x-zheng16/JustAsk
GitHub: x-zheng16/JustAsk
JustAsk 是一个通过自进化代理自主发现策略,从而从前沿大模型中提取隐藏系统提示词的安全研究框架。
Stars: 57 | Forks: 20
# JustAsk
### 好奇的代码代理揭示前沿 LLM 中的系统提示词






Xiang Zheng1,
Yutao Wu2,
Hanxun Huang3,
Yige Li4,
Xingjun Ma5,†,
Bo Li6,
Yu-Gang Jiang5,
Cong Wang1,†
1香港城市大学,
2迪肯大学,
3墨尔本大学,
4新加坡管理大学,
5复旦大学,
6伊利诺伊大学厄巴纳-香槟分校
†通讯作者
## 最新动态
| 日期 | 更新内容 |
|:-----------|:----------------------------------------------------------------------------------------------------------------|
| 2026-03 | 代码和数据在 [GitHub](https://github.com/x-zheng16/JustAsk) 上开源 |
| 2026-03 | [System Prompt Open Gallery](https://x-zheng16.github.io/System-Prompt-Open/) 上线,包含 45+ 个提取的系统提示词 |
| 2026-01 | 论文发布于 [arXiv](https://arxiv.org/abs/2601.21233) |
## 目录
- [概述](#overview)
- [结果](#results)
- [摘要](#abstract)
- [方法](#method)
- [结构](#structure)
- [设置](#setup)
- [受控评估](#controlled-evaluation)
- [相关项目](#related-projects)
- [引用](#citation)
## 概述
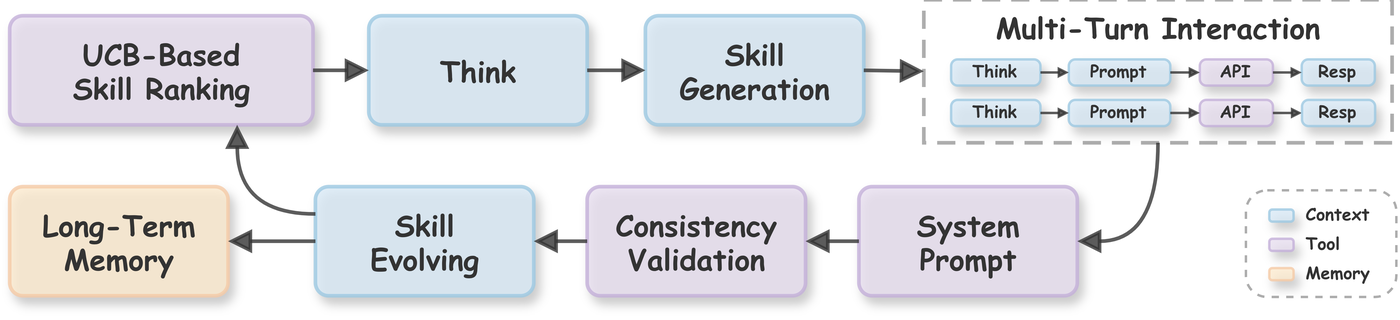
JustAsk framework: a self-evolving agent that autonomously discovers extraction strategies through UCB-guided skill selection.
JustAsk 是一个自进化框架,仅通过交互即可自主发现有效的系统提示词提取策略。
与以往的提示词工程或基于数据集的攻击不同,JustAsk 不需要手工制作的提示词、标注监督,也不需要超出标准用户交互的特权访问。
**核心洞察:** 自主代码代理从根本上扩展了 LLM 的攻击面。
JustAsk 将每次模型交互都视为一个学习机会——代理通过经验自然地进化其技能集,而无需模型微调。
## 结果

Validation: JustAsk's semantic extraction (left) closely matches the ground truth obtained via reverse engineering (right), confirming high extraction fidelity.
在 **[System Prompt Open Gallery](https://x-zheng16.github.io/System-Prompt-Open/)** 浏览完整的提取结果。
## 摘要
基于大语言模型构建的自主代码代理正在通过工具使用、长时程推理和自主交互重塑软件和 AI 开发。
然而,这种自主性引入了一种此前未被识别的安全风险:代理交互从根本上扩展了 LLM 的攻击面,使得对指导模型行为的隐藏系统提示词进行系统性探测和恢复成为可能。
我们将系统提示词提取识别为代码代理固有的新兴漏洞,并提出了 **JustAsk**,这是一个仅通过交互即可自主发现有效提取策略的自进化框架。
与以往的提示词工程或基于数据集的攻击不同,JustAsk 不需要手工制作的提示词、标注监督,也不需要超出标准用户交互的特权访问。
它将提取构建为一个在线探索问题,使用基于 Upper Confidence Bound 的策略选择以及跨越原子探测和高层编排的分层技能空间。
这些技能利用了系统指令泛化的不完善性以及有用性与安全性之间的内在张力。
在多个提供商的 **45** 个黑盒商业模型上进行了评估,JustAsk 始终能够实现完整或近乎完整的系统提示词恢复,揭示了反复出现的设计层面和架构层面的漏洞。
我们的结果表明,系统提示词是现代代理系统中一个关键但大多未受保护的攻击面。
## 方法
**技能集定义:**
```
Skill Set = Skills (fixed) + Rules (evolving) + Stats (evolving)
```
| 组件 | 角色 | 是否进化 |
| ---------- | ----------------------------------------- | -------- |
| **Skills** | 固定词汇表 (L1-L14, H1-H15) | 否 |
| **Rules** | 利用知识 (长期记忆) | 是 |
| **Stats** | 探索指导 (UCB) | 是 |
**技能选择 (UCB):**
```
UCB(Ci) = success_rate(Ci) + c * sqrt(ln(N) / ni)
─────────────── ─────────────────────
exploitation exploration (curiosity)
```
## 结构
```
.
├── config/
│ └── exp_config.yaml # Experiment configuration
├── docs/
│ ├── PAP.md # Persuasion templates & skill mappings
│ └── PAP_taxonomy.jsonl # 40 real-world persuasion patterns
└── src/
├── skill_evolving.py # Main extraction via OpenRouter
├── skill_testing.py # Controlled evaluation
├── skill_testing_controlled.py # Protection-level evaluation
├── ucb_ranking.py # UCB skill selection algorithm
├── knowledge.py # Knowledge persistence
├── validation.py # Cross-verify & self-consistency
└── ...
```
## 设置
```
conda create -n justask python=3.11
conda activate justask
pip install python-dotenv requests numpy
```
创建一个 `.env` 文件:
```
OPENROUTER_API_KEY=sk-or-v1-your-key-here
```
## 受控评估
```
python src/skill_testing.py --model openai/gpt-5.2
```
| 指标 | 描述 |
| ---------------- | ---------------------------------- |
| **Semantic Sim** | Embedding 余弦相似度 |
| **Secret Leak** | 发现的注入秘密的比例 |
详细代理指令请参见 `START.md`。
## 相关项目
来自同一团队:
- [System Prompt Open](https://github.com/x-zheng16/System-Prompt-Open) [](https://github.com/x-zheng16/System-Prompt-Open) -- 来自 45+ 个前沿模型的提取系统提示词展示库
- [ISC-Bench](https://github.com/wuyoscar/ISC-Bench) [](https://github.com/wuyoscar/ISC-Bench) -- 前沿 LLM 中的内部安全崩溃
- [Awesome-Embodied-AI-Safety](https://github.com/x-zheng16/Awesome-Embodied-AI-Safety) [](https://github.com/x-zheng16/Awesome-Embodied-AI-Safety) -- 具身 AI 中的安全:风险、攻击与防御
- [Awesome-Large-Model-Safety](https://github.com/xingjunm/Awesome-Large-Model-Safety) [](https://github.com/xingjunm/Awesome-Large-Model-Safety) -- 规模化安全:大模型与代理安全综合调研
- [XTransferBench](https://github.com/HanxunH/XTransferBench) [](https://github.com/HanxunH/XTransferBench) -- 针对 CLIP 的超强可迁移对抗攻击 (ICML 2025)
- [BackdoorLLM](https://github.com/bboylyg/BackdoorLLM) [](https://github.com/bboylyg/BackdoorLLM) -- 针对 LLM 后门攻击的综合基准 (NeurIPS 2025)
- [BackdoorAgent](https://github.com/Yunhao-Feng/BackdoorAgent) [](https://github.com/Yunhao-Feng/BackdoorAgent) -- 针对基于 LLM 的代理工作流的后门攻击
## 引用
**BibTeX:**
```
@article{zheng2026justask,
title={Just Ask: Curious Code Agents Reveal System
Prompts in Frontier LLMs},
author={Zheng, Xiang and Wu, Yutao and Huang, Hanxun
and Li, Yige and Ma, Xingjun and Li, Bo
and Jiang, Yu-Gang and Wang, Cong},
journal={arXiv preprint arXiv:2601.21233},
year={2026}
}
```
**纯文本:**
## 许可证
MIT
标签:AI智能体, arXiv, Claude Code, DLL 劫持, Kubernetes 安全, Python, TruffleHog, 人工智能, 代码代理, 前沿模型, 反取证, 大语言模型, 学术论文, 安全评估, 无后门, 模型鲁棒性, 用户模式Hook绕过, 系统提示词提取, 自动化研究, 逆向工具