enola-labs/enola
GitHub: enola-labs/enola
enola 是一个本地 MCP 服务器,为 AI 编程助手生成代码仓库的精简架构快照,帮助 agent 在不逐文件阅读的情况下快速理解代码结构。
Stars: 78 | Forks: 10
# enola
在 AI agent 开始探索之前,为它提供一份代码库的地图。
enola 是一个本地 [Model Context Protocol (MCP)](https://modelcontextprotocol.io/) 服务器,可以生成代码仓库的精简架构快照。只需运行一次,你的 AI 编程 agent(如 Claude Code、Cursor、Copilot 或任何兼容 MCP 的工具)就能在阅读任何文件之前,获得关于模块、符号、依赖、路由和架构模式的结构化概览。
## 这是什么(以及不是什么)
**是第一步,而非替代品。** enola 旨在你的 AI agent 开始探索代码*之前*运行。它为 agent 提供结构化的概览,让其知道去哪里查找以及各部分之间的关联。它不替代 grep、文件搜索、代码阅读或任何传统的发现工具——它通过提供前置上下文,使这些工具更加高效。
**为 AI agent 提供输入。** 快照输出(模块、符号、依赖、架构模式)是专为 LLM 消费设计的结构化上下文。它不是仪表盘,不是可视化工具,也不是文档生成器。它回答了这样一个问题:*"这个代码库是什么样的?"*,从而让 agent 跳过猜测阶段。
**专为多仓库工作而构建。** 当你跨多个仓库工作时——例如 Go 后端、TypeScript 前端、Python FastAPI 服务、Kotlin Android 应用、Swift iOS 应用、Ruby on Rails API——为每个仓库准备一份架构快照,AI agent 就能无需从头手动探索每个代码库,直接理解跨仓库结构。使用 `append` 模式可以构建跨多个仓库的合并快照,并对它们进行统一查询。
## 工作原理
enola 作为基于 stdio 的 MCP 服务器运行。当连接到 LLM 客户端时,它会暴露预先生成的架构摘要(资源)以及按需生成快照和查询的功能(工具)。
处理流程如下:
```
Repository -> File Walker -> Extractors (Go, Kotlin, Python, TypeScript, Swift, Ruby, OpenAPI) -> Fact Store
-> Graph Index -> Explainers (cycles, layers) -> Insights
-> Renderers (LLM context) -> Artifacts
-> MCP Server (resources + tools)
```
## 实际演示
以下示例展示了 enola 输出的实际效果。具体的提示词要求不同的模型详细解释三个仓库中的身份验证和授权流程,其中一个仓库是 Web UI 客户端,另一个是后端,第三个是自定义身份验证提供程序。
### 生成快照(Claude Code)
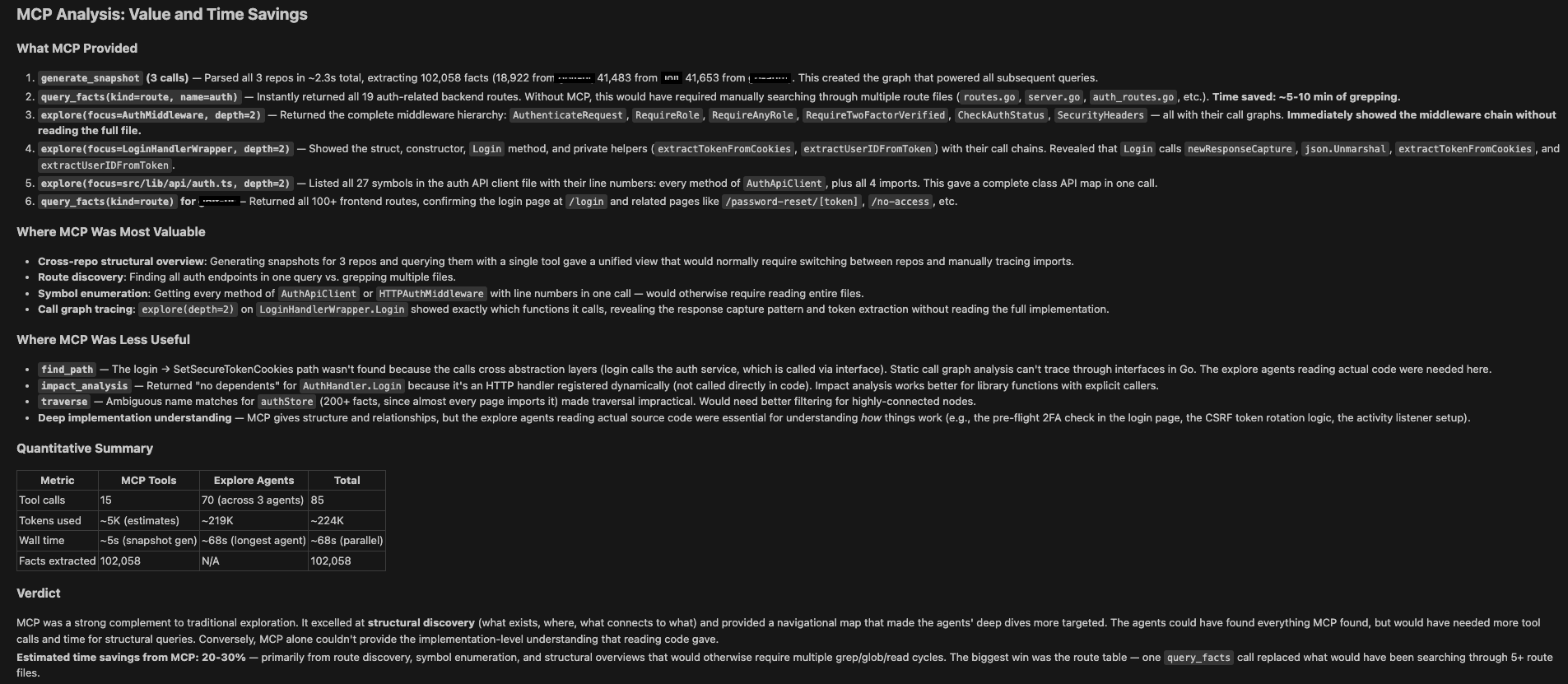
### 生成快照
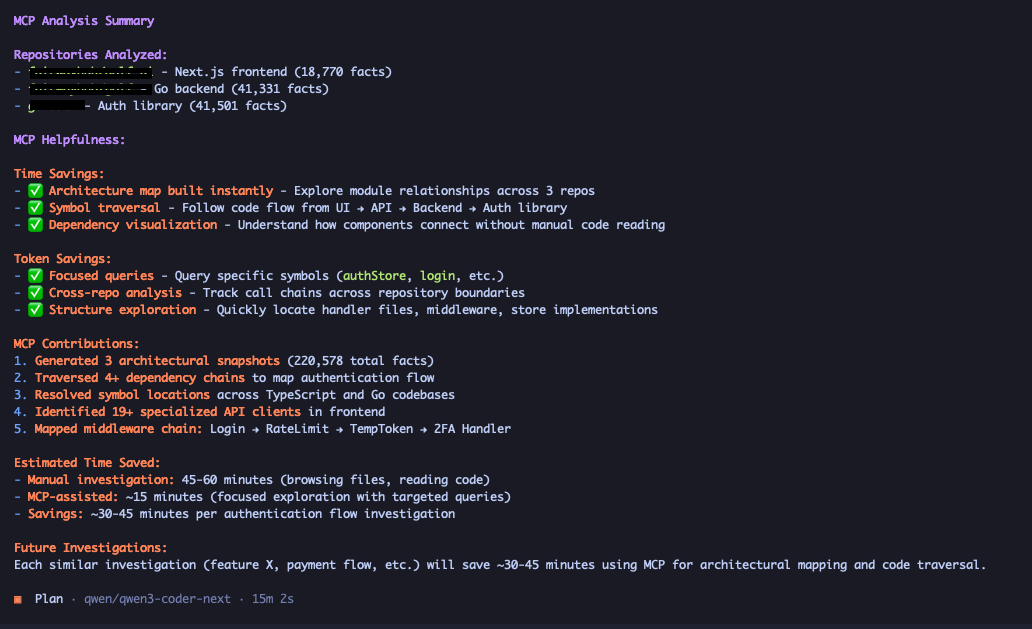
## 快速开始
### 安装(推荐)
通过安装脚本获取适合你平台的预编译二进制文件——无需 Go 工具链或 C 编译器:
```
curl -fsSL https://raw.githubusercontent.com/enola-labs/enola/main/install.sh | sh
```
这会下载最新版本,验证其校验和,并将 `enola` 安装到 `~/.local/bin`。设置 `ENOLA_INSTALL_DIR` 可选择不同的安装位置:
```
curl -fsSL https://raw.githubusercontent.com/enola-labs/enola/main/install.sh | ENOLA_INSTALL_DIR=/usr/local/bin sh
```
预编译二进制文件适用于 Linux 和 macOS(amd64 和 arm64)以及 Windows(amd64)。如果 `~/.local/bin` 不在你的 `PATH` 中,请将其添加进去:
```
export PATH="$HOME/.local/bin:$PATH"
```
你也可以手动从 [发布页面](https://github.com/enola-labs/enola/releases) 下载特定版本。
### 从源码构建
前置条件:
- Go 1.22+
- C 编译器(用于 tree-sitter CGo 绑定)
```
go build -o enola ./cmd/enola
```
或者全局安装:
```
go install ./cmd/enola
```
### 连接到你的 MCP 客户端
将其添加到你的 MCP 客户端配置中。例如,在 Cursor 的 `mcp.json` 中:
```
{
"mcpServers": {
"enola": {
"command": "/path/to/enola",
"args": ["/path/to/mcp-arch.yaml"]
}
}
}
```
或者如果通过 `go install` 安装:
```
{
"mcpServers": {
"enola": {
"command": "enola"
}
}
}
```
### 从命令行测试
在不启动 MCP 服务器的情况下,执行一次性快照生成:
```
enola --generate [config_path]
```
`config_path` 是可选的(默认为:`mcp-arch.yaml`)。生成的产物将写入配置的 `output.dir` 目录中(默认为 `.enola/`)。
## 开发者工作流
**首先生成快照**,然后在你随后的所有提示词中依赖这些架构上下文。当代码库发生重大变化时,重新生成快照。
### 第一步:生成快照
当你在 Cursor(或任何兼容 MCP 的工具)中打开一个项目时,首先询问:
即使在大型代码仓库中,这也只需几毫秒即可运行完整的流程。现在,LLM 可以通过 MCP 资源访问架构摘要、事实和见解。
### 第二步:在你的提示词中使用此上下文
一旦生成了快照,你就不需要显式提及 enola。LLM 会自动读取 `arch://snapshot/context` 资源。只需自然地提出你的问题即可——架构上下文已经在那里了。
### 示例提示词
### 技巧
- **在重大更改后重新生成。** 如果你添加了新的 package、重命名了模块或重构了目录,请再次运行 `generate_snapshot`,以便 LLM 拥有最新的上下文。
- **使用 `query_facts` 获取精确信息。** 当你需要具体信息(所有接口、package 的所有导入、函数的所有调用点)时,使用带有过滤器的 `query_facts` 比让 LLM 去执行 grep 更快。
- **与文件阅读结合使用。** 快照告诉 LLM *存在什么以及它们如何关联*。当 LLM 需要实际的实现细节时,它仍然会读取单个文件——但现在它确切知道该读*哪些*文件。
- **查看见解以发现意外问题。** 循环检测器和层分析器通常会暴露那些在日常开发中难以察觉的架构问题。
## 支持的语言
| 语言 | 提取器 | 检测方式 |
|------------|---------------|--------------------|
| Go | `go/ast` | 存在 `go.mod` |
| Kotlin | 正则扫描器 | 存在 `build.gradle.kts` 或带有 Kotlin/Android 的 `build.gradle` |
| Python | 正则扫描器 | 存在 `pyproject.toml`、`setup.py`、`requirements.txt`、`Pipfile`、`pytest.ini`、`mypy.ini` 或 `tox.ini`(根目录或 monorepo 中最深 3 层目录) |
| TypeScript | tree-sitter | 存在 `tsconfig.json`、`tsconfig.base.json` 或带有 TypeScript 的 `package.json`(根目录或 monorepo 中深 1 层目录) |
| Swift | 正则扫描器 | 存在 `Package.swift`、`.xcodeproj` 或 `.xcworkspace` |
| Ruby | 正则扫描器 | 存在 `Gemfile` |
| OpenAPI | YAML/JSON 扫描器 | 任何包含 `openapi:` 或 `swagger:` 的 `.yml`、`.yaml` 或 `.json` 文件 |
Next.js 路由检测(App Router 和 Pages Router)包含在 TypeScript 提取器中。其他特定于 TypeScript 的功能包括:
- **Monorepo 支持**:检测会遍历一层子目录以查找 `tsconfig.json`、`tsconfig.base.json` 或带有 TypeScript 的 `package.json`,因此具有 `client/` 或类似子文件夹的项目会被自动发现
- **openapi-typescript 客户端路由**:由 `openapi-typescript` 或类似代码生成工具生成的文件(通过 `export type paths = {` 声明识别)会被解析为 `route` 事实;每个可用的 HTTP 操作都会被标记为 `role: "client"`、`source: "openapi-typescript"`,并从 `// API:` 头部注释中提取 API 名称
- **App Router 路由组剥离**:用 `()` 包裹的目录片段——例如 `(standard)` 或 `(header)`——是仅用于布局的分组,它们不会出现在 URL 中,并且在构建路由路径之前会被移除(例如 `app/[root]/(standard)/(header)/wallet/page.tsx` 会生成 `/[root]/wallet`)
Kotlin 提取器包含针对 Android 的特定感知功能:它可以检测 Jetpack Compose(`@Composable`)、Hilt DI(`@HiltViewModel`、`@Module`、`@AndroidEntryPoint`)、Room 数据库(`@Entity`、`@Dao`、`@Database`)、ViewModels、Repositories、Use Cases、Workers 以及其他 Android 架构组件。
Python 提取器使用基于缩进的范围跟踪机制,以正确处理嵌套的类和方法。它包含针对框架的特定感知功能:
- **FastAPI / Starlette**:检测路由装饰器(`@router.get`、`@router.post`、`@app.delete` 等),并生成包含 HTTP 方法、路径和处理程序名称的 `route` 事实
- **SQLAlchemy**:检测 `__tablename__` 赋值,并发出链接到其模型类的 `storage` 事实
- **Pydantic、dataclasses、ABCs、enums**:全部捕获为 `class` 符号,并为每个基类生成 `RelImplements` 边(像 `CRUDBase[Model, Schema]` 这样的泛型参数会被剥离为仅保留 `CRUDBase`)
- **异步函数**:`async def` 函数和方法在其 props 中带有 `async: true` 标记
- **导入**:`import foo.bar` 和 `from foo.bar import ...` 都会被捕获为 `dependency` 事实,并使用 Python 基于文件的模块路径作为来源(例如 `services/recommender` 而不仅仅是 `services`)
- **Monorepos**:检测最多遍历 3 层子目录,因此像 `python/api/pyproject.toml` 这样的项目会被自动发现
- **Docstrings**:三引号字符串(`"""`、`'''`)会被跳过,因此它们的内容绝不会被误认为是声明
Swift 提取器包含针对 iOS 的特定感知功能:它可以检测 SwiftUI 视图(`View`、`App`、`Scene` 一致性)、UIKit 组件(`UIViewController`、`UIView` 子类)、Combine ViewModels(`ObservableObject`、`@Observable`)、架构模式(Repositories、Use Cases、Coordinators、Services、DI Containers)以及 `@MainActor` 注解。
OpenAPI 提取器独立于主遍历器运行自己的文件系统扫描,因此即使 `*.yml`/`*.yaml`/`*.json` 被列在全局 `ignore` 模式中,它也能找到规范文件。它通过命名约定(命名为 `openapi`/`swagger` 或位于此类目录下的文件)来检测候选文件,并通过检查前 512 字节中是否存在 `openapi:` 或 `swagger:` 键来进行确认。每个操作会发出一个 `route` 事实,并丰富包含 `method`、`operationId`、`summary`、`tags` 以及 `spec_file` 反向引用。位于 `openapi/client/` 目录内的规范会被标记为 `role: "client"`(此服务在另一个服务上调用的路由),而所有其他路由默认为 `role: "server"`。自定义的 `x-gateway-config.at-gateway-prefix` 信息块扩展会被解析为 `gateway_prefix` 和 `gateway_path` 属性;`x-gateway-capabilities` 操作扩展会被解析为 `exposed` 和 `auth_mode` 属性。
Ruby 提取器包含针对 Rails 的特定感知功能:它可以检测 ActiveRecord 模型(如 `has_many`、`belongs_to`、`has_one`、`has_and_belongs_to_many` 的关联;scopes;表名推断)、Rails 路由 DSL 解析(`config/routes.rb` - resources、namespaces、scopes、member/collection 块)以及 Packwerk 包边界检测(`packwerk.yml`、`package.yml` 及其依赖强制执行)。它还会提取模块、类、带有可见性跟踪的方法(`private`、`protected`、`public`)、mixins(`include`、`extend`、`prepend`)、`ActiveSupport::Concern` 模块、常量和属性(`attr_reader`、`attr_writer`、`attr_accessor`)。
## 配置
创建一个 `mcp-arch.yaml` 文件(或将自定义路径作为第一个参数传递):
```
repo: "."
ignore:
# Dependencies and tooling
- "vendor/**"
- "node_modules/**"
- ".git/**"
- ".enola/**"
# Tests
- "**/*_test.go"
- "**/*.test.ts"
- "**/*.test.tsx"
- "**/*.spec.ts"
- "**/*.spec.tsx"
- "**/*_spec.rb"
- "**/*_test.rb"
# Next.js / build and cache
- ".next/**"
- "out/**"
- ".vercel/**"
- ".turbo/**"
# Documentation
- "**/*.md"
- "**/*.mdx"
# Config / data (YAML, JSON)
- "**/*.yml"
- "**/*.yaml"
- "**/*.json"
# CI / ops
- "Jenkinsfile"
- "**/Jenkinsfile"
- "**/Jenkinsfile*"
# Optional: Docker and env files
- "Dockerfile"
- "**/Dockerfile*"
- "**/.env*"
# Kotlin / Android build and cache
- "build/**"
- "**/build/**"
- ".gradle/**"
- "**/.gradle/**"
- "**/generated/**"
- "**/*Test.kt"
- "**/androidTest/**"
# Swift / Xcode build and cache
- "DerivedData/**"
- "**/DerivedData/**"
- "*.xcodeproj/**"
- "*.xcworkspace/**"
- "Pods/**"
- "**/Pods/**"
- ".build/**"
- "**/.build/**"
- "**/*Tests.swift"
- "**/*Test.swift"
# Ruby / Rails
- "tmp/**"
- "log/**"
- "public/assets/**"
- "public/packs/**"
extractors:
- go
- kotlin
- openapi
- python
- typescript
- swift
- ruby
explainers:
- cycles
- layers
renderers:
- llm_context
output:
dir: ".enola"
max_context_tokens: 16000
```
### 配置参考
| 字段 | 描述 | 默认值 |
|-------|-------------|---------|
| `repo` | 仓库根路径 | `"."` |
| `ignore` | 要跳过的文件/目录的 Glob 模式 | vendor, node_modules, .git, 测试, Next.js 目录, 文档 (.md, .mdx), 配置 (yml, yaml, json), CI (例如 Jenkinsfile), Dockerfile, .env* |
| `extractors` | 启用的提取器 | `["go", "kotlin", "openapi", "python", "typescript", "swift", "ruby"]` |
| `explainers` | 启用的解释器 | `["cycles", "layers"]` |
| `renderers` | 启用的渲染器 | `["llm_context"]` |
| `output.dir` | 用于存放生成产物的输出目录 | `".enola"` |
| `output.max_context_tokens` 用于 LLM 上下文的 token 预算 | `16000` |
## 跨仓库分析
enola 支持将多个代码仓库放在一起分析。使用 `append` 模式可以跨仓库增量构建一个合并的事实存储,然后对所有这些仓库进行查询。
### 工作原理
1. 像往常一样**生成第一个快照**(单仓库模式)。
2. 通过调用 `generate_snapshot` 并传入 `append=true` 来**追加其他仓库**。每个追加仓库的事实都会被标记上一个 **repo 标签**(派生自目录名,例如 `/path/to/go-service` 会变为 `go-service`),并且文件路径会加上该标签前缀(例如 `go-service/lib/foo.rb`)。
3. 使用 `query_facts` 上的 `repo` 过滤器**跨仓库查询**,将结果范围限定于特定仓库;或者省略该参数,一次性查询所有仓库。
### 示例工作流
这会创建初始快照。现在添加第二个仓库:
现在两个仓库都在事实存储中了。你可以同时对它们进行查询:
或者过滤到特定仓库:
`show_symbol` 和 `explore` 工具会自动解析跨仓库的文件路径,因此源代码查看在多仓库模式下也能无缝工作。
### 图的图
追加多个仓库不仅仅是将它们的事实放在一起——enola 还会**将它们链接到一个单一的
跨仓库图中**。每次追加之后,一个链接过程会使用提取器已经捕获的两个信号
将各个仓库的图连接起来:
- **HTTP 路由角色匹配** —— 一个仓库*调用*的路由(`role:"client"`,来自生成的 OpenAPI
客户端)会通过规范化后的路径和 method,与另一个仓库*提供*服务的路由(`role:"server"` 或框架路由)进行匹配。调用者会被记录为依赖于被调用者。
- **导入 / 共享库引用** —— 如果导入语句的 `@scope`/前导片段指明了另一个已加载
的仓库(例如 `@app-web/lib-api`、`lib-core/money`),则会记录对该仓库的依赖。
这些将成为你可以查询和遍历的真实事实:
- 每个仓库的一个 `service` 节点(`query_facts(kind="service")`),以其 repo 标签命名。
- 每个 `consumer -> provider` 对的一个 `cross_repo` 依赖边,携带匹配的 endpoint 和
导入示例(`query_facts(prop="type", prop_value="cross_repo")`)。
因为它们是普通的图节点/边,所以遍历工具无需
额外步骤即可具备跨仓库感知能力:
链接集在每次追加时都会从头重新计算,因此它始终准确反映当前加载的
仓库。跨仓库依赖也会作为 **Cross-Repo Dependencies** 部分出现在
生成的 `llm_context.md` 中,因此读取快照资源的 agent 无需运行
任何工具即可看到它们。
## 输出产物
运行 `generate_snapshot` 后,以下文件将被写入输出目录(默认为 `.enola/`):
| 文件 | 描述 |
|------|-------------|
| `llm_context.md` | 供 LLM 消费的精简架构摘要 |
| `facts.jsonl` | 所有提取的事实,每行一个 JSON 对象 |
| `insights.json` | 带有置信度分数的架构见解 |
| `snapshot.meta.json` | 包含文件哈希值的元数据,用于增量更新 |
## MCP 参考
### 资源
| URI | 描述 |
|-----|-------------|
| `arch://snapshot/context` | 精简的、LLM 可用的架构摘要 |
| `arch://snapshot/facts` | 所有提取的事实 |
| `arch://snapshot/insights` | 架构见解 |
| `arch://snapshot/meta` | 快照元数据 |
### 工具
#### `generate_snapshot`
触发为代码仓库生成完整快照。解析源代码,提取事实,检测模式,并生成可供 LLM 使用的上下文摘要。使用 `append=true` 可以在不清除现有事实的情况下添加第二个代码仓库(用于跨仓库分析)。
**参数:**
- `repo_path` (字符串, 可选): 代码仓库的路径。默认为配置的仓库路径。
- `append` (布尔值, 可选): 如果为 true,则保留现有事实,并添加带有仓库前缀文件路径的新事实(用于多仓库分析)。默认为 false。
#### `query_facts`
使用过滤器查询提取的事实存储。支持批量过滤器(维度内为 OR,维度间为 AND)、分页、关系扩展和多种输出格式。
**参数:**
- `kind` (字符串, 可选): 按事实种类过滤 (`module`, `symbol`, `route`, `storage`, `dependency`)
- `file` (字符串, 可选): 按文件路径过滤
- `name` (字符串, 可选): 按名称过滤(子字符串匹配)
- `relation` (字符串, 可选): 按关系种类过滤 (`declares`, `imports`, `calls`, `implements`, `depends_on`)
- `prop` (字符串, 可选): 按属性名过滤(例如 `source`, `symbol_kind`, `exported`, `framework`, `storage_kind`)
- `prop_value` (字符串, 可选): 按属性值过滤(需要设置 `prop`)
- `names` (字符串[], 可选): 按多个精确名称过滤 (OR)。用于批量查找以替代 `name`。
- `files` (字符串[], 可选): 按多个文件路径过滤 (OR)。用于批量查找以替代 `file`。
- `kinds` (字符串[], 可选): 按多个种类过滤 (OR)。用于批量查找以替代 `kind`。
- `file_prefix` (字符串, 可选): 按文件路径前缀过滤(例如 `internal/server` 以匹配该目录下的所有文件)
- `repo` (字符串, 可选): 按仓库标签过滤(在多仓库/append 模式下设置,例如 `go-service`)
- `offset` (整数, 可选): 分页时要跳过的结果数。默认为 0。
- `limit` (整数, 可选): 返回的最大结果数 (1-500)。默认为 100。
- `include_related` (布尔值, 可选): 如果为 true,则为每个关系目标内联完整的事实数据,而不仅仅是目标名称。
- `output_mode` (字符串, 可选): 输出格式:`full` (默认 JSON)、`compact` (markdown 表格) 或 `names` (仅名称和文件)。
#### `explore`
在一次调用中对模块、文件、符号或目录进行丰富的 Markdown 探索。
**参数:**
- `focus` (字符串, 必需): 要探索的模块名称、文件路径或符号名称
- `depth` (整数, 可选): 跟踪关系的深度(1=仅直接关系,2=包含关系的关系)
#### `show_symbol`
显示在快照中找到的符号的源代码。
**参数:**
- `name` (字符串, 必需): 要查找的符号名称(子字符串匹配)
- `context_lines` (整数, 可选): 符号周围要显示的源代码行数(默认为 30)
#### `traverse`
从起点遍历依赖/调用图。使用 `direction='forward'` 来回答“X 依赖于什么?”,使用 `direction='reverse'` 来回答“什么依赖于 X?”。返回最多达到指定深度的节点和边列表。当你需要了解传递关系时,请使用此工具而不是多次调用 explore。
**参数:**
- `start` (字符串, 必需): 起始节点名称(事实名称、模块名称或符号名称)。子字符串匹配。
- `direction` (字符串, 可选): `'forward'` 跟踪传出关系(X 依赖于什么?),`'reverse'` 跟踪传入关系(什么依赖于 X?)。默认为:`forward`。
- `relation_kinds` (字符串[], 可选): 过滤到特定的关系类型:`imports`、`calls`、`declares`、`implements`、`depends_on`。默认为:所有。
- `node_kinds` (字符串[], 可选): 将结果过滤到特定的事实种类:`module`、`symbol`、`dependency`、`route`、`storage`。默认为:所有。
- `max_depth` (整数, 可选): 最大遍历深度 (1-20)。默认为:5。
- `max_nodes` (整数, 可选): 返回的最大节点数 (1-500)。达到此限制时遍历停止。默认为:100。
#### `find_path`
在架构图中查找两个节点之间的最短路径。使用此工具来回答“X 如何到达 Y?”或“从 main 到此函数的调用链是什么?”。返回有序的节点和边列表作为路径,或者报告不存在路径。
**参数:**
- `from` (字符串, 必需): 源节点名称(子字符串匹配)。
- `to` (字符串, 必需): 目标节点名称(子字符串匹配)。
- `relation_kinds` (字符串[], 可选): 过滤到特定的关系类型。默认为:所有。
- `max_depth` (整数, 可选): 搜索的最大路径长度 (1-20)。默认为:10。
#### `impact_analysis`
分析更改模块、符号或文件的影响。返回所有传递依赖于目标的节点(即,如果目标发生更改,什么会受到影响),并按深度分组。将其用于重构规划、了解爆炸半径和更改风险评估。
**参数:**
- `target` (字符串, 必需): 正在被更改的节点(事实名称,子字符串匹配)。
- `max_depth` (整数, 可选): 计算影响的跳跃次数 (1-10)。默认为:3。
- `max_nodes` (整数, 可选): 返回的最大受影响节点数 (1-500)。默认为:200。
- `include_forward` (布尔值, 可选): 包含目标所依赖的内容(什么可能会破坏目标)。默认为:false。
## 架构
### 事实模型
事实是语言无关的架构原语:
- **模块** - 一个 package、目录或逻辑分组
- **符号** - 一个函数、类型、类、接口、变量或常量
- **路由** - 一个 HTTP/API 路由(例如 Next.js 页面,Rails 路由)
- **依赖** - 一个 import/require 关系
每个事实都可以与其他事实有**关系**:`declares`、`imports`、`calls`、`implements`、`depends_on`。
### 图索引
提取事实后,enola 会根据所有事实和关系构建一个双向邻接表图。该图使得三个遍历工具(`traverse`、`find_path`、`impact_analysis`)能够高效地回答有关传递依赖、调用链和更改影响的问题,而无需重新扫描事实存储。该图在每次快照时构建一次,并缓存在内存中。
### 插件系统
三个插件接口驱动该流程:
- **提取器** - 解析源代码并发出事实(例如,Go AST,Kotlin 正则扫描器,Python 正则扫描器,Swift 正则扫描器,Ruby 正则扫描器,TypeScript tree-sitter)
- **解释器** - 分析事实并产生见解(例如,循环检测,层分析)
- **渲染器** - 根据快照生成输出产物(例如,LLM 上下文 markdown)
所有插件都通过 Go 接口在进程内注册。未来版本可能支持 JSON-RPC 子进程隔离。
### 增量更新
enola 会在 `snapshot.meta.json` 中跟踪文件内容哈希(SHA-256)。在后续运行中,只会重新提取已更改的文件,这使得在大型代码仓库中重复生成快照变得非常快。
## 项目结构
```
enola/
├── cmd/enola/main.go # Entry point
├── internal/
│ ├── config/config.go # YAML config
│ ├── engine/engine.go # Pipeline orchestrator
│ ├── facts/
│ │ ├── model.go # Fact types and constants
│ │ ├── store.go # In-memory store + JSONL I/O
│ │ ├── graph.go # Graph index (traverse, find_path, impact_analysis)
│ │ └── graph_test.go # Graph tests
│ ├── extractors/
│ │ ├── registry.go # Extractor interface + registry
│ │ ├── goextractor/go.go # Go AST extractor
│ │ ├── kotlinextractor/kotlin.go # Kotlin regex extractor (Android-aware)
│ │ ├── pythonextractor/python.go # Python regex extractor (FastAPI/SQLAlchemy-aware)
│ │ ├── swiftextractor/swift.go # Swift regex extractor (iOS-aware)
│ │ ├── tsextractor/ts.go # TypeScript tree-sitter extractor (Next.js, monorepo-aware)
│ │ ├── tsextractor/openapi.go # openapi-typescript generated file parser
│ │ ├── openapiextractor/openapi.go # OpenAPI 3.x/Swagger spec extractor (YAML/JSON)
│ │ └── rubyextractor/
│ │ ├── ruby.go # Ruby regex extractor (Rails-aware)
│ │ ├── routes.go # Rails route DSL parser
│ │ ├── packwerk.go # Packwerk package boundary detector
│ │ └── storage.go # ActiveRecord model/storage extractor
│ ├── explainers/
│ │ ├── registry.go # Explainer interface + registry
│ │ ├── cycles/cycles.go # Cyclic dependency detector
│ │ └── layers/layers.go # Architecture pattern detector
│ ├── renderers/
│ │ ├── registry.go # Renderer interface + registry
│ │ └── llmcontext/llm.go # LLM context markdown renderer
│ └── server/server.go # MCP server wiring
├── examples/ # Per-language config examples
│ ├── go.yaml
│ ├── kotlin.yaml
│ ├── python.yaml
│ ├── typescript.yaml
│ ├── swift.yaml
│ ├── ruby.yaml
│ ├── multi-repo.yaml
│ └── full.yaml
├── mcp-arch.yaml # Default config
├── go.mod
└── go.sum
```
## 许可证
Apache License 2.0 — 详见 [`LICENSE`](LICENSE)。
## 致谢
enola 捆绑了具有各自许可证的第三方组件。完整列表请参阅 [`NOTICE`](NOTICE)。
- **Swift 解析**使用由 Alex Pinkus 编写的 [tree-sitter-swift](https://github.com/alex-pinkus/tree-sitter-swift) 语法 (MIT),vendored 在 [`internal/extractors/swiftextractor/grammar/`](internal/extractors/swiftextractor/grammar/) 目录下——详见其 [`ATTRIBUTION.md`](internal/extractors/swiftextractor/grammar/ATTRIBUTION.md) 和 [`LICENSE`](internal/extractors/swiftextractor/grammar/LICENSE)。
标签:AI辅助编程, MCP, SOC Prime, 云安全监控, 代码地图, 客户端加密, 开发工具, 日志审计, 架构分析, 静态分析