ddalcu/mlx-serve
GitHub: ddalcu/mlx-serve
基于 Zig 的 Apple Silicon 原生 LLM 推理服务器,兼容 OpenAI 和 Anthropic API,附带 macOS GUI 应用,支持 Agent 模式和推测解码加速。
Stars: 357 | Forks: 30
# mlx-serve
[](https://github.com/ddalcu/mlx-serve/releases/latest)
[](LICENSE)
[](https://github.com/ddalcu/mlx-serve/releases/latest)
[](https://ziglang.org)
**[ddalcu.github.io/mlx-serve](https://ddalcu.github.io/mlx-serve/)**
原生 Zig 服务器,在 Apple Silicon 上运行 MLX 格式的语言模型,并暴露与 OpenAI 兼容和与 Anthropic 兼容的 HTTP API。无需 Python。附带 **MLX Core**,这是一款 macOS 菜单栏应用,内置聊天、Agent 模式和模型管理功能。
[ ](https://github.com/ddalcu/mlx-serve/releases/latest) **[下载 MLX Core.app](https://github.com/ddalcu/mlx-serve/releases/latest)** — macOS (Apple Silicon) 最新版本
### 通过 Homebrew 安装
```
brew tap ddalcu/mlx-serve https://github.com/ddalcu/mlx-serve
brew install --cask mlx-core # GUI menu bar app
brew install mlx-serve # CLI server only
```
## 功能
- 兼容 OpenAI 的 API(`/v1/chat/completions`、`/v1/completions`、`/v1/models`)
- OpenAI Responses API(`/v1/responses`)— 通过 `previous_response_id` 实现有状态链,带 `sequence_number` 的流式 SSE,以及用于不透明可往返历史数据块的 `/v1/responses/compact`
- `/v1/responses` 上的 WebSocket 传输 — 通过 `Upgrade: websocket` 建立相同的逐帧 JSON 契约
- 兼容 Anthropic 的 API(`/v1/messages`)— 与 Claude Code 配合使用
- 流式和非流式响应
- 工具调用(函数调用)及自动检测
- 跨请求重用 KV cache,实现快速的多轮对话
- 采样:temperature、top-k、top-p、repeat penalty、presence penalty
- **推测解码** — PLD(与模型无关的 n-gram 查找,默认开启)和 Gemma 4 助手起草器。自适应提示时间门(prompt-time gate)使新内容保持同等水平;代理式代码编辑循环最高可达 1.6 倍。
- 视觉/图像支持(Gemma 4 SigLIP 编码器)— 通过 `image_url` 内容块发送图像
- 推理/思考模式支持
- 通过 Jinja2(Jinja_cpp)的聊天模板,带有回退格式化
- 带有 CPU、内存和 GPU 指标的 TUI 状态栏
## MLX Core (macOS 应用)
封装服务器并提供完整 UI 的菜单栏应用:
- **模型浏览器** -- 从 HuggingFace 下载模型,支持断点续传。自动发现 LM Studio 中的模型(读取 `~/.lmstudio/settings.json` 中的 `downloadsFolder`);它们会出现在选择器中单独的“其他已发现模型”部分,因此你无需重新下载磁盘上已有的模型。
- **聊天界面** -- 具有Markdown渲染功能的多会话聊天。可将 PDF 或图像与文本一起拖入;PDF 通过 PDFKit 提取并内联到提示中。
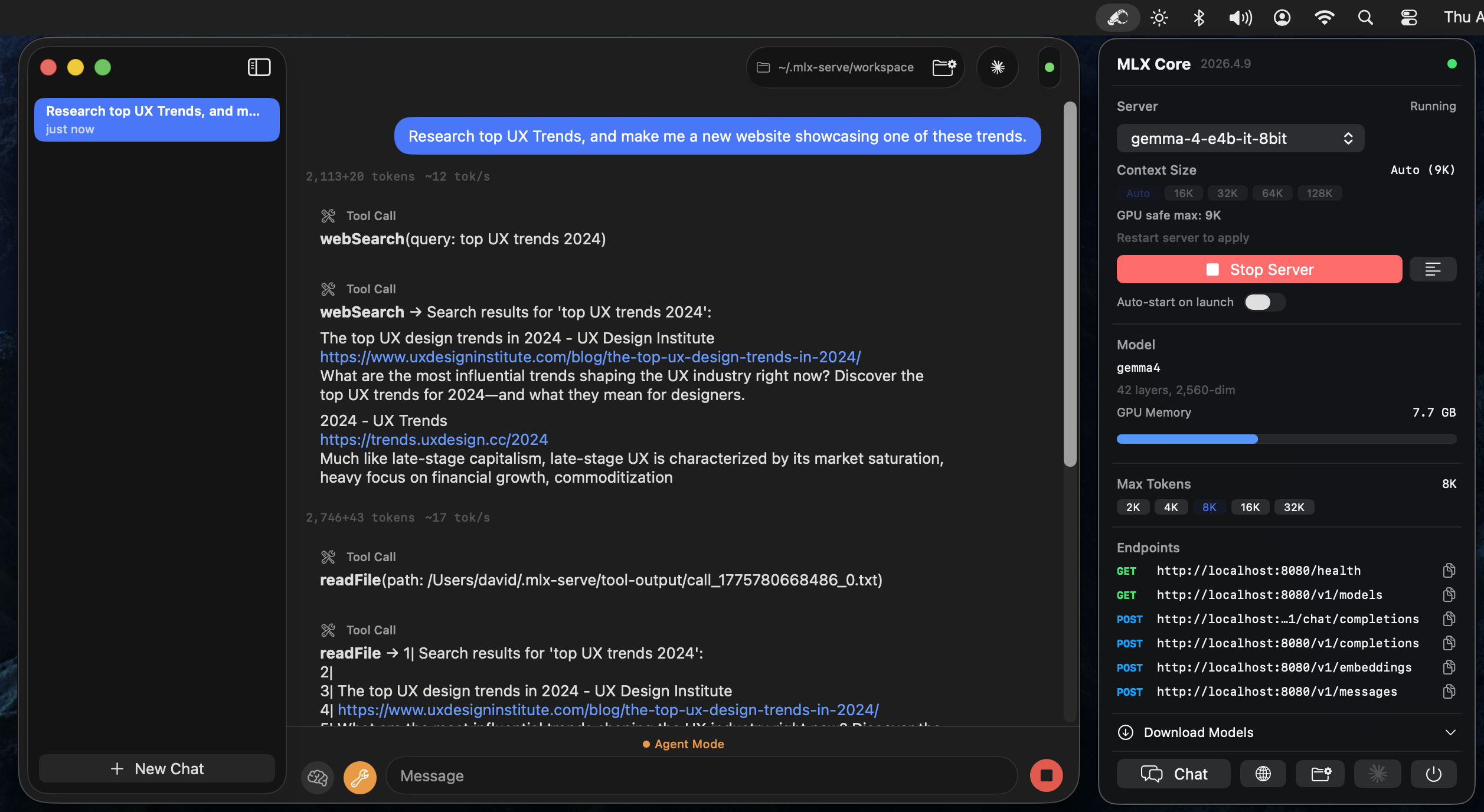
- **Agent 模式** -- 10 个内置工具(shell、cwd、readFile、writeFile、editFile、searchFiles、listFiles、browse、webSearch、saveMemory),带有自动工具调用循环
- **可编辑的系统提示** -- 通过 `~/.mlx-serve/system-prompt.md` 自定义 Agent 行为(Agent 菜单 → 编辑系统提示)
- **持久化记忆** -- Agent 可以跨会话将记忆保存到 `~/.mlx-serve/memory.md`
- **基于提示的技能** -- 将 `.md` 文件放入 `~/.mlx-serve/skills/` 目录,以教给 Agent 自定义功能
- **服务器管理** -- 启动/停止服务器,查看日志,提供适用于所有服务器启动标志和每个请求默认值的完整 **设置窗口** (Cmd+,)
- **图像生成 (FLUX.2)** -- 可选,托盘按钮;需要 Python(见下文)
- **视频生成 (LTX-Video 2.3,MLX 原生,带音频)** -- 可选,托盘按钮;需要 Python + ffmpeg(见下文)
### 图像 / 视频生成(可选)
托盘上有 **ImageGen** 和 **VideoGen** 按钮,它们通过 Python 子进程运行 [FLUX.2](https://huggingface.co/black-forest-labs) 和 [LTX-Video 2.3](https://github.com/dgrauet/ltx-2-mlx)。两者都在 MLX 上原生运行 — 无需 MPS/diffusers 路径。这完全是可选的 — Zig 服务器本身依然保持无 Python 依赖。
**前置条件:** 你的 Mac 上必须安装 Python 3 和 ffmpeg。
```
brew install python ffmpeg
```
然后启动 MLX Core,点击 ImageGen(或 VideoGen)托盘图标,并在窗口中点击 **安装**。该应用将会:
1. 在 `~/.mlx-serve/venv` 创建专用的虚拟环境(不会触碰你的系统 Python)
2. 安装 mflux (FLUX)、ltx-pipelines-mlx (LTX-2.3) 以及共享工具。大约 3 GB 的 pip 安装量。
3. 首次生成时下载模型权重(HuggingFace 缓存,支持断点续传)
**模型:**
| 功能 | 默认 | 其他选项 | 大致占用内存 |
|---|---|---|---|
| 图像 | FLUX.2-klein 4B 4-bit (mflux, 约 5 GB 预量化) | FLUX.1-schnell / dev 4-bit 和 8-bit | 8 / 12 / 16 GB |
| 视频 | LTX-Video 2.3 Q4 | — | 24 GB 内存,首次运行下载约 50 GB (LTX 41 GB + Gemma 8 GB) |
图像生成路径使用 [`mflux`](https://github.com/filipstrand/mflux) 进行原生 MLX 推理,并内置 4/8 位量化 — 这是让 FLUX 在 32 GB 以下的 Apple Silicon 上运行的唯一方式。视频生成路径使用 [`ltx-2-mlx`](https://github.com/dgrauet/ltx-2-mlx),这是一个用于 LTX-Video 2.3 的原生 MLX 管道,带有音频生成功能(通过系统 `ffmpeg` 混流)。
输出文件将保存至 `~/.mlx-serve/generations/images/YYYY-MM-DD/` 和 `.../videos/YYYY-MM-DD/`。
## 支持的模型
| 架构 | `model_type` | 示例 | 聊天格式 | 视觉 |
|---|---|---|---|---|
| **Gemma 4** | `gemma4` | `gemma-4-e2b-it-4bit`, `gemma-4-e4b-it-8bit`, `gemma-4-26b-a4b-it-4bit` | Gemma turns | SigLIP |
| **Gemma 3** | `gemma3` | `gemma-3-12b-it-qat-4bit` | Gemma turns | -- |
| **Qwen 3 / 3.5 / 3.6** | `qwen3`, `qwen3_5`, `qwen3_5_moe`, `qwen3_next` | `Qwen3-4B`, `Qwen3.5-4B`, `Qwen3.6-35B-A3B` | ChatML | -- |
| **Nemotron-H** | `nemotron_h` | Nemotron-3-Nano-4B | ChatML | -- |
| **LFM2** | `lfm2` | LFM2.5-350M | ChatML | -- |
| **Llama** | `llama` | Llama 3, Llama 3.1, Llama 3.2 | Llama-3 | -- |
| **Mistral** | `mistral` | Mistral 7B | ChatML | -- |
任何使用上述架构之一的量化 MLX 模型都应该可以工作。具有不支持架构的模型会在模型浏览器中被标记,但仍可下载。我们尚未实现的架构记录在 [TODO.md](TODO.md) 中。
## 前置条件
- macOS,搭载 Apple Silicon (M1/M2/M3/M4)
- [Zig 0.15+](https://ziglang.org/download/)
- mlx-c 和 libwebp:
```
brew install mlx-c webp
```
## 快速入门
### 下载模型
MLX Core 应用可以直接下载模型,或者使用 CLI:
```
pip install huggingface-hub
huggingface-cli download mlx-community/gemma-4-e4b-it-4bit --local-dir ~/.mlx-serve/models/gemma-4-e4b-it-4bit
```
### 构建并运行
```
zig build -Doptimize=ReleaseFast
./zig-out/bin/mlx-serve --model ~/.mlx-serve/models/gemma-4-e4b-it-4bit --serve --port 8080
```
### 构建应用
```
cd app && SKIP_NOTARIZE=1 bash build.sh
open "MLX Core.app"
```
代码签名需要设置 `APPLE_DEVELOPER_ID` 和 `APPLE_TEAM_ID` 环境变量。
## 用法
### 交互模式
```
./zig-out/bin/mlx-serve --model /path/to/model --prompt "What is 2+2?"
```
### HTTP 服务器
```
./zig-out/bin/mlx-serve --model /path/to/model --serve --port 8080
```
### CLI 选项
| 标志 | 默认值 | 描述 |
|---|---|---|
| `--model PATH` | 必填 | MLX 模型目录的路径 |
| `--serve` | 关闭 | 启动 HTTP 服务器 |
| `--host ADDR` | `127.0.0.1` | 要绑定的主机地址 |
| `--port N` | `11234` | HTTP 服务器的端口 |
| `--prompt TEXT` | `"Hello"` | 交互模式的提示词 |
| `--max-tokens N` | `100` | 最大生成 token 数 |
| `--temp F` | `0.0` | 采样 temperature(0 = 贪婪) |
| `--ctx-size N` | auto | 上下文窗口大小(auto = 根据 GPU 内存计算) |
| `--timeout N` | `300` | 请求超时时间(秒) |
| `--reasoning-budget N` | `-1` | 思考 token 预算(`-1` = 无限制,`0` = 不思考) |
| `--no-vision` | 关闭 | 即使模型支持,也禁用视觉编码器 |
| `--pld` / `--no-pld` | 开启 | 提示查找解码(与模型无关的推测解码) |
| `--pld-draft-len N` | `5` | 每次 PLD 步骤的最大 draft token 数 |
| `--pld-key-len N` | `3` | PLD 的 N-gram 匹配键长度 |
| `--drafter DIR` | 无 | Gemma 4 助手 draft 模型检查点(例如 `gemma-4-E4B-it-assistant-bf16`) |
| `--draft-block-size N` | `4` | Gemma 4 draft 模型每轮的 draft 数量 |
| `--log-level` | `info` | 日志级别(error、warn、info、debug) |
## API
### POST /v1/chat/completions
```
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [{"role": "user", "content": "Write a haiku about programming."}],
"max_tokens": 256,
"stream": true
}'
```
支持 `messages`、`max_tokens`、`temperature`、`top_p`、`top_k`、`stream`、`tools`、`repetition_penalty`、`presence_penalty` 和 `logprobs`。消息可以包含 `image_url` 内容块(base64 或 URL),用于支持视觉的模型。
### POST /v1/messages (Anthropic)
```
curl http://localhost:8080/v1/messages \
-H "Content-Type: application/json" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "mlx-serve",
"max_tokens": 256,
"messages": [{"role": "user", "content": "Write a haiku about programming."}]
}'
```
与 Claude Code 兼容(`ANTHROPIC_BASE_URL=http://localhost:8080 claude`)以及 Anthropic SDK。支持流式传输、工具调用和扩展思考。
### POST /v1/responses (OpenAI Responses API)
```
curl http://localhost:8080/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "mlx-serve",
"input": "Write a haiku about programming.",
"stream": true
}'
```
通过 `previous_response_id` 实现有状态链,带有每个事件 `sequence_number` 的完整流式 SSE,包含 `tools` / `tool_choice` / `text` / `reasoning` / `usage` 回显的符合 schema 的封装。`POST /v1/responses/compact` 返回一个不透明的 base64 历史数据块,该数据块可以直接作为 `compaction` 输入项往返传递,无需任何 LLM 调用。同一端点还接受 `Upgrade: websocket` 握手 — 每个文本帧都是一条 `response.create` JSON 消息,而每个 SSE 事件都会变成一个出站文本帧。
### 其他端点
- `GET /health` -- 健康检查
- `GET /v1/models` -- 列出已加载的模型
- `POST /v1/completions` -- 文本补全
- `POST /v1/messages` -- Anthropic Messages API
- `GET /v1/responses/{id}`, `DELETE /v1/responses/{id}` -- 获取 / 删除已保存的响应
## 性能
在 Apple M4(16 GB 统一内存)上基准测试:
| 模型 | Prefill | Decode | 内存 |
|---|---|---|---|
| Gemma-4 E4B (4-bit) | ~390 tok | ~33 tok/s | 4.3 GB |
| Qwen3.5-4B (4-bit) | ~380 tok/s | ~38 tok/s | 2.3 GB |
| LFM2.5-350M (8-bit) | ~3800 tok/s | ~210 tok/s | 0.4 GB |
| Nemotron-3-Nano-4B (8-bit) | -- | ~22 tok/s | 4.3 GB |
生成速度与 mlx-lm (Python) 相当,同时使用了更少的内存,启动速度提升 3 倍。主要优化包括:完全延迟的异步管道(带有重排的 eval,先提交模式),JIT 编译的激活函数(GELU、GeGLU、softcap 通过 `mlx_compile`),以及 GPU 内存布线。
## 推测解码
两种风格,均为贪婪等价(在 temp=0 时,前 30 个 token 字节一致;在 temp > 0 时,通过 Leviathan 概率比采样器在数学上精确一致):
- **PLD**(提示查找解码)— 在 `prompt + generated_tokens` 中进行与模型无关的 n-gram 匹配。默认开启(`--pld`);无需针对每个模型进行设置。在代理式循环、RAG、代码编辑等答案复述提示内容的场景中胜出。
- **Gemma 4 助手 draft 模型** — Google 的小型 4 层交叉注意力 draft 模型(`gemma-4-{E2B,E4B,26B-A4B,31B}-it-assistant-bf16`)。通过 `--drafter
](https://github.com/ddalcu/mlx-serve/releases/latest) **[下载 MLX Core.app](https://github.com/ddalcu/mlx-serve/releases/latest)** — macOS (Apple Silicon) 最新版本
### 通过 Homebrew 安装
```
brew tap ddalcu/mlx-serve https://github.com/ddalcu/mlx-serve
brew install --cask mlx-core # GUI menu bar app
brew install mlx-serve # CLI server only
```
## 功能
- 兼容 OpenAI 的 API(`/v1/chat/completions`、`/v1/completions`、`/v1/models`)
- OpenAI Responses API(`/v1/responses`)— 通过 `previous_response_id` 实现有状态链,带 `sequence_number` 的流式 SSE,以及用于不透明可往返历史数据块的 `/v1/responses/compact`
- `/v1/responses` 上的 WebSocket 传输 — 通过 `Upgrade: websocket` 建立相同的逐帧 JSON 契约
- 兼容 Anthropic 的 API(`/v1/messages`)— 与 Claude Code 配合使用
- 流式和非流式响应
- 工具调用(函数调用)及自动检测
- 跨请求重用 KV cache,实现快速的多轮对话
- 采样:temperature、top-k、top-p、repeat penalty、presence penalty
- **推测解码** — PLD(与模型无关的 n-gram 查找,默认开启)和 Gemma 4 助手起草器。自适应提示时间门(prompt-time gate)使新内容保持同等水平;代理式代码编辑循环最高可达 1.6 倍。
- 视觉/图像支持(Gemma 4 SigLIP 编码器)— 通过 `image_url` 内容块发送图像
- 推理/思考模式支持
- 通过 Jinja2(Jinja_cpp)的聊天模板,带有回退格式化
- 带有 CPU、内存和 GPU 指标的 TUI 状态栏
## MLX Core (macOS 应用)
封装服务器并提供完整 UI 的菜单栏应用:
- **模型浏览器** -- 从 HuggingFace 下载模型,支持断点续传。自动发现 LM Studio 中的模型(读取 `~/.lmstudio/settings.json` 中的 `downloadsFolder`);它们会出现在选择器中单独的“其他已发现模型”部分,因此你无需重新下载磁盘上已有的模型。
- **聊天界面** -- 具有Markdown渲染功能的多会话聊天。可将 PDF 或图像与文本一起拖入;PDF 通过 PDFKit 提取并内联到提示中。
- **Agent 模式** -- 10 个内置工具(shell、cwd、readFile、writeFile、editFile、searchFiles、listFiles、browse、webSearch、saveMemory),带有自动工具调用循环
- **可编辑的系统提示** -- 通过 `~/.mlx-serve/system-prompt.md` 自定义 Agent 行为(Agent 菜单 → 编辑系统提示)
- **持久化记忆** -- Agent 可以跨会话将记忆保存到 `~/.mlx-serve/memory.md`
- **基于提示的技能** -- 将 `.md` 文件放入 `~/.mlx-serve/skills/` 目录,以教给 Agent 自定义功能
- **服务器管理** -- 启动/停止服务器,查看日志,提供适用于所有服务器启动标志和每个请求默认值的完整 **设置窗口** (Cmd+,)
- **图像生成 (FLUX.2)** -- 可选,托盘按钮;需要 Python(见下文)
- **视频生成 (LTX-Video 2.3,MLX 原生,带音频)** -- 可选,托盘按钮;需要 Python + ffmpeg(见下文)
### 图像 / 视频生成(可选)
托盘上有 **ImageGen** 和 **VideoGen** 按钮,它们通过 Python 子进程运行 [FLUX.2](https://huggingface.co/black-forest-labs) 和 [LTX-Video 2.3](https://github.com/dgrauet/ltx-2-mlx)。两者都在 MLX 上原生运行 — 无需 MPS/diffusers 路径。这完全是可选的 — Zig 服务器本身依然保持无 Python 依赖。
**前置条件:** 你的 Mac 上必须安装 Python 3 和 ffmpeg。
```
brew install python ffmpeg
```
然后启动 MLX Core,点击 ImageGen(或 VideoGen)托盘图标,并在窗口中点击 **安装**。该应用将会:
1. 在 `~/.mlx-serve/venv` 创建专用的虚拟环境(不会触碰你的系统 Python)
2. 安装 mflux (FLUX)、ltx-pipelines-mlx (LTX-2.3) 以及共享工具。大约 3 GB 的 pip 安装量。
3. 首次生成时下载模型权重(HuggingFace 缓存,支持断点续传)
**模型:**
| 功能 | 默认 | 其他选项 | 大致占用内存 |
|---|---|---|---|
| 图像 | FLUX.2-klein 4B 4-bit (mflux, 约 5 GB 预量化) | FLUX.1-schnell / dev 4-bit 和 8-bit | 8 / 12 / 16 GB |
| 视频 | LTX-Video 2.3 Q4 | — | 24 GB 内存,首次运行下载约 50 GB (LTX 41 GB + Gemma 8 GB) |
图像生成路径使用 [`mflux`](https://github.com/filipstrand/mflux) 进行原生 MLX 推理,并内置 4/8 位量化 — 这是让 FLUX 在 32 GB 以下的 Apple Silicon 上运行的唯一方式。视频生成路径使用 [`ltx-2-mlx`](https://github.com/dgrauet/ltx-2-mlx),这是一个用于 LTX-Video 2.3 的原生 MLX 管道,带有音频生成功能(通过系统 `ffmpeg` 混流)。
输出文件将保存至 `~/.mlx-serve/generations/images/YYYY-MM-DD/` 和 `.../videos/YYYY-MM-DD/`。
## 支持的模型
| 架构 | `model_type` | 示例 | 聊天格式 | 视觉 |
|---|---|---|---|---|
| **Gemma 4** | `gemma4` | `gemma-4-e2b-it-4bit`, `gemma-4-e4b-it-8bit`, `gemma-4-26b-a4b-it-4bit` | Gemma turns | SigLIP |
| **Gemma 3** | `gemma3` | `gemma-3-12b-it-qat-4bit` | Gemma turns | -- |
| **Qwen 3 / 3.5 / 3.6** | `qwen3`, `qwen3_5`, `qwen3_5_moe`, `qwen3_next` | `Qwen3-4B`, `Qwen3.5-4B`, `Qwen3.6-35B-A3B` | ChatML | -- |
| **Nemotron-H** | `nemotron_h` | Nemotron-3-Nano-4B | ChatML | -- |
| **LFM2** | `lfm2` | LFM2.5-350M | ChatML | -- |
| **Llama** | `llama` | Llama 3, Llama 3.1, Llama 3.2 | Llama-3 | -- |
| **Mistral** | `mistral` | Mistral 7B | ChatML | -- |
任何使用上述架构之一的量化 MLX 模型都应该可以工作。具有不支持架构的模型会在模型浏览器中被标记,但仍可下载。我们尚未实现的架构记录在 [TODO.md](TODO.md) 中。
## 前置条件
- macOS,搭载 Apple Silicon (M1/M2/M3/M4)
- [Zig 0.15+](https://ziglang.org/download/)
- mlx-c 和 libwebp:
```
brew install mlx-c webp
```
## 快速入门
### 下载模型
MLX Core 应用可以直接下载模型,或者使用 CLI:
```
pip install huggingface-hub
huggingface-cli download mlx-community/gemma-4-e4b-it-4bit --local-dir ~/.mlx-serve/models/gemma-4-e4b-it-4bit
```
### 构建并运行
```
zig build -Doptimize=ReleaseFast
./zig-out/bin/mlx-serve --model ~/.mlx-serve/models/gemma-4-e4b-it-4bit --serve --port 8080
```
### 构建应用
```
cd app && SKIP_NOTARIZE=1 bash build.sh
open "MLX Core.app"
```
代码签名需要设置 `APPLE_DEVELOPER_ID` 和 `APPLE_TEAM_ID` 环境变量。
## 用法
### 交互模式
```
./zig-out/bin/mlx-serve --model /path/to/model --prompt "What is 2+2?"
```
### HTTP 服务器
```
./zig-out/bin/mlx-serve --model /path/to/model --serve --port 8080
```
### CLI 选项
| 标志 | 默认值 | 描述 |
|---|---|---|
| `--model PATH` | 必填 | MLX 模型目录的路径 |
| `--serve` | 关闭 | 启动 HTTP 服务器 |
| `--host ADDR` | `127.0.0.1` | 要绑定的主机地址 |
| `--port N` | `11234` | HTTP 服务器的端口 |
| `--prompt TEXT` | `"Hello"` | 交互模式的提示词 |
| `--max-tokens N` | `100` | 最大生成 token 数 |
| `--temp F` | `0.0` | 采样 temperature(0 = 贪婪) |
| `--ctx-size N` | auto | 上下文窗口大小(auto = 根据 GPU 内存计算) |
| `--timeout N` | `300` | 请求超时时间(秒) |
| `--reasoning-budget N` | `-1` | 思考 token 预算(`-1` = 无限制,`0` = 不思考) |
| `--no-vision` | 关闭 | 即使模型支持,也禁用视觉编码器 |
| `--pld` / `--no-pld` | 开启 | 提示查找解码(与模型无关的推测解码) |
| `--pld-draft-len N` | `5` | 每次 PLD 步骤的最大 draft token 数 |
| `--pld-key-len N` | `3` | PLD 的 N-gram 匹配键长度 |
| `--drafter DIR` | 无 | Gemma 4 助手 draft 模型检查点(例如 `gemma-4-E4B-it-assistant-bf16`) |
| `--draft-block-size N` | `4` | Gemma 4 draft 模型每轮的 draft 数量 |
| `--log-level` | `info` | 日志级别(error、warn、info、debug) |
## API
### POST /v1/chat/completions
```
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [{"role": "user", "content": "Write a haiku about programming."}],
"max_tokens": 256,
"stream": true
}'
```
支持 `messages`、`max_tokens`、`temperature`、`top_p`、`top_k`、`stream`、`tools`、`repetition_penalty`、`presence_penalty` 和 `logprobs`。消息可以包含 `image_url` 内容块(base64 或 URL),用于支持视觉的模型。
### POST /v1/messages (Anthropic)
```
curl http://localhost:8080/v1/messages \
-H "Content-Type: application/json" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "mlx-serve",
"max_tokens": 256,
"messages": [{"role": "user", "content": "Write a haiku about programming."}]
}'
```
与 Claude Code 兼容(`ANTHROPIC_BASE_URL=http://localhost:8080 claude`)以及 Anthropic SDK。支持流式传输、工具调用和扩展思考。
### POST /v1/responses (OpenAI Responses API)
```
curl http://localhost:8080/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "mlx-serve",
"input": "Write a haiku about programming.",
"stream": true
}'
```
通过 `previous_response_id` 实现有状态链,带有每个事件 `sequence_number` 的完整流式 SSE,包含 `tools` / `tool_choice` / `text` / `reasoning` / `usage` 回显的符合 schema 的封装。`POST /v1/responses/compact` 返回一个不透明的 base64 历史数据块,该数据块可以直接作为 `compaction` 输入项往返传递,无需任何 LLM 调用。同一端点还接受 `Upgrade: websocket` 握手 — 每个文本帧都是一条 `response.create` JSON 消息,而每个 SSE 事件都会变成一个出站文本帧。
### 其他端点
- `GET /health` -- 健康检查
- `GET /v1/models` -- 列出已加载的模型
- `POST /v1/completions` -- 文本补全
- `POST /v1/messages` -- Anthropic Messages API
- `GET /v1/responses/{id}`, `DELETE /v1/responses/{id}` -- 获取 / 删除已保存的响应
## 性能
在 Apple M4(16 GB 统一内存)上基准测试:
| 模型 | Prefill | Decode | 内存 |
|---|---|---|---|
| Gemma-4 E4B (4-bit) | ~390 tok | ~33 tok/s | 4.3 GB |
| Qwen3.5-4B (4-bit) | ~380 tok/s | ~38 tok/s | 2.3 GB |
| LFM2.5-350M (8-bit) | ~3800 tok/s | ~210 tok/s | 0.4 GB |
| Nemotron-3-Nano-4B (8-bit) | -- | ~22 tok/s | 4.3 GB |
生成速度与 mlx-lm (Python) 相当,同时使用了更少的内存,启动速度提升 3 倍。主要优化包括:完全延迟的异步管道(带有重排的 eval,先提交模式),JIT 编译的激活函数(GELU、GeGLU、softcap 通过 `mlx_compile`),以及 GPU 内存布线。
## 推测解码
两种风格,均为贪婪等价(在 temp=0 时,前 30 个 token 字节一致;在 temp > 0 时,通过 Leviathan 概率比采样器在数学上精确一致):
- **PLD**(提示查找解码)— 在 `prompt + generated_tokens` 中进行与模型无关的 n-gram 匹配。默认开启(`--pld`);无需针对每个模型进行设置。在代理式循环、RAG、代码编辑等答案复述提示内容的场景中胜出。
- **Gemma 4 助手 draft 模型** — Google 的小型 4 层交叉注意力 draft 模型(`gemma-4-{E2B,E4B,26B-A4B,31B}-it-assistant-bf16`)。通过 `--drafter ` 选择性启用。draft 模型交叉关注目标的 KV cache — 没有单独复制的权重。
两者共享一个**自适应提示时间门**:对提示词进行 3-gram 重复评分(`spec_gate_threshold = 0.01`)会在新内容上自动禁用推测,因此创意写作和一次性问答的运行速度与使用 `--no-pld` 时保持同等水平,而不是付出每步验证的开销。**运行时接受门**会在接受率低于盈亏平衡点(5 次尝试后为 0.30)时进一步在解码中途禁用推测。并在该请求的剩余部分保持禁用状态。
### 在实际代理式代码编辑工作负载上的加速
Apple M 系列,MLX 4-bit 权重,temp=0,提示词中包含函数并要求进行小修改(典型的 mlx-serve 工作负载)。`nospec` = 带有 `--no-pld` 标志的相同二进制文件:
| 模型 | nospec | PLD | Drafter |
|---|---:|---:|---:|
| Gemma 4 E4B (4-bit) | 28.0 tok/s | **45.0 tok/s · 1.61×** | **44.6 tok/s · 1.59×** |
| Qwen 3.5 4B (4-bit) | 28.1 tok/s | **40.5 tok/s · 1.44×** | — |
| LFM2.5 350M (8-bit) | 162 tok/s | 160 tok/s · 0.99× | — |
在创意/新内容提示词上,得益于门控机制,这两个功能都保持在同等水平(≈1.0×) — **没有性能倒退**。350M 的 LFM2.5 对推测解码大致呈中性 — 它的前向传播足够小,以至于验证过程的成本与 AR 差不多。
使用 **`./tests/bench_spec_matrix.sh`**(与附带二进制文件对比的 release 比较矩阵)或 **`./tests/bench_spec.sh --corpus`**(包含 echo、code-rename、JSON、RAG、agent、plain Q&A、code-translate、summarize、creative 的 9 提示阈值调整语料库)进行复现。
### 与 LM Studio 对比 (HTTP-vs-HTTP)
**总体快 39%**(跨 18 个单元格的几何平均值,最佳 mlx-serve 对比最佳 LMS,相同的 4-bit 权重,ctx=4096,temp=0)。
| 模型 | Echo | 代码 | 自由格式 |
|---|---:|---:|---:|
| Gemma 4 E2B | **+122%** | **+47%** | +20% |
| Gemma 4 E4B | **+97%** | **+53%** | **+35%** |
| Gemma 4 31B | +20% | +4% | -1% |
| Gemma 4 26B-A4B-MoE | **+66%** | +23% | +31% |
| Qwen 3.6 27B | **+60%** | +24% | +32% |
| Qwen 3.6 35B-A3B-MoE | **+88%** | +20% | +25% |
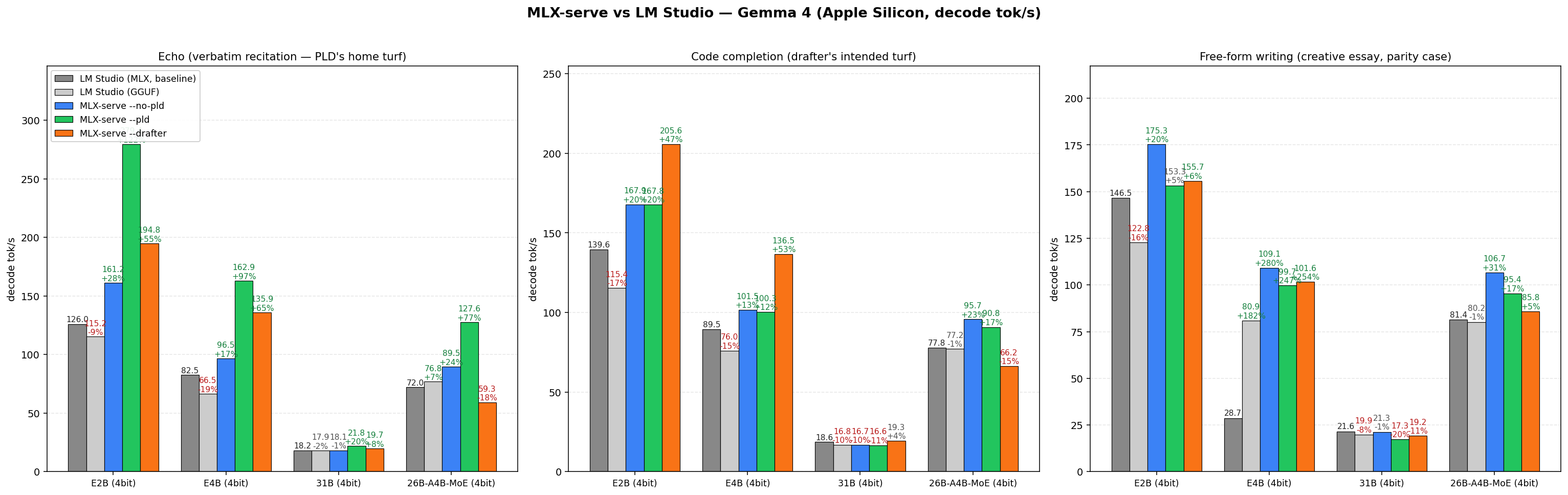
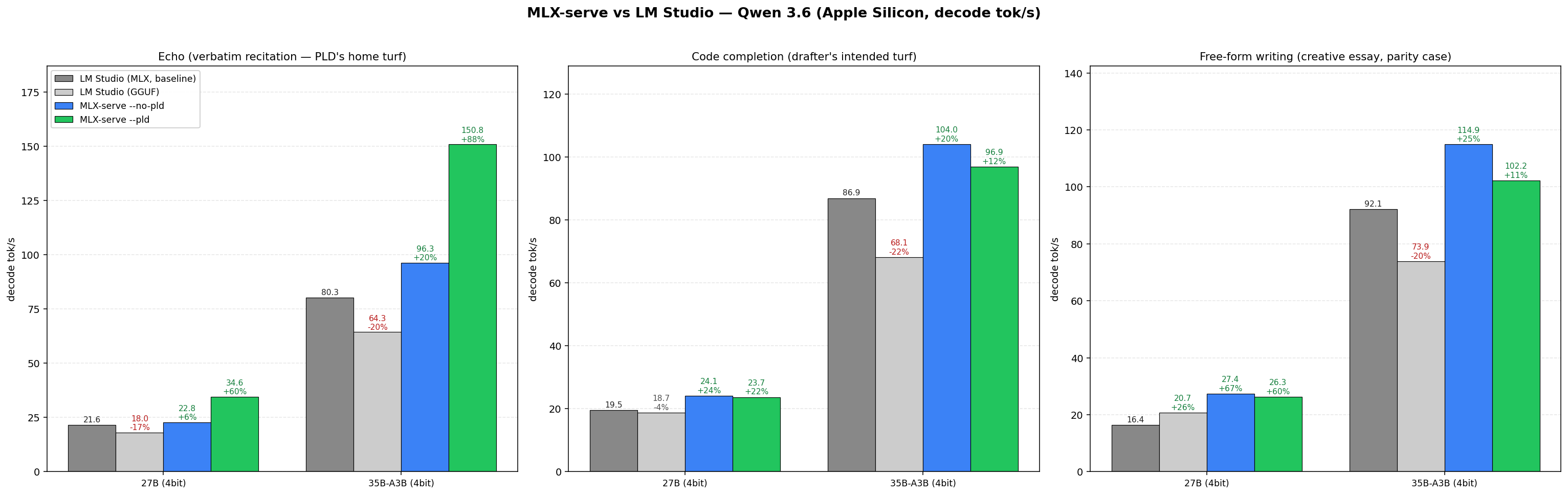
复现方法:`./tests/bench_vs_lmstudio.sh --family gemma`(或 `qwen36`)。需要 `lms`、`jq`、`python3`、`matplotlib`。
## 许可证
MIT
基准测试复现
``` # Prefill(约 840 token 提示词): ./zig-out/bin/mlx-serve --model ~/.mlx-serve/models/gemma-4-e4b-it-4bit \ --prompt "$(python3 -c "print('Explain the following topics in extreme detail: ' + ', '.join([f'topic {i} about science and technology and its impact on human civilization throughout history' for i in range(1,50)]))")" \ --max-tokens 1 # Decode(256 tokens,temp=0): ./zig-out/bin/mlx-serve --model ~/.mlx-serve/models/gemma-4-e4b-it-4bit \ --prompt "Write a detailed essay about quantum computing" \ --max-tokens 256 ``` 运行 3 次,并取第 2-3 次运行的平均值(第 1 次运行包括从磁盘加载模型)。标签:Agent模式, AI应用, AI推理引擎, AI智能体, Anthropic兼容API, Apple M系列芯片, Apple Silicon, Function Calling, HTTP API, KV缓存, LLM推理服务, macOS开发, macOS菜单栏应用, Mac原生, MLX, MLX Core, ML框架, OpenAI兼容API, SSE, WebSocket, Zig语言, 依赖分析, 多轮对话, 大模型推理, 工具调用, 开源AI, 无Python, 本地大模型, 本地部署, 模型管理, 流式输出, 系统托盘, 边缘AI计算