L-Defraiteur/lucivy
GitHub: L-Defraiteur/lucivy
基于后缀 FST 的 BM25 全文搜索引擎,支持跨 token 边界的子串、模糊和正则搜索,专为代码搜索和向量数据库混合检索场景设计。
Stars: 43 | Forks: 3
# lucivy v2
[](https://pypi.org/project/lucivy/)
[](https://www.npmjs.com/package/lucivy)
[](https://www.npmjs.com/package/lucivy-wasm)
[](https://crates.io/crates/lucivy-core)
[](https://github.com/L-Defraiteur/lucivy/actions/workflows/ci.yml)
[](LICENSE)
具有子串匹配、模糊搜索和正则表达式功能的 BM25 全文搜索引擎——全部支持跨 token 感知。
专为代码搜索、技术文档设计,并作为向量数据库的 BM25 补充。
### v2 新特性
- **纯 SFX 引擎** —— 所有查询均通过后缀 FST 路由,无遗留代码路径
- **5 种绑定** —— Python, Node.js, C++, WASM (emscripten), Rust
- **分布式搜索** —— `export_stats` / `merge_stats` / `search_with_global_stats`
- **增量同步** —— LUCIDS 分片增量导出/应用
- **正确的跨分片 BM25** —— 无论使用 1 个分片还是 4 个分片,得分完全相同 (diff=0.0000)
- **0 个 clippy 警告** —— 使用 `-D warnings` 通过 CI 检查
[**试试实时演练场**](https://l-defraiteur.github.io/lucivy/) —— 通过 WASM 完全在你的浏览器中运行。
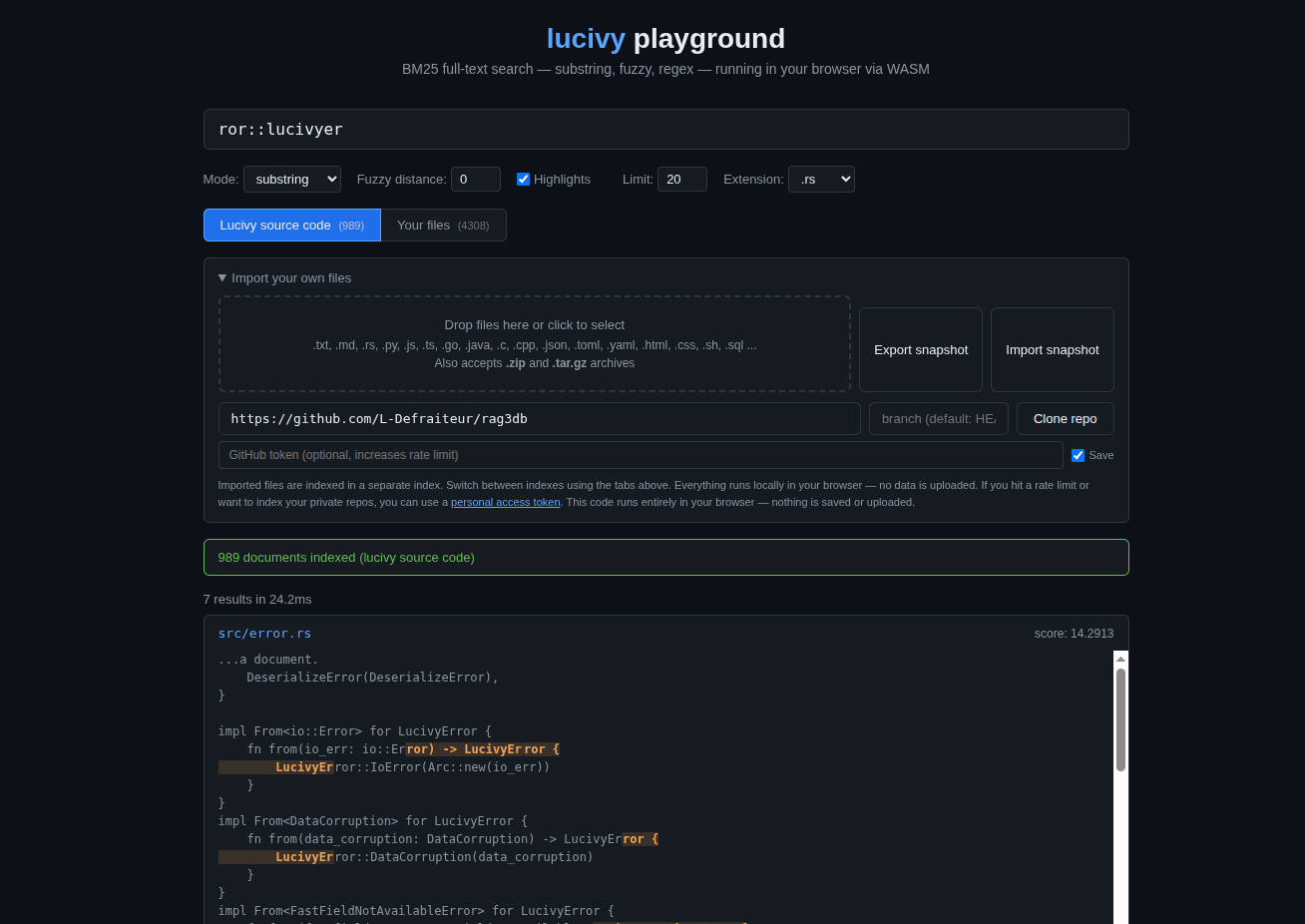
## lucivy 的与众不同之处
大多数搜索引擎匹配的是**整个 token**。搜索 "mutex" 会找到单词 "mutex" —— 但找不到 "getMutexHandle" 或 "lockmutex",因为分词器将它们视为单个不透明的 token。lucivy 匹配的是 **token 内部的子串**:"mutex" 能找到每一次出现的位置,甚至隐藏在复合词、驼峰命名标识符或拼接字符串中。
这之所以有效,是因为 lucivy 在索引时构建了一个 **后缀 FST** (.sfx)。每个 token 的每一个后缀都会被索引,并按位置进行分区(SI=0 = token 起始,SI>0 = 子串)。这使得子串搜索与精确匹配搜索一样精确,并支持 BM25 评分。
### 跨 token 匹配
分词器在单词边界处分割文本。"rag3weaver" 会变成 ["rag3", "weaver"]。传统的搜索无法找到原始的复合词 —— 而 lucivy 可以。SFX 引擎沿着跨 token 边界的**兄弟链接**来重构跨越多个 token 的匹配。
### 带有三元组鸽巢原理的模糊搜索
模糊搜索(Levenshtein 距离)使用了一种**三元组鸽巢**策略:在距离 d 处,查询中至少有一个三元组必须完全出现。lucivy 通过 SFX 找到该三元组,然后验证完整的匹配。这避免了扫描整个索引 —— 只评估至少包含一个精确三元组的候选项。
### 带字面量提取的正则表达式
正则表达式查询通过从模式中提取**字面量部分**来进行优化。"log_[a-z]+_error" 包含字面量 "log_" 和 "_error"。lucivy 首先通过 SFX 搜索这些字面量,然后仅对候选项验证完整的正则表达式。无需全索引扫描。
### BM25 评分 —— 跨分片准确无误
lucivy 使用标准的 BM25 评分。在分片模式下,全局统计信息(文档频率、总文档数、总 token 数)在评分前进行聚合,因此无论你使用 1 个分片还是 4 个分片,结果都是**完全一致**的。没有近似值。
## 安装
所有内容均为 **MIT 许可证**。
| 语言 | 安装 | 包 |
|----------|---------|---------|
| Python | `pip install lucivy` | [PyPI](https://pypi.org/project/lucivy/) |
| Node.js | `npm install lucivy` | [npm](https://www.npmjs.com/package/lucivy) |
| WASM (浏览器) | `npm install lucivy-wasm` | [npm](https://www.npmjs.com/package/lucivy-wasm) |
| Rust | `cargo add lucivy-core` | [crates.io](https://crates.io/crates/lucivy-core) |
| C++ | 通过 CXX 桥接的静态库(从源代码构建) |
## 快速开始
### Python
```
import lucivy
# 创建索引
index = lucivy.Index.create("/tmp/my_index", fields=[
{"name": "body", "type": "text", "stored": True}
])
# 添加文档
index.add(1, body="The pthread_mutex_lock function acquires a mutex")
index.add(2, body="Use std::lock_guard for RAII mutex management")
index.commit()
# 子字符串搜索 — 在 "pthread_mutex_lock" 中查找 "mutex"
results = index.search({"type": "contains", "field": "body", "value": "mutex"})
# 模糊搜索 — 即使存在拼写错误 ("mutx") 也能找到 "mutex"
results = index.search({"type": "contains", "field": "body", "value": "mutx", "distance": 1})
# 正则表达式 — 查找 "lock" 后跟任意字符再接 "mutex"
results = index.search({"type": "contains", "field": "body", "value": "lock.*mutex", "regex": True})
# 前缀 / startsWith — 查找以 "pthread" 开头的 token
results = index.search({"type": "contains", "field": "body", "value": "pthread", "anchor_start": True})
```
### Node.js
```
const { Index } = require('lucivy');
const index = Index.create('/tmp/my_index', [
{ name: 'body', type: 'text', stored: true }
]);
index.add(1, { body: 'The pthread_mutex_lock function acquires a mutex' });
index.commit();
const results = index.search({ type: 'contains', field: 'body', value: 'mutex' });
```
### 分片
```
# 4 个 shard — 文档分布在各个 shard 中
index = lucivy.Index.create("/tmp/sharded", fields=[
{"name": "body", "type": "text", "stored": True}
], shards=4)
```
### 分布式搜索(多机)
```
import lucivy
query = {"type": "contains", "field": "body", "value": "mutex"}
# 1. 每个节点导出其本地 BM25 统计信息
stats_a = node_a.export_stats(query) # JSON string
stats_b = node_b.export_stats(query) # JSON string
# 2. Coordinator 合并来自所有节点的统计信息
merged = lucivy.merge_stats([stats_a, stats_b])
# 3. 每个节点使用全局统计信息进行搜索(正确的 IDF)
results_a = node_a.search_with_global_stats(query, merged, limit=10)
results_b = node_b.search_with_global_stats(query, merged, limit=10)
# 4. Coordinator 按分数合并 top-K 结果
all_results = sorted(results_a + results_b, key=lambda r: r.score, reverse=True)[:10]
```
### 增量同步
```
# Client 将其 shard 版本发送给 server
client_versions = client_index.shard_versions
# Server:导出 delta(仅包含自 client 版本以来发生更改的 segment)
delta = server_index.export_sharded_delta(client_versions)
# Client:应用 delta(写入新 segment,移除旧 segment,重新加载 reader)
client_index.apply_sharded_delta(delta)
```
## 功能特性
### 搜索
- **子串搜索** —— 在 token 内部查找文本,而不仅仅是整个 token
- **模糊搜索** —— 带有三元组加速的 Levenshtein 距离
- **正则表达式** —— 带字面量部分优化的跨 token 正则表达式
- **短语** —— 具有跨 token 感知的多 token 邻接匹配
- **前缀 / startsWith** —— 锚定到 token 起始位置 (SI=0)
- **精确匹配** —— 跨 token 感知的完整 token 匹配
- **高亮** —— 所有查询类型的字节偏移量高亮
- **过滤器** —— 非文本字段过滤(数值范围、相等、隶属关系)
- **BM25 评分** —— 正确的跨分片统计
- **More Like This** —— 通过参考文本查找相似文档
### 索引
- **分片** —— 可配置的路由将文档分发到 N 个分片以进行并行搜索
- **增量** —— 通过延迟提交添加、删除、更新文档
- **后台定稿** —— 段落定稿在池线程中运行,不在索引器中
- **可配置的合并策略** —— 带有可调阈值的基于日志的合并
### 同步与分发
- **LUCE** —— 完整的快照导出/导入(所有分片在一个数据块中)
- **LUCID** —— 单个分片的增量差异同步(仅限已更改的段)
- **LUCIDS** —— 跨多个分片的增量差异同步
- **分布式搜索** —— export_stats / merge / search_with_global_stats 管道
### 平台
- **Python** (PyO3) — `pip install lucivy` — [README](bindings/python/README.md)
- **Node.js** (NAPI) — `npm install lucivy` — [README](bindings/nodejs/README.md)
- **浏览器 / WASM** (emscripten) — SharedArrayBuffer + 多线程 — [README](bindings/emscripten/README.md)
- **Rust** — `lucivy-core` 在 crates.io 上
- **C++** — cxx 桥接
## 查询参考
| 参数 | 类型 | 默认值 | 描述 |
|-----------|------|---------|-------------|
| `type` | string | 必填 | `"contains"`, `"contains_split"`, `"boolean"` 等 |
| `field` | string | 必填 | 要搜索的字段 |
| `value` | string | 必填 | 搜索文本或正则表达式模式 |
| `distance` | int | 0 | 模糊搜索的 Levenshtein 距离 (0 = 精确) |
| `anchor_start` | bool | false | 匹配必须始于 token 边界 (SI=0) |
| `exact_match` | bool | false | 匹配必须覆盖整个 token |
| `regex` | bool | false | 将 value 视为正则表达式模式 |
| `filters` | array | none | 非文本字段过滤器 (eq, gt, in, between, ...) |
### 查询类型
| 类型 | 描述 |
|------|-------------|
| `contains` | 子串、模糊或正则表达式搜索 (跨 token) |
| `contains_split` | 按空格拆分,每个词都是一个 `contains`,以 OR 组合 |
| `boolean` | 使用 must / should / must_not 组合子查询 |
| `startsWith` | Token 前缀 —— 匹配必须始于 token 边界 (SI=0) |
| `term` | 精确的整 token 匹配 (anchor_start + exact_match) |
| `fuzzy` | 模糊子串 (`contains` + `distance` 的别名) |
| `regex` | 正则表达式子串 (`contains` + `regex=true` 的别名) |
| `phrase` | 按顺序相邻的 token |
## 性能
在 Linux 内核源代码树的 90,000 个文件上进行的基准测试(前 20 个结果,3 次运行的平均值):
| 查询 | 1 个分片 | 4 个分片 |
|-------|---------|----------|
| `contains 'mutex_lock'` | 261ms | 137ms |
| `contains 'function'` | 127ms | 131ms |
| `contains_split 'struct device'` | 338ms | 347ms |
| `contains 'sched'` | 119ms | 128ms |
| `startsWith 'sched'` | 185ms | 178ms |
| `fuzzy 'schdule' (d=1)` | 559ms | 318ms |
| `regex 'mutex.*lock'` | - | 373ms |
| `regex 'kmalloc.*sizeof'` | - | 442ms |
| `contains 'drivers'` (path 字段) | 7ms | 7ms |
索引耗时:90K 文档 **50s**(1 个分片)/ **100s**(4 个分片轮询)。
## 架构
```
Document -> Tokenizer -> Postings (inverted index)
-> SFX (suffix FST + sfxpost)
-> Fast fields
-> Doc store (compressed)
Query -> SFX walk (substring/fuzzy/regex)
-> Posting resolve (doc_ids + positions)
-> BM25 scoring (with global stats)
-> Highlights (byte offsets)
```
### SFX 文件格式
每个被索引的段包含:
- `.sfx` — 带有按 SI=0 / SI>0 条目分区的后缀 FST
- `.sfxpost` — 将后缀序数映射到 doc_id 的倒排列表
- `.termtexts` — 用于跨 token 兄弟链解析的 token 文本存储
- `.gapmap` — 用于分隔符跟踪的间隙编码字节序列
### 分片
文档通过可配置路由 (`balance_weight`) 分布到各个分片中:
- **`balance_weight=1.0`** (默认) — 类似轮询。分布均匀,索引最快。
- **`balance_weight=0.2`** — token 感知。将共享稀有 token 的文档放在同一位置。
- **`balance_weight=0.0`** — 纯 token 感知。最大化的同址共存。
## 从源代码构建
```
# Rust 库测试
cargo test --lib
# Python 绑定
cd bindings/python && maturin develop --release
# Node.js 绑定
cargo build -p lucivy-napi --release
cp target/release/liblucivy_napi.so bindings/nodejs/lucivy.node
# C++ 绑定
cargo build -p lucivy-cpp --release
# WASM (emscripten)
bash bindings/emscripten/build.sh
```
## 传承
lucivy 最初是 [tantivy](https://github.com/quickwit-oss/tantivy) v0.22 的一个分支。底层存储层(段、倒排列表、文档存储、快速字段、分词器、聚合)仍然源自 tantivy 的代码库。
该层之上的所有内容都已被重写或从零开始构建:
| 组件 | tantivy | lucivy |
|-----------|---------|--------|
| **搜索** | 词项字典查找(整个 token) | SFX 引擎 —— 后缀 FST,通过兄弟链接和 falling walk 实现跨 token 匹配 |
| **模糊** | 词项字典上的 Levenshtein DFA | SFX 上的三元组鸽巢 —— 无全索引扫描 |
| **正则** | 词项字典上的 DFA | 字面量提取 + SFX 查找 + DFA 验证 |
| **子串** | 不支持 | 原生支持 —— 每个 token 的每个后缀都在 SI=0/SI>0 处被索引 |
| **跨 token** | 不支持 | 兄弟表 + falling walk 跨越 token 边界重构匹配 |
| **高亮** | 非内置 | 所有查询类型(子串、模糊、正则、跨 token)的字节偏移高亮 |
| **线程** | 每次合并执行 `thread::spawn` | luciole —— 自定义 actor 运行时,具有 DAG 执行、流式管道、WaitGraph 诊断、WASM 安全等特性 |
| **分片** | 非内置 | 具有可配置路由的 ShardedHandle,正确的跨分片 BM25 |
| **分布式** | 非内置 | export_stats / merge_stats / search_with_global_stats 管道 |
| **同步** | 非内置 | LUCE 快照,LUCID/LUCIDS 增量差异 |
| **WASM** | 不支持 | 带有 pthreads, SharedArrayBuffer, OPFS 的完整 emscripten 构建 |
| **绑定** | 仅 Rust | Python (PyO3), Node.js (napi-r), C++ (CXX), WASM (emscripten), Rust |
在约 120K 行 tantivy 衍生基础设施之上,新增了约 40K 行原始 lucivy 代码。
感谢 tantivy 团队构建的坚实基础。
## 许可证
MIT。详见 [LICENSE](LICENSE)。
标签:BM25算法, C++, GNU通用公共许可证, Node.js, NVIDIA, Python, Rust, WebAssembly, 代码搜索, 信息检索, 倒排索引, 全文检索, 分布式检索, 可视化界面, 后缀自动机, 向量数据库, 增量同步, 子字符串匹配, 幻觉缓解, 技术文档检索, 搜索引擎, 数据擦除, 数据检索, 文本处理, 无后门, 本地搜索, 模糊搜索, 混合检索, 离线搜索, 网络流量审计, 词法分析, 语义检索, 跨Token匹配, 通知系统, 高亮