoLM 专为嵌入式设备打造:45MB RAM,80KB 二进制文件,零依赖。
**问:输出质量好吗?**
答:TinyLlama 1.1B 是一个小模型 —— 它能很好地处理简单任务(问答、摘要、基础推理、JSON 生成)。它无法与 GPT-4 媲美,但它能在没有互联网的 10 美元开发板上运行。对于结构化输出,`--json` 语法模式可保证生成有效的 JSON,而不受模型质量的影响。
**问:支持 GPU 加速吗?**
答:PicoLM 在设计上仅支持 CPU。目标硬件(10-15 美元的开发板)没有 GPU。在 x86/ARM CPU 上,SIMD (NEON/SSE2) 提供了显著的加速。
**问:我可以使用其他模型吗?**
答:任何采用 LLaMA 架构的 GGUF 模型都可以。从 [HuggingFace](https://huggingface.co/models?search=gguf) 下载并将其指定给 PicoLM 即可。推荐的量化格式:Q4_K_M(质量/大小平衡最佳)或 Q2_K(最小,但质量较低)。
## 路线图
- [ ] 面向 x86 的 AVX2/AVX-512 内核(在现代 CPU 上实现 2-4 倍的生成速度)
- [ ] 使用草稿模型的推测解码
- [ ] 上下文滑动窗口(超越 max_seq_len 的无限生成)
- [ ] 权重剪枝以进一步减少内存
- [ ] 用于服务器模式的连续批处理
- [ ] Mistral / Phi 架构支持
## 技术博客
有关优化历程的详细文章(包含代码片段和经验分享),请参阅 [**BLOG.md**](BLOG.md)。
## 许可证
MIT 许可证。详见 [LICENSE](LICENSE)。
PicoLM —— 因为智能不应该依赖数据中心。
标签:C11, DLL 劫持, GGUF格式, IoT, LLM, NLP, TinyML, Unmanaged PE, 人工智能助手, 低功耗硬件, 低成本硬件, 内存优化, 去中心化AI, 大模型推理, 大语言模型, 实时告警, 客户端加密, 嵌入式AI, 嵌入式系统, 开源, 微型机器学习, 微控制器, 本地部署, 机器人, 极小体积, 模型压缩, 物联网, 硬件加速, 离线AI, 资源优化, 轻量级推理, 边缘计算, 量化技术, 零依赖
