socprime/detectflow-main
GitHub: socprime/detectflow-main
Stars: 530 | Forks: 77
# SOC Prime DetectFlow 开源版
AI 强化的检测情报。通过为您的团队配备经过 11 年检测情报训练的 AI,实现网络攻击的线速检测。
将您的日常工作从 SIEM 的琐碎优化提升到跨数据流水线、AIDR、EDR、数据湖和 SIEM 的检测编排。
了解更多信息请访问 **[socprime.com](https://socprime.com/)**
- 亚秒级 MTTD:0.005–0.01 秒,而 SIEM 需要 15 分钟以上
- 在 SIEM 摄取之前的传输过程中对事件进行标记和富化
- 随您的基础设施扩展,不受供应商强加的上限限制
- 对流式事件应用数以万计的 Sigma 规则
- 无需更改 SIEM;兼容现有的摄取架构
- 专为物理隔离和云连接的部署约束而设计(数据保留在您的控制之下)
**结果:在现有基础设施上实现 10 倍的规则容量。**
## 当前版本的特性
- **实时仪表板** - 流水线性能和指标的实时可视化
- **流水线管理** - 创建、配置和监控基于 Flink 的 ETL 流水线
- **日志源配置** - 定义用于事件转换的解析脚本和字段映射
- **规则管理** - 管理来自云端(SOC Prime 平台或 SigmaHQ GitHub 存储库)和本地存储库的 Sigma 规则
- **过滤器配置** - 创建预过滤器以减少误报
- **主题同步** - 发现并管理 Kafka 主题
- **热重载支持** - 无需重启流水线即可更新规则、过滤器和解析器
## 开发中的特性
- **与 SIEM、EDR 和数据湖集成**
- Splunk
- Microsoft Sentinel
- Elasticsearch
- OpenSearch
- **与 LLM 防火墙 AIDR Bastion 集成**
- **检测规则暂存**
- **AI 驱动的数据架构验证和重映射**
## 系统架构
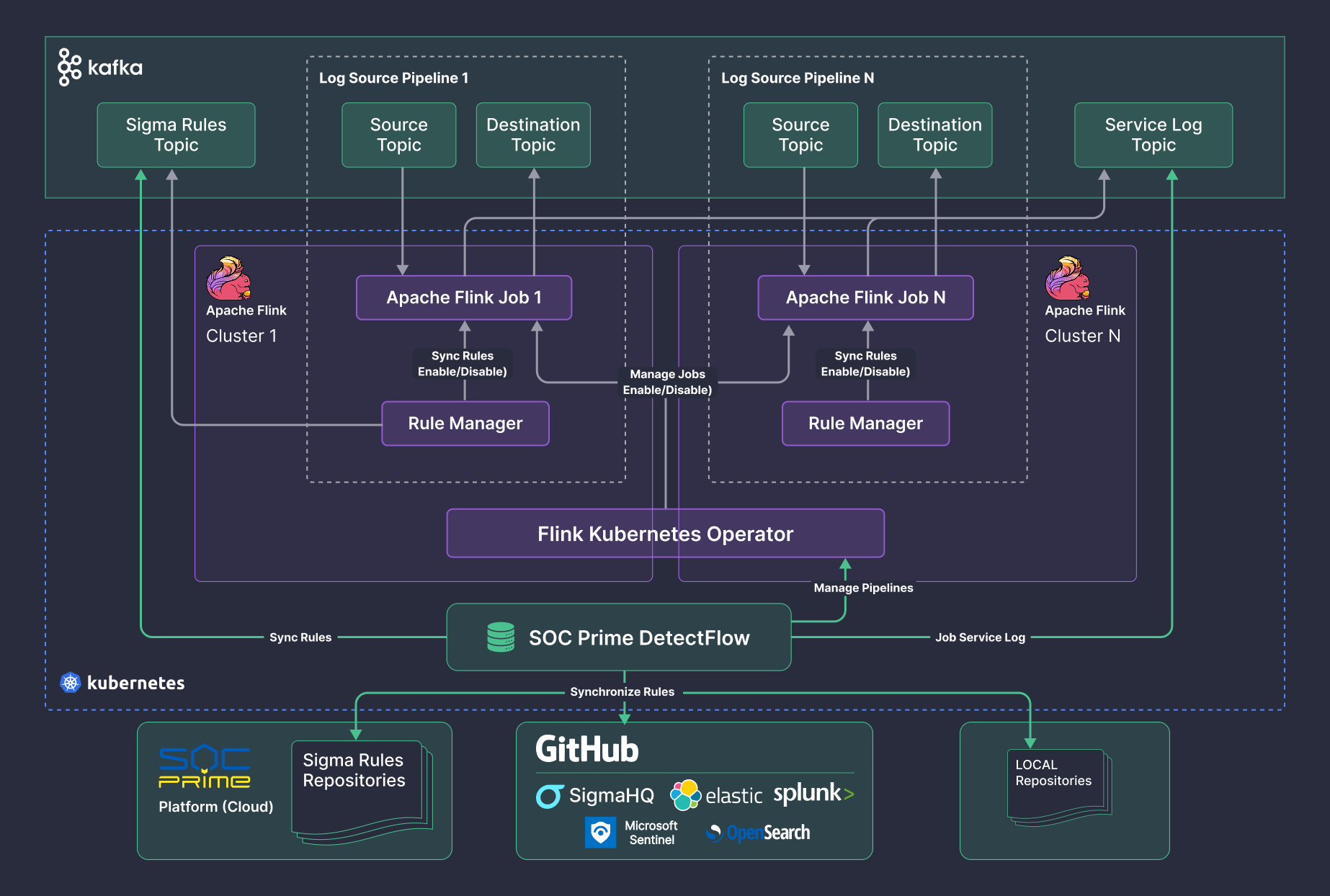
DetectFlow 由以下项目组成,每个项目都在单独的仓库中:
- [DetectFlow Backend](https://github.com/socprime/detectflow-backend)
- [DetectFlow UI](https://github.com/socprime/detectflow-ui)
- [DetectFlow MatchNode](https://github.com/socprime/detectflow-matchnode)
- [DetectFlow Schema Parser](https://github.com/socprime/detectflow-parser)
请查阅每个项目以获取更多详细信息。
## 系统要求
### 技术栈:
- Apache Kafka 3.8+ (https://kafka.apache.org/)
- Kubernetes 1.28+ (https://kubernetes.io/)
- PostgreSQL 14+ (https://www.postgresql.org/)
- Apache Flink 1.13+(可以与 DetectFlow 一起部署)(https://flink.apache.org/)
### 网络和基础设施:
- 对已部署资源的内部访问权限
- 已部署资源之间的网络连接
- 至少包含 3 个节点(工作节点)的 Kubernetes 集群(每个节点至少 8 vCPU,32 GiB RAM)。如需更详细的计算
- 允许的出站互联网访问:
- 访问 *.socprime.com 以获取 SOC Prime 平台的 API 访问权限,用于同步检测(可选,需要 API 密钥)
- 访问 *.github.com 以通过 GitHub 集成从公共开源存储库(包括 SigmaHQ、Microsoft、Splunk 和 Elastic)拉取开源检测(可选)
在计算所需资源方面,应考虑 DetectFlow 的以下组件,并将每个组件的单独要求相加来估算总量:
- **用户界面节点(管理面板)** 是管理事件匹配过程的控制中心。该组件至少需要 2 个 CPU 和 4 GB RAM
- **任务管理器节点**,控制流水线运行的默认组件(基于匹配节点,Apache Flink 技术)。该组件至少需要 1 个 CPU 和 4 GB RAM
- **匹配节点**,通过管理面板控制的流水线,将检测规则与 Apache Kafka 主题事件进行匹配。匹配节点(流水线)的数量是自定义的,您应该根据要创建的流水线数量来估算所需的 Kubernetes 集群资源。
## 部署
部署应由具备 Kubernetes 专业知识并拥有为本项目提供的 Kubernetes 集群管理员访问权限的人员执行。
K8S 的配置文件可以在此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 找到。
部署分为两部分:
1. Apache Flink(根据其官方部署建议)
2. DetectFlow 本身
此外,还需要一个 Apache Kafka 实例。如果您没有,可以使用 [Apache Kafka Quickstart](https://kafka.apache.org/quickstart/) 进行安装。
### Apache Flink 部署
1. 根据 [https://cert-manager.io/docs/installation/](https://cert-manager.io/docs/installation/) 安装 Cert Manager
2. 在此处了解 Apache Flink Kubernetes Operator 的核心概念:[https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-main/](https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-main/)
3. 使用 Helm 部署 Apache Flink Kubernetes Operator。
Helm chart 管理 Operator 的安装。要将 Operator(以及 helm chart)安装到特定的命名空间,请运行以下命令:
```
> helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.13.0/
Out: "flink-operator-repo" has been added to your repositories
> helm repo update
Out: Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "flink-operator-repo" chart repository
...Successfully got an update from the "bitnami" chart repository
Update Complete. ⎈Happy Helming!⎈
> helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator --namespace flink-operator --create-namespace
Out: NAME: flink-kubernetes-operator
LAST DEPLOYED: Thu Feb 5 12:07:08 2026
NAMESPACE: flink-operator
STATUS: deployed
REVISION: 1
TEST SUITE: None
```
来源:[https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-main/docs/operations/helm/](https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-main/docs/operations/helm/)
4. 为 Flink Sigma Detector 部署带有静态配置的 ConfigMap。
运行以下命令创建命名空间:
```
> kubectl create ns flink
Out: namespace/flink created
```
打开此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `flink-configmap.yaml` 并指定以下参数的值:
- `namespace: flink`
对于所有其他参数,请保留默认值。
运行以下命令:
```
> kubectl apply -f flink-configmap.yaml -n flink
Out: configmap/flink-config created
```
5. 为 Flink Sigma Detector 部署 Secrets。
打开此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `flink-secret.yaml` 并指定以下参数的 Base64 值(如果需要,否则保留默认值):
- `KAFKA_BOOTSTRAP_SERVERS:`
- `KAFKA_AUTH_METHOD:`
运行以下命令:
```
> kubectl apply -f flink-secret.yaml -n flink
Out: secret/flink-secret created
```
6. 为 Flink 状态存储部署 PersistentVolumeClaims。
打开此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `flink-pvcs.yaml` 并为每个 name: 块中的以下参数指定值:
- `namespace:`
- `storage:`
- `storageClassName:`
运行以下命令:
```
> kubectl apply -f flink-pvcs.yaml -n flink
Out:
persistentvolumeclaim/flink-checkpoints-pvc created
persistentvolumeclaim/flink-ha-pvc created
persistentvolumeclaim/flink-savepoints-pvc created
```
(可选)对于 PVC,通过运行以下命令为节点添加选择器/标签:
```
> kubectl label nodes NAME spec-node-ns-pod-disk=pvc-security
```
7. 为 Flink ServiceAccount 部署 RBAC 配置。它授予 Flink 创建和管理 TaskManager pod 的权限。
打开此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `flink-rbac.yaml` 并指定以下参数的值:
- `Namespace: flink`
运行以下命令:
```
> kubectl apply -f flink-rbac.yaml -n flink
Out:
serviceaccount/flink created
role.rbac.authorization.k8s.io/flink created
rolebinding.rbac.authorization.k8s.io/flink-role-binding created
role.rbac.authorization.k8s.io/event-reader created
rolebinding.rbac.authorization.k8s.io/grant-event-reader created
```
### 拉取 Docker 镜像
根据每个项目的 README.md 指南在本地构建 Docker 镜像:
- [DetectFlow Backend](https://github.com/socprime/detectflow-backend)
- [DetectFlow UI](https://github.com/socprime/detectflow-ui)
- [DetectFlow MatchNode](https://github.com/socprime/detectflow-matchnode)
1. 将镜像上传到您的 Kubernetes 集群可以访问的容器镜像仓库。
2. 编辑部署文件和 configmap 中的以下字段/变量,使镜像地址与您的容器镜像仓库匹配。
- `文件: admin-panel-be-deployment.yaml`
- `字段: spec/template/spec/containers/image`
- `文件: admin-panel-ui-deployment.yaml`
- `字段: spec/template/spec/containers/image`
- `文件: admin-panel-be-configmap.yaml`
- `变量: FLINK_IMAGE`
注意:这些文件将在后续步骤中应用。
### DetectFlow 部署
DetectFlow 由两部分组成:
- DetectFlow 后端
- DetectFlow UI
#### DetectFlow 后端部署
1. 为 DetectFlow 后端部署带有静态配置的 ConfigMap。
打开此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `admin-panel-be-configmap.yaml` 并指定以下参数的值:
- `KAFKA_BOOTSTRAP_SERVERS:`
设置 Kafka 服务器的 IP/主机名和端口。
运行以下命令:
```
> kubectl apply -f admin-panel-be-configmap.yaml -n flink
Out: configmap/admin-panel-be-config created
```
2. 为 DetectFlow 后端部署包含敏感数据配置的 Secret。
打开此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `admin-panel-be-secret.yaml` 并指定以下参数的值:
- `DATABASE_URL:`
`DATABASE_URL` 的格式如下:`postgresql+asyncpg://user:password@postgres_url:postgres_port/db_name`。它应该转换为 Base64。
运行以下命令:
```
> kubectl apply -f admin-panel-be-secret.yaml -n flink
Out: secret/admin-panel-be-secret created
```
3. 使用此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `admin-panel-be-pvc.yaml` 为 DetectFlow 后端部署 PersistentVolumeClaims。
运行以下命令:
```
> kubectl apply -f admin-panel-be-pvc.yaml -n flink
Out: persistentvolumeclaim/admin-panel-metrics-pvc created
```
4. 使用此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `admin-panel-be-deployment.yaml` 为 DetectFlow 后端创建 Deployment 资源。
运行以下命令:
```
> kubectl apply -f admin-panel-be-deployment.yaml -n flink
Out: deployment.apps/admin-panel-be created
```
5. 使用此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `admin-panel-be-service.yaml` 为 DetectFlow 后端部署网络服务资源。
运行以下命令:
```
> kubectl apply -f admin-panel-be-service.yaml -n flink
Out: service/admin-panel-be created
```
6. 通过以下链接检查 Admin-Panel-Backend-API 是否正在运行且可访问:
`http://network_service_ip:8000`
#### DetectFlow UI 部署
1. 为 DetectFlow UI 部署带有静态配置的 ConfigMap。
打开此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `admin-panel-ui-configmap.yaml` 并指定以下参数的值:
注意:`NAME.NAMESPACE.CLUSTER_DOMAIN_NAME`(默认:`svc.cluster.local`)
- `VITE_PREVIEW_ALLOWED_HOSTS:`
设置 admin-panel-be 的内部主机名,例如:`admin-panel-be.flink.svc.cluster.local`
运行以下命令:
```
> kubectl apply -f admin-panel-ui-configmap.yaml -n flink
Out: configmap/admin-panel-ui-config created
```
2. 使用此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `admin-panel-ui-deployment.yaml` 为 DetectFlow UI 创建 Deployment 资源。
运行以下命令:
```
> kubectl apply -f admin-panel-ui-deployment.yaml -n flink
Out: deployment.apps/admin-panel-ui created
```
3. 使用此 [folder](https://github.com/socprime/detectflow-main/tree/main/detectflow_kubernetes_config_files) 中的 `admin-panel-ui-service.yaml` 为 DetectFlow UI 部署网络服务资源。
运行以下命令:
```
> kubectl apply -f admin-panel-ui-service.yaml -n flink
Out: service/admin-panel-ui created
```
4. 通过以下链接检查 Admin-Panel-UI 是否正在运行且可访问:
- `http://network-service-ip:4173`
默认凭据:
- 邮箱:`admin@soc.local`
- 密码:`admin`
## 快速入门
DetectFlow 将来自 Kafka 主题的日志事件与 Sigma 检测规则进行匹配,并为每个匹配的事件标记与匹配规则相关的附加元数据:
- ID
- 标题 (Title)
- 严重程度 (Severity)
- MITRE ATT&CK (子) 技术 ID
开始使用:
1. 确保您的 Kafka 实例具有:
- 包含您想要与检测规则匹配的日志源事件的主题(DetectFlow 的源主题)
- 用于存放由 SIEM/EDR/数据湖消费的已标记事件的主题(DetectFlow 的目标主题)
2. 创建包含 Sigma 格式检测规则的存储库:
- 本地存储库
- 与 SOC Prime 平台同步的云存储库(可选,需要 API 密钥)
- 与 GitHub 公共开源存储库(包括 SigmaHQ、Microsoft、Splunk 和 Elastic)同步的云存储库(可选)
3. 创建日志源配置以解析事件并将其字段映射到检测规则的字段。
4. (可选)创建过滤器以在匹配之前过滤掉某些事件。
5. 使用前面步骤中的主题、存储库、日志源和过滤器创建流水线。
6. 在仪表板上监控流水线运行情况。
7. 使用标记的事件进行威胁推理:将它们传递给关联 ML 模型(如 MITRE TIE),或直接在您的 SIEM 中根据添加到事件的元数据构建聚合。
### 访问应用程序
1. 导航到管理面板 URL
2. 使用部署时设置的凭据登录
3. 身份验证成功后,您将被重定向到仪表板
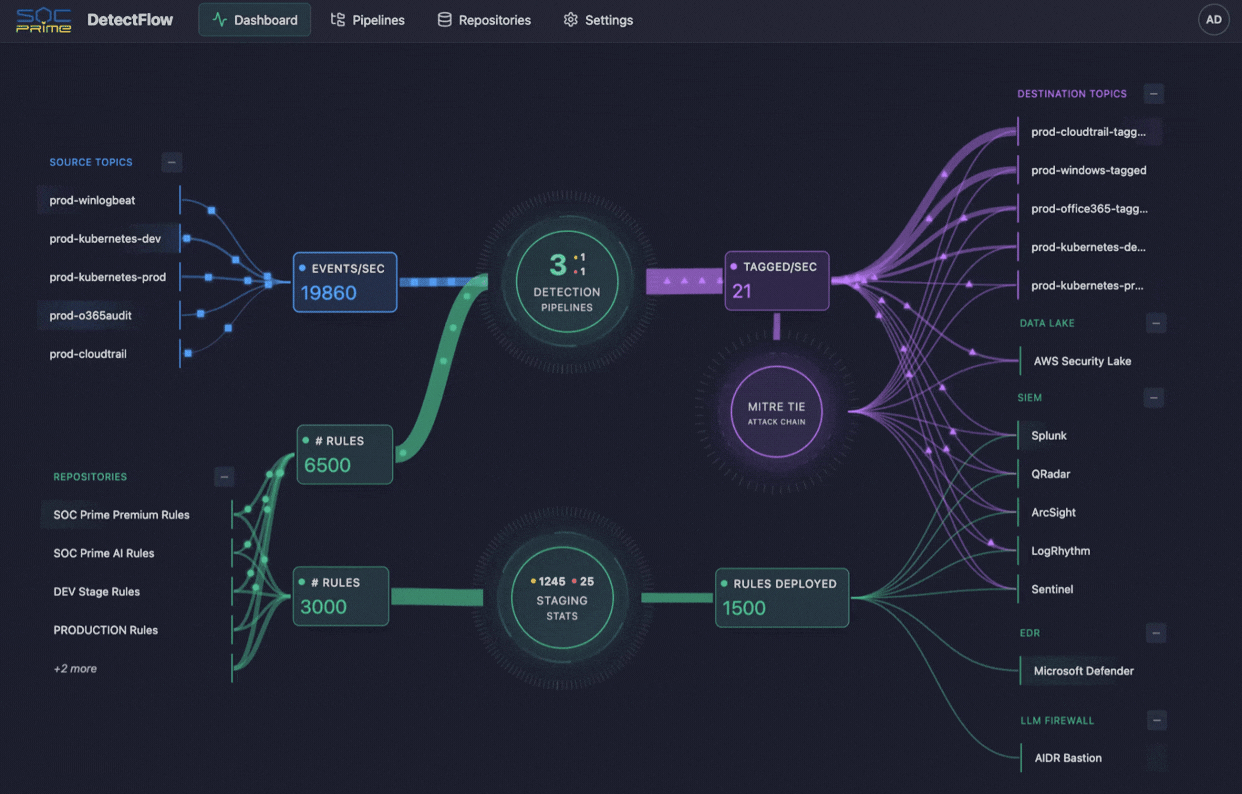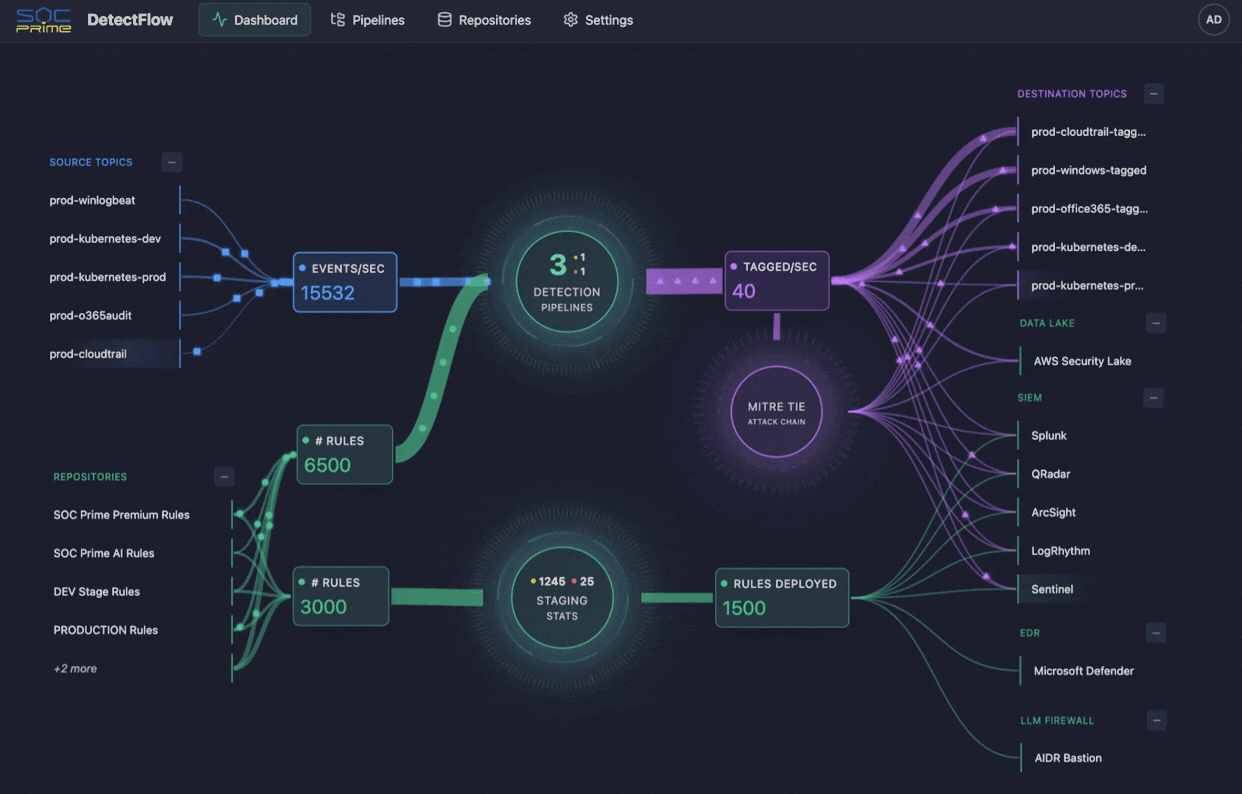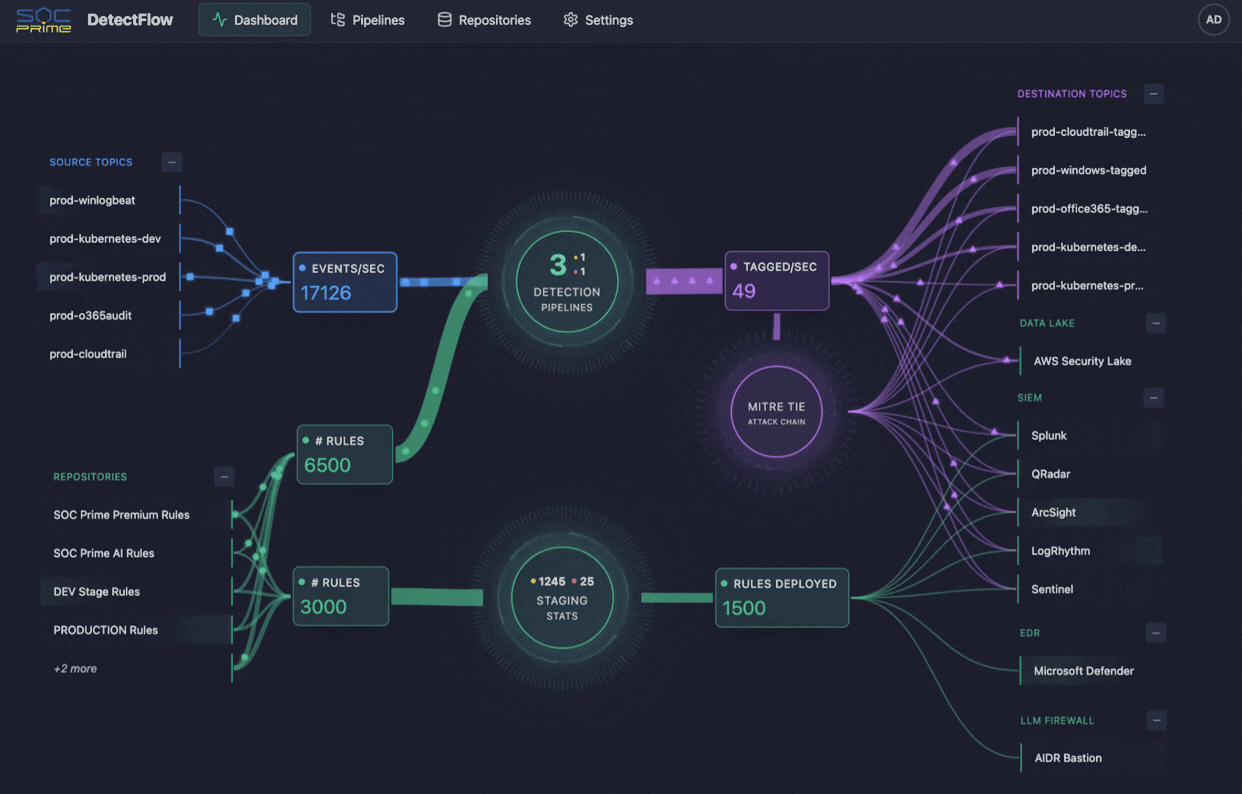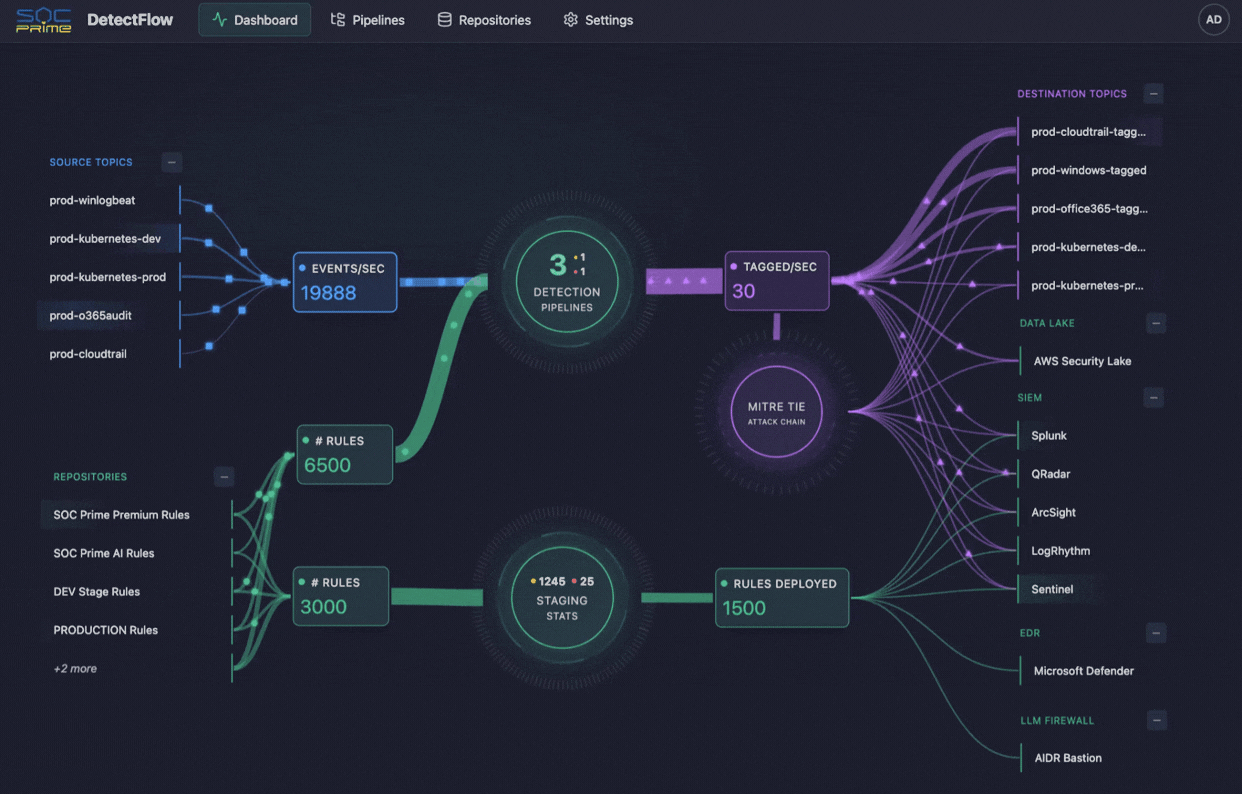
### 仪表板
仪表板通过实时指标和可视化提供检测流水线基础设施的实时概览。
仪表板中心显示一个交互式图表,展示:
- **源主题 (Source Topics)**(左上方) - 将事件输入流水线的 Kafka 主题
- **存储库 (Repositories)**(左下方) - 带有活动规则计数的规则存储库
- **流水线 (Pipelines)**(中心) - 活动流水线
- **目标主题 (Destination Topics)**(右侧) - 写入标记事件的输出主题
**交互:**
- 点击任何节点以查看详细信息
- 节点根据其状态和活动进行颜色编码
- 节点之间的连接代表数据流
点击流水线图标查看所有流水线的详细统计信息:
- 流水线名称和状态
- 源主题和目标主题
- 输入/输出吞吐量(每秒事件数)
- Kafka 消费者延迟(待处理记录)
- 处理状态(运行中、暂停、失败)
### 流水线
流水线是核心处理单元,负责从 Kafka 消费事件、应用检测规则并输出标记的事件。
#### 创建流水线
1. 导航到 **Pipelines** → **New Pipeline**
2. 填写必填字段:
必填字段
- **Pipeline Name** - 流水线的唯一标识符
- **Source Topic** - 要从中消费事件的 Kafka 主题(必须存在)
- **Destination Topic** - 要写入标记事件的 Kafka 主题(必须存在)
- **Repositories** - 要应用的一个或多个规则存储库(至少需要一个)
- **Log Source** - 预先配置的带有解析脚本和映射的日志源。**重要提示:** 确保流水线的源主题和存储库与 LogSource 配置匹配,以获得最佳结果。
可选字段
- **Save Untagged Events** - 切换是否保留不匹配任何规则的事件
- **Filters** - 用于减少误报的预过滤器(可选)
- **Custom Fields** - YAML 格式的静态键值对,用于富化所有事件
**重要提示:**
- 更改 **Source Topic** 或 **Destination Topic** 以及启用或禁用流水线需要重启流水线(60-90 秒停机时间)
- 更改 **Repositories**、**Filters**、**Log Source** 或 **Custom Fields** 使用热重载(零停机时间)
- 流水线必须处于 **Enabled** 状态更改才能生效
#### 启用/禁用流水线
- **Enable** - 在 Kubernetes 中创建 FlinkDeployment 并开始处理
- **Disable** - 停止处理并移除 FlinkDeployment
### 日志源
日志源定义了在规则匹配之前如何解析和转换原始事件。每个日志源包含:
1. **解析脚本 (Parsing Script)** - 用于提取和转换字段的 DSL 查询
2. **字段映射 (Field Mapping)** - 用于将解析后的字段与 Sigma 规则字段对齐的 YAML 映射
#### 创建日志源
1. 导航到 **Settings** → **Log Sources** → **New Log Source**
2. 填写必填字段:
- **Name** - 日志源的唯一标识符
- **Source Topics** - 用于测试的 Kafka 主题(至少需要一个)
- **Parsing Script** - 使用解析器函数的 DSL 查询(参见 [Parser Functions Reference](https://github.com/socprime/detectflow-parser))
- **Mapping (YAML)** - 字段映射配置
- **Repositories** - 用于生成映射的存储库
### 存储库与规则
存储库是 Sigma 检测规则的集合。有两种类型:
1. **云存储库 (Cloud Repositories)** - 通过 API 从 SOC Prime 平台或开源 GitHub 存储库同步
2. **本地存储库 (Local Repositories)** - 手动创建和管理
有关支持的 Sigma 规则范围的详细信息可以在此处找到 [here](https://github.com/socprime/detectflow-parser/blob/main/SUPPORTED_SIGMAS.md)。
#### 云存储库
云存储库通过 API 自动同步:
- 来自 SOC Prime 平台(需要 API 密钥)
- 来自开源 GitHub 存储库
#### 本地存储库
本地存储库允许您独立创建和管理规则。
创建本地存储库
1. 导航到 **Settings** → **Repositories**
2. 点击 **New Repository**(或 **+** 按钮)
3. 输入存储库名称
4. 点击 **Create Repository**
#### 管理本地存储库中的规则
规则必须采用 Sigma YAML 格式。
**添加规则:**
1. 从侧边栏选择一个本地存储库
2. 点击 **Add Rule** 按钮
3. 输入规则名称
4. 在编辑器中粘贴 Sigma 规则 YAML
5. 点击 **Create**
**批量上传规则:**
1. 选择一个本地存储库
2. 点击 **Upload** 按钮
3. 拖放 YAML 文件或点击选择。您也可以上传受密码保护的压缩包。
4. 规则将被自动解析并上传
5. 查看上传结果
### 主题 (Topics)
主题代表您集群中的 Kafka 主题。系统会自动发现主题并显示它们与流水线的关联。
主题用于:
1. **流水线配置** - 作为源主题和目标主题
2. **日志源测试** - 作为解析脚本的测试主题
3. **仪表板可视化** - 显示在流水线图中
**注意:** 主题必须先在 Kafka 中存在,然后才能在流水线中使用。
### 过滤器
过滤器是检测前的过滤器,通过在规则匹配之前过滤事件来减少误报。
#### 创建过滤器
1. 导航到 **Settings** → **Filters** → **New Filter**
2. 填写必填字段:
必填字段
- **Filter Name** - 过滤器的唯一标识符
- **Filter (YAML)** - YAML 格式的 Sigma 检测条件
过滤器使用 Sigma 检测语法:
```
detection:
condition: selection
selection:
EventID: 4624
LogonType: 3
SubjectUserName|re: '.*\$' # Exclude machine accounts
```
过滤器逻辑:
- 过滤器在规则匹配 **之前** 应用
- 匹配过滤器条件的事件将从规则匹配中 **排除**
- 可以组合多个过滤器(AND 逻辑)
- 过滤器使用与 Sigma 检测条件相同的语法
## 许可证
本 SOC Prime DetectFlow 软件根据双重许可模型提供:(i) 欧盟公共许可证 1.2 版和 (ii) SOC Prime 商业许可证。根据您的预期用途,您必须选择这两种许可证之一。有关详细信息,请参阅 [LICENSE](LICENSE) 文件。
标签:AI, AMSI绕过, Apache Flink, Apex, Clean Code, CPE识别, CVE扫描, EDR, ETL, Gradle集成, JavaCC, Kafka, Maven集成, OWASP, PMD, SCA, Sigma 规则, SOC Prime, SonarQube插件, 事件富化, 人工智能, 代码规范检查, 供应链安全, 依赖检查, 反模式检测, 域名分析, 威胁情报, 威胁检测, 子域名突变, 安全运营中心, 实时流处理, 实时监控, 开发工具, 开发者工具, 开源安全工具, 数据湖, 数据管道, 机器学习, 测试用例, 用户模式Hook绕过, 网络安全, 网络攻击检测, 网络映射, 脆弱性评估, 自动化代码审查, 自动化安全运营, 请求拦截, 软件工程, 软件成分分析, 逆向工具, 逆向工程平台, 隐私保护