
面向 Apple Silicon 的 MLX 推理服务器
自托管的推理服务器,可在 Apple Silicon 上运行 LLM、VLM 和图像生成模型。
兼容 OpenAI + Anthropic + Ollama 的 HTTP API。自托管;无需第三方 API 密钥。
原生 MTP 工件检测和家族特定的缓存策略门控,使推测/缓存设置明确且模型安全。
寻找原生 Swift macOS 应用或 Swift 推理引擎?请访问 osaurus.ai。







快速开始 •
模型支持 •
功能特性 •
图像生成 •
API •
桌面应用 •
JANG •
CLI •
配置 •
贡献 •
한국어
 |
 |
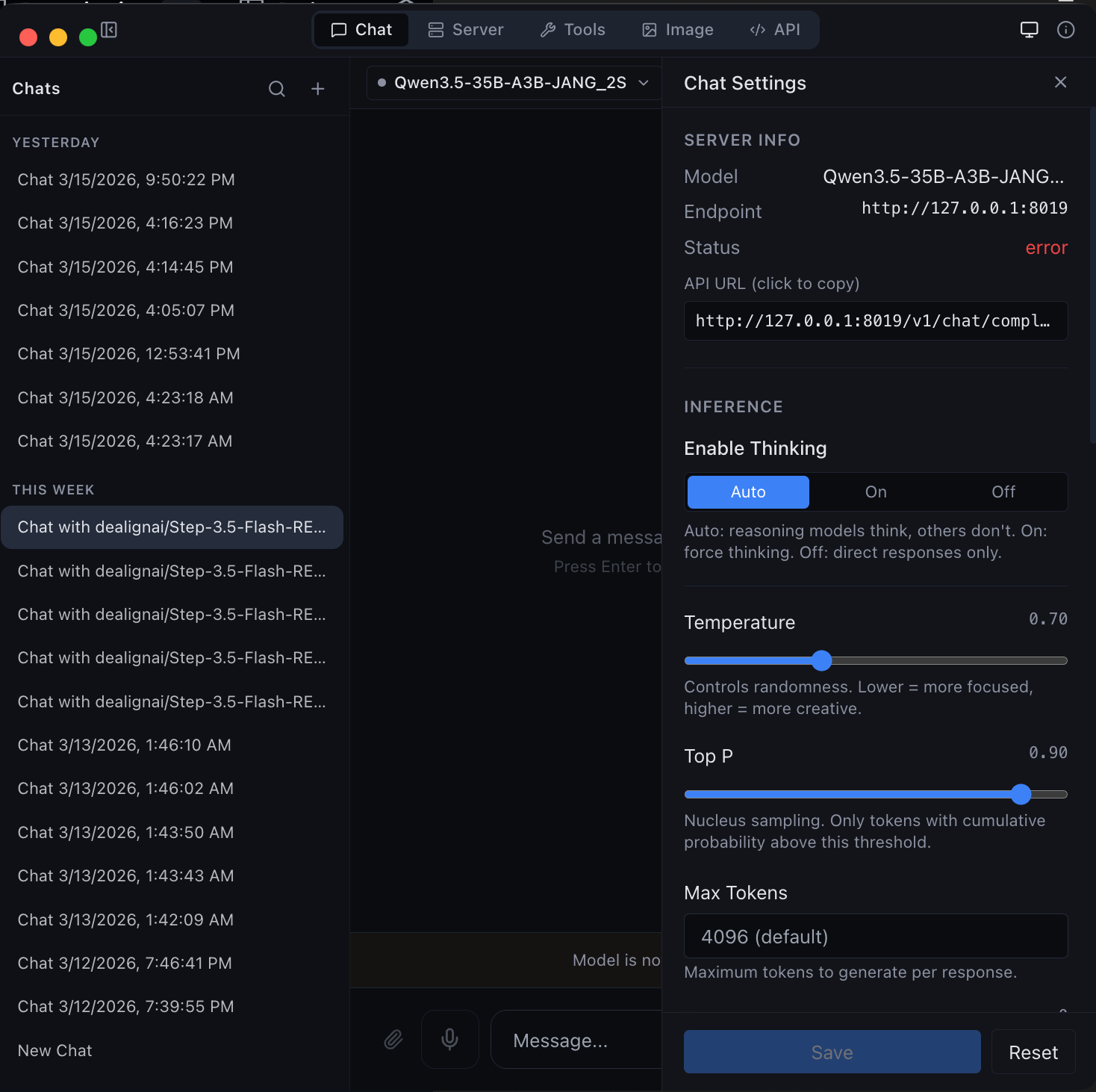
| Chat with any MLX model -- thinking mode, streaming, and syntax highlighting |
Agentic chat with full coding capabilities -- tool use and structured output |
## 快速开始
### 通过 PyPI 安装
已在 [PyPI 上发布为 `vmlx`](https://pypi.org/project/vmlx/) -- 一条命令即可安装并运行:
```
# 推荐:uv(快速,无需处理虚拟环境)
brew install uv
uv tool install vmlx
vmlx serve mlx-community/Qwen3-8B-4bit
# 或:pipx(与系统 Python 隔离)
brew install pipx
pipx install vmlx
vmlx serve mlx-community/Qwen3-8B-4bit
# 或:在虚拟环境中使用 pip
python3 -m venv ~/.vmlx-env && source ~/.vmlx-env/bin/activate
pip install vmlx
vmlx serve mlx-community/Qwen3-8B-4bit
```
vMLX 推理服务器现在正在 `http://0.0.0.0:8000` 上运行,提供 OpenAI + Anthropic 兼容的 API。可与来自 [mlx-community](https://huggingface.co/mlx-community) 的任何模型配合使用 -- 数千款模型已准备就绪。
### 或者下载桌面应用
获取 [MLX Studio](https://github.com/jjang-ai/mlxstudio/releases/latest) -- 一款原生 macOS 应用,提供聊天界面、模型管理、图像生成和开发者工具。无需终端。只需下载 DMG 文件并拖入“应用程序”文件夹。
### 与 OpenAI SDK 配合使用
```
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
response = client.chat.completions.create(
model="local",
messages=[{"role": "user", "content": "Hello!"}],
stream=True,
)
for chunk in response:
print(chunk.choices[0].delta.content or "", end="", flush=True)
```
### 与 Anthropic SDK 配合使用
```
import anthropic
client = anthropic.Anthropic(base_url="http://localhost:8000/v1", api_key="not-needed")
message = client.messages.create(
model="local",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello!"}],
)
print(message.content[0].text)
```
### 与 curl 配合使用
```
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"messages": [{"role": "user", "content": "Hello!"}],
"stream": true
}'
```
## 模型支持
vMLX 可运行任何 MLX 模型。指向一个 HuggingFace 仓库或本地路径即可开始。
| 类型 | 模型 |
|------|--------|
| **文本 LLM** | Qwen 2/2.5/3/3.5/3.6, Llama 3/3.1/3.2/3.3/4, Mistral/Mixtral, **Mistral-Medium-3.5** (ministral3), Mistral-Small-4, Gemma 3/4, Phi-4, DeepSeek V2/V3/V4, GLM-4/5, MiniMax M2.5/M2.7, Nemotron, **Laguna** (poolside), **ZAYA** (CCA + MoE), Kimi K2.5/K2.6, StepFun, 以及任何 mlx-lm 模型 |
| **视觉 LLM** | Qwen-VL, Qwen3.5-VL / Qwen3.6-VL, Pixtral, InternVL, LLaVA, Gemma 3n / 4-VL, Mistral-Medium-3.5 (PIXTRAL) |
| **多模态全能** | **Nemotron-3-Nano-Omni** (文本 + 图像 + 音频 + 视频) — 配备 Parakeet 音频编码器 + RADIO ViT 视觉塔;通过 OmniMultimodalDispatcher 路由,支持 `/v1/chat/completions`, `/v1/messages`, `/v1/responses`, `/api/chat` |
| **MoE 模型** | Qwen 3.5/3.6 MoE (A3B/A10B), Mixtral, DeepSeek V2/V3/V4, MiniMax M2.5/M2.7, Llama 4, Laguna (256 个路由专家,top-8) |
| **混合 SSM** | Nemotron-H, Jamba, GatedDeltaNet (Mamba + Attention), Qwen3.5-A3B 混合模型, Granite MoE 混合模型, LFM2 |
| **图像生成** | Flux Schnell/Dev, Z-Image Turbo (通过 mflux) |
| **图像编辑** | Qwen Image Edit (通过 mflux) |
| **嵌入** | 任何兼容 mlx-lm 的嵌入模型 |
| **重排序** | 交叉编码器重排序模型 |
| **音频** | Kokoro TTS, Whisper STT (通过 mlx-audio) |
## 功能特性
### 推理引擎
| 功能 | 描述 |
|---------|-------------|
| **连续批处理** | 高效处理多个并发请求 |
| **前缀缓存** | 为重复的提示词复用 KV 状态 — 使后续消息响应即时 |
| **分页 KV 缓存** | 基于块的缓存,支持内容寻址去重 |
| **KV 缓存量化** | 将缓存状态压缩为 q4/q8,节省 2-4 倍内存 |
| **磁盘缓存 (L2)** | 将提示词缓存持久化到 SSD — 服务器重启后依然存在 |
| **块磁盘缓存** | 与分页 KV 缓存配对的每个块持久化缓存 |
| **推测解码** | 小型草稿模型提议 token,实现 20-90% 的速度提升 |
| **提示查找解码** | 无需草稿模型 — 复用提示/上下文中的 n-gram 匹配。最适合结构化或重复输出(代码、JSON、模式)。通过 `--enable-pld` 启用。 |
| **JIT 编译** | `mx.compile` Metal 内核融合 (实验性) |
| **混合 SSM 支持** | 正确处理 Mamba/GatedDeltaNet 层与注意力机制 |
| **分布式计算** | 通过 Thunderbolt 5 / 以太网 / WiFi 在多台 Mac 上进行流水线并行 |
### 分布式推理 (多 Mac)
在单台 Mac 内存不足时,跨 2 台以上机器运行大型模型。每台 Mac 加载一部分 transformer 层,并通过网络通信隐藏状态。
```
# 在工作机 Mac 上:
pip install vmlx
vmlx-worker --secret mysecret
# 在协调机 Mac 上(运行服务器):
vmlx serve JANGQ-AI/Qwen3.5-Coder-Rerank-397B-A27B-JANG_2L --distributed --cluster-secret mysecret
```
| 功能 | 描述 |
|---------|-------------|
| **流水线并行** | 跨节点拆分层 — 隐藏状态 (~8KB/步) 顺序流动 |
| **自动发现** | Bonjour mDNS, UDP 广播, HTTP 探测, Tailscale, 缓存的对等点, 手动 IP |
| **能力评分选举** | 最强大的 Mac 自动成为协调器 |
| **任何网络均可** | TB5 (120 Gbps), 10GbE, 1GbE, WiFi, Tailscale — 流水线并行不受带宽限制 |
| **JANG 支持** | 每个工作节点从 JANG safetensors (mmap) 加载其层范围 |
| **实时节点列表** | 桌面应用显示发现的节点、链接类型、延迟、层分配 |
| **集群 API** | `/v1/cluster/status`, `/v1/cluster/nodes`, `/v1/cluster/scan` REST 端点 |
### 5 层缓存架构
```
Request -> Tokens
|
L1: Memory-Aware Prefix Cache (or Paged Cache)
| miss
L2: Disk Cache (or Block Disk Store)
| miss
Inference -> float16 KV states
|
KV Quantization -> q4/q8 for storage
|
Store back into L1 + L2
```
### 工具调用
针对每个主要模型系列的自动检测解析器:
`qwen` - `llama` - `mistral` - `hermes` - `deepseek` - `glm47` - `minimax` - `nemotron` - `granite` - `functionary` - `xlam` - `kimi` - `step3p5`
### 推理/思考模式
提取 `
` 块的自动检测推理解析器:
`qwen3` (Qwen3, QwQ, StepFun) - `minimax_m2` (MiniMax M2/M2.5/M2.7) - `deepseek_r1` (DeepSeek R1, Gemma 3, GLM, Phi-4) - `openai_gptoss` (GLM Flash, GPT-OSS)
### 音频
| 功能 | 描述 |
|---------|-------------|
| **文本转语音** | 通过 mlx-audio 使用 Kokoro TTS — 多种声音,流式输出 |
| **语音转文本** | 通过 mlx-audio 使用 Whisper STT — 转录和翻译 |
## 图像生成与编辑
通过 [mflux](https://github.com/filipstrand/mflux) 使用 Flux 模型在本地生成和编辑图像。
```
pip install vmlx[image]
# 图像生成
vmlx serve schnell # or dev, z-image-turbo
vmlx serve ~/.mlxstudio/models/image/flux1-schnell-4bit
# 图像编辑
vmlx serve qwen-image-edit # instruction-based editing
```
### 生成 API
```
curl http://localhost:8000/v1/images/generations \
-H "Content-Type: application/json" \
-d '{
"model": "schnell",
"prompt": "A cat astronaut floating in space with Earth in the background",
"size": "1024x1024",
"n": 1
}'
```
```
# Python(OpenAI SDK)
response = client.images.generate(
model="schnell",
prompt="A cat astronaut floating in space",
size="1024x1024",
n=1,
)
```
### 编辑 API
```
# 使用文本提示编辑图像(Flux Kontext / Qwen Image Edit)
curl http://localhost:8000/v1/images/edits \
-H "Content-Type: application/json" \
-d '{
"model": "flux-kontext",
"prompt": "Change the background to a sunset",
"image": "",
"size": "1024x1024",
"strength": 0.8
}'
```
```
# Python
import base64
with open("source.png", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = requests.post("http://localhost:8000/v1/images/edits", json={
"model": "flux-kontext",
"prompt": "Make the sky purple",
"image": image_b64,
"size": "1024x1024",
"strength": 0.8,
})
```
### 支持的图像模型
**生成模型:**
| 模型 | 步数 | 速度 | 内存 |
|-------|-------|-------|--------|
| **Flux Schnell** | 4 | 最快 | ~6-24 GB |
| **Z-Image Turbo** | 4 | 快 | ~6-24 GB |
| **Flux Dev** | 20 | 慢 | ~6-24 GB |
**编辑模型:**
| 模型 | 步数 | 类型 | 内存 |
|-------|-------|------|--------|
| **Qwen Image Edit** | 28 | 基于指令的编辑 | ~54 GB |
## API参考
### API 网关
桌面应用在单个端口(默认 `8080`)上运行一个 **API 网关**,通过名称将请求路由到所有已加载的模型。同时运行多个模型,并通过一个 URL 访问它们。
```
# 通过网关访问所有模型
curl http://localhost:8080/v1/chat/completions \
-d '{"model": "Qwen3.5-122B", "messages": [{"role": "user", "content": "Hi"}]}'
# 也可配合 Ollama CLI 使用
OLLAMA_HOST=http://localhost:8080 ollama run Qwen3.5-122B
```
该网关支持 **OpenAI**、**Anthropic** 和 **Ollama** 线格式。在 API 标签页中配置端口。
### 端点
**OpenAI / Anthropic**
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `POST` | `/v1/chat/completions` | OpenAI Chat Completions API (流式 + 非流式) |
| `POST` | `/v1/messages` | Anthropic Messages API |
| `POST` | `/v1/responses` | OpenAI Responses API |
| `POST` | `/v1/completions` | 文本补全 |
| `POST` | `/v1/images/generations` | 图像生成 |
| `POST` | `/v1/images/edits` | 图像编辑 (Qwen Image Edit) |
| `POST` | `/v1/embeddings` | 文本嵌入 |
| `POST` | `/v1/rerank` | 文档重排序 |
| `POST` | `/v1/audio/transcriptions` | 语音转文本 (Whisper) |
| `POST` | `/v1/audio/speech` | 文本转语音 (Kokoro) |
| `GET` | `/v1/models` | 列出已加载模型 |
| `GET` | `/v1/cache/stats` | 缓存统计 |
| `GET` | `/health` | 服务器健康检查 |
**Ollama**
| 方法 | 路径 | 描述 |
|--------|------|-------------|
| `POST` | `/api/chat` | 聊天补全 (NDJSON 流式) |
| `POST` | `/api/generate` | 文本生成 (NDJSON 流式) |
| `GET` | `/api/tags` | 列出已加载模型 |
| `POST` | `/api/show` | 模型详情 |
| `POST` | `/api/embeddings` | 生成嵌入 |
### curl 示例
**聊天补全(流式)**
```
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"messages": [{"role": "user", "content": "Explain quantum computing in 3 sentences."}],
"stream": true,
"temperature": 0.7
}'
```
**带思考模式的聊天补全**
```
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"messages": [{"role": "user", "content": "Solve: what is 23 * 47?"}],
"enable_thinking": true,
"stream": true
}'
```
**工具调用**
```
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"messages": [{"role": "user", "content": "What is the weather in Tokyo?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City name"}
},
"required": ["location"]
}
}
}]
}'
```
**Anthropic Messages API**
```
curl http://localhost:8000/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: not-needed" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "local",
"max_tokens": 1024,
"messages": [{"role": "user", "content": "Hello!"}]
}'
```
**嵌入**
```
curl http://localhost:8000/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"input": "The quick brown fox jumps over the lazy dog"
}'
```
**文本转语音**
```
curl http://localhost:8000/v1/audio/speech \
-H "Content-Type: application/json" \
-d '{
"model": "kokoro",
"input": "Hello, welcome to vMLX!",
"voice": "af_heart"
}' --output speech.wav
```
**语音转文本**
```
curl http://localhost:8000/v1/audio/transcriptions \
-F file=@audio.wav \
-F model=whisper
```
**图像生成**
```
curl http://localhost:8000/v1/images/generations \
-H "Content-Type: application/json" \
-d '{
"model": "schnell",
"prompt": "A mountain landscape at sunset",
"size": "1024x1024"
}'
```
**重排序**
```
curl http://localhost:8000/v1/rerank \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"query": "What is machine learning?",
"documents": [
"ML is a subset of AI",
"The weather is sunny today",
"Neural networks learn from data"
]
}'
```
**缓存统计**
```
curl http://localhost:8000/v1/cache/stats
```
**健康检查**
```
curl http://localhost:8000/health
```
## 桌面应用
vMLX 包含一个原生 macOS 桌面应用(MLX Studio),提供 5 种模式:
| 模式 | 描述 |
|------|-------------|
| **聊天** | 对话界面,包含聊天记录、思考模式、工具调用、智能体编码 |
| **服务器** | 管理模型会话 — 启动、停止、配置、监控 |
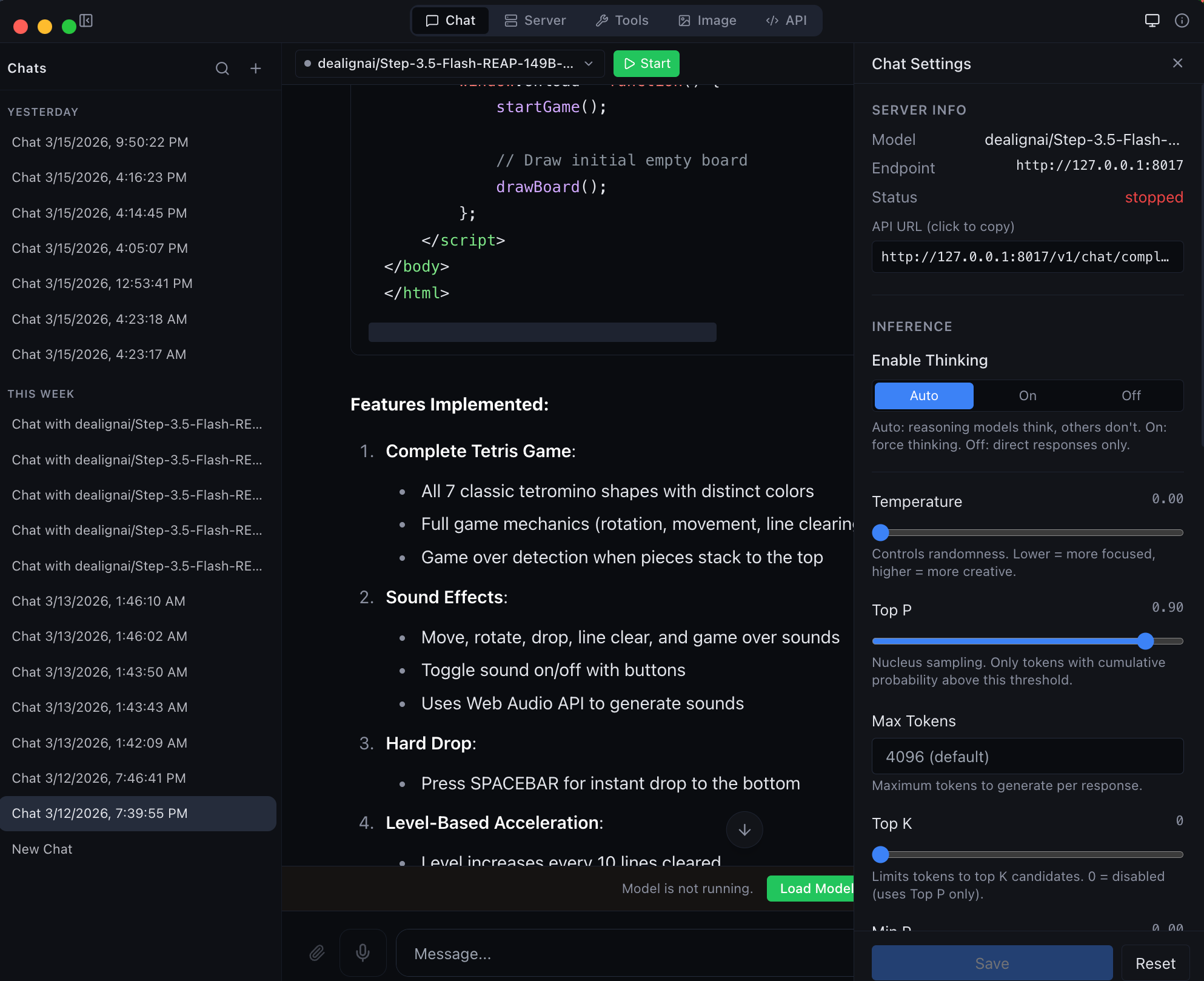
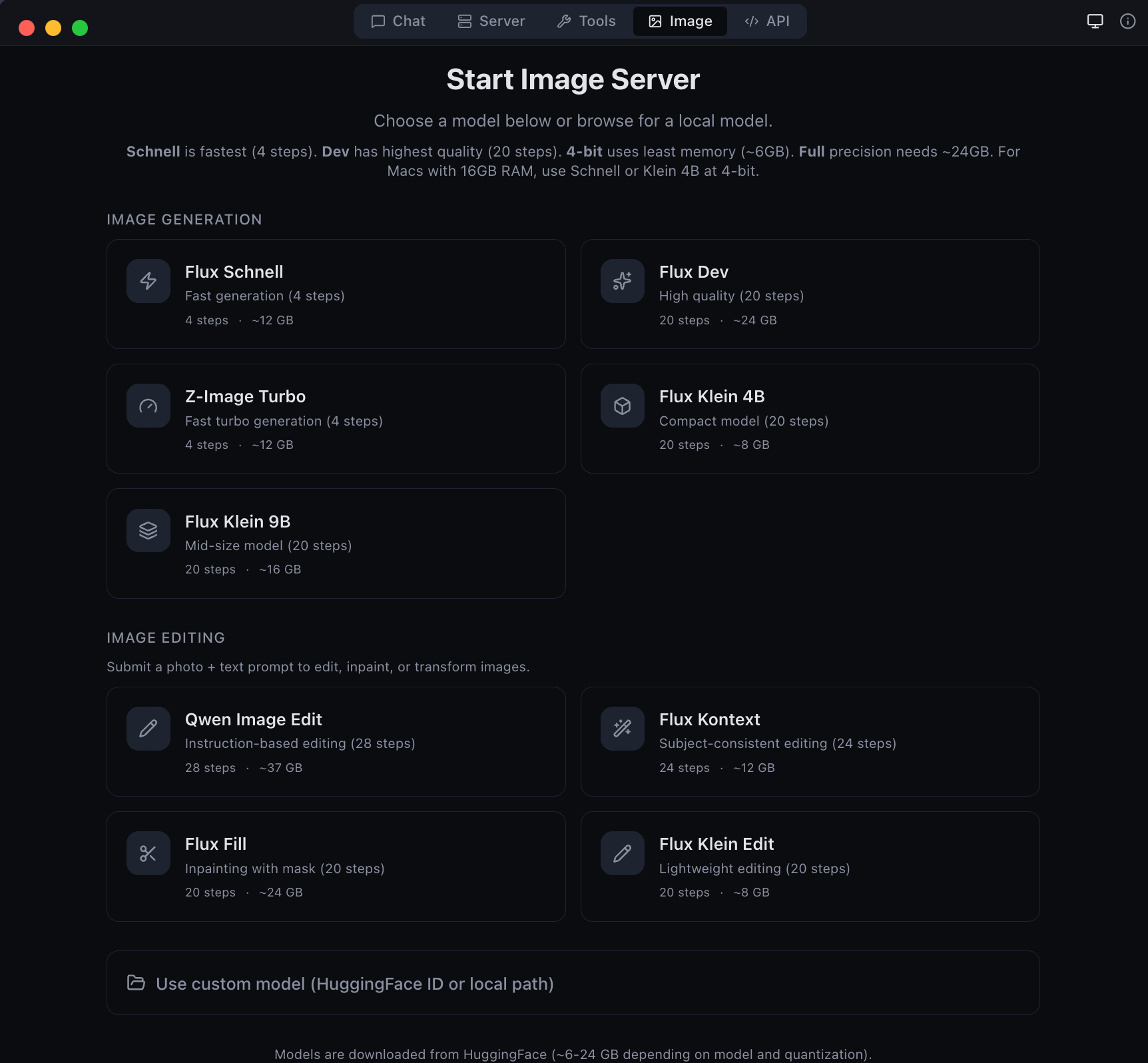
| **图像** | 使用 Flux、Kontext、Qwen 和 Fill 模型进行文本到图像生成和图像编辑 |
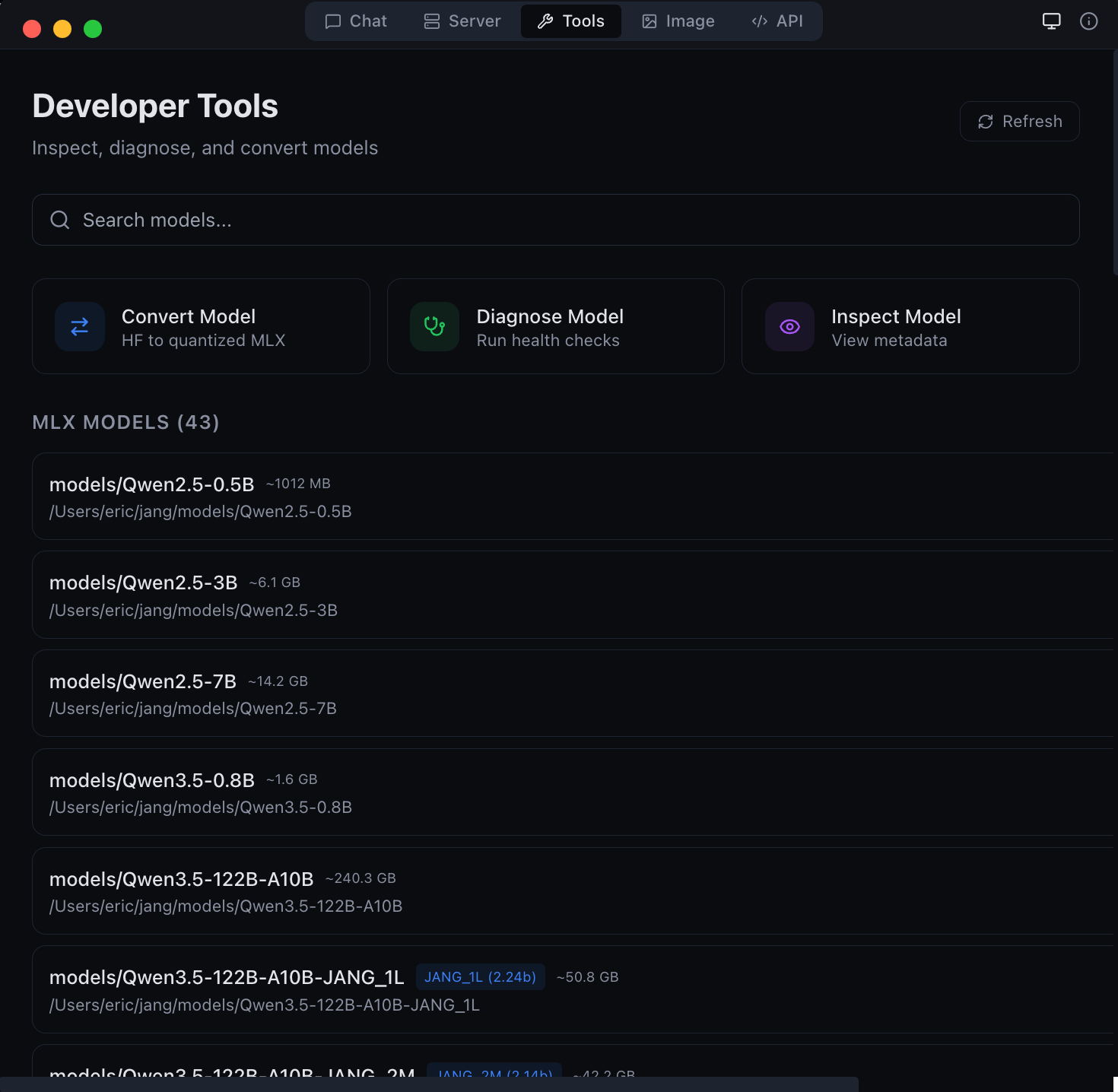
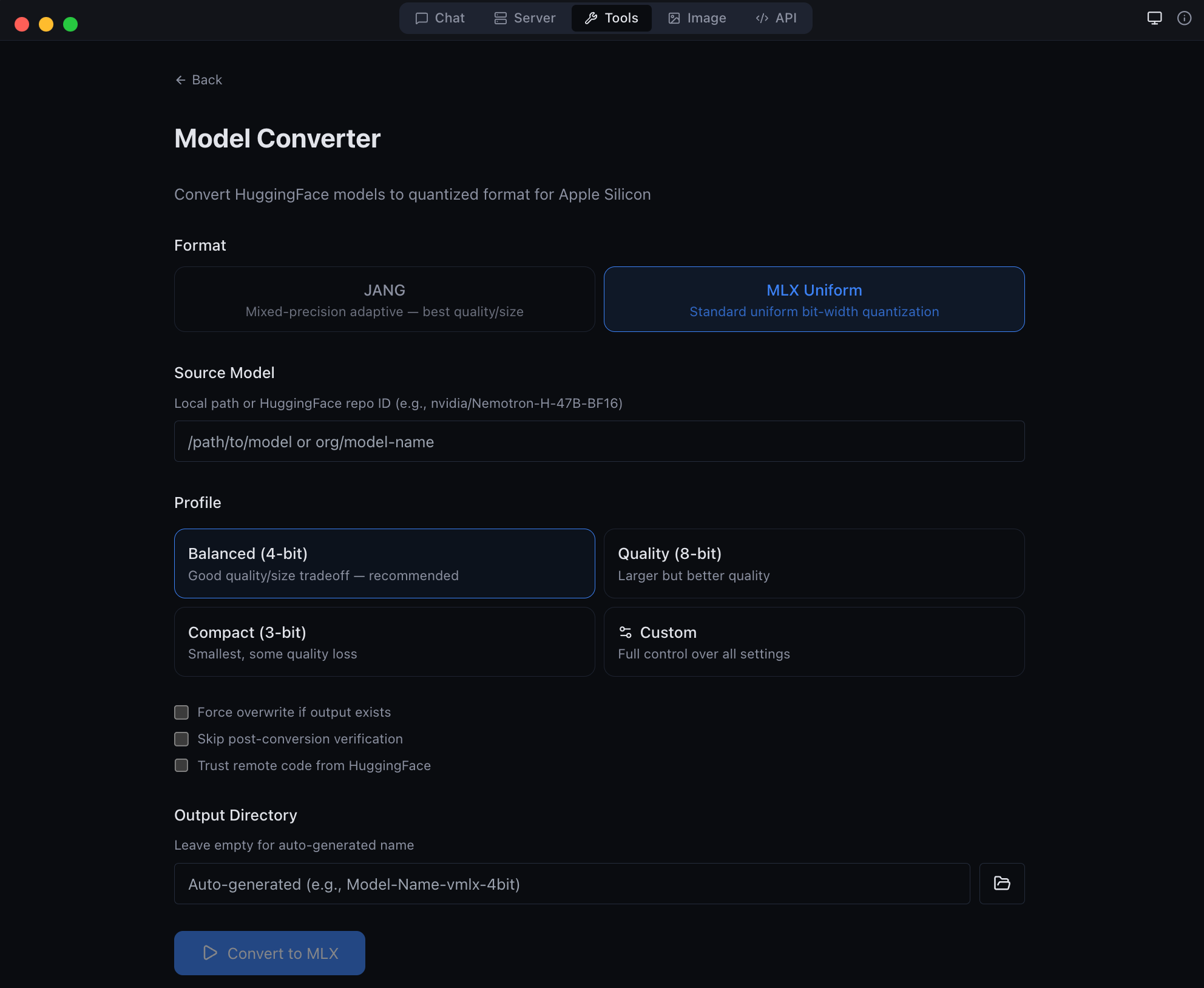
| **工具** | 模型转换器、GGUF 转 MLX、检查器、诊断工具 |
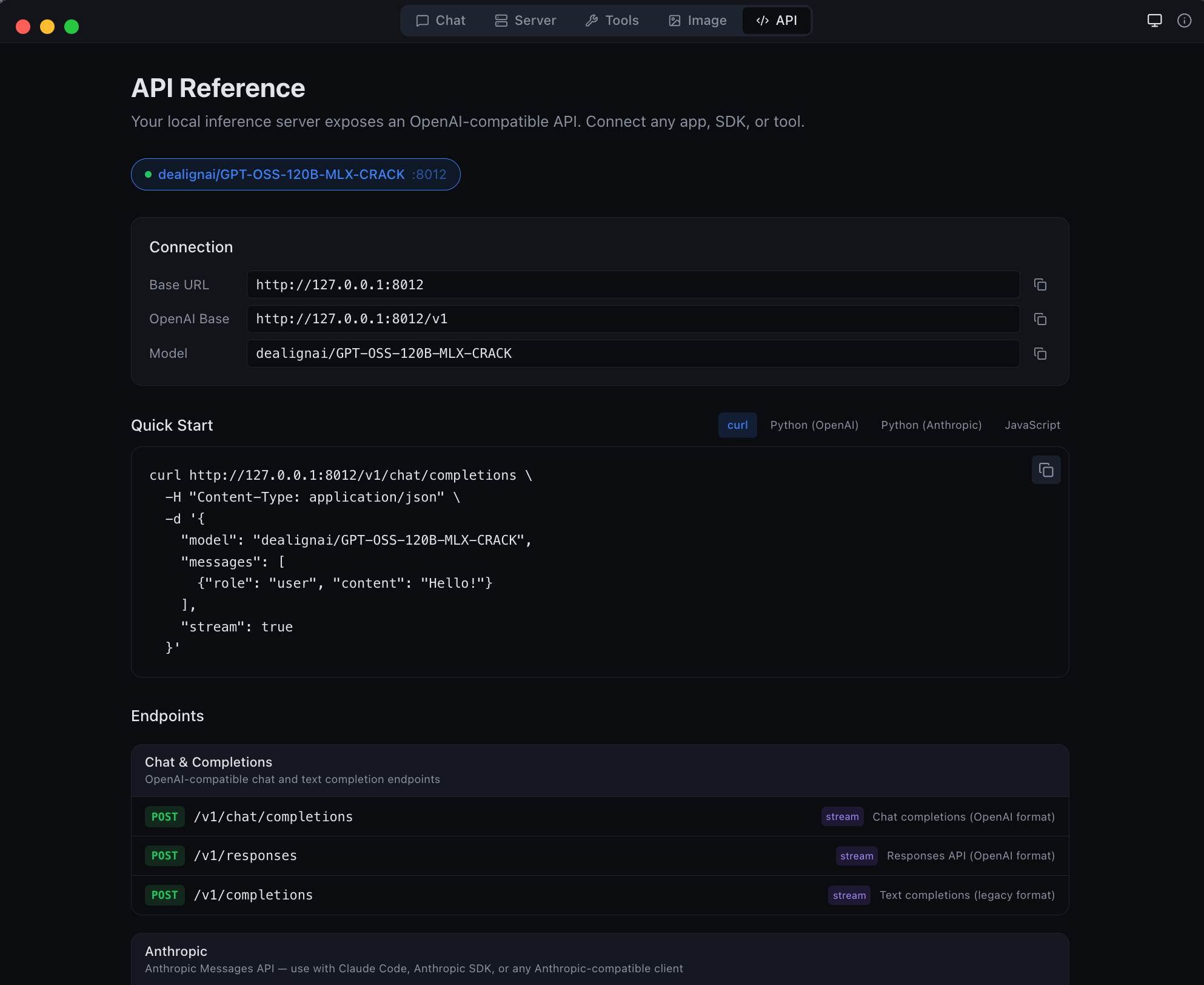
| **API** | 实时端点参考,提供可复制粘贴的代码片段 |
 |
 |
| Image generation and editing with Flux models |
Developer tools -- model conversion and diagnostics |
 |
 |
| Anthropic Messages API endpoint -- full compatibility |
GGUF to MLX conversion -- bring your own models |
### 下载
从 [MLX Studio Releases](https://github.com/jjang-ai/mlxstudio/releases/latest) 获取最新 DMG,或从源代码构建:
```
git clone https://github.com/jjang-ai/vmlx.git
cd vmlx/panel
npm install && npm run build
npx electron-builder --mac dmg
```
### 菜单栏
vMLX 位于菜单栏中,显示所有正在运行的模型、GPU 内存使用情况和快速控制。
## 高级量化
vMLX 开箱即支持标准 MLX 量化(4 位、8 位均匀量化)。对于希望进一步优化的用户,**JANG 自适应混合精度**为不同层类型分配不同的位宽 — 注意力层获得更多位,MLP 层获得更少位 — 从而在相同模型尺寸下实现更好的质量。
### JANG 配置
| 配置 | 注意力 | 嵌入 | MLP | 平均位数 | 用例 |
|---------|-----------|------------|-----|----------|----------|
| `JANG_2M` | 8 位 | 4 位 | 2 位 | ~2.5 | 均衡压缩 |
| `JANG_2L` | 8 位 | 6 位 | 2 位 | ~2.7 | 质量 2 位 |
| `JANG_3M` | 8 位 | 3 位 | 3 位 | ~3.2 | **推荐** |
| `JANG_4M` | 8 位 | 4 位 | 4 位 | ~4.2 | 标准质量 |
| `JANG_6M` | 8 位 | 6 位 | 6 位 | ~6.2 | 接近无损 |
### 转换
```
pip install vmlx[jang]
# 标准 MLX 量化
vmlx convert my-model --bits 4
# JANG 自适应量化
vmlx convert my-model --jang-profile JANG_3M
# 激活感知校准(在2-3比特时表现更好)
vmlx convert my-model --jang-profile JANG_2L --calibration-method activations
# 提供转换后的模型服务
vmlx serve ./my-model-JANG_3M --continuous-batching --use-paged-cache
```
预量化的 JANG 模型可在 [JANGQ-AI on HuggingFace](https://huggingface.co/JANGQ-AI) 获取。
### Smelt 模式(部分专家加载)
对于内存不足的 MoE 模型,**Smelt** 仅从 SSD 加载每层的部分专家,并保持骨干网络常驻。路由偏向于常驻专家,因此响应质量保持连贯,同时内存使用量下降。权衡:吞吐量与加载的专家百分比成反比,因为专家交换在热路径上访问 SSD。
```
# 每层加载50%的专家(仅使用 --smelt 时的默认设置)
vmlx serve ./MyMoE-JANG_4M --smelt --smelt-experts 50
# 激进模式:加载25% —— 内存占用最小,速度最慢
vmlx serve ./MyMoE-JANG_4M --smelt --smelt-experts 25
```
**`Nemotron-Cascade-2-30B-A3B-JANG_4M` 基准测试**(23 个 MoE 层 × 128 个专家,Apple M3 Ultra / 128 GB,专用机器,无并行模型):
| `--smelt-experts` | 活跃 RAM | 解码 tok/s | RAM 耗损 | 连贯性 |
|---|---:|---:|---|---|
| _关闭(基线)_ | **17,408 MB** | **89.9** | — | ✓ |
| `50` | 9,529 MB | **66.5** | **−45%** | ✓ |
| `25` | 5,590 MB | * | **−68%** | ✓ |
\* 响应过短(2-5 个 token),在 25% 时无法可靠地测量稳态 tok/s。主观上响应迅速。
所有三种配置均产生了连贯、非循环的输出。未观察到质量下降 — 路由偏差使模型保持相关性。
**Smelt 与 VLM 模式互斥。** vMLX 检测到 smelt 并自动禁用 `--is-mllm`(附带警告),因为视觉塔未通过部分专家加载器连接 — 在 smelt 加载的 VLM 上输入图像会产生垃圾 logit。在运行 smelt 时使用纯文本模型,或在运行 VLM 时禁用 smelt。
Smelt 需要 JANG 格式的 MoE 模型。与稠密模型(无专家可部分加载)或非 JANG 格式不兼容。
## CLI 命令
```
vmlx serve # Start inference server
vmlx convert --bits 4 # MLX uniform quantization
vmlx convert -j JANG_3M # JANG adaptive quantization
vmlx info # Model metadata and config
vmlx doctor # Run diagnostics
vmlx bench # Performance benchmarks
vmlx-worker --secret # Start distributed worker node
```
## 配置
### 服务器选项
```
vmlx serve \
--host 0.0.0.0 \ # Bind address (default: 0.0.0.0)
--port 8000 \ # Port (default: 8000)
--api-key sk-your-key \ # Optional API key authentication
--continuous-batching \ # Enable concurrent request handling
--enable-prefix-cache \ # Reuse KV states for repeated prompts
--use-paged-cache \ # Block-based KV cache with dedup
--kv-cache-quantization q8 \ # Quantize cache: q4 or q8
--enable-disk-cache \ # Persist cache to SSD
--enable-jit \ # JIT Metal kernel compilation
--tool-call-parser auto \ # Auto-detect tool call format
--reasoning-parser auto \ # Auto-detect thinking format
--log-level INFO \ # Logging: DEBUG, INFO, WARNING, ERROR
--max-model-len 8192 \ # Max context length
--speculative-model \ # Draft model for speculative decoding
--enable-pld \ # Prompt Lookup Decoding — no draft model, best for code/JSON/schemas
--distributed \ # Enable multi-Mac pipeline parallelism
--cluster-secret \ # Shared auth secret for workers
--distributed-mode pipeline \ # pipeline (default) or tensor (coming soon)
--worker-nodes ip:port,... \ # Manual worker IPs (overrides auto-discovery)
--cors-origins "*" # CORS allowed origins
```
### 量化选项
```
vmlx convert \
--bits 4 \ # Uniform quantization bits: 2, 3, 4, 6, 8
--group-size 64 \ # Quantization group size (default: 64)
--output ./output-dir \ # Output directory
--jang-profile JANG_3M \ # JANG mixed-precision profile
--calibration-method activations # Activation-aware calibration
```
### 图像生成与编辑选项
```
pip install vmlx[image]
# 生成模型
vmlx serve schnell \ # or dev, z-image-turbo
--image-quantize 4 \ # Quantization: 4, 8 (omit for full precision)
--port 8001
# 编辑模型
vmlx serve qwen-image-edit \ # Instruction-based editing (full precision only)
--port 8001
# 本地模型目录
vmlx serve ~/.mlxstudio/models/image/FLUX.1-schnell-mflux-4bit
```
### 音频选项
TTS 和 STT 需要 `mlx-audio` 包:
```
pip install mlx-audio
# 文本转语音:提供 Kokoro 模型服务
vmlx serve kokoro --port 8002
# 语音转文字:提供 Whisper 模型服务
vmlx serve whisper --port 8003
```
### 可选依赖项
```
pip install vmlx # Core: text LLMs, VLMs, embeddings, reranking
pip install vmlx[image] # + Image generation (mflux)
pip install vmlx[jang] # + JANG quantization tools
pip install vmlx[dev] # + Development/testing tools
pip install vmlx[image,jang] # Multiple extras
```
## 架构
```
+--------------------------------------------+
| Desktop App (Electron) |
| Chat | Server | Image | Tools | API |
+--------------------------------------------+
| Session Manager (TypeScript) |
| Process spawn | Health monitor | Tray |
+--------------------------------------------+
| vMLX Engine (Python / FastAPI) |
| +--------+ +---------+ +-----------+ |
| |Simple | | Batched | | ImageGen | |
| |Engine | | Engine | | Engine | |
| +---+----+ +----+----+ +-----+-----+ |
| | | | |
| +---+------------+--+ +-----+-----+ |
| | mlx-lm / mlx-vlm | | mflux | |
| +--------+-----------+ +-----------+ |
| | |
| +--------+----------------------------+ |
| | MLX Metal GPU Backend | |
| | quantized_matmul | KV cache | SDPA | |
| +--------------------------------------+ |
+--------------------------------------------+
| L1: Prefix Cache (Memory-Aware / Paged) |
| L2: Disk Cache (Persistent / Block Store) |
| KV Quant: q4/q8 at storage boundary |
+--------------------------------------------+
```
## 贡献
欢迎贡献。以下是设置开发环境的方法:
```
git clone https://github.com/jjang-ai/vmlx.git
cd vmlx
# Python 引擎
python -m venv .venv && source .venv/bin/activate
pip install -e ".[dev,jang,image]"
pytest tests/ -k "not Async" # 2000+ tests
# Electron 桌面应用
cd panel && npm install
npm run dev # Development mode with hot reload
npx vitest run # 1545+ tests
```
### 项目结构
```
vmlx/
vmlx_engine/ # Python inference engine (FastAPI server)
panel/ # Electron desktop app (React + TypeScript)
src/main/ # Electron main process
src/renderer/ # React frontend
src/preload/ # IPC bridge
tests/ # Python test suite
assets/ # Screenshots and logos
```
### 指南
- 提交 PR 前运行完整测试套件
- 遵循现有代码风格和模式
- 包含新功能的测试
- 为面向用户的更改更新文档
## 许可证
Apache License 2.0 -- 详见 [LICENSE](LICENSE)。
由 Jinho Jang (eric@jangq.ai) 构建
JANGQ AI • PyPI • GitHub • 下载
## 한국어 (韩语)
### vMLX — 面向 Apple Silicon 的本地 AI 引擎
在 Mac 上完全本地地运行 LLM、VLM、图像生成和编辑模型。
兼容 OpenAI + Anthropic API。无云端。无需 API 密钥。数据不会离开您的设备。
### 快速开始
```
pip install vmlx
vmlx serve mlx-community/Llama-3.2-3B-Instruct-4bit
```
### 主要功能
| 功能 | 描述 |
|------|------|
| **文本生成** | 支持 MLX 和 JANG 格式的 LLM 推理 |
| **视觉-语言模型** | 图像 + 文本多模态推理 |
| **图像生成** | Flux Schnell/Dev, Z-Image Turbo (基于 mflux) |
| **图像编辑** | Qwen Image Edit (基于文本指令的图像编辑) |
| **5 级缓存** | 前缀、分页、KV 量化、磁盘、内存感知缓存 |
| **连续批处理** | 处理多个并发请求 |
| **智能体工具** | 30 个内置工具(文件、网页搜索、Git、终端) |
| **OpenAI API** | /v1/chat/completions, /v1/images/generations, /v1/images/edits |
| **Anthropic API** | /v1/messages (流式、工具调用、系统提示) |
### 图像生成
```
pip install vmlx[image]
vmlx serve schnell # 빠른 생성 (4 단계)
vmlx serve dev # 고품질 생성 (20 단계)
```
### 图像编辑
```
vmlx serve qwen-image-edit # 텍스트 지시 기반 이미지 편집
```
```
# 图像编辑 API
curl http://localhost:8000/v1/images/edits \
-H "Content-Type: application/json" \
-d '{
"model": "qwen-image-edit",
"prompt": "배경을 해질녘으로 변경",
"image": "",
"size": "1024x1024",
"strength": 0.8
}'
```
### 桌面应用 (MLX Studio)
原生 macOS 桌面应用,提供 5 种模式:
| 模式 | 描述 |
|------|------|
| **聊天** | 对话界面、聊天记录、工具调用、智能体编码 |
| **服务器** | 模型会话管理 — 启动、停止、配置、监控 |
| **图像** | 文本到图像生成和图像编辑 (Flux, Qwen 模型) |
| **工具** | 模型转换器、GGUF-MLX 转换、诊断 |
| **API** | 实时端点参考及代码片段 |
### 安装
```
pip install vmlx # 기본: 텍스트 LLM, VLM, 임베딩
pip install vmlx[image] # + 이미지 생성/편집 (mflux)
pip install vmlx[jang] # + JANG 양자화 도구
pip install vmlx[audio] # + TTS/STT (mlx-audio)
```
### 许可证
Apache License 2.0 — 详见 [LICENSE](LICENSE)。
开发者: 장진호 (eric@jangq.ai)
JANGQ AI •
通过 Ko-fi 支持我们