Mesh-LLM/mesh-llm
GitHub: Mesh-LLM/mesh-llm
Mesh-LLM 是一个基于 llama.cpp 的分布式大模型推理系统,能够汇聚多台设备的闲置 GPU 算力,自动处理流水线并行或专家分片,并对外提供兼容 OpenAI 的统一 API。
Stars: 2689 | Forks: 323
# Mesh LLM

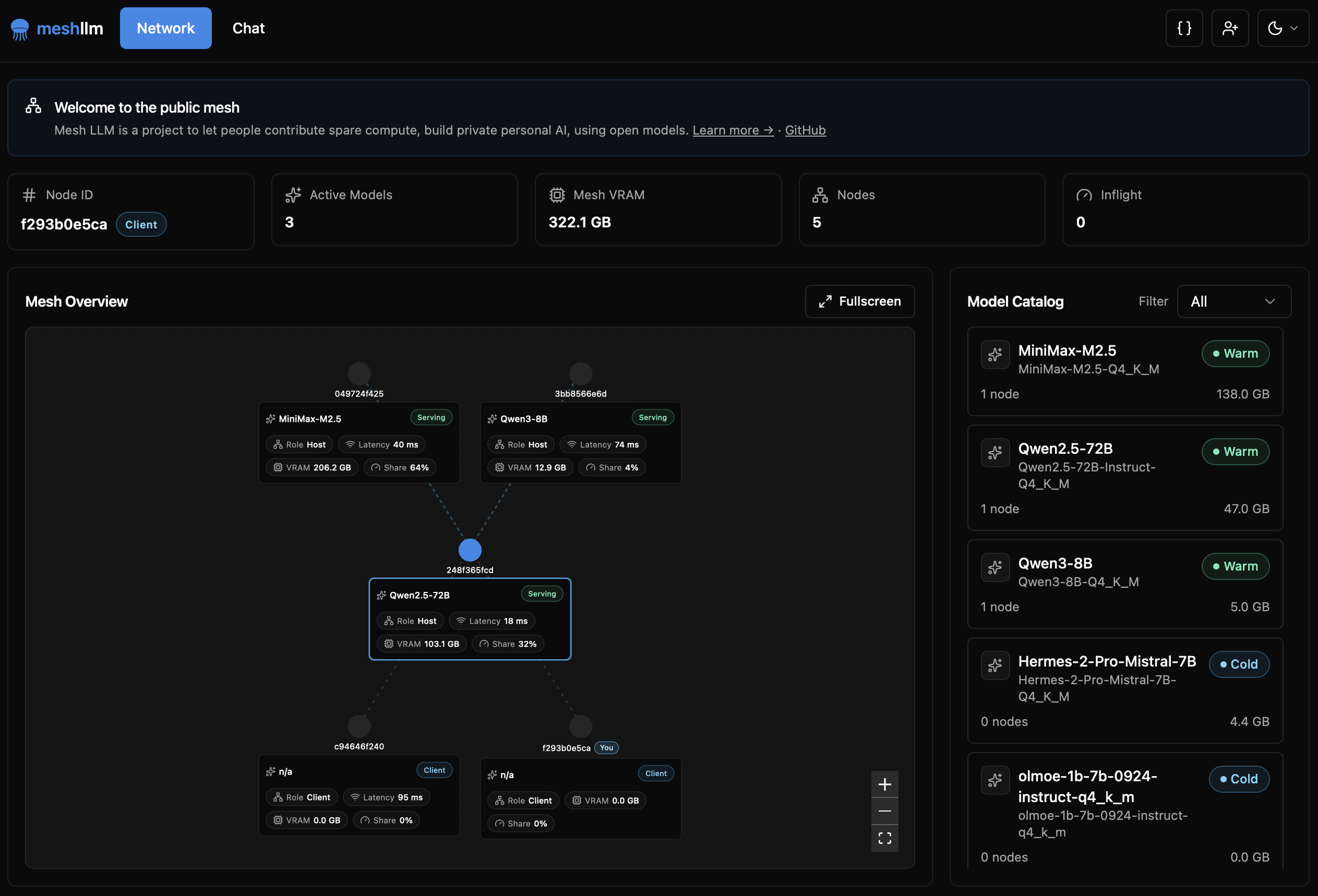
Mesh LLM 允许你汇聚多台机器的闲置 GPU 算力,并将结果作为一个 OpenAI 兼容的 API 暴露出来。
如果一个模型可以放在一台机器上,它就在那里运行。如果不能,Mesh LLM 会自动将工作负载分发到整个 mesh 网络中:
- Dense(稠密)模型使用流水线并行。
- MoE 模型使用专家分片,零跨节点推理流量。
- 每个节点在 `http://localhost:9337/v1` 获得相同的本地 API。
## 为什么使用它
- 运行超过单机承载能力的超大模型。
- 将几台配置不均的机器整合为一个共享推理池。
- 为代理提供本地的 OpenAI 兼容端点,无需手动连接每个工具。
- 保持设置简单:先启动一个节点,稍后添加更多。
## 快速开始
安装最新版本:
```
curl -fsSL https://raw.githubusercontent.com/Mesh-LLM/mesh-llm/main/install.sh | bash
```
然后启动一个节点:
```
mesh-llm serve --auto
```
检查本地 GPU 身份:
```
mesh-llm gpus
```
该命令:
- 为你的机器选择合适的内置后端
- 按需下载模型
- 加入最佳公共 mesh
- 在 `http://localhost:9337/v1` 暴露 OpenAI 兼容 API
- 在 `http://localhost:3131` 启动 Web 控制台
检查可用内容:
```
curl -s http://localhost:9337/v1/models | jq '.data[].id'
```
发送请求:
```
curl http://localhost:9337/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"GLM-4.7-Flash-Q4_K_M","messages":[{"role":"user","content":"hello"}]}'
```
## 常见工作流程
### 1. 尝试公共 mesh
```
mesh-llm serve --auto
```
这是查看系统端到端运行的最简单方法。
### 2. 启动私有 mesh
```
mesh-llm serve --model Qwen2.5-32B
```
这将启动模型服务,打开本地 API 和控制台,并打印供其他机器使用的邀请令牌。
### 3. 从源码构建
```
git clone https://github.com/Mesh-LLM/mesh-llm
cd mesh-llm
just build
```
要求:`just`,`cmake`,Rust 工具链,Node.js 24 + npm。NVIDIA GPU 构建需要 `nvcc`(CUDA toolkit)。AMD GPU 构建需要 ROCm/HIP。Vulkan GPU 构建需要 Vulkan 开发文件以及 `glslc`。纯 CPU 和 Jetson/Tegra 也可以正常工作。对于源码构建,`just build` 会在 Linux 上自动检测 CUDA、ROCm 或 Vulkan,或者你可以强制指定 `backend=rocm` 或 `backend=vulkan`。详情请参阅 [CONTRIBUTING.md](CONTRIBUTING.md)。
也支持通过 `just build` 在 Windows 上进行源码构建,支持 `cuda`、`rocm`/`hip`、`vulkan` 和 `cpu` 后端。Metal 仍然是 macOS 独占。GitHub 标签发布版本现在提供 `cpu`、`cuda`、`rocm` 和 `vulkan` 的 Windows `.zip` 包,你可以使用 `just release-build-windows`、`just release-build-cuda-windows`、`just release-build-rocm-windows`、`just release-build-vulkan-windows` 以及匹配的 `release-bundle-*-windows` 配方在本地生成相同的构建产物。
## 运行
安装完成后,你可以运行:
```
mesh-llm serve --auto # join the best public mesh, start serving
```
仅此而已。它会为你的硬件下载模型,连接到其他节点,并为你提供 `http://localhost:9337` 上的 OpenAI 兼容 API。
或者启动你自己的 mesh:
```
mesh-llm serve --model Qwen2.5-32B # downloads model (~20GB), starts API + web console
mesh-llm serve --model Qwen2.5-3B # or a small model first (~2GB)
```
添加另一台机器:
```
mesh-llm serve --join # token printed by the first machine
```
或者发现并加入公共 mesh:
```
mesh-llm serve --auto # find and join the best mesh
mesh-llm client --auto # join as API-only client (no GPU)
```
## 工作原理
每个节点在 `http://localhost:9337/v1` 获得一个 OpenAI 兼容 API。分发是自动的 —— 你只需指定 `mesh-llm serve --model X`,mesh 就会找出最佳策略:
- **模型适合一台机器?** → 独立运行,全速,无网络开销
- **Dense 模型太大?** → 流水线并行 —— 层在节点间拆分
- **MoE 模型太大?** → 专家并行 —— 专家在节点间拆分,零跨节点流量
如果一个节点有足够的 VRAM,它总是运行完整模型。拆分仅在必要时发生。
目前使用的是轻度修改的 llama.cpp 版本(具体分支拉取位置请参阅 Justfile)。
**流水线并行** —— 对于无法放在一台机器上的 Dense 模型,层会按 VRAM 比例分配到各个节点。llama-server 运行在 VRAM 最高的节点上并通过 RPC 进行协调。每个 rpc-server 仅从本地磁盘加载其分配的层。感知延迟:优先选择 RTT 最低的对等节点,硬性限制为 80ms —— 高延迟节点作为 API 客户端保留在 mesh 中,但不参与拆分。
**MoE 专家并行** —— Mixture-of-Experts 模型(Qwen3-MoE、GLM、OLMoE、Mixtral、DeepSeek —— 越来越成为性能最好的架构)会从 GGUF 头部自动检测。mesh 读取专家路由统计数据以识别最重要的专家,然后为每个节点分配一个重叠分片:关键专家的共享核心在所有节点复制,加上在节点间分布的独特专家。每个节点获得一个独立的 GGUF,包含完整的 trunk 加上其专家子集,并运行自己独立的 llama-server —— 推理期间零跨节点流量。会话通过哈希路由到节点以保持 KV cache 局部性。
**多模型** —— 不同节点同时服务不同模型。API 代理通过查看每个请求中的 `model` 字段并通过 QUIC 隧道路由到正确的节点。`/v1/models` 列出所有可用内容。
**感知负载的重新平衡** —— 一个统一的需求映射跟踪 mesh 想要哪些模型(来自 `--model` 标志、API 请求和 gossip)。需求信号在所有节点间传播并随 TTL 自然衰减。备用节点自动提升以服务有活跃需求的未服务模型,或者当一个模型明显比其他模型更热时重新平衡。当模型失去其最后一个服务器时,备用节点会在约 60 秒内检测到。
**延迟设计** —— 核心洞察是 HTTP 流式传输可以容忍延迟,而 RPC 会倍增延迟。llama-server 始终运行在与 GPU 相同的机器上。mesh 隧道传输 HTTP,因此跨网络延迟仅影响首字时间,不影响每个 token 的吞吐量。RPC 仅在模型物理上无法放在一台机器上的流水线拆分时才跨越网络。
### 网络优化
- **零传输 GGUF 加载** —— `SET_TENSOR_GGUF` 告诉 rpc-server 从本地磁盘读取权重。模型加载时间从 111s 降至 5s。
- **RPC 往返减少** —— 缓存 `get_alloc_size`,跳过中间体的 GGUF 查找。每个 token 的往返次数:558 → 8。
- **直接服务器到服务器传输** —— 中间张量通过 TCP 直接在 rpc-server 之间推送,不由客户端中继。
- **推测解码** —— 草稿模型在主机上本地运行,提议的 token 在一次批量前向传播中验证。代码吞吐量提升 38%(75% 接受率)。
## 用法
### 启动 mesh
```
mesh-llm serve --model Qwen2.5-32B
```
启动模型服务并打印邀请令牌。此 mesh 是**私有**的 —— 只有你与其共享令牌的人才能加入。
要使其变为**公共**(其他人可以通过 `--auto` 发现):
```
mesh-llm serve --model Qwen2.5-32B --publish
```
### 加入 mesh
```
mesh-llm serve --join # join with invite token (GPU node)
mesh-llm client --join # join as API-only client (no GPU)
```
### 命名 mesh(伙伴模式)
```
mesh-llm serve --auto --model GLM-4.7-Flash-Q4_K_M --mesh-name "poker-night"
```
每个人都运行相同的命令。第一个创建它,其他所有人发现 "poker-night" 并自动加入。`--mesh-name` 意味着 `--publish` —— 命名 mesh 始终发布到目录。
### 自动发现
```
mesh-llm serve --auto # discover, join, and serve a model
mesh-llm client --auto # join as API-only client (no GPU)
mesh-llm discover # browse available meshes
mesh-llm gpus # inspect local GPUs and stable IDs
```
### 多模型
```
mesh-llm serve --model Qwen2.5-32B --model GLM-4.7-Flash
# 按模型名称路由
curl localhost:9337/v1/chat/completions -d '{"model":"GLM-4.7-Flash-Q4_K_M", ...}'
```
不同节点服务不同模型。API 代理通过 `model` 字段进行路由。
### 检查本地 GPU
```
mesh-llm gpus
mesh-llm gpus --json
mesh-llm gpu benchmark --json
```
`mesh-llm gpus` 打印本地 GPU 条目、后端设备名称、稳定 ID、VRAM、统一内存状态,以及当基准测试指纹可用时的缓存带宽。添加 `--json` 以获取机器可读的清单输出,或运行 `mesh-llm gpu benchmark --json` 以刷新本地指纹并将基准测试结果打印为 JSON。
仅使用 `mesh-llm gpus` 或 `mesh-llm gpus --json` 中可固定的 `Stable ID` / `stable_id` 值进行固定启动配置。`index:*` 等稳定 ID 后备值或 `CUDA0` / `HIP0` / `MTL0` 等后端设备名称仍可出于清单目的打印,但它们不是有效的固定目标。
### 启动配置
`mesh-llm serve` 现在可以从 `~/.mesh-llm/config.toml` 加载启动模型:
```
version = 1
[gpu]
assignment = "pinned"
[[models]]
model = "Qwen3-8B-Q4_K_M"
gpu_id = "pci:0000:65:00.0"
[[models]]
model = "bartowski/Qwen2.5-VL-7B-Instruct-GGUF/qwen2.5-vl-7b-instruct-q4_k_m.gguf"
mmproj = "bartowski/Qwen2.5-VL-7B-Instruct-GGUF/mmproj-f16.gguf"
ctx_size = 8192
gpu_id = "uuid:GPU-12345678"
[[plugin]]
name = "blackboard"
enabled = true
```
使用默认配置路径启动:
```
mesh-llm serve
```
如果没有配置启动模型,`mesh-llm serve` 会打印 `⚠️` 警告,显示帮助并退出。
或者指向不同的文件:
```
mesh-llm serve --config /path/to/config.toml
```
优先级规则:
- 显式的 `--model` 或 `--gguf` 会忽略配置的 `[[models]]`。
- 显式的 `--ctx-size` 会覆盖所选启动模型的配置 `ctx_size`。
- 插件条目仍位于同一文件中。
固定启动说明:
- `assignment = "pinned"` 要求每个配置的 `[[models]]` 条目都包含 `gpu_id`。
- 有效的 `gpu_id` 值来自 `mesh-llm gpus` / `mesh-llm gpus --json` 报告的可固定稳定 ID,而不是后备清单 ID。
- 当配置的 ID 缺失、有歧义、本地后端不支持或无法在当前机器上解析时,固定配置会失败并关闭。
- 显式的 `--model` / `--gguf` 仍然绕过配置的 `[[models]]`,因此它们也绕过配置拥有的固定 `gpu_id` 值。
### 无参数行为
```
mesh-llm # no args — prints --help and exits
```
不启动控制台或绑定任何端口。使用 `--help` 中显示的 CLI 标志来启动或加入 mesh。
## 后台服务
要将其安装为每用户后台服务:
```
curl -fsSL https://raw.githubusercontent.com/Mesh-LLM/mesh-llm/main/install.sh | bash -s -- --service
```
服务安装是用户范围的:
- macOS 在 `~/Library/LaunchAgents/com.mesh-llm.mesh-llm.plist` 安装 `launchd` 代理
- Linux 在 `~/.config/systemd/user/mesh-llm.service` 安装 `systemd --user` 单元
- 共享环境配置位于 `~/.config/mesh-llm/service.env`
- 启动模型位于 `~/.mesh-llm/config.toml`
这两个平台处理启动启动的方式相同:
- macOS:`launchd` 运行 `~/.config/mesh-llm/run-service.sh`,该脚本加载 `service.env` 并执行 `mesh-llm serve`。
- Linux:安装程序将 `mesh-llm serve` 直接写入 `~/.config/systemd/user/mesh-llm.service` 的 `ExecStart=` 中。
后台服务不再存储自定义启动参数。改为在 `~/.mesh-llm/config.toml` 中配置启动模型。
`service.env` 是可选的,并且两个平台共享。使用纯 `KEY=value` 行,例如:
```
MESH_LLM_NO_SELF_UPDATE=1
```
如果你在 Linux 上手动编辑单元,请重新加载并重启它:
```
systemctl --user daemon-reload
systemctl --user restart mesh-llm.service
```
在 Linux 上这是一个用户服务,所以如果你希望它在重启后登录前继续运行,请启用一次 lingering:
```
sudo loginctl enable-linger "$USER"
```
## Web 控制台
```
mesh-llm serve --model Qwen2.5-32B # dashboard at http://localhost:3131
```
实时拓扑、每节点 GPU 容量、模型选择器和内置聊天。所有内容均来自 `/api/status`(JSON)和 `/api/events`(SSE)。
## 多模态支持
mesh-llm 在以下端点支持多模态请求:
- `POST /v1/chat/completions`
- `POST /v1/responses`
控制台支持图像、音频和文件附件。大附件使用请求范围的 blob 上传,而不是永久存储。
### 当前支持矩阵
| Family / model type | Vision | Audio | Notes |
|---|---|---|---|
| `Qwen3-VL`, `Qwen3VL` | yes | no | 示例:`Qwen3VL-2B-Instruct-Q4_K_M` |
| `Qwen2-VL`, `Qwen2.5-VL` | yes | no | 具有视觉能力的 Qwen VL 系列 |
| `LLaVA`, `mllama`, `PaliGemma`, `Idefics`, `Molmo`, `InternVL`, `GLM-4V`, `Ovis`, `Florence` | yes | no | 检测为具有视觉能力的系列 |
| `Qwen2-Audio` | no | yes | 具有音频能力的系列 |
| `SeaLLM-Audio` | no | yes | 具有音频能力的系列 |
| `Ultravox` | no | yes | 具有音频能力的系列 |
| `ni` | no or metadata-dependent | yes | 示例:`Qwen2.5-Omni-3B-Q4_K_M` |
| `Whisper` | no | yes | 具有音频能力的系列 |
| 任何带有 `mmproj` 侧车的 GGUF | yes | depends | 视觉支持的强本地信号 |
| 任何具有 `vision_config` / 视觉 token ID 的模型 | yes | depends | 由元数据提升 |
| 任何具有 `audio_config` / 音频 token ID 的模型 | depends | yes | 由元数据提升 |
| 仅限通用 `multimodal`、`-vl`、`image`、`video`、`voice` 命名 | likely | likely | 仅作为提示,不是强有力的路由保证 |
备注:
- `yes` 表示 mesh-llm 将模型视为运行时可支持,用于路由和 UI。
- `likely` 表示 mesh-llm 显示较弱的提示,但不依赖其作为硬性能力。
- 混合图像+音频请求仅在所选的模型/运行时实际支持这两种模态时才有效。
- 非目标:`POST /v1/audio/transcriptions`、`POST /v1/audio/speech` 和 `v1/realtime`。
有关完整功能和传输详情,请参阅 [mesh-llm/docs/MULTI_MODAL.md](mesh-llm/docs/MULTI_MODAL.md)。
### 开发
从源代码构建和 UI 开发说明位于 [CONTRIBUTING.md](CONTRIBUTING.md)。
## 与代理一起使用
mesh-llm 在 `localhost:9337` 上暴露 OpenAI 兼容 API。任何支持自定义 OpenAI 端点的工具都可以使用。`/v1/models` 列出可用模型;请求中的 `model` 字段路由到正确的节点。
对于内置启动器集成(`goose`、`claude`):
- 如果 mesh 已经在 `--port` 上本地运行,则重用它。
- 如果没有,`mesh-llm` 会自动启动一个自动加入 mesh 的后台客户端节点。
- 如果省略 `--model`,启动器会选择 mesh 上可用的最强工具能力模型。
- 当控制工具退出时(例如 `claude` 退出),自动启动的节点会自动清理。
### goose
[Goose](https://github.com/block/goose) 可作为 CLI(`goose session`)和桌面应用 提供。
```
mesh-llm goose
```
使用特定模型(例如:MiniMax):
```
mesh-llm goose --model MiniMax-M2.5-Q4_K_M
```
此命令会写入/更新 `~/.config/goose/custom_providers/mesh.json` 并启动 Goose。
### pi
1. 启动 mesh 客户端:
```
mesh-llm client --auto --port 9337
```
2. 检查可用模型:
```
curl -s http://localhost:9337/v1/models | jq '.data[].id'
```
### Lemonade
mesh-llm 内置了一个 `lemonade` 插件,将本地 [Lemonade Server](https://lemonade-server.ai) 注册为另一个 OpenAI 兼容后端。有关设置和验证步骤,请参阅 [docs/USAGE.md](docs/USAGE.md#lemonade-integration)。
如果你希望 mesh 可通过 `--auto` 发现,请发布它:
```
mesh-llm serve --model Qwen2.5-32B --publish
```
### 3. 添加另一台机器
```
mesh-llm serve --join
```
如果机器应该在不服务模型的情况下加入,请使用 `mesh-llm client`:
```
mesh-llm client --join
```
### 4. 为组创建命名 mesh
```
mesh-llm serve --auto --model GLM-4.7-Flash-Q4_K_M --mesh-name "poker-night"
```
每个人都运行相同的命令。第一个节点创建 mesh,其余节点发现并自动加入。
### 5. 服务多个模型
```
mesh-llm serve --model Qwen2.5-32B --model GLM-4.7-Flash
```
请求通过 `model` 字段路由:
```
curl localhost:9337/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"GLM-4.7-Flash-Q4_K_M","messages":[{"role":"user","content":"hello"}]}'
```
## 工作原理
Mesh LLM 保持用户界面简单:与 `localhost:9337` 通信,选择一个模型,让 mesh 决定如何服务它。
- 如果一个模型适合一台机器,它就在那里运行,没有网络开销。
- 如果 Dense 模型不适合,层会在低延迟对等节点之间拆分。
- 如果 MoE 模型不适合,专家会在节点之间拆分,请求会通过哈希路由以保持缓存局部性。
- 不同的节点可以同时服务不同的模型。
每个节点还在端口 `3131` 上暴露管理 API 和 Web 控制台。
## 安装说明
安装程序目前针对 macOS 和 Linux 发布包。Windows 即将推出。
要在安装期间强制使用特定的内置版本:
```
curl -fsSL https://raw.githubusercontent.com/Mesh-LLM/mesh-llm/main/install.sh | MESH_LLM_INSTALL_FLAVOR=vulkan bash
```
已安装的发布包使用特定版本的 llama.cpp 二进制文件:
- macOS:`metal`
- Linux:`cpu`、`cuda`、`rocm`、`vulkan`
要将包安装更新到最新发布版本:
```
mesh-llm update
```
要安装特定的内置发布标签:
```
mesh-llm update --version v0.X.Y
```
如果从源代码构建,请始终使用 `just`:
```
git clone https://github.com/Mesh-LLM/mesh-llm
cd mesh-llm
just build
```
要求和特定后端的构建说明位于 [CONTRIBUTING.md](CONTRIBUTING.md)。
## Web 控制台
当节点运行时,打开:
```
http://localhost:3131
```
控制台显示实时拓扑、VRAM 使用情况、加载的模型和内置聊天。它由 `/api/status` 和 `/api/events` 提供支持。
你也可以尝试托管演示:
**[mesh-llm-console.fly.dev](https://mesh-llm-console.fly.dev/)**
## 更多文档
- [docs/USAGE.md](docs/USAGE.md) 了解服务安装、模型命令、存储和运行时控制
- [docs/AGENTS.md](docs/AGENTS.md) 了解 Goose、Claude Code、pi、OpenCode、curl 和 blackboard 的用法
- [docs/BENCHMARKS.md](docs/BENCHMARKS.md) 了解基准测试数字和背景
- [CONTRIBUTING.md](CONTRIBUTING.md) 了解本地开发和构建工作流
- [PLUGINS.md](PLUGINS.md) 了解插件系统和 blackboard 内部机制
- [mesh-llm/README.md](mesh-llm/README.md) 了解 Rust crate 结构
- [ROADMAP.md](ROADMAP.md) 了解未来工作
## 社区
加入 Goose Discord 上的 [#mesh-llm 频道](https://discord.gg/goose-oss) 进行讨论和支持。
标签:C++, DLL 劫持, Expert Sharding (专家分片), GNU通用公共许可证, GPU 池化, llama.cpp, LLM, MITM代理, MoE (混合专家), Node.js, OpenAI 兼容 API, Pipeline Parallelism (流水线并行), Rust, Unmanaged PE, Vectored Exception Handling, 分布式推理, 可视化界面, 大语言模型, 推理加速, 数据擦除, 本地部署, 模型服务化, 模型路由, 私有化部署, 算力共享, 网络流量审计, 边缘计算, 通知系统, 防御规避, 高可用性