Tanmay-Bhatnagar22/TraceLens
GitHub: Tanmay-Bhatnagar22/TraceLens
一款基于 Python 和 Tkinter 的桌面元数据分析工具,专注从 50 多种文件格式中提取元数据并进行隐私风险评分和取证分析。
Stars: 1 | Forks: 0
# TraceLens: 智能元数据分析与隐私检测工具包







**TraceLens** 是一款综合性桌面应用程序,专注于隐私和取证风险评估,用于提取、分析、编辑和管理文件元数据。它使用 Python 和 Tkinter 构建,为专业人员、取证分析师和注重隐私的用户提供了友好的 GUI 和强大的命令行界面。
## 目录
- [概述](#overview)
- [核心功能](#key-features)
- [截图](#screenshots)
- [功能分解](#feature-breakdown)
- [支持的文件类型](#supported-file-types)
- [项目结构](#project-structure)
- [系统架构](#architecture)
- [技术栈](#technical-stack)
- [安装说明](#installation)
- [使用方法](#usage)
- [GUI 应用程序](#gui-application)
- [命令行界面](#command-line-interface)
- [配置](#configuration)
- [数据库模式](#database-schema)
- [API 参考](#api-reference)
- [测试](#testing)
- [故障排除](#troubleshooting)
- [已知限制](#known-limitations)
- [许可证](#license)
## 概述
TraceLens 使用户能够:
- 从 50 多种文件格式中**提取**详细的元数据
- 使用智能评分**分析**隐私风险和取证影响
- 通过精细的字段级控制**编辑**和管理元数据
- 以多种格式(PDF、JSON、XML、CSV、Excel)**生成**综合报告
- 使用 SQLite 持久化**跟踪**提取历史
- 通过交互式仪表板**可视化**元数据趋势和风险模式
非常适合:
- 数字取证专业人员
- 隐私倡导者和安全研究人员
- 数据分析师和合规团队
- 系统管理员和 IT 审计员
## 核心功能
**多格式元数据提取**
- 通过 PyPDF2 处理 PDF 文件
- 带有行数统计和编码检测的文本文档
- 包含 EXIF 数据的图像
- 音频文件(MP3、FLAC、M4A、WAV)
- Office 文档
- 通过 Hachoir 解析器支持 50 多种其他格式
**智能风险分析**
- 基于规则的隐私风险评分器(0-100 分制)
- 检测 GPS 坐标、作者身份、设备信息、编辑痕迹
- 识别隐藏的元数据块(XMP、EXIF、IPTC、MakerNote)
- 为提取的文件生成取证时间线
- 颜色编码的风险等级:LOW、MEDIUM、HIGH
**元数据编辑与管理**
- 带验证的字段级编辑控制
- 将元数据更改写回文件
- 多文件批量编辑
- 撤销/重做功能
- 每个文件的版本跟踪
**综合报告**
- 导出为 PDF、JSON、XML、CSV、Excel
- 带有聚合摘要的批量处理
- 带有标题和章节的格式化文本报告
- 所有报告格式中均包含风险分析
- 可定制的报告模板
**SQLite 历史记录与持久化**
- 用于提取历史记录的本地数据库
- 搜索和过滤提取的记录
- 按任意字段排序
- 批量导出提取历史
- 带确认的数据删除
- 时间范围过滤
**交互式仪表板**
- 带有图表和图形的统计数据
- 元数据趋势分析
- 风险分布可视化
- 文件类型细分
- 提取时间线
**双界面**
- **GUI**:功能齐全的 Tkinter 桌面应用程序
- **CLI**:菜单驱动的终端界面
## 截图
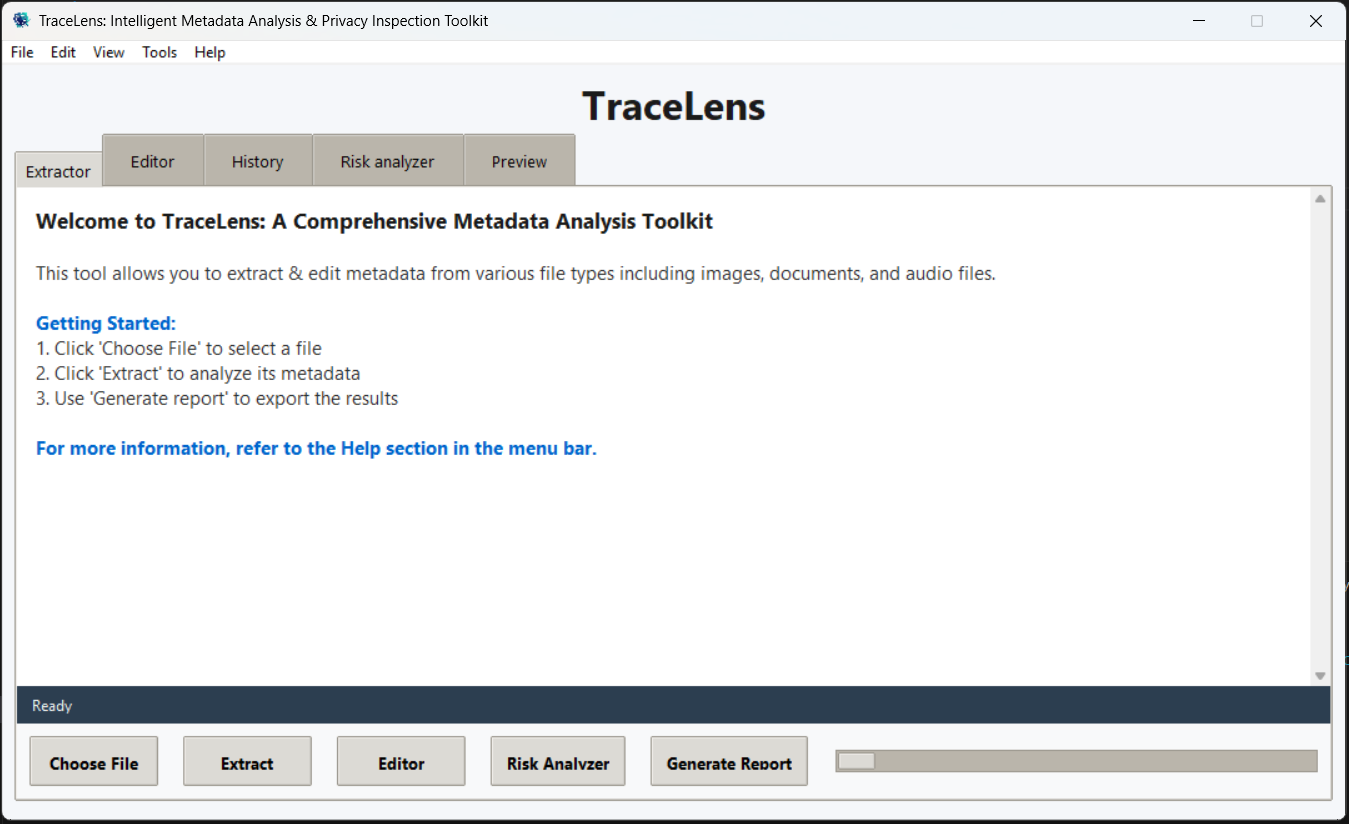
### 应用程序界面
主应用程序窗口
### GUI 功能
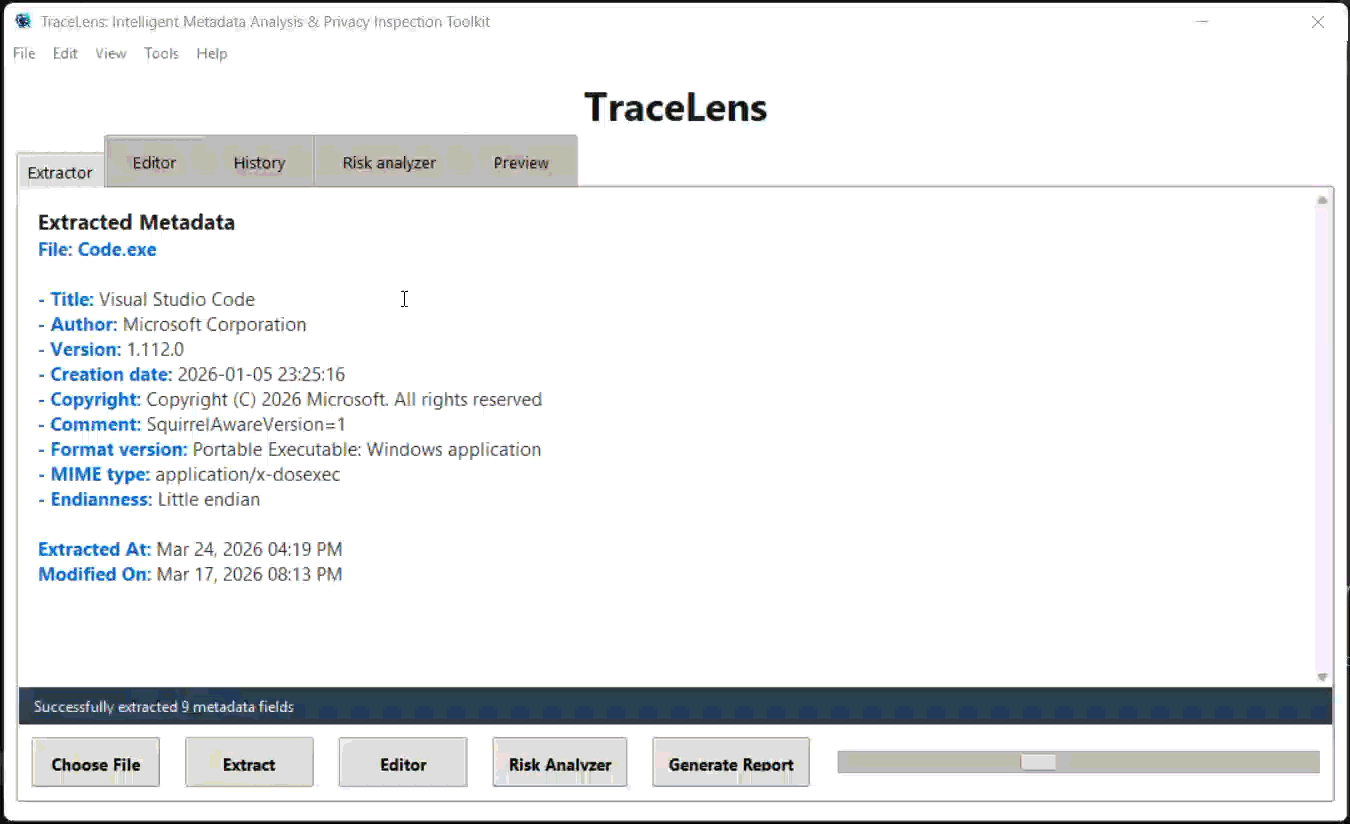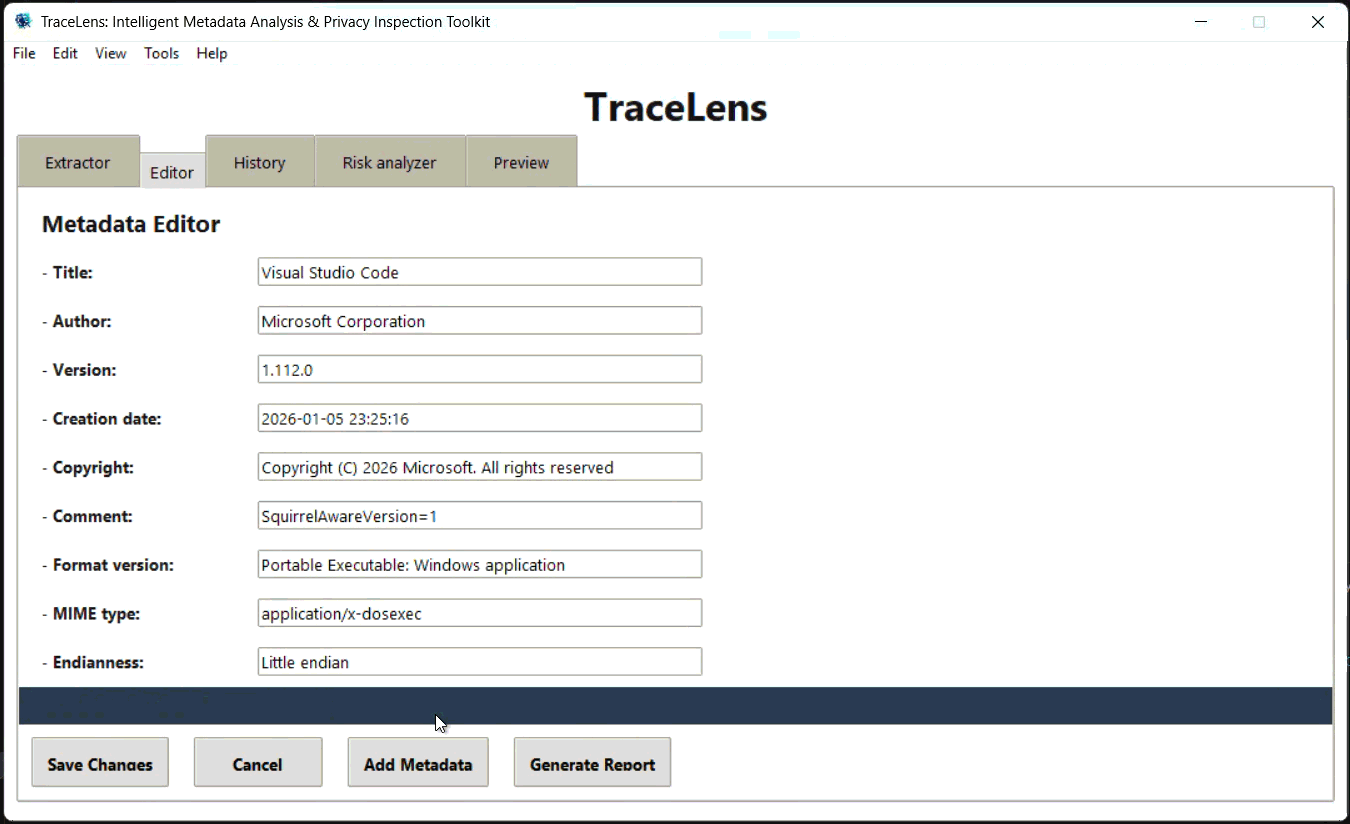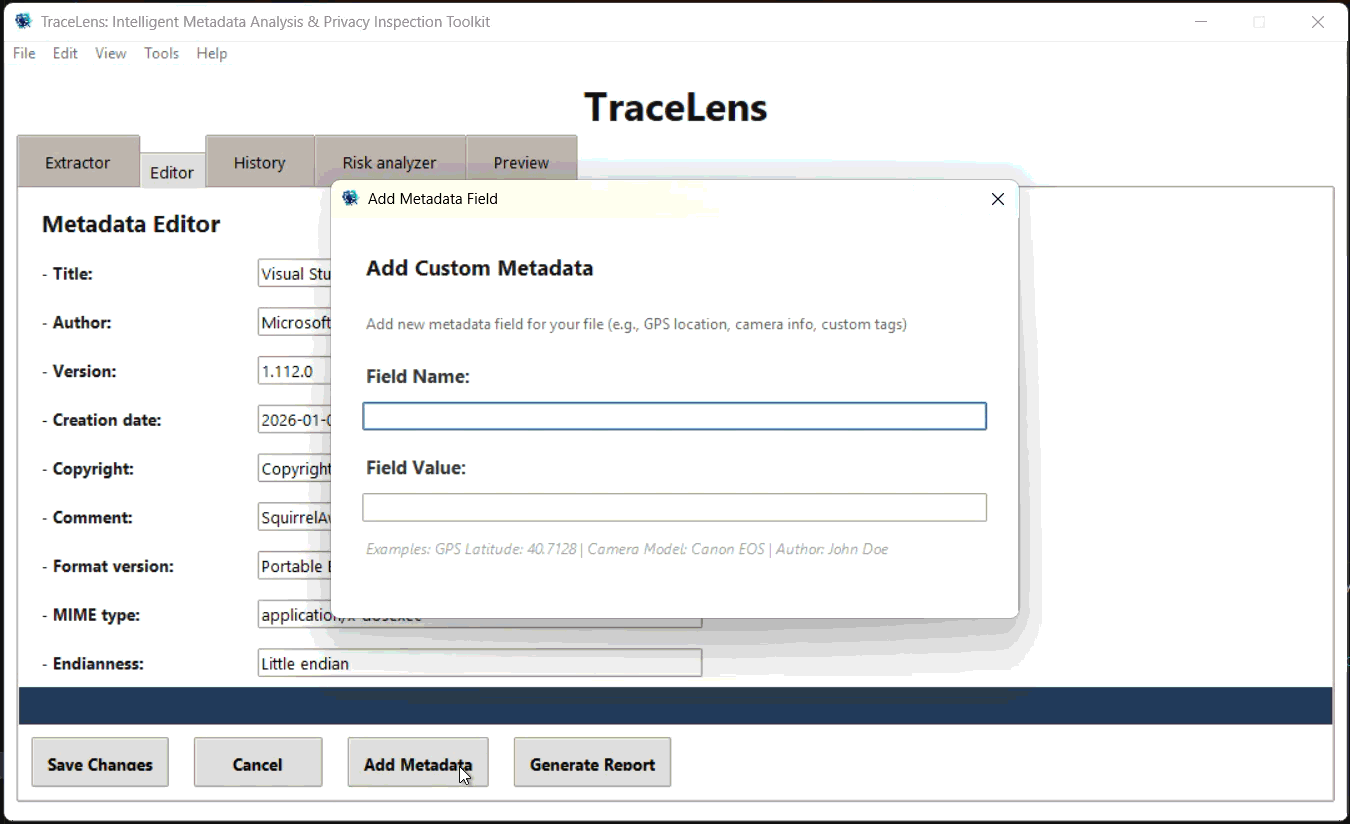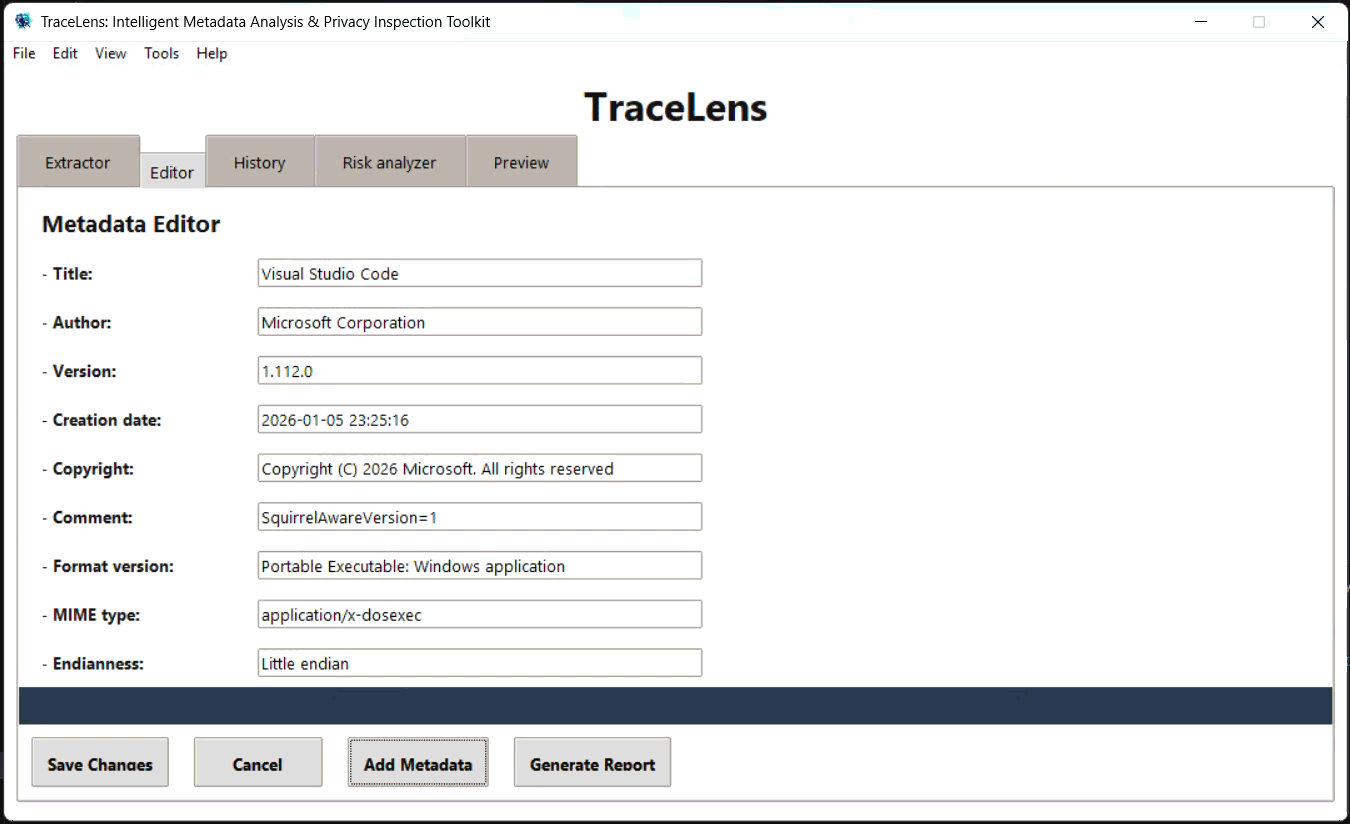
#### 提取器 (Extractor) 选项卡
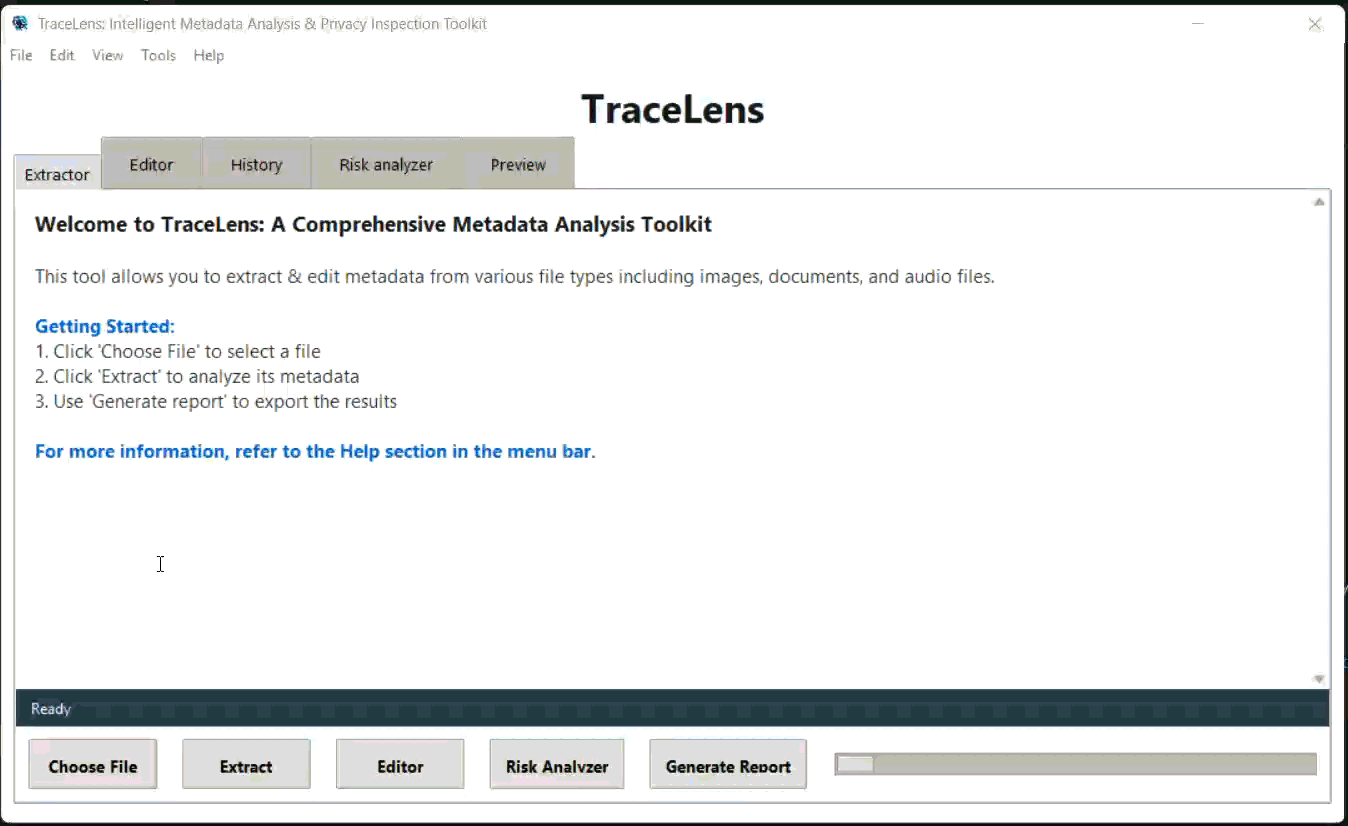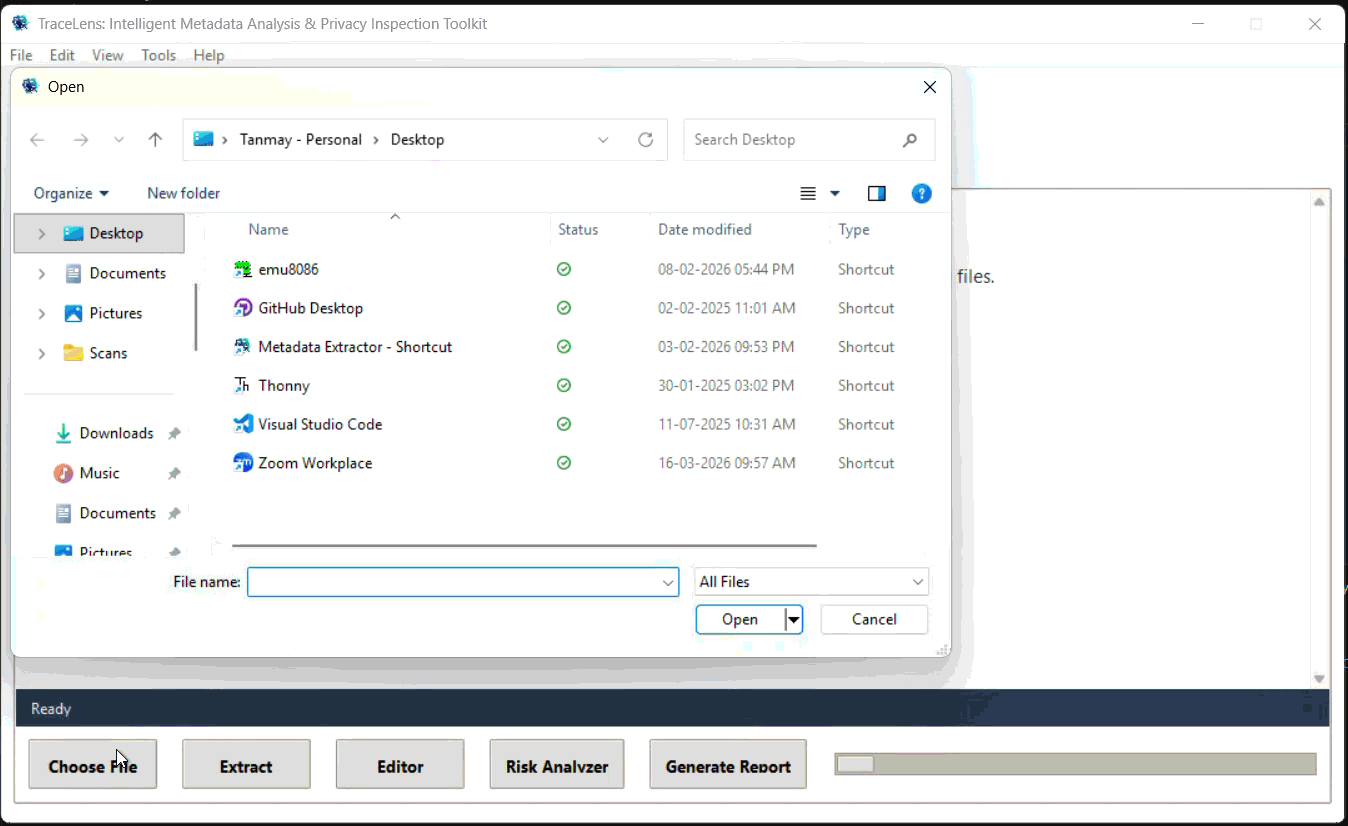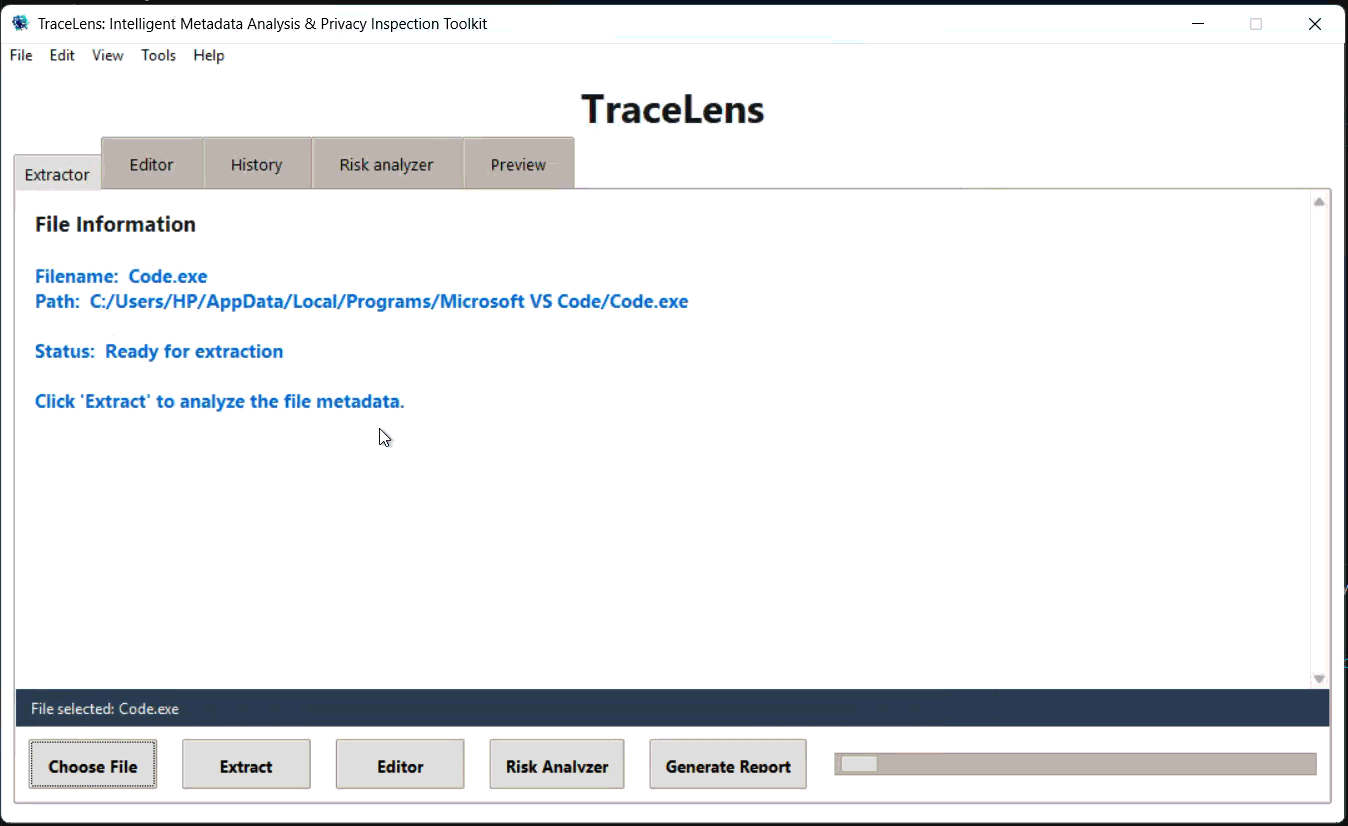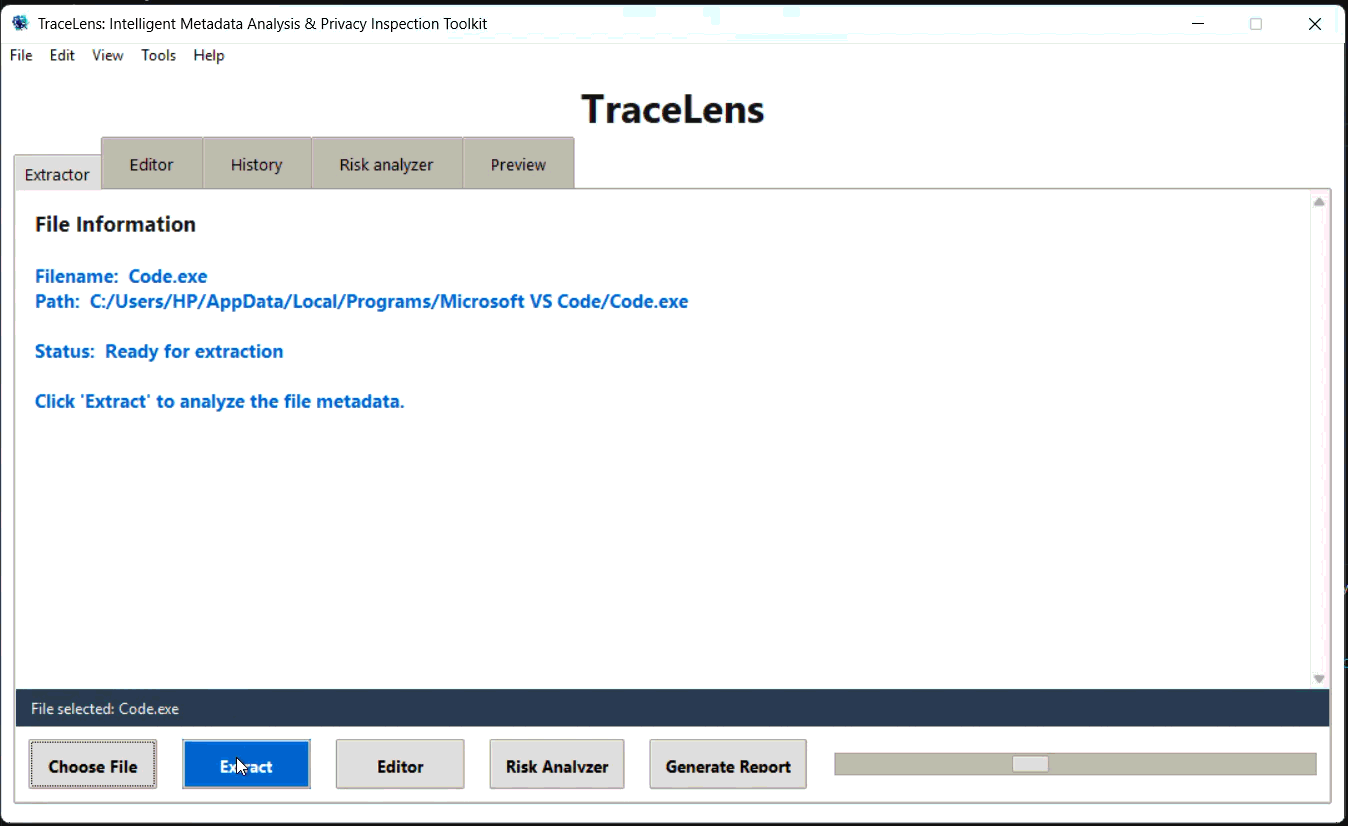
#### 编辑器 (Editor) 选项卡
#### 风险分析器 (Risk Analyzer) 选项卡
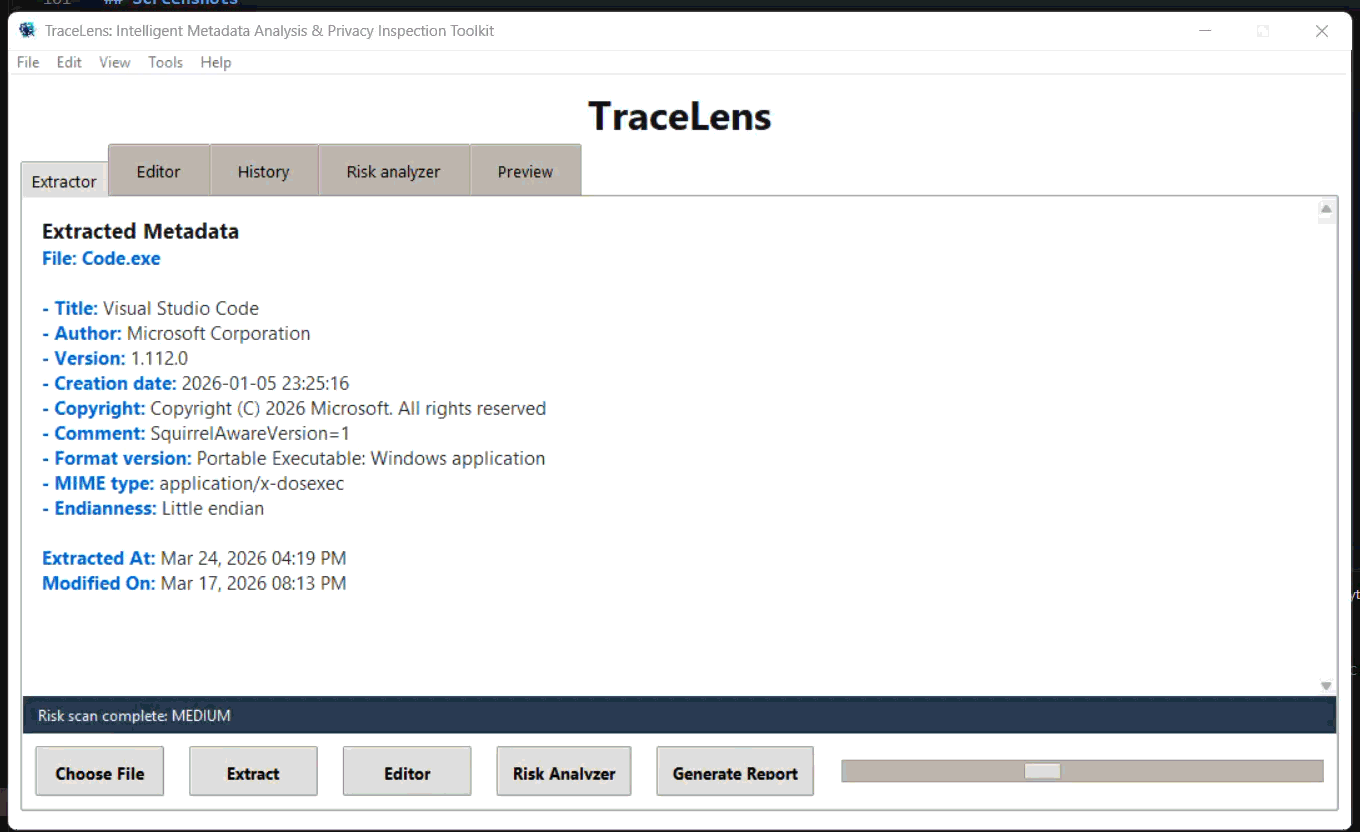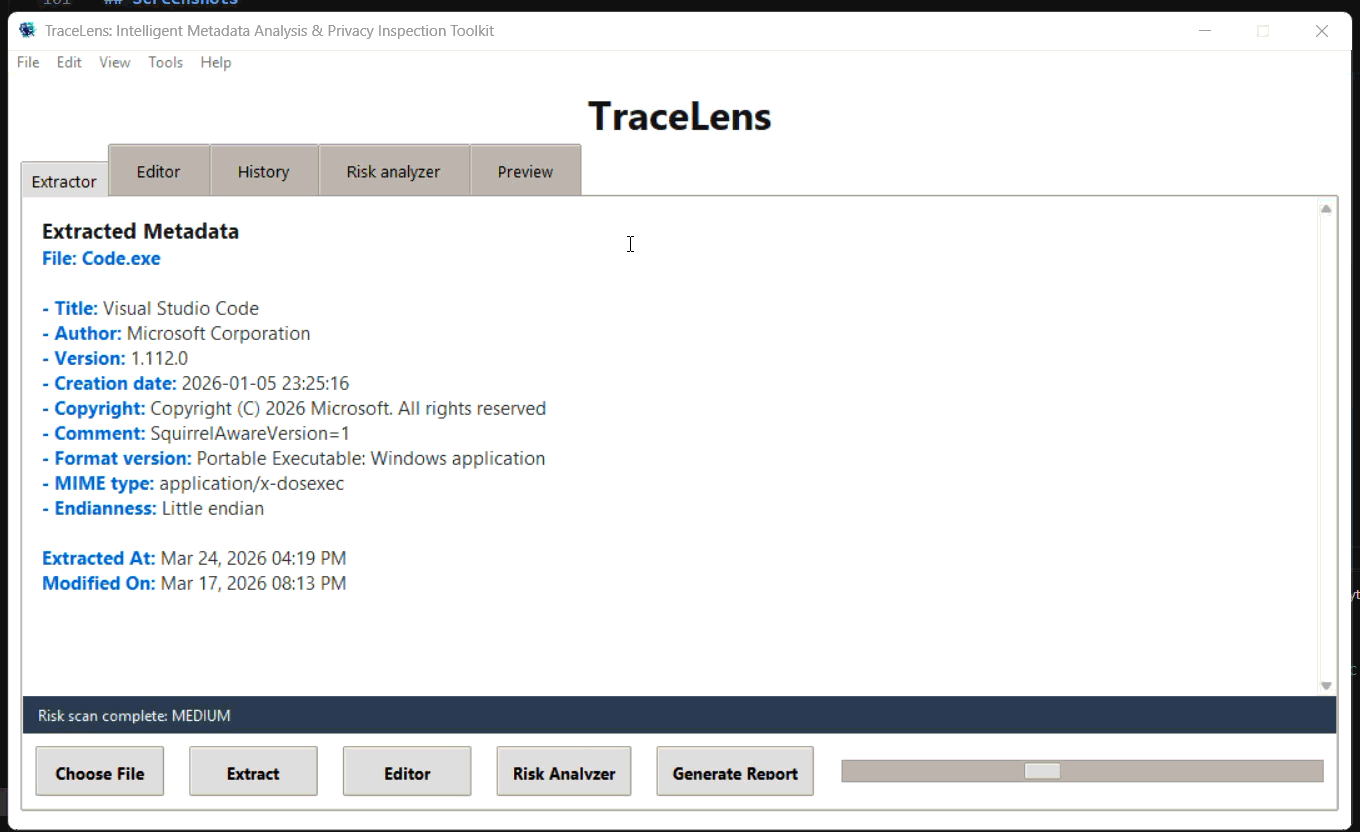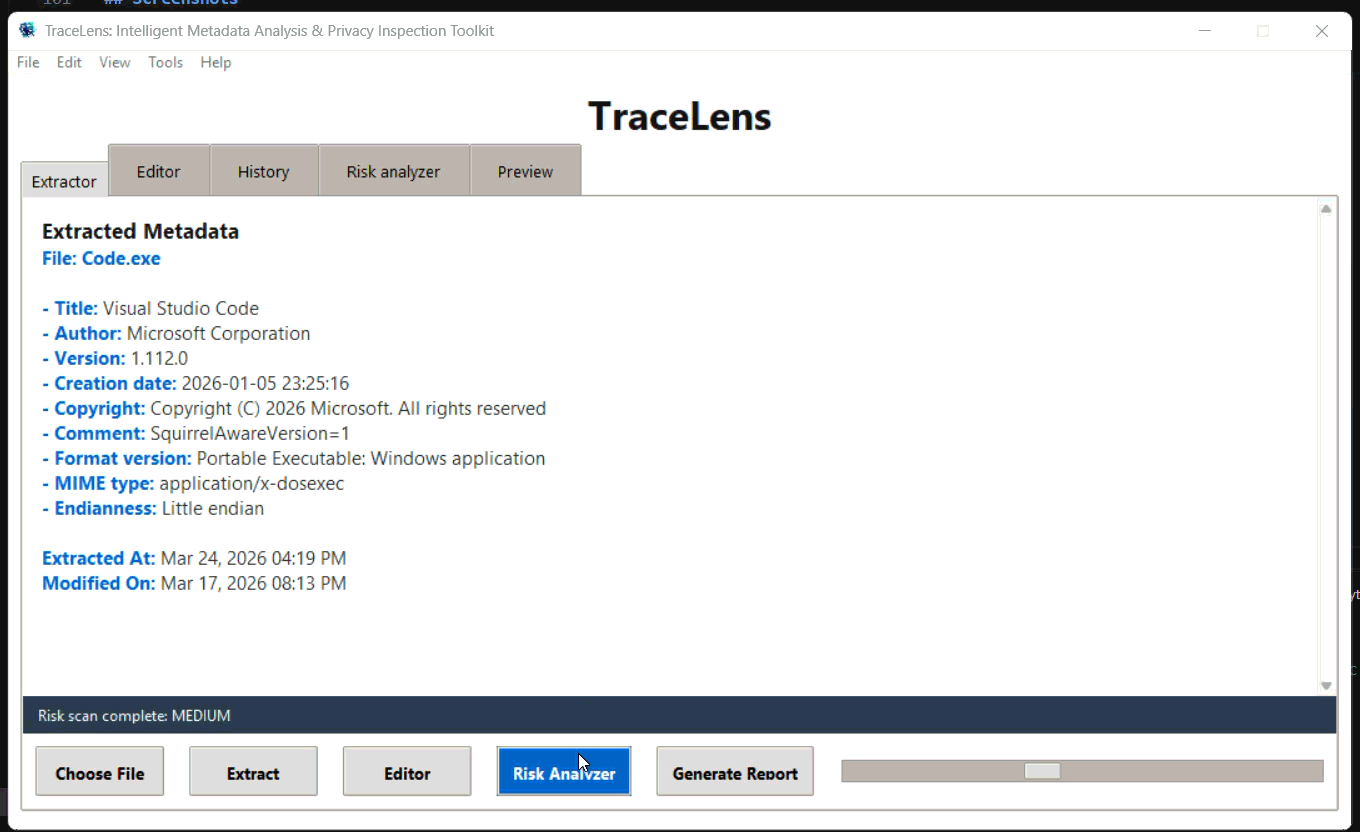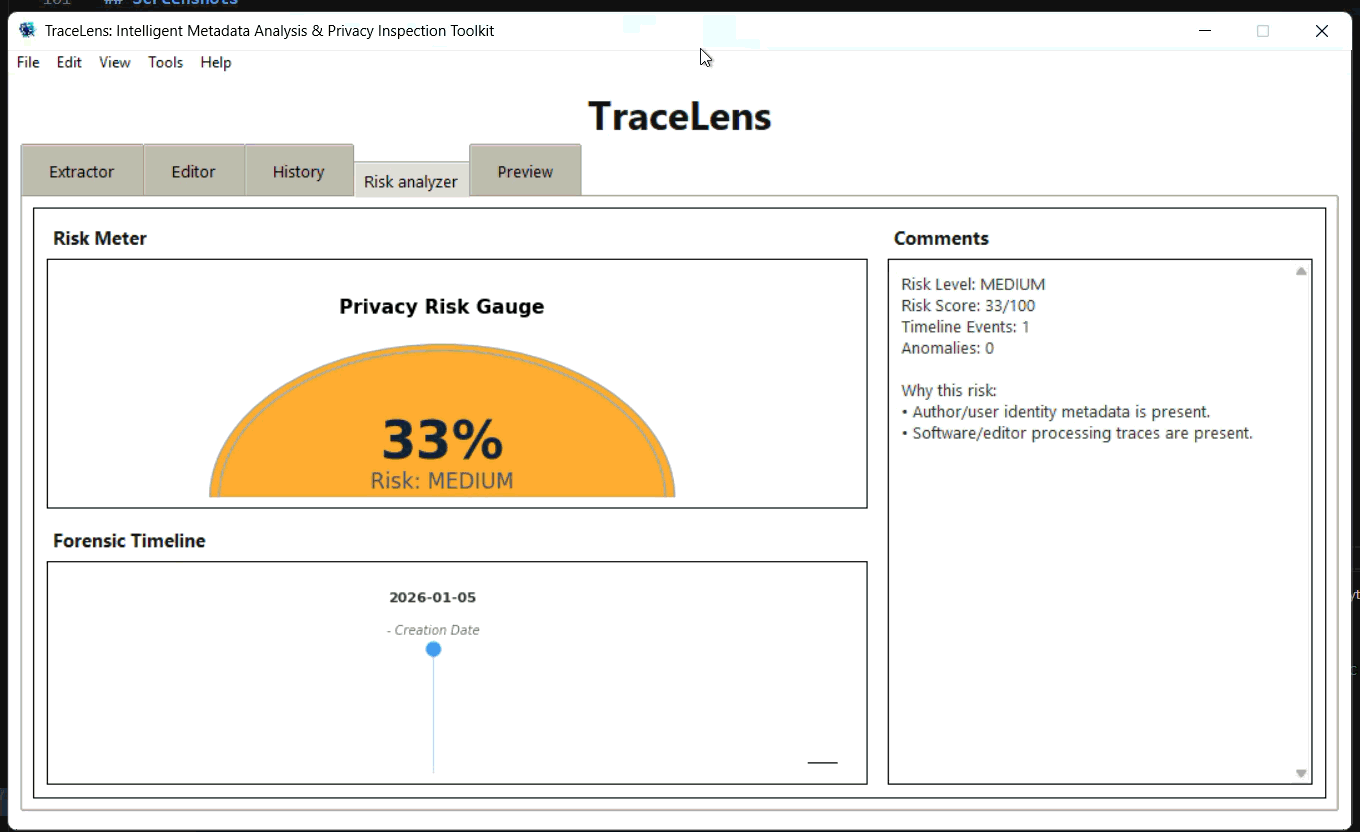
注意:*如果文件未被修改,时间线中只显示创建日期。*
#### 预览/报告 选项卡
注意:*需要在 Windows 上安装 Poppler 才能查看预览。*
#### 历史记录 (History) 选项卡
注意:*以前文件的元数据也可以使用历史记录选项卡直接从数据库中获取。*
#### 仪表板
### CLI 界面
## 功能分解
### 1) 元数据提取
从多种文件类型中提取综合元数据:
- 从 Extractor 选项卡中选择一个文件,然后点击 "Extract Metadata"
- 格式感知提取策略:
- **PDF 文件**:标题、作者、主题、创建者、关键词、页数、创建日期、修改日期
- **文本文件**:文件大小、行数、编码、字符数
- **图像文件**:EXIF 数据(相机型号、GPS、拍摄日期、尺寸)
- **音频文件**:标题、艺术家、专辑、时长、比特率、编解码器
- **文档文件**:作者、主题、标题、修订次数、最后修改者
- **其他格式**:Hachoir 解析器提取可用的元数据块
- 结果以有组织的表格格式显示
- 带有时间戳的自动数据库持久化
- 导出元数据以供外部处理
### 2) 元数据编辑与写回
通过精细控制修改提取的元数据:
- 在 Editor 选项卡中显示可编辑的元数据字段
- 保留不可编辑的核心字段:`File Name`、`File Size`、`File Type`、`Extracted At`、`Modified On`
- 多种格式的写回支持:
- **PDF**:通过 PyPDF2 处理文档属性
- **图像**:通过 piexif 处理 EXIF/IPTC(JPEG、TIFF),PNG 文本块
- **音频**:通过 mutagen 处理 ID3 标签(MP3、FLAC、M4A、OGG、WAV)
- **Office**:通过 python-docx (.docx) 和 openpyxl (.xlsx) 处理核心属性
- **文本**:元数据头部注入(JSON、YAML、注释)
- **后备方案**:为不支持的格式生成配套的 `.meta.json` 文件
- 多文件批量编辑
- 带有更改跟踪的撤销/重做功能
- 写入操作前的验证
### 3) 历史记录管理与数据库
具有强大搜索和过滤功能的全面提取历史记录:
- 每次提取都会保存到 SQLite 数据库(`file_metadata.db`)中
- **搜索和过滤功能**:
- 跨元数据字段的全文搜索
- 文件类型过滤(PDF、图像、音频、文档等)
- 日期范围过滤(过去 24 小时、7 天、30 天、自定义)
- 按任意列排序(文件名、大小、提取日期、风险等级)
- 具有 AND/OR 逻辑的多字段搜索
- **数据管理**:
- 在应用程序中查看任何历史记录
- 确认后删除单个记录
- 带安全确认的批量删除
- 清除整个历史记录(提供备份机会)
- 自动时间戳跟踪
- **导出选项**:
- CSV,用于电子表格分析
- Excel,用于高级数据操作
- JSON,用于 API 集成
- XML,用于数据交换
- PDF,用于正式报告
- 跨应用程序会话保留历史记录
- 自动清理策略(可选归档)
### 4) 隐私与取证风险分析
具有可操作见解的智能风险评分:
- **风险评分引擎**:
- 0-100 分制:LOW (0-29)、MEDIUM (30-64)、HIGH (65-100)
- 基于规则的检测系统(可扩展)
- 按风险类别进行加权评分
- **检测规则**:
- **GPS/位置数据**:EXIF 或元数据中的精确地理坐标(30 分)
- **作者身份**:作者、创建者、所有者、用户信息(18 分)
- **设备信息**:相机型号、序列号、设备标识符(18 分)
- **编辑痕迹**:软件、应用程序、编辑器、版本历史(15 分)
- **隐藏元数据**:XMP、IPTC、EXIF、MakerNote 块、缩略图(20 分)
- **风险输出**:
- 带有原因的数字风险评分
- 颜色编码的严重性指示器
- 触发规则的特定元数据字段
- 显示日期和位置的时间线提取
- 异常检测(意外的元数据存在)
- **批量分析**:
- 同时分析多个文件
- 按级别汇总风险摘要
- 文件夹级别的分组和统计
- 比较风险分析
- 跨文件的时间线整合
- **用例**:
- 文档共享前的隐私审计
- 取证时间线重建
- 数据清理验证
- 合规性检查
### 5) 报告与导出功能
以多种格式生成综合报告:
- **报告类型**:
- **PDF 报告**:带有页眉/页脚、表格、分页的专业格式化文档
- **文本报告**:带有章节和元数据表格的纯文本格式
- **数据导出**:标准格式的结构化数据
- **导出格式**:
- **JSON**:具有嵌套结构和数组的完整元数据
- **XML**:具有适当编码的分层元数据
- **CSV**:为电子表格优化的表格格式
- **Excel**:带有格式的多工作表工作簿
- **PDF**:带有样式的专业视觉报告
- **报告内容**:
- 文件信息(名称、路径、大小、类型)
- 完整的元数据提取
- 风险分析摘要(如果可用)
- 批量处理摘要
- 提取时间戳和元数据完整性
- **高级功能**:
- 多种报告布局和模板
- 文件夹的批量报告生成
- 批量模式下的风险摘要聚合
- 带预览的打印支持
- 电子邮件导出功能
- 自定义页眉/页脚选项
### 6) 交互式仪表板与分析
全面的统计信息和见解:
- **仪表板组件**:
- 摘要卡片(总文件数、平均元数据字段数、提取成功率)
- 风险分布饼图
- 文件类型细分条形图
- 大小分布直方图
- 提取时间线(随时间变化的文件数)
- 元数据完整性热力图
- **过滤选项**:
- 日期范围选择
- 文件类型过滤
- 跨结果的文本搜索
- 风险等级过滤
- 源文件夹过滤
- **分析功能**:
- 元数据趋势和模式
- 前 10 个最常见的元数据字段
- 分析过的最大文件
- 最近的提取
- 成功/失败率统计
- 按文件类型划分的风险分布
- **导出分析**:
- 保存仪表板快照
- 将统计信息导出为 CSV/Excel
- 生成分析报告
- 与利益相关者分享见解
## 支持的文件类型
### 提取支持
**文档格式**:
- PDF (`.pdf`) - 完整的元数据支持
- Microsoft Office (`.docx`, `.xlsx`, `.pptx`) - 核心属性 + 自定义属性
- OpenDocument (`.odt`, `.ods`, `.odp`) - 通过 Hachoir
- Pages, Numbers, Keynote (macOS) - 通过achoir
**图像格式**:
- JPEG (`.jpg`, `.jpeg`) - 完整的 EXIF、IPTC、Makernote
- PNG (`.png`) - EXIF、颜色配置文件、ICC
- TIFF (`.tiff`, `.tif`) - GeoTIFF、EXIF、压缩信息
- GIF (`.gif`) - 动画帧、元数据块
- BMP (`.bmp`) - 颜色深度、分辨率
- WebP (`.webp`) - EXIF、XMP
- SVG (`.svg`) - 文档属性、图层
- PSD (`.psd`) - Photoshop 图层、颜色信息
- ICO (`.ico`) - 图标属性
**音频格式**:
- MP3 (`.mp3`) - ID3 标签 (v1, v2.3, v2.4)
- FLAC (`.flac`) - Vorbis 注释
- M4A/AAC (`.m4a`, `.aac`) - iTunes 属性、atom 元数据
- OGG Vorbis (`.ogg`, `.ogv`) - Vorbis 注释
- WAV (`.wav`) - INFO 标签、ID3
- WMA (`.wma`) - ASF 元数据
- OPUS (`.opus`) - Opus 注释
**视频格式**:
- MP4/MOV (`.mp4`, `.mov`) - Atom 元数据、时长、编解码器
- AVI (`.avi`) - RIFF 属性、帧率
- MKV (`.mkv`) - Matroska 标签、章节
- FLV (`.flv`) - OnMetaData 标签
- WebM (`.webm`) - 时长、编解码器信息
- MTS/M2TS (`.mts`, `.m2ts`) - 视频属性
**归档格式**:
- ZIP (`.zip`) - 文件列表、压缩方法
- RAR (`.rar`) - 归档元数据
- 7z (`.7z`) - 归档属性
- TAR (`.tar`) - 归档成员
- GZIP (`.gz`, `.gzip`) - 压缩元数据
**文本与代码**:
- UTF-8 文本 (`.txt`) - 大小、行数、编码
- Python (`.py`) - Docstrings、模块元数据
- JavaScript (`.js`) - 注释、结构
- Java (`.java`) - 类信息
- C/C++ (`.c`, `.cpp`, `.h`) - 头部信息
- JSON (`.json`) - 结构、schema 信息
- XML (`.xml`) - 命名空间、编码、schema
- YAML (`.yml`, `.yaml`) - 配置结构
- CSV (`.csv`) - 列数、编码
- Markdown (`.md`) - 标题、链接、结构
- HTML/CSS (`.html`, `.css`) - Meta 标签、样式表
- LaTeX (`.tex`) - 文档类、包
**50 多种其他格式**:
- Hachoir 解析器自动检测并分析 50 多种其他格式
- 包括 MIDI、EXE、DLL、ELF、ISO、FLAC、DV、WMV 等
### 写回支持
**主要支持**:
- PDF 文件(文档属性)
- JPEG 图像(通过 piexif 处理 EXIF)
- PNG 图像(文本块)
- TIFF 图像(通过 piexif 处理 EXIF)
- MP3 音频(通过 mutagen 处理 ID3 标签)
- FLAC 音频(Vorbis 注释)
- M4A/AAC 音频(iTunes 属性)
- OGG 音频(Vorbis 注释)
- DOCX 文件(核心属性)
- XLSX 文件(工作簿属性)
**基于文本的写回**:
- 向文本文件注入元数据头部
- JSON 伴随文件(`.metadata.json`)
- YAML front matter 支持
- CSV 元数据字段
**后备机制**:
- 不支持的格式 → 伴随的 `.meta.json` 文件
- 保持原始文件完整性
- 外部元数据管理
## 技术栈
**核心框架**:
- Python 3.10+(类型提示:`dict[str, Any]`、`X | None`)
- Tkinter - Python 附带的跨平台 GUI 框架
**元数据提取**:
- PyPDF2 (3.0+) - PDF 解析和元数据提取
- Hachoir (3.2+) - 支持 50 多种格式的通用元数据解析器
- piexif (1.1.3+) - 图像 EXIF 元数据处理
- mutagen (1.47+) - 音频元数据(ID3、Vorbis、MP4)
- python-docx (1.1+) - Microsoft Word 文档访问
- openpyxl (3.1+) - Excel 工作簿处理
- pdf2image (1.16+) - PDF 渲染
**数据处理**:
- pandas (2.0+) - 数据分析和统计计算
- Pillow (10.0+) - 图像处理
- matplotlib (3.7+) - 图表和可视化
**报告生成**:
- ReportLab (4.0+) - PDF 创建和操作
**开发与测试**:
- pytest (8.3+) - 测试框架
- 类型提示和数据类,用于强类型化
- 用于隔离单元测试的 Mock 对象
## 项目结构
```
TraceLens/
├── src/ # Source code directory
│ ├── main.py # Application entry point
│ ├── cli.py # Command-line interface
│ ├── gui.py # Tkinter GUI implementation
│ ├── extractor.py # Metadata extraction engine
│ ├── editor.py # Metadata editing
│ ├── db.py # SQLite database wrapper
│ ├── report.py # Report generation
│ └── risk_analyzer.py # Risk scoring engine
├── tests/ # Test suite
│ ├── test_main.py # Main module tests
│ ├── test_gui.py # GUI tests
│ ├── test_extractor.py # Extractor tests
│ ├── test_editor.py # Editor tests
│ ├── test_db.py # Database tests
│ ├── test_report.py # Report tests
│ └── test_risk_analyzer.py # Risk analysis tests
├── requirements.txt # Python dependencies
├── LICENSE # MIT license
└── README.md # This file
```
## 系统架构
### 系统设计
应用程序遵循**分层架构**,具有清晰的关注点分离:
```
┌─────────────────────────────────────────────────────────────┐
│ USER INTERFACE LAYER │
│ ┌───────────┐ ┌────────────┐ ┌────────────┐ ┌─────────┐ │
│ │ Extractor │ │ Editor │ │ History │ │Analytics│ │
│ │ Tab │ │ Tab │ │ Tab │ │Dashboard│ │
│ └─────┬─────┘ └─────┬──────┘ └─────┬──────┘ └────┬────┘ │
│ │ │ │ │ │
└────────┼──────────────┼───────────────┼──────────────┼──────┘
│ │ │ │
▼ ▼ ▼ ▼
┌─────────────────────────────────────────────────────────────┐
│ CORE BUSINESS LOGIC LAYER │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ Extractor │ │ Editor │ │ Risk Analyzer │ │
│ │ - Validate │ │ - Parse │ │ - Score rules │ │
│ │ - Extract │ │ - Validate │ │ - Timeline gen │ │
│ │ - Format │ │ - Write-back │ │ - Anomaly detect │ │
│ └──────┬───────┘ └──────┬───────┘ └────────┬─────────┘ │
│ │ │ │ │
└─────────┼─────────────────┼───────────────────┼─────────────┘
│ │ │
▼ ▼ ▼
┌─────────────────────────────────────────────────────────────┐
│ DATA PERSISTENCE LAYER │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ SQLite DB │ │ Reporter │ │ File System │ │
│ │ - Metadata │ │ - PDF Gen │ │ - .meta.json │ │
│ │ - History │ │ - Export │ │ - Modified files │ │
│ │ - Timestamps │ │ - Formatting │ │ - Backups │ │
│ └──────────────┘ └──────────────┘ └──────────────────┘ │
└─────────────────────────────────────────────────────────────┘
```
### 模块职责
#### **main.py** - 应用程序入口点
- 初始化应用程序
- 启动 GUI
- 处理启动错误和日志记录
#### **cli.py** - 命令行界面层
- 提供交互式、菜单驱动的终端工作流
- 无需 GUI 即可公开提取、历史记录、报告和风险分析操作
- 处理 CLI 输入验证和用户提示
- 与核心模块(`extractor.py`、`db.py`、`report.py`、`risk_analyzer.py`)集成
- 支持在无头环境中进行自动化友好的使用
#### **gui.py** - 表示层
- Tkinter GUI 实现
- 基于选项卡的界面管理
- 用户输入处理
- 结果可视化
- 设置和首选项
#### **extractor.py** - 数据获取层
- 文件验证
- 格式检测
- 元数据提取算法
- 数据库持久化
- 可选的备份创建
#### **editor.py** - 数据修改层
- 元数据解析和验证
- 字段级编辑
- 写回逻辑
- 回滚/备份管理
- 特定格式的序列化
#### **db.py** - 数据访问层
- SQLite 连接管理
- CRUD 操作
- 查询构建
- 导出适配器
- 数据聚合
#### **report.py** - 报告层
- 报告生成
- 通过 ReportLab 创建 PDF
- 多种导出格式
- 打印管理
- 模板渲染
#### **risk_analyzer.py** - 分析引擎
- 基于规则的风险评分
- 隐私/取证规则定义
- 时间线提取
- 异常检测
- 批量分析支持
### 数据流
```
User Action → GUI Event → Core Logic → Data Store → Report → User
▲ │ Output
│ │
└────────── Feedback Display ◄───────────┘
```
### 使用的设计模式
- **MVC 模式**:分离模型(数据)、视图(GUI)、控制器(业务逻辑)
- **工厂模式**:文件类型检测和处理程序选择
- **策略模式**:每种格式采用不同的提取/写入策略
- **观察者模式**:响应数据变化的 GUI 状态更新
- **单例模式**:数据库和分析器实例
- **类型提示**:完整的 Python 3.10+ 类型注释覆盖
## 安装说明
### 前置条件
- **Python 3.10 或更高版本**(现代类型语法所需)
- 检查您的版本:`python --version`
- 诸如 `dict[str, Any]` 和 `X | None` 之类的现代类型提示需要 Python 3.10+
- **Tkinter**(通常随 Python 附带)
- Windows:默认包含
- macOS:`brew install python-tk@3.x`
- Linux:`sudo apt-get install python3-tk`
- **虚拟环境**(推荐)
### 分步设置
#### 1. 克隆仓库
```
git clone https://github.com/Tanmay-Bhatnagar22/TraceLens.git
cd TraceLens
```
#### 2. 创建虚拟环境
```
# Windows
python -m venv .venv
# macOS/Linux
python3 -m venv .venv
```
#### 3. 激活虚拟环境
Windows (PowerShell):
```
.venv\Scripts\Activate.ps1
```
Windows (命令提示符):
```
.venv\Scripts\activate.bat
```
macOS/Linux:
```
source .venv/bin/activate
```
#### 4. 安装核心依赖
```
# 安装核心依赖
pip install -r requirements.txt
# 或单独安装
pip install PyPDF2>=3.0.0 Pillow>=10.0.0 pandas>=2.0.0 \
reportlab>=4.0.0 hachoir>=3.2.0 pdf2image>=1.16.0 \
pytest>=8.3.0 matplotlib>=3.7.0
```
#### 5. 安装可选依赖(推荐)
用于扩展的元数据支持:
```
# Image EXIF metadata (JPEG, TIFF)
pip install piexif>=1.1.3
# Audio metadata (MP3, FLAC, M4A, 等)
pip install mutagen>=1.47.0
# Microsoft Office files (.docx, .xlsx, .pptx)
pip install python-docx>=1.1.0 openpyxl>=3.1.0
# 或一次性全部安装
pip install piexif mutagen python-docx openpyxl
```
#### 6. 验证安装
```
# 检查导入
python -c "import PyPDF2; import tkinter; print('Setup successful!')"
```
## 使用方法
### 运行应用程序
#### GUI 模式(推荐)
```
# 从 repository 根目录
python src/main.py
```
Tkinter 界面将启动并包含以下选项卡:
- **Extractor**:选择并分析文件
- **Editor**:修改元数据
- **History**:搜索和管理提取记录
- **Risk Analyzer**:隐私分析
- **Preview**:生成并查看报告
- **Dashboard**:查看统计信息(通过工具菜单)
#### CLI 模式
```
# 从 src 目录
python cli.py
```
在菜单驱动的界面中导航:
```
╔════════════════════════════════════╗
║ TraceLens CLI Menu ║
╠════════════════════════════════════╣
║ 1. Extract Metadata from File ║
║ 2. View History ║
║ 3. Search History ║
║ 4. Generate Report ║
║ 5. Risk Analysis ║
║ 6. Batch Processing ║
║ 0. Exit ║
╚════════════════════════════════════╝
```
### 基本工作流
1. **提取元数据**
- 打开 Extractor 选项卡
- 点击 "Browse" 选择文件
- 点击 "Extract Metadata"
- 在元数据面板中查看结果
2. **编辑元数据**(可选)
- 切换到 Editor 选项卡
- 修改可编辑的字段
- 点击 "Save Changes"
- 选择性地 "Write Back" 到文件
3. **分析风险**
- 切换到 Risk Analyzer 选项卡
- 查看风险评分和原因
- 检查时间线和异常
- 对于批量处理:选择多个文件
4. **生成报告**
- 切换到 Preview 选项卡
- 选择导出格式(PDF、CSV、JSON 等)
- 点击 "Export" 保存文件
- 点击 "Print" 进行即时打印
5. **浏览历史记录**
- 切换到 History 选项卡
- 按文件名或元数据搜索
- 按日期、文件类型或风险等级过滤
- 删除或导出记录
### 高级用法
#### 批量处理
```
Menu → Batch Process → Select Folder
- Analyze all files in directory
- Generate aggregate report
- Export summary statistics
```
#### 自定义报告
```
Preview Tab → Export Options:
- Select format (PDF/CSV/JSON/XML/Excel)
- Choose specific fields to include
- Apply filters before export
```
#### 数据库管理
```
Tools → Database Operations:
- Backup database
- Export history to file
- Clear history (with confirmation)
- View database statistics
```
### 命令行示例
以编程方式提取元数据:
```
from src.extractor import MetadataExtractor
extractor = MetadataExtractor()
metadata = extractor.extract_pdf_metadata("document.pdf")
print(metadata)
```
执行风险分析:
```
from src.risk_analyzer import PrivacyForensicAnalyzer
analyzer = PrivacyForensicAnalyzer()
metadata = {"author": "John Doe", "gps": "37.7749° N, 122.4194° W"}
result = analyzer.analyze(metadata)
print(f"Risk Score: {result['score']}")
print(f"Risk Level: {result['level']}")
```
## 配置
### 设置文件
设置存储在应用程序首选项中:
```
Edit → Preferences → General
- Default export format
- Database location
- Batch processing options
- Display preferences
```
### 数据库位置
默认:`file_metadata.db`(在应用程序目录中)
要使用自定义位置:
```
from src.db import MetadataDatabase
db = MetadataDatabase(db_path="/custom/path/metadata.db")
```
### 日志
启用调试日志记录:
```
Edit → Preferences → Debug → Enable Logging
```
日志存储在:`./logs/traceLens.log`
## API 参考
### MetadataExtractor 类
```
from src.extractor import MetadataExtractor
from src import db
extractor = MetadataExtractor(db_client=db.db_manager)
# 提取 PDF metadata
metadata = extractor.extract_pdf_metadata("file.pdf")
# 提取 text metadata
metadata = extractor.extract_text_metadata("file.txt")
# 带格式检测的通用提取
metadata = extractor.extract_metadata("file.ext")
# 检查文件是否有效
is_valid, error_msg = extractor._validate_file_path("file.path")
```
### MetadataEditor 类
```
from src.editor import MetadataEditor
editor = MetadataEditor()
# 解析 metadata
parsed = editor.parse_metadata({"Author": "John", "Title": "Doc"})
# 验证 fields
is_valid, errors = editor.validate_metadata(parsed)
# 写回文件
success = editor.write_metadata_to_file("file.pdf", modified_metadata)
```
### MetadataDatabase 类
```
from src.db import MetadataDatabase
db = MetadataDatabase(db_path="file_metadata.db")
# 插入 metadata
db.insert_metadata({
"file_path": "/path/to/file",
"file_name": "document.pdf",
"file_type": "pdf",
"full_metadata": json.dumps(metadata)
})
# 查询历史
records = db.get_all_metadata()
# 搜索 metadata
results = db.search_metadata(search_term="author", file_type="pdf")
# 导出 data
df = db.get_metadata_as_dataframe()
# 删除记录
db.delete_metadata(record_id)
```
### PrivacyForensicAnalyzer 类
```
from src.risk_analyzer import PrivacyForensicAnalyzer
analyzer = PrivacyForensicAnalyzer()
# 分析单个文件
result = analyzer.analyze(metadata)
# 返回: {
# "score": 65,
# "level": "HIGH",
# "reasons": ["发现 GPS data", "已识别 Author"],
# "timeline": [...],
# "anomalies": [...]
# }
# 批量分析
results = analyzer.analyze_batch(file_list)
# 获取风险级别
level = analyzer.get_risk_level(score) # Returns "LOW", "MEDIUM", or "HIGH"
```
### MetadataReporter 类
```
from src.report import MetadataReporter
reporter = MetadataReporter()
# 生成 text 报告
text = reporter.generate_report_text(metadata, file_path)
# 生成 PDF 报告
pdf_path = reporter.generate_pdf_report(
metadata,
output_path="report.pdf",
include_risk=True,
risk_analysis=result
)
# 导出为 formats
reporter.export_to_json(metadata, "export.json")
reporter.export_to_csv(metadata_list, "export.csv")
reporter.export_to_excel(metadata_list, "export.xlsx")
reporter.export_to_xml(metadata, "export.xml")
```
### GUI 类
```
from src.gui import MetadataAnalyzerApp
app = MetadataAnalyzerApp()
app.run() # Starts the Tkinter main loop
```
reporter.export_to_json(metadata, "export.json")
reporter.export_to_csv(metadata_list, "export.csv")
reporter.export_to_excel(metadata_list, "export.xlsx")
reporter.export_to_xml(metadata, "export.xml")
```
### GUI Class
```python
from src.gui import MetadataAnalyzerApp
app = MetadataAnalyzerApp()
app.run() # Starts the Tkinter main loop
```
## 数据库模式
### 元数据表
```
CREATE TABLE metadata (
id INTEGER PRIMARY KEY AUTOINCREMENT,
file_path TEXT NOT NULL,
file_name TEXT NOT NULL,
file_size_formatted TEXT,
file_type TEXT,
extracted_at TEXT NOT NULL,
modified_on TEXT,
full_metadata TEXT NOT NULL
);
```
### 列规范
| 列 | 类型 | 描述 |
|--------|------|-------------|
| `id` | INTEGER | 自动递增的主键 |
| `file_path` | TEXT | 源文件的完整路径 |
| `file_name` | TEXT | 提取的文件名 |
| `file_size_formatted` | TEXT | 人类可读的文件大小(例如,"1.5 MB") |
| `file_type` | TEXT | 文件扩展名(例如,"pdf"、"jpg") |
| `extracted_at` | TEXT | 提取时的 ISO 8601 时间戳 |
| `modified_on` | TEXT | 源文件的最后修改时间 |
| `full_metadata` | TEXT | 作为 JSON 字符串的完整元数据 |
### JSON 元数据格式
`full_metadata` 列将完整的元数据存储为 JSON:
```
{
"File Name": "document.pdf",
"File Size (bytes)": 1024000,
"File Type": "pdf",
"Extracted At": "2024-03-24T10:30:00",
"Pages": 50,
"Author": "John Doe",
"Title": "Important Report",
"Subject": "Business Analysis",
"Creator": "Microsoft Word",
"Keywords": "report, analysis, 2024",
"Created": "2024-01-15T09:00:00",
"Modified": "2024-03-20T14:30:00"
}
```
### 数据库位置
- **默认**:应用程序根目录中的 `file_metadata.db`
- **自动创建**:首次运行时自动创建数据库
- **备份**:使用 工具 → 数据库操作 → 备份数据库
### 查询示例
```
from src import db
# 获取所有记录
all_records = db.db_manager.get_all_metadata()
# 按 term 搜索
results = db.db_manager.search_metadata(search_term="author")
# 按日期范围过滤
from datetime import datetime, timedelta
recent = db.db_manager.get_metadata_by_date_range(
start_date=datetime.now() - timedelta(days=7),
end_date=datetime.now()
)
# 导出为 DataFrame
df = db.db_manager.get_metadata_as_dataframe()
# 统计记录
count = db.db_manager.count_metadata()
```
## 测试
### 运行测试
运行完整的测试套件:
```
# 所有测试
pytest tests/
# 详细输出
pytest tests/ -v
# 附带 coverage 报告
pytest tests/ --cov=src --cov-report=html
```
### 运行单个测试模块
标签:CSV, Excel, GUI, HTTP工具, JSON, meg, PDF导出, pytest, Python, SQLite, Tkinter, XML, 信息安全, 元数据分析, 元数据编辑, 命令行界面, 域渗透, 操作系统信息识别, 数字取证, 数据分析工具, 数据提取, 文件管理, 无后门, 桌面应用, 电子数据取证, 网络安全, 网络安全审计, 自动化脚本, 逆向工具, 隐私保护, 隐私清理