jundot/omlx
GitHub: jundot/omlx
为 Apple Silicon 优化的本地 LLM 推理服务器,通过连续批处理与分层缓存实现高效、安全的私有模型服务。
Stars: 17946 | Forks: 1529

oMLX
针对 Mac 优化的 LLM 推理
连续批处理与分层 KV 缓存,直接通过菜单栏管理。




junkim.dot@gmail.com · https://omlx.ai/me
安装 ·
快速开始 ·
功能 ·
模型 ·
CLI 配置 ·
基准测试 ·
oMLX.ai
English ·
中文 ·
한국어 ·
日本語
## 安装
### macOS 应用程序
从 [Releases](https://github.com/jundot/omlx/releases) 下载 `.dmg`,拖到应用程序文件夹,完成。应用程序内置应用内自动更新,因此后续升级只需一键。请注意,macOS 应用程序不会安装 `omlx` CLI 命令。如需在终端使用,请通过 Homebrew 或从源码安装。
### Homebrew
```
brew tap jundot/omlx https://github.com/jundot/omlx
brew install omlx
# 升级到最新版本
brew update && brew upgrade omlx
# 作为后台服务运行(崩溃后自动重启)
brew services start omlx
# 可选:MCP(模型上下文协议)支持
/opt/homebrew/opt/omlx/libexec/bin/pip install mcp
```
### 从源码安装
```
git clone https://github.com/jundot/omlx.git
cd omlx
pip install -e . # Core only
pip install -e ".[mcp]" # With MCP (Model Context Protocol) support
```
需要 macOS 15.0+(Sequoia)、Python 3.10+ 和 Apple Silicon(M1/M2/M3/M4)。
## 快速入门
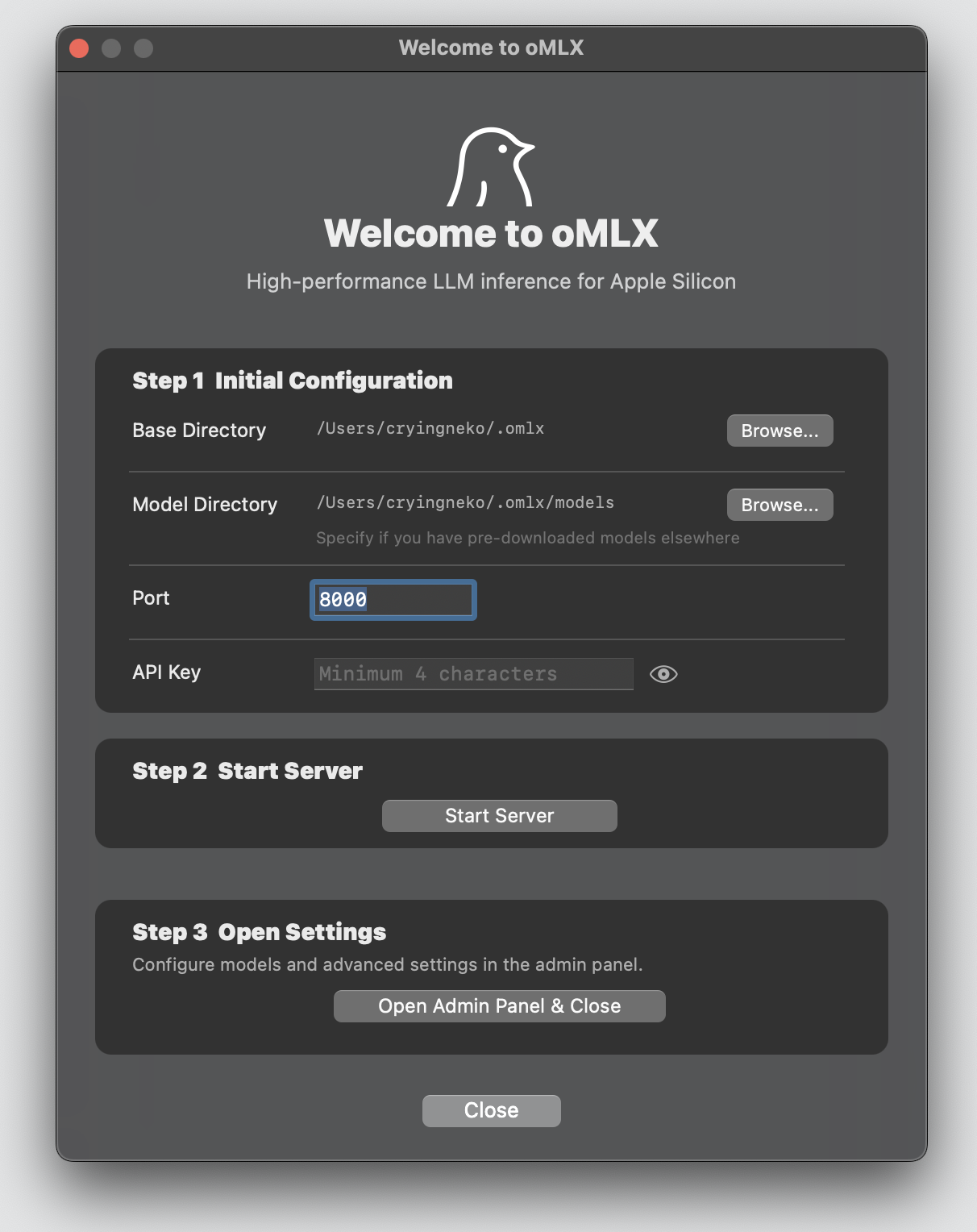
### macOS 应用程序
从应用程序文件夹启动 oMLX。欢迎界面会引导你完成三个步骤——模型目录、启动服务器和下载首个模型。仅此而已。如需连接 OpenClaw、OpenCode 或 Codex,请参见[集成](#integrations)。
### CLI
```
omlx serve --model-dir ~/models
```
服务器会自动从子目录中发现 LLM、VLM、嵌入模型和重排序器。任何 OpenAI 兼容客户端均可连接到 `http://localhost:8000/v1`。内置聊天界面也提供在 `http://localhost:8000/admin/chat`。
### Homebrew 服务
如果通过 Homebrew 安装,可以将 oMLX 作为托管的后台服务运行:
```
brew services start omlx # Start (auto-restarts on crash)
brew services stop omlx # Stop
brew services restart omlx # Restart
brew services info omlx # Check status
```
服务会以零配置默认设置运行(`~/.omlx/models`,端口 8000)。如需自定义,可以设置环境变量(`OMLX_MODEL_DIR`、`OMLX_PORT` 等)或运行一次 `omlx serve --model-dir /your/path` 以将设置持久化到 `~/.omlx/settings.json`。
日志记录在两个位置:
- **服务日志**:`$(brew --prefix)/var/log/omlx.log`(标准输出/标准错误)
- **服务器日志**:`~/.omlx/logs/server.log`(结构化应用日志)
## 功能
支持在 Apple Silicon 上运行的文本 LLM、视觉语言模型(VLM)、OCR 模型、嵌入和重排序器。
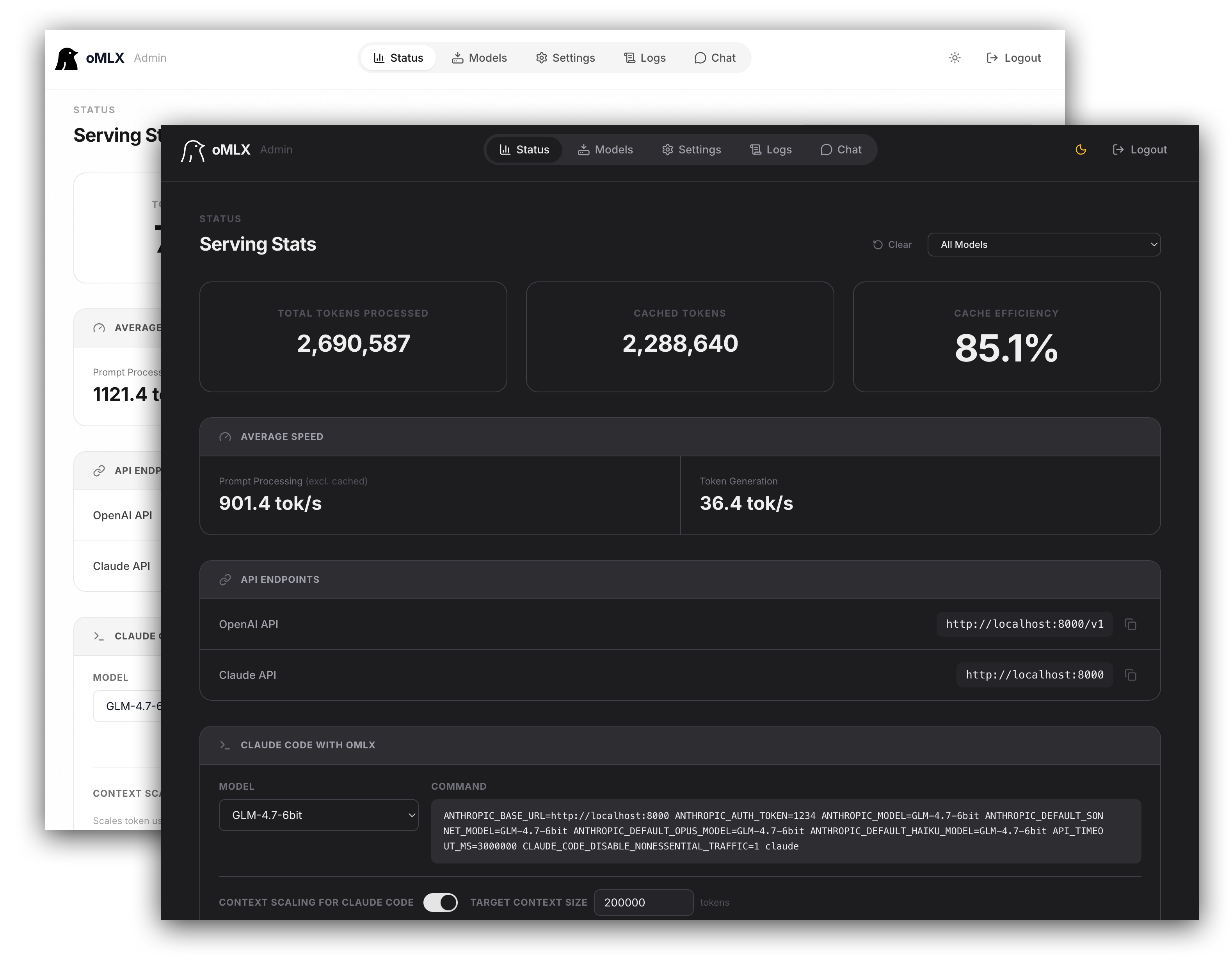
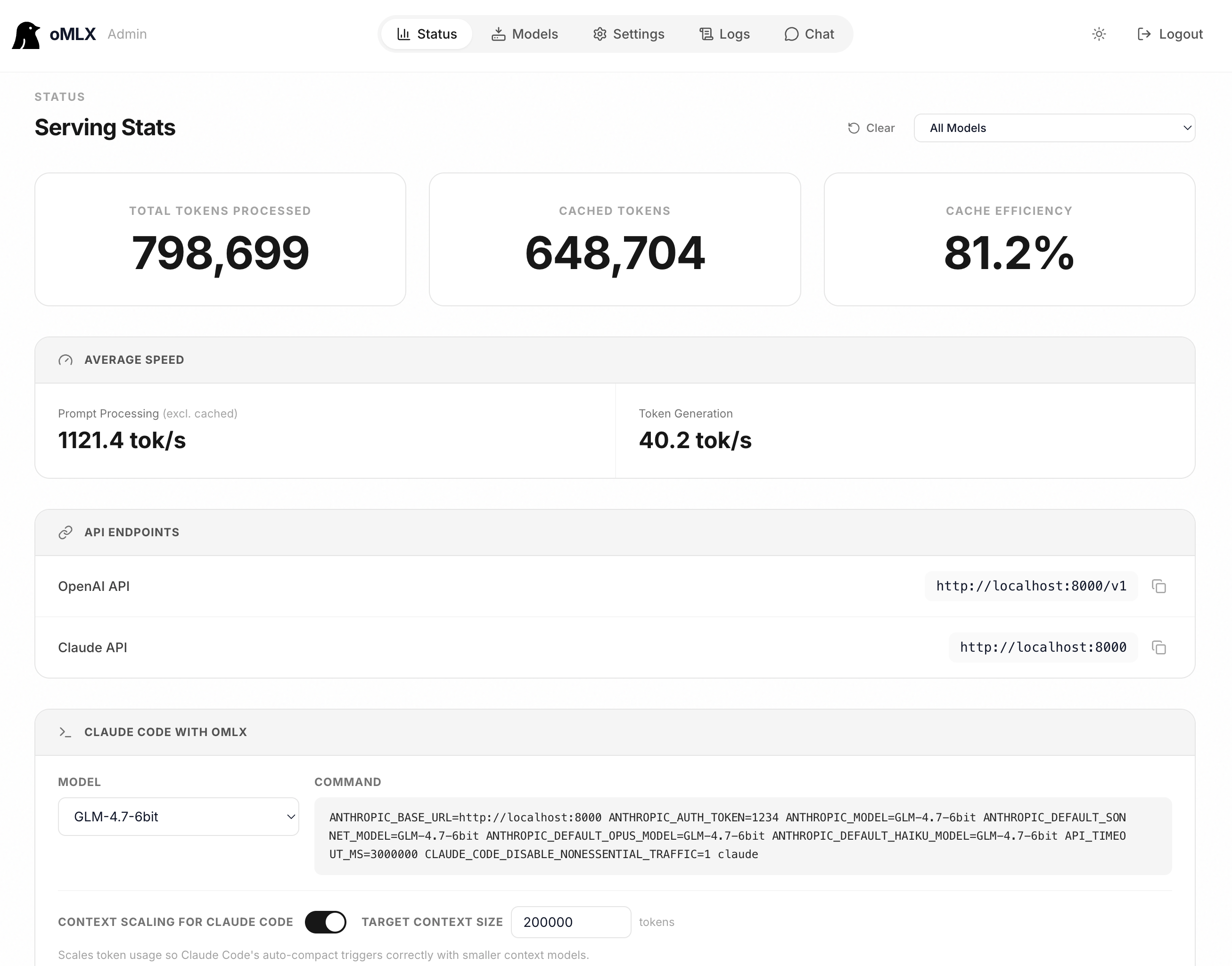
### 管理面板
提供位于 `/admin` 的 Web UI,用于实时监控、模型管理、聊天、基准测试以及每个模型的设置。支持英文、韩文、日文和中文。所有 CDN 依赖均已打包,确保完全离线可用。
### 视觉语言模型
使用与文本 LLM 相同的连续批处理和分层 KV 缓存栈运行 VLM。支持多图像聊天、base64/URL/文件图像输入,以及带有视觉上下文的功能调用。OCR 模型(DeepSeek-OCR、DOTS-OCR、GLM-OCR)会自动检测并使用优化后的提示词。
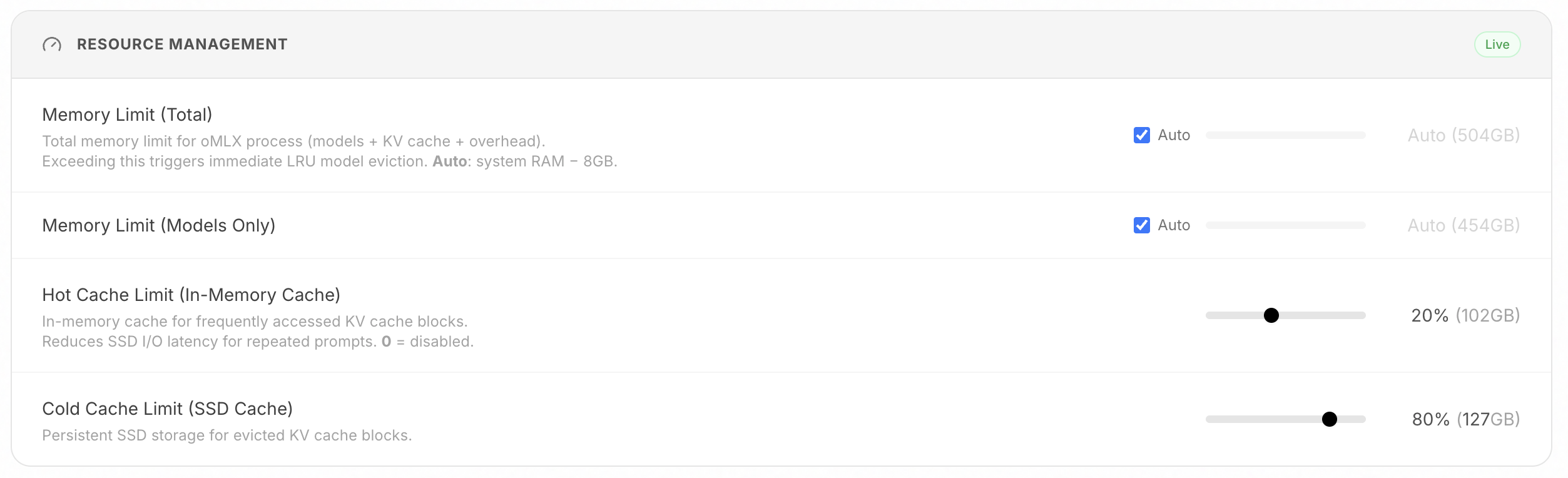
### 分层 KV 缓存(热 + 冷)
受 vLLM 启发,基于块的管理 KV 缓存,支持前缀共享和写时复制。缓存操作分为两个层级:
- **热层(RAM)**:频繁访问的块保持在内存中,实现快速访问。
- **冷层(SSD)**:当热缓存填满时,块会以 safetensors 格式卸载到 SSD。下次请求匹配前缀时,直接从磁盘恢复而非重新计算——即使服务器重启后也是如此。
### 连续批处理
通过 mlx-lm 的 BatchGenerator 处理并发请求。最大并发请求数可通过 CLI 或管理面板配置。
### Claude Code 优化
支持上下文缩放,可在运行小型上下文模型时使用 Claude Code。缩放报告的 token 数量,使自动紧凑触发时机更准确,SSE 长连接保持活跃以防止预填充期间读取超时。
### 多模型服务
在同一个服务器中加载 LLM、VLM、嵌入模型和重排序器。模型通过组合自动与手动控制进行管理:
- **LRU 淘汰**:最近最少使用的模型在内存不足时自动淘汰。
- **手动加载/卸载**:管理面板中的状态徽章允许按需加载或卸载模型。
- **模型固定**:将常用模型固定以保持常驻内存。
- **每模型 TTL**:为每个模型设置空闲超时,超时后自动卸载。
- **进程内存限制**:总内存限制(默认:系统 RAM - 8GB)防止系统级 OOM。
### 每模型设置
直接在管理面板中配置每个模型的采样参数、聊天模板参数、TTL、模型别名、模型类型覆盖等。更改会立即生效,无需重启服务器。
- **模型别名**:设置自定义的 API 可见名称。`/v1/models` 返回别名,请求同时接受别名和目录名。
- **模型类型覆盖**:手动将模型设为 LLM 或 VLM,不受自动检测影响。
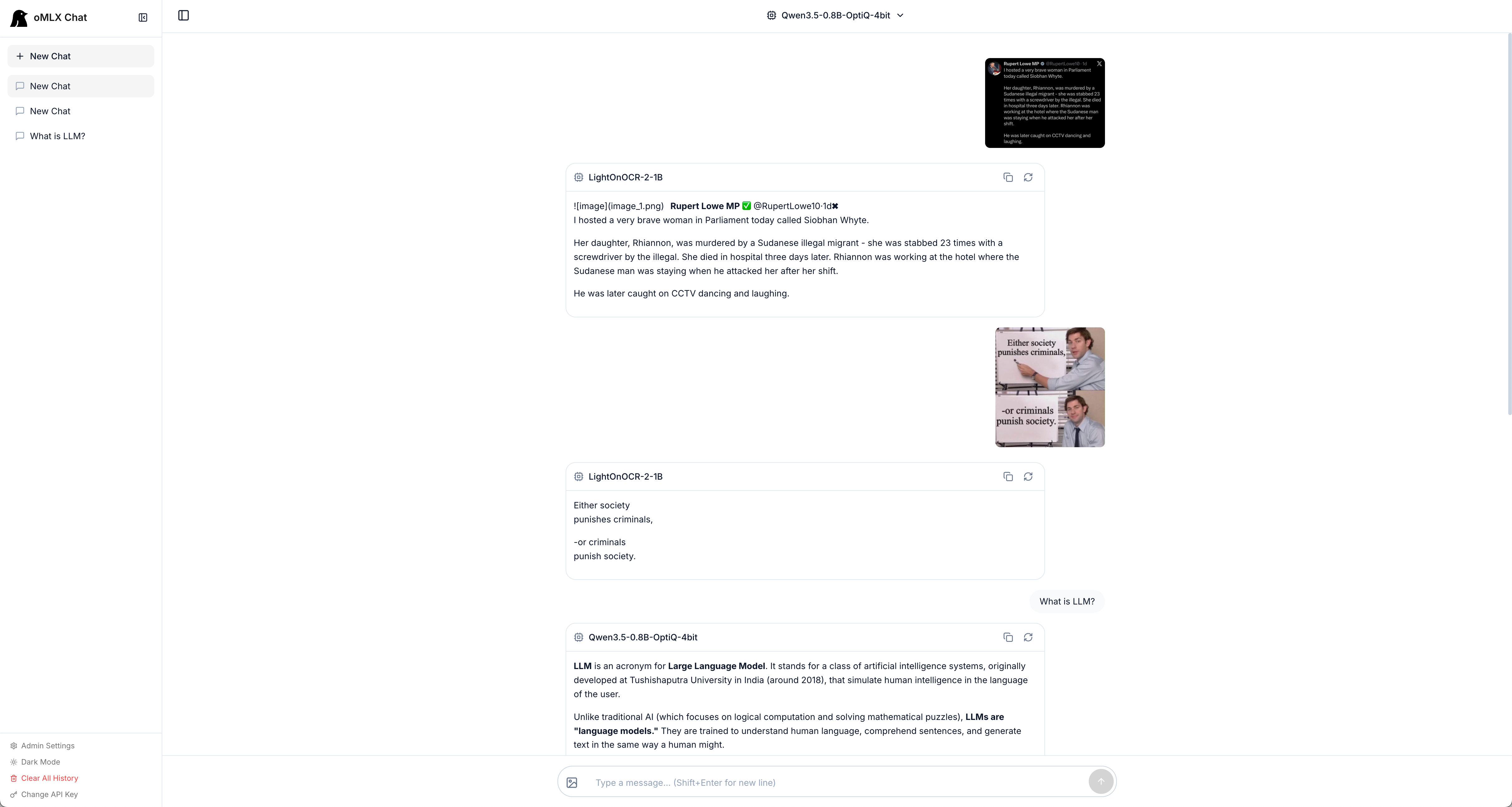
### 内置聊天
从管理面板直接与任何已加载模型聊天。支持对话历史、模型切换、深色模式、推理模型输出,以及 VLM/OCR 模型的图像上传。
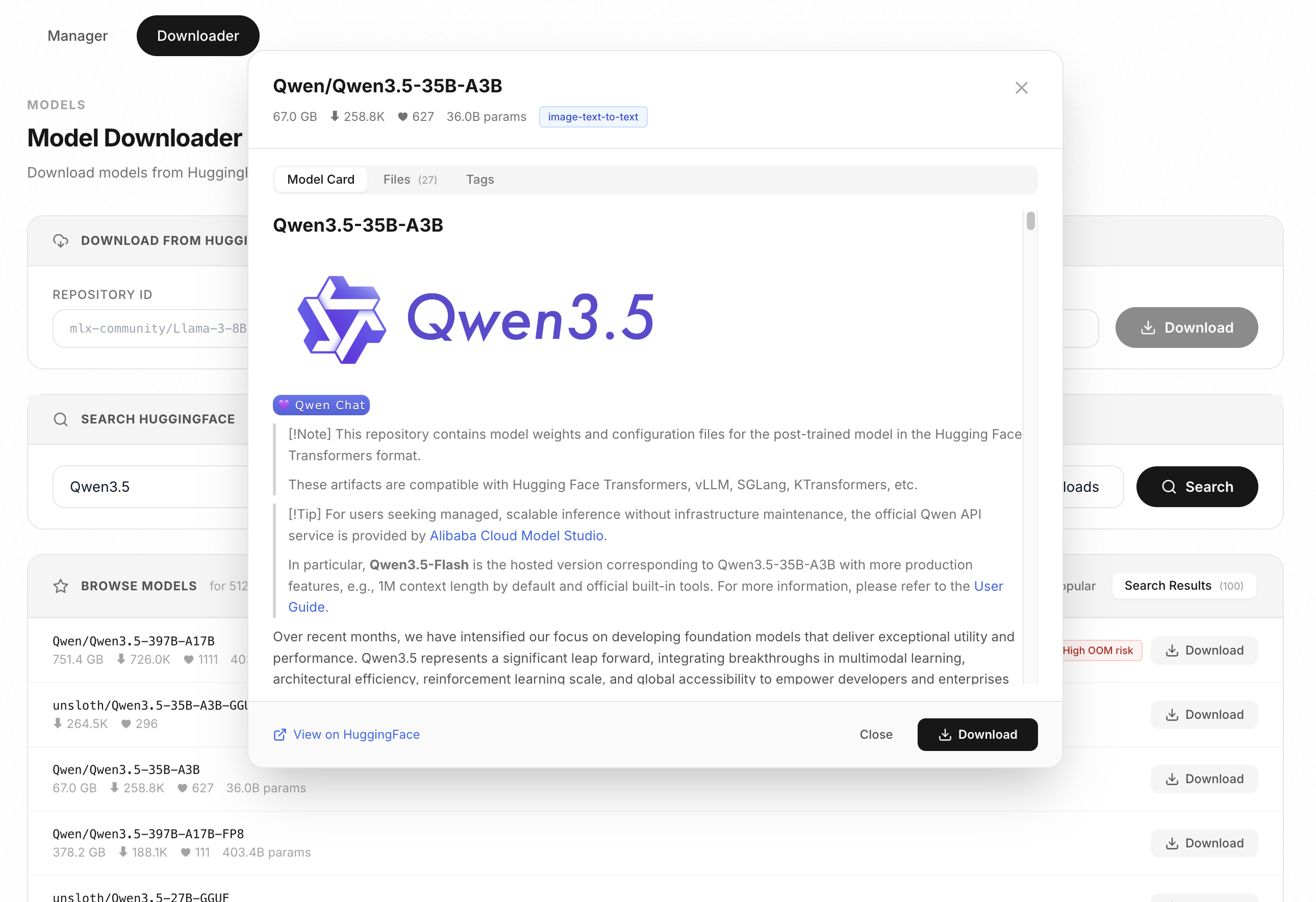
### 模型下载器
在管理面板中搜索并直接下载 HuggingFace 上的 MLX 模型。浏览模型卡片,检查文件大小,并一键下载。
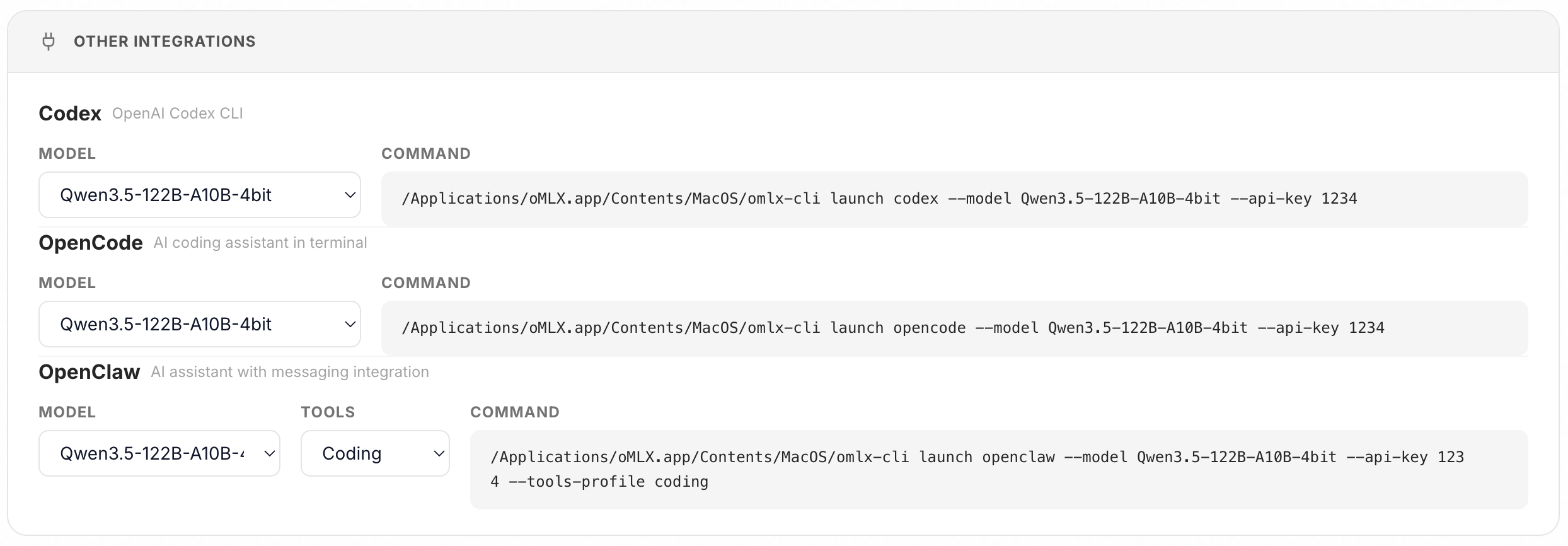
### 集成
一键设置 OpenClaw、OpenCode、Codex 和 Pi,无需手动编辑配置。
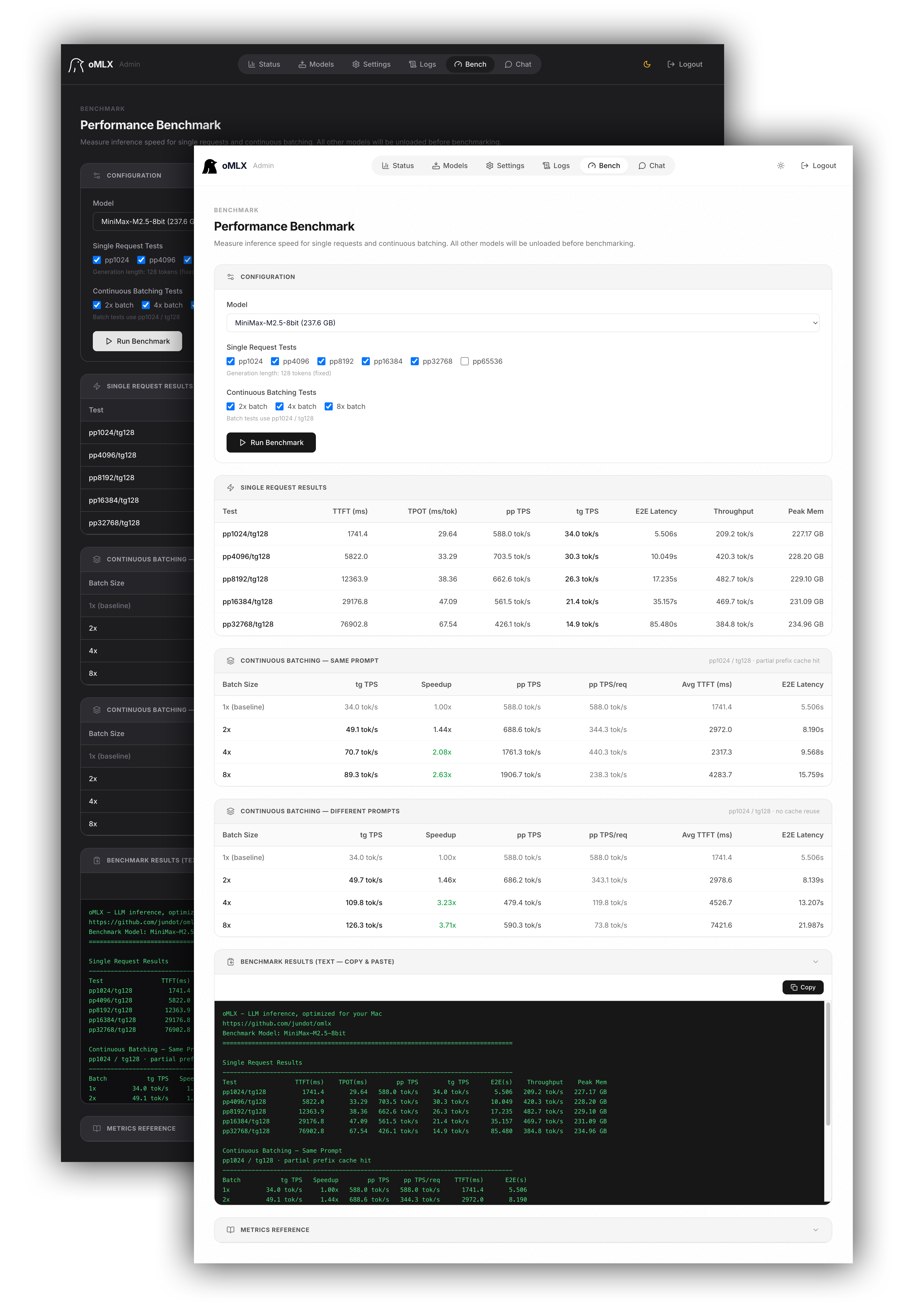
### 性能基准测试
从管理面板一键运行基准测试。测量预填充(PP)和文本生成(TG)的 tokens/秒,并包含部分前缀缓存命中测试以获取真实性能数据。
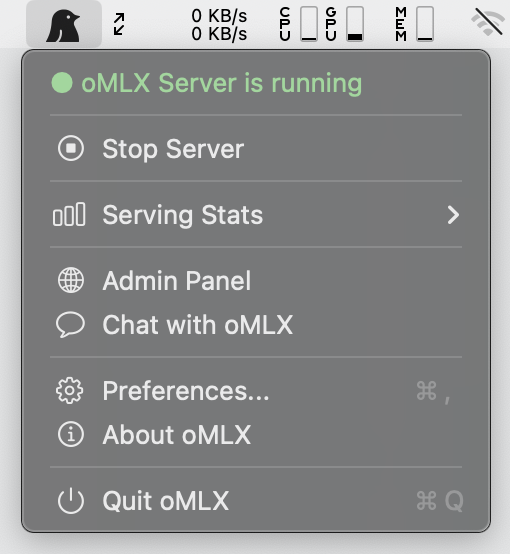
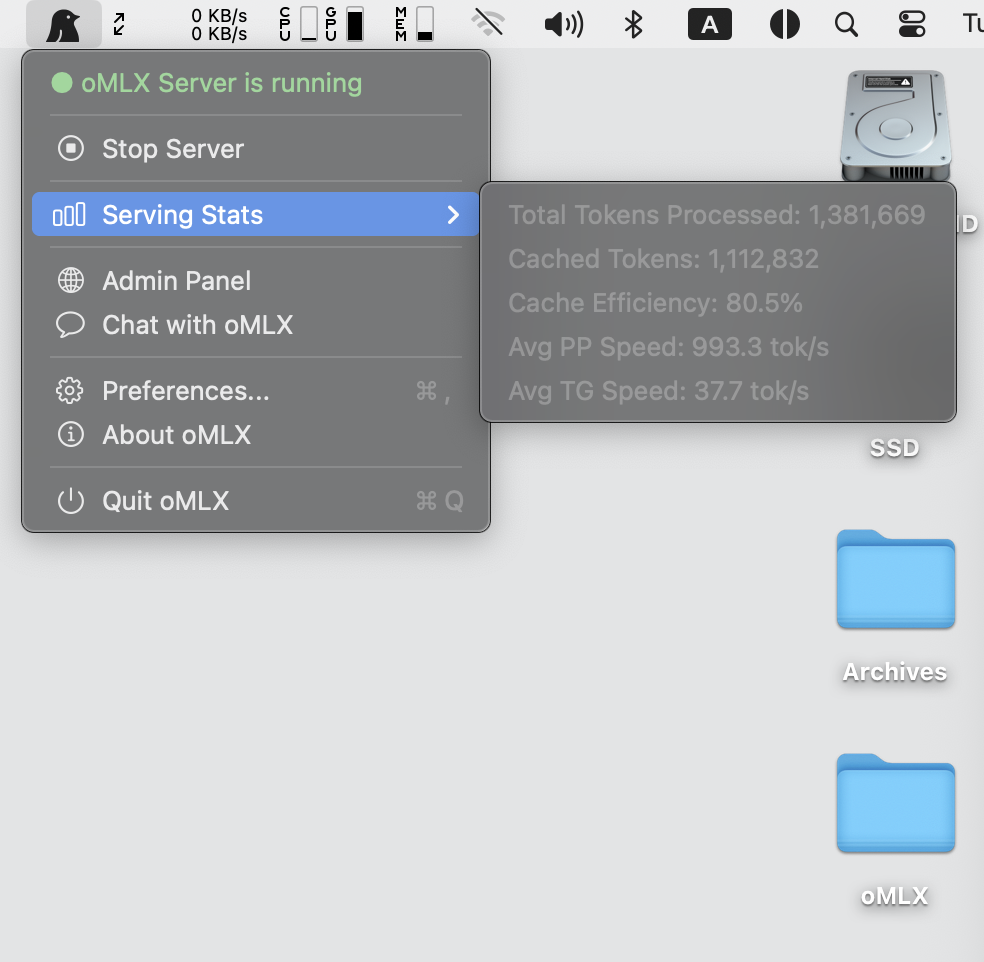
### macOS 菜单栏应用
原生 PyObjC 菜单栏应用(非 Electron)。无需打开终端即可启动、停止和监控服务器。包含持久化服务状态(重启后保留)、崩溃自动重启和应用内自动更新。
### API 兼容性
与 OpenAI 和 Anthropic API 的即插即用替代方案。支持流式使用统计(`stream_options.include_usage`)、Anthropic 自适应思维,以及视觉输入(base64、URL)。
| 端点 | 描述 |
|----------|-------------|
| `POST /v1/chat/completions` | 聊天补全(流式) |
| `POST /v1/completions` | 文本补全(流式) |
| `POST /v1/messages` | Anthropic 消息 API |
| `POST /v1/embeddings` | 文本嵌入 |
| `POST /v1/rerank` | 文档重排序 |
| `GET /v1/models` | 列出可用模型 |
### 工具调用与结构化输出
支持 mlx-lm 中所有可用的函数调用格式、JSON Schema 验证以及 MCP 工具集成。工具调用需要模型的聊天模板支持 `tools` 参数。以下模型系列可通过 mlx-lm 内置工具解析器自动检测:
| 模型系列 | 格式 |
|------|
| Llama、Qwen、DeepSeek 等 | JSON `
标签:AI模型部署, Apache 2.0, Apple Silicon, Auto Update, Continuous Batching, Dashboard, KV缓存, LLM推理, macOS App, oMLX, Python, SSD缓存, Tiered Caching, 中文支持, 命令行界面, 实时推理, 推理服务, 无后门, 日文支持, 本地推理, 机器学习推理, 模型优化, 端侧推理, 缓存优化, 菜单栏管理, 连续批处理, 逆向工具, 韩文支持, 高性能计算