MachineheadLearning/fraud-forensics-pipeline
GitHub: MachineheadLearning/fraud-forensics-pipeline
一个端到端的信用卡欺诈检测与取证分析 Pipeline,融合了行为特征工程、XGBoost 分类、SHAP 可解释性以及面向调查员的交互式仪表板,展示了从原始交易数据到可操作调查工具的完整工作流。
Stars: 0 | Forks: 0
# 欺诈检测 Pipeline 与调查员仪表板
*包含行为特征工程、XGBoost 分类、SHAP 可解释性以及交互式 Streamlit 仪表板的端到端欺诈检测系统。*
Python · Pandas · XGBoost · SHAP · SMOTE · Streamlit · Plotly
## 交互式仪表板
无需安装任何软件,即可探索完整的 Pipeline 结果——模型性能、交易级调查、SHAP 可解释性以及残余风险分析。
**[→ 打开实时仪表板](https://fraud-detection-dashboards.streamlit.app)**
## 项目描述
本项目实现了一个完整的欺诈检测 Pipeline——从原始交易数据、行为特征工程、模型训练与评估,到面向调查员的交互式仪表板。它使用了 Sparkov 生成的合成数据集(Kartik2112,被 Amazon 的欺诈数据集基准引用),所有发现均被视为方法论演示,而非真实世界的欺诈洞察。该 Pipeline 的独特之处在于其领域感知方法:具有成本敏感框架的召回率优先评估、在严格的零泄漏协议下构建的 15 个行为特征、全局和单笔交易级别的基于 SHAP 的可解释性、操作性阈值分析,以及专为调查员工具设计的 4 视图 Streamlit 仪表板。这是一个展示完整端到端工作流的作品集演示——不仅仅是笔记本中的模型指标,而是一个将分析与实用工具相连接的可用系统。
## 仪表板预览
| 概览 | 交易审计器 |
|----------|-------------------|
|  |  |
| 模型可解释性 | 残余风险审计 |
|---------------------|-------------------|
|  |  |
仪表板加载预计算的预测和指标。
## 核心功能
- 采用零泄漏协议(扩展窗口、移位中位数、滚动计数)的 **15 个行为特征**
- 在高度不平衡数据集(0.58% 欺诈率,1:172 比例)上应用 **XGBoost + SMOTE**
- 在 t=0.40–0.60 范围内进行阈值敏感性分析的 **召回率优先评估**
- **SHAP 可解释性** —— 全局重要性、方向性蜂群图以及单笔交易的瀑布图分解
- **地理空间中立性审计** —— 独立的 Notebook 证明地理特征未增加任何判别信号
- **4 视图交互式仪表板** —— 概览、交易审计器、模型可解释性、残余风险审计
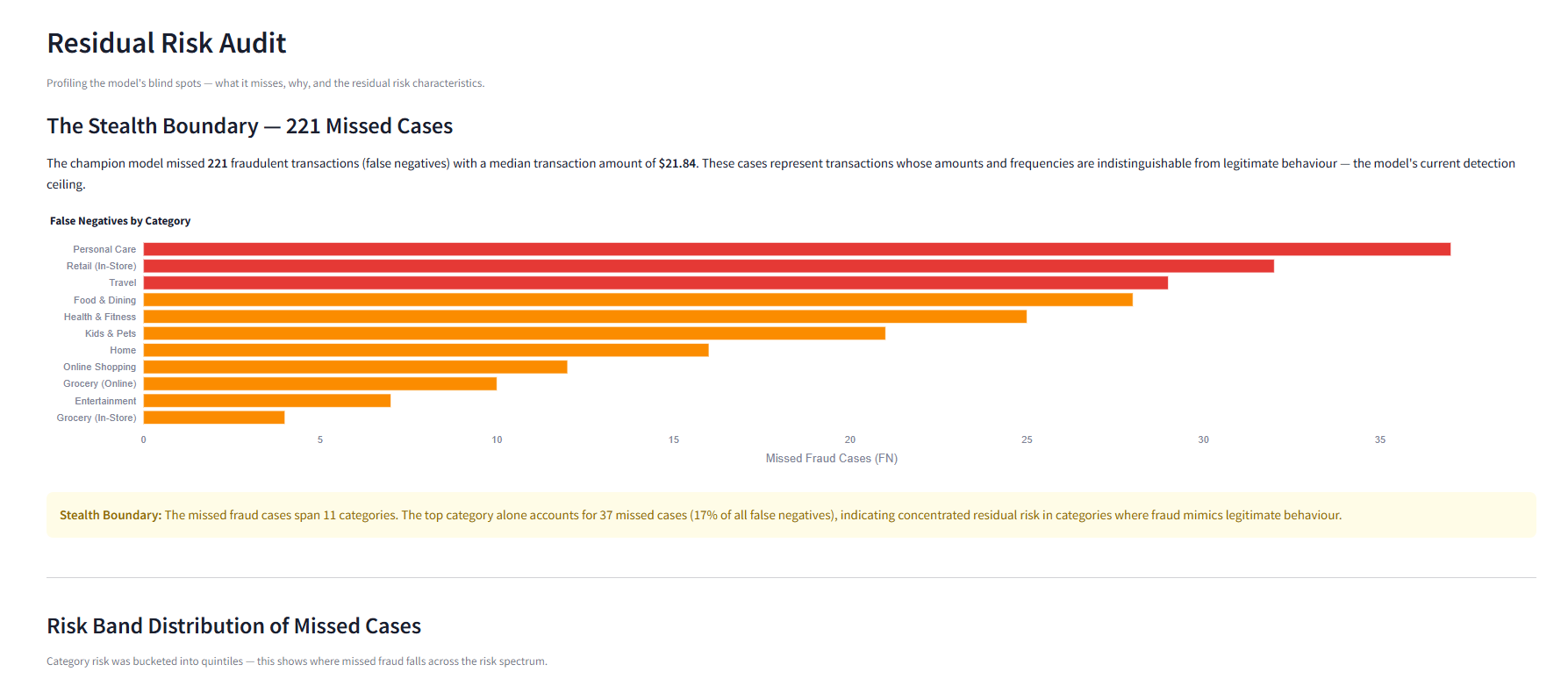
- **残余风险分析** —— 对 221 个漏判欺诈案例进行系统审计,揭示低金额下的“隐蔽边界”
- **预计算的仪表板数据** —— 仪表板从序列化的 JSON/CSV 即时加载,无运行时推理
## 数据集
- **名称:** [信用卡交易欺诈检测数据集](https://www.kaggle.com/datasets/kartik2112/fraud-detection) (Kartik2112)
- **生成器:** Sparkov (合成)
- **规模:** 约 130 万笔训练交易,约 55.6 万笔测试交易
- **欺诈率:** 0.58%(1:172 不平衡比例)
- **特征:** 包含交易金额、商家、类别、时间戳、持卡人人口统计和地理位置的命名字段
## 本地设置与复现
### 完整复现
```
git clone https://github.com/MachineheadLearning/fraud-forensics-pipeline.git
cd fraud-forensics-pipeline
pip install -r requirements.txt
```
从 [Kaggle 数据集页面](https://www.kaggle.com/datasets/kartik2112/fraud-detection) 下载 `fraudTrain.csv` 和 `fraudTest.csv`,并将它们放置在 `data/raw/` 目录下。然后端到端运行 `analysis.ipynb`——这将在 `models/` 中重新生成所有模型组件,并在 `dashboard_data/` 中重新生成仪表板数据。
## 方法论
### 特征工程
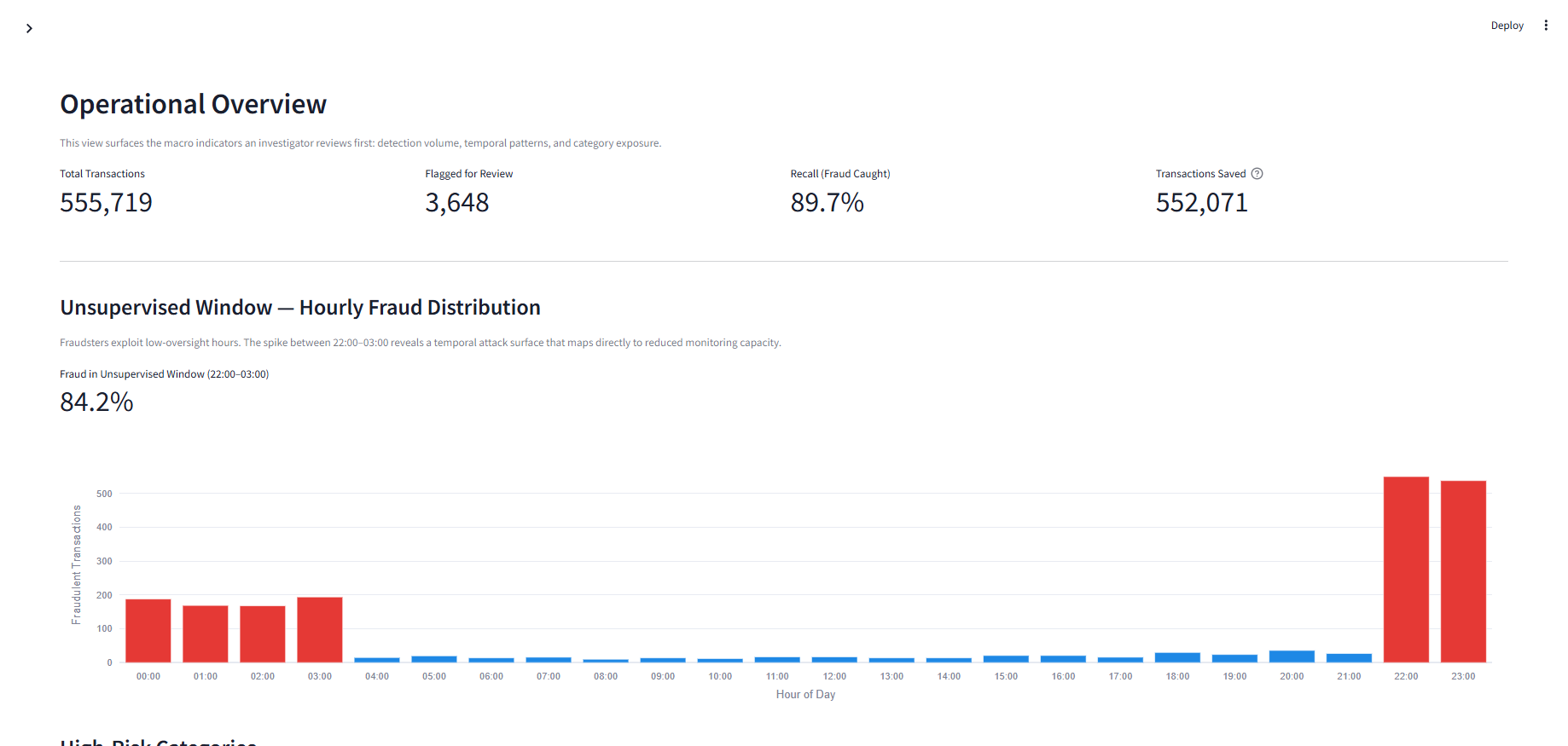
该 Pipeline 构建了 15 个行为特征,旨在捕捉调查员通常会寻找的信号。消费突增因子根据持卡人的扩展中位数衡量每笔交易的金额,从而相对于个人基线揭示异常消费。24 小时、7 天和 30 天时间范围的速率窗口跟踪交易频率,而速率爆发比率则捕捉相对于每月基线的短期加速——即那些代表测卡行为的快速连续活动。夜间窗口标记会记录 22:00 至 03:00 之间的交易,该数据集中 84% 的欺诈行为集中在此时段。类别偏移检测可在持卡人建立购买历史后识别首次使用的类别,从而标记行为模式的转变。所有持卡人级别的特征均遵循零泄漏协议:扩展窗口仅使用具有移位中位数的先前交易,滚动速率窗口使用 `closed='left'` 严格排除当前交易。
### 评估——为何召回率如此重要
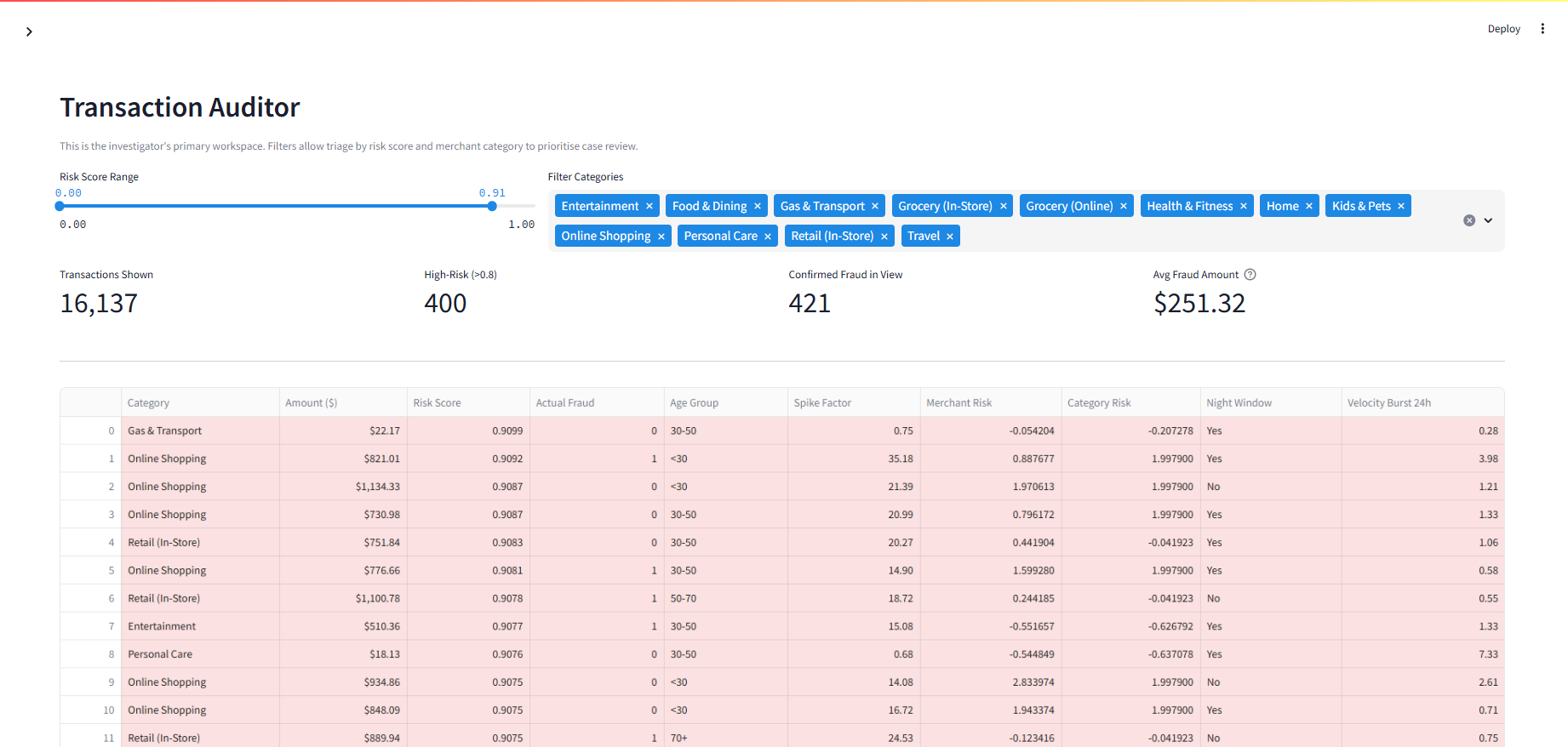
在欺诈检测中,漏掉一笔欺诈交易(假阴性)的代价远高于将正常交易误报(假阳性)。漏判的欺诈案件意味着经济损失和信任度下降;而假警报仅消耗分析师的时间。本项目使用召回率、精确率以及精确率-召回率曲线进行评估,而非准确率,因为在 0.58% 的欺诈率下,准确率会产生误导性的偏高结果。阈值分析展示了具体的权衡:将阈值从 t=0.50 降低到 t=0.40 会增加 768 个警报(+21%),但仅多捕获 1.8% 的欺诈行为。选定的操作点 (t=0.50) 能以 52.7% 的精确率捕获 89.7% 的欺诈——大约每 2 笔被标记的交易中就有 1 笔被确认为欺诈。
### 可解释性
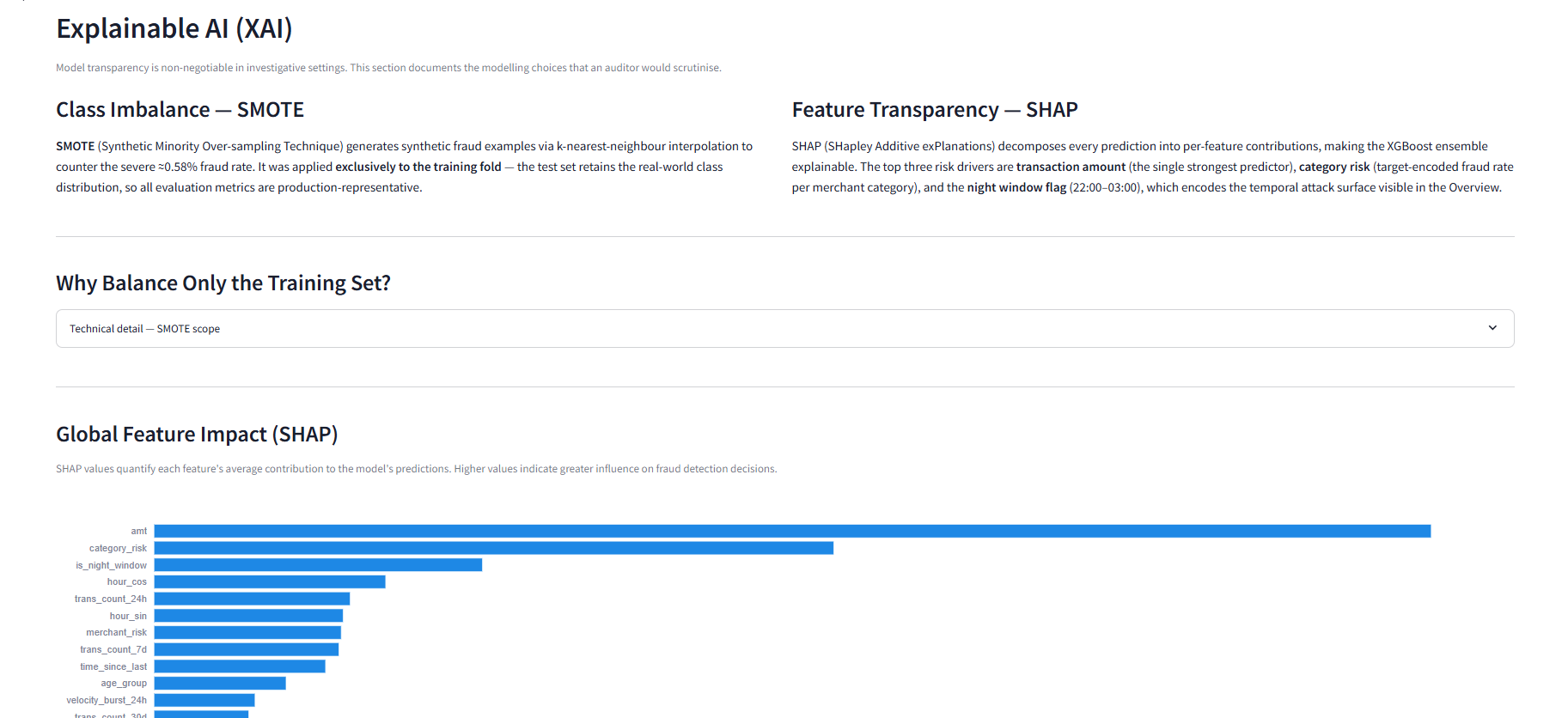
SHAP (SHapley Additive exPlanations) 提供了三个层面的模型透明度:全局特征重要性排名、通过蜂群图进行的方向性影响分析,以及单笔交易的瀑布图分解,准确展示特定交易被标记的原因。这满足了金融服务领域期望的“解释权”框架——每个警报都可以附带一份其风险驱动因素的人类可读分解说明。
## 项目结构
```
fraud-forensics-pipeline/
├── README.md
├── requirements.txt
├── .gitignore
├── data/
│ └── raw/ # fraudTrain.csv, fraudTest.csv (gitignored)
├── dashboard_data/
│ ├── dashboard_stats.json # Pre-computed KPIs, chart data, model metrics
│ └── investigative_results.csv # Filtered transactions with risk scores
├── notebooks/
│ ├── analysis.ipynb # Full pipeline: EDA → features → model → export
│ └── geospatial_neutrality_report.ipynb
├── app/
│ └── dashboard.py # Streamlit dashboard (4 views)
├── models/ # champion_model.joblib, scaler.joblib (gitignored)
└── screenshots/ # Dashboard screenshots for README
```
## 局限性与未来方向
### 局限性
该数据集是合成的(由 Sparkov 生成),因此其模式比真实的对抗性欺诈更具确定性——在此训练的模型不应用于指导真实的欺诈决策。该模型的主要盲区是低金额伪装欺诈(漏判案例的中位数为 $21.84),这类欺诈混入正常消费模式中,成功避开了所有风险区间的检测。行为特征需要交易历史记录,这导致没有既定基线的新账户存在冷启动脆弱性。该 Pipeline 是面向批处理的,不具备实时评分功能,并且使用单一模型架构,没有集成堆叠或基于图的方法。
### 未来方向
图链接分析可以通过识别共享的设备指纹、资金来源或商户集群来实现欺诈团伙检测。主动学习反馈循环——即调查员对标记交易的判定结果用于重新训练模型——将在连续的部署周期中收紧精确率与召回率的权衡。时间漂移监控将在欺诈策略演变时检测概念漂移,并在模型性能下降影响到警报队列之前触发重新训练。
## 作者
**Miguel Buitrago** — [LinkedIn](https://www.linkedin.com/in/miguel-buitrago-ortiz-62774b270)
作为一个作品集项目构建,展示了从数据探索、模型训练到面向调查员的仪表板工具的端到端工作流。Claude Code 被用作开发加速器。
标签:Apex, Kubernetes, NoSQL, Plotly, Python, SHAP, SMOTE, Streamlit, XGBoost, 不平衡数据处理, 事务审计, 交互式仪表盘, 代码示例, 分类模型, 反欺诈, 可解释性, 异常检测, 投资组合项目, 数据分析, 数据科学, 无后门, 机器学习, 欺诈检测, 特征工程, 端到端, 网络安全, 行为特征, 访问控制, 资源验证, 逆向工具, 金融科技, 隐私保护