OpenMOSS/MOSS-TTS
GitHub: OpenMOSS/MOSS-TTS
MOSS-TTS 是一套开源的高保真语音与声音生成模型家族,覆盖从实时流式 TTS 到语音克隆与音效设计的一站式解决方案。
Stars: 3845 | Forks: 342
# MOSS-TTS 家族









 [English](README.md) | [简体中文](README_zh.md)
MOSS‑TTS 家族是一个开源的**语音与声音生成模型家族**,来自 [MOSI.AI](https://mosi.cn/#hero) 和 [OpenMOSS 团队](https://www.open-moss.com/)。它专为**高保真**、**高表现力**以及**复杂真实场景**而设计,涵盖稳定的长语音生成、多说话人对话、声音/角色设计、环境音效以及实时流式 TTS。
## 新闻
* 2026.4.13: 🚀 MOSS-TTS-Nano 现已上线!我们的约 1 亿参数模型支持多语言语音克隆、48 kHz 立体声输入/输出,并且仅需 4 个 CPU 核心即可运行流式输出。查看 [GitHub 仓库](https://github.com/OpenMOSS/MOSS-TTS-Nano) 和我们的 [博客](https://openmoss.github.io/MOSS-TTS-Nano-Demo/) 获取更多细节。
* 2026.3.31: 📄 我们的 [MOSS-TTSD](https://arxiv.org/pdf/2603.19739) 与 [MOSS-VoiceGenerator](https://arxiv.org/pdf/2603.28086) 技术报告现已发布在 arXiv 上!
* 2026.3.26: 📘 新增了 MOSS-TTS-Realtime 的微调教程。
* 2026.3.20: 📄 我们的 [技术报告](https://arxiv.org/pdf/2603.18090) 现已发布在 arXiv 上!
* 2026.3.18: 🚀 在配套仓库 [`OpenMOSS/llama.cpp`](https://github.com/OpenMOSS/llama.cpp/tree/moss-tts-firstclass) 中新增了第一流的 MOSS-TTS `llama.cpp` 实现,包含端到端文档以及可运行的 GGUF 骨干推理管线和 ONNX 音频编解码器解码。请参阅 [第一流端到端指南](https://github.com/OpenMOSS/llama.cpp/blob/moss-tts-firstclass/docs/moss-tts-firstclass-e2e.md)。
* 2026.3.16: 📘 新增了针对 MossTTSLocal 架构的微调教程,适用于 MOSS-TTS-Local-Transformer!
* 2026.3.12: 🚀 为 `MossTTSDelay` 架构新增 SGLang 后端支持,使 MOSS-TTS(Delay)与 MOSS-SoundEffect 的高效推理成为可能,生成吞吐量提升约 **3 倍**!
* 2026.3.11: 📘 新增了针对 MossTTSDelay 架构的微调教程,适用于 MOSS-TTS(Delay)、MOSS-TTSD、MOSS-VoiceGenerator 和 MOSS-SoundEffect!
* 2026.3.10: ⚡️ 显著优化了 llama.cpp 推理管线中的 VRAM 使用量。现在 8B 模型即可适配 8GB GPU!
* 2026.3.4: 🚀 新增 **PyTorch-free 推理支持**——通过 **llama.cpp + ONNX Runtime** 实现轻量级设备端部署。量化的 **GGUF 权重**已发布在 [OpenMOSS-Team/MOSS-TTS-GGUF](https://huggingface.co/OpenMOSS-Team/MOSS-TTS-GGUF),**ONNX 音频编解码器**可在 [OpenMOSS-Team/MOSS-Audio-Tokenizer-ONNX](https://huggingface.co/OpenMOSS-Team/MOSS-Audio-Tokenizer-ONNX) 获取。更多细节请参考 [llama.cpp 后端](#llamacpp-backend-torch-free-inference)。
* 2026.3.4: 🎉 我们在 [ClawHub](https://clawhub.ai) 中为 🦞 OpenClaw 添加了 MOSS-TTS 技能:[feishu-voice-tts](https://clawhub.ai/helloeveryworlds/feishu-voice-tts) 和 [moss-tts-voice](https://clawhub.ai/luogao2333/moss-tts-voice)。
* 2026.2.10: 🎉🎉🎉 我们已发布 [MOSS-TTS 家族](https://huggingface.co/collections/OpenMOSS-Team/moss-tts)。查看我们的 [博客](https://mosi.cn/#models) 获取更多细节!我们的 **Huggingface 空间**已上线:[MOSS-TTS](https://huggingface.co/spaces/OpenMOSS-Team/MOSS-TTS)、[MOSS-TTSD-v1.0](https://huggingface.co/spaces/OpenMOSS-Team/MOSS-TTSD-v1.0)、[MOSS-VoiceGenerator](https://huggingface.co/spaces/OpenMOSS-Team/MOSS-VoiceGenerator)。
## 演示
## 目录
- [介绍](#introduction)
- [模型架构](#model-architecture)
- [已发布模型](#released-models)
- [支持语言](#supported-languages)
- [快速入门](#quickstart)
- [OpenClaw API 技能](#openclaw-api-skills)
- [环境搭建](#environment-setup)
- [(可选) 安装 FlashAttention 2](#optional-install-flashattention-2)
- [MOSS-TTS 基础用法](#moss-tts-basic-usage)
- [微调](#fine-tuning)
- [llama.cpp 后端(无 PyTorch 推理)](#llamacpp-backend-torch-free-inference)
- [SGLang 后端(加速推理)](#sglang-backend-accelerated-inference)
- [评估](#evaluation)
- [MOSS-TTS](#moss-tts-seed-tts-eval)
- [MOSS-TTSD](#moss-ttsd-subjective--ttsd-eval)
- [MOSS-VoiceGenerator](#moss-voicegenerator-subjective)
- [MOSS-TTS-Nano](#moss-tts-nano)
- [介绍](#moss-tts-nano-introduction)
- [模型权重](#moss-tts-nano-model-weights)
- [MOSS-Audio-Tokenizer](#moss-audio-tokenizer)
- [介绍](#mat-intro)
- [模型权重](#model-weights)
- [客观重建评估](#objective-reconstruction-evaluation)
- [更多信息](#more-information)
- [社区项目](#community-projects)
- [引用](#citation)
## 介绍
[English](README.md) | [简体中文](README_zh.md)
MOSS‑TTS 家族是一个开源的**语音与声音生成模型家族**,来自 [MOSI.AI](https://mosi.cn/#hero) 和 [OpenMOSS 团队](https://www.open-moss.com/)。它专为**高保真**、**高表现力**以及**复杂真实场景**而设计,涵盖稳定的长语音生成、多说话人对话、声音/角色设计、环境音效以及实时流式 TTS。
## 新闻
* 2026.4.13: 🚀 MOSS-TTS-Nano 现已上线!我们的约 1 亿参数模型支持多语言语音克隆、48 kHz 立体声输入/输出,并且仅需 4 个 CPU 核心即可运行流式输出。查看 [GitHub 仓库](https://github.com/OpenMOSS/MOSS-TTS-Nano) 和我们的 [博客](https://openmoss.github.io/MOSS-TTS-Nano-Demo/) 获取更多细节。
* 2026.3.31: 📄 我们的 [MOSS-TTSD](https://arxiv.org/pdf/2603.19739) 与 [MOSS-VoiceGenerator](https://arxiv.org/pdf/2603.28086) 技术报告现已发布在 arXiv 上!
* 2026.3.26: 📘 新增了 MOSS-TTS-Realtime 的微调教程。
* 2026.3.20: 📄 我们的 [技术报告](https://arxiv.org/pdf/2603.18090) 现已发布在 arXiv 上!
* 2026.3.18: 🚀 在配套仓库 [`OpenMOSS/llama.cpp`](https://github.com/OpenMOSS/llama.cpp/tree/moss-tts-firstclass) 中新增了第一流的 MOSS-TTS `llama.cpp` 实现,包含端到端文档以及可运行的 GGUF 骨干推理管线和 ONNX 音频编解码器解码。请参阅 [第一流端到端指南](https://github.com/OpenMOSS/llama.cpp/blob/moss-tts-firstclass/docs/moss-tts-firstclass-e2e.md)。
* 2026.3.16: 📘 新增了针对 MossTTSLocal 架构的微调教程,适用于 MOSS-TTS-Local-Transformer!
* 2026.3.12: 🚀 为 `MossTTSDelay` 架构新增 SGLang 后端支持,使 MOSS-TTS(Delay)与 MOSS-SoundEffect 的高效推理成为可能,生成吞吐量提升约 **3 倍**!
* 2026.3.11: 📘 新增了针对 MossTTSDelay 架构的微调教程,适用于 MOSS-TTS(Delay)、MOSS-TTSD、MOSS-VoiceGenerator 和 MOSS-SoundEffect!
* 2026.3.10: ⚡️ 显著优化了 llama.cpp 推理管线中的 VRAM 使用量。现在 8B 模型即可适配 8GB GPU!
* 2026.3.4: 🚀 新增 **PyTorch-free 推理支持**——通过 **llama.cpp + ONNX Runtime** 实现轻量级设备端部署。量化的 **GGUF 权重**已发布在 [OpenMOSS-Team/MOSS-TTS-GGUF](https://huggingface.co/OpenMOSS-Team/MOSS-TTS-GGUF),**ONNX 音频编解码器**可在 [OpenMOSS-Team/MOSS-Audio-Tokenizer-ONNX](https://huggingface.co/OpenMOSS-Team/MOSS-Audio-Tokenizer-ONNX) 获取。更多细节请参考 [llama.cpp 后端](#llamacpp-backend-torch-free-inference)。
* 2026.3.4: 🎉 我们在 [ClawHub](https://clawhub.ai) 中为 🦞 OpenClaw 添加了 MOSS-TTS 技能:[feishu-voice-tts](https://clawhub.ai/helloeveryworlds/feishu-voice-tts) 和 [moss-tts-voice](https://clawhub.ai/luogao2333/moss-tts-voice)。
* 2026.2.10: 🎉🎉🎉 我们已发布 [MOSS-TTS 家族](https://huggingface.co/collections/OpenMOSS-Team/moss-tts)。查看我们的 [博客](https://mosi.cn/#models) 获取更多细节!我们的 **Huggingface 空间**已上线:[MOSS-TTS](https://huggingface.co/spaces/OpenMOSS-Team/MOSS-TTS)、[MOSS-TTSD-v1.0](https://huggingface.co/spaces/OpenMOSS-Team/MOSS-TTSD-v1.0)、[MOSS-VoiceGenerator](https://huggingface.co/spaces/OpenMOSS-Team/MOSS-VoiceGenerator)。
## 演示
## 目录
- [介绍](#introduction)
- [模型架构](#model-architecture)
- [已发布模型](#released-models)
- [支持语言](#supported-languages)
- [快速入门](#quickstart)
- [OpenClaw API 技能](#openclaw-api-skills)
- [环境搭建](#environment-setup)
- [(可选) 安装 FlashAttention 2](#optional-install-flashattention-2)
- [MOSS-TTS 基础用法](#moss-tts-basic-usage)
- [微调](#fine-tuning)
- [llama.cpp 后端(无 PyTorch 推理)](#llamacpp-backend-torch-free-inference)
- [SGLang 后端(加速推理)](#sglang-backend-accelerated-inference)
- [评估](#evaluation)
- [MOSS-TTS](#moss-tts-seed-tts-eval)
- [MOSS-TTSD](#moss-ttsd-subjective--ttsd-eval)
- [MOSS-VoiceGenerator](#moss-voicegenerator-subjective)
- [MOSS-TTS-Nano](#moss-tts-nano)
- [介绍](#moss-tts-nano-introduction)
- [模型权重](#moss-tts-nano-model-weights)
- [MOSS-Audio-Tokenizer](#moss-audio-tokenizer)
- [介绍](#mat-intro)
- [模型权重](#model-weights)
- [客观重建评估](#objective-reconstruction-evaluation)
- [更多信息](#more-information)
- [社区项目](#community-projects)
- [引用](#citation)
## 介绍
` 或 `data:audio/wav;base64,{b64_audio}`,其中 `b64_audio` 是 WAV 文件的 Base64 字符串
#### MOSS-SoundEffect
```
curl -X POST http://localhost:30000/generate \
-H "Content-Type: application/json" \
-d '{
"text": "${token:125}${ambient_sound:a sports car roaring past on the highway.}",
"sampling_params": {
"max_new_tokens": 512,
"temperature": 1.5,
"top_p": 0.6,
"top_k": 50
}
}'
```
- `text` 应仅包含两个标记字段:`${token:125}` 和 `${ambient_sound:...}`,其中 `${ambient_sound:...}` 后的内容为期望音效的自然语言描述
- 建议使用 `${token:125}` 以获得更稳定的生成
- 请勿传入 `audio_data`,否则模型可能输出域外结果
#### 响应
```
{"text": "", "...": "..."}
```
HTTP 响应为 JSON 对象,可能包含多个字段。`.text` 字段存储生成音频的 WAV Base64 字符串。通常只需提取该字段并 Base64 解码即可;例如,将响应保存为 `response.json` 后运行 `jq -r '.text' response.json | base64 -d -i > output.wav`。
## 评估
本节汇总了**家族级评估亮点**,涵盖 MOSS-TTS、MOSS-TTSD 与 MOSS-VoiceGenerator。完整细节请参见各模型卡片。
### MOSS-TTS
MOSS-TTS 在开源零样本 TTS 基准 `Seed‑TTS‑eval` 上达到 SOTA,超越所有开源模型,并接近领先闭源系统。
| 模型 | 参数 | 开源 | EN WER (%) ↓ | EN SIM (%) ↑ | ZH CER (%) ↓ | ZH SIM (%) ↑ |
|---|---:|:---:|---:|---:|---:|---:|
| DiTAR | 0.6B | ❌ |1.69 | 73.5 | 1.02 | 75.3 |
| FishAudio‑S1 | 4B | ❌ | 1.72 | 62.57 | 1.22 | 72.1 |
| CosyVoice3 | 1.5B | ❌ | 2.22 | 72 | 1.12 | 78.1 |
| Seed‑TTS | | ❌ | 2.25 | 76.2 | 1.12 | 79.6 |
| MiniMax‑Speech | | ❌ | 1.65 | 69.2 | 0.83 | 78.3 |
| | | | | | | |
| CosyVoice | 0.3B | ✅ | 4.29 | 60.9 | 3.63 | 72.3 |
| CosyVoice2 | 0.5B | ✅ | 3.09 | 65.9 | 1.38 | 75.7 |
| CosyVoice3 | 0.5B | ✅ | 2.02 | 71.8 | 1.16 | 78 |
| F5‑TTS | 0.3B | ✅ | 2 | 67 | 1.53 | 76 |
| SparkTTS | 0.5B | ✅ | 3.14 | 57.3 | 1.54 | 66 |
| FireRedTTS | 0.5B | ✅ | 3.82 | 46 | 1.51 | 63.5 |
| FireRedTTS‑2 | 1.5B | ✅ | 1.95 | 66.5 | 1.14 | 73.6 |
| Qwen2.5‑Omni | 7B | ✅ | 2.72 | 63.2 | 1.7 | 75.2 |
| FishAudio‑S1‑mini | 0.5B | ✅ | 1.94 | 55 | 1.18 | 68.5 |
| IndexTTS2 | 1.5B | ✅ | 2.23 | 70.6 | 1.03 | 76.5 |
| VibeVoice | 1.5B | ✅ | 3.04 | 68.9 | 1.16 | 74.4 |
| HiggsAudio‑v2 | 3B | ✅ | 2.44 | 67.7 | 1.5 | 74 |
| GLM-TTS | 1.5B | ✅ | 2.23 | 67.2 | 1.03 | 76.1 |
| GLM-TTS-RL | 1.5B | ✅ | 1.91 | 68.1 | **0.89** | 76.4 |
| VoxCPM | 0.5B | ✅ | 1.85 | 72.9 | 0.93 | 77.2 |
| Qwen3‑TTS | 0.6B | ✅ | 1.68 | 70.39 | 1.23 | 76.4 |
| Qwen3‑TTS | 1.7B | ✅ | **1.5** | 71.45 | 1.33 | 76.72 |
| | | | | | | |
| **MossTTSDelay** | **8B** | ✅ | 1.84 | 70.86 | 1.37 | 76.98 |
| **MossTTSLocal** | **1.7B** | ✅ | 1.93 | **73.28** | 1.44 | **79.62** |
### MOSS‑TTSD
#### 客观评估
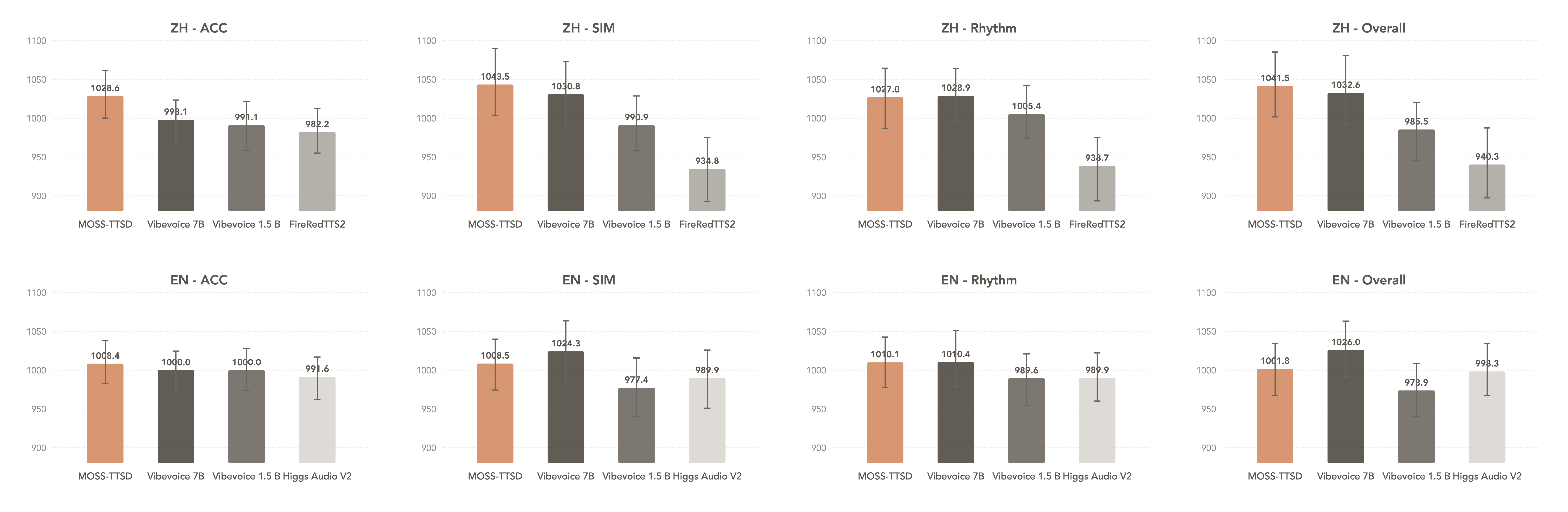
我们使用三个客观指标评估 MOSS‑TTSD‑v1.0:说话人归属准确率(ACC)、说话人相似度(SIM)和词错误率(WER)。与多个开源及闭源模型对比,结果显示 MOSS‑TTSD‑v1.0 在各方面均达到最佳或次佳。
| 模型 | ZH - SIM | ZH - ACC | ZH - WER | EN - SIM | EN - ACC | EN - WER |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: |
| **与开源模型对比** | | | | | | |
| **MOSS-TTSD-v1.0** | **0.7949** | **0.9587** | **0.0485** | **0.7326** | **0.9626** | 0.0988 |
| MOSS-TTSD-v0.7 | 0.7423 | 0.9391 | 0.0517 | 0.6743 | 0.9266 | 0.1612 |
| Vibevoice 7B | 0.7590 | 0.9222 | 0.0570 | 0.7140 | 0.9554 | **0.0946** |
| Vibevoice 1.5 B | 0.7415 | 0.8798 | 0.0818 | 0.6961 | 0.9353 | 0.1133 |
| FireRedTTS2 | 0.7383 | 0.9022 | 0.0768 | - | - | - |
| Higgs Audio V2 | - | - | - | 0.6860 | 0.9025 | 0.2131 |
| **与闭源模型对比** | | | | | | |
| **MOSS-TTSD-v1.0 (elevenlabs_voice)** | **0.8165** | **0.9736** | 0.0391 | **0.7304** | **0.9565** | 0.1005 |
| Eleven V3 | 0.6970 | 0.9653 | **0.0363** | 0.6730 | 0.9498 | **0.0824** |
| | | | | | | |
| **MOSS-TTSD-v1.0 (gemini_voice)** | - | - | - | **0.7893** | **0.9655** | 0.0984 |
| gemini-2.5-pro-preview-tts | - | - | - | 0.6786 | 0.9537 | **0.0859** |
| gemini-2.5-flash-preview-tts | - | - | - | 0.7194 | 0.9511 | 0.0871 |
| | | | | | | |
| **MOSS-TTSD-v1.0 (doubao_voice)** | **0.8226** | **0.9630** | 0.0571 | - | - | - |
| Doubao_Podcast | 0.8034 | 0.9606 | **0.0472** | - | - | - |
#### 主观评估
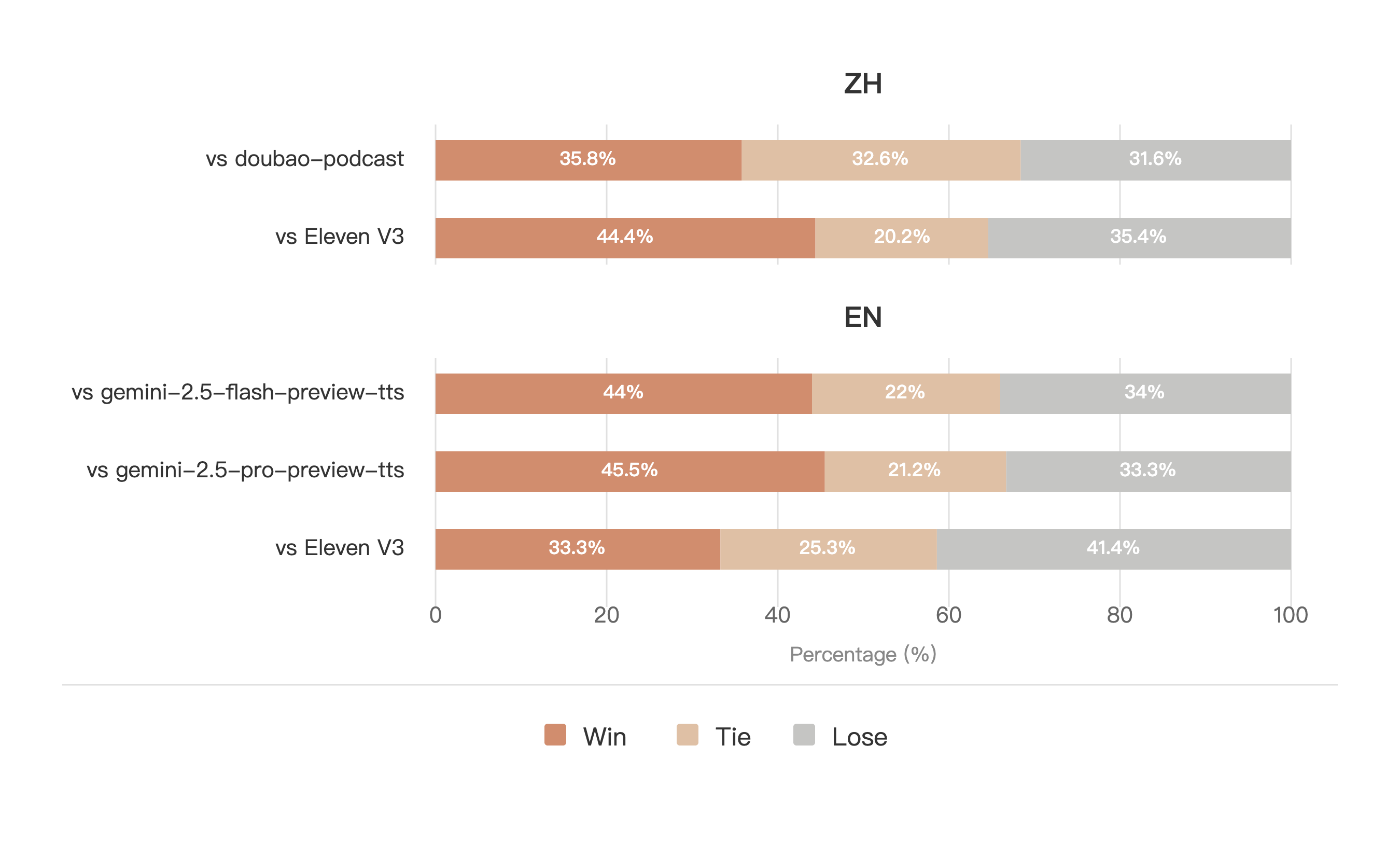
对于开源模型,标注者对每对样本在说话人归属、音色相似度、韵律和整体质量上进行评分。采用 LMSYS Chatbot Arena 的评估方法,计算 Elo 评分与置信区间。
对于闭源模型,标注者选择每对中的整体更优样本,并计算胜率。
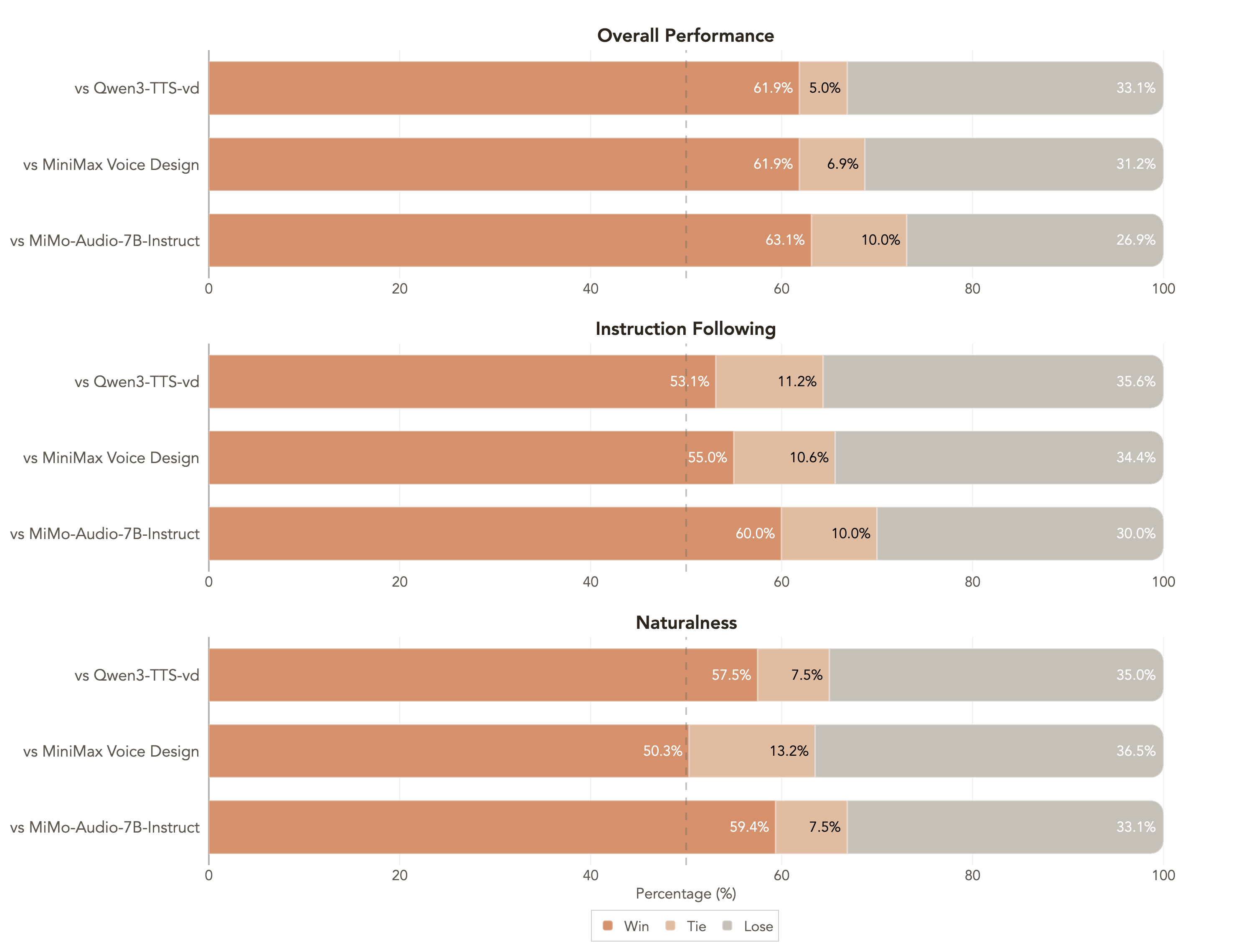
### MOSS‑VoiceGenerator
MOSS‑VoiceGenerator 在**整体偏好**、**指令遵循**与**自然度**方面表现强劲。
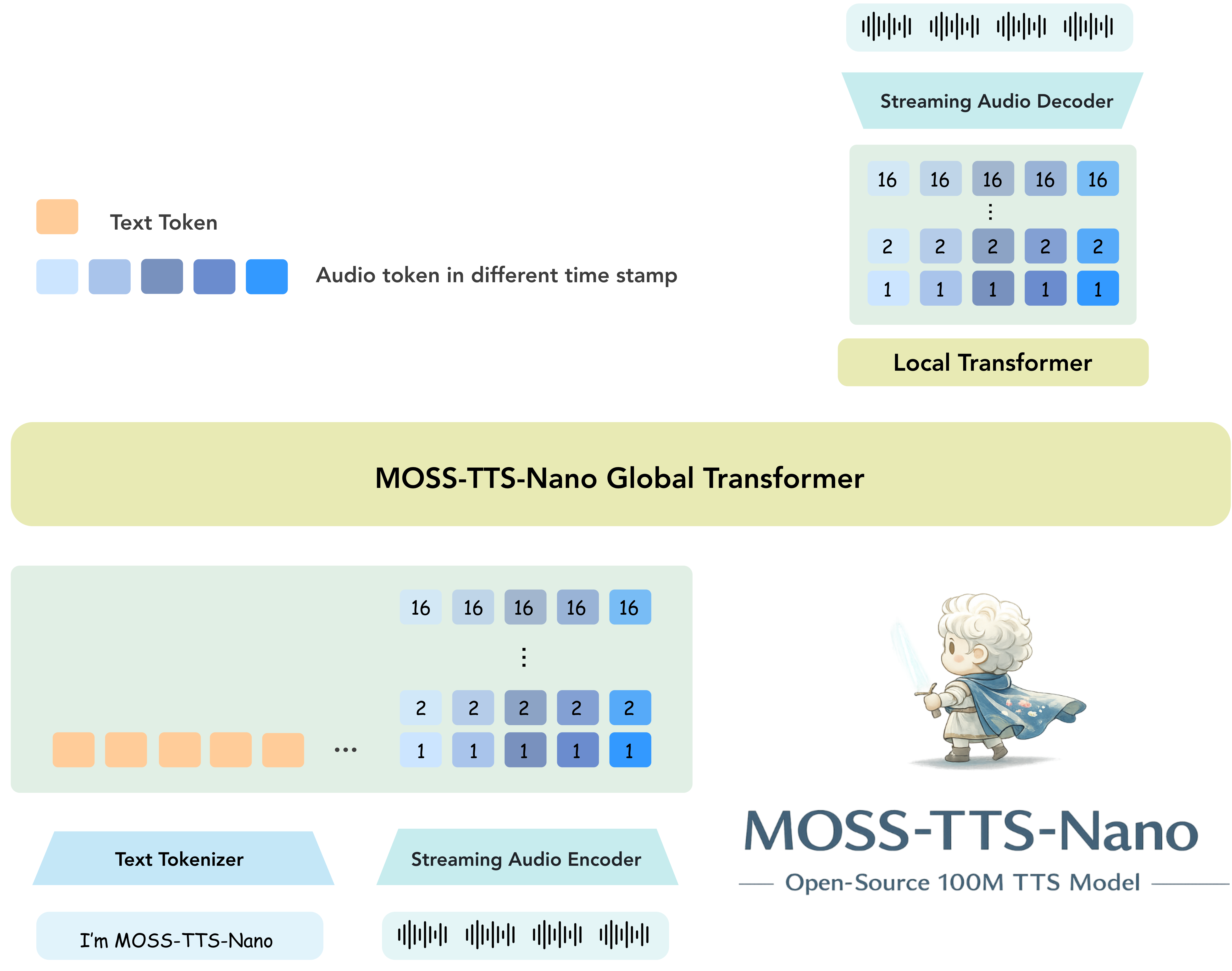



MOSS-TTS-Nano 架构
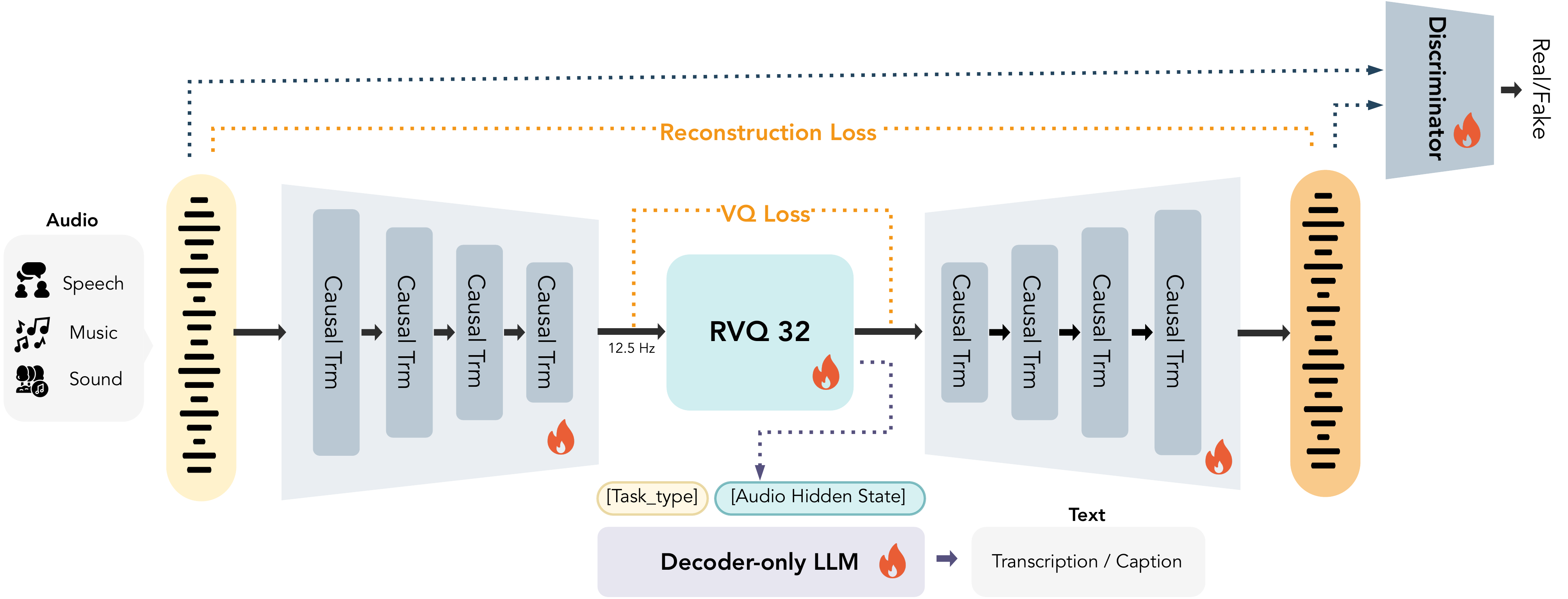
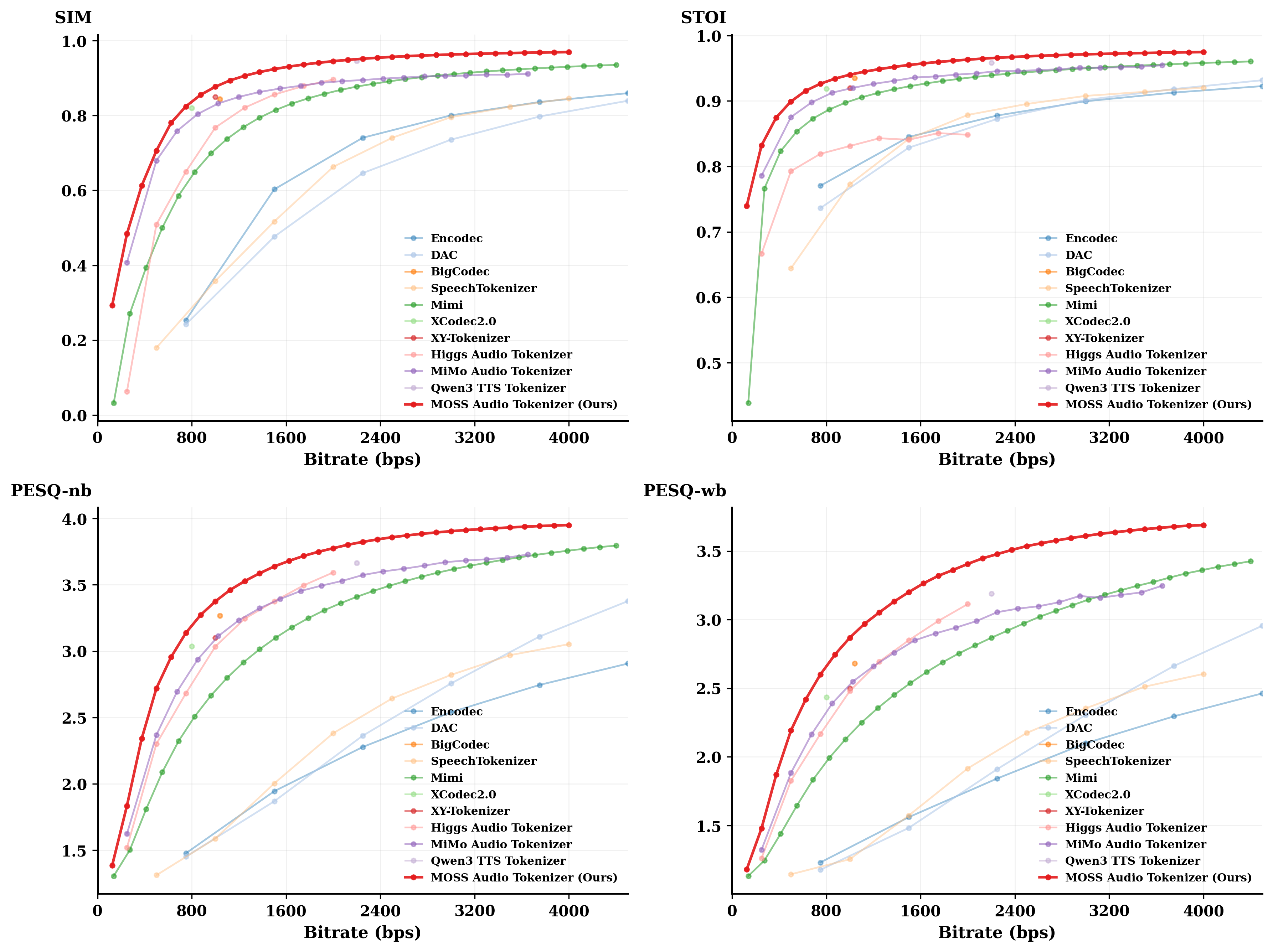
### 模型权重 | 模型 | Hugging Face | ModelScope | | :---: | :---: | :---: | | **MOSS-TTS-Nano** | [](https://huggingface.co/OpenMOSS-Team/MOSS-TTS-Nano) | [](https://modelscope.cn/models/openmoss/MOSS-TTS-Nano) | ## MOSS-Audio-Tokenizer ### 介绍 **MOSS-Audio-Tokenizer** 作为整个 MOSS-TTS 家族的统一离散音频接口。基于 **Cat**(Causal Audio Transformer with Transformer)架构——一种完全由因果 Transformer 块构成的“CNN-free”同构音频编解码器。 - **统一离散桥梁**:为 MOSS-TTS、MOSS-TTSD、MOSS-VoiceGenerator、MOSS-SoundEffect 与 MOSS-TTS-Realtime 提供一致的音频表示。 - **极致压缩与高保真**:将 24 kHz 原始音频压缩至 12.5 Hz 帧率,采用 32 层残差向量量化器(RVQ),支持 0.125 kbps 至 4 kbps 比特率下的高保真重建。 - **海量规模通用音频训练**:从零开始在大规模数据(300 万小时,涵盖语音、音效与音乐)上训练,在开源音频编解码器中达到最先进重建质量。 - **原生流式设计**:纯因果 Transformer 架构专为可扩展性与低延迟流式推理而设计,支持实时生产流程。 如需了解设置、高级用法与评估指标,请访问 [MOSS-Audio-Tokenizer 仓库](https://github.com/OpenMOSS/MOSS-Audio-Tokenizer)。
 Architecture of MOSS Audio Tokenizer
Architecture of MOSS Audio Tokenizer
标签:AIStudio, API文档, arXiv, CNCF毕业项目, Discord, HuggingFace, ModelScope, MOSI.AI, MOSS-TTS, OpenMOSS, TTS, Vectored Exception Handling, 中文模型, 凭据扫描, 博客, 声纹设计, 声音模型, 声音生成, 复杂场景, 多说话人对话, 大模型, 实时流式TTS, 开源模型, 微信, 模型家族, 环境音效, 生成模型, 角色设计, 语音合成, 语音技术, 语音模型, 语音生成, 逆向工具, 长语音稳定, 高保真, 高表现力