vincentkoc/openamnesia
GitHub: vincentkoc/openamnesia
一个 local-first 的 agent 记忆引擎,能将多源 session 日志转化为结构化的 moments、facts 和 skills,为 AI 提供高质量的持续上下文。
Stars: 29 | Forks: 3
Open Amnesia
为 agent 打造的 local-first 记忆。从原始 trace 到可靠的 context。
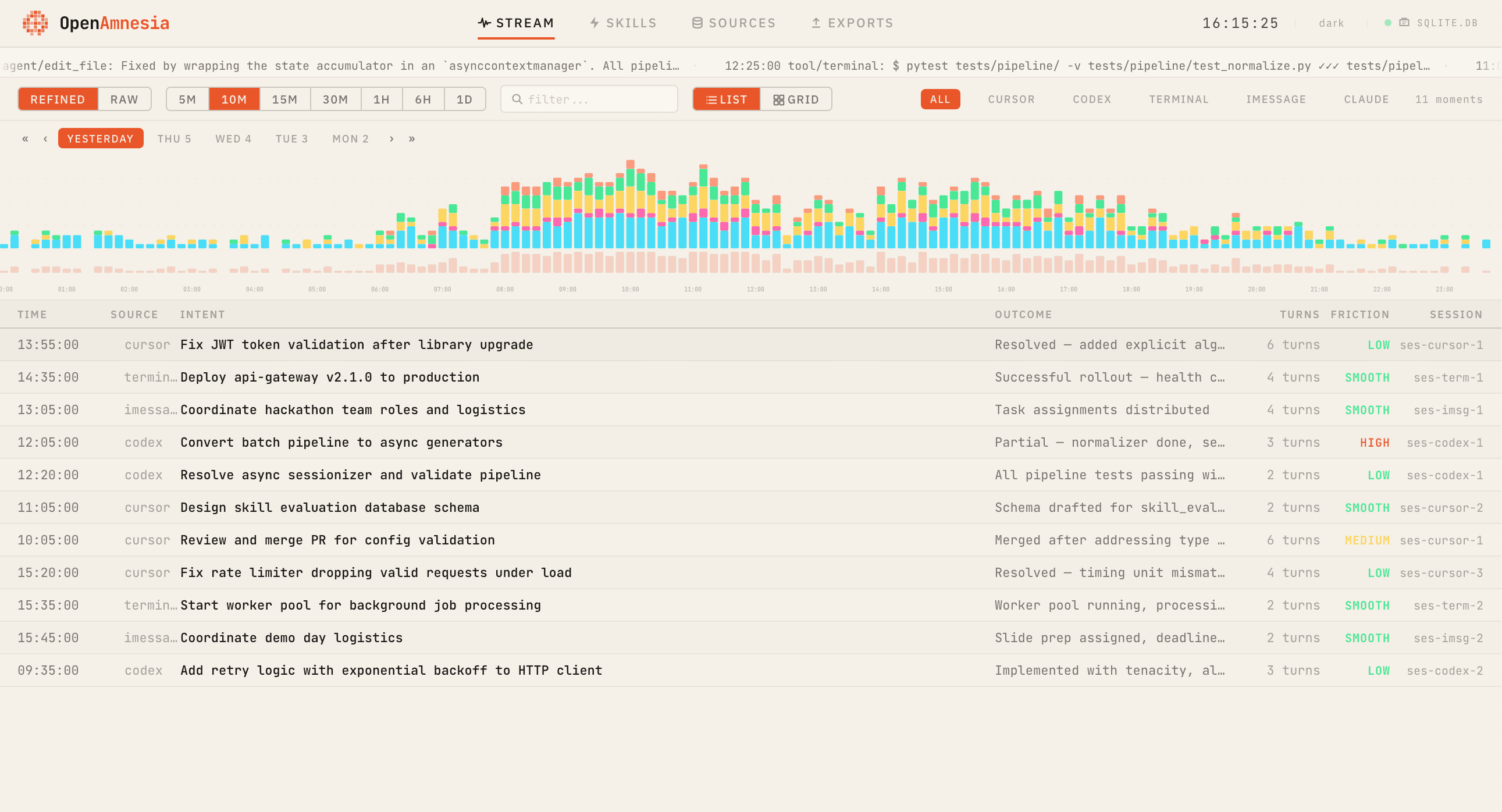
一个持续学习的 context 引擎,能将混乱的 session 日志转化为结构化的 moments、facts 和 skills。
## 灵感 Agent 的好坏取决于它的 context——但大部分 context 都散落在各种凌乱的 trace 中:编码 agent 的 session、IDE 聊天、tool 调用以及个人消息。我们希望有一个持续学习的 context 引擎,能够安全地从真实活动中提取记忆,让 agent 能够以高信噪比的历史记录进行冷启动,并在项目演进时保持最新状态。 Open Amnesia 就是我们的答案:一个 local-first 的“memory stream”,能够自动将混乱的 session 日志转化为结构化的 moments、facts 和 skills。 ## 功能与作用 Open Amnesia 会接入多源日志(Codex、Claude、iMessage),并将它们转换为结构化的 memory 层: - 将异构的 session 格式统一规范为单一的 event schema - 将活动切分为“moments”(intent → actions/tool calls → outcomes → artifacts) - 对 session 进行聚类和总结,生成高信噪比的时间线(按天/周/月) - 提取以下内容的候选对象: - Facts(稳定的 context:项目、决策、人员、配置) - Skills(可重复的工作流:triggers、steps、checks) - 导出: - 基于日期的 memory 文件(`YYYY_MM_DD.md`),供 PKM/agent 使用 - JSON + HTTP endpoints,让任何 agent/runtime 都能按需获取 context 最终结果:为个人和项目 agent 提供一个保护隐私的冷启动 + 持续更新 pipeline。 ## 构建方式 我们构建了一个 local-first 的 pipeline,专注于确保确定性和可重复处理: 1. Connectors 从不同来源(Codex、Claude、iMessage)接入日志 2. Filters + redaction 对数据进行清理和范围界定(时间范围、项目标签、密钥/PII 模式) 3. 规范化将所有内容转换为稳定的 Event IR(包含 tool 调用/结果结构的逐轮记录) 4. Sessionization + clustering 将 events 分组为连贯的 moments 和 threads 5. Enrichment(LLM 辅助的总结 + 提取)仅在确定性预处理完成后运行 6. 存储落地到 SQLite 中作为系统的记录源(system-of-record) 7. 服务层通过 FastAPI API 暴露只读的 context 8. UI(React)提供检查、过滤和导出控制 memory 会每天/每周/每月以一致的模板导出,以便下游 agent 能够稳定地使用它。 ## 遇到的挑战 - Schema 规范化:每个来源记录“turns”的方式都不尽相同(tool 调用、metadata、时间戳、嵌套结构) - 确定性分组:确保时间和项目过滤器在各个 connector 中表现一致 - LLM 噪声 + token 预算:enrichment 成本高昂,如果过早运行,可能会放大混乱的聚类结果 - 去重:避免重复的横幅、重试和 tool 刷屏产生低质量的记忆 - 隐私限制:在提取价值的同时,严格遵守 local-first 和 redaction 的要求 ## 我们引以为傲的成果 - 实现了从三个真实来源(Codex、Claude、iMessage)的端到端接入 - 稳定的 Event IR → Moment → Memory pipeline,且输出可复现 - 基于日期的 memory 导出,并提供一个干净的只读 API 供 agent 使用 - Tool 调用/结果提取,保留了 evidence 和 artifacts(diffs、commands、links) - 实用的过滤功能:支持按时间窗口和“project group”进行过滤,适用于多项目工作流 ## 经验总结 数据的一致性胜过 prompt 的精巧程度。Agent 记忆的质量取决于在任何 LLM 步骤之前的稳定、确定性的预处理——规范化、过滤和去重。一旦数据的“形状”变得可靠,提取和总结的效果就会大幅提升,且成本更低。 ## Open Amnesia 的未来规划 - 持续学习循环:friction signals → skill patches → eval → promote - 按项目划分的 memory stream 和时间线回放 UI - Skill Gym:自动生成并管理 skills,将其作为带版本的 artifacts(triggers/steps/checks/metrics) - 将赞助商的集成作为模块: - You.com:用于 grounded enrichment 和获取新鲜 context - Composio:用于执行操作(创建 issue、发布总结、更新文档) - 第三方集成:用于部署/计算/语音,具体取决于工作流 - Local watchers + LaunchAgent 用于实时接入(可选择开启),并配备更严格的 redaction 策略 ## 技术栈 - 语言:Python, TypeScript - 后端:FastAPI, SQLite - 前端:React, Vite, Tailwind CSS, React Router, TanStack Query - LLM/Enrichment:LiteLLM (OpenAI models), You.com APIs, Composio - 部署:Render, Akash - 工具:ruff, mypy, pytest, pre-commit ## 快速开始 ``` python -m venv .venv source .venv/bin/activate pip install -e . ``` 运行交互式 SDK 菜单: ``` amnesia ``` 端到端演示(为所有已启用的来源执行接入 + discovery): ``` make e2e-all ``` 运行 API/UI: ``` make api make ui ``` 部署: ``` make deploy-render make deploy-akash ``` ## 命令 ``` amnesia # Interactive SDK menu make e2e-all # Full ingest + discovery (recent window) make e2e-all MODE=all # Full ingest + discovery (all time) python scripts/run_ingest.py --config config.yaml python scripts/run_discovery.py --source codex --limit 500 ``` ## API 只读 memory endpoints: - `/api/memory/daily?date=YYYY-MM-DD` - `/api/memory/daily/latest` - `/api/memory/daily/range?start=YYYY-MM-DD&end=YYYY-MM-DD` ## 部署 Render: - 设置 `RENDER_API_KEY` 和 `RENDER_SERVICE_ID` - 运行:`make deploy-render` Akash: - 构建/推送镜像到 GHCR(CI 会自动为 Akash 部署执行此操作) - 设置 `AKASH_WALLET`, `AKASH_KEY_NAME`, `AKASH_KEYRING_BACKEND`, `AKASH_NET` - 可选:`AKASH_IMAGE`(默认为 GHCR) - 运行:`make deploy-akash` CI/CD: - 手动部署工作流:`.github/workflows/deploy.yml` - 选择目标 `render` 或 `akash` ## 配置 ``` store: backend: sqlite dsn: sqlite:///./data/amnesia.db exports: enabled: true memory: enabled: true mode: openclawd output_dir: ./exports/memory formats: ["md"] daily: true weekly: true monthly: true per_project: true e2e: mode: recent since_days: 30 discovery_limit: 500 log_level: INFO ``` ## 过滤器 通用的过滤维度: - 内容:`include_contains` / `exclude_contains` - 分组:`include_groups` / `exclude_groups` - 参与者:`include_actors` / `exclude_actors` - 时间窗口:`since_ts` / `until_ts` (ISO-8601) 示例: ``` sources: - name: codex enabled: true path: ~/.codex pattern: "*.jsonl" include_groups: ["opik-main"] since_ts: "2026-02-01T00:00:00Z" ```标签:AI智能体, 上下文工程, 数据脱敏, 日志处理, 本地优先, 记忆系统, 逆向工具