# CIA 世界概况档案 1990-2025
一份完整的、结构化的 CIA World Factbook 档案,跨度 **36 年**(1990-2025),涵盖 **281 个实体**,在标准化的 SQLite 数据库中包含 **1,071,603 个数据字段**。
CIA World Factbook 已于 **2026 年 2 月 4 日** 停止更新。本档案保存了自 1990 年以来发布的每一版,并创建了一个结构化的、可查询的数据集。
**[搜索交互式档案](https://worldfactbookarchive.org/)** | **[项目文档](https://milkmp.github.io/CIA-World-Factbooks-Archive-1990-2025/)** | **[执行摘要](https://github.com/MilkMp/CIA-World-Factbooks-Archive-1990-2025/blob/main/docs/CIA_Factbook_Archive_Executive_Summary.pdf/)**
## 数据库统计
| 指标 | 数值 |
|--------|-------|
| **覆盖年份** | 1990-2025(36 个版本) |
| **实体** | 281 个(192 个主权国家,65 个地区,6 个争议地区等) |
| **国家-年度记录** | 9,536 |
| **分类记录** | 83,682 |
| **数据字段** | 1,071,603 |
| **内容大小** | ~656 MB(含 FieldValues + FTS) |
| **字段名称变体** | 1,132 个映射到 416 个规范名称 |
| **结构化子值** | 1,775,588 个从原始文本解析(2,599 个子字段) |
## 数据来源
| 年份 | 来源 | 方法 |
|-------|--------|--------|
| 1990-1995, 1997-1999 | [Project Gutenberg](https://www.gutenberg.org/) | 纯文本解析(十年间有 4 种格式变体) |
| 1996 | [CIA 原始文件](https://web.archive.org/web/19970528151800id_/http://www.odci.gov:80/cia/publications/nsolo/wfb-96.txt.gz) + Gutenberg | 来自 Wayback Machine 的 CIA 纯文本文件(替换了 7 个国家的 Gutenberg 截断数据) |
| 2000 | [Wayback Machine](https://web.archive.org/) | HTML zip 下载 + 经典格式解析器 |
| 2001 | Project Gutenberg | 文本回退(HTML zip 已损坏) |
| 2002-2020 | Wayback Machine | 来自 cia.gov 的 HTML zip 档案,4 代解析器 |
| 2021-2025 | [factbook/cache.factbook.json](https://github.com/factbook/cache.factbook.json) | 包含年末提交快照的 Git 历史 |
## 逐年细分
| 年份 | 来源 | 国家数 | 字段数 |
|------|--------|-----------|--------|
| 1990 | 文本 | 249 | 15,750 |
| 1991 | 文本 | 247 | 14,903 |
| 1992 | 文本 | 264 | 17,372 |
| 1993 | 文本 | 266 | 18,509 |
| 1994 | 文本 | 266 | 28,633 |
| 1995 | 文本 | 266 | 19,599 |
| 1996 | 文本 | 266 | 21,118 |
| 1997 | 文本 | 266 | 23,405 |
| 1998 | 文本 | 266 | 23,524 |
| 1999 | 文本 | 266 | 25,178 |
| 2000 | HTML | 267 | 25,724 |
| 2001 | 文本 | 265 | 27,281 |
| 2002 | HTML | 268 | 27,430 |
| 2003 | HTML | 268 | 28,676 |
| 2004 | HTML | 271 | 28,958 |
| 2005 | HTML | 271 | 28,728 |
| 2006 | HTML | 274 | 28,962 |
| 2007 | HTML | 266 | 29,103 |
| 2008 | HTML | 263 | 30,755 |
| 2009 | HTML | 260 | 30,818 |
| 2010 | HTML | 262 | 30,805 |
| 2011 | HTML | 263 | 33,635 |
| 2012 | HTML | 271 | 35,192 |
| 2013 | HTML | 269 | 36,731 |
| 2014 | HTML | 268 | 36,680 |
| 2015 | HTML | 268 | 36,870 |
| 2016 | HTML | 268 | 36,804 |
| 2017 | HTML | 268 | 37,046 |
| 2018 | HTML | 268 | 37,285 |
| 2019 | HTML | 268 | 37,394 |
| 2020 | HTML | 268 | 36,687 |
| 2021 | JSON | 260 | 39,714 |
| 2022 | JSON | 260 | 37,344 |
| 2023 | JSON | 260 | 37,558 |
| 2024 | JSON | 260 | 34,838 |
| 2025 | JSON | 260 | 32,594 |
## 仓库结构
```
data/
master_countries.sql # 281 canonical entities
countries.sql # 9,536 country-year records
categories.sql # 83,682 category records
field_name_mappings.sql # 1,132 field name standardization rules
fields/
country_fields_1990.sql.gz # Split by year (36 gzipped files)
...
country_fields_2025.sql.gz
schema/
create_tables.sql # DDL for all 5 tables
create_field_values.sql # DDL for FieldValues (structured sub-values)
etl/
build_archive.py # HTML parser (2000-2020)
load_gutenberg_years.py # Text parser (1990-2001)
reload_json_years.py # JSON loader (2021-2025)
build_field_mappings.py # Field name standardization
classify_entities.py # Entity type classification
repair_1996_truncated.py # CIA original text parser for 7 truncated 1996 countries
validate_integrity.py # Data quality checks
export_to_sqlite.py # SQL Server -> SQLite export (with FTS5)
structured_parsing/
parse_field_values.py # Decompose text blobs into typed sub-values (55 parsers)
validate_field_values.py # Validation: spot checks, coverage, numeric stats
export_field_values_to_sqlite.py # Export FieldValues + refs to SQLite
dashboard_preview.py # Local preview dashboard (8 chart panels)
DESIGN.md # Architecture and design document
stardict/
build_stardict.py # Generate StarDict dictionaries for KOReader/GoldenDict
scripts/
factbook_search.py # Command-line search utility
validate_cocom.py # COCOM region validation
validate_integrity.py # Data integrity checks
queries/
sample_queries.sql # 18 analytical queries for Power BI / analysis
search_cli.py # Command-line search tool
docs/
DATABASE_SCHEMA.md # Table definitions and relationships
ETL_PIPELINE.md # How the archive was built
FIELD_EVOLUTION.md # How CIA field names changed over time
METHODOLOGY.md # Complete methodology: parsing, standardization, validation
screenshots/ # 29 PNGs + 5 animated GIFs of the web application
index.html # GitHub Pages static landing page
```
## ETL 流程与 Python 脚本
获取数据有 **两种方式**:
1. **导入预构建的 SQL 转储文件**(位于 `data/`)——无需 Python。见下方 [如何还原](#how-to-restore)。
2. **从头重新运行 ETL 流程** —— `etl/` 中的 Python 脚本直接从原始来源(Wayback Machine, Project Gutenberg, GitHub)下载原始 Factbook 数据,解析每种格式变体,并通过 pyodbc 将结构化结果加载到 SQL Server。这是档案最初构建的方式。
1990 年至 2025 年间,原始 CIA World Factbook 的格式至少变更了 **10 次**。`etl/` 中的每个脚本之所以存在,是因为解析器的前一个版本在新年份数据上出错了。该流程处理了 4 种纯文本格式变体、5 代 HTML 布局以及最后的 JSON 时代 —— 每种都需要自己的解析器。
### 脚本
| 脚本 | 代码行数 | 年份 | 功能描述 |
|--------|-------|-------|--------------|
| `build_archive.py` | 986 | 2000-2020 | 从 Wayback Machine 下载 HTML zip 文件,检测每年使用的是 5 种 HTML 布局中的哪一种,并解析字段。处理下载失败时的 CDX API 回退,过滤模板/打印页面,并对条目进行去重。 |
| `load_gutenberg_years.py` | 1,043 | 1990-2001 | 解析具有 4 种不同格式变体(标记、星号、at 符号、冒号)的 Project Gutenberg 纯文本版本。包含模糊国家名称匹配以处理别名,如“Burma”和“Ivory Coast”。 |
| `reload_json_years.py` | 413 | 2021-2025 | 从 factbook/cache.factbook.json 仓库检出一年的 git 提交并加载结构化 JSON。去除内容字段中嵌入的 HTML。 |
| `build_field_mappings.py` | 783 | 所有年份 | 使用 7 规则系统将 1,132 个原始字段名称变体映射到 416 个规范名称:身份、短横线标准化、CIA 重命名、合并、特定国家条目、噪声检测和人工审查。使用区分大小写的排序规则(`COLLATE Latin1_General_CS_AS`)以确保大小写变体获得单独的映射行。所有时代中用于子字段边界的 Content 中的管道(`\|`)分隔符。 |
| `classify_entities.py` | 283 | 所有年份 | 根据Dependency Status和Government Type字段,将 281 个实体自动分类为 9 种类型(主权、地区、争议等),并对边缘情况进行硬编码覆盖。 |
| `repair_1996_truncated.py` | 189 | 1996 | 解析 CIA 原始的 `wfb-96.txt.gz`(带有居中国家/部分名称的页眉格式),并替换 7 个国家的截断 Gutenberg 条目:Venezuela, Armenia, Greece, Luxembourg, Malta, Monaco, Tuvalu。 |
| `validate_integrity.py` | 296 | 所有年份 | 具有 10 项检查的只读验证套件:字段数量基准、美国人口/GDP 真值、逐年一致性、来源溯源、NULL 检测和未映射字段名称缺口分析。 |
| `structured_parsing/parse_field_values.py` | 1,400+ | 所有年份 | 使用 55 个特定字段解析器 + 通用回退,将 1,071,603 个原始文本块分解为 1,775,588 个类型化子值。每行包含一个 `SourceFragment` 列,显示生成该值的精确文本切片,以及一个 `IsComputed` 标志,用于区分源提取值(0)和解析器派生值(1)。提取陆地/水域面积、男性/女性预期寿命、年龄段、性别比、识字率、预算、海拔、抚养比、GDP 构成、二氧化碳排放、水/卫生设施等。 |
| `structured_parsing/validate_field_values.py` | 231 | 所有年份 | 根据源数据库验证 FieldValues:行数、覆盖率、数值提取率、针对已知真值(美国人口、俄罗斯面积、日本军费)的抽查。 |
| `structured_parsing/export_field_values_to_sqlite.py` | 269 | 所有年份 | 将 FieldValues + 所有参考表导出到自包含的 SQLite 数据库(factbook.db,使用 `--webapp` 时含 FTS5 + ISOCountryCodes 约 656 MB)。包括导出后完整性检查,用于检测并回填任何未映射的字段名称。 |
### 为什么解析如此困难
CIA 从未维护稳定的 schema。每隔几年 HTML 布局就会完全改变,字段名称在未通知的情况下被重命名,整个类别也被重组。例如:
- **1990-1999(纯文本):** 十年间有四种不同的格式约定。1990-1993 使用带有缩进字段的 `Country: Name` 标题。1994 年引入了标记标签(`_@_`, `_*_`, `_#_`)。1996 年切换为完全没有标记的裸露章节标题。1999 年再次更改了分隔符方案。每种变体都需要自己的基于正则表达式的解析器。
- **2000-2020(HTML):** CIA 至少重新设计了 Factbook 网站 5 次。2000 年版使用 `
FieldName:` 内联格式。到 2004 年切换为 `
` 表格布局。2008 年引入了 CollapsiblePanel JavaScript 小部件。2014 年改为展开/折叠 `` 部分。2017 年移至字段锚点 `` 结构。一个在 2006 年数据上有效的解析器在 2010 年数据上会产生乱码。
- **2001:** Wayback Machine 的 2001 年 HTML zip 已损坏,因此解析回退到 Project Gutenberg 纯文本版本 —— 这是 HTML 和文本流程必须交换的唯一一年。
- **字段名称漂移:** 几十年来 CIA 静默地重命名字段。“GDP - real growth rate”变成了“Real GDP growth rate”。“Telephones”拆分为“Telephones - fixed lines”和“Telephones - mobile cellular”。石油子字段被合并到“Petroleum”中。`build_field_mappings.py` 脚本通过 7 个规则层映射所有 1,132 个变体,以维护时间序列连续性。
- **特定国家的干扰:** 1990 年代的版本将政府机构名称(议会、大会、法院)作为顶级字段嵌入。已解体国家(塞尔维亚和黑山、荷属安的列斯)出现又消失。北塞浦路斯、马来西亚州和荷属安的列斯岛屿作为需要特殊处理的子条目出现。
完整技术细节请参阅 [docs/METHODOLOGY.md](docs/METHODOLOGY.md) 和 [docs/ETL_PIPELINE.md](docs/ETL_PIPELINE.md)。
## 如何还原
### 前置条件
- SQL Server 2017+(或 Azure SQL)
- [ODBC Driver 18 for SQL Server](https://learn.microsoft.com/en-us/sql/connect/odbc/download-odbc-driver-for-sql-server)
- Python 3.8+ 并安装 `pyodbc`(用于 ETL 脚本和 CLI 搜索工具)
### 步骤
1. **创建数据库:**
CREATE DATABASE CIA_WorldFactbook;
2. **运行架构脚本:**
sqlcmd -S localhost -d CIA_WorldFactbook -i schema/create_tables.sql
3. **导入数据(按顺序):**
sqlcmd -S localhost -d CIA_WorldFactbook -i data/master_countries.sql
sqlcmd -S localhost -d CIA_WorldFactbook -i data/countries.sql
sqlcmd -S localhost -d CIA_WorldFactbook -i data/categories.sql
sqlcmd -S localhost -d CIA_WorldFactbook -i data/field_mappings.sql
4. **导入字段数据(解压并导入每一年):**
cd data/fields
# 在 Linux/macOS 上:
for f in *.sql.gz; do gunzip -k "$f" && sqlcmd -S localhost -d CIA_WorldFactbook -i "${f%.gz}"; done
# 在 Windows (PowerShell) 上:
Get-ChildItem *.sql.gz | ForEach-Object {
$sql = $_.FullName -replace '\.gz$',''
[System.IO.Compression.GZipStream]::new(
[System.IO.File]::OpenRead($_.FullName),
[System.IO.Compression.CompressionMode]::Decompress
).CopyTo([System.IO.File]::Create($sql))
sqlcmd -S localhost -d CIA_WorldFactbook -i $sql
}
5. **验证:**
SELECT COUNT(*) FROM CountryFields; -- 应返回 1,071,603
### 结构化字段值数据库(新)
`CountryFields.Content` 中的原始文本已使用 55 个专用解析器分解为 **2,599 个不同子字段** 中的 **1,775,588 个类型化子值**。每行包含一个 `SourceFragment`,显示生成该值的精确文本切片,以及一个 `IsComputed` 标志,用于区分直接从源文本提取的值(`0`)和通过计算派生的值(`1`,例如针对 1995 年之前的数据计算男性/女性预期寿命的平均值)。Content 中的子字段边界使用管道(`|`)分隔符以便明确解析。这使得无需针对每个查询使用正则表达式即可进行 SQL 查询 —— 例如,按陆地与水域比例对国家进行排名、比较男性与女性预期寿命,或绘制预算赤字趋势图。
**下载:** [factbook.db (~656 MB) 来自 Release v3.4](https://github.com/MilkMp/CIA-World-Factbooks-Archive-1990-2025/releases/tag/v3.4) —— 单个自包含数据库,包含所有表、FTS5 搜索索引和 ISO 国家代码。
**实时仪表板:** [worldfactbookarchive.org/analysis/structured-data](https://worldfactbookarchive.org/analysis/structured-data) —— 显示带有 SQL 和源数据选项卡的新查询的交互式图表。
数据库是自包含的,其中包含所有参考表。示例查询:
```
-- Top 10 countries by land area (2025) with land/water split
SELECT c.Name,
MAX(CASE WHEN fv.SubField = 'land' THEN fv.NumericVal END) AS land_sqkm,
MAX(CASE WHEN fv.SubField = 'water' THEN fv.NumericVal END) AS water_sqkm
FROM FieldValues fv
JOIN CountryFields cf ON fv.FieldID = cf.FieldID
JOIN Countries c ON cf.CountryID = c.CountryID
JOIN FieldNameMappings fnm ON cf.FieldName = fnm.OriginalName
WHERE c.Year = 2025 AND fnm.CanonicalName = 'Area'
GROUP BY c.Name
ORDER BY land_sqkm DESC LIMIT 10;
```
完整架构、解析器注册表和子字段目录请参阅 [etl/structured_parsing/DESIGN.md](etl/structured_parsing/DESIGN.md)。
### StarDict 词典(适用于 KOReader / GoldenDict)
StarDict 格式的离线词典,可与 [KOReader](https://koreader.rocks/)、[GoldenDict](http://goldendict.org/) 和其他 StarDict 兼容应用一起使用。按名称、ISO 代码或 FIPS 代码查找任何国家,并获取完整的 Factbook 条目。
**每年两个版本:**
- **常规版** —— 按类别分组的完整字段文本(地理、人口、经济等)
- **结构化版** —— 从 FieldValues 表中解析的带有单位的数值子值
共计 **72 部词典**:36 年(1990-2025)x 2 个版本,压缩后约 97 MB。
**生成:**
```
pip install pyglossary python-idzip
python etl/stardict/build_stardict.py # all 72
python etl/stardict/build_stardict.py --years 2025 # just 2025
python etl/stardict/build_stardict.py --editions general # general only
```
输出至 `data/stardict/`。每部词典都是一个包含 `.ifo`、`.idx`、`.dict.dz` 和 `.syn` 文件的目录。将该目录复制到您的词典应用的数据文件夹中(例如 KOReader 的 `koreader/data/dict/`)。
格式详情、同义词解析、验证(16/16 测试)和安装指南请参阅 [etl/stardict/README.md](etl/stardict/README.md)。
### 替代方案:SQLite(无需 SQL Server)
预构建的 SQLite 数据库(`factbook.db`,约 656 MB)可作为发布下载提供给不需要 SQL Server 的用户。该文件超过 GitHub 的 100 MB 文件大小限制,因此不包含在仓库本身中。
**下载:** [factbook.db 来自最新发布](https://github.com/MilkMp/CIA-World-Factbooks-Archive-1990-2025/releases/latest)
将下载的文件放在项目根目录的 `data/factbook.db` 处。SQLite 无需安装 —— Python 的内置 `sqlite3` 模块可以直接查询它。
| | SQL Server | SQLite |
|--|-----------|--------|
| **设置** | 安装 SQL Server + ODBC 驱动,运行架构 + 导入脚本 | 下载一个 `.db` 文件 |
| **大小** | 约 263 MB,分布在 36 个 gzip 压缩的 SQL 文件中 | 约 656 MB 单个文件 |
| **查询工具** | SSMS, sqlcmd, pyodbc | Python `sqlite3`, DB Browser, 任何 SQLite 客户端 |
| **最适用于** | Power BI,企业分析,大规模连接 | 快速探索,脚本编写,轻量级应用 |
| **Schema** | 相同的 5 表结构 | 相同的 5 表结构 |
SQLite 数据库包含与 SQL Server 版本相同的表(包括带有 IsComputed 的 FieldValues)、相同的索引和相同的 1,071,603 个字段,外加一个 FTS5 全文搜索索引,用于快速关键字和布尔搜索。这就是 [实时 webapp](https://worldfactbookarchive.org/) 运行的平台。
**关于数值的说明:** `CountryFields` 表存储的原始文本内容与 CIA 发布的完全一致。没有预计算的 `Value` 列。webapp 上的 CSV 和 Excel 导出在下载时使用正则提取解析数值。要自行提取数值,请通过 `FieldNameMappings` 连接并应用所需字段的模式:
```
import sqlite3, re
db = sqlite3.connect("factbook.db")
db.row_factory = sqlite3.Row
# 提取 Population 为 integer
rows = db.execute("""
SELECT c.Year, mc.CanonicalName, cf.Content
FROM CountryFields cf
JOIN Countries c ON cf.CountryID = c.CountryID
JOIN MasterCountries mc ON c.MasterCountryID = mc.MasterCountryID
JOIN FieldNameMappings fm ON cf.FieldName = fm.OriginalName
WHERE fm.CanonicalName = 'Population'
ORDER BY mc.CanonicalName, c.Year
""").fetchall()
for r in rows:
m = re.search(r'[\d,]{5,}', r["Content"])
value = int(m.group().replace(",", "")) if m else None
if value:
print(f"{r['CanonicalName']} ({r['Year']}): {value:,}")
```
其他字段的常见提取模式:
| 字段 | 模式 | 示例 |
|-------|---------|---------|
| 人口 | `re.search(r'[\d,]{5,}', text)` → 去除逗号,转换为 int | 331,449,281 |
| 人均实际 GDP | `re.search(r'\$([\d,]+)', text)` → 去除逗号,转换为 int | $63,500 |
| 出生时预期寿命 | `re.search(r'total population:\s*([\d.]+)', text)` → float | 78.5 years |
| 人口增长率 | `re.search(r'(-?[\d.]+)%', text)` → float | 0.7% |
| 军费开支 | `re.search(r'([\d.]+)%\s*of\s*G[DN]P', text)` → float | 3.45% of GDP |
| 面积 | `re.search(r'total\s*:?\s*([\d,]+)\s*sq\s*km', text)` → 去除逗号,转换为 int | 9,833,517 sq km |
| 出生/死亡率 | `re.search(r'([\d.]+)\s*(?:births\|deaths)\s*/\s*1,000', text)` → float | 11.0 births/1,000 |
## 实时 Web 应用
该档案以 FastAPI + Jinja2 Web 应用程序形式在 **[worldfactbookarchive.org](https://worldfactbookarchive.org/)** 上提供服务。主要功能:
- **全文搜索**,支持国会图书馆布尔语法(AND, OR, NOT, "短语", 截断)
- **图书馆** —— 整个档案集合的卡片式概览
- **浏览档案** 按年份(1990-2025)和国家(281 个实体)
- **国家概况**,包含类别深入、字段时间序列和数据导出(CSV, Excel, PDF)
- **文本差异** —— 任意国家的并排年份比较,带高亮更改
- **国家词典**,包含 ISO 代码、实体类型和 COCOM 区域分配
- **交互式地图库** —— 可浏览的国家地图,支持搜索和过滤
- **数据导出** —— CSV, Excel, 可打印 PDF 报告,以及完整的分析就绪数据集下载
- **情报分析仪表板**,由 Mapbox GL JS 和 Apache ECharts 驱动:
- **区域仪表板** —— 带有 6 个 COCOM 区域的全球分级统计图、悬停弹出窗口、首都标记和点击缩放
- **COCOM 区域详情** —— 区域地图,带有 GDP、人口、军费开支的排名条形图
- **时间线地图** —— 跨越 36 年的动画分级统计图,支持多国时间序列和播放速度控制
- **地图比较** —— 两张同步地图,用于并排年份比较,具有共享色阶
- **通信分析** —— 互联网、移动、宽带普及率,带有数字鸿沟指标
- **全球趋势** —— 任意国家的多指标时间序列
- **全球排名** —— 任意指标的可排序国家排名,支持年份选择
- **变化检测** —— 逐年字段变化,带有趋势图和区域过滤
- **字段浏览器** —— 浏览所有 414 个规范数据字段,包含 36 年的覆盖率统计
- **高级分析浏览器** —— 相关性散点图、热力图矩阵、排名竞赛和树状图可视化
- **查询构建器** —— 跨所有指标的自定义分析查询,具有灵活的过滤器
- **贸易网络** —— 全球进口/出口关系的地理和力导向图
- **组织网络** —— 国际组织成员资格和联盟可视化
- **地缘政治图谱** —— 领土争端和基础设施地图
- **政治稳定性** —— 政体类型分级统计图、政权更迭追踪和区域同行比较
- **自然资源与经济** —— 资源生产地图、大宗商品散点图和国家概况
- **已解体国家** —— Factbook 中不再包含的历史实体,带有存档指标数据
- **结构化字段数据** —— 1,775,588 个已解析子值的交互式仪表板,带有图表/SQL/源选项卡,显示每个数字的确切提取来源
- **情报档案**,遵循 ICD 203 分析标准
- **区域威胁简报**,包含不稳定和安全指标
- **Factbook 测验** —— 4 种模式:国家识别、首都城市、大小比拼和旗帜识别
- **错误报告**,通过 GitHub Issues 集成
**技术栈:** Python 3.12, FastAPI, Jinja2, SQLite (FTS5), Mapbox GL JS v3, Apache ECharts 5, 部署于 Fly.io。
Web 应用程序源代码维护在一个单独的私有仓库中。
## 实体类型
| 类型 | 数量 | 描述 |
|------|-------|-------------|
| sovereign | 192 | 独立国家 |
| territory | 65 | 属地,海外领土 |
| misc | 7 | 大洋,世界,欧盟 |
| disputed | 6 | 科索沃,加沙地带,西岸等 |
| crown_dependency | 3 | 泽西岛,根西岛,马恩岛 |
| freely_associated | 3 | 马绍尔群岛,密克罗尼西亚,帕劳 |
| special_admin | 2 | 香港,澳门 |
| dissolved | 2 | 荷属安的列斯,塞尔维亚和黑山 |
| antarctic | 1 | 南极洲 |
## 字段名称标准化
在 36 年的时间跨度内,CIA 重命名了许多字段。`FieldNameMappings` 表将 1,132 个原始字段名称变体映射到 416 个规范名称(区分大小写,因此 `Natural hazards` 和 `natural hazards` 获得单独的行):
| 映射类型 | 数量 | 描述 |
|-------------|-------|-------------|
| identity | 184 | 现代字段名称(未更改) |
| rename | 159 | CIA 重命名的字段(例如 "GDP - real growth rate" -> "Real GDP growth rate") |
| dash_format | 64 | 格式差异(单短横线 vs 双短横线) |
| consolidation | 48 | 子字段合并到父字段中(例如 Oil production/consumption -> Petroleum) |
| country_specific | 354 | 区域子条目,政府机构名称 |
| noise | 281 | 解析器伪影,片段(标记为 IsNoise=1) |
## 示例查询
有关 18 个现成的分析查询,请参阅 [queries/sample_queries.sql](queries/sample_queries.sql),包括:
- 人口时间序列(单个国家)
- G7 国家 GDP 比较
- 军费开支趋势
- 互联网用户增长
- 随时间出现/消失的国家
- 合并后的石油子字段视图
## 截图
### 搜索与浏览
| | |
|---|---|
| 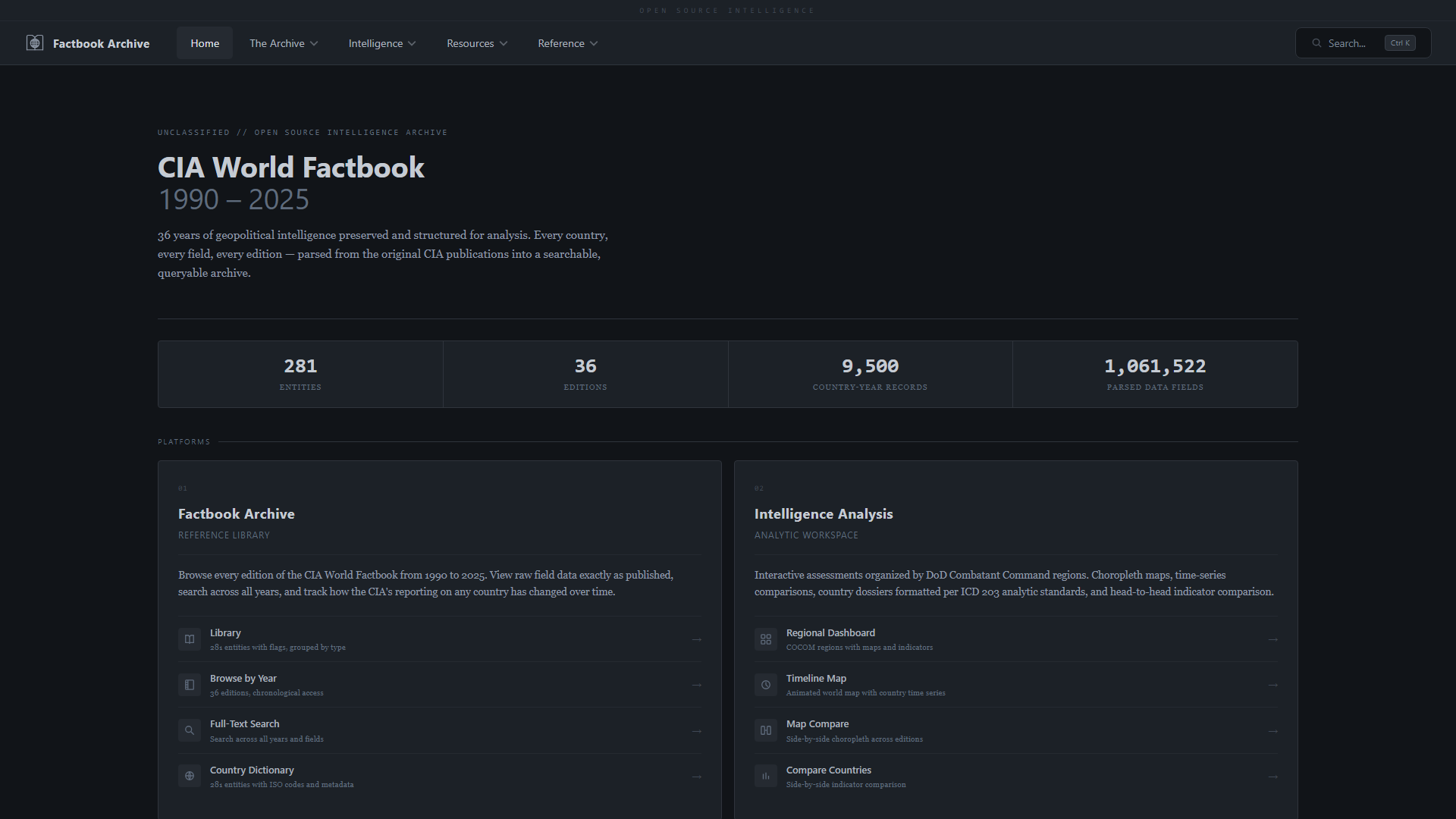 | 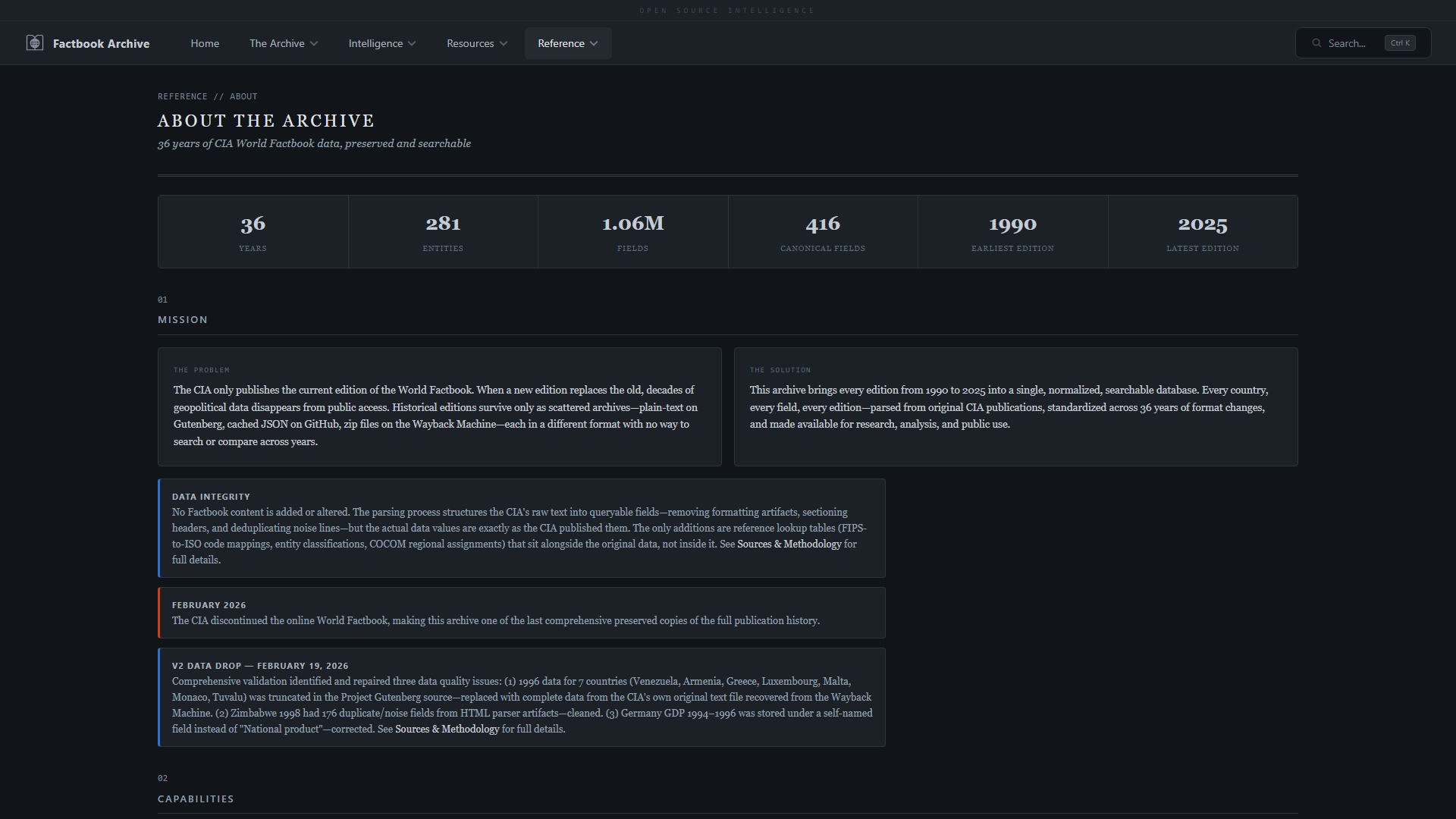 |
| **首页** —— 数据库统计、导航和实时搜索 | **关于** —— 项目使命、架构和方法论 |
| 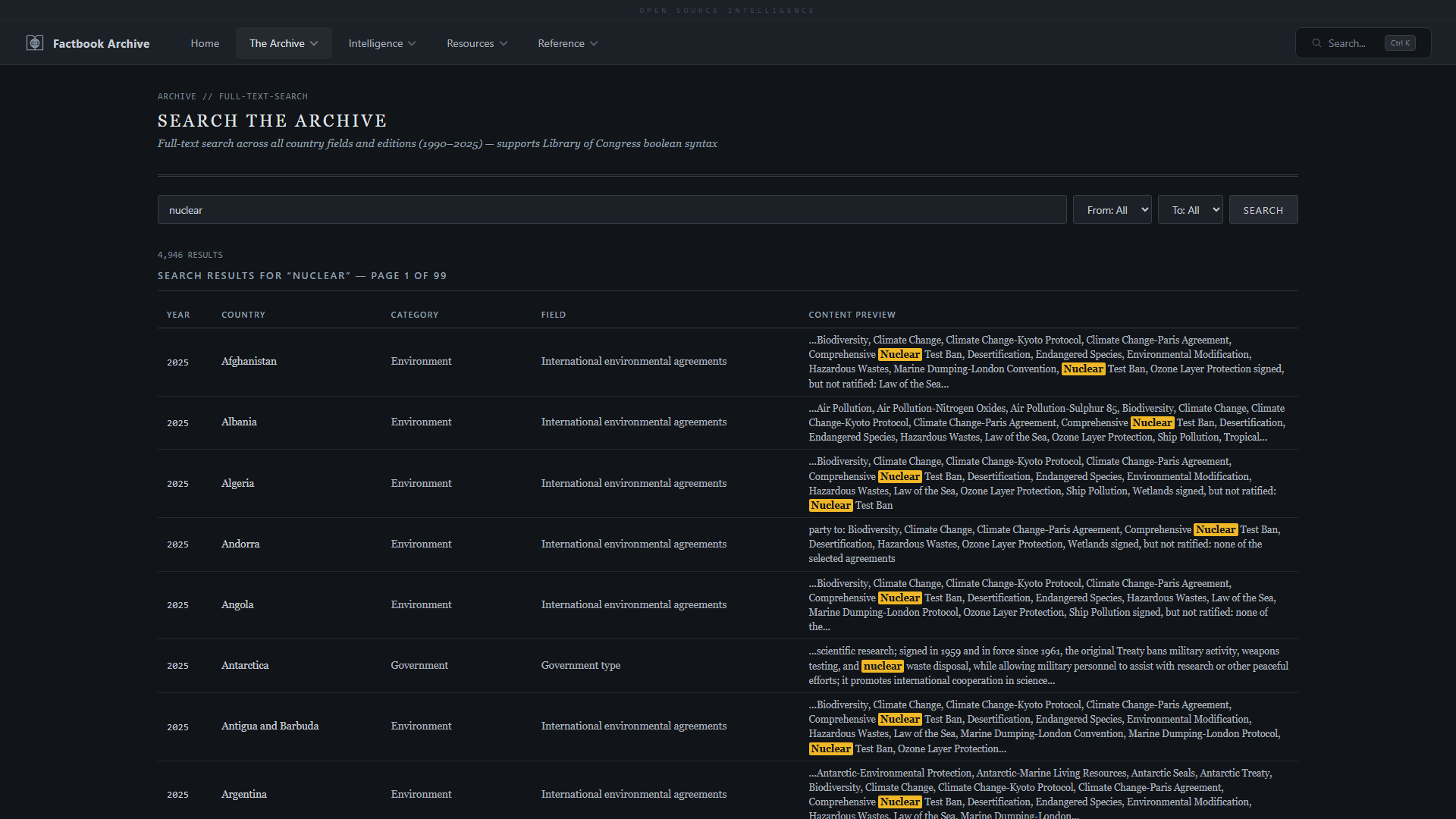 | 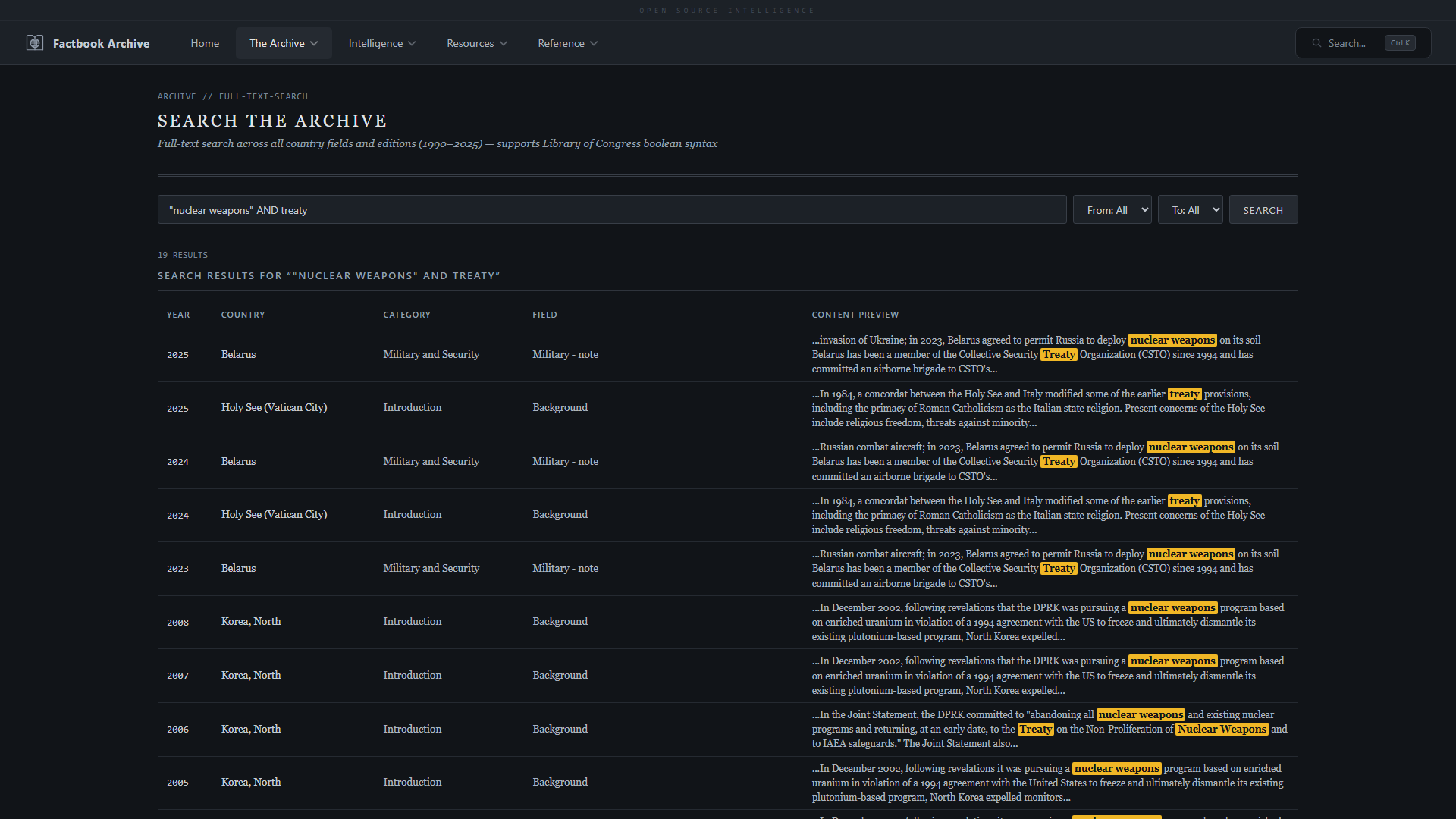 |
| **全文搜索** —— 跨 1,071,603 个字段的关键字搜索 | **布尔搜索** —— 带有短语匹配的 AND/OR/NOT 运算符 |
### 档案
| | |
|---|---|
| 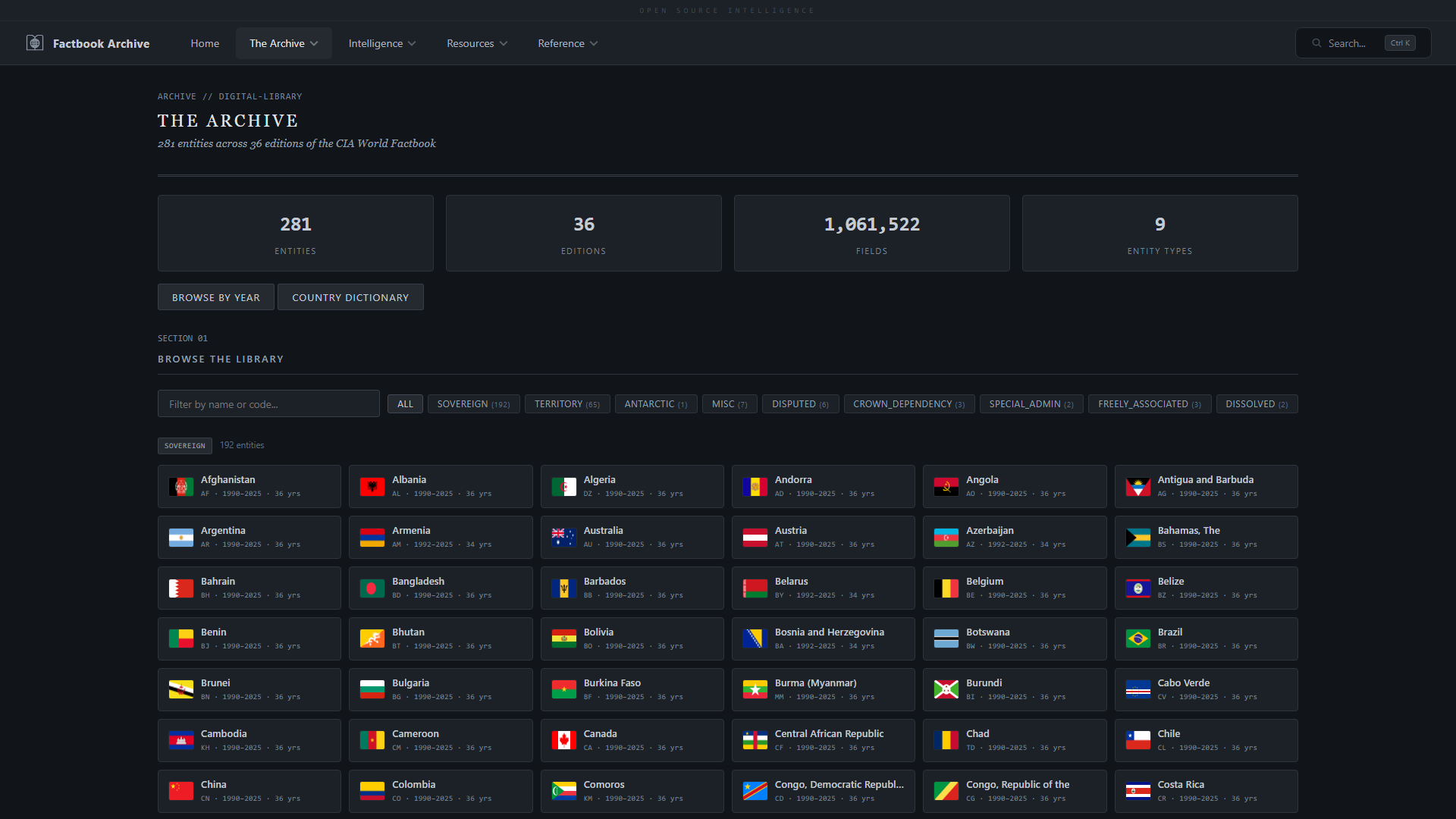 | 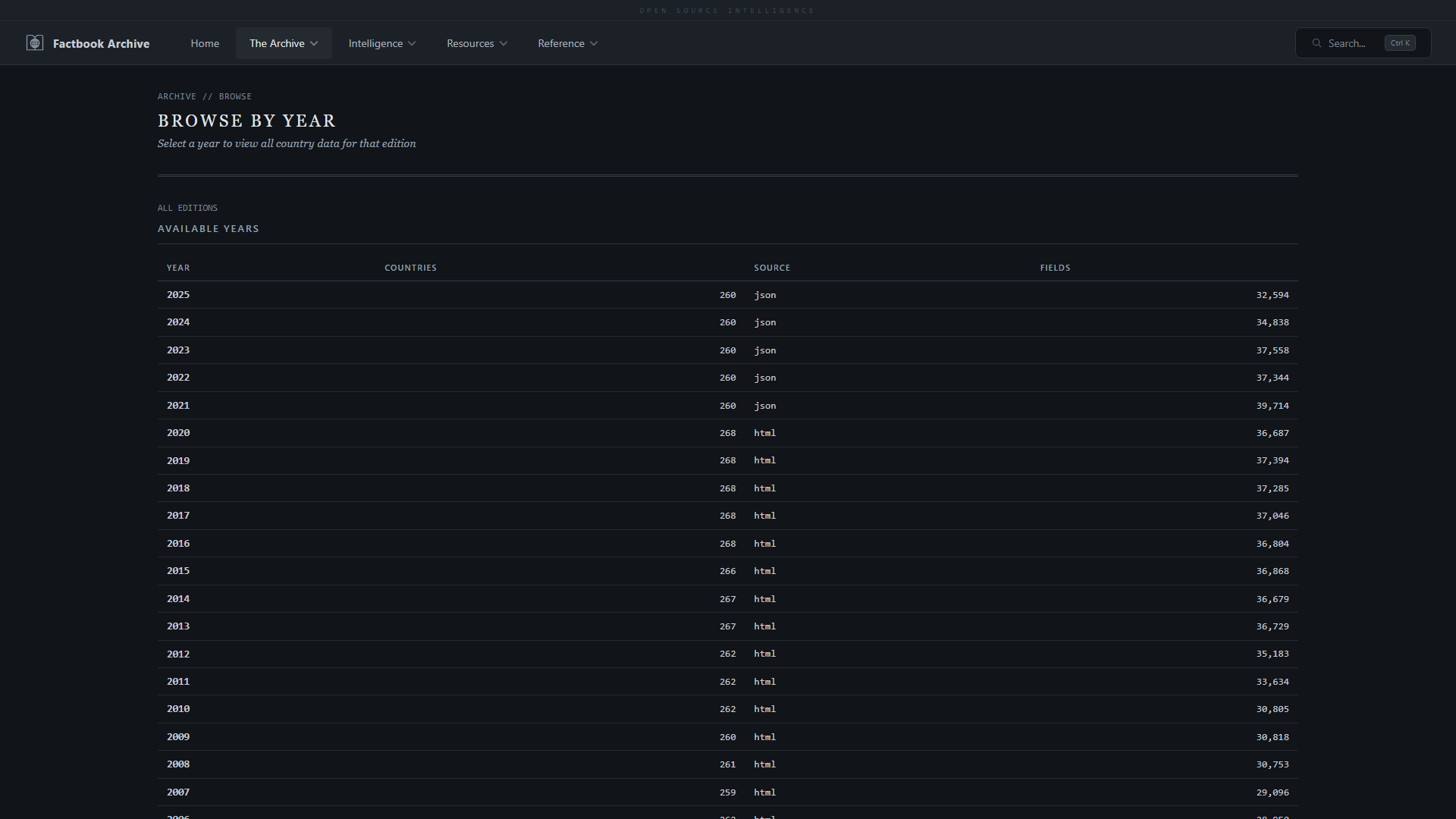 |
| **图书馆** —— 整个档案集合的卡片式概览 | **浏览档案** —— 导航 36 年间的 281 个实体 |
| 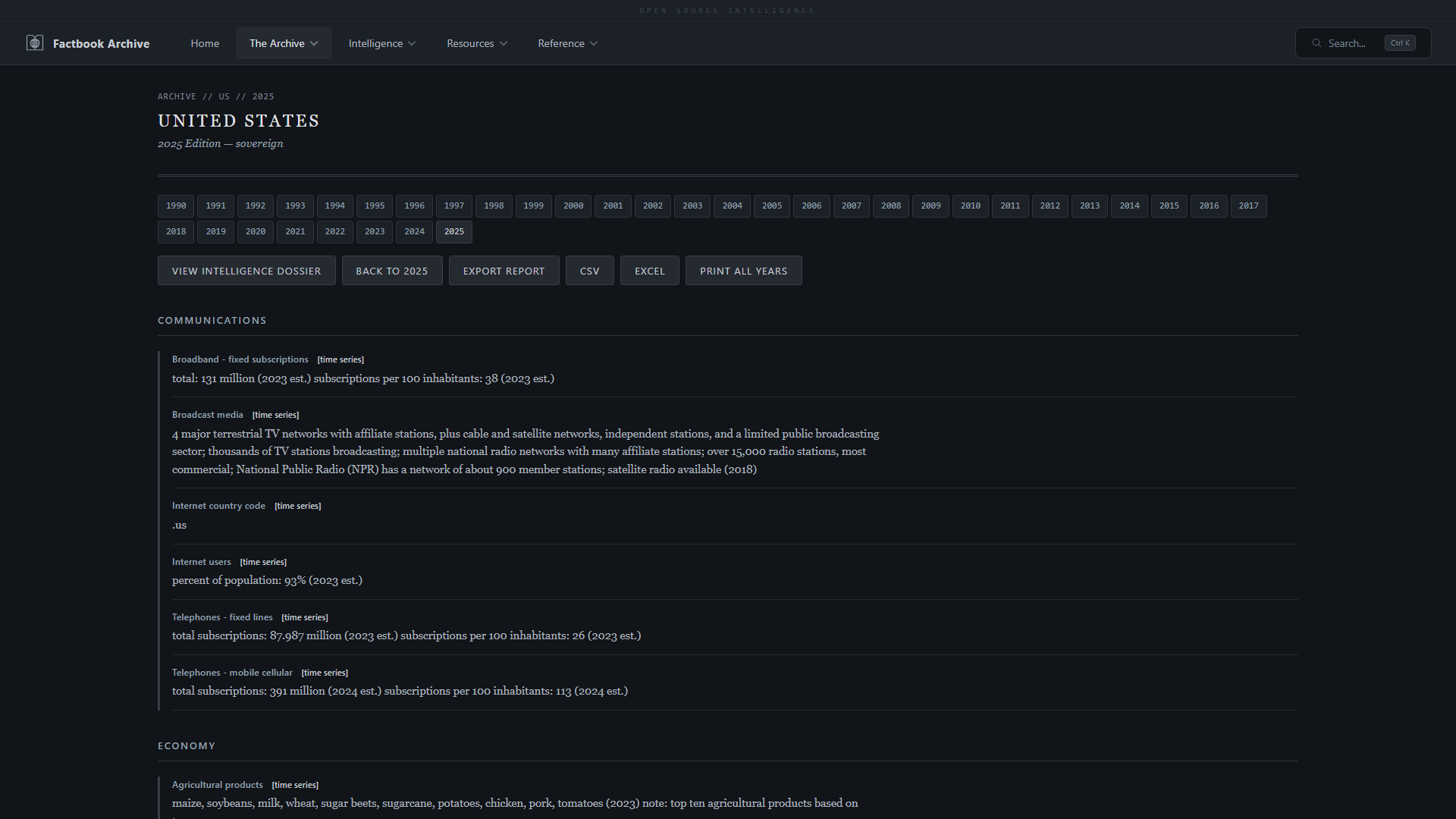 | 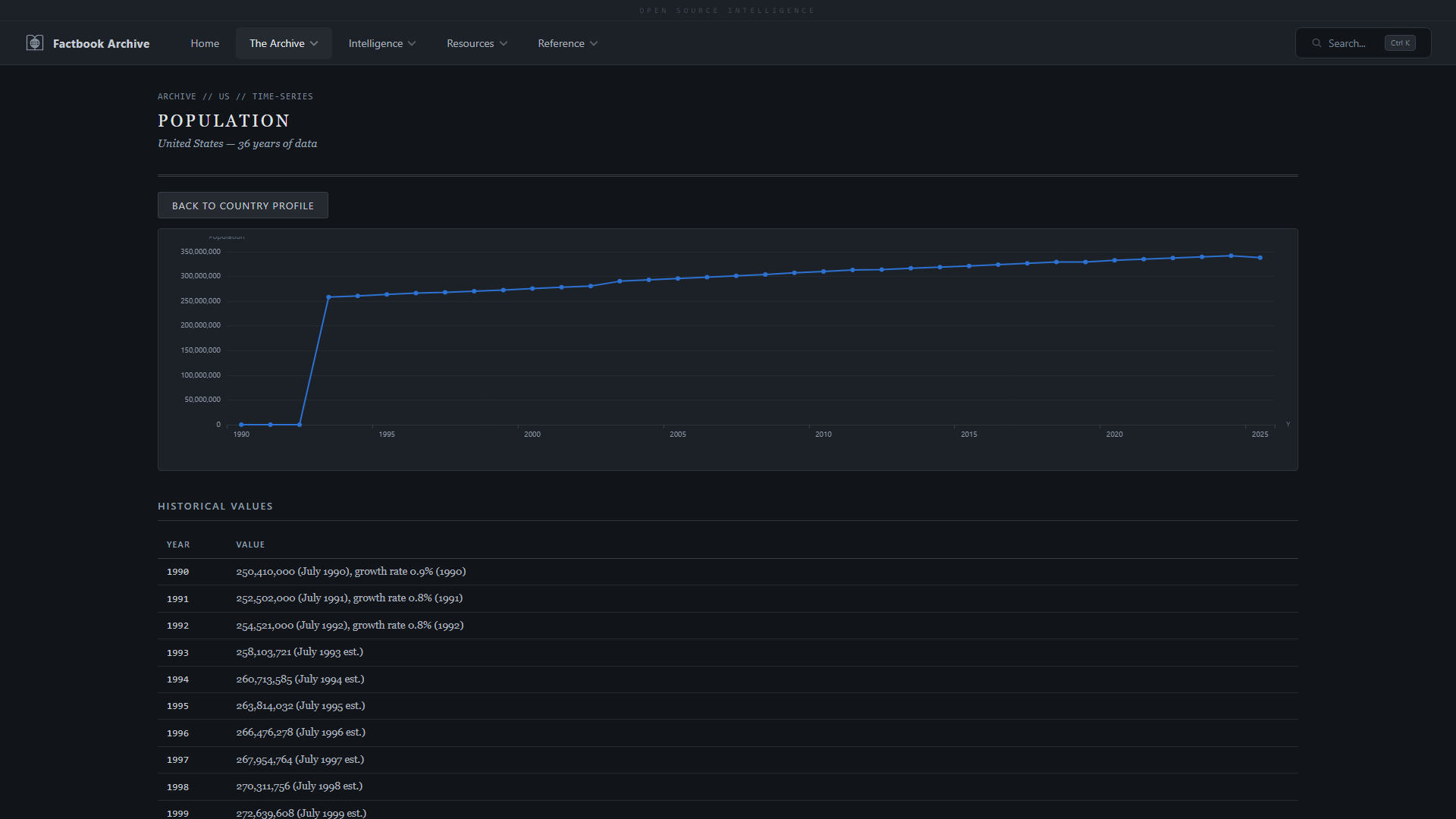 |
| **国家概况** —— 按类别划分的完整 factbook 数据 | **字段时间序列** —— 使用 Apache ECharts 跟踪 36 年间的任何字段 |
| 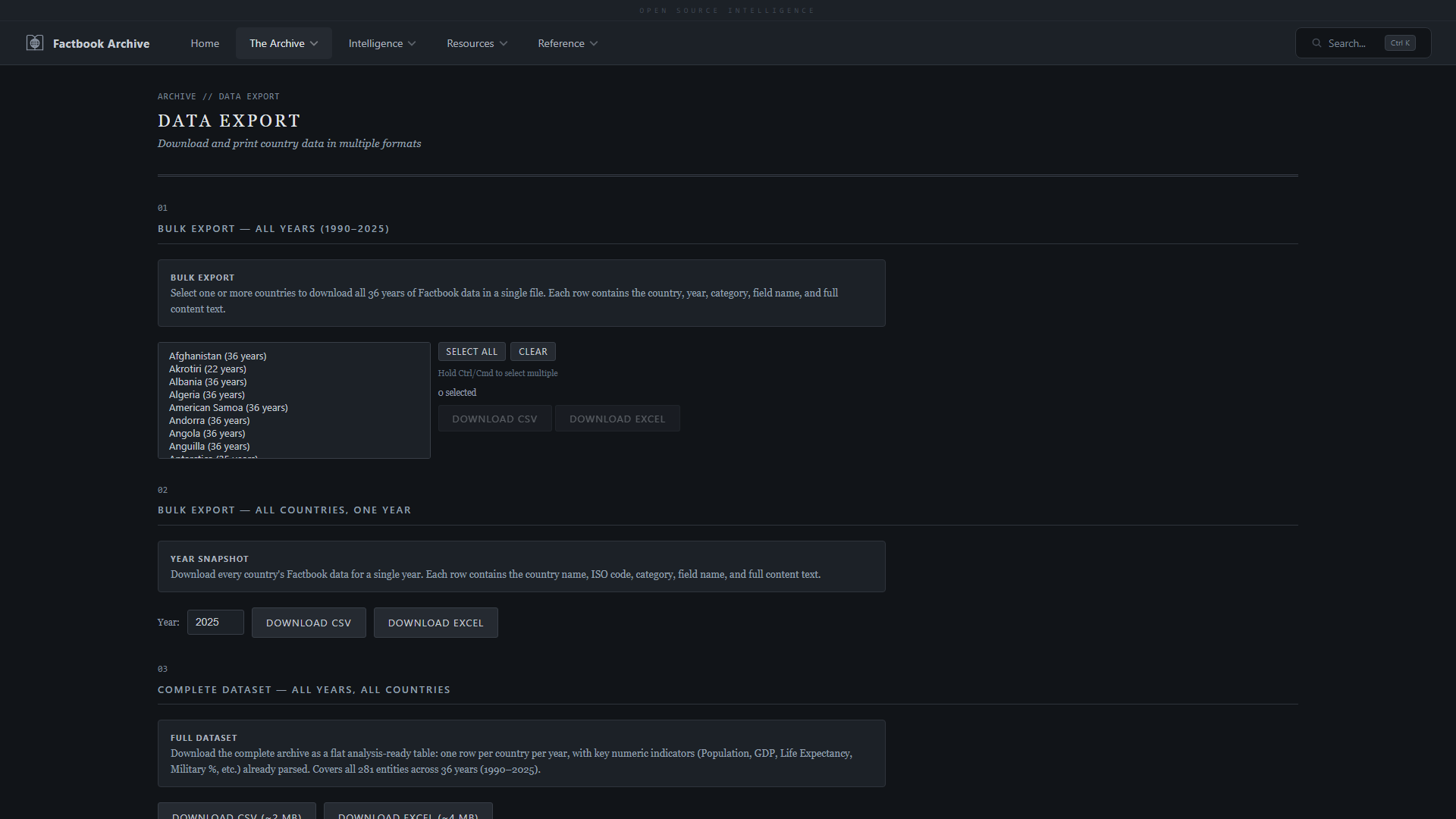 | 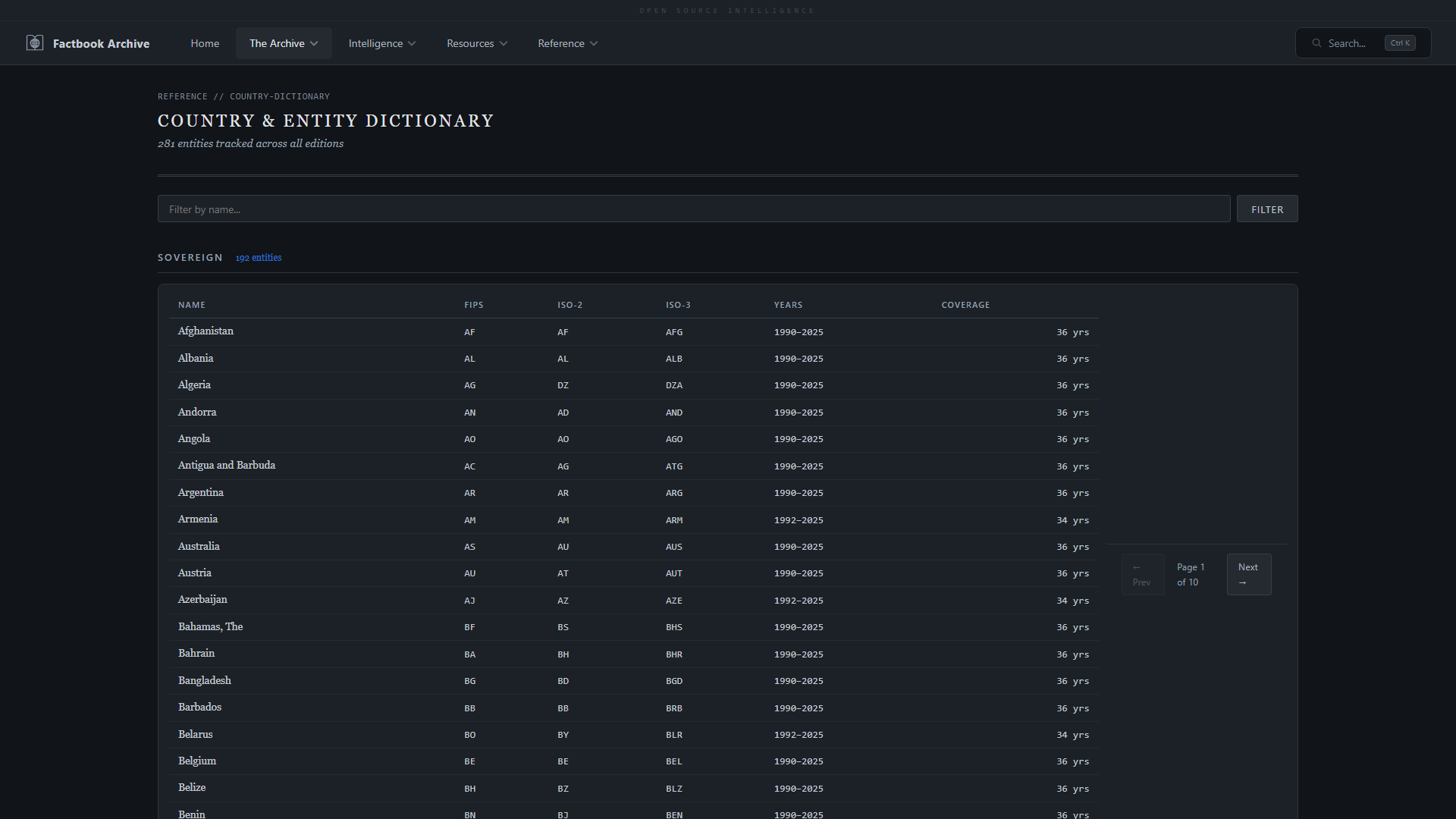 |
| **数据导出** —— CSV, Excel 和可打印 PDF 报告 | **国家词典** —— 所有 281 个实体及其类型、区域和 ISO 代码 |
|  |  |
| **文本差异** —— 并排年份比较,带高亮更改 | **Factbook 测验** —— 4 种游戏模式来测试您的世界知识 |
### 情报分析
| | |
|---|---|
| 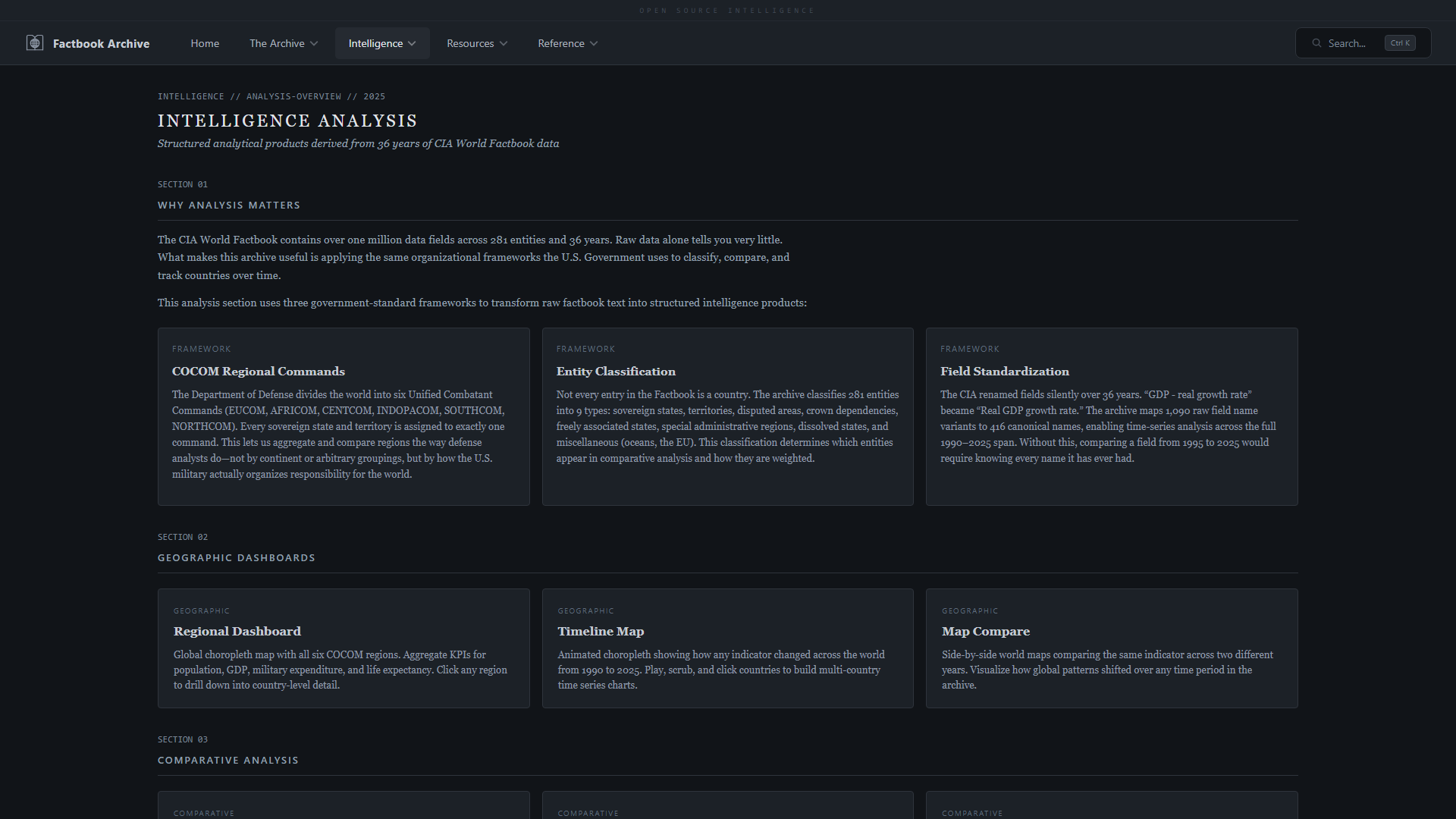 | 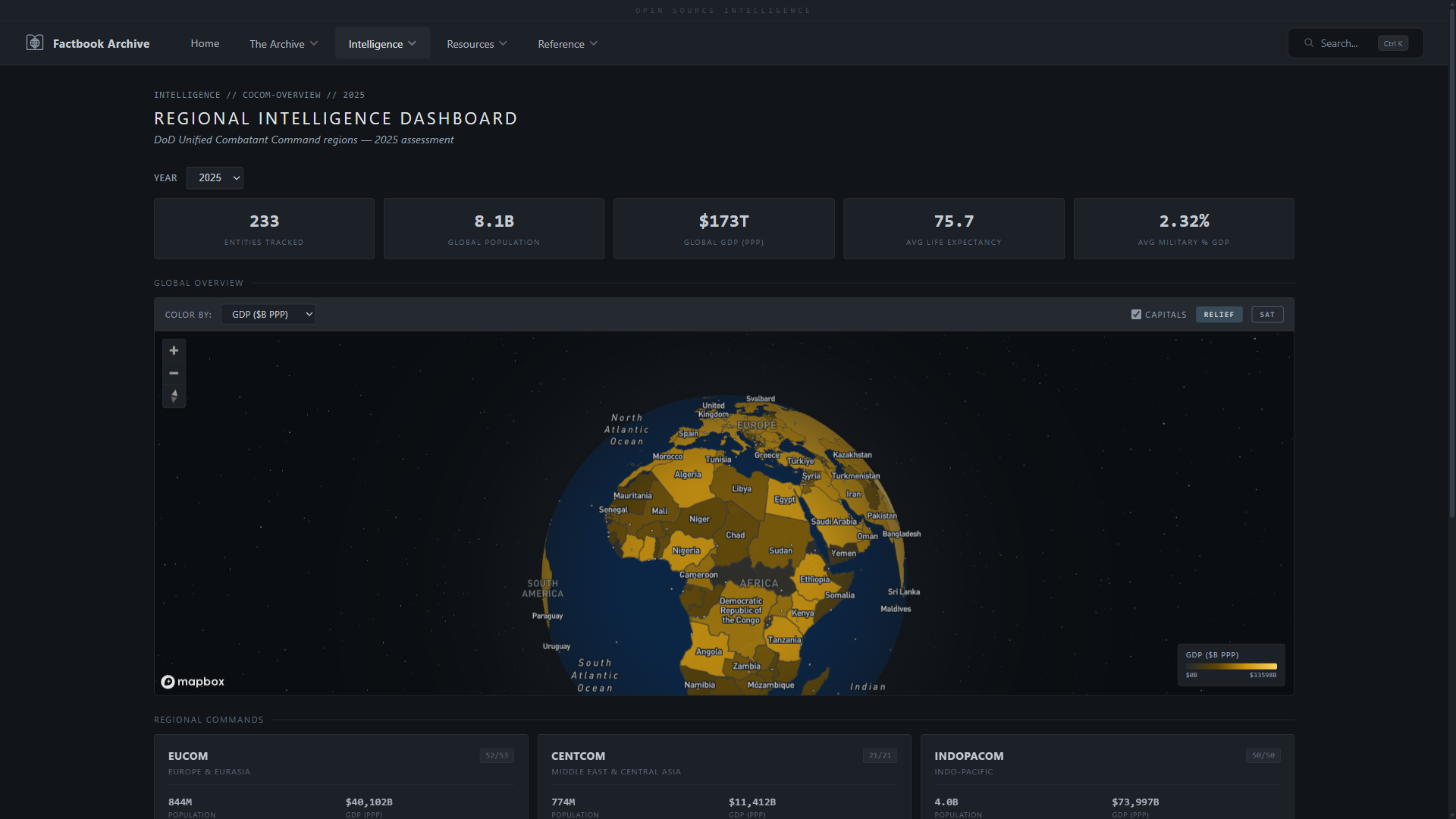 |
| **分析概览** —— 可用的仪表板和分析产品 | **区域仪表板** —— Mapbox GL JS 分级统计图,带悬停弹出窗口、首都标记和 COCOM 深入 |
| 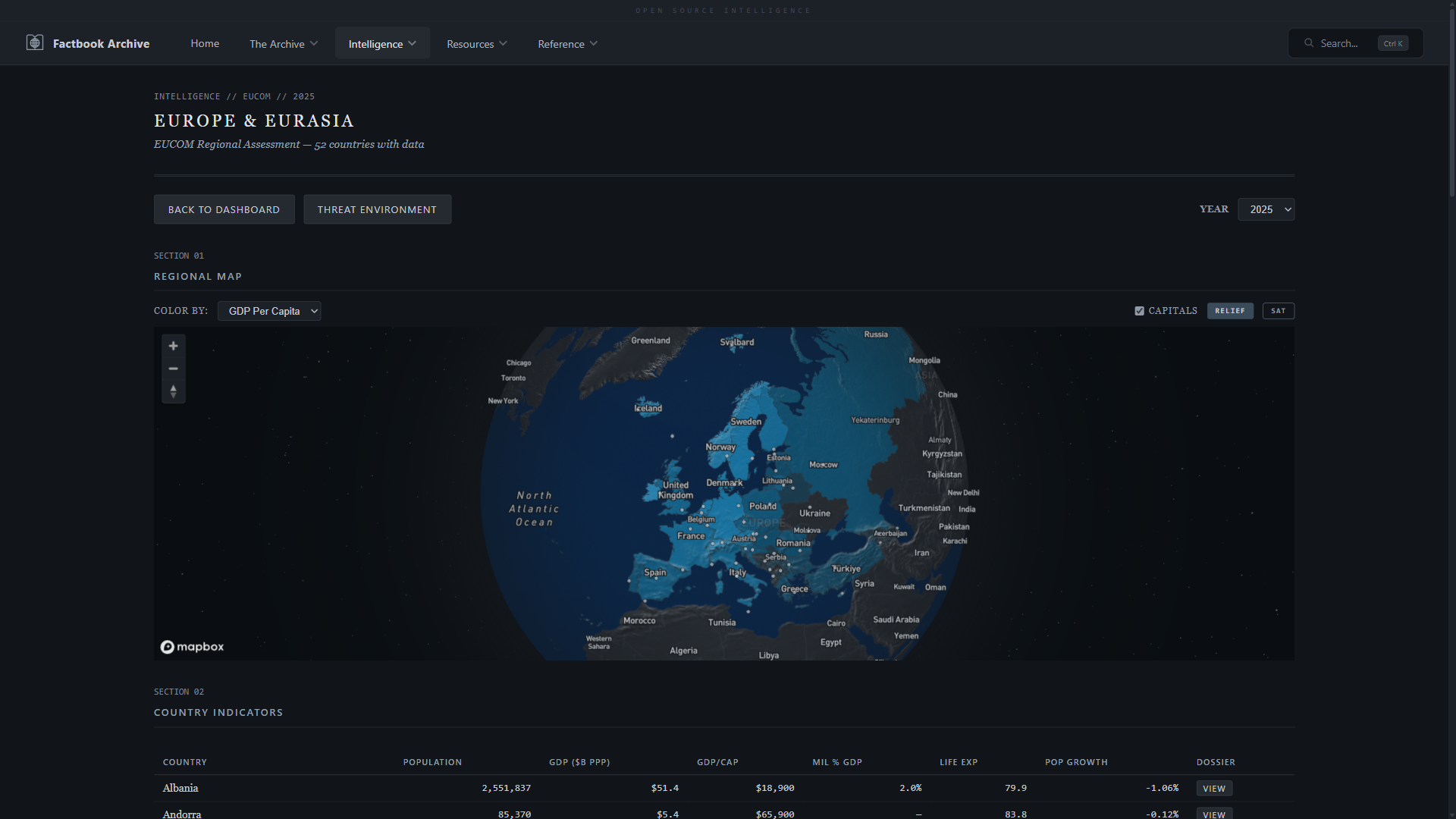 | 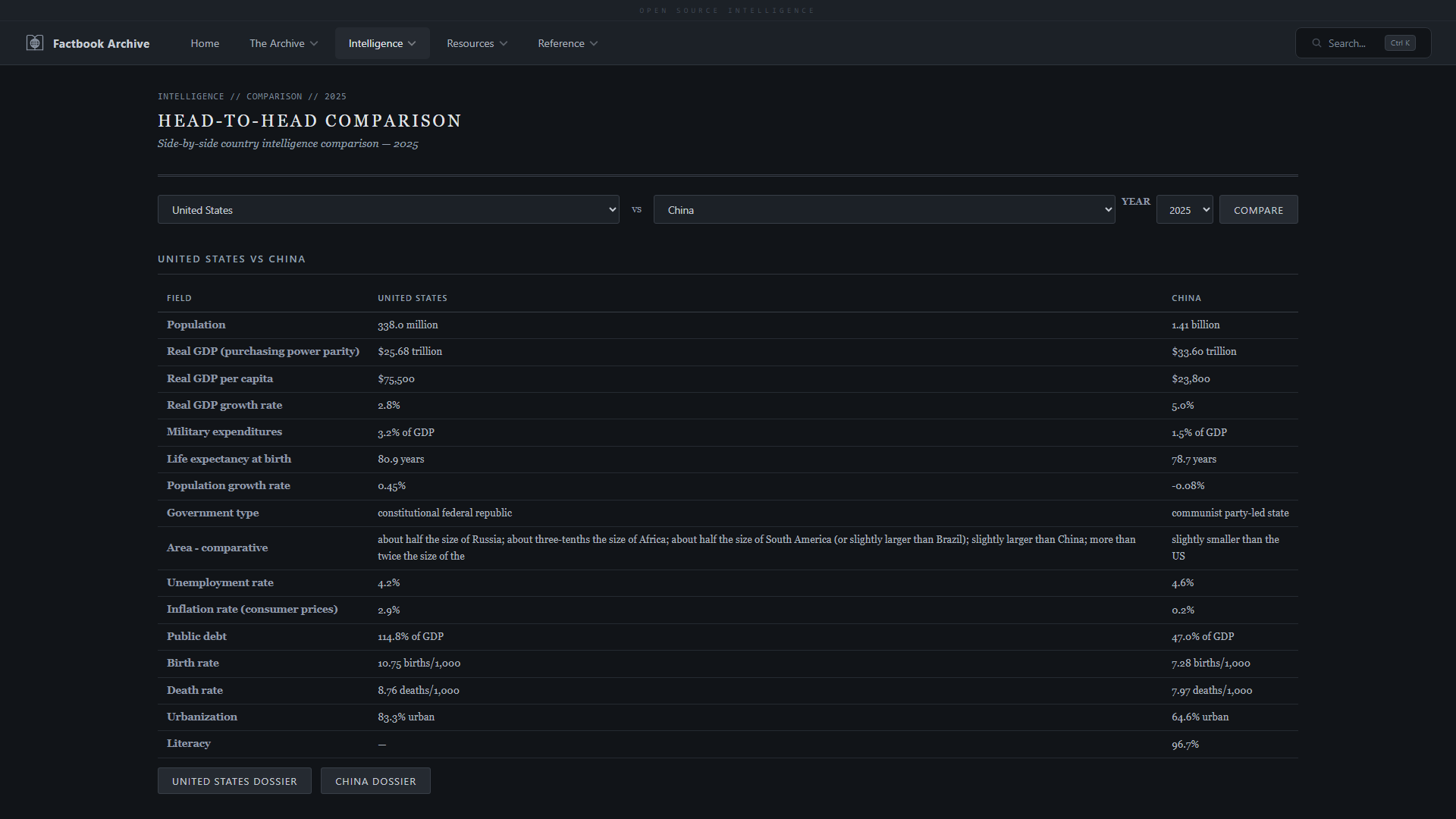 |
| **COCOM 区域详情** —— 带有国家级 KPI 的 Mapbox 区域地图 | **比较国家** —— 任意两个国家的并排比较 |
| 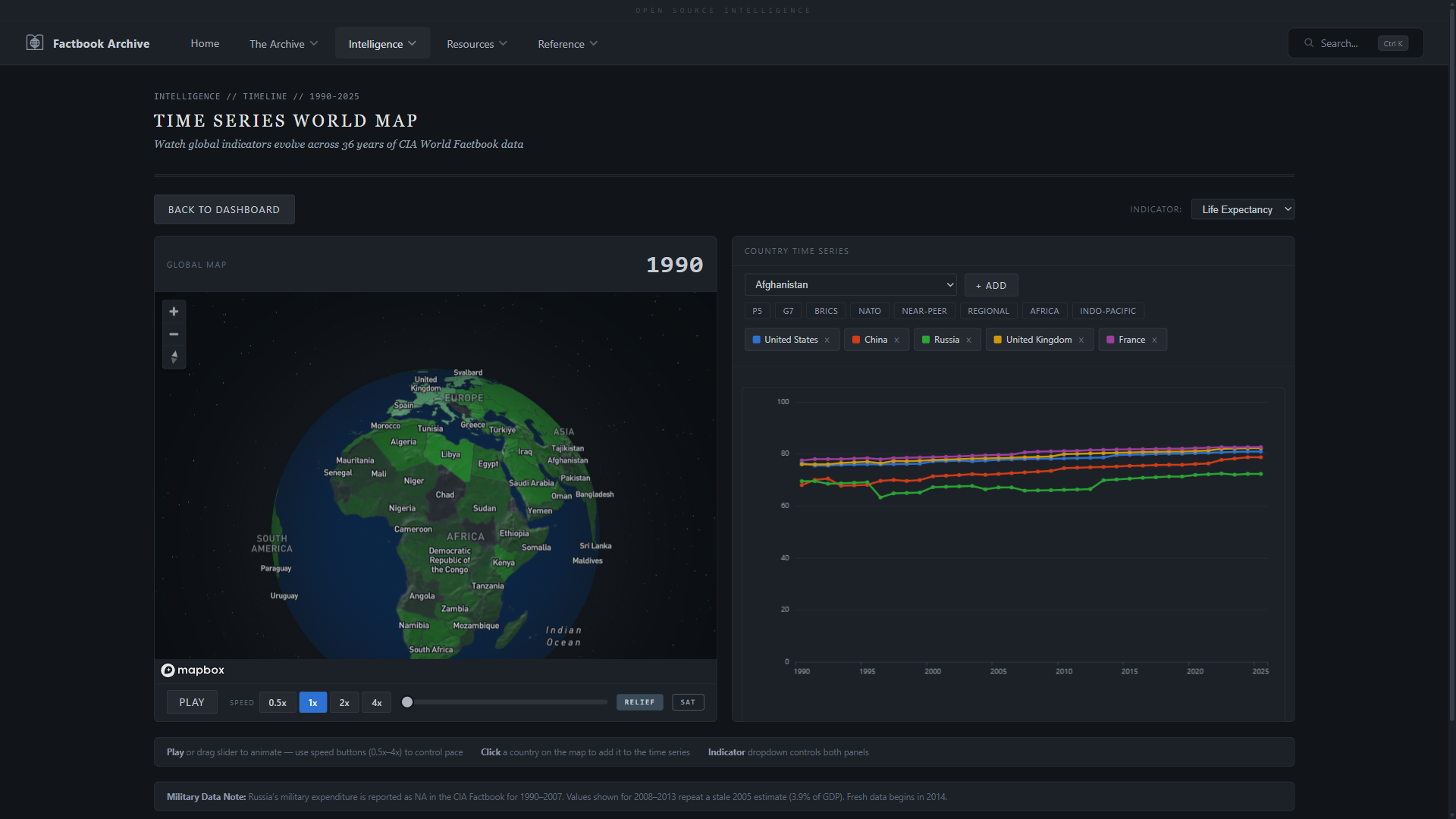 | 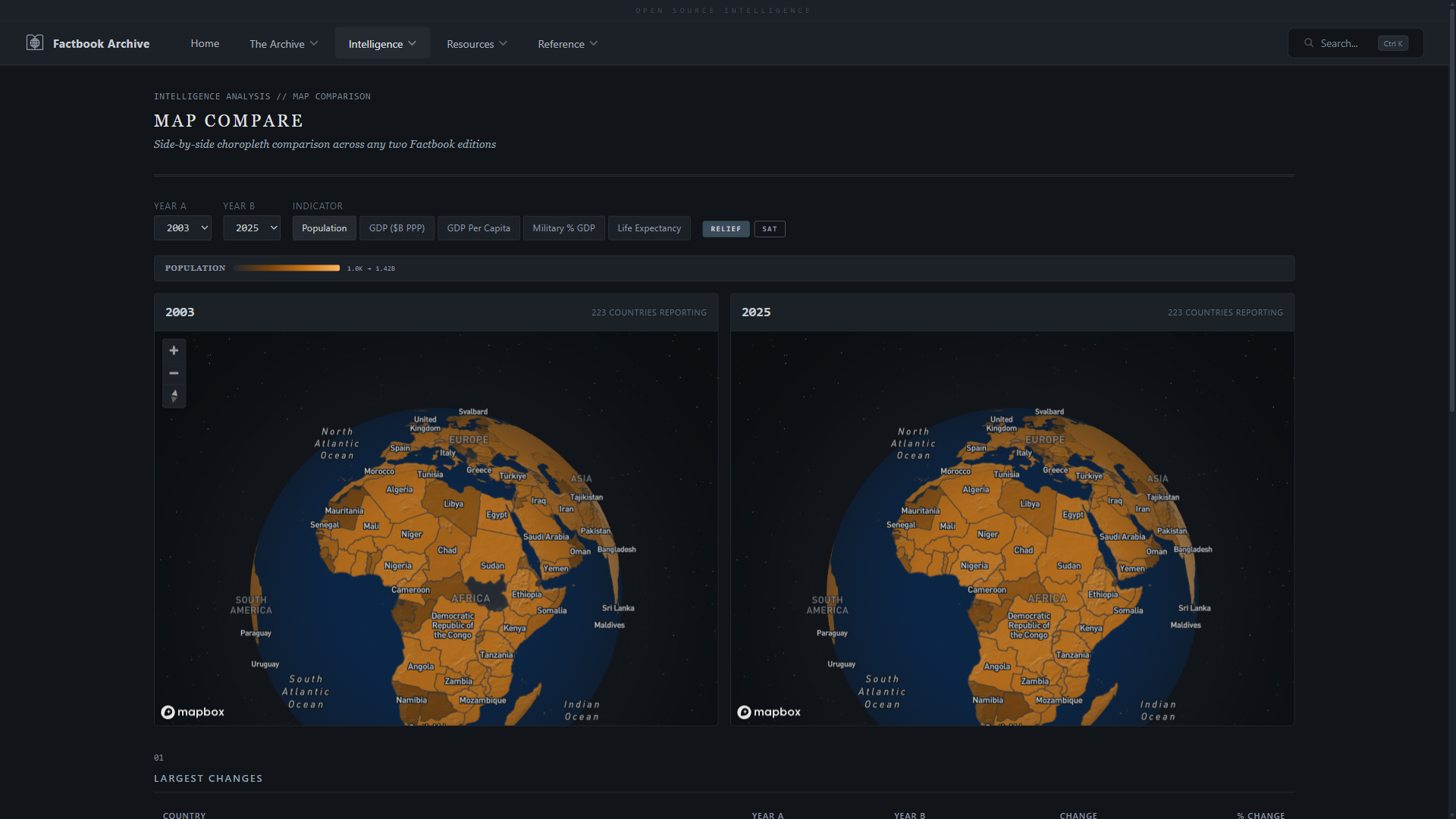 |
| **时间线地图** —— 1990-2025 年的动画 Mapbox 分级统计图,带有多国时间序列 | **地图比较** —— 两张同步的 Mapbox 地图,用于并排年份比较 |
| 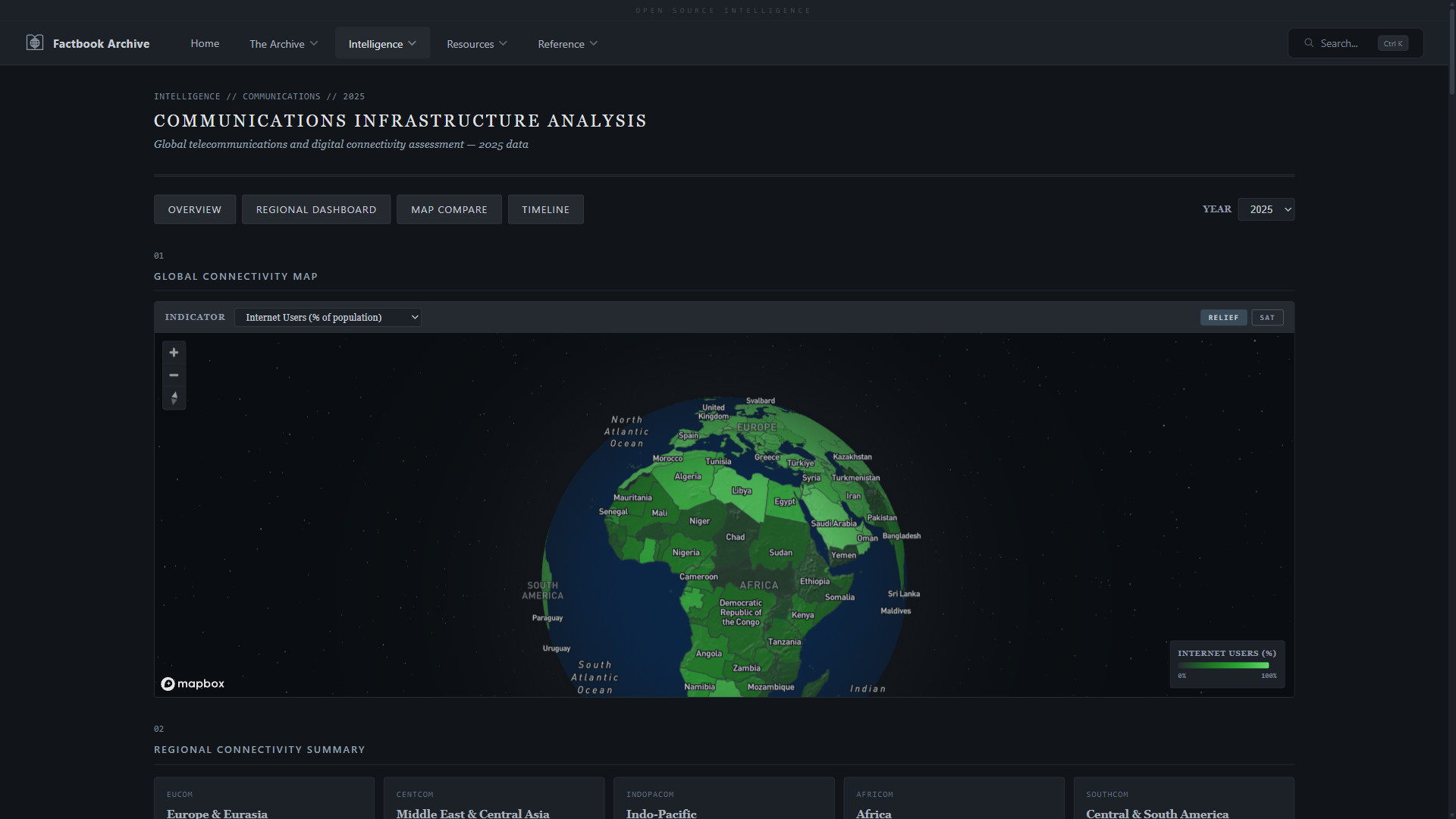 | 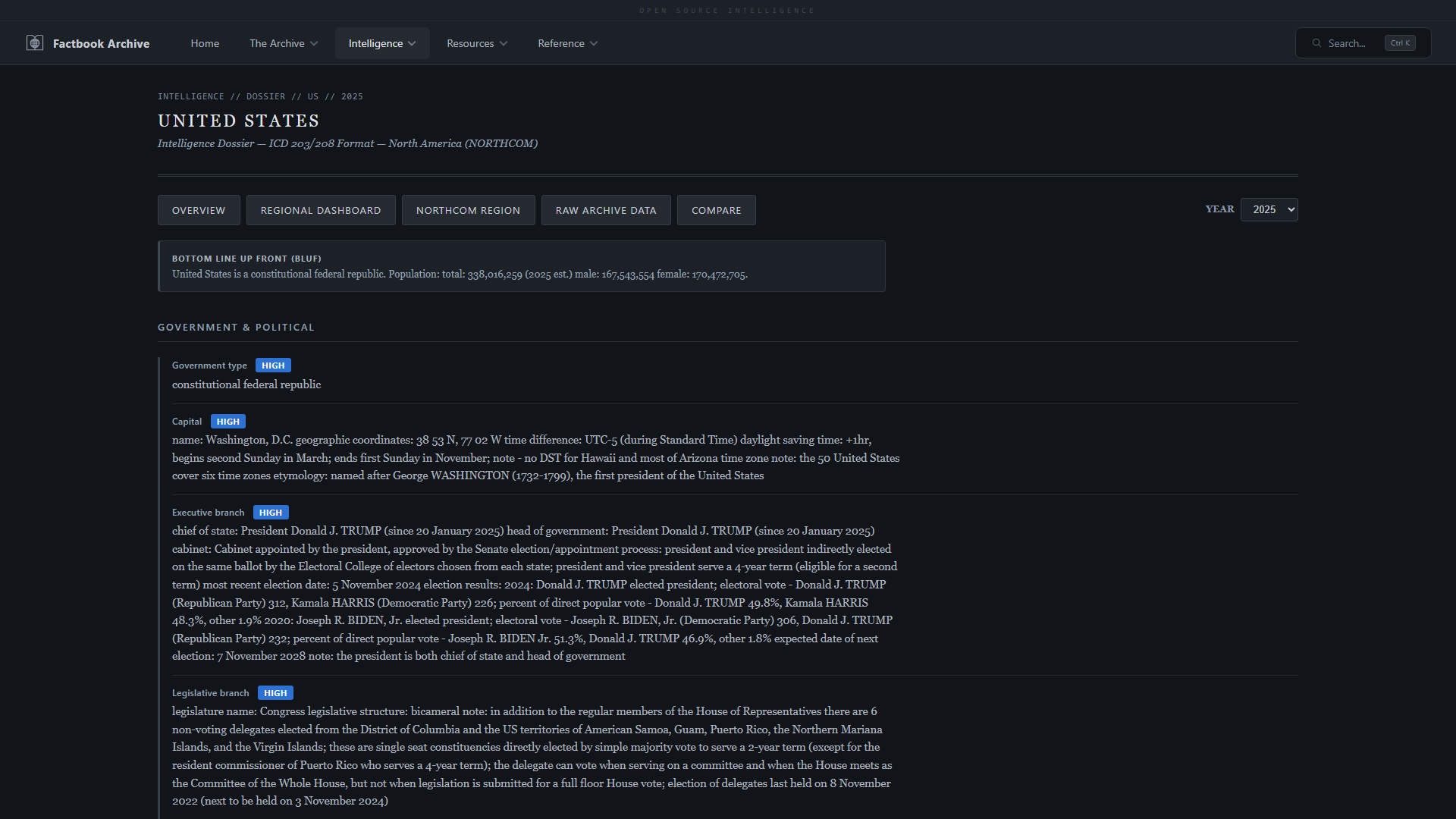 |
| **通信分析** —— 带有互联网、移动、宽带指标的 Mapbox 分级统计图 | **情报档案** —— 遵循 ICD 203 标准的国家级评估 |
|  | 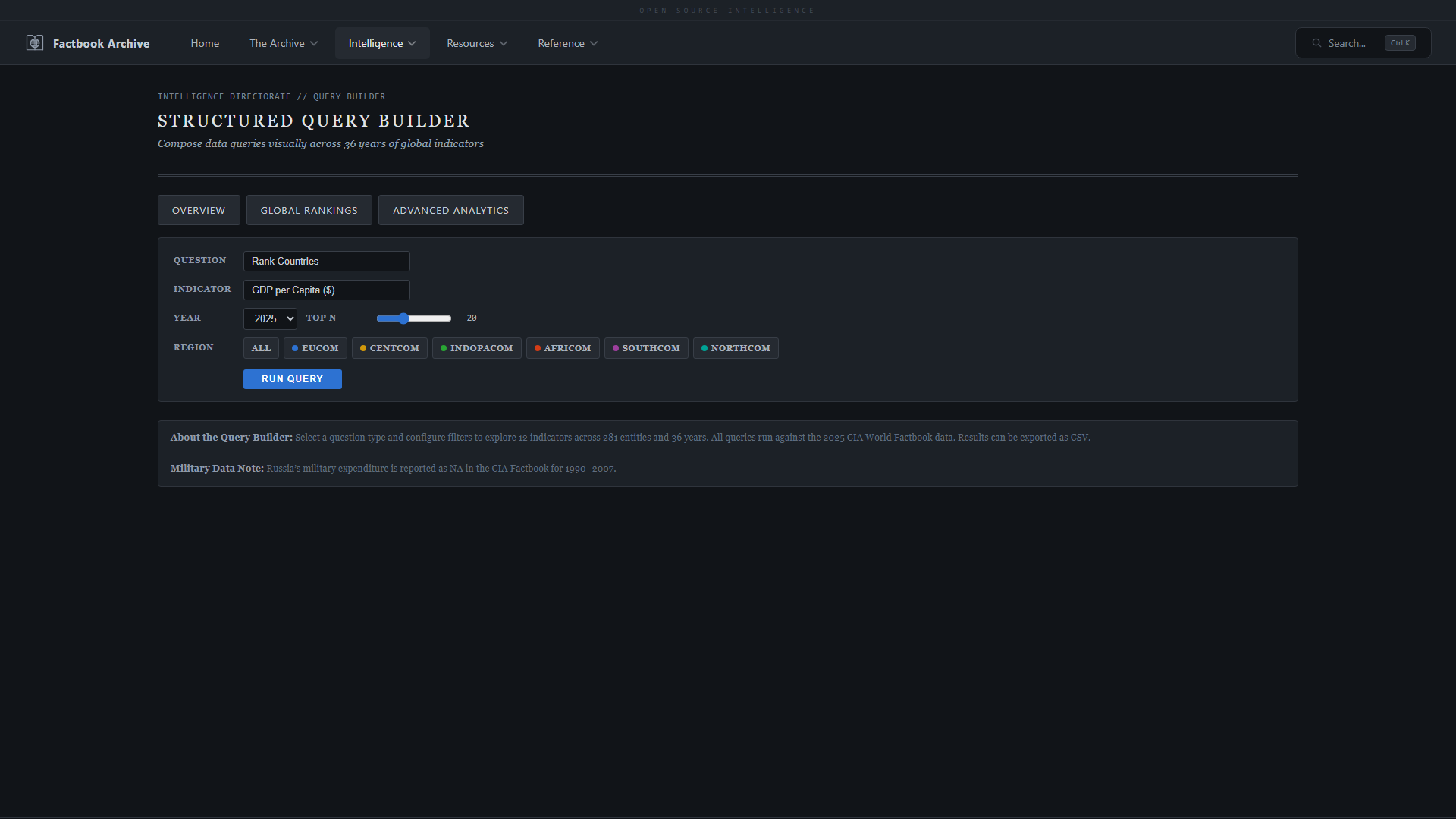 |
| **贸易网络** —— 全球贸易关系的地理和力导向图 | **查询构建器** —— 跨所有指标的自定义分析查询 |
| 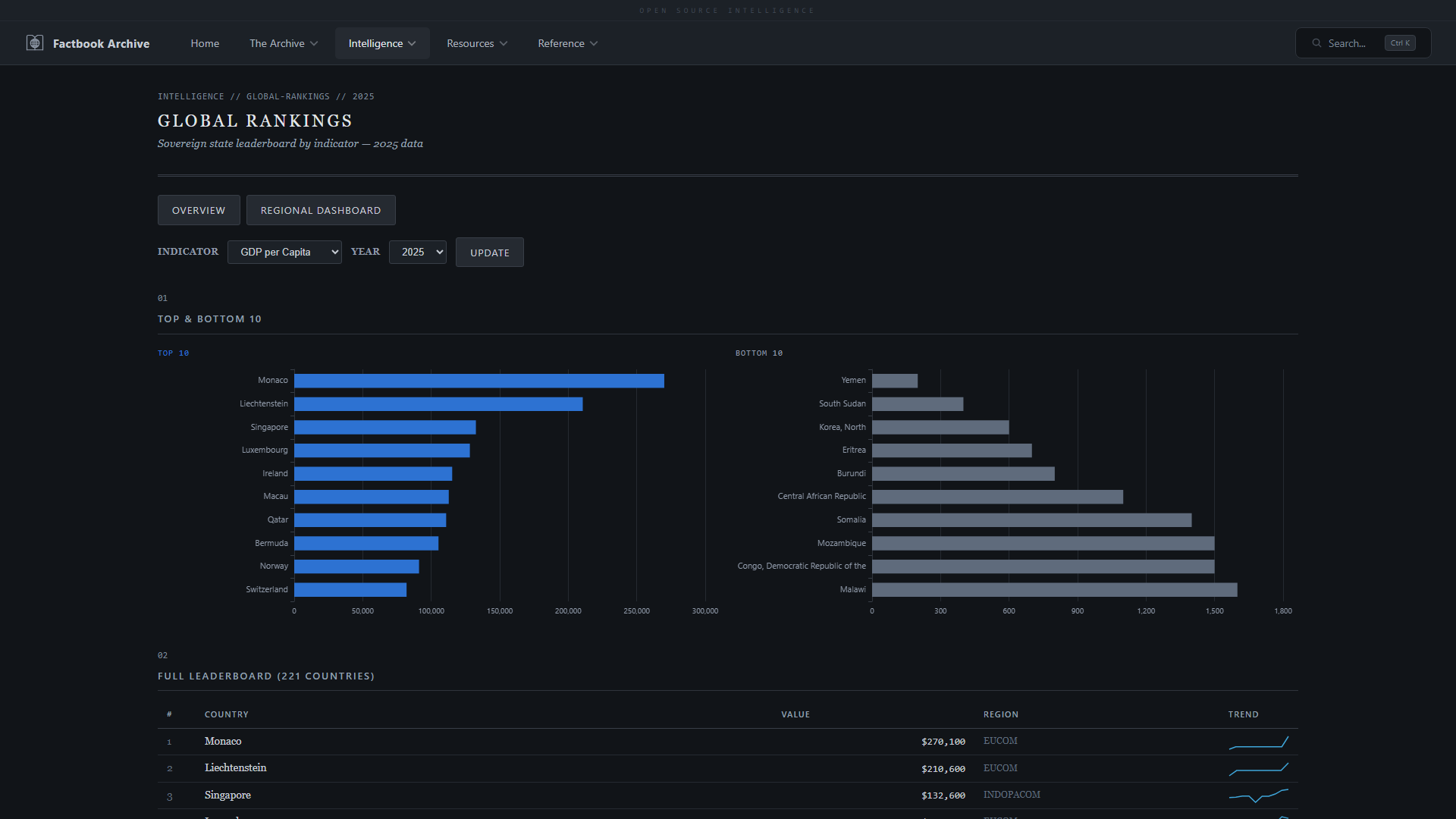 | 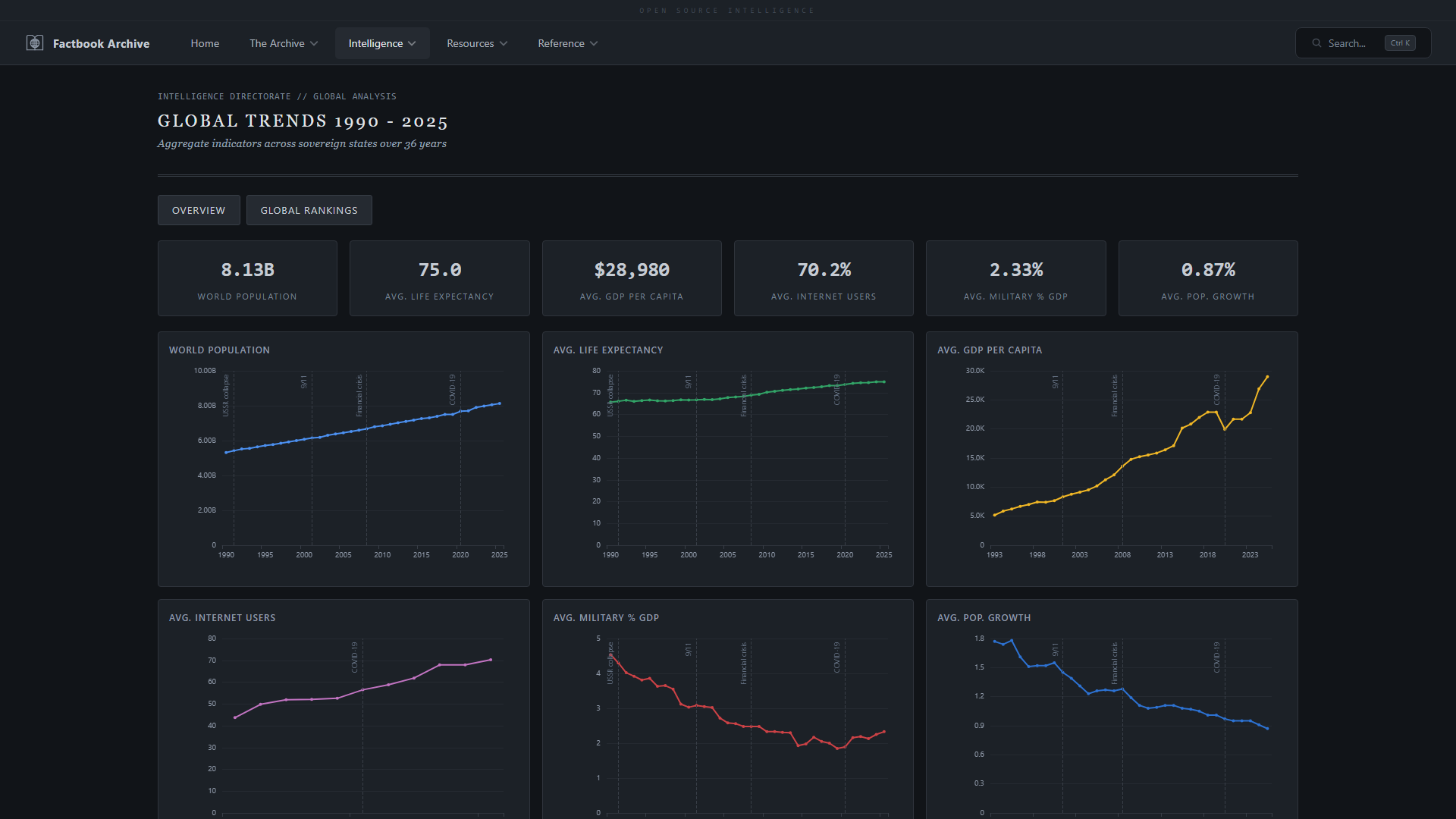 |
| **全球排名** —— 任意指标的可排序国家排名 | **全球趋势** —— 跨所有版本的多指标时间序列 |
| 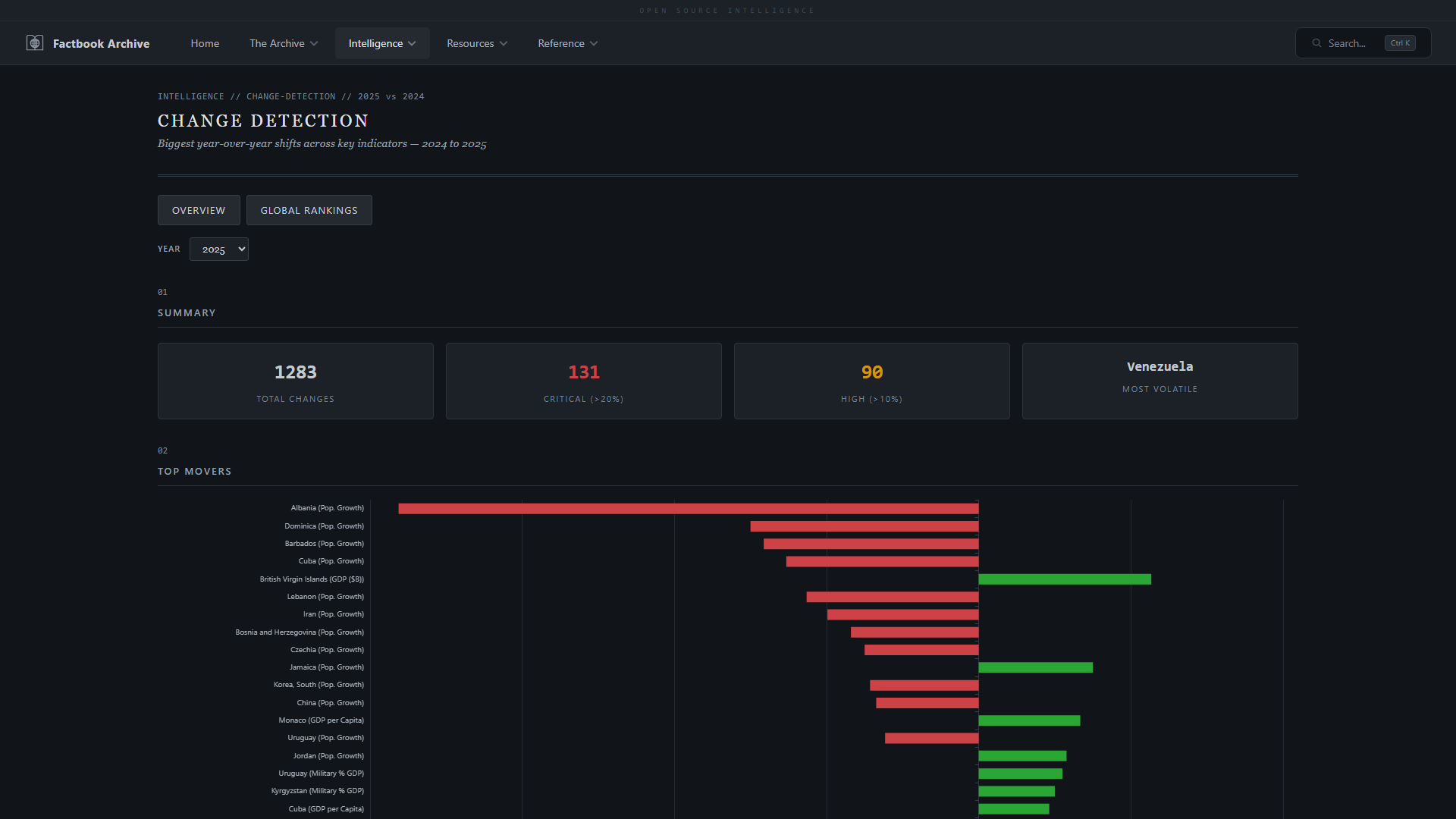 |  |
| **变化检测** —— 逐年字段变化,带有趋势图 | **字段浏览器** —— 浏览所有数据字段及覆盖率统计 |
| 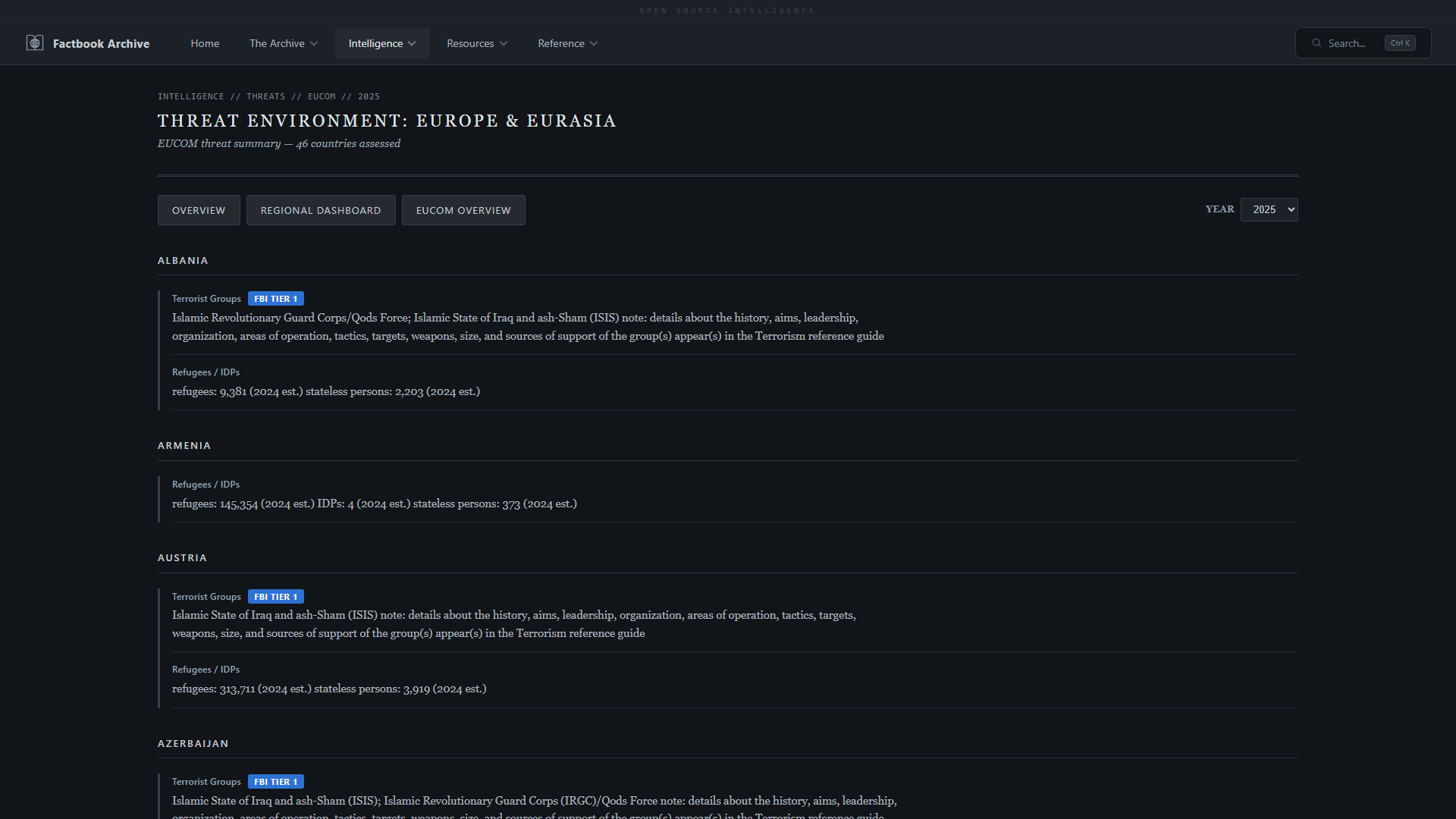 | 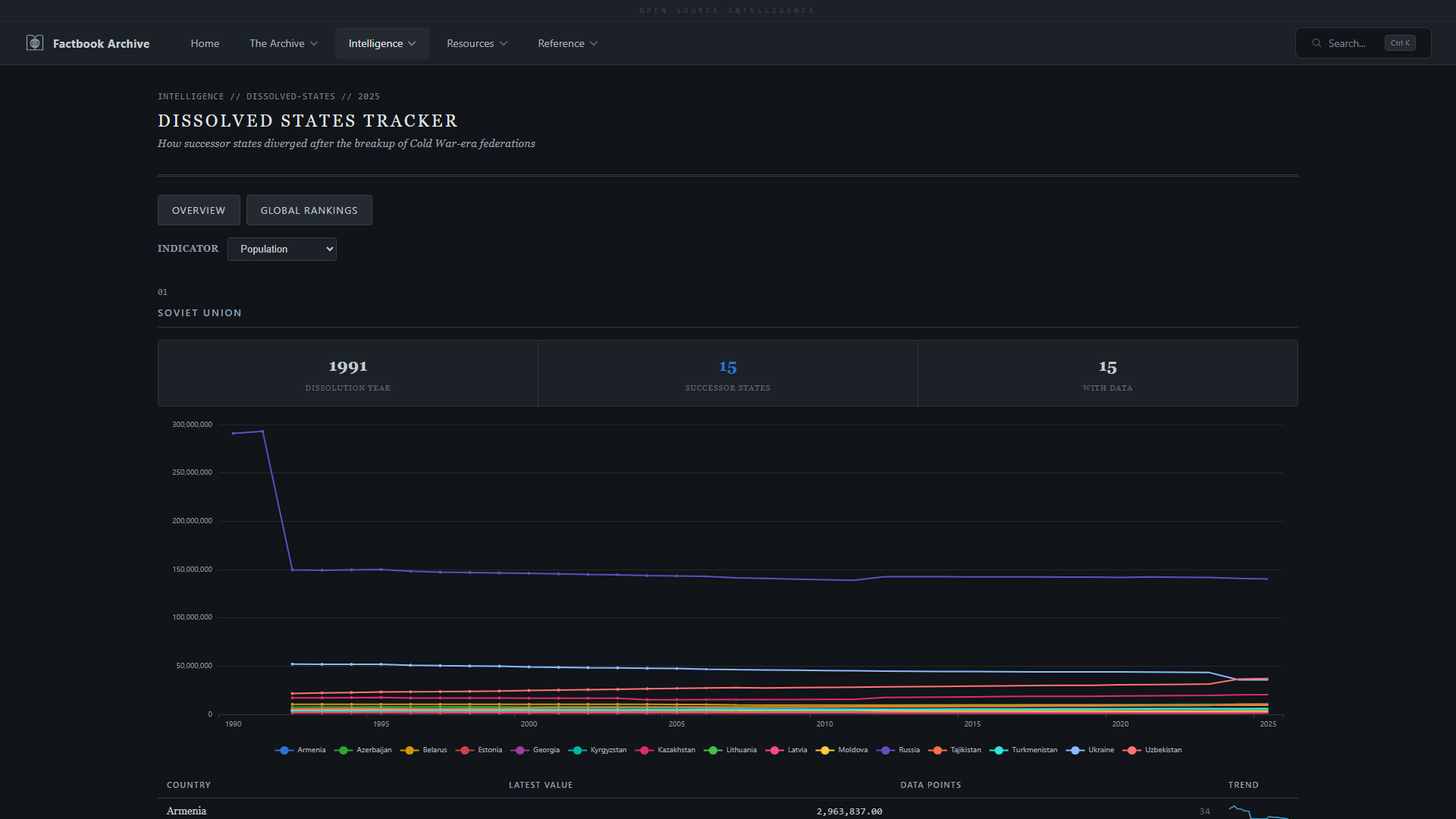 |
| **区域威胁简报** —— COCOM 级别的不稳定和安全指标 | **已解体国家** —— Factbook 中不再包含的历史实体 |
|  | |
| **组织网络** —— 国际组织成员资格和联盟 | |
## 许可证
CIA World Factbook 是美国政府的工作成果,属于**公共领域**(17 U.S.C. § 105)。本档案根据 [CC0 1.0 Universal (Public Domain Dedication)](LICENSE) 发布。
## 关于
CIA World Factbook 最初于 1962 年作为机密文件出版,并从 1971 年开始向公众开放。在线版于 1990 年代推出,每周更新,直至 2026 年 2 月 4 日停刊。
建立此档案是为了作为一个保存项目,确保这一独特的纵向数据集对研究人员、分析人员和公众保持可访问性。 标签:BSD, CIA World Factbook, DFIR, ESC4, ETL, JavaCC, OSINT, Python, SQL, SQLite, Wayback Machine, 世界概况, 人口统计, 代码示例, 信息检索, 全文检索, 公共数据, 历史数据, 反汇编, 国家信息, 地缘政治, 幻觉缓解, 数据分析, 数据归档, 数据挖掘, 无后门, 系统审计, 经济数据, 逆向工具
|