Brightd4/AEGIS-MIS
GitHub: Brightd4/AEGIS-MIS
AEGIS-MIS 是一个混合式可解释虚假信息检测系统,用于识别误导性文本内容。
Stars: 0 | Forks: 0
# AEGIS 管理信息系统
## 信息安全自动化可解释防护 – 虚假信息识别系统






AEGIS MIS(信息安全自动化可解释防护 – 虚假信息识别系统)是一个混合式的可解释虚假信息检测系统,它结合了基于规则的分析与机器学习技术,以提供可解释且轻量化的虚假信息分析。
该系统旨在应对日益增长的虚假信息挑战,同时保持透明度、可解释性和计算效率。
## 在线演示
AEGIS MIS 已公开部署于下方链接:
https://aegis-mis.onrender.com
## 演示截图
## 示例输入
```
BREAKING: Scientists confirm the government is hiding a secret cure for cancer. Share this immediately before it gets removed.
```
## 示例输出
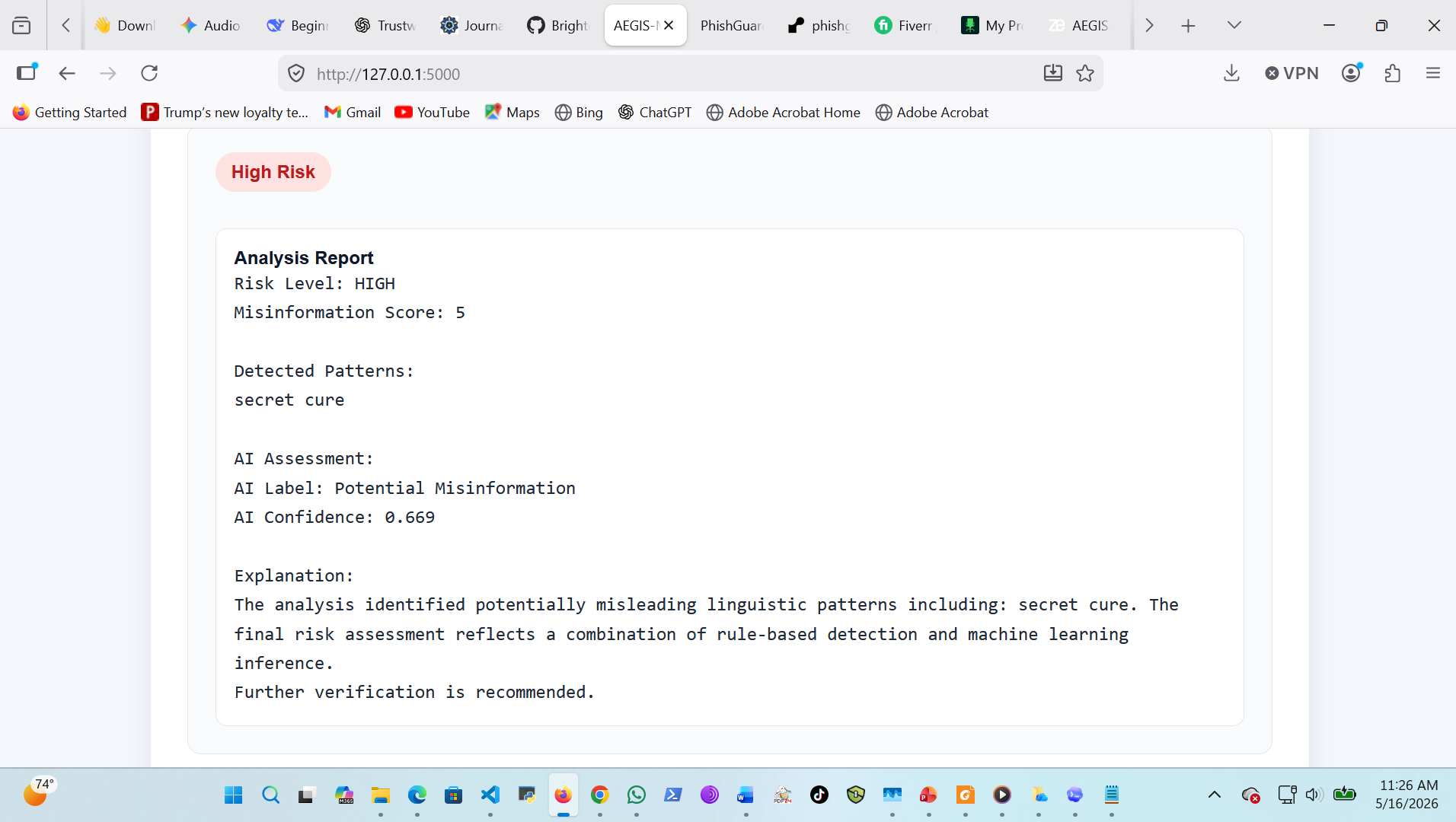
```
Risk Level: HIGH
AI Label: Potential Misinformation
Detected Pattern:
secret cure
AI Confidence: 0.669
```
## 概述
虚假信息在数字平台上快速传播,使得自动化检测变得越来越重要。然而,许多机器学习系统作为黑盒模型运作,可解释性有限。
AEGIS MIS 通过一种混合架构来应对这一挑战,该架构结合了:
- 基于规则的分析以确保可解释性
- 使用 TF-IDF 和 Logistic Regression 的机器学习分类
- 用于透明决策支持的可解释性机制
该系统为分析可疑或误导性文本内容提供了一种轻量且可解释的方法。
## 主要特性
- 混合式虚假信息检测
- 基于规则的语言模式分析
- TF-IDF 特征提取
- Logistic Regression 分类
- 可解释的决策支持
- 轻量化架构
- Flask Web 界面
- REST API 支持
- 实时文本分析
## 摘要
AEGIS MIS 是一个混合式虚假信息检测原型,旨在识别潜在的欺骗性、操纵性或误导性文本内容。
该系统集成了基于规则的模式检测与一个基于 TF-IDF 特征提取和 Logistic Regression 的机器学习分类器。这些组件通过一个混合评分引擎相结合,产生可解释的虚假信息风险评估。
为支持透明度和可信度,AEGIS MIS 包含一个可解释性模块,该模块会突出显示导致每次分类决策的触发因素和模型信号。
该框架通过一个轻量级的 Flask Web 应用程序和 REST API 进行部署,支持交互式分析以及与其他专注于安全的系统集成。
## 工作原理
该系统使用两种互补的检测方法来处理文本。
### 1. 基于规则的分析
基于规则的引擎分析:
- 可疑关键词
- 误导性语言模式
- 耸人听闻的表达
- 操纵性短语
- 基于触发因素的指标
每个检测到的模式都会对累积的虚假信息风险评分做出贡献。
### 2. 机器学习分类
机器学习流水线:
- 将文本转换为 TF-IDF 特征向量
- 应用 Logistic Regression 分类
- 生成基于概率的预测
- 产生置信度分数
### 最终决策层
两个组件的输出相结合,产生:
- 最终的虚假信息风险等级
- AI 分类标签
- 置信度分数
- 可解释的推理输出
## 系统架构
AEGIS MIS 框架由以下组件构成:
- 输入预处理模块
- 基于规则的分析引擎
- TF-IDF 特征提取层
- 机器学习分类引擎
- 混合评分层
- 可解释性引擎
- Flask Web 界面
- REST API 层
## 数据集
AEGIS MIS 使用两类数据集:
1. 合成原型验证数据集
2. 源自公开可用的 LIAR 数据集的基准评估数据集
合成数据集用于在受控的实验环境中验证混合可解释架构。
基准评估数据集源自 LIAR 数据集,用于虚假信息分类实验。
数据集来源:
https://www.cs.ucsb.edu/~william/data/liar_dataset.zip
预处理流水线包括:
- 文本规范化
- 转换为小写
- 标签简化
- TF-IDF 特征提取
处理后的数据用于训练集成在 AEGIS MIS 框架中的轻量化 Logistic Regression 虚假信息分类器。
机器学习流水线生成序列化的模型制品,用于实时推理和部署期间。
## Web 界面
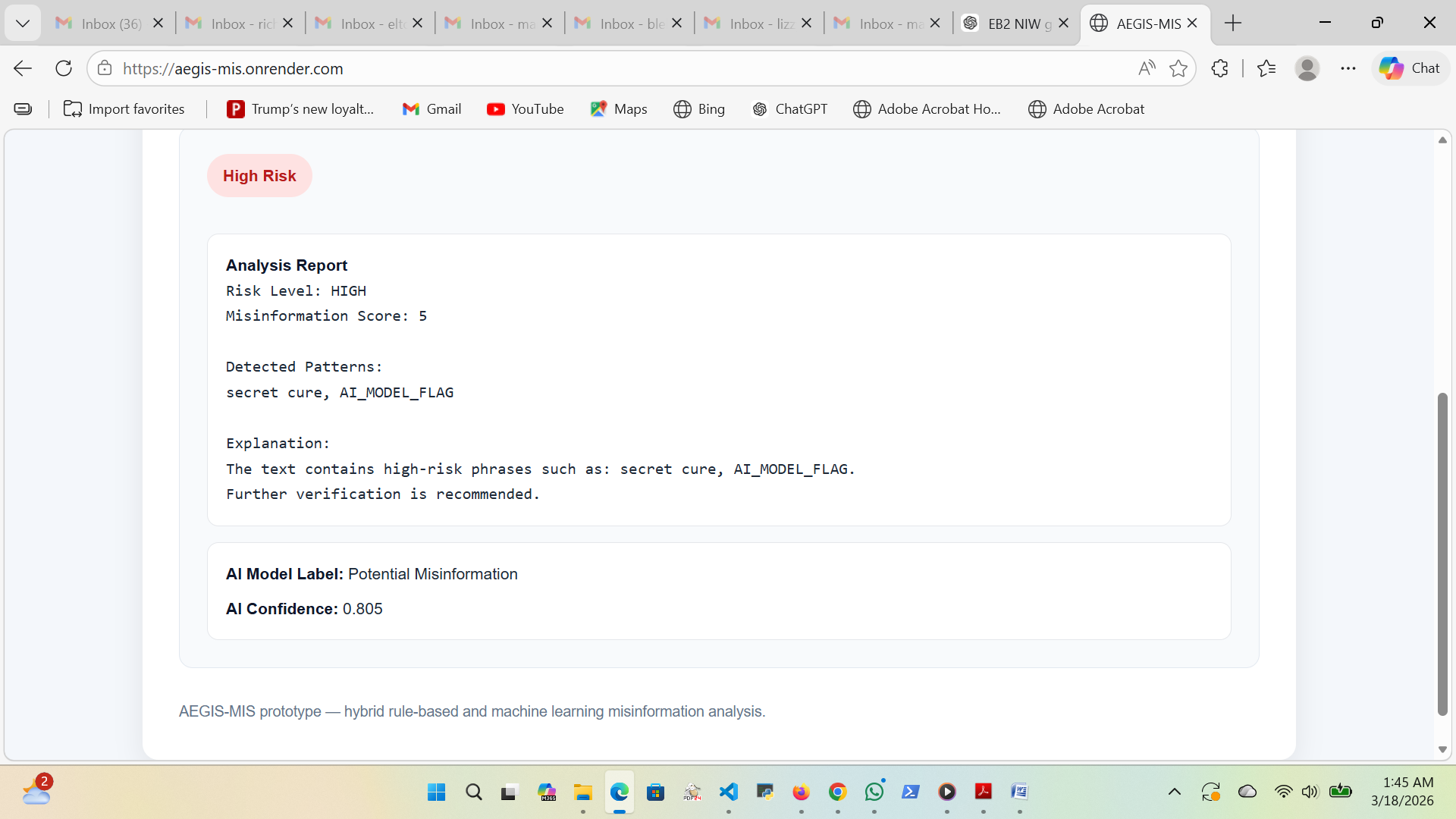
## 分析结果示例
## 可复现性
该代码仓库包含:
- 源代码
- 训练脚本
- 序列化的机器学习模型
- 部署配置文件
- 示例截图
- 用于依赖安装的需求文件
可以使用下文提供的安装说明在本地复现该项目。
## 安装指南
克隆仓库:
```
git clone https://github.com/Brightd4/aegis-mis.git
cd aegis-mis
```
创建并激活虚拟环境:
```
python -m venv .venv
```
在 Windows 上激活:
```
.venv\Scripts\activate
```
安装依赖项:
```
pip install -r requirements.txt
```
运行应用程序:
```
python app.py
```
应用程序将在本地运行于:
```
http://127.0.0.1:5000
```
## 项目结构
```
AEGIS-MIS
├── data/
├── docs/
├── exhibits/
├── figures/
├── models/
├── screenshots/
├── src/
│ ├── detector.py
│ ├── explainer.py
│ ├── ml_detector.py
│ └── main.py
├── app.py
├── train_model.py
├── requirements.txt
├── Procfile
├── README.md
└── .gitignore
```
## 局限性
AEGIS MIS 是一个轻量级的研究原型,存在一些局限性。
- 基于规则的引擎依赖于手动定义的模式
- 基准评估是在有限的虚假信息数据集上进行的
- 该系统目前主要关注英文文本
- 模型可能产生误报或漏报
- 合成验证数据集并未完全代表真实世界虚假信息的复杂性
该框架旨在用于研究和教育目的,而非生产级别的虚假信息审核。
## 伦理考量
AEGIS MIS 旨在支持可解释的虚假信息分析,同时保持决策过程的透明度。
该系统不作权威性的事实判断,不应作为审查、内容删除或法律决策的唯一依据。
在评估潜在误导性信息时,人工验证和上下文解读仍然至关重要。
## 未来工作
潜在的未来改进包括:
- 基于深度学习的虚假信息检测
- 基于 Transformer 的架构
- 多语言虚假信息分析
- 实时社交媒体监控
- 对抗性鲁棒性评估
- 扩展基准测试
- 可解释性 AI 可视化改进
## DOI
存档的 AEGIS MIS 软件版本可在 Zenodo 上获取:
https://doi.org/10.5281/zenodo.20161662
## 引用
如果您在研究或学术工作中使用 AEGIS MIS,请引用:
```
Duffour, B., & Ayitey, A. (2026). AEGIS MIS: A Hybrid Explainable Misinformation Detection System Using Rule Based Analysis and Machine Learning.
```
## 许可证
本项目基于 MIT 许可证发布。
标签:Apex, Flask, meg, Python, SEO优化, TCP/UDP协议, TF-IDF, 云计算, 信息安全, 信息操作, 内容审核, 可解释人工智能, 子域名暴力破解, 数字平台监控, 文本分类, 无后门, 机器学习, 检测系统, 网络安全, 网络测绘, 自动化检测, 虚假信息检测, 规则引擎, 轻量级系统, 逆向工具, 逻辑回归, 隐私保护